Python3入门到精通——项目结构¶
作者: Daniel Meng
GitHub: LibertyDream
博客:明月轩
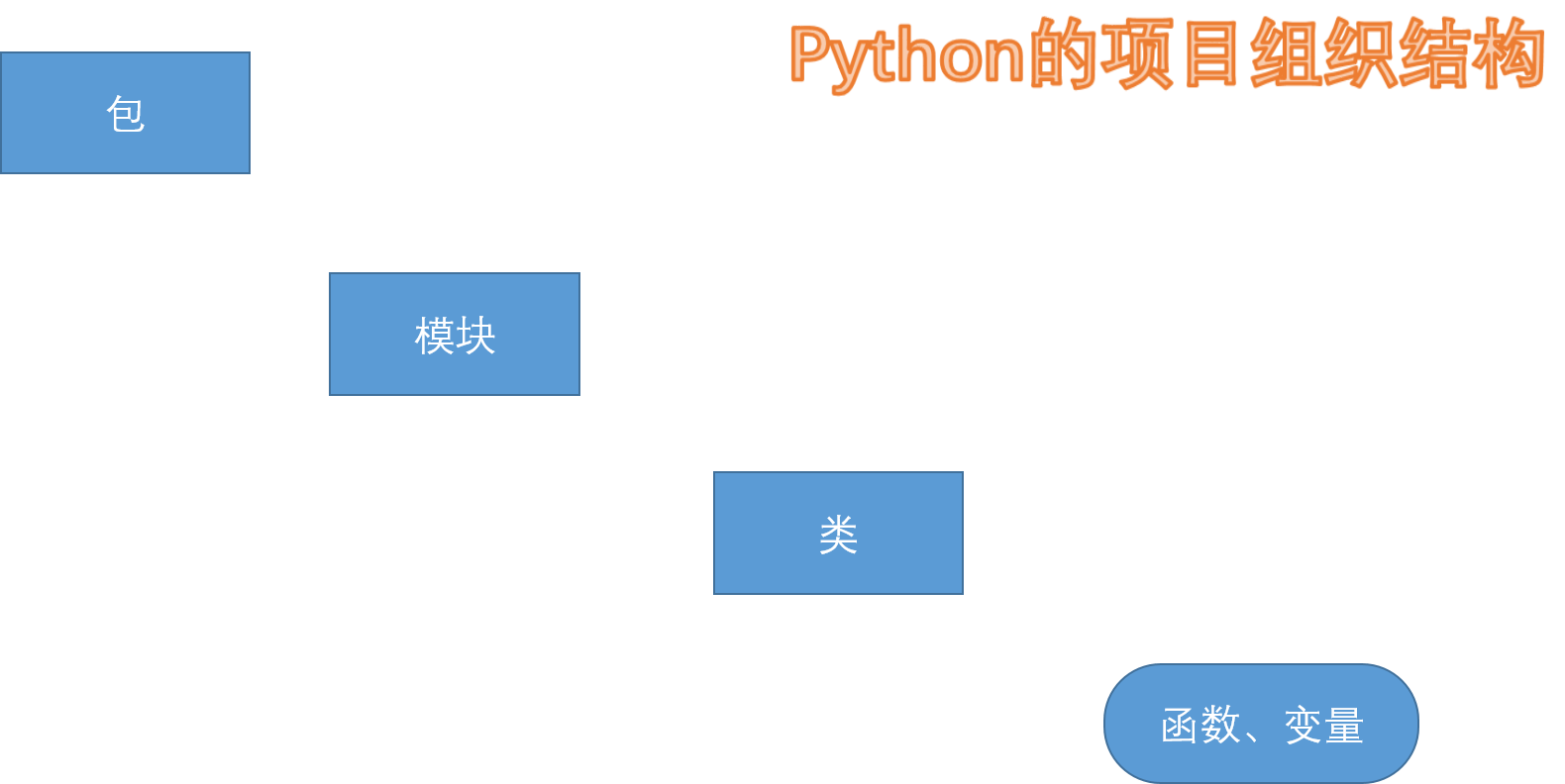
python项目结构和其他语言一样,都是层级结构。
- 包是最顶级的结构,常常是围绕某一特定主题的功能模块的集合
- 模块就是一个个的python文件,用于实现某一种特定功能
- 类是项目结构中的基本建设单位,通常负责模块下某一子功能的实现
一个包可以有多个模块,一个模块可以有多个类,一个类可以有多个函数。函数和变量不属于项目结构,通常从属于类之中,负责完成计算任务和记录、传递数据。
区别于c、java等语言,python使模块和单个文件一体带来的效果是一个文件中可以有多个java中主类一样的类。一个模块中也可以不写类,只是写一些函数或是存放一些变量
包与模块的名字¶
包就是文件夹,文件夹的名字就是包名。但并不是是一个文件夹就是一个包,python识别一个文件夹是否为包是依赖一个文件_init_.py,只要有这个文件(并不需要里面有特定内容),python就会判定当前文件夹是一个包。
包下面可以有子包。模块可以和子包平级
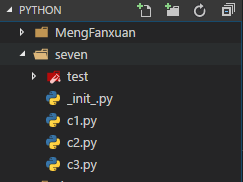
一个模块就是一个.py结尾的文件。模块名就是文件名。当不同包有相同名称的模块时,通过包名.模块名进行调用,前面的包名也就是所谓的命名空间,更准确的表述应该是路径.模块名
上面所说的包识别文件
_init_.py,它也是文件,所以它也是一个模块。但这个模块的名字可不是init,这个模块的名字就是它的包名,如图所示的话其名字就是seven
模块与包的导入¶
有时一个模块下面的数据会期望被其他模块访问,比如对下列文件结构
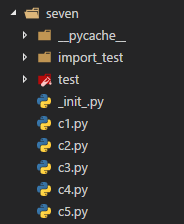
文件c5.py期望访问c4.py中的变量import_var,这时需要使用关键字import来导入模块。单纯的import只能导入模块不能直接导入模块下的变量。于是在c5.py文件中可以这么写
import c4
print(c4.import_var) or do something
python是解释型语言,对变量的访问要遵循先定义后使用的原则,即是说上面两行代码不可颠倒顺序。
导入模块时,如果两个模块不在同一文件夹下,需要加上命名空间,也就是路径,比如上述文件结构变动:
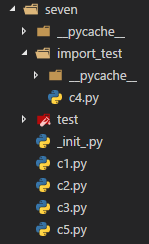
此时c5.py的导入模块语句应变成
import import_test.c4
print(import_test.c4.import_var) or do something
显而易见,当包下层级很多或名字很长时,import的使用会不方便,此时可以使用as关键字。
import import_test.c4 as a
print(a.import_var) or do something
即使使用了as关键词,使用外部变量依旧要使用模块名.变量名的方式来调用。有没有导入后直接使用变量的方式呢?有的,那就是from import导入方式
from import_test.c4 import import_var
print(import_var) or do something
有了from后,import也可以直接导入模块了
from import_test import c4
print(c4.import_var) or do something
有时一个模块里有很多变量需要导入,可以使用*来表示全部导入。但不推荐这么做! 一来这样会带来阅读难度逻辑不清,二者*可能会将不需要的内容也导入进来,增加冗余
from [namespace.]module_name import *
为了限制*,可以使用下面操作限制其代表内容,以c4.py为例
# c4.py
__all__ = ['import_a','import_b','import_c']
import_var = 2
import_a = 3
import_b = 4
import_c = 5
在文件开头加入__all__(all左右是双下划线)列表。此时对于操作from c4 import *来讲,只能获取all列表中的量,即变量import_var并未被导入
在变量不多的时候也可以在import关键字后面,以,分隔列出所需要的变量
from [namespace.]module_name import var1,var2,...
但有限的变量也可能因为名字长度、变量数量的缘故超出python规范的80字符边界。此时可以使用()或\来进行换行
from [namespace.]module_name import (var1,var2,
...)
from [namespace.]module_name import var1,var2, \
var3,var4...
虽然效果相同,但不推荐使用\
__init__.py的作用¶
在前文中我们提到过python用于识别包的文件__init__.py(下文简称为init模块)。它的作用当然不止于此。
- 预处理模块
init模块在其所在包被导入时,python解释器会自动寻找并运行该模块(不论是导入包内模块还是只是一个模块内的变量),所以可以在里面对包内的一些模块进行预处理等操作
- 限制导入模块
上面我们介绍限制import *时,讲到过__all__这个列表,对于init模块同样适用。比如对于如下文件结构
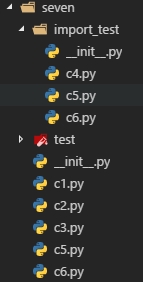
在import_test的初始模块中加入__all__ = ['c4']
此时在seven.c6中若执行from import_test import *并试图访问import_test.c5或import_test.c6中的元素将会报错
# seven.c6
from import_test import *
print(c4.import_a)
print(c4.import_b)
print(c5.import_d)
- 批量导入
python标准库经常会为自定义模块所使用,如果每个模块都要导入标准库中的各自所需的模块,不仅繁琐而且冗余多。此时init模块就派上了用场。
可以将本包内可能用到的系统库通过init模块统一导入,其他模块使用时通过package_name.module_name方式调用即可
包和模块误区纠正¶
- 包和模块不会被重复导入,多个模块内
import相同模块,导入阶段只会导入一次,但会带来代码冗余 - 避免循环导入
假设有如下文件结构
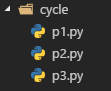
p1~p3三个模块下分别有如下语句
# p1.py
from p2 import p2
p1 = 1
print(p2)
# p2.py
from p3 import p3
p2 = 2
# p3.py
from p1 import p1
p3 = 3
这就构成了循环导入,或许单看都没有问题,但运行时会出错,这是一个很难察觉的问题,特别是在模块很多的大型项目中。终止方式很简单,删掉其中一个的导入即可
- 导入模块时,就会运行模块代码
比如模块p2被导入到p1模块中时,p2模块中的代码便会被执行,如果有像在控制台上的输出,也会输出出来
模块内置变量¶
如上文所示,模块中拥有很多__varName__形式的变量。可以使用dir()函数了解所有变量。在本地python环境下,运行如下代码
test_var_a = 2
test_var_b = 3
infos = dir()
print(infos)
可以得到如下结果:
PS E:\Python\seven> python .\c7.py
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'test_var_a', 'test_var_b']
dir()可以接收模块名、类名作为参数,用于查看模块或类内的变量有哪些
可以看到dir()中包括了隐含的内置变量和自定义的变量。内置变量中需要掌握的有这么几个:
- __doc__ 文件注释
- __name__ 文件全名,即
路径.文件名或者命名空间.文件名 - __file__ 文件的路径地址,结果因执行命令而异,比如可能是windows下的相对路径地址或者是绝对路径地址
- __package__ 包名,有多层的话彼此以
.分隔
__builtins__ 内置函数存在其中
__cached__ 文件缓存路径
__loader__ 加载模块时导入程序所使用的对象,多用于自检
__spec__ 导入模块时所使用的规约
上述说明为一般情况,针对入口文件(进入/启动程序的文件)略有不同。当前文件为入口文件时:
__name__的内容被修改为__main____package__为空,即其不属于任何包,即使实际路径上存在着若干上级目录或包__file__为当前目录。即./entry_file_name形式
有人可能心有疑惑,入口文件既然是文件,按照python理解应该也是模块,那应该也可以当作一个模块来运行。如果想要这么做,在运行该文件时需要这么写命令(必须在入口文件上级目录中执行):
python -m namespace.module_name或者python namespace_path\module_name
# __name__经典应用——让一个模块同时具备可执行性和可导入性
if __name__ == '__main__': # 分辨当前模块是要用于执行还是导入
pass
相对导入和绝对导入¶
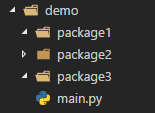
要理解相对导入和绝对导入,首先要理解顶级包的概念。下图展示了常规python项目的结构样式,main.py是入口文件。
对于package2又有如下结构
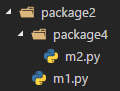
此时从上帝视角看,此项目的顶级包应该是demo,但是因为入口文件main.py处于demo之下,所以是访问不到的,也因此顶级包具体是谁需要看入口文件的位置。可以通过打印__package__来检验。
print(__package__)
PS E:\Python\demo> python .\main.py
None
如果main中导入m2。对m2来讲此时的顶级包是package2,即最多到main同级的包。
# main.py
import package2.package4.m2
# m2.py
print(__package__)
PS E:\Python\demo> python .\main.py
package2.package4
这里的顶级包.次级包. ... .模块名的访问方式就是绝对导入
相对导入使用的符号是.,一个.表示当前目录,..表示上级目录,...表示上上级目录,以此类推
相对导入使用方式是from .基于当前模块位置的路径.模块名 import something,入口文件内不能使用相对导入,import后面不能使用相对导入
本例中可以这样使用
# main.py
import package2.package4.m2
# m1.py
demo_var = 2
print(__package__)
# m2.py
from ..m1 import demo_var
print(__package__)
PS E:\Python\demo> python .\main.py
package2
package2.package4
main调用m2,m2调用了m1,m1的包路径优先输出,之后输出m2的。要留意,这里m1,m2的顶级包都只是到达了main同级的package2
相对导入的实现实际上是依靠__name__这一内置变量,上面说过入口文件的__name__会被修改为__main__,所以相对导入在入口文件中不行。如果非要在入口文件中使用相对导入,可以使用上文所说的通过视入口文件为模块的方式运行程序