Python3入门到精通——正则表达式与JSON¶
作者: Daniel Meng
GitHub: LibertyDream
博客:明月轩
什么是正则表达式¶
正则表达式是一种特殊的字符串序列,用于检测接收到的字符串是否符合特定的模式或规则。如果符合规则,我们说字符串与正则表达式相匹配。常用于检索、替换或者修改文本,应用有邮件格式检测,电话号码检测等等。
比如说,现在我们想查询字符串 sub = abc 是否存在于字符串 s = xaababcbcd 中。abc 可以被视为要求严格对应的一条正则表达式。
正则表达式通常自左向右检测匹配结果,所以从第一个字符开始匹配 s[0] == sub[0],匹配标绿,反之为红
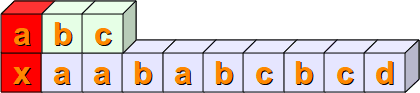
第一个字符不匹配,向右滑动一格检测 s[1:4] == sub
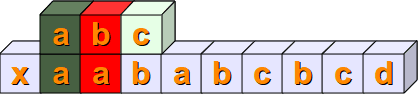
第二个字符不匹配,匹配失败,递归继续向右滑动,直到 s[4:7]==sub,匹配完成
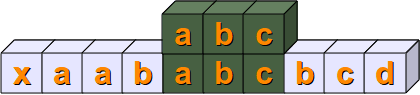

应用实例¶
导入表达式库
import re
硬件与版本
%load_ext watermark
%watermark -v -m -p ipywidgets,re
普通字符匹配

# 检索 hungry
re.search(r'hungry','Stay hungry, Stay foolish!').group()
通配符

re.findall(r'b.d','bad,bed,bid,bud')
定位符
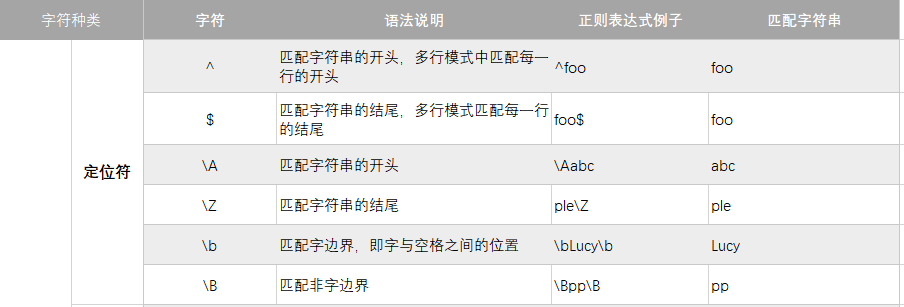
# 匹配字符串开头的字母
print('^ 示例:', re.search(r'^\w', 'I am Daniel Meng').group())
print('\A 示例:', re.search(r'\A\w', 'I am Daniel Meng').group())
# 匹配字符串结尾的字母
print('$ 示例:', re.search(r'\w$', 'I am Daniel Meng').group())
print('\Z 示例:', re.search(r'\w\Z', 'I am Daniel Meng').group())
# 匹配姓名 Daniel Meng
print('\\b 示例:', re.search(r'\bDaniel Meng\b', 'I am Daniel Meng haha').group())
# 匹配不是开头或结尾的app,即左右两边都是字符
print('\\B 示例:', re.findall(r'\Bapp\B', 'app capp appd eappe app app'))
限定符
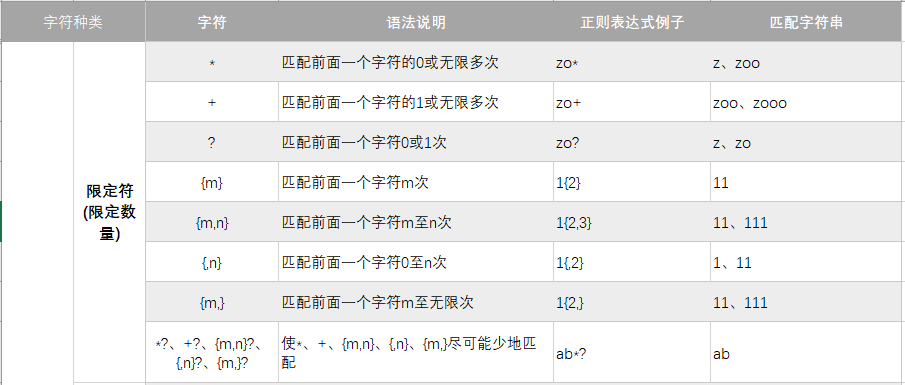
text = 'google good book'
# g 后面有 0 或以上的 o
print('* 示例:',re.findall(r'go*',text))
# g 后面有 0 或 1 个 o
print('? 示例:',re.findall(r'go?',text))
# g 后面有 1 个以上的 o
print('+ 示例:',re.findall(r'go+',text))
# g 后面有 1 或 2 个 o
print('{} 示例:',re.findall(r'go{1,2}',text))
# 懒惰匹配
print('懒惰匹配示例:',re.findall(r'go*?',text), re.findall(r'go+?',text))
转义字符

# 匹配句子中的逗号
print('\\ 示例:',re.search(r'\,', 'Stay hungry, Stay foolish').group())
分支条件

print('| 示例:',re.search(r'zhuang|zhunag', 'zhuang zhunag').group())
字符集合
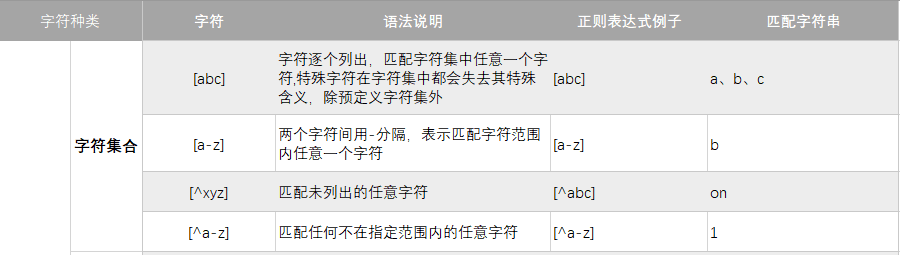
# 匹配字符集中的任意字符
print('[a-z] 示例:',re.search(r'[a-z]+', 'Tear down the wall').group())
# 匹配字符集之外的任意字符
print('[^a-z] 示例:',re.search(r'[^a-z]+', 'Tear down the wall').group())
分组
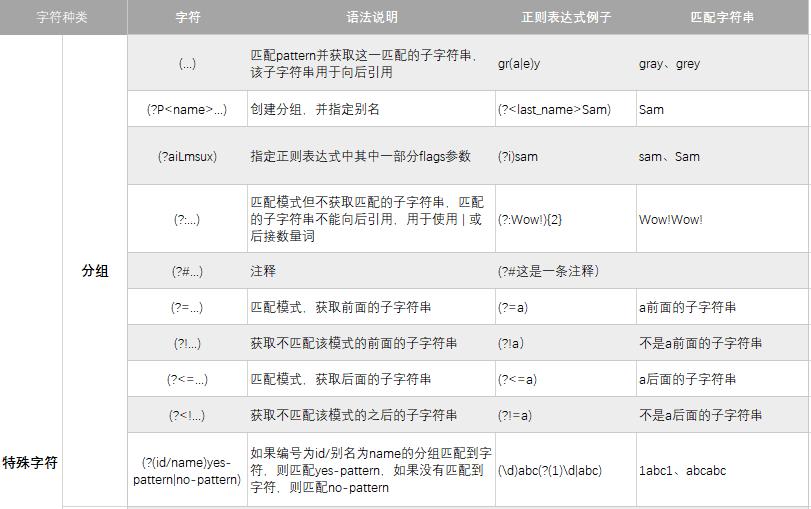
# 分组的向后引用
print('(...) 示例:', re.search(r'(ha)\1\1','hahaha').group())
# 给分组命名
print('(?P<name>) 示例:', re.search(r'(?P<one>)\w+','ha ha ha').group())
# 匹配 hello 忽略大小写
print('(?i) 示例:', re.findall(r'(?i)hello','hello Hello'))
# 添加注释
print('(?#) 示例:', re.search(r'(?#匹配笑声)\w+ \w+','ha ha').group())
# 匹配 def 前的 abc
print('(?=) 示例1:', re.search(r'abc(?=def)','defabc'))
print('(?=) 示例2:', re.search(r'abc(?=def)','abcdef').group())
# 匹配不在 def 前的 abc
print('(?!) 示例1:', re.search(r'abc(?!def)','defabc').group())
print('(?!) 示例2:', re.search(r'abc(?!def)','abcdef'))
# 匹配 abc 后的 def
print('(?<=) 示例:', re.search(r'(?<=abc)def','abcdef').group())
# 匹配不在 abc 后面的 def
print('(?<!) 示例:', re.search(r'(?<!abc)def','abcdef'))
# 如果结尾是数字匹配数字,否则匹配 haha
print('(?(id/name) yes-pattern | no-parrtern) 示例1:',
re.search(r'(\w+) good (?(1)\w+|---)','read good book').group())
print('(?(id/name) yes-pattern | no-parrtern) 示例2:',
re.search(r'(\d+)? good (?(1)\d+|\w+)','read good book').group())
向后引用

print(re.search(r'(?P<number>\d)abc(?P=number)','1abc1').group())
print(re.search(r'(?P<number>\d)abc\1','1abc1').group())
预定义字符
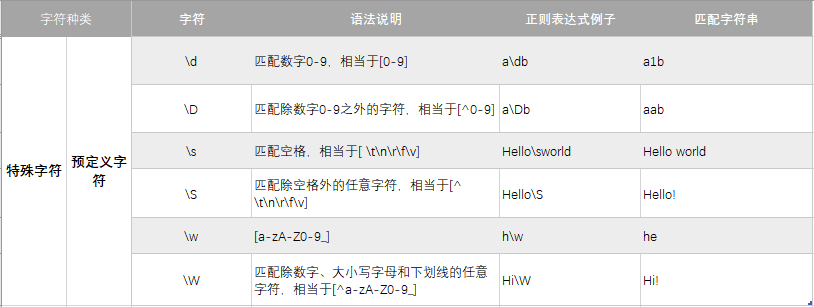
# 找出QQ号
print(re.search(r'\d+', 'Li Meimei has a QQ called 19202120291. What"s about Han Lei?').group())
# 找出QQ号之前的内容
print(re.search(r'\D+', 'Li Meimei has a QQ called 19202120291. What"s about Han Lei?').group())
# 匹配 Li Meimei
print(re.search(r'Li\sMeimei', 'Li Meimei has a QQ called 19202120291. What"s about Han Lei?').group())
# 匹配 Lei?
print(re.search(r'Lei\S', 'Li Meimei has a QQ called 19202120291. What"s about Han Lei?').group())
# 匹配句首单词
print(re.search(r'\w+', 'Li Meimei has a QQ called 19202120291. What"s about Han Lei?').group())
# 匹配句尾标点
print(re.search(r'\W$', 'Li Meimei has a QQ called 19202120291. What"s about Han Lei?').group())
re模块¶
从上面例子里应该会注意到,Python 里想要使用正则表达式,离不开 re 模块。严格的 re 运用三板斧为:
- 将构成正则表达式的字符串编译成 Pattern 实例
- 使用 Pattern 与字符串进行匹配,得到匹配结果 Match 实例
- 使用 Match 实例获取匹配到的信息
import re
pattern = re.compile(r'\d{4}-\d{2}-\d{2}')
# 不会匹配到生日
ret = pattern.match('Tom was born on 2000-01-01')
if ret is not None:
print(ret.group())
match 方法是从头开始匹配的,如果第一个字符起就不符合表达式,则自动停止搜索并返回 None
pattern.match('2000-01-01 is Tom"s birthday').group()
re 模块里提供了大量正则表达式的处理方法,可能会用到的有
| 函数 | 功能 | 函数 | 功能 |
|---|---|---|---|
| re.compile ( ) | 将字符串形式的正则表达式编译为Pattern对象 | re.match ( ) | 匹配字符串开头 |
| re.search ( ) | 从左到右扫描字符串,返回对应第一个匹配对象 | re.finall ( ) | 匹配的子字符串以列表形式返回 |
| re.finditer ( ) | 返回匹配访问顺序 | re.split ( ) | 按照能够匹配的子串将string分割后返回列表 |
| re.sub ( ) | 输出修改替换后的字符串 | re.subn ( ) | 返回一个元组(新字符串,替换次数) |
| re.escape ( ) | 转义除ASCII字母、数字和下划线的所有字符 | re.purge ( ) | 清除所有正则表达式缓存 |
此外,re 模块提供了若干匹配模式,使 re 用起来更加灵活
| flags | 功能 |
|---|---|
| re.I(re.IGNORECASE) | 忽略大小写(括号内是完整写法,下同) |
| re.M(MULTILINE) | 多行模式,'^'和'$'匹配每行的开头和结尾 |
| re.S(DOTALL) | 点任意匹配模式,'.'匹配任意字符,包括换行符 |
| re.L(LOCALE) | 使预定字符类 \w \W \b \B \s \S 取决于当前语言设定 |
| re.U(UNICODE) | 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性 |
| re.X(VERBOSE) | 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释 |
| re.A(ASCII) | 在unicode字符串模式的情况下影响\w, \W, \b, \B, \d, \D, \s, \S,让它们只匹配ASCII码,在bytes字符串模式下会被忽略 |
【例】re.match(pattern, string, flags=0)
pattern:需要匹配的正则表达式
string:需要被匹配的字符串
flags:匹配模式
匹配模式可以使用按位或运算符'|'表示同时生效
pattern = re.compile('ab.c')
print(pattern.search('AB\nC'))
pattern = re.compile('ab.c', re.I)
print(pattern.search('AB\nC'))
pattern = re.compile('ab.c', re.I | re.S)
pattern.search('AB\nC').group()
re.compile¶
re.compile(pattern,flags = 0)
按照字符串 pattern 指定的规则生成一个 re.Pattern 实例,即一个可用的正则表达式对象。实例拥有 match 等匹配方法。
import re
sample_str = 'good good study, day day up'
pattern = re.compile(r'\w[ao]+\w')
print(pattern.findall(sample_str))
re.match¶
re.match(pattern, string, flags=0)
如果字符串开头处有匹配模式的子字符串,则返回匹配对象。即使在多行模式下,也只匹配字符串开头,而非每行开头
re.match()接受参数介绍:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
匹配apple banana orange中开头的 apple
import re
match = re.match(r'apple','apple banana orange')
match.group()
无法匹配文中的 banana
print(re.match(r'banana','apple banana orange'))
| group( ) 格式 | 功能 |
|---|---|
| group([group1, …]) | 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 |
| groups([default]) | 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 |
| groupdict([default]) | 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 |
| start([group]) | 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 |
| end([group]) | 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 |
| span([group]) | 返回(start(group), end(group))。 |
| expand(template) | 将匹配到的分组代入template中然后返回。template中可以使用\id或\g |
import re
match = re.match(r'(\w+)\W+(\w+ \w+)(?P<sign>.*)', 'Hello, Daniel Meng!')
# 获取两个分组
match.group(1,2)
# 获取所有分组
match.groups()
# 获取分组字典,因为只有标点分组有别名,故只会获得一个返回值
match.groupdict()
# 获取姓名分组在字符串中的起始索引
match.start(2)
# 获取姓名分组在字符串中的结尾索引
match.end(2)
# 获取第二个分组的起止区间
match.span(2)
# 将匹配到的分组重构,倒着说
match.expand(r'\2\g<sign> \1')
import re
search = re.search(r'[a-z]+\d', 'aaa bbb1 ccc2 ddd3')
search.group()
import re
re.findall(r'[a-z]+\d', 'aaa bbb1 ccc2 ddd3')
import re
city_iter = re.finditer(r'[A-Z][a-z]+ \w+', 'Bei jing Shang hai Liu yang')
for city in city_iter:
print('go to %s' % city.group())
re.split¶
re.split(pattern,string,maxsplit=0,flags=0)
split 会将匹配到的内容当作切分符,将切分结果列表返回。maxsplit 指定最多切几刀,默认全切。
import re
re.split(r'\d','one1two2three3four4five',maxsplit=3)
如果是以分组作为切分符,分组内容也将返回,如果只是正则表达式,则返回被分割出来的内容
re.split(r'(\d)','one1two2three3four4five')
re.sub¶
re.sub(pattern, repl, string[, count]) | pattern.sub(repl, string[, count])
从给定字符串中检索匹配 pattern 的内容,替换为 repl 并返回新字符串。
- 当
repl是字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。 - 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count用于指定最多替换次数,不指定时全部替换。
import re
text = 're module is very important for regular expression. # that"s true'
# 删除字符串中的注释
pure_text = re.sub(r'\s?#.*$', '', text)
print(pure_text)
# 替换空格为-
link_text = re.sub(r' ','-', pure_text)
print(link_text)
import re
pattern = re.compile(r'(\s?\w+ \w+\s?)\w+(\s?\w+ \w+\s?)')
text = 'I say what you say'
print(pattern.sub(r'\2 what \1', text))
def to_up(match):
return match.group(1).title() + 'what' + match.group(2).title()
print(pattern.sub(to_up, text))
import re
pattern = re.compile(r'(\s?\w+ \w+\s?)\w+(\s?\w+ \w+\s?)')
text = 'I say what you say'
print(pattern.subn(r'\2 what \1', text))
def to_up(match):
return match.group(1).title() + 'what' + match.group(2).title()
print(pattern.subn(to_up, text))
import re
print(re.escape('^hi.*'))
JSON¶
JSON 全称是 JavaScript 对象标记(JavaScript object notation),是一种轻量级的数据交换格式,强调一下,JSON 是一种数据格式。
数据格式都有其特定的表示形式,对于 JSON 就是 {"name": content },应用中常常表现为字符串,符合 JSON 格式的字符串简称 JSON 字符串。
JSON 作为一种数据交换格式,可以和各种编程语言下某种数据类型或数据结构进行转换,Python 中就是字典。
和 Web 时代流行的另一种数据交换格式 XML 相比,JSON 更易于阅读,更易于解析也更易于网络传输。同时,在不同编程语言的程序间交换数据时,通常也会选择 JSON 格式。比较流行的服务设计规范比如 REST 同样选定 JSON 作为数据交换格式。
Python 里的 JSON¶
Python 将和 JSON 相关的操作封装在模块 json 内
import json
JSON 格式数据传给 Python 时收到的会是一个字符串,通过 loads 方法解析字符串获取 JSON 对象,Python 内的 JSON 对象都被表示为一个字典。而这种由字符串到数据格式的转化有个专业名词——反序列化。
data = '{"name":"Daniel Meng", "age":18, "married":false}'
json_data = json.loads(data)
print(type(json_data), json_data)
这里注意几件事:
- JSON 自有其数据格式规定,比如
{}内的键和字符串必须用双引号而不能用单引号,布尔值用 false、true 表示 - 不同编程语言会用各自设计好的某种数据结构承载 JSON 格式数据,比如 Python 选择用字典。同时,解析后的数据表示与语言相关,比如例子中
"变成单引号,false 变成 False
| JSON 数据类型 | Python 数据类型 |
|---|---|
| object | dict |
| array | list |
| string | str |
| number | int |
| number | float |
| true | True |
| false | False |
| null | None |
JSON 本身只是规定了最小基本数据单元的样子,而传输时的 JSON 数据可以很复杂
data = '[{"a":"aaa", "b":{"c": 111}},{"d":"ddd", "e":{"f": 222}}]'
json_data = json.loads(data)
print(type(json_data), json_data)
有反序列化自然有序列化,即将其他数据类型转换成用于传输的字符串。Python 中通过 json 模块下的 dumps 方法实现该功能
import json
json_data = [
{'name': 'Daniel Meng', 'age': 18, 'married': False},
{'name': 'Joey Meng', 'age': 26, 'married': True}
]
data = json.dumps(json_data)
print(type(data), data)