上一章中我们讲到当下实现高并发的主流方式是 事件循环 + 回调 + I/O 复用,不同系统 I/O 复用会有一些差异,Windows 是 select, Linux 是 epoll。回调因为逻辑割裂通常都会用协程驱动的方式代替,Python 为此提供了 async 和 await 原生协程。
所以还欠缺事件循环模块,对此 Python 提供了 asyncio 模块,这也是 Python 应对异步 I/O 编程提供的一整套解决方案。具体而言 asyncio 完成了以下功能:
- 包含各种特定系统实现的模块化事件循环
- 传输和协议抽象
- 对TCP、UDP、SSL、子进程、延时调用以及其他的具体支持
- 模仿
futures模块但适用于事件循环使用的 Future 类 - 基于
yield from的协议和任务,可以用顺序的方式编写并发代码 - 必须使用一个将产生阻塞 IO 的调用时,有接口可以把这个事件转移到线程池
- 模仿
threading模块中的同步原语、可以用在单线程内的协程之间
基于 asyncio 开发的框架有很多,比如 tornado,gevent,twisted 等。tornado 自身实现了 web 服务功能,一般和 django + flask + nginx 搭配的比较多
asyncio 的使用也是很便利的,不妨看个例子
import nest_asyncio # jupyter notebook 本身也运行着一个事件循环,不能嵌套。要用 nest_asyncio
nest_asyncio.apply()
import asyncio
import time
async def get_html(url):
print('start getting url')
await asyncio.sleep(2)
print('task completed')
def main():
start_time = time.time()
loop = asyncio.get_event_loop() # 获取事件循环
loop.run_until_complete(get_html('http://www.google.com'))
print(time.time() - start_time)
main()
这里首先用 async 标明协程处理程序,对阻塞操作用 await 标明保证异步执行后续代码。调用函数内 get_event_loop 方法获取事件循环,会持续监听套接字请求,run_until_complete会陷入阻塞,当任务完成恢复执行。
要注意 time.sleep() 是同步方法,直到调用完成前都会陷入阻塞状态,无法实现单线程内的并发。要使用 asyncio.sleep,这是异步的。可以简单验证二者区别,这里要用到 asyncio.wait() 方法,其本身是一个协程,接收可迭代对象做参数,类似于多线程中的 wait,可以指定 ALL_COMPLETED,FIRST_COMPLETED,FIRST_EXCEPTION 三种返回时机,默认为全部任务完成才返回。
import asyncio
import time
async def num_io(num_id):
print('start processing {}'.format(num_id))
await asyncio.sleep(2)
print('task {} completed'.format(num_id))
async def num_io_time(num_id):
print('start processing {}'.format(num_id))
time.sleep(2)
print('task {} completed'.format(num_id))
def main():
loop = asyncio.get_event_loop()
start_time = time.time()
tasks = [num_io(i) for i in range(5)]
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start_time)
print('----------------------------------')
start_time = time.time()
tasks = [num_io_time(i) for i in range(5)]
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start_time)
main()
可以看到使用 time.sleep 使程序退化为同步阻塞形式,没有实现异步并发
除了 asyncio.wait(),Python 提供了更高层的抽象等待方法 asyncio.gather(),能够分组执行任务,分组取消任务,批量传入时注意要解包
import asyncio
async def num_io(num_id):
print('start processing {}'.format(num_id))
await asyncio.sleep(2)
print('task {} completed'.format(num_id))
async def str_io(str_id):
print('start processing {}'.format(str_id))
await asyncio.sleep(2)
print('{} is OK'.format(str_id))
def main():
loop = asyncio.get_event_loop()
task_1 = [num_io(i) for i in range(3)]
task_2 = [str_io('str_'+str(i)) for i in range(3)]
loop.run_until_complete(asyncio.gather(*task_1, *task_2)) # 注意解包
print('--------------------')
task_1 = [num_io(i) for i in range(3,6)]
task_2 = [str_io('str_'+str(i)) for i in range(3,6)]
task_1 = asyncio.gather(*task_1) # 先建局部再统一传入也都可以
task_2 = asyncio.gather(*task_2)
task_1.cancel() # 取消一组任务
loop.run_until_complete(asyncio.gather(task_2)) # 不需要再解包了,如果再传入 task_1 会报 CancelledError
main()
获取返回值¶
驱动协程完成任务少不了接收返回值,有两种方法可选 asyncio.ensure_future(),类似多线程,返回一个 Future 对象,event_loop_obj.create_task(),返回 task 对象,Future、task 使用方法相同都能调用其中的 .result() 获取协程返回值。
Task 是 Future 的子类,主要是将协程包装进 future 当中。因为生成器实现协程必须在一开始执行一次 send(None),同时任务结束后要处理 StopIteration 异常并存储返回值,这些工作线程返回对象 future 无法实现,于是进一步封装出了 Task
task 对象可以通过 add_done_callback() 指定回调方法,协程任务完成后执行
import asyncio
async def num_io(num_id):
print('start processing {}'.format(num_id))
await asyncio.sleep(2)
print('task {} completed'.format(num_id))
return 'Coroutine Finished'
def call_back(future):
print('success calling call_back method')
def main():
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(num_io(1))
loop.run_until_complete(future)
print('future:{}'.format(future.result()))
print('--------------------')
task = loop.create_task(num_io(2))
task.add_done_callback(call_back)
loop.run_until_complete(task)
print('task:{}'.format(task.result()))
main()
回调方法可能需要传入参数,这时可以使用 funcitontools.partial(func,args) 将调用函数与所需参数进行封装,组装成新方法作回调用
import asyncio
from functools import partial
async def num_io(num_id):
print('start processing {}'.format(num_id))
await asyncio.sleep(2)
print('task {} completed'.format(num_id))
return 'Coroutine Finished'
def call_back(args, future): # 参数在前,future 在后
print('call_back method get args:{}'.format(args))
def main():
loop = asyncio.get_event_loop()
task = loop.create_task(num_io(1))
task.add_done_callback(partial(call_back,'Hello World'))
loop.run_until_complete(task)
print('task:{}'.format(task.result()))
main()
取消任务¶
生产环境中经常面临因某些原因要中断任务执行。这里涉及到两点,一是断开所有任务,二是停止事件循环。一般启动事件循环时会使用 loop.run_forever() 方法一直循环下去,而 loop.run_until_complete() 则是在此基础上通过回调,在任务完成后从 future 对象内获取 loop 对象调用 stop() 方法将循环关闭
下面以 CTRL + C 中断为例
import asyncio
'''stop_loop.py
终端运行,jupyter 自身有 loop 不能 close()
'''
async def nip(times):
print('go to bed')
await asyncio.sleep(times)
print('get up after {}s'.format(times))
def main():
loop = asyncio.get_event_loop()
tasks = [nip(times) for times in range(1,5)]
try:
loop.run_until_complete(asyncio.wait(tasks))
except KeyboardInterrupt:
all_tasks = asyncio.Task.all_tasks()
for task in all_tasks:
print('task cancel:{}'.format(task.cancel()))
loop.stop()
loop.run_forever()
finally:
loop.close()
main()
这里定义了 4 个睡眠任务异步执行,终端传入中断指令后捕获 KeyboardInterrupt 异常。asyncio 模块下专门有 Task 类管理任务,其 all_tasks() 方法会找到 loop 对象(如果没有就新建),返回循环列表中的所有任务。之后遍历任务列表,调用 cancel() 方法取消任务,之后停止循环。
注意 loop.stop() 方法只是改变事件循环内部停止标识,标识后循环任务销毁但 loop 仍处于就绪态,所以要调用 run_forever() 方法使其恢复正常,最后执行 loop.close() 关闭循环,close 会清空就绪、计划队列,然后结束进程。
协程嵌套¶
之前通过生成其展示过调用者和子生成器间建立双通“管道”的过程。这里还是举例说明 asyncio 模块下的协程嵌套
import asyncio
async def compute(x, y):
print("Compute %s + %s ..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
时序图如下
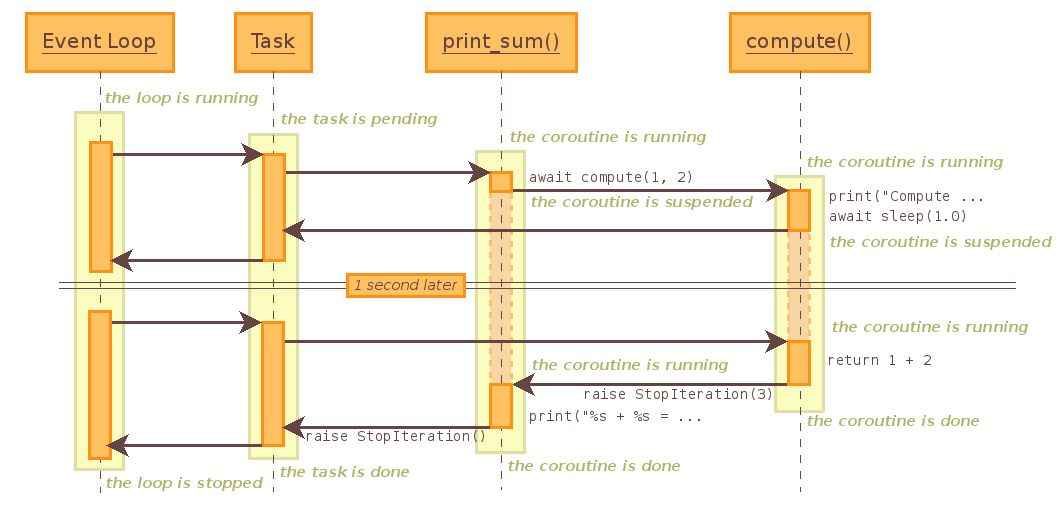
事件循环启动后,指定监听任务 print_sum,print_sum开始执行,调用协程 compute 完成求和计算,而compute 内部又调用 sleep,陷入阻塞,注意这里没有经过“委托人”print_sum,直接送回调用者。恢复执行后,调用者直接向子协程收取结果,返回 1+2 后 compute 调用完毕,print_sum 收到停止信号,打印输出后 print_sum 协程任务也已执行完毕,继续上报。整个任务执行完毕,loop.close() 关闭事件循环
call 系列方法¶
asyncio 允许定制任务在事件循环中执行的时机,对应于
call_soon(call_back_func, *args): 下次循环立刻执行call_at(loop_times, call_back_func, *args): 事件循环中的某个时刻执行call_later(delay_times, call_back_func, *args): 几秒钟后执行,自动按时间升序执行call_soon_threadsafe: 效果同call_soon且保证线程安全
import asyncio
def call_back(times):
print('I want to sleep {}s'.format(times))
def stop_loop(loop):
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(call_back, 2)
loop.call_soon(stop_loop,loop) # call_back 的下一次循环停止 loop 循环
loop.run_forever()
import asyncio
def call_back(times):
print('{}s has gone'.format(times))
def stop_loop(loop):
loop.stop()
loop = asyncio.get_event_loop()
loop.call_later(3, call_back, 3) # 会自动按时间重排
loop.call_later(1, call_back, 1)
loop.call_later(2, call_back, 2)
loop.call_later(4, stop_loop,loop)
loop.run_forever()
import asyncio
def call_back(times):
print('another {}s has gone'.format(times))
def stop_loop(loop):
loop.stop()
loop = asyncio.get_event_loop()
now = loop.time() # 注意是循环内的时间
loop.call_at(now + 3, call_back, 3) # 会自动按时间重排
loop.call_at(now + 1, call_back, 1)
loop.call_at(now + 2, call_back, 2)
loop.call_at(now + 4, stop_loop,loop)
loop.run_forever()
asyncio 与多线程¶
I/O 复用下有时依旧不能避免阻塞 I/O 操作,比如数据库读写。asyncio 作为一整套异步解决方案,提供了线程池的接口run_in_executor(executor, func, *args),对于必须处理的同步操作可以放到线程池里交给其他线程处理
import asyncio
import socket
import time
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urlparse
def get_url(url):
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
# IPv4,TCP 连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 80)) #阻塞不会消耗cpu
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
data = b""
while True:
d = client.recv(1024)
if d:
data += d
else:
break
data = data.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
client.close()
start_time = time.time()
loop = asyncio.get_event_loop()
executor = ThreadPoolExecutor(3)
tasks = []
for url in range(20):
url = "http://shop.projectsedu.com/goods/{}/".format(url)
task = loop.run_in_executor(executor, get_url, url)
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print("last time:{}".format(time.time()-start_time))
asyncio 模拟 http¶
我们曾通过 selectors 借助函数回调模拟 http 协议执行过程,有了 asyncio 后借助协程可以更加简便的实现这一目的
import asyncio
import socket
import time
from urllib.parse import urlparse
async def get_url(url):
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
reader, writer = await asyncio.open_connection(host,80)
writer.write("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
all_lines = []
async for raw_line in reader:
data = raw_line.decode("utf8")
all_lines.append(data)
html = "\n".join(all_lines)
return html
async def main():
tasks = []
for url in range(3):
url = "http://shop.projectsedu.com/goods/{}/".format(url)
tasks.append(asyncio.ensure_future(get_url(url)))
for task in asyncio.as_completed(tasks):
result = await task
print(result)
start_time = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
print('last time:{}'.format(time.time()-start_time))
首先,asyncio 提供了协程 open_connection(),不再需要手动通过 socket.socket 指定协议请求连接了,免去阻塞困扰的同时协程会返回处理读写请求的两个对象。async for 能将 for 循环接收读取内容的工作异步化,防止有同步操作阻塞执行,影响效率。
为了达到完成一个任务处理一个任务的效果,asyncio 也提供了 as_completed() 方法,但要注意因为任务都是异步的,要加上 await 等待任务结果。
asyncio 同步与通信¶
介绍 GIL 时我们举例说明 GIL 会因 I/O 操作、时间片耗尽和字节码情况主动释放,导致变量值震荡。但 asyncio 虽是异步,却能保证在非 I/O 阻塞场景下变量值的稳定
var_a = 0
async def add():
global var_a
for i in range(1000000):
var_a += 1
async def subtract():
global var_a
for i in range(1000000):
var_a -= 1
import asyncio
loop = asyncio.get_event_loop()
tasks = [add(), subtract()]
loop.run_until_complete(asyncio.wait(tasks))
print(var_a)
其中原因是,异步并发是单线程的,除非涉及到阻塞 I/O 操作会调用协程转到其他方法,其余计算任务都会全部执行完(至函数体结束)才转到其他方法
但异步场景下有时也会面临同步困扰,比如两个异步程序同时调用了一个协程,为了数据安全、鲁棒需要锁机制。但异步程序杜绝使用阻塞方法,比如 Python 的 lock,于是 asyncio 提供了代码级的锁 asyncio.Lock,不调用 Python 原生的锁,只是创立一个标识,访问前检测标识状态,以此保证冲突资源的线性访问。
基于同样的道理 asyncio 还提供了异步的双端队列 asyncio.Queue,get 和 put 方法使用前也要加上 await
import asyncio
from asyncio import Lock # 注意是 asyncio 下的锁
cache = {}
lock = Lock()
async def parse_url(url):
await asyncio.sleep(2)
return 'decorate {' + str(url) + '}'
async def get_stuff(url):
async with lock.acquire():
if url in cache:
return cache[url]
stuff = await parse_url(url)
return stuff
async def use_stuff(url):
stuff = await get_stuff(url)
# do something
pass
async def parse_stuff(url):
stuff = await get_stuff(url)
# do something
pass
伪代码展示的是当 use_stuff 和 parse_stuff 都被添加到事件循环中时,可能存在的访问冲突,二者都尝试访问 get_stuff 获取对象,这里使用 lock.acquire() 对获取过程加锁保证顺序性。
注意这里的 acquire 也是一个协程,同时实现了上下文管理器协议 __exit__ 和 __enter__,所以可以使用 with await 方式,而 asyncio 为了保证语义清晰,提供了 __await__,__aenter__ 协议应对这种情况,于是有了 asyncio with 语法。