迭代对象与迭代器¶
一般遍历数据都会采用 for 循环的方式,但其核心在于“迭代”。能被遍历访问的对象称之为可迭代对象,由底层协议__iter__支持,内置类型 list, tuple 等都实现了该协议,Python 文档中参数形式声明为 iterable 就是指所传参数必须实现了 __iter__
在此基础上再加上 __next__ 协议,就构成了迭代器,迭代器是和 __getitem__ 协议所代表的随机访问相对的另一种集合元素访问方式,多用于一个接一个的遍历数据。此外,迭代器提供了一种惰性数据访问方式,只有当实际调用发生时才去访问、计算数据,否则只是一个声明占位
Python 的 collections.abc 模块提供了可迭代对象 Iterable 和迭代器 Iterator 两个接口
from collections.abc import Iterable, Iterator
help(Iterable)
help(Iterator)
迭代器是软件工程设计模式中的一种,强调迭代对象和迭代器分离,对象只实现 __iter__,迭代器里实现 __next__。__iter__ 要返回一个迭代器,可以自定义,也可以使用全局方法 iter(obj),其会先在对象内部寻找__iter__实现,没有则尝试调用 obj 的 __getitem__
class UserList:
def __init__(self, lst_id, form):
self.id = lst_id
self.form = form
def __iter__(self):
return UserListIterator(self.form)
class UserListIterator:
def __init__(self, iter_obj):
self.index = 0
self.val = iter_obj
def __next__(self):
try:
word = self.val[self.index]
except IndexError:
raise StopIteration
self.index += 1
return word
使用迭代器实际就是不断通过全局方法 next() 调用 __next__ 直到收到 StopIteration 异常,这也是上面我们进行异常转换的原因
usr_lst = UserList(1, ['Daniel', 'Tom', 'Li Lei'])
usr_itor = iter(usr_lst)
while True:
try:
print(next(usr_itor))
except StopIteration:
break
上述迭代器使用过程就是 for 循环做的事情
usr_lst = UserList(1, ['Daniel', 'Tom', 'Li Lei'])
for item in usr_lst:
print(item)
生成器¶
只要函数体内部出现了 yeild 关键字,函数就成为了生成器,每次 yeild 会返回一个生成器对象。
def gen_func():
yield 1
def func():
return 1
print(gen_func(), func())
yeild 只是返回生成器对象,不妨碍后续代码执行,函数体内可以有多个 yeild。同时生成器也实现了迭代器协议,可以遍历访问
def gen_func():
yield 1
yield 2
print('Without being interrupted')
for gen in gen_func():
print(gen)
既然可迭代,为什么要多此一举多写个生成器呢?是为了惰性求值,有时处理数据量过大,或计算过程中冗余数据过多,一次性处理硬件设备支撑不了。惰性计算的计算是延迟的,只有实际调用发生时才计算数据,这样我们就能分批适时完成计算任务,节约硬件资源
以求解斐波那契数为例
def lst_feibo(n):
lst = [0, 1]
if n < 3:
return lst[n]
idx, a, b = 2, 0, 1
while idx < n:
a, b = b, a+b
lst.append(b)
idx += 1
print(lst)
lst_feibo(10)
这里使用了列表做临时存储,如果所求 n 很大,内存会溢出。用生成器的做法会是
def gen_feibo(n):
if n == 0: return 0
if n == 1: return 1
idx, a, b = 2, 0, 1
yield 0
yield 1
while idx < n:
a, b = b, a+b
yield b
idx += 1
for gen in gen_feibo(10):
print(gen, end=' ')
这里我们可以自由决定什么时候向外传递计算值,也只有真实执行计算时才有输出。更重要的是,这种自由控制函数的能力使得跨程序协作成为可能,比如gen_feibo可以改为两个程序执行并保证结果不变,靠 list 的单程序就不容易做到这一点
但生成器是怎么做到的呢?这里牵涉到一些底层机制了。举例来讲,
def foo():
doo()
def doo():
a=1
pass
foo 调用了 doo,运行时 Python 解释器会调用底层的 C 函数 PyEval_EvalFrameEx 执行 foo,创建一个栈帧(stack frame)作 foo 的上下文,而 Python 中一切皆对象,栈帧同样是对象,函数体内部的代码经编译转换成字节码对象,可以通过 dis 模块查看
import dis
dis.dis(foo)
字节码对象全局唯一,运行在栈帧确立的上下文环境当中。当执行到 doo 调用部分时,又会创建一个新栈帧来执行 boo 的字节码。重点在于所有的栈帧都存放在堆上,而不同于 C++,JAVA 存放在栈内,执行完毕后并不会被自动销毁,也就是说 Python 里的栈帧是独立于调用者存在的
可以通过 inspect 模块,查验 frame 生存周期
import inspect
frame = None
def foo():
doo()
def doo():
global frame
frame = inspect.currentframe()
foo()
运行 foo 以后栈帧被存放在了全局变量 frame 内,可以看下其内结构
dir(frame)
frame.f_code.co_name # 执行栈帧名
frame.f_back.f_code.co_name # 调用者栈帧名
可以看到这实际就是一个递归过程(学习过操作系统原理的话更易理解),可以用下面这张图表示
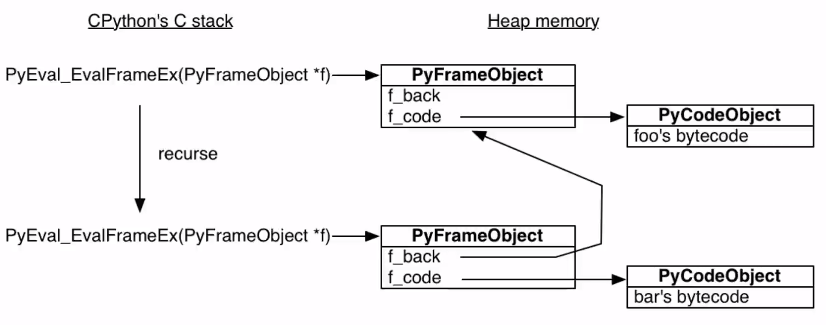
调用函数存于函数栈内,但字节码存于堆上,正因如此生成器有了实现的可能。可以看下生成器的字节码
import dis
def gen_demo():
yield 1
name = 'Daniel'
yield 2
age = 18
return 'Done'
dis.dis(gen_demo)
可以看到代码运行到 yeild 时转到了 YIELD_VALUE 执行随后出栈。yeild 创立生成器对象,实际是对一般的 frame 和字节码进行了封装
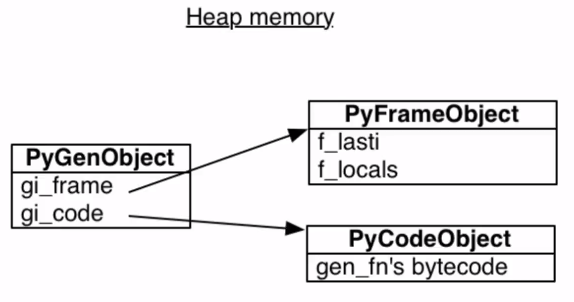
f_lasti 指明上一条运行指令,f_locals 则是调用者 frame 保存的局部变量
gen = gen_demo()
print(gen.gi_frame.f_lasti, gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti, gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti, gen.gi_frame.f_locals)
对照字节码不难发现,开始时 f_lasti 为空因为一条指令都没执行,但开始执行后 f_lasti 标记着最近一次指令调用位置,f_locals 记录着当时的现场信息
正因为有指令,有环境,且生成器对象同位于堆内存不会主动释放,只要能拿到栈帧对象,任何地点,任何时间我们都能恢复现场,这也正是实现协程的根源
生成器在 Python 内部都多处应用,比如 collections.UserList,其用 Python 向我们展示了 list 内部机制(list 本身是用 C 实现的,不允许自由覆盖方法),比如 for 遍历的场景下就用到了生成器
def SimulateUserList:
def __getitem__(self, index):
raise IndexError
def __iter__(self):
i = 0
try:
while True:
v = self[i]
yield v
i += 1
except IndexError:
return
应用生成器也可以实现一个读取超大文件的自定义 read 方法,允许自定义分隔符
def read_lines(file, spliter):
buf = "" # 缓存对象
while True:
while spliter in buf: # 读取内容中可能存在不止一个分隔符
pos = buf.index(spliter)
yield buf[:pos]
buf = buf[pos + len(spliter):]
chunk = file.read( 4096 * 10) # 每次读取 4096 × 10 个字节的内容
if not chunk: # 读取到文件末尾
yield buf
break
buf += chunk