执行上面的代码后,可以在同目录下的 apply/data/demo data 文件夹中看到相同结构内容

压缩文件能帮助我们节省空间和时间。ZIP 是种存档文件,支持无损数据压缩。用 Python 打开 ZIP 文件夹先得有 Zip File 库。
本文所有文件都已打包进独立 ZIP 文件中,来提取看看吧。
from zipfile import ZipFile
# 压缩文件路径
file = './data/demo data.zip'
# 读取并解压内容
with ZipFile (file, 'r') as zip:
zip.printdir()
zip.extractall(path='./data/demo data')
File Name Modified Size Beijing/ 2021-01-09 21:55:24 0 Beijing/1.jpg 2021-01-09 22:00:28 14363 Beijing/2.jpg 2021-01-09 22:00:28 10942 Beijing/3.jpg 2021-01-09 22:00:28 5100 Beijing/4.jpg 2021-01-09 22:00:28 4142 Beijing/5.jpg 2021-01-09 22:00:28 6914 Beijing/6.jpg 2021-01-09 22:00:28 4493 Beijing/7.jpg 2021-01-09 22:00:28 4518 Beijing/8.jpg 2021-01-09 22:00:28 12041 Employee.txt 2021-01-09 22:00:28 85 Liberty Dream.txt 2021-01-09 22:00:28 163 Products.csv 2021-01-09 22:00:28 79 sample_db.sql 2021-01-09 22:00:28 4299 sample_json.json 2021-01-09 22:01:12 120 sample_pickle.pkl 2021-01-09 22:00:28 0 test1.py 2021-01-09 22:00:28 17 test_demo_1.py 2021-01-09 22:00:28 23 test_demo_2.py 2021-01-09 22:00:28 23 test_img1.png 2021-01-09 22:00:28 255274 World_city.xlsx 2021-01-09 22:00:28 11582
执行上面的代码后,可以在同目录下的 apply/data/demo data 文件夹中看到相同结构内容
文本文件算是最常见的文件格式了。Python 用 open() 方法读取指定路径的文件,并用参数指定访问方式。读文件模式为 r,还有其他访问模式:
w —— 写入文件r+ 或 w+ —— 读取并写入文件a —— 追加到既有文本后面a+ —— 读取后再追加Python 提供了三种方法读取文本文件:
read(n) – 从文本中读取 n 个字符,不指定数字就读取全部。可以自动识别定界符并分隔句子。readline(n) – 从文件中读取 n 个字符,但不超过一行readlines() – 读取全部信息,但不同于 read(),该方法不会管分隔符,将其一并读入列表来看看这些方法读文件时的异同吧:
# 读取 text 文件,指定解码格式为 utf-8
with open(r'./data/demo data/Liberty Dream.txt','r',encoding='utf-8') as f:
print(f.read())
欢迎来到 Python 文件导入教程。我们会关注以下文件类型的处理: 1. Text 2. CSV 3. Excel 4. SQL 5. Web 数据 6. Image 阅读愉快!
read() 方法成功以结构化的方式读入了所有数据。
# 读取 text 文件,读取 n 个字节
with open(r'./data/demo data/Liberty Dream.txt','r',encoding='utf-8') as f:
print(f.read(4))
欢迎来到
给 read() 指定一个数后,可以读取定量的字符
# 按行读取 text 文件
with open(r'./data/demo data/Liberty Dream.txt','r',encoding='utf-8') as f:
print(f.readline())
欢迎来到 Python 文件导入教程。我们会关注以下文件类型的处理:
用了 readline(),只读了一行文本进来
# 将 text 文件解析成列表
with open(r'./data/demo data/Liberty Dream.txt','r',encoding='utf-8') as f:
print(f.readlines())
['欢迎来到 Python 文件导入教程。我们会关注以下文件类型的处理:\n', '1. Text\n', '2. CSV\n', '3. Excel\n', '4. SQL\n', '5. Web 数据\n', '6. Image\n', '阅读愉快!']
这里 readlines() 方法将整个文本提取成了列表格式。
import pandas as pd
# 读取文件为 DataFrame
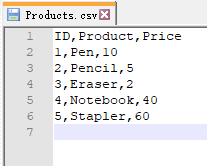
df = pd.read_csv(r'./data/demo data/Products.csv')
df
| ID | Product | Price | |
|---|---|---|---|
| 0 | 1 | Pen | 10 |
| 1 | 2 | Pencil | 5 |
| 2 | 3 | Eraser | 2 |
| 3 | 4 | Notebook | 40 |
| 4 | 5 | Stapler | 60 |
但数据值里包括逗号的话 CSV 文件就会遇到问题。这可以靠采用不同分隔符解决,比如 \t 或 ; 等:
import pandas as pd
df = pd.read_csv(r'./data/demo data/Employee.txt',delimiter='\t')
df
| ID,Name,Job | |
|---|---|
| 0 | 1,Tom,Full Stack |
| 1 | 2,Jerry,Frontend |
| 2 | 3,Merry,Backend |
| 3 | 4,Jack,Data Science |
想必你对 Excel 文件不会陌生,谈到表格类数据必定少不了它。Pandas 提供了一个很方便的方法 read_excel() 读取 Excel 文件:
import pandas as pd
df = pd.read_excel(r'./data/demo data/World_city.xlsx')
df
| ID | City | Country | |
|---|---|---|---|
| 0 | 1 | Beijing | China |
| 1 | 2 | Tokyo | Japan |
| 2 | 3 | New Delhi | India |
| 3 | 4 | Seoul | South Koera |
但 Excel 文件通常有多个表单,此时可以用 Pandas 的 ExcelFile() 方法打印文件内所有表单名称:
# pandas 读取 Excel sheets
xls = pd.ExcelFile(r'./data/demo data/World_city.xlsx')
xls.sheet_names
['Asia', 'Europe', 'Africa']
这样我们就可以通过参数 sheet_name 借助 read_excel() 方法读取任意表单内的数据了:
# 读取欧洲表单
df = pd.read_excel(r'./data/demo data/World_city.xlsx', sheet_name='Europe')
df
| ID | City | Country | |
|---|---|---|---|
| 0 | 1 | London | Britain |
| 1 | 2 | Pairs | France |
| 2 | 3 | Berlin | Germany |
| 3 | 4 | Moscow | Russia |
实际项目中,免不了从项目数据库中提取数据(所以 SQL 还是得学滴)。数据在数据库中是以表格形式存储的,(一般)这些系统又名关系数据库管理系统(RDBMS),访问不同数据库需要不同的 PYthon 模块支持,比如 SQLite 需要 sqlite3,MySQL 需要 mysql-connector。
一般的数据访问步骤为:
connect() 创建一个数据库连接,需要传入要访问的数据库名。它会返回一个 Connection 对象cursor() 创建一个 cursor 对象,通过它实现操作数据的 SQL 指令execute() 方法执行 SQL 命令。检索数据会用到 SELECT 语句,并将查询存入一个对象fetchone() 读入一行,或是 fetchcall() 读取所有行一个好习惯是,即使只是读取数据,也用 commit() 方法将你的事务保存/提交。
from getpass import getpass
from mysql.connector import connect, Error
# 连接数据库
try:
db=connect(
host="localhost",
user=input("Enter username: "),
passwd=getpass("Enter password: "),
database="nba",
auth_plugin='mysql_native_password'
)
except Error as e:
print(e)
# 获取游标
cursor = db.cursor()
# 执行查询操作
cursor.execute("SELECT * FROM player LIMIT 10")
df = pd.DataFrame(cursor.fetchall())
db.commit()
df
Enter username: root Enter password: ········
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 10001 | 1001 | 韦恩-艾灵顿 | 1.93 |
| 1 | 10002 | 1001 | 雷吉-杰克逊 | 1.91 |
| 2 | 10003 | 1001 | 安德烈-德拉蒙德 | 2.11 |
| 3 | 10004 | 1001 | 索恩-马克 | 2.16 |
| 4 | 10005 | 1001 | 布鲁斯-布朗 | 1.96 |
| 5 | 10006 | 1001 | 兰斯顿-加洛韦 | 1.88 |
| 6 | 10007 | 1001 | 格伦-罗宾逊三世 | 1.98 |
| 7 | 10008 | 1001 | 伊斯梅尔-史密斯 | 1.83 |
| 8 | 10009 | 1001 | 扎扎-帕楚里亚 | 2.11 |
| 9 | 10010 | 1001 | 乔恩-洛伊尔 | 2.08 |
team_id = int(input("team id: "))
height = float(input("height: "))
select_query ="""
SELECT player_id,player_name FROM player
WHERE team_id=%d AND height > %f;
""" % (team_id, height)
cursor.execute(select_query)
df = pd.DataFrame(cursor.fetchall())
db.commit()
df
team id: 1001 height: 1.96
| 0 | 1 | |
|---|---|---|
| 0 | 10003 | 安德烈-德拉蒙德 |
| 1 | 10004 | 索恩-马克 |
| 2 | 10007 | 格伦-罗宾逊三世 |
| 3 | 10009 | 扎扎-帕楚里亚 |
| 4 | 10010 | 乔恩-洛伊尔 |
| 5 | 10011 | 布雷克-格里芬 |
| 6 | 10012 | 雷吉-巴洛克 |
| 7 | 10014 | 斯坦利-约翰逊 |
| 8 | 10015 | 亨利-埃伦森 |
| 9 | 10018 | 斯维亚托斯拉夫-米凯卢克 |
# 关闭数据库
cursor.close()
db.close()
JSON (JavaScript Object Notation) 是用于数据存储、交换的轻量可读文件格式。机器很容易解析、生成这些文件。
JSON 中的数据用类似 Python 字典的方式存在 {} 中,JSON 是语言独立的,一般文件长这样:
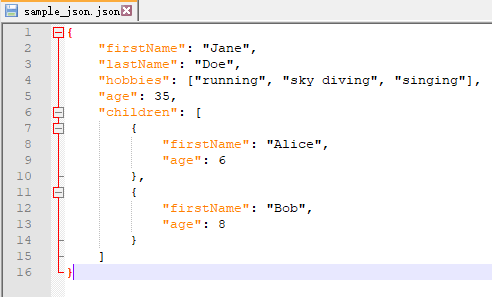
Python 提供了 json 模块来读取 JSON 文件,像读文本一样简单。只不过这里的读方法变成了 json.load(),其返回一个 JSON 字典。
接着就可以用 pandas.DataFrame() 方法将其转换成 Pandas dataframe 格式了。
import json
with open(r'./data/demo data/sample_json.json','r') as file:
data = json.load(file)
print(type(data))
df_json = pd.DataFrame(data)
df_json
<class 'dict'>
| firstName | lastName | age | |
|---|---|---|---|
| 0 | Jane | Doe | 35 |
| 1 | Teddy | Dunken | 40 |
你甚至可以用 pandas.read_json() 直接将 JSON 文件读入 dataframe:
path = r'./data/demo data/sample_json.json'
df = pd.read_json(path)
df
| firstName | lastName | age | |
|---|---|---|---|
| 0 | Jane | Doe | 35 |
| 1 | Teddy | Dunken | 40 |
Pickle 文件常用于存储 Python 序列化对象,也就是说像 list,set,tuple,dict 这些在存入磁盘前先被转换成了字符流。这可以让你之后继续使用对象,当训练完模型想存起来之后预测用时,这就能派上用场了。
所以,如果存储前将文件序列化了,用之前就得先反序列化,这可以通过 pickle 模块的 pickle.load() 方法实现。在用 open() 打开 pickle 文件时候记得得用 rb 做参数,相应的,写入时记得用 wb。
import pickle
import pandas as pd
pickle_data = {'Name':['Tom','Jerry'],'Company':['Apple','Google'],
'Job':['Intern','Full time']}
with open(r'./data/demo data/sample_pickle.pkl','wb') as fw:
pickle.dump(pickle_data, fw)
with open(r'./data/demo data/sample_pickle.pkl','rb') as fo:
read_data = pickle.load(fo)
print(type(read_data))
df = pd.DataFrame(read_data)
df
<class 'dict'>
| Name | Company | Job | |
|---|---|---|---|
| 0 | Tom | Apple | Intern |
| 1 | Jerry | Full time |
网络爬虫就是从网络上抓取海量数据,这对要分析数据的数据科学家来讲很重要。
Python 提供了 requests 模块方便我们从网络获取数据。requests.get() 方法接收一个 URL 参数并返回相应的 HTML 结果。其工作流程可以概括为:
比如想了解北京市,从维基百科抓获的数据形式如下
import requests
web_resp = requests.get('https://zh.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82')
# response 对象 text 属性,将网页 HTML 作为字符串返回
print(web_resp.text)
<!DOCTYPE html>
<html class="client-nojs" lang="zh" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>北京市 - 维基百科,自由的百科全书</title>
<script>document.documentElement.className="client-js";RLCONF={"wgBreakFrames":!1,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"zh","wgMonthNames":["","1月","2月","3月","4月","5月","6月","7月","8月","9月","10月","11月","12月"],"wgRequestId":"X-ld-wpAAL8AAvn2aXcAAACI","wgCSPNonce":!1,"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":!1,"wgNamespaceNumber":0,"wgPageName":"北京市","wgTitle":"北京市","wgCurRevisionId":63604485,"wgRevisionId":63604485,"wgArticleId":463,"wgIsArticle":!0,"wgIsRedirect":!1,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["有参考文献错误的页面","CS1英语来源 (en)","CS1含有中文文本 (zh)","引文格式1错误:日期","含有访问日期但无网址的引用的页面","CS1俄语来源 (ru)","CS1美国英语来源 (en-us)","顶注重定向需要审阅的条目","维基数据存在坐标数据的页面","使用多个图像且自动缩放的页面",
"含有非中文內容的條目","嵌入hAudio微格式的條目","包含AAT标识符的维基百科条目","包含BNF标识符的维基百科条目","包含GND标识符的维基百科条目","包含ISNI标识符的维基百科条目","包含LCCN标识符的维基百科条目","包含NARA标识符的维基百科条目","包含NDL标识符的维基百科条目","包含NKC标识符的维基百科条目","包含NNL标识符的维基百科条目","包含VIAF标识符的维基百科条目","使用人口模板的頁面","中華人民共和國省級行政區","亞洲首都","国家园林城市","中華人民共和國直轄市","北京市","中国特大城市","国家历史文化名城","京津冀城市群","夏季奥林匹克运动会主办城市","亚洲运动会主办城市","中国历代国都","国家中心城市","国家经济中心城市"],"wgPageContentLanguage":"zh","wgPageContentModel":"wikitext","wgRelevantPageName":"北京市","wgRelevantArticleId":463,"wgUserVariant":"zh",
"wgIsProbablyEditable":!0,"wgRelevantPageIsProbablyEditable":!0,"wgRestrictionEdit":[],"wgRestrictionMove":[],"wgMediaViewerOnClick":!0,"wgMediaViewerEnabledByDefault":!0,"wgPopupsReferencePreviews":!1,"wgPopupsConflictsWithNavPopupGadget":!1,"wgPopupsConflictsWithRefTooltipsGadget":!0,"wgVisualEditor":{"pageLanguageCode":"zh","pageLanguageDir":"ltr","pageVariantFallbacks":["zh-hans","zh-hant","zh-cn","zh-tw","zh-hk","zh-sg","zh-mo","zh-my"]},"wgMFDisplayWikibaseDescriptions":{"search":!0,"nearby":!0,"watchlist":!0,"tagline":!0},"wgWMESchemaEditAttemptStepOversample":!1,"wgULSCurrentAutonym":"中文","wgNoticeProject":"wikipedia","wgCoordinates":{"lat":39.90555555555555,"lon":116.3913888888889},"wgCentralAuthMobileDomain":!1,"wgEditSubmitButtonLabelPublish":!0,"wgULSPosition":"interlanguage","wgWikibaseItemId":"Q956"};RLSTATE={"ext.gadget.large-font":"ready","ext.globalCssJs.user.styles":"ready","site.styles":"ready","noscript":"ready","user.styles":
"ready","ext.globalCssJs.user":"ready","user":"ready","user.options":"loading","ext.cite.styles":"ready","skins.vector.styles.legacy":"ready","jquery.tablesorter.styles":"ready","ext.visualEditor.desktopArticleTarget.noscript":"ready","ext.uls.interlanguage":"ready","ext.wikimediaBadges":"ready","wikibase.client.init":"ready"};RLPAGEMODULES=["ext.cite.ux-enhancements","site","mediawiki.page.ready","jquery.tablesorter","mediawiki.toc","skins.vector.legacy.js","ext.gadget.edit0","ext.gadget.Edittools-refToolbar","ext.gadget.WikiMiniAtlas","ext.gadget.ReferenceTooltips","ext.gadget.UnihanTooltips","ext.gadget.variant-link-fix","ext.gadget.FixedTopBottomLink","ext.gadget.confirm-logout","ext.gadget.shortURL","ext.gadget.Difflink","ext.gadget.AdvancedSiteNotices","ext.gadget.hideConversionTab","ext.gadget.internalLinkHelper-altcolor","ext.gadget.noteTA","ext.gadget.noteTAvector","ext.gadget.NavFrame","ext.gadget.collapsibleTables","ext.gadget.notifyConversion",
"ext.centralauth.centralautologin","mmv.head","mmv.bootstrap.autostart","ext.popups","ext.visualEditor.desktopArticleTarget.init","ext.visualEditor.targetLoader","ext.eventLogging","ext.wikimediaEvents","ext.navigationTiming","ext.uls.compactlinks","ext.uls.interface","ext.cx.eventlogging.campaigns","ext.centralNotice.geoIP","ext.centralNotice.startUp"];</script>
<script>(RLQ=window.RLQ||[]).push(function(){mw.loader.implement("user.options@1hzgi",function($,jQuery,require,module){/*@nomin*/mw.user.tokens.set({"patrolToken":"+\\","watchToken":"+\\","csrfToken":"+\\"});
});});</script>
<link rel="stylesheet" href="/w/load.php?lang=zh&modules=ext.cite.styles%7Cext.uls.interlanguage%7Cext.visualEditor.desktopArticleTarget.noscript%7Cext.wikimediaBadges%7Cjquery.tablesorter.styles%7Cskins.vector.styles.legacy%7Cwikibase.client.init&only=styles&skin=vector"/>
<script async="" src="/w/load.php?lang=zh&modules=startup&only=scripts&raw=1&skin=vector"></script>
<meta name="ResourceLoaderDynamicStyles" content=""/>
<link rel="stylesheet" href="/w/load.php?lang=zh&modules=ext.gadget.large-font&only=styles&skin=vector"/>
<link rel="stylesheet" href="/w/load.php?lang=zh&modules=site.styles&only=styles&skin=vector"/>
<meta name="generator" content="MediaWiki 1.36.0-wmf.25"/>
<meta name="referrer" content="origin"/>
<meta name="referrer" content="origin-when-crossorigin"/>
<meta name="referrer" content="origin-when-cross-origin"/>
<meta property="og:image" content="https://upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/1200px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg"/>
<link rel="preconnect" href="//upload.wikimedia.org"/>
<link rel="alternate" media="only screen and (max-width: 720px)" href="//zh.m.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" type="application/x-wiki" title="编辑本页" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit"/>
<link rel="edit" title="编辑本页" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit"/>
<link rel="apple-touch-icon" href="/static/apple-touch/wikipedia.png"/>
<link rel="shortcut icon" href="/static/favicon/wikipedia.ico"/>
<link rel="search" type="application/opensearchdescription+xml" href="/w/opensearch_desc.php" title="Wikipedia (zh)"/>
<link rel="EditURI" type="application/rsd+xml" href="//zh.wikipedia.org/w/api.php?action=rsd"/>
<link rel="alternate" hreflang="zh" href="/zh/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hans" href="/zh-hans/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hant" href="/zh-hant/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hans-CN" href="/zh-cn/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hant-HK" href="/zh-hk/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hant-MO" href="/zh-mo/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hans-MY" href="/zh-my/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hans-SG" href="/zh-sg/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="zh-Hant-TW" href="/zh-tw/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="alternate" hreflang="x-default" href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="license" href="//creativecommons.org/licenses/by-sa/3.0/"/>
<link rel="canonical" href="https://zh.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82"/>
<link rel="dns-prefetch" href="//login.wikimedia.org"/>
<link rel="dns-prefetch" href="//meta.wikimedia.org" />
</head>
<body class="mediawiki ltr sitedir-ltr mw-hide-empty-elt ns-0 ns-subject mw-editable page-北京市 rootpage-北京市 skin-vector action-view skin-vector-legacy"><div id="mw-page-base" class="noprint"></div>
<div id="mw-head-base" class="noprint"></div>
<div id="content" class="mw-body" role="main">
<a id="top"></a>
<div id="siteNotice" class="mw-body-content"><!-- CentralNotice --></div>
<div class="mw-indicators mw-body-content">
<div id="mw-indicator-noteTA-d455684c" class="mw-indicator"><img alt="本页使用了标题或全文手工转换" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/Zh_conversion_icon_m.svg/35px-Zh_conversion_icon_m.svg.png" decoding="async" title="本页使用了标题或全文手工转换" width="35" height="22" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/Zh_conversion_icon_m.svg/53px-Zh_conversion_icon_m.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/cd/Zh_conversion_icon_m.svg/70px-Zh_conversion_icon_m.svg.png 2x" data-file-width="32" data-file-height="20" /></div>
</div>
<h1 id="firstHeading" class="firstHeading" lang="zh">北京市</h1>
<div id="bodyContent" class="mw-body-content">
<div id="siteSub" class="noprint">维基百科,自由的百科全书</div>
<div id="contentSub"></div>
<div id="contentSub2"></div>
<div id="jump-to-nav"></div>
<a class="mw-jump-link" href="#mw-head">跳到导航</a>
<a class="mw-jump-link" href="#searchInput">跳到搜索</a>
<div id="mw-content-text" lang="zh" dir="ltr" class="mw-content-ltr"><div class="mw-parser-output"><div id="noteTA-d455684c" class="noteTA"><div class="noteTA-group"><div data-noteta-group-source="module" data-noteta-group="地名"></div></div><div class="noteTA-local"><div data-noteta-code="zh-hans:丰台; zh-hant:豐臺;"></div><div data-noteta-code="zh-hant:衚衕; zh-hans:胡同;"></div><div data-noteta-code="zh-hans:哈瓦那;zh-tw:哈瓦那;zh-hk:夏灣拿;zh-cn:哈瓦那;"></div></div></div>
<div role="note" class="hatnote navigation-not-searchable"><a href="/wiki/Wikipedia:%E6%B6%88%E6%AD%A7%E4%B9%89" title="Wikipedia:消歧义"><img alt="Disambig gray.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5f/Disambig_gray.svg/25px-Disambig_gray.svg.png" decoding="async" width="25" height="19" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5f/Disambig_gray.svg/38px-Disambig_gray.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5f/Disambig_gray.svg/50px-Disambig_gray.svg.png 2x" data-file-width="220" data-file-height="168" /></a>  「<b>北平</b>」重定向至此。关于其他用法,请见「<b><a href="/wiki/%E5%8C%97%E5%B9%B3_(%E6%B6%88%E6%AD%A7%E7%BE%A9)" title="北平 (消歧義)">北平 (消歧义)</a></b>」。</div>
<p><span style="font-size: small;"><span id="coordinates"><a href="/wiki/%E5%9C%B0%E7%90%86%E5%9D%90%E6%A0%87" class="mw-redirect" title="地理坐标">坐标</a>:<span class="plainlinks nourlexpansion"><a class="external text" href="//tools.wmflabs.org/geohack/geohack.php?language=zh&pagename=%E5%8C%97%E4%BA%AC%E5%B8%82&params=39_54_20_N_116_23_29_E_region:CN-11_type:adm1st&title=%E5%8C%97%E4%BA%AC%E5%B8%82"><span class="geo-default"><span class="geo-dms" title="此地的地图、航拍照片和其他数据"><span class="latitude">39°54′20″N</span> <span class="longitude">116°23′29″E</span></span></span><span class="geo-multi-punct"> / </span><span class="geo-nondefault"><span class="vcard"><span class="geo-dec" title="此地的地图、航拍照片和其他数据">39.90556°N 116.39139°E</span><span style="display:none"> / <span class="geo">39.90556; 116.39139</span></span><span style="display:none"> (<span class="fn org">北京市</span>)</span></span></span></a></span></span></span>
</p>
<table class="infobox geography vcard" style="width:23em; font-size:85%;">
<tbody><tr>
<td colspan="2" class="mergedtoprow" style="line-height:1.25em; text-align:center;font-size:1.3em;"><b>北京市</b>
</td></tr>
<tr>
<td colspan="2" style="background-color:#cddeff; font-weight:bold; text-align:center;"><span class="nowrap"><b><a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">直辖市</a></b></span>
</td></tr>
<tr>
<td colspan="2" style="text-align:center;"><style data-mw-deduplicate="TemplateStyles:r61200722/mw-parser-output/.tmulti">.mw-parser-output .tmulti .thumbinner{display:flex;flex-direction:column}.mw-parser-output .tmulti .trow{display:flex;flex-direction:row;clear:left;flex-wrap:wrap;width:100%;box-sizing:border-box}.mw-parser-output .tmulti .tsingle{margin:1px;float:left}.mw-parser-output .tmulti .theader{clear:both;font-weight:bold;text-align:center;align-self:center;background-color:transparent;width:100%}.mw-parser-output .tmulti .thumbcaption{text-align:left;background-color:transparent}.mw-parser-output .tmulti .text-align-left{text-align:left}.mw-parser-output .tmulti .text-align-right{text-align:right}.mw-parser-output .tmulti .text-align-center{text-align:center}@media all and (max-width:720px){.mw-parser-output .tmulti .thumbinner{width:100%!important;box-sizing:border-box;max-width:none!important;align-items:center}.mw-parser-output .tmulti .trow{justify-content:center}.mw-parser-output .tmulti .tsingle{float:none!important;max-width:100%!important;box-sizing:border-box;text-align:center}.mw-parser-output .tmulti .thumbcaption{text-align:center}}</style><div class="thumb tmulti tnone center"><div class="thumbinner" style="width:272px;max-width:272px;border:none"><div class="trow"><div class="tsingle" style="width:270px;max-width:270px"><div class="thumbimage" style="border:1;;height:120px;overflow:hidden"><a href="/wiki/File:Beijing_skyline_from_northeast_4th_ring_road.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/64/Beijing_skyline_from_northeast_4th_ring_road.jpg/268px-Beijing_skyline_from_northeast_4th_ring_road.jpg" decoding="async" width="268" height="121" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/64/Beijing_skyline_from_northeast_4th_ring_road.jpg/402px-Beijing_skyline_from_northeast_4th_ring_road.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/64/Beijing_skyline_from_northeast_4th_ring_road.jpg/536px-Beijing_skyline_from_northeast_4th_ring_road.jpg 2x" data-file-width="7091" data-file-height="3190" /></a></div></div></div><div class="trow"><div class="tsingle" style="width:178px;max-width:178px"><div class="thumbimage" style="border:1;;height:132px;overflow:hidden"><a href="/wiki/File:Flickr_-_archer10_(Dennis)_-_China-6123.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/176px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg" decoding="async" width="176" height="132" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/264px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/352px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg 2x" data-file-width="3264" data-file-height="2448" /></a></div></div><div class="tsingle" style="width:90px;max-width:90px"><div class="thumbimage" style="border:1;;height:132px;overflow:hidden"><a href="/wiki/File:The_Great_Wall_of_China_-_Badaling.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/The_Great_Wall_of_China_-_Badaling.jpg/88px-The_Great_Wall_of_China_-_Badaling.jpg" decoding="async" width="88" height="132" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/The_Great_Wall_of_China_-_Badaling.jpg/132px-The_Great_Wall_of_China_-_Badaling.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/The_Great_Wall_of_China_-_Badaling.jpg/176px-The_Great_Wall_of_China_-_Badaling.jpg 2x" data-file-width="2048" data-file-height="3072" /></a></div></div></div><div class="trow"><div class="tsingle" style="width:97px;max-width:97px"><div class="thumbimage" style="border:1;;height:95px;overflow:hidden"><a href="/wiki/File:TempleofHeaven-HallofPrayer_(square).jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/TempleofHeaven-HallofPrayer_%28square%29.jpg/95px-TempleofHeaven-HallofPrayer_%28square%29.jpg" decoding="async" width="95" height="95" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/TempleofHeaven-HallofPrayer_%28square%29.jpg/143px-TempleofHeaven-HallofPrayer_%28square%29.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/69/TempleofHeaven-HallofPrayer_%28square%29.jpg/190px-TempleofHeaven-HallofPrayer_%28square%29.jpg 2x" data-file-width="1303" data-file-height="1303" /></a></div></div><div class="tsingle" style="width:171px;max-width:171px"><div class="thumbimage" style="border:1;;height:95px;overflow:hidden"><a href="/wiki/File:Hall_of_Supreme_Harmony,_Forbidden_City,_from_southeast.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg/169px-Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg" decoding="async" width="169" height="95" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg/254px-Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg/338px-Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg 2x" data-file-width="6048" data-file-height="3402" /></a></div></div></div><div class="trow"><div class="tsingle" style="width:136px;max-width:136px"><div class="thumbimage" style="border:1;;height:86px;overflow:hidden"><a href="/wiki/File:Beijing_National_Stadium_1.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e0/Beijing_National_Stadium_1.jpg/134px-Beijing_National_Stadium_1.jpg" decoding="async" width="134" height="87" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e0/Beijing_National_Stadium_1.jpg/201px-Beijing_National_Stadium_1.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e0/Beijing_National_Stadium_1.jpg/268px-Beijing_National_Stadium_1.jpg 2x" data-file-width="1024" data-file-height="662" /></a></div></div><div class="tsingle" style="width:132px;max-width:132px"><div class="thumbimage" style="border:1;;height:86px;overflow:hidden"><a href="/wiki/File:%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/ee/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg/130px-%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg" decoding="async" width="130" height="87" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/ee/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg/195px-%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/ee/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg/260px-%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg 2x" data-file-width="4252" data-file-height="2835" /></a></div></div></div><div class="trow"><div class="tsingle" style="width:270px;max-width:270px"><div class="thumbimage" style="border:1;;height:123px;overflow:hidden"><a href="/wiki/File:National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a5/National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg/268px-National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg" decoding="async" width="268" height="124" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a5/National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg/402px-National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a5/National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg/536px-National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg 2x" data-file-width="1620" data-file-height="747" /></a></div></div></div></div></div>北京市风光(顺时针方向):<br /><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">北京CBD</a>天际线、<a href="/wiki/%E5%85%AB%E8%BE%BE%E5%B2%AD%E9%95%BF%E5%9F%8E" class="mw-redirect" title="八达岭长城">八達嶺長城</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%95%85%E5%AE%AE" class="mw-redirect" title="北京故宮">北京故宮</a><a href="/wiki/%E5%A4%AA%E5%92%8C%E6%AE%BF" title="太和殿">太和殿</a>、<a href="/wiki/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C" title="三里屯太古里">三里屯太古里</a>、<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%A4%A7%E6%9C%83%E5%A0%82" class="mw-redirect" title="人民大會堂">人民大會堂</a>(左)與<a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%A4%A7%E5%89%A7%E9%99%A2" title="国家大剧院">国家大剧院</a>(右)夜景、<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA_(%E5%8C%97%E4%BA%AC)" title="国家体育场 (北京)">国家体育场</a>、<a href="/wiki/%E5%A4%A9%E5%9D%9B" title="天坛">天坛</a>祈年殿、<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%9F%8E%E6%A5%BC" class="mw-redirect" title="天安门城楼">天安门城楼</a>
</td></tr>
<tr>
<td colspan="2" style="text-align:center;"><a href="/wiki/File:Beijing_in_China_(%2Ball_claims_hatched).svg" class="image" title="图中高亮显示的是北京市"><img alt="图中高亮显示的是北京市" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/0e/Beijing_in_China_%28%2Ball_claims_hatched%29.svg/300px-Beijing_in_China_%28%2Ball_claims_hatched%29.svg.png" decoding="async" width="300" height="239" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/0e/Beijing_in_China_%28%2Ball_claims_hatched%29.svg/450px-Beijing_in_China_%28%2Ball_claims_hatched%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/0e/Beijing_in_China_%28%2Ball_claims_hatched%29.svg/600px-Beijing_in_China_%28%2Ball_claims_hatched%29.svg.png 2x" data-file-width="1181" data-file-height="940" /></a>
</td></tr>
<tr>
<td style="width:38%;"><b>简称</b></td>
<td><b>京</b></td></tr>
<tr style="display:none">
<td style="width:38%;"><b>名称起源</b></td>
<td></td></tr>
<tr>
<td style="width:38%;"><b>国家</b></td>
<td><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a></td></tr>
<tr><td><b>政府所在地</b></td>
<td><a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">通州区</a></td></tr> <tr><td><b>最大区县</b></td><td><a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">密云区</a></td></tr>
<tr>
<td><b>主要领导人</b>
</td>
<td>
</td></tr>
<tr class="mergedrow">
<td>-<span class="nowrap"><a href="/wiki/%E5%B8%82%E5%A7%94%E4%B9%A6%E8%AE%B0" class="mw-redirect" title="市委书记">市委书记</a></span>
</td>
<td><a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">蔡奇</a>
</td></tr>
<tr class="mergedrow">
<td><span class="nowrap">-<a href="/wiki/%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A" class="mw-redirect" title="人大常委会">人大常委会</a>主任</span>
</td>
<td><a href="/wiki/%E6%9D%8E%E4%BC%9F_(%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%B8%B8%E5%A7%94)" class="mw-redirect" title="李伟 (北京市委常委)">李偉</a>
</td></tr>
<tr class="mergedrow">
<td>-<span class="nowrap"><a href="/wiki/%E5%B8%82%E9%95%BF" title="市长">市长</a></span>
</td>
<td><a href="/wiki/%E9%99%88%E5%90%89%E5%AE%81" title="陈吉宁">陈吉宁</a>
</td></tr>
<tr class="mergedbottomrow">
<td>-<span class="nowrap"><a href="/wiki/%E6%94%BF%E5%8D%8F" class="mw-redirect" title="政协">政协</a>主席</span>
</td>
<td><a href="/wiki/%E5%90%89%E6%9E%97_(%E4%BA%BA%E7%89%A9)" title="吉林 (人物)">吉林</a>
</td></tr>
<tr>
<td><b><a href="/wiki/%E9%9D%A2%E7%A7%AF" title="面积">面积</a></b>
</td>
<td>16,411 km²(<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%90%84%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E9%9D%A2%E7%A7%AF%E5%88%97%E8%A1%A8" class="mw-redirect" title="中华人民共和国各省级行政区面积列表">第29位</a>)
</td></tr>
<tr class="mergedrow">
<td>-占全国
</td>
<td>0.174%
</td></tr>
<tr class="mergedbottomrow" style="display:none">
<td>-占水域
</td>
<td>%
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%BA%BA%E5%8F%A3" title="人口">人口</a></b><sub>(2019)</sub>
</td>
<td>2153.6万<br />
<p>-城镇 1865万<sup id="cite_ref-1" class="reference"><a href="#cite_note-1">[1]</a></sup><br />
-市区 1123.6万<sup id="cite_ref-2" class="reference"><a href="#cite_note-2">[2]</a></sup><span id="noteTag-cite_ref-sup"><sup id="cite_ref-3" class="reference"><a href="#cite_note-3">[註 1]</a></sup></span>
</p>
</td></tr>
<tr class="mergedrow" style="display:none">
<td>-<a href="/wiki/%E4%BA%BA%E5%8F%A3%E5%AF%86%E5%BA%A6" title="人口密度">密度</a>
</td>
<td>/km²
</td></tr>
<tr class="mergedbottomrow" style="display:none">
<td>-占全国
</td>
<td>%
</td></tr>
<tr style="display:none">
<td><b><a href="/wiki/%E6%80%BB%E5%92%8C%E7%94%9F%E8%82%B2%E7%8E%87" title="总和生育率">总和生育率</a></b><sub>(2010)</sub>
</td>
<td>(<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%90%84%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E6%80%BB%E5%92%8C%E7%94%9F%E8%82%B2%E7%8E%87%E8%A1%A8" title="中华人民共和国各省级行政区总和生育率表">第位</a>)
</td></tr>
<tr>
<td><b><a href="/wiki/%E6%96%B9%E8%A8%80" title="方言">方言</a></b>
</td>
<td><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%AF%9D" title="北京话">北京话</a>
</td></tr>
<tr>
<td><b><a href="/wiki/%E5%9B%BD%E5%86%85%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="国内生产总值">GDP</a></b><sub>(2019)</sub>
</td>
<td><a href="/wiki/%E4%BA%BA%E6%B0%91%E5%B8%81" title="人民币">¥</a>35371.3亿人民币<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%B8%81" title="人民币">元</a><sup id="cite_ref-4" class="reference"><a href="#cite_note-4">[3]</a></sup><br />约合5350亿<span style="white-space: nowrap">美元</span>
</td></tr>
<tr class="mergedrow">
<td>-<a href="/wiki/%E4%BA%BA%E5%9D%87%E5%9B%BD%E5%86%85%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" class="mw-redirect" title="人均国内生产总值">人均</a>
</td>
<td>¥16.4万人民币<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%B8%81" title="人民币">元</a><br />约合24800<span style="white-space: nowrap">美元</span>
</td></tr>
<tr class="mergedbottomrow" style="display:none">
<td>-占全国
</td>
<td><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%9C%B0%E5%8C%BA%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC%E5%88%97%E8%A1%A8" title="中华人民共和国省级行政区地区生产总值列表">%</a>
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%BA%BA%E7%B1%BB%E5%8F%91%E5%B1%95%E6%8C%87%E6%95%B0" title="人类发展指数">HDI</a></b><sub>(2017)</sub>
</td>
<td>0.887(<span style="background:#007F00;color:#FFFFFF;"> 极高 </span>,<a href="/wiki/%E4%B8%AD%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E4%BA%BA%E7%B1%BB%E5%8F%91%E5%B1%95%E6%8C%87%E6%95%B0%E5%88%97%E8%A1%A8" class="mw-redirect" title="中国省级行政区人类发展指数列表">第1位</a>)
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%B8%AD%E5%9C%8B%E6%B0%91%E6%97%8F%E5%88%97%E8%A1%A8" title="中國民族列表">主要民族</a></b></td>
<td><a href="/wiki/%E6%B1%89%E6%97%8F" title="汉族">汉族</a> 96%<br /><a href="/wiki/%E6%BB%A1%E6%97%8F" title="满族">满族</a> 2%<br /><a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">回族</a> 1.6%<br /><a href="/wiki/%E8%92%99%E5%8F%A4%E6%97%8F" title="蒙古族">蒙古族</a> 0.3%
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%A2%83%E5%86%85%E5%9C%B0%E5%8C%BA%E9%82%AE%E6%94%BF%E7%BC%96%E7%A0%81%E5%88%97%E8%A1%A8" title="中华人民共和国境内地区邮政编码列表">邮政编码</a></b></td>
<td>100000
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7" class="mw-redirect" title="中华人民共和国电话区号">电话区号</a></b></td>
<td><a href="/wiki/%E5%9B%BD%E9%99%85%E5%86%A0%E7%A0%81" class="mw-redirect" title="国际冠码">+</a><a href="/wiki/%E5%9B%BD%E9%99%85%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7%E5%88%97%E8%A1%A8" title="国际电话区号列表">86</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7" class="mw-redirect" title="中华人民共和国电话区号">(0)10</a>
</td></tr>
<tr>
<td><b><a href="/wiki/%E5%B8%82%E6%A0%91" title="市树">市树</a></b></td>
<td><a href="/wiki/%E4%BE%A7%E6%9F%8F" title="侧柏">侧柏</a>、<a href="/wiki/%E5%9B%BD%E6%A7%90" class="mw-redirect" title="国槐">国槐</a>
</td></tr>
<tr>
<td><b><a href="/wiki/%E5%B8%82%E8%8A%B1" title="市花">市花</a></b></td>
<td><a href="/wiki/%E6%9C%88%E5%AD%A3" title="月季">月季</a>、<a href="/wiki/%E8%8F%8A%E8%8A%B1" title="菊花">菊花</a>
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%BD%A6%E8%BE%86%E7%89%8C%E7%85%A7" class="mw-redirect" title="中华人民共和国车辆牌照">车辆号牌</a></b></td>
<td>京A, C, E, F, H, J, K, L, M, N, P, Q<br />京B(出租车)<br />京G,Y(郊区)<br />京O,D(警察和政府)
</td></tr>
<tr>
<td><b><a href="/wiki/%E5%8E%BF%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="县级行政区">县级行政区</a></b>
</td>
<td>16个
</td></tr>
<tr>
<td><b><a href="/wiki/%E4%B9%A1%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="乡级行政区">乡级行政区</a></b>
</td>
<td>322个
</td></tr>
<tr>
<td><b><a href="/wiki/ISO_3166-2" title="ISO 3166-2">ISO 3166-2</a></b></td>
<td>CN-BJ
</td></tr>
<tr>
<td colspan="2" style="text-align:center;"><b>政府门户网站</b><br /><a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/">首都之窗</a>
</td></tr>
<tr>
<td colspan="2"><span style="font-size:smaller;"><b>人口与GDP数据的参考文献:</b></span><div style="padding-left:2em;"><small><div>
<ul><li>2010年2月26日,中国之声《央广新闻》14时15分报道</li></ul></div></small></div><span style="font-size:smaller;"><b>民族数据的参考文献:</b></span><div style="padding-left:2em;"><small><div>
<li>2010年8月20日,新华网-新华新闻报道</li></div></small>
</div></td></tr></tbody></table>
<table class="infobox" style="width: 22em; text-align:left; font-size:small; line-height:1.5em;"><tbody><tr><td colspan="2" style="text-align:center;font-size: 125%; background-color: #b0c4de;"><b>北京市</b></td></tr><tr><th scope="row" style="text-align:left;font-weight:normal; white-space: nowrap; font-size: small;"><a href="/wiki/%E6%B1%89%E8%AF%AD" title="汉语">汉语</a></th><td style="font-size: small; width: 50%;;"><span style="font-size: 1rem; width: 50%;"><span lang="zh-hani"> 北京 </span></span></td></tr><tr><td colspan="2" style="text-align:center;font-size: small; width: 50%;;"></td></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;"><a href="/wiki/%E6%B1%89%E8%AF%AD%E6%8B%BC%E9%9F%B3" title="汉语拼音">汉语拼音</a></th><td style="width: 50%; text-align: left;"><style data-mw-deduplicate="TemplateStyles:r58929728">.mw-parser-output .sans-serif{font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,Lato,"Helvetica Neue",Helvetica,Arial,sans-serif}</style><span class="sans-serif"> Běijīng<br /><span class="unicode haudio"><span class="fn"><span style="white-space:nowrap"><a href="/wiki/File:Zh-Beijing.ogg" title="关于这个音频文件"><img alt="关于这个音频文件" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/11px-Loudspeaker.svg.png" decoding="async" width="11" height="11" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/17px-Loudspeaker.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/22px-Loudspeaker.svg.png 2x" data-file-width="20" data-file-height="20" /></a> </span><a href="//upload.wikimedia.org/wikipedia/commons/8/8a/Zh-Beijing.ogg" class="internal" title="Zh-Beijing.ogg">发音</a></span><small class="metadata audiolinkinfo" style="cursor:help;"> <sup><a href="/wiki/Wikipedia:%E5%AA%92%E9%AB%94%E5%B9%AB%E5%8A%A9" class="mw-redirect" title="Wikipedia:媒體幫助"><span style="cursor:help;">帮助</span></a>·<a href="/wiki/File:Zh-Beijing.ogg" title="File:Zh-Beijing.ogg"><span style="cursor:help;">信息</span></a></sup></small></span> </span></td></tr><tr style="display:none"><td colspan="2">
</td></tr><tr><th scope="row" style="text-align:left;font-weight:normal; white-space: nowrap; font-size: small;"><a href="/wiki/%E9%83%B5%E6%94%BF%E5%BC%8F%E6%8B%BC%E9%9F%B3" title="郵政式拼音">郵政式拼音</a></th><td style="font-size: small; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> Peking </span></td></tr><tr><td colspan="2" style="text-align:center;font-size: small; width: 50%;;"><table class="collapsible collapsed" cellspacing="3" style="border-spacing:3px;padding:0;border:none;margin:-3px;width:auto;min-width:100%;font-size:small;clear:none;float:none;background-color:transparent"><tbody><tr><th colspan="2" style="text-align:center;font-size:125%;font-weight:bold;font-size: 100%; text-align: left; background-color: #f9ffbc">标音</th></tr><tr><th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;"><a href="/wiki/%E5%AE%98%E8%AF%9D" title="官话">官话</a></th></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E6%B1%89%E8%AF%AD%E6%8B%BC%E9%9F%B3" title="汉语拼音">汉语拼音</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> Běijīng<br /><span class="unicode haudio"><span class="fn"><span style="white-space:nowrap"><a href="/wiki/File:Zh-Beijing.ogg" title="关于这个音频文件"><img alt="关于这个音频文件" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/11px-Loudspeaker.svg.png" decoding="async" width="11" height="11" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/17px-Loudspeaker.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/22px-Loudspeaker.svg.png 2x" data-file-width="20" data-file-height="20" /></a> </span><a href="//upload.wikimedia.org/wikipedia/commons/8/8a/Zh-Beijing.ogg" class="internal" title="Zh-Beijing.ogg">发音</a></span><small class="metadata audiolinkinfo" style="cursor:help;"> <sup><a href="/wiki/Wikipedia:%E5%AA%92%E9%AB%94%E5%B9%AB%E5%8A%A9" class="mw-redirect" title="Wikipedia:媒體幫助"><span style="cursor:help;">帮助</span></a>·<a href="/wiki/File:Zh-Beijing.ogg" title="File:Zh-Beijing.ogg"><span style="cursor:help;">信息</span></a></sup></small></span> </span></td></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E5%A8%81%E5%A6%A5%E7%91%AA%E6%8B%BC%E9%9F%B3" title="威妥瑪拼音">威妥瑪拼音</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> Pei<sup>3</sup>ching<sup>1</sup> or Pei<sup>3</sup>-ching<sup>1</sup> </span></td></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E6%B3%A8%E9%9F%B3%E7%AC%A6%E8%99%9F" title="注音符號">注音符號</a></th><td style="text-align: left; width: 50%;;">ㄅㄟˇ ㄐㄧㄥ</td></tr><tr><th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;"><a href="/wiki/%E5%AE%98%E8%AF%9D" title="官话">其他官话</a></th></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E5%8D%97%E4%BA%AC%E5%AE%98%E8%AF%9D" class="mw-redirect" title="南京官话">南京官话</a><a href="/wiki/%E5%8D%97%E4%BA%AC%E8%A9%B1%E6%8B%89%E4%B8%81%E5%8C%96%E6%96%B9%E6%A1%88#輸入法方案" title="南京話拉丁化方案">拼音</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> bä<sup>5</sup>jin<sup>1</sup> </span></td></tr><tr><th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;"><a href="/wiki/%E9%97%BD%E8%AF%AD" title="闽语">闽语</a></th></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E9%97%BD%E5%8D%97%E8%AF%AD" title="闽南语">闽南语</a><a href="/wiki/%E7%99%BD%E8%A9%B1%E5%AD%97" title="白話字">白話字</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> Pak-kiaⁿ </span></td></tr><tr><th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;"><a href="/wiki/%E5%90%B4%E8%AF%AD" title="吴语">吴语</a></th></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E5%90%B4%E8%AF%AD" title="吴语">拉丁化</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> poh<sup>入</sup>cin<sup>平</sup> </span></td></tr><tr><th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;"><a href="/wiki/%E7%B2%A4%E8%AF%AD" title="粤语">粤语</a></th></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E7%B2%B5%E6%8B%BC" class="mw-redirect" title="粵拼">粵拼</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> bak<sup>1</sup>ging<sup>1</sup> </span></td></tr><tr><th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;"><a href="/wiki/%E5%AE%A2%E5%AE%B6%E8%AF%9D" title="客家话">客家话</a></th></tr><tr><th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">- <a href="/wiki/%E5%AE%A2%E5%AE%B6%E8%A9%B1%E6%8B%BC%E9%9F%B3%E6%96%B9%E6%A1%88" title="客家話拼音方案">客家话拼音</a></th><td style="text-align: left; width: 50%;;"><link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r58929728"/><span class="sans-serif"> Pet-kîn </span></td></tr></tbody></table></td></tr></tbody></table>
<p><b>北京市</b>,通称<b>北京</b>(<a href="/wiki/%E6%B1%89%E8%AF%AD%E6%8B%BC%E9%9F%B3" title="汉语拼音">汉语拼音</a>:<i>Běijīng</i>;<a href="/wiki/%E9%82%AE%E6%94%BF%E5%BC%8F%E6%8B%BC%E9%9F%B3" class="mw-redirect" title="邮政式拼音">邮政式拼音</a>:Peking),简称“<b>京</b>”,是<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B" class="mw-redirect" title="中華人民共和國">中華人民共和國</a>的<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">首都</a>及<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">直辖市</a>,是中國大陸的<a href="/wiki/%E6%94%BF%E6%B2%BB" title="政治">政治</a>、<a href="/wiki/%E6%96%87%E5%8C%96" title="文化">文化</a>、科技和国际交往中心,是<a href="/wiki/%E6%8C%89%E5%B8%82%E5%9F%9F%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%88%97%E7%9A%84%E4%B8%96%E7%95%8C%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="按市域人口排列的世界城市列表">世界人口第三多的城市</a>和<a href="/wiki/%E5%85%A8%E7%90%83%E9%A6%96%E9%83%BD%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%90%8D" title="全球首都人口排名">人口最多的首都</a>,具有重要的国际影响力。北京位於<a href="/wiki/%E8%8F%AF%E5%8C%97%E5%B9%B3%E5%8E%9F" class="mw-redirect" title="華北平原">華北平原</a>的西北边缘,背靠<a href="/wiki/%E7%87%95%E5%B1%B1" title="燕山">燕山</a>,有<a href="/wiki/%E6%B0%B8%E5%AE%9A%E6%B2%B3" title="永定河">永定河</a>流经<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E6%B1%A0" class="mw-redirect" title="北京城池">老城</a>西南,毗邻<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a>、<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北省</a>,为<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%86%80%E5%9F%8E%E5%B8%82%E7%BE%A4" title="京津冀城市群">京津冀城市群</a>的重要组成部分。
</p><p>北京是中国<a href="/wiki/%E5%9B%9B%E5%A4%A7%E5%8F%A4%E9%83%BD" class="mw-redirect" title="四大古都">古都</a>之一,是拥有三千余年建城历史、八百六十余年建都史的<a href="/wiki/%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" class="mw-redirect" title="历史文化名城">历史文化名城</a>,有<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">辽</a>、<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">金</a>、<a href="/wiki/%E5%85%83%E6%9C%9D" title="元朝">元</a>、<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">明</a>、<a href="/wiki/%E6%B8%85" class="mw-redirect" title="清">清</a>五个<a href="/wiki/%E6%9C%9D%E4%BB%A3" title="朝代">朝代</a>在此定都,及数个政权建政于此。<a href="/wiki/%E7%89%A7%E9%87%8E%E4%B9%8B%E6%88%98" title="牧野之战">公元前1122年</a><a href="/wiki/%E5%91%A8%E6%AD%A6%E7%8E%8B" title="周武王">周武王</a>灭<a href="/wiki/%E5%95%86%E6%9C%9D" title="商朝">商</a>后,封宗室<a href="/wiki/%E5%8F%AC%E5%85%AC%E5%A5%AD" title="召公奭">召公奭</a>于<a href="/wiki/%E7%87%95%E5%9B%BD" title="燕国">燕国</a>,是为北京建城之始。金中都时期人口超过一百万,为元、明、清三代的北京城的建设奠定了基础。1949年,北京被定为<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a>首都,此后曾发生了<a href="/wiki/%E7%BA%A2%E5%85%AB%E6%9C%88" title="红八月">红八月</a>、<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">四五运动</a>、<a href="/wiki/%E5%85%AD%E5%9B%9B%E5%A4%A9%E5%AE%89%E9%97%A8%E4%BA%8B%E4%BB%B6" class="mw-redirect" title="六四天安门事件">六四天安门事件</a>等各种重大事件。北京荟萃了自元明清以来的近世<a href="/wiki/%E4%B8%AD%E5%8D%8E%E6%96%87%E5%8C%96" title="中华文化">中华文化</a>,拥有众多历史名胜古迹和人文景观,拥有7项<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%96%E7%95%8C%E9%81%97%E4%BA%A7" class="mw-redirect" title="中国世界遗产">世界遗产</a>,是世界上拥有<a href="/wiki/%E6%96%87%E5%8C%96%E9%81%97%E4%BA%A7" title="文化遗产">文化遗产</a>项目数最多的城市。在中国过去的八个世纪里,几乎北京所有的主要建筑都拥有不可磨灭的历史意义。北京古迹众多,著名的有<a href="/wiki/%E7%B4%AB%E7%A6%81%E5%9F%8E" class="mw-redirect" title="紫禁城">紫禁城</a>、<a href="/wiki/%E5%A4%A9%E5%9D%9B" title="天坛">天坛</a>、<a href="/wiki/%E9%A2%90%E5%92%8C%E5%9B%AD" title="颐和园">颐和园</a>、<a href="/wiki/%E5%9C%86%E6%98%8E%E5%9B%AD" title="圆明园">圆明园</a>、<a href="/wiki/%E5%8C%97%E6%B5%B7%E5%85%AC%E5%9B%AD" title="北海公园">北海公园</a>等;<a href="/wiki/%E8%83%A1%E5%90%8C" title="胡同">胡同</a>和<a href="/wiki/%E5%9B%9B%E5%90%88%E9%99%A2" title="四合院">四合院</a>作为北京老城的典型民居形式,已经是北京历史重要的文化符号<sup id="cite_ref-autogenerated2_5-0" class="reference"><a href="#cite_note-autogenerated2-5">[4]</a></sup>。北京是中国重要的旅游城镇之一,被《<a href="/wiki/%E7%B1%B3%E5%85%B6%E6%9E%97" title="米其林">米其林</a>旅游指南》评为“三星级旅游推荐”(最高级别)<sup id="cite_ref-6" class="reference"><a href="#cite_note-6">[5]</a></sup>。
</p><p>北京在中国大陸的政治、经贸、文化、教育和科技领域拥有显著影响力,为中国大陸绝大多数<a href="/wiki/%E5%9B%BD%E6%9C%89%E4%BC%81%E4%B8%9A" title="国有企业">国有企业</a>总部所在地,并且拥有全球最多的<a href="/wiki/%E8%B4%A2%E5%AF%8C%E4%B8%96%E7%95%8C500%E5%BC%BA" title="财富世界500强">财富世界500强</a>企业总部<sup id="cite_ref-7" class="reference"><a href="#cite_note-7">[6]</a></sup>,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">北京商务中心区</a>聚集有大量国际性金融商务办公设施及<a href="/wiki/%E6%91%A9%E5%A4%A9%E5%A4%A7%E6%A5%BC" class="mw-redirect" title="摩天大楼">摩天大楼</a>,<a href="/wiki/%E4%B8%AD%E5%85%B3%E6%9D%91" title="中关村">中关村地区</a>则集中了中国大陸重要的高新技术产业。北京是<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E9%90%B5%E8%B7%AF%E9%81%8B%E8%BC%B8" title="中華人民共和國鐵路運輸">中国大陸铁路运输</a>和<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%AC%E8%B7%AF" class="mw-redirect" title="中国公路">公路运输</a>的枢纽城市之一,<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%A6%96%E9%83%BD%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA" title="北京首都国际机场">北京首都国际机场</a>的旅客吞吐量位居世界第二<sup id="cite_ref-2018年旅客破亿_8-0" class="reference"><a href="#cite_note-2018年旅客破亿-8">[7]</a></sup>,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">北京地铁</a>则是世界上运营里程最长、客运量最多的<a href="/wiki/%E5%9F%8E%E5%B8%82%E8%BD%A8%E9%81%93%E4%BA%A4%E9%80%9A%E7%B3%BB%E7%BB%9F" class="mw-redirect" title="城市轨道交通系统">城市轨道交通系统</a><sup id="cite_ref-9" class="reference"><a href="#cite_note-9">[8]</a></sup><sup id="cite_ref-10" class="reference"><a href="#cite_note-10">[9]</a></sup><sup id="cite_ref-11" class="reference"><a href="#cite_note-11">[10]</a></sup>。北京是中国大陸拥有最多<a href="/wiki/%E9%AB%98%E7%AD%89%E9%99%A2%E6%A0%A1" class="mw-redirect" title="高等院校">高等院校</a>的城市<sup id="cite_ref-Beijing_12-0" class="reference"><a href="#cite_note-Beijing-12">[11]</a></sup>,校址位于北京的<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6" title="清华大学">清华大学</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%A6" title="北京大学">北京大学</a>被视为中国大陸顶尖大学的代表<sup id="cite_ref-13" class="reference"><a href="#cite_note-13">[12]</a></sup>。北京在全球政治、经济等社会活动中处于重要地位并具有主导辐射带动能力,在GaWC<a href="/wiki/%E5%85%A8%E7%90%83%E5%9F%8E%E5%B8%82" title="全球城市">全球城市</a>排行中排名第6,在中華人民共和国中,仅次于<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港</a>和<a href="/wiki/%E4%B8%8A%E6%B5%B7" class="mw-redirect" title="上海">上海</a><sup id="cite_ref-14" class="reference"><a href="#cite_note-14">[13]</a></sup>。
</p>
<div id="toc" class="toc" role="navigation" aria-labelledby="mw-toc-heading"><input type="checkbox" role="button" id="toctogglecheckbox" class="toctogglecheckbox" style="display:none" /><div class="toctitle" lang="zh" dir="ltr"><h2 id="mw-toc-heading">目录</h2><span class="toctogglespan"><label class="toctogglelabel" for="toctogglecheckbox"></label></span></div>
<ul>
<li class="toclevel-1 tocsection-1"><a href="#名称"><span class="tocnumber">1</span> <span class="toctext">名称</span></a></li>
<li class="toclevel-1 tocsection-2"><a href="#历史"><span class="tocnumber">2</span> <span class="toctext">历史</span></a>
<ul>
<li class="toclevel-2 tocsection-3"><a href="#史前"><span class="tocnumber">2.1</span> <span class="toctext">史前</span></a></li>
<li class="toclevel-2 tocsection-4"><a href="#古代"><span class="tocnumber">2.2</span> <span class="toctext">古代</span></a></li>
<li class="toclevel-2 tocsection-5"><a href="#近代"><span class="tocnumber">2.3</span> <span class="toctext">近代</span></a></li>
<li class="toclevel-2 tocsection-6"><a href="#文化大革命期间"><span class="tocnumber">2.4</span> <span class="toctext">文化大革命期间</span></a></li>
<li class="toclevel-2 tocsection-7"><a href="#现当代"><span class="tocnumber">2.5</span> <span class="toctext">现当代</span></a></li>
</ul>
</li>
<li class="toclevel-1 tocsection-8"><a href="#地理"><span class="tocnumber">3</span> <span class="toctext">地理</span></a>
<ul>
<li class="toclevel-2 tocsection-9"><a href="#氣候"><span class="tocnumber">3.1</span> <span class="toctext">氣候</span></a></li>
<li class="toclevel-2 tocsection-10"><a href="#空气污染"><span class="tocnumber">3.2</span> <span class="toctext">空气污染</span></a></li>
</ul>
</li>
<li class="toclevel-1 tocsection-11"><a href="#行政区划"><span class="tocnumber">4</span> <span class="toctext">行政区划</span></a></li>
<li class="toclevel-1 tocsection-12"><a href="#政治"><span class="tocnumber">5</span> <span class="toctext">政治</span></a>
<ul>
<li class="toclevel-2 tocsection-13"><a href="#四大机构"><span class="tocnumber">5.1</span> <span class="toctext">四大机构</span></a></li>
</ul>
</li>
<li class="toclevel-1 tocsection-14"><a href="#经济"><span class="tocnumber">6</span> <span class="toctext">经济</span></a>
<ul>
<li class="toclevel-2 tocsection-15"><a href="#經濟數據"><span class="tocnumber">6.1</span> <span class="toctext">經濟數據</span></a></li>
<li class="toclevel-2 tocsection-16"><a href="#-{zh:基础设施;zh-hans:基础设施;zh-hant:基礎建設}-"><span class="tocnumber">6.2</span> <span class="toctext">基础设施</span></a>
<ul>
<li class="toclevel-3 tocsection-17"><a href="#公路"><span class="tocnumber">6.2.1</span> <span class="toctext">公路</span></a></li>
<li class="toclevel-3 tocsection-18"><a href="#铁路"><span class="tocnumber">6.2.2</span> <span class="toctext">铁路</span></a></li>
<li class="toclevel-3 tocsection-19"><a href="#航空"><span class="tocnumber">6.2.3</span> <span class="toctext">航空</span></a></li>
<li class="toclevel-3 tocsection-20"><a href="#地面公交"><span class="tocnumber">6.2.4</span> <span class="toctext">地面公交</span></a></li>
<li class="toclevel-3 tocsection-21"><a href="#出租车"><span class="tocnumber">6.2.5</span> <span class="toctext">出租车</span></a></li>
<li class="toclevel-3 tocsection-22"><a href="#邮电"><span class="tocnumber">6.2.6</span> <span class="toctext">邮电</span></a></li>
</ul>
</li>
<li class="toclevel-2 tocsection-23"><a href="#旅游業"><span class="tocnumber">6.3</span> <span class="toctext">旅游業</span></a></li>
</ul>
</li>
<li class="toclevel-1 tocsection-24"><a href="#教育"><span class="tocnumber">7</span> <span class="toctext">教育</span></a></li>
<li class="toclevel-1 tocsection-25"><a href="#人口"><span class="tocnumber">8</span> <span class="toctext">人口</span></a></li>
<li class="toclevel-1 tocsection-26"><a href="#文化"><span class="tocnumber">9</span> <span class="toctext">文化</span></a>
<ul>
<li class="toclevel-2 tocsection-27"><a href="#文学"><span class="tocnumber">9.1</span> <span class="toctext">文学</span></a></li>
<li class="toclevel-2 tocsection-28"><a href="#饮食文化"><span class="tocnumber">9.2</span> <span class="toctext">饮食文化</span></a></li>
<li class="toclevel-2 tocsection-29"><a href="#表演艺术"><span class="tocnumber">9.3</span> <span class="toctext">表演艺术</span></a></li>
<li class="toclevel-2 tocsection-30"><a href="#艺术园区"><span class="tocnumber">9.4</span> <span class="toctext">艺术园区</span></a></li>
</ul>
</li>
<li class="toclevel-1 tocsection-31"><a href="#人物"><span class="tocnumber">10</span> <span class="toctext">人物</span></a></li>
<li class="toclevel-1 tocsection-32"><a href="#宗教"><span class="tocnumber">11</span> <span class="toctext">宗教</span></a></li>
<li class="toclevel-1 tocsection-33"><a href="#体育"><span class="tocnumber">12</span> <span class="toctext">体育</span></a></li>
<li class="toclevel-1 tocsection-34"><a href="#友好城市"><span class="tocnumber">13</span> <span class="toctext">友好城市</span></a></li>
<li class="toclevel-1 tocsection-35"><a href="#注释"><span class="tocnumber">14</span> <span class="toctext">注释</span></a></li>
<li class="toclevel-1 tocsection-36"><a href="#参考文献"><span class="tocnumber">15</span> <span class="toctext">参考文献</span></a></li>
<li class="toclevel-1 tocsection-37"><a href="#外部链接"><span class="tocnumber">16</span> <span class="toctext">外部链接</span></a></li>
<li class="toclevel-1 tocsection-38"><a href="#参见"><span class="tocnumber">17</span> <span class="toctext">参见</span></a></li>
</ul>
</div>
<h2><span id=".E5.90.8D.E7.A7.B0"></span><span class="mw-headline" id="名称">名称</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=1" title="编辑章节:名称">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<p>曾先后被称为<a href="/wiki/%E8%93%9F%E5%9F%8E" title="蓟城">蓟城</a>、<a href="/wiki/%E7%87%95%E9%83%BD" class="mw-redirect" title="燕都">燕中都</a>、燕京、<a href="/wiki/%E8%93%9F%E5%8E%BF%E5%9F%8E" class="mw-redirect" title="蓟县城">蓟县</a>、<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">广阳郡</a>、<a href="/wiki/%E5%B9%BF%E9%98%B3%E5%9B%BD" class="mw-redirect" title="广阳国">广阳国</a>、<a href="/wiki/%E5%B9%BD%E5%B7%9E" class="mw-redirect" title="幽州">幽州</a>、<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">燕国</a>、<a href="/wiki/%E7%87%95%E9%83%A1" title="燕郡">燕郡</a>、<a href="/wiki/%E6%B6%BF%E9%83%A1" title="涿郡">涿郡</a>、<a href="/wiki/%E8%8C%83%E9%98%B3%E8%8A%82%E5%BA%A6%E4%BD%BF" class="mw-redirect" title="范阳节度使">范阳</a>、<a href="/wiki/%E5%8D%A2%E9%BE%99%E8%8A%82%E5%BA%A6%E4%BD%BF" class="mw-redirect" title="卢龙节度使">卢龙</a>、南京<a href="/wiki/%E5%B9%BD%E9%83%BD%E5%BA%9C" title="幽都府">幽都府</a>、南京<a href="/wiki/%E6%9E%90%E6%B4%A5%E5%BA%9C" title="析津府">析津府</a>、<a href="/wiki/%E7%87%95%E5%B1%B1%E5%BA%9C%E8%B7%AF" title="燕山府路">燕山府路</a>、<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">中都大兴府</a>、<a href="/wiki/%E4%B8%AD%E9%83%BD%E8%B7%AF" title="中都路">中都路</a>、<a href="/wiki/%E5%A4%A7%E9%83%BD" class="mw-redirect" title="大都">大都路</a><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%BA%9C" title="大兴府">大兴府</a>、<a href="/wiki/%E5%8C%97%E5%B9%B3" class="mw-redirect" title="北平">北平府</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC" class="mw-redirect" title="北京">北京</a>、<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">京师</a>、<a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a>、<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">京兆地方</a>、<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">北平特别市</a>等。现名北京市。有京城、京都、<a href="/wiki/%E4%BA%AC%E7%95%BF" class="mw-disambig" title="京畿">京畿</a>、京兆等非正式称呼。
</p>
<h2><span id=".E5.8E.86.E5.8F.B2"></span><span class="mw-headline" id="历史">历史</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=2" title="编辑章节:历史">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2" title="北京历史">北京历史</a></div>
<h3><span id=".E5.8F.B2.E5.89.8D"></span><span class="mw-headline" id="史前">史前</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=3" title="编辑章节:史前">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>距今60万年-2万年的时间内,北京地区处于<a href="/wiki/%E6%97%A7%E7%9F%B3%E5%99%A8%E6%97%B6%E4%BB%A3" title="旧石器时代">旧石器时代</a>,在周口店发现了旧石器时代早期<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%9B%B4%E7%AB%8B%E4%BA%BA" class="mw-redirect" title="北京直立人">北京直立人</a>、中期<a href="/w/index.php?title=%E6%96%B0%E6%B4%9E%E4%BA%BA&action=edit&redlink=1" class="new" title="新洞人(页面不存在)">新洞人</a>和晚期<a href="/wiki/%E5%B1%B1%E9%A1%B6%E6%B4%9E%E4%BA%BA" title="山顶洞人">山顶洞人</a>的典型遗址。北京地区在不晚于1万年前已经开始进入<a href="/wiki/%E6%96%B0%E7%9F%B3%E5%99%A8%E6%97%B6%E4%BB%A3" title="新石器时代">新石器时代</a>。当时该地区人类定居生活固定化,逐渐从山洞中迁徙出来,到平原地区定居<sup id="cite_ref-15" class="reference"><a href="#cite_note-15">[14]</a></sup>。
</p>
<h3><span id=".E5.8F.A4.E4.BB.A3"></span><span class="mw-headline" id="古代">古代</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=4" title="编辑章节:古代">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>北京作为城市的历史可以追溯到3,000年前。<a href="/wiki/%E8%A5%BF%E5%91%A8" title="西周">西周</a>初年,<a href="/wiki/%E5%91%A8%E6%AD%A6%E7%8E%8B" title="周武王">周武王</a>封<a href="/wiki/%E5%8F%AC%E5%85%AC%E5%A5%AD" title="召公奭">召公奭</a>于<a href="/wiki/%E7%87%95%E5%9C%8B" class="mw-redirect" title="燕國">燕國</a>。燕国早期都城位于今<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">房山区</a><a href="/wiki/%E7%90%89%E7%92%83%E6%B2%B3%E9%81%97%E5%9D%80" title="琉璃河遗址">琉璃河遗址</a>。一些学者将琉璃河古城视为北京城的源头。据《史记》,周武王封尧的后人建立<a href="/wiki/%E8%96%8A%E5%9C%8B" title="薊國">蓟国</a>,都城为蓟。春秋时期,燕灭蓟,将都城迁至蓟。蓟城的具体位置尚有争议。郦道元《水经注》认为,蓟城的位置就在今天的北京。1950年代起,北京<a href="/wiki/%E5%AE%A3%E6%AD%A6%E9%97%A8" title="宣武门">宣武门</a>至<a href="/wiki/%E5%92%8C%E5%B9%B3%E9%97%A8_(%E5%8C%97%E4%BA%AC)" title="和平门 (北京)">和平门</a>一带的基建工程中发现了大量的春秋时代至西汉的陶井,学者据此认为蓟城的位置就在这一带,认为蓟城是北京城的起源。然而,这一区域并未发现西周时代的遗存,西周时蓟城的位置仍然未知。
</p><p>前222年,<a href="/wiki/%E7%A7%A6%E5%9B%BD" title="秦国">秦国</a>灭燕后,设北京为<a href="/wiki/%E8%93%9F%E5%8E%BF" class="mw-redirect" title="蓟县">蓟县</a>,为<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">广阳郡</a>郡治。汉<a href="/wiki/%E5%85%83%E5%87%A4" title="元凤">元凤</a>元年广阳郡蓟县属<a href="/wiki/%E5%B9%BD%E5%B7%9E" class="mw-redirect" title="幽州">幽州</a>管辖。<a href="/wiki/%E6%9C%AC%E5%A7%8B" title="本始">本始</a>元年更名为<a href="/wiki/%E5%B9%BF%E9%98%B3%E5%9B%BD" class="mw-redirect" title="广阳国">广阳国</a>首府。<a href="/wiki/%E4%B8%9C%E6%B1%89" title="东汉">东汉</a><a href="/wiki/%E5%85%89%E6%AD%A6%E5%B8%9D" class="mw-redirect" title="光武帝">光武</a>改制时,置幽州<a href="/wiki/%E5%88%BA%E5%8F%B2" title="刺史">刺史</a>部于蓟县。永元八年复为<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">广阳郡</a>治所。<a href="/wiki/%E8%A5%BF%E6%99%8B" title="西晋">西晋</a>时,朝廷改广阳郡为燕国,而幽州迁至<a href="/wiki/%E8%8C%83%E9%98%B3" title="范阳">范阳</a>。<a href="/wiki/%E5%8D%81%E5%85%AD%E5%9B%BD" class="mw-redirect" title="十六国">十六国</a><a href="/wiki/%E5%90%8E%E8%B5%B5" title="后赵">后赵</a>时,幽州驻所迁回蓟县,燕国改设为燕郡,历经<a href="/wiki/%E5%89%8D%E7%87%95" title="前燕">前燕</a>、<a href="/wiki/%E5%89%8D%E7%A7%A6" title="前秦">前秦</a>、<a href="/wiki/%E5%8C%97%E7%87%95" title="北燕">北燕</a>、<a href="/wiki/%E5%90%8E%E7%87%95" class="mw-redirect" title="后燕">后燕</a>和<a href="/wiki/%E5%8C%97%E9%AD%8F" title="北魏">北魏</a>的统治而不变。
</p><p><a href="/wiki/%E9%9A%8B%E6%9C%9D" title="隋朝">隋朝</a>开皇三年(583年)废除燕郡。但很快在大业三年(607年),<a href="/wiki/%E9%9A%8B%E6%9C%9D" title="隋朝">隋朝</a>改<a href="/wiki/%E5%B9%BD%E5%B7%9E" class="mw-redirect" title="幽州">幽州</a>为<a href="/wiki/%E6%B6%BF%E9%83%A1" title="涿郡">涿郡</a>。<a href="/wiki/%E5%94%90%E6%9C%9D" title="唐朝">唐朝</a><a href="/wiki/%E6%AD%A6%E5%BE%B7" title="武德">武德</a>年间,<a href="/wiki/%E6%B6%BF%E9%83%A1" title="涿郡">涿郡</a>复称为<a href="/wiki/%E5%B9%BD%E5%B7%9E" class="mw-redirect" title="幽州">幽州</a>。贞观元年,幽州划归<a href="/wiki/%E6%B2%B3%E5%8C%97%E9%81%93" title="河北道">河北道</a>监察区。后北京成为<a href="/wiki/%E8%8C%83%E9%98%B3%E8%8A%82%E5%BA%A6%E4%BD%BF" class="mw-redirect" title="范阳节度使">范阳节度使</a>的驻地。<a href="/wiki/%E5%AE%89%E5%8F%B2%E4%B9%8B%E4%B9%B1" class="mw-redirect" title="安史之乱">安史之乱</a>期间,杂胡<a href="/wiki/%E5%AE%89%E7%A6%84%E5%B1%B1" class="mw-redirect" title="安禄山">安禄山</a>在<a href="/wiki/%E8%8C%83%E9%99%BD" class="mw-redirect" title="范陽">范陽</a>(今日<a href="/wiki/%E5%8C%97%E4%BA%AC" class="mw-redirect" title="北京">北京</a>、<a href="/wiki/%E4%BF%9D%E5%AE%9A" class="mw-redirect" title="保定">保定</a>附近)称<a href="/wiki/%E7%9A%87%E5%B8%9D" title="皇帝">帝</a>,建国号为“<a href="/wiki/%E5%A4%A7%E7%87%95" class="mw-redirect" title="大燕">大燕</a>”。唐朝平乱后,复置幽州,归<a href="/wiki/%E5%8D%A2%E9%BE%99%E8%8A%82%E5%BA%A6%E4%BD%BF" class="mw-redirect" title="卢龙节度使">卢龙节度使</a>节制<span id="noteTag-cite_ref-sup"><sup id="cite_ref-16" class="reference"><a href="#cite_note-16">[註 2]</a></sup></span>。<a href="/wiki/%E4%BA%94%E4%BB%A3" class="mw-redirect" title="五代">五代</a>初期,军阀<a href="/wiki/%E5%88%98%E4%BB%81%E6%81%AD" class="mw-redirect" title="刘仁恭">刘仁恭</a>割据此地,后其子<a href="/wiki/%E5%88%98%E5%AE%88%E5%85%89" class="mw-redirect" title="刘守光">刘守光</a>称燕王,被<a href="/wiki/%E5%90%8E%E5%94%90" title="后唐">后唐</a>消灭。<a href="/wiki/%E5%90%8E%E6%99%8B" title="后晋">后晋</a>的建立者<a href="/wiki/%E6%B2%99%E9%99%80%E4%BA%BA" class="mw-redirect" title="沙陀人">沙陀人</a><a href="/wiki/%E7%9F%B3%E6%95%AC%E7%91%AD" title="石敬瑭">石敬瑭</a>为了打败后唐,投降<a href="/wiki/%E5%A5%91%E4%B8%B9%E4%BA%BA" title="契丹人">契丹人</a>,将<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">燕云十六州</a>在后晋天福元年(936年)送给<a href="/wiki/%E5%A5%91%E4%B8%B9" class="mw-redirect" title="契丹">契丹</a>,并向契丹称自己為<a href="/wiki/%E5%85%92%E7%9A%87%E5%B8%9D" class="mw-redirect" title="兒皇帝">儿皇帝</a>。石敬瑭割让包括今北京在内的<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">燕云十六州</a>为辽国或<a href="/wiki/%E9%87%91%E5%9B%BD" class="mw-redirect" title="金国">金国</a>后来对<a href="/wiki/%E5%90%8E%E6%B1%89" class="mw-redirect" title="后汉">后汉</a>、<a href="/wiki/%E5%90%8E%E5%91%A8" title="后周">后周</a>、<a href="/wiki/%E5%AE%8B%E6%9C%9D" title="宋朝">宋朝</a>威胁打开了门户。
</p><p><a href="/wiki/%E5%8C%97%E5%AE%8B" title="北宋">北宋</a>初年,<a href="/wiki/%E5%AE%8B%E5%A4%AA%E5%AE%97" title="宋太宗">宋太宗</a>在<a href="/wiki/%E9%AB%98%E6%A2%81%E6%B2%B3" title="高梁河">高梁河</a>(今北京市<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">海淀区</a>)与<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">辽</a>战斗,意图收复<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">燕云十六州</a>未果。<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">辽朝</a>于<a href="/wiki/%E4%BC%9A%E5%90%8C_(%E5%B9%B4%E5%8F%B7)" title="会同 (年号)">会同元年</a>起在北京地区建立了陪都,号<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B9%BD%E9%83%BD%E5%BA%9C" class="mw-redirect" title="南京幽都府">南京幽都府</a>;<a href="/wiki/%E9%96%8B%E6%B3%B0_(%E9%81%BC)" title="開泰 (遼)">开泰元年</a>改号<a href="/wiki/%E6%9E%90%E6%B4%A5%E5%BA%9C" title="析津府">析津府</a>。北宋末年,宋联金灭辽后收复<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">燕云十六州</a>,并设置<a href="/wiki/%E7%87%95%E5%B1%B1%E5%BA%9C%E8%B7%AF" title="燕山府路">燕山府路</a>和<a href="/wiki/%E9%9B%B2%E4%B8%AD%E5%BA%9C%E8%B7%AF" class="mw-redirect" title="雲中府路">云中府路</a>,北京属于燕山府路。<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">金朝</a>以<a href="/wiki/%E5%BC%B5%E8%A6%BA" title="張覺">张觉</a>事件为借口大举攻宋,再次出兵<a href="/wiki/%E7%87%95%E5%B1%B1%E5%BA%9C" title="燕山府">燕山府</a>。<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">金朝</a><a href="/wiki/%E8%B4%9E%E5%85%83_(%E9%87%91%E6%9C%9D)" title="贞元 (金朝)">贞元</a>元年(1153年),<a href="/wiki/%E5%AE%8C%E9%A2%9C%E4%BA%AE" class="mw-redirect" title="完颜亮">完颜亮</a>正式迁都于北京,改燕京为圣都,不久又称<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">中都大兴府</a>,这是北京历史上第一次成为中国的首都,至今已有八百余年建都史。<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">金中都</a>的建成使北京成为当时世界上最繁华的商业大都市,人口超过一百万,城内居住着众多部族,东西方众多文化在这里交流融合,北京从此成为国际性都市。完颜亮在中都之东开通了潞河,潞城因此改名<a href="/wiki/%E9%80%9A%E5%B7%9E_(%E5%8C%97%E4%BA%AC)" title="通州 (北京)">通州</a>,西面则建成<a href="/wiki/%E5%8D%A2%E6%B2%9F%E6%A1%A5" title="卢沟桥">卢沟桥</a><span id="noteTag-cite_ref-sup"><sup id="cite_ref-17" class="reference"><a href="#cite_note-17">[註 3]</a></sup></span>,使西南陆路各种货物可以直接进入中都。金代还首创了漕运形式,即从水路运送粮米到京城。
</p><p>蒙古帝国<a href="/wiki/%E6%88%90%E5%90%89%E6%80%9D%E6%B1%97" title="成吉思汗">成吉思汗</a>麾下大将<a href="/wiki/%E6%9C%A8%E5%8D%8E%E9%BB%8E" title="木华黎">木华黎</a>从1214年农历五月开始到1215年农历五月攻下金中都,对中都整整围困了将近一年之久。城破后展开了为期一个月的大屠杀,超过百万人殒命,又纵火焚城,几乎彻底毁灭了这座城市<sup id="cite_ref-18" class="reference"><a href="#cite_note-18">[15]</a></sup>。金朝著名大词人<a href="/wiki/%E5%85%83%E5%A5%BD%E9%97%AE" title="元好问">元好问</a>的胞兄元好古也在屠城中丧命。<a href="/wiki/%E5%BF%BD%E5%BF%85%E7%83%88" title="忽必烈">忽必烈</a>1260年即位後,決定以漢地作為統治基礎,將燕京定為首都,至元元年(1264年)改稱中都路大兴府。至元九年(1272年),中都大兴府正式改名为<a href="/wiki/%E5%85%83%E5%A4%A7%E9%83%BD" title="元大都">大都路</a><span id="noteTag-cite_ref-sup"><sup id="cite_ref-19" class="reference"><a href="#cite_note-19">[註 4]</a></sup></span>。
</p><p><a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">明朝</a>初年,<a href="/wiki/%E6%9C%B1%E5%85%83%E7%92%8B" title="朱元璋">朱元璋</a>以<a href="/wiki/%E9%87%91%E9%99%B5" class="mw-redirect" title="金陵">金陵</a><a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">应天府</a>(今<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京市</a>)为京师,大都路于洪武元年八月被明軍收復,改称为北平府,同年十月应军事需要划归<a href="/wiki/%E5%B1%B1%E4%B8%9C" class="mw-redirect" title="山东">山东</a><a href="/wiki/%E8%A1%8C%E7%9C%81" class="mw-redirect" title="行省">行省</a>。洪武二年三月,改为北平<a href="/wiki/%E6%89%BF%E5%AE%A3%E5%B8%83%E6%94%BF%E4%BD%BF%E5%8F%B8" title="承宣布政使司">承宣布政使司</a>驻地。燕王<a href="/wiki/%E6%9C%B1%E6%A3%A3" class="mw-redirect" title="朱棣">朱棣</a>经<a href="/wiki/%E9%9D%96%E9%9A%BE" class="mw-redirect" title="靖难">靖难</a>之变夺得皇位后,于<a href="/wiki/%E6%B0%B8%E4%B9%90_(%E6%98%8E%E6%9C%9D)" title="永乐 (明朝)">永乐</a>元年(1402年)升<a href="/wiki/%E7%87%95%E4%BA%AC" class="mw-redirect" title="燕京">燕京</a>北平为北京,暫稱“<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">行在</a>”(<a href="/wiki/%E5%A4%A9%E5%AD%90" title="天子">天子</a>行銮驻跸的所在,就称“行在”)且在北伐時常驻于此,现在的北京也从此得名。朱棣行在北京后,一改元態,北京城秩序井然,繁榮安樂。永乐十九年正月,明成祖<a href="/wiki/%E6%9C%B1%E6%A3%A3" class="mw-redirect" title="朱棣">朱棣</a>正式<a href="/wiki/%E6%B0%B8%E6%A8%82%E9%81%B7%E9%83%BD" class="mw-redirect" title="永樂遷都">移鼎燕京</a>,以燕京为<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">京师</a>,稱為「北京」。金陵应天府则作为<a href="/wiki/%E7%95%99%E9%83%BD" class="mw-redirect" title="留都">留都</a>,称<a href="/wiki/%E5%8D%97%E4%BA%AC" class="mw-redirect" title="南京">南京</a>。<a href="/wiki/%E6%98%8E%E4%BB%81%E5%AE%97" title="明仁宗">明仁宗</a>及<a href="/wiki/%E6%98%8E%E5%AE%A3%E5%AE%97" title="明宣宗">明宣宗</a>的时期,因<a href="/wiki/%E7%9A%87%E5%B8%9D" title="皇帝">皇帝</a>個人的喜好因素,北京之<a href="/wiki/%E4%BA%AC%E5%B8%88" class="mw-redirect mw-disambig" title="京师">京师</a>地位一度降為<a href="/wiki/%E5%90%9B%E4%B8%BB" title="君主">君主</a>暫幸之<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">行在</a>,复稱金陵应天府為南京,<a href="/wiki/%E6%98%8E%E8%8B%B1%E5%AE%97" title="明英宗">明英宗</a>親政後,<a href="/wiki/%E6%AD%A3%E7%BB%9F_(%E5%B9%B4%E5%8F%B7)" title="正统 (年号)">正統</a>七年(1441年)時才恢復燕京京师的地位。
</p><p>1626年5月30日,北京西南隅的工部王恭厂火药库发生<a href="/wiki/%E7%8E%8B%E6%81%AD%E5%BB%A0%E5%A4%A7%E7%88%86%E7%82%B8" title="王恭廠大爆炸">王恭厰大爆炸</a>,死伤2万多人<sup id="cite_ref-20" class="reference"><a href="#cite_note-20">[16]</a></sup>,原因不明,朝野震惊,中外骇然,<a href="/wiki/%E6%98%8E%E7%86%B9%E5%AE%97" title="明熹宗">明熹宗</a>下了一道<a href="/wiki/%E7%BD%AA%E5%B7%B1%E8%AF%8F" title="罪己诏">罪己诏</a>,表示要痛加省醒,告诫大小臣工“务要竭虑洗心办事,痛加反省”,并下旨发府库万两黄金赈灾。1643年,北京内爆发<a href="/wiki/%E6%98%8E%E6%9C%AB%E5%A4%A7%E9%BC%A0%E7%96%AB" title="明末大鼠疫">明末大鼠疫</a>重大疫情、造成20多万人死亡,被认为是明朝灭亡的重要因素之一<sup id="cite_ref-:0_21-0" class="reference"><a href="#cite_note-:0-21">[17]</a></sup><sup id="cite_ref-:1_22-0" class="reference"><a href="#cite_note-:1-22">[18]</a></sup><sup id="cite_ref-:2_23-0" class="reference"><a href="#cite_note-:2-23">[19]</a></sup><sup id="cite_ref-:3_24-0" class="reference"><a href="#cite_note-:3-24">[20]</a></sup>。1644年4月25日,<a href="/wiki/%E6%9D%8E%E8%87%AA%E6%88%90" title="李自成">李自成</a>攻陷北京,<a href="/wiki/%E5%B4%87%E7%A5%AF%E5%B8%9D" class="mw-redirect" title="崇祯帝">崇祯帝</a>在<a href="/wiki/%E7%85%A4%E5%B1%B1" class="mw-redirect" title="煤山">煤山</a><a href="/wiki/%E8%87%AA%E7%B8%8A" class="mw-redirect" title="自縊">自縊</a>,<a href="/wiki/%E7%94%B2%E7%94%B3%E4%B9%8B%E8%AE%8A" title="甲申之變">明朝滅亡</a>。清朝<a href="/wiki/%E9%A0%86%E6%B2%BB%E5%B8%9D" class="mw-redirect" title="順治帝">順治帝</a><a href="/wiki/%E6%98%8E%E6%B8%85%E6%88%98%E4%BA%89" title="明清战争">入关</a>后即迁都北京,亦称为京师<a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a>,属<a href="/wiki/%E7%9B%B4%E9%9A%B6%E7%9C%81" title="直隶省">直隶省</a>。清廷在北京实行旗民分居政策,即满汉蒙<a href="/wiki/%E5%85%AB%E6%97%97" title="八旗">八旗</a>居住内城,非旗籍<a href="/wiki/%E6%B1%89%E4%BA%BA" class="mw-redirect" title="汉人">汉人</a>和<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">回民</a>居住外城。<a href="/wiki/%E5%85%AB%E6%97%97%E5%88%B6%E5%BA%A6" class="mw-redirect" title="八旗制度">旗人</a>事务由<a href="/wiki/%E4%B9%9D%E9%97%A8%E6%8F%90%E7%9D%A3" class="mw-redirect" title="九门提督">九門提督</a>管理,而<a href="/wiki/%E6%B1%89%E6%97%8F" title="汉族">汉族</a>、<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">回族</a>事务则交给<a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a><a href="/wiki/%E8%A1%99%E9%97%A8" class="mw-redirect" title="衙门">衙门</a>管理。
</p>
<h3><span id=".E8.BF.91.E4.BB.A3"></span><span class="mw-headline" id="近代">近代</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=5" title="编辑章节:近代">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>1853年8月28日,<a href="/wiki/%E5%A4%AA%E5%B9%B3%E5%86%9B" class="mw-redirect" title="太平军">太平军</a>攻克<a href="/wiki/%E4%B8%B4%E6%B4%BA%E5%85%B3%E9%95%87" title="临洺关镇">临洺关镇</a>,北京大批人口逃离,全城戒严,人心惶惶之际,物价飞腾,米珠薪桂,一片混乱。
</p><p>1860年9月21日,<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E9%B8%A6%E7%89%87%E6%88%98%E4%BA%89" title="第二次鸦片战争">英法联军</a>在<a href="/wiki/%E5%85%AB%E9%87%8C%E6%A9%8B%E4%B9%8B%E6%88%B0" title="八里橋之戰">八里桥之战</a>中打败清军,随后攻破北京城,放火烧毁<a href="/wiki/%E5%9C%93%E6%98%8E%E5%9C%92" class="mw-redirect" title="圓明園">圆明园</a>,<a href="/wiki/%E5%92%B8%E4%B8%B0%E5%B8%9D" title="咸丰帝">咸丰帝</a>逃至<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">承德</a>。10月至11月,清政府与英法俄在<a href="/wiki/%E7%A4%BC%E9%83%A8" title="礼部">礼部</a>衙门签订《<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%9D%A1%E7%BA%A6" title="北京条约">北京条约</a>》,外国<a href="/wiki/%E4%BD%BF%E8%8A%82" title="使节">使节</a>和<a href="/wiki/%E5%9F%BA%E7%9D%A3%E6%95%99" title="基督教">基督教</a><a href="/wiki/%E4%BC%A0%E6%95%99%E5%A3%AB" title="传教士">传教士</a>得到特许允进北京,在城内各处兴建<a href="/wiki/%E6%95%99%E5%A0%82" title="教堂">教堂</a>,使馆则集中在<a href="/wiki/%E4%B8%9C%E4%BA%A4%E6%B0%91%E5%B7%B7" title="东交民巷">东交民巷</a><sup id="cite_ref-1860年北京条约_25-0" class="reference"><a href="#cite_note-1860年北京条约-25">[21]</a></sup>。1888年,北京第一条<a href="/wiki/%E9%93%81%E8%B7%AF" class="mw-redirect" title="铁路">铁路</a><a href="/wiki/%E8%A5%BF%E8%8B%91%E9%93%81%E8%B7%AF" title="西苑铁路">西苑铁路</a>在<a href="/wiki/%E4%B8%AD%E5%8D%97%E6%B5%B7" title="中南海">中南海</a>建成,但该铁路并非营业性质<sup id="cite_ref-bj-general_26-0" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:73</sup>,已于1925年被拆除,此后北京的第一条营业铁路为1897年通车的<a href="/wiki/%E6%B4%A5%E8%8A%A6%E9%93%81%E8%B7%AF" title="津芦铁路">津芦铁路</a><sup id="cite_ref-bj-general_26-1" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:72</sup>。
</p><p>1900年6月,<a href="/wiki/%E4%B9%89%E5%92%8C%E5%9B%A2%E8%BF%90%E5%8A%A8" title="义和团运动">义和团</a>进入北京,烧毁城内教堂,并围攻各国使馆。8月,<a href="/wiki/%E5%85%AB%E5%9C%8B%E8%81%AF%E8%BB%8D" title="八國聯軍">八国联军</a>攻占北京,解救被义和团围攻的各国公使。1901年8月,八国联军从北京撤军。9月7日,清政府同西方签订《<a href="/wiki/%E8%BE%9B%E4%B8%91%E6%9D%A1%E7%BA%A6" title="辛丑条约">辛丑条约</a>》。同年,西便门和东便门城墙上各开一铁路豁口,成为对北京城墙最早的改造<sup id="cite_ref-bj-general_26-2" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:72</sup>。1902年1月,<a href="/wiki/%E6%85%88%E7%A6%A7%E5%A4%AA%E5%90%8E" title="慈禧太后">慈禧太后</a>和<a href="/wiki/%E5%85%89%E7%BB%AA%E5%B8%9D" title="光绪帝">光绪帝</a>回到北京下<a href="/wiki/%E7%BD%AA%E5%B7%B1%E8%AF%8F" title="罪己诏">罪己诏</a>。1909年,连接北京至<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">张家口</a>的<a href="/wiki/%E4%BA%AC%E5%BC%A0%E9%93%81%E8%B7%AF" title="京张铁路">京张铁路</a>在<a href="/wiki/%E8%A9%B9%E5%A4%A9%E4%BD%91" title="詹天佑">詹天佑</a>的主持下建成通车<sup id="cite_ref-bj-general_26-3" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:73</sup>。1911年3月30日,<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6" title="清华大学">清华大学</a>成立。
</p>
<link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r61200722/mw-parser-output/.tmulti"/><div class="thumb tmulti tleft"><div class="thumbinner" style="width:272px;max-width:272px"><div class="trow"><div class="tsingle" style="width:164px;max-width:164px"><div class="thumbimage" style="height:128px;overflow:hidden"><a href="/wiki/File:ROC_Div_City_Peiping_2.svg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/13/ROC_Div_City_Peiping_2.svg/162px-ROC_Div_City_Peiping_2.svg.png" decoding="async" width="162" height="128" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/13/ROC_Div_City_Peiping_2.svg/243px-ROC_Div_City_Peiping_2.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/13/ROC_Div_City_Peiping_2.svg/324px-ROC_Div_City_Peiping_2.svg.png 2x" data-file-width="677" data-file-height="535" /></a></div><div class="thumbcaption text-align-center"><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a>北平市</div></div><div class="tsingle" style="width:104px;max-width:104px"><div class="thumbimage" style="height:128px;overflow:hidden"><a href="/wiki/File:Beijing_1948_JP.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/102px-Beijing_1948_JP.jpg" decoding="async" width="102" height="129" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/153px-Beijing_1948_JP.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/204px-Beijing_1948_JP.jpg 2x" data-file-width="6293" data-file-height="7933" /></a></div><div class="thumbcaption text-align-center">1940年代的北京城區</div></div></div></div></div>
<p>1912年1月1日,<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a>在<a href="/wiki/%E5%8D%97%E4%BA%AC" class="mw-redirect" title="南京">南京</a>成立,同年3月迁都北京。民国伊始,北京仍依清制称<a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a>,至民国三年,改为<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">京兆地方</a>,直辖于<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C" title="北洋政府">北洋政府</a>。这一时期,北京新建了<a href="/wiki/%E6%9C%89%E8%BD%A8%E7%94%B5%E8%BD%A6" class="mw-redirect" title="有轨电车">有轨电车</a>系统和一批现代的文化教育机构,<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%9A%87%E5%9F%8E" title="北京皇城">北京皇城</a>的城墙也逐步被拆除,但内外城仅被局部改造<sup id="cite_ref-bj-general_26-4" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:74</sup>。1919年北京因<a href="/wiki/%E5%B1%B1%E4%B8%9C%E9%97%AE%E9%A2%98" class="mw-redirect" title="山东问题">山东问题</a>爆发<a href="/wiki/%E4%BA%94%E5%9B%9B%E8%BF%90%E5%8A%A8" title="五四运动">五四运动</a>,学生放火燒了<a href="/wiki/%E6%9B%B9%E6%B1%9D%E9%9C%96" title="曹汝霖">曹汝霖</a>的<a href="/wiki/%E8%B5%B5%E5%AE%B6%E6%A5%BC" title="赵家楼">住宅</a><sup id="cite_ref-27" class="reference"><a href="#cite_note-27">[23]</a></sup>。1920年5月7日,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E8%8B%91%E6%9C%BA%E5%9C%BA" title="北京南苑机场">北京南苑机场</a>开通北京首条民用航空线路<sup id="cite_ref-bj-general_26-5" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:74</sup>。1928年<a href="/wiki/%E5%8C%97%E4%BC%90%E6%88%98%E4%BA%89" class="mw-redirect" title="北伐战争">北伐战争</a>后,<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E9%A6%96%E9%83%BD" title="中華民國首都">中華民國首都</a>迁回南京,京兆地方改名为<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">北平特别市</a>。1930年6月,北平降格为<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="河北省 (中華民國)">河北省</a>省辖市,同年12月复升为<a href="/wiki/%E9%99%A2%E8%BE%96%E5%B8%82" class="mw-redirect" title="院辖市">院辖市</a>。这一时期,北京尽管不具<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">首都</a>的地位,但在<a href="/wiki/%E6%95%99%E8%82%B2" title="教育">教育</a>方面仍有关键的优势,被国际人士称为“中国的<a href="/wiki/%E6%B3%A2%E5%A3%AB%E9%A1%BF" title="波士顿">波士顿</a>”。1937年<a href="/wiki/%E4%B8%83%C2%B7%E4%B8%83%E4%BA%8B%E5%8F%98" class="mw-redirect" title="七·七事变">七·七事变</a>后,北平被<a href="/wiki/%E6%97%A5%E8%BB%8D" class="mw-redirect" title="日軍">日軍</a>占领,将北平改名为北京<sup id="cite_ref-28" class="reference"><a href="#cite_note-28">[24]</a></sup><sup class="reference" style="white-space:nowrap;">:40</sup>。1945年<a href="/wiki/%E5%A4%A7%E6%97%A5%E6%9C%AC%E5%B8%9D%E5%9C%8B" class="mw-redirect" title="大日本帝國">日本</a>宣布向<a href="/wiki/%E5%90%8C%E7%9B%9F%E5%9C%8B_(%E7%AC%AC%E4%BA%8C%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%B0)" title="同盟國 (第二次世界大戰)">同盟国</a>投降,<a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%8A%97%E6%97%A5%E6%88%98%E4%BA%89" title="中国抗日战争">中国抗日战争</a>结束。同年8月21日第十一战区<a href="/wiki/%E5%AD%99%E8%BF%9E%E4%BB%B2" class="mw-redirect" title="孙连仲">孙连仲</a>部接收北京,并更名北平。
</p>
<div class="thumb tleft"><div class="thumbinner" style="width:152px;"><a href="/wiki/File:Jinianbei.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/30/Jinianbei.jpg/150px-Jinianbei.jpg" decoding="async" width="150" height="225" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/30/Jinianbei.jpg/225px-Jinianbei.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/30/Jinianbei.jpg/300px-Jinianbei.jpg 2x" data-file-width="800" data-file-height="1200" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Jinianbei.jpg" class="internal" title="放大"></a></div><a href="/wiki/%E4%BA%BA%E6%B0%91%E8%8B%B1%E9%9B%84%E7%BA%AA%E5%BF%B5%E7%A2%91" title="人民英雄纪念碑">人民英雄纪念碑</a>,为纪念中国近现代史上的牺牲的人民英雄而建。</div></div></div>
<p>1949年1月31日,<a href="/wiki/%E5%82%85%E4%BD%9C%E4%B9%89" title="傅作义">傅作义</a>与<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A" title="中国共产党">中国共产党</a>达成和平协议,率<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E5%9C%8B%E8%BB%8D" title="中華民國國軍">中華民國國軍</a>25万人改投中共,<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%92%8C%E5%B9%B3%E8%A7%A3%E6%94%BE" title="北平和平解放">北平和平解放</a><sup id="cite_ref-29" class="reference"><a href="#cite_note-29">[25]</a></sup>。同年9月27日<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE" title="中国人民政治协商会议">中国人民政治协商会议</a>第一届全体会议通过《<a href="/wiki/%E5%85%B3%E4%BA%8E%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E9%83%BD%E3%80%81%E7%BA%AA%E5%B9%B4%E3%80%81%E5%9B%BD%E6%AD%8C%E3%80%81%E5%9B%BD%E6%97%97%E7%9A%84%E5%86%B3%E8%AE%AE" title="关于中华人民共和国国都、纪年、国歌、国旗的决议">决议</a>》,将<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a>的国都定于北平,復名为北京。1949年10月1日,<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C_(1949%E2%80%931954)" class="mw-redirect" title="中华人民共和国中央人民政府 (1949–1954)">中央人民政府</a>在北京<a href="/wiki/%E5%BC%80%E5%9B%BD%E5%A4%A7%E5%85%B8" class="mw-redirect" title="开国大典">宣告成立</a>。此后,天安门广场上举行过多次<a href="/wiki/%E9%98%85%E5%85%B5" title="阅兵">阅兵</a><sup id="cite_ref-30" class="reference"><a href="#cite_note-30">[26]</a></sup>。1949年11月21日,北京市封闭了全市的所有妓院<sup id="cite_ref-bj-general_26-6" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:83</sup>。1950年2月,建筑学家<a href="/wiki/%E6%A2%81%E6%80%9D%E6%88%90" title="梁思成">梁思成</a>和<a href="/wiki/%E9%99%88%E5%8D%A0%E7%A5%A5" title="陈占祥">陈占祥</a>联手提出《<a href="/wiki/%E6%A2%81%E9%99%88%E6%96%B9%E6%A1%88" title="梁陈方案">关于中央人民政府行政中心区位置的建议</a>》,建议在<a href="/wiki/%E5%85%AC%E4%B8%BB%E5%9D%9F" title="公主坟">公主坟</a>以东、<a href="/wiki/%E6%9C%88%E5%9D%9B" title="月坛">月坛</a>以西的适中地点(即<a href="/wiki/%E4%B8%89%E9%87%8C%E6%B2%B3_(%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A5%BF%E5%9F%8E%E5%8C%BA)" title="三里河 (北京市西城区)">三里河</a>一带)建设首都行政中心区域<sup id="cite_ref-31" class="reference"><a href="#cite_note-31">[27]</a></sup>,但最终北京市采纳的是朱兆雪、赵冬日“以天安门为中心逐步扩建、改建”的意见,导致城墙于1953年至60年代被逐步拆除<sup id="cite_ref-32" class="reference"><a href="#cite_note-32">[28]</a></sup>。
</p>
<h3><span id=".E6.96.87.E5.8C.96.E5.A4.A7.E9.9D.A9.E5.91.BD.E6.9C.9F.E9.97.B4"></span><span class="mw-headline" id="文化大革命期间">文化大革命期间</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=6" title="编辑章节:文化大革命期间">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E7%BA%A2%E5%85%AB%E6%9C%88" title="红八月">红八月</a>、<a href="/wiki/%E5%A4%A7%E5%85%B4%E4%BA%8B%E4%BB%B6" title="大兴事件">大兴事件</a>、<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6%E7%99%BE%E6%97%A5%E5%A4%A7%E6%AD%A6%E6%96%97" title="清华大学百日大武斗">清华大学百日大武斗</a>和<a href="/wiki/%E6%96%87%E5%8C%96%E5%A4%A7%E9%9D%A9%E5%91%BD" title="文化大革命">文化大革命</a></div>
<p>1966年8月18日,<a href="/wiki/%E6%AF%9B%E6%B3%BD%E4%B8%9C" title="毛泽东">毛泽东</a>在<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%9F%8E%E6%A5%BC" class="mw-redirect" title="天安门城楼">天安门城楼</a>上接见了红卫兵代表<a href="/wiki/%E5%AE%8B%E5%BD%AC%E5%BD%AC" title="宋彬彬">宋彬彬</a>,红卫兵受到鼓舞,“<a href="/w/index.php?title=%E9%A6%96%E9%83%BD%E7%BA%A2%E5%8D%AB%E5%85%B5%E7%BA%A0%E5%AF%9F%E9%98%9F%E8%A5%BF%E5%9F%8E%E5%88%86%E9%98%9F&action=edit&redlink=1" class="new" title="首都红卫兵纠察队西城分队(页面不存在)">西纠</a>”等红卫兵组织相继成立,<a href="/wiki/%E7%BA%A2%E5%85%AB%E6%9C%88" title="红八月">北京的文革屠杀</a>逐渐展开<sup id="cite_ref-:0_21-1" class="reference"><a href="#cite_note-:0-21">[17]</a></sup><sup id="cite_ref-:12_33-0" class="reference"><a href="#cite_note-:12-33">[29]</a></sup><sup id="cite_ref-:15_34-0" class="reference"><a href="#cite_note-:15-34">[30]</a></sup><sup id="cite_ref-:14_35-0" class="reference"><a href="#cite_note-:14-35">[31]</a></sup><sup id="cite_ref-36" class="reference"><a href="#cite_note-36">[32]</a></sup><sup id="cite_ref-37" class="reference"><a href="#cite_note-37">[33]</a></sup><sup id="cite_ref-38" class="reference"><a href="#cite_note-38">[34]</a></sup>。据1980年官方数据,在1966年8-9月间,在北京市有1772人被<a href="/wiki/%E7%BA%A2%E5%8D%AB%E5%85%B5" title="红卫兵">红卫兵</a>打死,其中包括很多学校的老师和校长,另有至少33695户被抄家、85196个家庭被驱逐出北京<sup id="cite_ref-:0_21-2" class="reference"><a href="#cite_note-:0-21">[17]</a></sup><sup id="cite_ref-:15_34-1" class="reference"><a href="#cite_note-:15-34">[30]</a></sup><sup id="cite_ref-:31_39-0" class="reference"><a href="#cite_note-:31-39">[35]</a></sup><sup id="cite_ref-:17_40-0" class="reference"><a href="#cite_note-:17-40">[36]</a></sup><sup id="cite_ref-:2_23-1" class="reference"><a href="#cite_note-:2-23">[19]</a></sup><sup id="cite_ref-:7_41-0" class="reference"><a href="#cite_note-:7-41">[37]</a></sup>;此外,受到北京市区红卫兵杀戮的影响,北京<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8E%BF" class="mw-disambig" title="大兴县">大兴县</a>从8月27日至9月1日爆发了“<a href="/wiki/%E5%A4%A7%E5%85%B4%E4%BA%8B%E4%BB%B6" title="大兴事件">大兴事件</a>”,数天内先后有325人遭屠杀,最大的80岁,最小的才38天,有22户人家被杀绝<sup id="cite_ref-:1_22-1" class="reference"><a href="#cite_note-:1-22">[18]</a></sup><sup id="cite_ref-:20_42-0" class="reference"><a href="#cite_note-:20-42">[38]</a></sup><sup id="cite_ref-:21_43-0" class="reference"><a href="#cite_note-:21-43">[39]</a></sup>。亦有学者指出,1985年官方统计显示,北京屠杀实际死亡人数上万<sup id="cite_ref-:8_44-0" class="reference"><a href="#cite_note-:8-44">[40]</a></sup>。此后北京市仍有多起<a href="/wiki/%E6%AD%A6%E6%96%97" title="武斗">武斗</a>事件发生,如1968年的<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6%E7%99%BE%E6%97%A5%E5%A4%A7%E6%AD%A6%E6%96%97" title="清华大学百日大武斗">清华大学百日大武斗</a>,城市建设也处于极度混乱之中,城市规划更无法正常编制<sup id="cite_ref-bj-general_26-7" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:95</sup>。
</p><p>1969年10月1日,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E4%B8%80%E6%9C%9F%E5%B7%A5%E7%A8%8B" title="北京地铁一期工程">北京地铁一期工程</a>通车。1976年1月8日,国务院总理<a href="/wiki/%E5%91%A8%E6%81%A9%E6%9D%A5" title="周恩来">周恩来</a><a href="/wiki/%E5%91%A8%E6%81%A9%E6%9D%A5%E4%B9%8B%E6%AD%BB" title="周恩来之死">病逝于</a><a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E8%A7%A3%E6%94%BE%E5%86%9B%E7%AC%AC%E4%B8%89%E3%80%87%E4%BA%94%E5%8C%BB%E9%99%A2" title="中国人民解放军第三〇五医院">中国人民解放军第三〇五医院</a>,此后由于民众对<a href="/wiki/%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="四人帮">四人帮</a>的不满情绪,<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">四五运动</a>在北京爆发。9月9日,毛泽东在中南海<a href="/wiki/%E6%AF%9B%E6%B3%BD%E4%B8%9C%E4%B9%8B%E6%AD%BB" title="毛泽东之死">病逝</a>,一个月后发生<a href="/wiki/%E7%B2%89%E7%A2%8E%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="粉碎四人帮">怀仁堂政变</a>,“四人帮”被捕。
</p>
<h3><span id=".E7.8E.B0.E5.BD.93.E4.BB.A3"></span><span class="mw-headline" id="现当代">现当代</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=7" title="编辑章节:现当代">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>文化大革命结束后,北京市的<a href="/wiki/%E6%94%B9%E9%9D%A9%E5%BC%80%E6%94%BE" title="改革开放">改革开放</a>首先从京郊农村改革开始,1984年北京市农村种植业已有97%的生产队实现<a href="/wiki/%E5%AE%B6%E5%BA%AD%E8%81%94%E4%BA%A7%E6%89%BF%E5%8C%85%E8%B4%A3%E4%BB%BB%E5%88%B6" title="家庭联产承包责任制">家庭联产承包责任制</a><sup id="cite_ref-bj-general_26-8" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:115</sup>。
</p><p>1982年7月22日,北京市编制《北京城市建设总体规划方案》,该方案明确北京市的性质为“全国的政治中心和文化中心”,1983年获批<sup id="cite_ref-bj-general_26-9" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:133</sup>,此后北京市的城市建设迅速发展,一改此前“重生产、轻生活”的思维。
</p><p>1987年,北京市提出“打通两厢,缓解中央”,开始大规模建设城市道路<sup id="cite_ref-bj-general_26-10" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:141</sup>。次年,北京市新技术产业开发试验区在<a href="/wiki/%E4%B8%AD%E5%85%B3%E6%9D%91" title="中关村">中关村</a>成立<sup id="cite_ref-bj-general_26-11" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:144</sup>。
</p><p>1989年爆发<a href="/wiki/%E5%85%AD%E5%9B%9B%E5%A4%A9%E5%AE%89%E9%97%A8%E4%BA%8B%E4%BB%B6" class="mw-redirect" title="六四天安门事件">六四天安门事件</a>,学生自该年4月<a href="/wiki/%E8%83%A1%E8%80%80%E9%82%A6%E4%B9%8B%E6%AD%BB" title="胡耀邦之死">胡耀邦逝世</a>后占领<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%B9%BF%E5%9C%BA" title="天安门广场">天安门广场</a>长达51天,6月4日被执政党中国共产党派遣军队出动坦克等作战武器,武力镇压<sup id="cite_ref-趙紫陽_45-0" class="reference"><a href="#cite_note-趙紫陽-45">[41]</a></sup>,此事件造成多人伤亡,从1989年5月20日起在北京市部分地区实行的戒严直至1990年1月11日才正式解除。
</p><p>1990年,北京市成功举办<a href="/wiki/1990%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1990年亚洲运动会">第11届</a><a href="/wiki/%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲运动会">亚洲运动会</a>,1991年开始<a href="/wiki/2000%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E7%94%B3%E5%8A%9E%E8%BF%87%E7%A8%8B" title="2000年夏季奥林匹克运动会申办过程">着手申办</a><a href="/wiki/2000%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2000年夏季奥林匹克运动会">2000年夏季奥林匹克运动会</a><sup id="cite_ref-bj-general_26-12" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:547</sup>,但1993年9月以两票之差不敌悉尼。1992年7月10日,当时处于规划阶段的亦庄工业区更名为<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%BB%8F%E6%B5%8E%E6%8A%80%E6%9C%AF%E5%BC%80%E5%8F%91%E5%8C%BA" title="北京经济技术开发区">北京经济技术开发区</a><sup id="cite_ref-bj-general_26-13" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:552</sup>。
</p><p>1993年10月,《北京城市总体规划(1991-2010年)》获国务院批准<sup id="cite_ref-bj-general_26-14" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:136</sup>。
</p><p>1994年9月,北京市举办了<a href="/w/index.php?title=1994%E5%B9%B4%E8%BF%9C%E4%B8%9C%E5%8F%8A%E5%8D%97%E5%A4%AA%E5%B9%B3%E6%B4%8B%E6%AE%8B%E7%96%BE%E4%BA%BA%E8%BF%90%E5%8A%A8%E4%BC%9A&action=edit&redlink=1" class="new" title="1994年远东及南太平洋残疾人运动会(页面不存在)">第6届</a><a href="/wiki/%E8%BF%9C%E4%B8%9C%E5%8F%8A%E5%8D%97%E5%A4%AA%E5%B9%B3%E6%B4%8B%E6%AE%8B%E7%96%BE%E4%BA%BA%E8%BF%90%E5%8A%A8%E4%BC%9A" title="远东及南太平洋残疾人运动会">远东及南太平洋残疾人运动会</a>。
</p><p>1995年,北京又承办了联合国<a href="/wiki/%E7%AC%AC%E5%9B%9B%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A6%87%E5%A5%B3%E5%A4%A7%E4%BC%9A" title="第四次世界妇女大会">第四次世界妇女大会</a>,通过《北京宣言》和《行动纲领》,同年北京市开始实行每周五天工作制<sup id="cite_ref-bj-general_26-15" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:566</sup>。
</p><p>1996年1月21日,<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">北京西站</a>开通运营,北京市电话号码同年5月8日由七位升至八位<sup id="cite_ref-bj-general_26-16" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:573</sup>。
</p><p>1997年,北京市先后开通首条<a href="/wiki/%E5%85%AC%E8%BB%8A%E5%B0%88%E7%94%A8%E9%81%93" title="公車專用道">公交专用车道</a><sup id="cite_ref-bj-general_26-17" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:579</sup>和<a href="/wiki/%E7%A9%BA%E8%AA%BF%E5%B7%B4%E5%A3%AB" title="空調巴士">空調巴士</a>线路<sup id="cite_ref-bj-general_26-18" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:580</sup>。
</p><p>1998年11月25日,北京市正式启动<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季奥林匹克运动会">2008年夏季奥林匹克运动会</a>的<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E7%94%B3%E5%8A%9E%E8%BF%87%E7%A8%8B" title="2008年夏季奥林匹克运动会申办过程">申办工作</a><sup id="cite_ref-46" class="reference"><a href="#cite_note-46">[42]</a></sup>。
</p><p>1999年6月,建筑界名家<a href="/wiki/%E8%B4%9D%E8%81%BF%E9%93%AD" title="贝聿铭">贝聿铭</a>与<a href="/wiki/%E5%90%B3%E8%89%AF%E9%8F%9E" title="吳良鏞">吳良鏞</a>、<a href="/wiki/%E5%91%A8%E5%B9%B2%E5%B3%99" title="周干峙">周干峙</a>、<a href="/wiki/%E5%BC%A0%E5%BC%80%E6%B5%8E" title="张开济">张开济</a>、<a href="/wiki/%E5%8D%8E%E6%8F%BD%E6%B4%AA" title="华揽洪">华揽洪</a>、<a href="/wiki/%E9%83%91%E5%AD%9D%E7%87%AE" title="郑孝燮">郑孝燮</a>、<a href="/wiki/%E7%BD%97%E5%93%B2%E6%96%87" title="罗哲文">罗哲文</a>、<a href="/wiki/%E9%98%AE%E4%BB%AA%E4%B8%89" title="阮仪三">阮仪三</a>联名向<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">北京市政府</a>提交意见书《在急速发展中要审慎地保护北京历史文化名城》,指出应该顺应历史文化名城保护与发展的客观规律,对北京旧城进行积极的、慎重的保护与改善,而不是“加速改造”,建议编订具有法律效力的完整的《北京历史文化名城保护规划》<sup id="cite_ref-47" class="reference"><a href="#cite_note-47">[43]</a></sup>,同年中关村科技园区管理委员会正式成立,<a href="/wiki/%E5%B9%B3%E5%AE%89%E5%A4%A7%E8%A1%97" title="平安大街">平安大街</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E5%A4%8D%E5%85%AB%E7%BA%BF" class="mw-redirect" title="北京地铁复八线">北京地铁复八线</a>等重大基础设施也正式完工<sup id="cite_ref-bj-general_26-19" class="reference"><a href="#cite_note-bj-general-26">[22]</a></sup><sup class="reference" style="white-space:nowrap;">:592</sup>。
</p><p>2001年,北京市赢得<a href="/wiki/%E7%AC%AC29%E5%B1%8A%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" class="mw-redirect" title="第29届奥林匹克运动会">第29届奥林匹克运动会</a>主办权,同年举办了<a href="/wiki/2001%E5%B9%B4%E5%A4%8F%E5%AD%A3%E4%B8%96%E7%95%8C%E5%A4%A7%E5%AD%B8%E9%81%8B%E5%8B%95%E6%9C%83" title="2001年夏季世界大學運動會">第21届世界大学生运动会</a>,第29届奥运会和<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E6%AE%8B%E7%96%BE%E4%BA%BA%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季残疾人奥林匹克运动会">第13届残奥会</a>则分别于2008年8月和9月成功举办。
</p><p>2012年7月21日,北京发生<a href="/wiki/2012%E5%B9%B4%E5%8C%97%E4%BA%AC%E7%89%B9%E5%A4%A7%E6%9A%B4%E9%9B%A8" title="2012年北京特大暴雨">特大暴雨</a>,79人死亡<sup id="cite_ref-灾情通报2_48-0" class="reference"><a href="#cite_note-灾情通报2-48">[44]</a></sup><sup id="cite_ref-人民网20120806_49-0" class="reference"><a href="#cite_note-人民网20120806-49">[45]</a></sup><sup id="cite_ref-50" class="reference"><a href="#cite_note-50">[46]</a></sup>。
</p><p>2014年,北京市被中央政府增加了“科技创新中心”的城市战略定位<sup id="cite_ref-51" class="reference"><a href="#cite_note-51">[47]</a></sup>,<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%86%80%E5%8D%8F%E5%90%8C%E5%8F%91%E5%B1%95" title="京津冀协同发展">京津冀协同发展</a>也被提升至国家战略层面<sup id="cite_ref-52" class="reference"><a href="#cite_note-52">[48]</a></sup>。该年11月10日至11日,北京市举行<a href="/wiki/2014%E5%B9%B4%E4%B8%AD%E5%9B%BDAPEC%E5%B3%B0%E4%BC%9A" title="2014年中国APEC峰会">APEC峰会</a>。2015年至2016年,北京发生<a href="/wiki/2015%E5%B9%B4%E8%87%B32016%E5%B9%B4%E5%86%AC%E4%B8%AD%E5%9B%BD%E5%8C%97%E4%BA%AC%E9%9B%BE%E9%9C%BE%E4%BA%8B%E4%BB%B6" title="2015年至2016年冬中国北京雾霾事件">严重的空气污染</a><sup id="cite_ref-:25_53-0" class="reference"><a href="#cite_note-:25-53">[49]</a></sup><sup id="cite_ref-:13_54-0" class="reference"><a href="#cite_note-:13-54">[50]</a></sup><sup id="cite_ref-:5_55-0" class="reference"><a href="#cite_note-:5-55">[51]</a></sup>。
</p><p>2015年,北京市获得<a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季奥林匹克运动会">2022年冬季奥林匹克运动会</a>主办权<sup id="cite_ref-56" class="reference"><a href="#cite_note-56">[52]</a></sup>,将成为全球第一个既举办过夏季奥运会,又举办过冬季奥运会的城市。
</p><p>2016年,国务院印发《北京加强全国科技创新中心建设总体方案》。
</p><p>2017年9月,《北京城市总体规划(2016年—2035年)》获批,将北京市定位为全国政治中心、文化中心、国际交往中心、科技创新中心,同时指出“老城不能再拆”<sup id="cite_ref-57" class="reference"><a href="#cite_note-57">[53]</a></sup>。11月18日,北京<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">大兴区</a><a href="/wiki/%E8%A5%BF%E7%BA%A2%E9%97%A8%E5%9C%B0%E5%8C%BA" title="西红门地区">西红门镇</a>新建庄二村新康东路8号聚福缘公寓发生一场<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E2%80%9C11%C2%B718%E2%80%9D%E7%81%AB%E7%81%BE" title="北京大兴“11·18”火灾">重大火灾</a>,19人遇难<sup id="cite_ref-58" class="reference"><a href="#cite_note-58">[54]</a></sup>,此后北京市政府展开颇具争议的<a href="/wiki/2017%E5%B9%B4%E5%8C%97%E4%BA%AC%E5%AE%89%E5%85%A8%E9%9A%90%E6%82%A3%E6%8E%92%E6%9F%A5%E6%95%B4%E6%94%B9%E6%B4%BB%E5%8A%A8" class="mw-redirect" title="2017年北京安全隐患排查整改活动">安全隐患排查整改活动</a><sup id="cite_ref-59" class="reference"><a href="#cite_note-59">[55]</a></sup>。
</p><p>2019年1月11日,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">北京市人民政府</a>正式迁至通州区<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83" title="北京城市副中心">北京城市副中心</a><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83%E8%A1%8C%E6%94%BF%E5%8A%9E%E5%85%AC%E5%8C%BA" title="北京城市副中心行政办公区">行政办公区</a><sup id="cite_ref-60" class="reference"><a href="#cite_note-60">[56]</a></sup>。
</p><p>2020年1月12日,<a href="/wiki/%E9%A6%96%E9%83%BD%E5%8C%BB%E7%A7%91%E5%A4%A7%E5%AD%A6%E9%99%84%E5%B1%9E%E5%8C%97%E4%BA%AC%E5%9C%B0%E5%9D%9B%E5%8C%BB%E9%99%A2" title="首都医科大学附属北京地坛医院">首都医科大学附属北京地坛医院</a>收治两名<a href="/wiki/2019%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85" title="2019冠状病毒病">2019冠状病毒病</a>疑似患者,2019冠状病毒病疫情<a href="/wiki/2019%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85%E5%8C%97%E4%BA%AC%E5%B8%82%E7%96%AB%E6%83%85" title="2019冠状病毒病北京市疫情">在北京爆发</a><sup id="cite_ref-61" class="reference"><a href="#cite_note-61">[57]</a></sup>,北京市也于该年1月24日启动重大突发公共卫生事件一级响应<sup id="cite_ref-62" class="reference"><a href="#cite_note-62">[58]</a></sup>,此后随着疫情缓和,北京市于4月30日将重大突发公共卫生事件应急响应级别下调至二级响应<sup id="cite_ref-63" class="reference"><a href="#cite_note-63">[59]</a></sup>,6月6日更一度下调至三级响应<sup id="cite_ref-64" class="reference"><a href="#cite_note-64">[60]</a></sup>,本地确诊病例也于6月8日暂时清零<sup id="cite_ref-chinanews20200609_65-0" class="reference"><a href="#cite_note-chinanews20200609-65">[61]</a></sup>,但6月11日爆发的<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%96%B0%E5%8F%91%E5%9C%B0%E5%86%9C%E4%BA%A7%E5%93%81%E6%89%B9%E5%8F%91%E5%B8%82%E5%9C%BA" title="北京新发地农产品批发市场">北京新发地农产品批发市场</a><a href="/wiki/2020%E5%B9%B4%E5%8C%97%E4%BA%AC%E6%96%B0%E5%8F%91%E5%9C%B0%E5%86%9C%E4%BA%A7%E5%93%81%E6%89%B9%E5%8F%91%E5%B8%82%E5%9C%BA%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85%E8%81%9A%E9%9B%86%E6%80%A7%E7%96%AB%E6%83%85" title="2020年北京新发地农产品批发市场冠状病毒病聚集性疫情">聚集性疫情</a>使得北京市再次进入二级响应状态,相关确诊病例至7月6日已累计335例,此后未有增长,7月20日北京市将应急响应机制再次下调至三级<sup id="cite_ref-66" class="reference"><a href="#cite_note-66">[62]</a></sup>,此后北京市仍保持疫情防控常态化状态。8月27日,国务院批复了涉及东城、西城两区的《首都功能核心区控制性详细规划(街区层面)(2018年-2035年)》<sup id="cite_ref-67" class="reference"><a href="#cite_note-67">[63]</a></sup>。
</p>
<h2><span id=".E5.9C.B0.E7.90.86"></span><span class="mw-headline" id="地理">地理</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=8" title="编辑章节:地理">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E7%90%86" title="北京地理">北京地理</a></div>
<div class="thumb tright"><div class="thumbinner" style="width:252px;"><a href="/wiki/File:Beijing_satellite_image,_LandSat-5,_2010-08-08.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/42/Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg/250px-Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg" decoding="async" width="250" height="242" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/42/Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg/375px-Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/42/Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg/500px-Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg 2x" data-file-width="2566" data-file-height="2479" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Beijing_satellite_image,_LandSat-5,_2010-08-08.jpg" class="internal" title="放大"></a></div>北京卫星照片,拍摄于2010年8月。</div></div></div>
<p>北京市位于<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%B9%B3%E5%8E%9F" title="华北平原">华北平原</a>的西北边缘,背靠<a href="/wiki/%E5%A4%AA%E8%A1%8C%E5%B1%B1" title="太行山">太行山</a>余脉和<a href="/wiki/%E7%87%95%E5%B1%B1" title="燕山">燕山</a>山脉,面对辽阔的<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%B9%B3%E5%8E%9F" title="华北平原">华北平原</a>,东南距<a href="/wiki/%E6%B8%A4%E6%B5%B7" title="渤海">渤海</a>約150公里。市域东西宽约160公里,南北长约176公里,土地面积16411平方公里,其中平原面积6338平方公里,占38.6%;山区面积10072平方公里,占61.4%<sup id="cite_ref-68" class="reference"><a href="#cite_note-68">[64]</a></sup>。北京地势总体上上西北高,东南低。全市地貌由西北山地和东南平原两大地貌单元组成。北京市平均<a href="/wiki/%E6%B5%B7%E6%8B%94" title="海拔">海拔</a>高度43.5米<sup id="cite_ref-69" class="reference"><a href="#cite_note-69">[65]</a></sup>,其中平原的海拔高度在20~60米,而山地一般海拔1000~1500米,全市最高峰为位于<a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">门头沟区</a>西北部的东灵山,海拔2303米<sup id="cite_ref-70" class="reference"><a href="#cite_note-70">[66]</a></sup>。北京沒有天然湖泊,天然河道自西向东有<a href="/wiki/%E6%8B%92%E9%A9%AC%E6%B2%B3" title="拒马河">拒马河</a>、<a href="/wiki/%E6%B0%B8%E5%AE%9A%E6%B2%B3" title="永定河">永定河</a>、<a href="/wiki/%E5%8C%97%E8%BF%90%E6%B2%B3" title="北运河">北运河</a>、<a href="/wiki/%E6%BD%AE%E7%99%BD%E6%B2%B3" title="潮白河">潮白河</a>、蓟运河五大<a href="/wiki/%E6%B0%B4%E7%B3%BB" title="水系">水系</a>,均屬<a href="/wiki/%E6%B5%B7%E6%B2%B3" title="海河">海河</a>流域<sup id="cite_ref-71" class="reference"><a href="#cite_note-71">[67]</a></sup>。
</p>
<h3><span id=".E6.B0.A3.E5.80.99"></span><span class="mw-headline" id="氣候">氣候</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=9" title="编辑章节:氣候">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>北京市地处<a href="/wiki/%E6%9A%96%E6%B8%A9%E5%B8%A6" class="mw-redirect" title="暖温带">暖温带</a><a href="/w/index.php?title=%E5%8D%8A%E6%BF%95%E6%BD%A4%E5%9C%B0%E5%8C%BA&action=edit&redlink=1" class="new" title="半濕潤地区(页面不存在)">半濕潤地区</a>,<a href="/wiki/%E6%B0%94%E5%80%99" class="mw-redirect" title="气候">气候</a>属于<a href="/wiki/%E6%B8%A9%E5%B8%A6%E5%AD%A3%E9%A3%8E%E6%B0%94%E5%80%99" title="温带季风气候">暖温带半湿润大陆性季风气候</a>,<sup id="cite_ref-72" class="reference"><a href="#cite_note-72">[68]</a></sup>平原地区平均年降水量约600毫米,市区代表站最大年降水量为1404.6毫米,最大24小时降水量为404.2毫米,平均年最大积雪深度为7.5厘米,历史最大积雪深度33.5厘米。北京四季分明,<a href="/wiki/%E6%98%A5%E5%AD%A3" title="春季">春季</a>多風和沙尘,<a href="/wiki/%E5%A4%8F%E5%AD%A3" title="夏季">夏季</a>炎熱多雨,<a href="/wiki/%E7%A7%8B%E5%AD%A3" title="秋季">秋季</a>晴朗干燥,<a href="/wiki/%E5%86%AC%E5%AD%A3" title="冬季">冬季</a>寒冷且大风猛烈。其中春季和秋季很短,大概一个月出头左右;而夏季和冬季则很长,各接近五个月。北京季风性特征明显,全年60%的降水集中在夏季的7、8月份,而其他季节空气较为干燥。年平均气温約為12.9 °C。最冷月(1月)平均气温为−3.1 °C,最热月(7月)平均气温为26.7 °C。极端最低气温为−33.2 °C(1980年1月30日佛爷顶),极端最高气温43.5 °C(1961年6月10日房山区)。市区极端最低气温为−27.4 °C(1966年2月22日),市区极端最高气温41.9 °C(1999年7月24日)。
</p><p><br />
</p>
<table class="wikitable collapsible" style="width:90%; text-align:center; font-size:90%; line-height: 1.2em; margin:auto;">
<tbody><tr>
<th colspan="14">北京市(平均数据1986-2015年,极端数据1951-2017年)气候平均数据
</th></tr>
<tr>
<th>月份
</th>
<th>1月
</th>
<th>2月
</th>
<th>3月
</th>
<th>4月
</th>
<th>5月
</th>
<th>6月
</th>
<th>7月
</th>
<th>8月
</th>
<th>9月
</th>
<th>10月
</th>
<th>11月
</th>
<th>12月
</th>
<th style="border-left-width:medium">全年
</th></tr>
<tr>
<th height="16">历史最高温​℃(℉)
</th>
<td style="background:#FFBB77;color:#000000;text-align:center;">14.3<br /> (57.7)
</td>
<td style="background:#FF952C;color:#000000;text-align:center;">19.8<br /> (67.6)
</td>
<td style="background:#FF5200;color:#000000;text-align:center;">29.5<br /> (85.1)
</td>
<td style="background:#FF3700;color:#000000;text-align:center;">33.5<br /> (92.3)
</td>
<td style="background:#FF0200;color:#FFFFFF;text-align:center;">41.1<br /> (106)
</td>
<td style="background:#FF0600;color:#FFFFFF;text-align:center;">40.6<br /> (105.1)
</td>
<td style="background:#F90000;color:#FFFFFF;text-align:center;">41.9<br /> (107.4)
</td>
<td style="background:#FF1600;color:#FFFFFF;text-align:center;">38.3<br /> (100.9)
</td>
<td style="background:#FF2C00;color:#000000;text-align:center;">35.0<br /> (95)
</td>
<td style="background:#FF4800;color:#000000;text-align:center;">31.0<br /> (87.8)
</td>
<td style="background:#FF7D00;color:#000000;text-align:center;">23.3<br /> (73.9)
</td>
<td style="background:#FF9730;color:#000000;text-align:center;">19.5<br /> (67.1)
</td>
<td style="background:#F90000;color:#FFFFFF;text-align:center; border-left-width:medium">41.9<br /> (107.4)
</td></tr>
<tr>
<th height="16">平均高温​℃(℉)
</th>
<td style="background:#F2F2FF;color:#000000;text-align:center;">2.1<br /> (35.8)
</td>
<td style="background:#FFF6ED;color:#000000;text-align:center;">5.8<br /> (42.4)
</td>
<td style="background:#FFC78F;color:#000000;text-align:center;">12.6<br /> (54.7)
</td>
<td style="background:#FF8F1F;color:#000000;text-align:center;">20.7<br /> (69.3)
</td>
<td style="background:#FF6400;color:#000000;text-align:center;">26.9<br /> (80.4)
</td>
<td style="background:#FF4B00;color:#000000;text-align:center;">30.5<br /> (86.9)
</td>
<td style="background:#FF4400;color:#000000;text-align:center;">31.5<br /> (88.7)
</td>
<td style="background:#FF4B00;color:#000000;text-align:center;">30.5<br /> (86.9)
</td>
<td style="background:#FF6900;color:#000000;text-align:center;">26.2<br /> (79.2)
</td>
<td style="background:#FF9831;color:#000000;text-align:center;">19.4<br /> (66.9)
</td>
<td style="background:#FFD7AF;color:#000000;text-align:center;">10.3<br /> (50.5)
</td>
<td style="background:#FBFBFF;color:#000000;text-align:center;">3.8<br /> (38.8)
</td>
<td style="background:#FF9F3F;color:#000000;text-align:center; border-left-width:medium">18.4<br /> (65.1)
</td></tr>
<tr>
<th height="16">每日平均气温​℃(℉)
</th>
<td style="background:#D7D7FF;color:#000000;text-align:center;">−2.9<br /> (26.8)
</td>
<td style="background:#E8E8FF;color:#000000;text-align:center;">0.4<br /> (32.7)
</td>
<td style="background:#FFEDDC;color:#000000;text-align:center;">7.0<br /> (44.6)
</td>
<td style="background:#FFB76F;color:#000000;text-align:center;">14.9<br /> (58.8)
</td>
<td style="background:#FF8D1B;color:#000000;text-align:center;">21.0<br /> (69.8)
</td>
<td style="background:#FF7100;color:#000000;text-align:center;">25.0<br /> (77)
</td>
<td style="background:#FF6400;color:#000000;text-align:center;">26.9<br /> (80.4)
</td>
<td style="background:#FF6C00;color:#000000;text-align:center;">25.8<br /> (78.4)
</td>
<td style="background:#FF8E1E;color:#000000;text-align:center;">20.8<br /> (69.4)
</td>
<td style="background:#FFBE7E;color:#000000;text-align:center;">13.8<br /> (56.8)
</td>
<td style="background:#FFFAF6;color:#000000;text-align:center;">5.1<br /> (41.2)
</td>
<td style="background:#E1E1FF;color:#000000;text-align:center;">−0.9<br /> (30.4)
</td>
<td style="background:#FFC388;color:#000000;text-align:center; border-left-width:medium">13.1<br /> (55.6)
</td></tr>
<tr>
<th height="16">平均低温​℃(℉)
</th>
<td style="background:#C0C0FF;color:#000000;text-align:center;">−7.1<br /> (19.2)
</td>
<td style="background:#CFCFFF;color:#000000;text-align:center;">−4.3<br /> (24.3)
</td>
<td style="background:#EFEFFF;color:#000000;text-align:center;">1.6<br /> (34.9)
</td>
<td style="background:#FFE0C2;color:#000000;text-align:center;">8.9<br /> (48)
</td>
<td style="background:#FFB76F;color:#000000;text-align:center;">14.9<br /> (58.8)
</td>
<td style="background:#FF952C;color:#000000;text-align:center;">19.8<br /> (67.6)
</td>
<td style="background:#FF8104;color:#000000;text-align:center;">22.7<br /> (72.9)
</td>
<td style="background:#FF8811;color:#000000;text-align:center;">21.7<br /> (71.1)
</td>
<td style="background:#FFAF60;color:#000000;text-align:center;">16.0<br /> (60.8)
</td>
<td style="background:#FFE1C3;color:#000000;text-align:center;">8.8<br /> (47.8)
</td>
<td style="background:#E9E9FF;color:#000000;text-align:center;">0.6<br /> (33.1)
</td>
<td style="background:#CCCCFF;color:#000000;text-align:center;">−4.9<br /> (23.2)
</td>
<td style="background:#FFE5CC;color:#000000;text-align:center; border-left-width:medium">8.2<br /> (46.8)
</td></tr>
<tr>
<th height="16">历史最低温​℃(℉)
</th>
<td style="background:#6B6BFF;color:#000000;text-align:center;">−22.8<br /> (−9)
</td>
<td style="background:#5252FF;color:#FFFFFF;text-align:center;">−27.4<br /> (−17.3)
</td>
<td style="background:#9595FF;color:#000000;text-align:center;">−15.0<br /> (5)
</td>
<td style="background:#D5D5FF;color:#000000;text-align:center;">−3.2<br /> (26.2)
</td>
<td style="background:#F4F4FF;color:#000000;text-align:center;">2.5<br /> (36.5)
</td>
<td style="background:#FFDAB5;color:#000000;text-align:center;">9.8<br /> (49.6)
</td>
<td style="background:#FFB46A;color:#000000;text-align:center;">15.3<br /> (59.5)
</td>
<td style="background:#FFCF9F;color:#000000;text-align:center;">11.4<br /> (52.5)
</td>
<td style="background:#FAFAFF;color:#000000;text-align:center;">3.7<br /> (38.7)
</td>
<td style="background:#D3D3FF;color:#000000;text-align:center;">−3.5<br /> (25.7)
</td>
<td style="background:#A4A4FF;color:#000000;text-align:center;">−12.3<br /> (9.9)
</td>
<td style="background:#8383FF;color:#000000;text-align:center;">−18.3<br /> (−0.9)
</td>
<td style="background:#5252FF;color:#FFFFFF;text-align:center; border-left-width:medium">−27.4<br /> (−17.3)
</td></tr>
<tr>
<th height="16">平均<a href="/wiki/%E9%99%8D%E6%B0%B4" title="降水">降水</a>量​㎜(英⁠寸)
</th>
<td style="background:#FAFFFA;color:#000000;text-align:center;">2.7<br /> (0.106)
</td>
<td style="background:#F6FFF6;color:#000000;text-align:center;">5.0<br /> (0.197)
</td>
<td style="background:#EFFFEF;color:#000000;text-align:center;">10.2<br /> (0.402)
</td>
<td style="background:#DBFFDB;color:#000000;text-align:center;">23.1<br /> (0.909)
</td>
<td style="background:#C4FFC4;color:#000000;text-align:center;">39.0<br /> (1.535)
</td>
<td style="background:#88FF88;color:#000000;text-align:center;">76.7<br /> (3.02)
</td>
<td style="background:#03FF03;color:#000000;text-align:center;">168.8<br /> (6.646)
</td>
<td style="background:#4BFF4B;color:#000000;text-align:center;">120.2<br /> (4.732)
</td>
<td style="background:#A6FFA6;color:#000000;text-align:center;">57.4<br /> (2.26)
</td>
<td style="background:#DBFFDB;color:#000000;text-align:center;">24.1<br /> (0.949)
</td>
<td style="background:#EAFFEA;color:#000000;text-align:center;">13.1<br /> (0.516)
</td>
<td style="background:#FBFFFB;color:#000000;text-align:center;">2.4<br /> (0.094)
</td>
<td style="background:#BAFFBA;color:#000000;text-align:center; border-left-width:medium">542.7<br /> (21.366)
</td></tr>
<tr>
<th height="16">平均降水日数​<span style="font-size:90%;" class="nowrap">(≥ 0.1 mm)</span>
</th>
<td style="background:#E8E8FF;color:#000000;text-align:center;">1.8
</td>
<td style="background:#DFDFFF;color:#000000;text-align:center;">2.3
</td>
<td style="background:#D6D6FF;color:#000000;text-align:center;">3.3
</td>
<td style="background:#C3C3FF;color:#000000;text-align:center;">4.7
</td>
<td style="background:#B3B3FF;color:#000000;text-align:center;">6.1
</td>
<td style="background:#8080FF;color:#000000;text-align:center;">9.9
</td>
<td style="background:#6161FF;color:#FFFFFF;text-align:center;">12.8
</td>
<td style="background:#7878FF;color:#000000;text-align:center;">10.9
</td>
<td style="background:#9E9EFF;color:#000000;text-align:center;">7.6
</td>
<td style="background:#C3C3FF;color:#000000;text-align:center;">4.8
</td>
<td style="background:#DADAFF;color:#000000;text-align:center;">2.9
</td>
<td style="background:#E6E6FF;color:#000000;text-align:center;">2.0
</td>
<td style="background:#B6B6FF;color:#000000;text-align:center; border-left-width:medium">69.1
</td></tr>
<tr>
<th height="16">平均<a href="/wiki/%E7%9B%B8%E5%AF%B9%E6%B9%BF%E5%BA%A6" class="mw-redirect" title="相对湿度">相对湿度</a>​(%)
</th>
<td style="background:#5656FF;color:#FFFFFF;text-align:center;">44
</td>
<td style="background:#5A5AFF;color:#FFFFFF;text-align:center;">43
</td>
<td style="background:#6262FF;color:#FFFFFF;text-align:center;">41
</td>
<td style="background:#5A5AFF;color:#FFFFFF;text-align:center;">43
</td>
<td style="background:#4343FF;color:#FFFFFF;text-align:center;">49
</td>
<td style="background:#1D1DFF;color:#FFFFFF;text-align:center;">59
</td>
<td style="background:#0000F2;color:#FFFFFF;text-align:center;">70
</td>
<td style="background:#0000EA;color:#FFFFFF;text-align:center;">72
</td>
<td style="background:#0606FF;color:#FFFFFF;text-align:center;">65
</td>
<td style="background:#2121FF;color:#FFFFFF;text-align:center;">58
</td>
<td style="background:#3030FF;color:#FFFFFF;text-align:center;">54
</td>
<td style="background:#4B4BFF;color:#FFFFFF;text-align:center;">47
</td>
<td style="background:#3131FF;color:#FFFFFF;text-align:center; border-left-width:medium">53.8
</td></tr>
<tr>
<th height="16">每月平均<a href="/wiki/%E6%97%A5%E7%85%A7%E6%97%B6%E6%95%B0" class="mw-redirect" title="日照时数">日照时数</a>
</th>
<td style="background:#D4D400;color:#000000;text-align:center;">186.2
</td>
<td style="background:#D9D900;color:#000000;text-align:center;">188.1
</td>
<td style="background:#DDDD00;color:#000000;text-align:center;">227.5
</td>
<td style="background:#E3E300;color:#000000;text-align:center;">242.8
</td>
<td style="background:#E7E700;color:#000000;text-align:center;">267.6
</td>
<td style="background:#DFDF00;color:#000000;text-align:center;">225.6
</td>
<td style="background:#D6D600;color:#000000;text-align:center;">194.5
</td>
<td style="background:#D9D900;color:#000000;text-align:center;">208.2
</td>
<td style="background:#DADA00;color:#000000;text-align:center;">207.5
</td>
<td style="background:#D8D800;color:#000000;text-align:center;">205.2
</td>
<td style="background:#D1D100;color:#000000;text-align:center;">174.5
</td>
<td style="background:#CECE00;color:#000000;text-align:center;">172.3
</td>
<td style="background:#DADA00;color:#000000;text-align:center; border-left-width:medium">2,500
</td></tr>
<tr>
<td colspan="14" style="text-align:center;font-size:95%;">来源:<a rel="nofollow" class="external text" href="http://cdc.cma.gov.cn/dataSetLogger.do?changeFlag=dataLogger">中国气象局 国家气象信息中心</a>
</td></tr></tbody></table>
<h3><span id=".E7.A9.BA.E6.B0.94.E6.B1.A1.E6.9F.93"></span><span class="mw-headline" id="空气污染">空气污染</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=10" title="编辑章节:空气污染">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>北京的空气污染长期为人诟病。空气的主要<a href="/w/index.php?title=%E6%B1%A1%E6%9F%93%E6%BA%90&action=edit&redlink=1" class="new" title="污染源(页面不存在)">污染源</a>为工业废气及<a href="/w/index.php?title=%E6%B1%BD%E8%BD%A6%E5%B0%BE%E6%B0%94&action=edit&redlink=1" class="new" title="汽车尾气(页面不存在)">汽车尾气</a>排放。根据<a href="/wiki/%E8%81%94%E5%90%88%E5%9B%BD%E7%8E%AF%E5%A2%83%E8%A7%84%E5%88%92%E7%BD%B2" class="mw-redirect" title="联合国环境规划署">联合国环境规划署</a>统计,<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%94%BF%E5%BA%9C" class="mw-disambig" title="北京政府">北京政府</a>近年来花费超过1700亿<a href="/wiki/%E7%BE%8E%E5%85%83" title="美元">美元</a>治理<a href="/wiki/%E5%8C%97%E4%BA%AC" class="mw-redirect" title="北京">北京</a>的环境污染<sup id="cite_ref-73" class="reference"><a href="#cite_note-73">[69]</a></sup>,同時也實行了一系列提升北京市空氣質量的措施。這些措施包括將<a href="/wiki/%E9%A6%96%E9%92%A2%E6%80%BB%E5%85%AC%E5%8F%B8" class="mw-redirect" title="首钢总公司">首钢总公司</a>分批遷移至<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北省</a>,並關閉很多对环境造成高污染的企业<sup id="cite_ref-74" class="reference"><a href="#cite_note-74">[70]</a></sup>;使用天然气、电力等清洁能源的節能環保公交车<sup id="cite_ref-75" class="reference"><a href="#cite_note-75">[71]</a></sup>;限制政府和私人汽车行驶;大幅降低公交车、地铁票价以鼓励北京市民尽可能利用公共交通工具出行;在北京奥运期间,利用可再生能源来对约20%的奥运场地进行电力供应;禁止尾气排放污染量大的的“黄标车”进入市区;<sup id="cite_ref-76" class="reference"><a href="#cite_note-76">[72]</a></sup>在北京周边的<a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4" class="mw-redirect" title="内蒙古">内蒙古</a>、<a href="/wiki/%E5%B1%B1%E8%A5%BF" class="mw-redirect" title="山西">山西</a>等地大力植树以提高绿化率等。
</p><p>奥运会之后,北京的空气质量并未因此而好转,2011年2月21日,美国驻华大使馆录得的北京空气污染指数已超过了正常的可测量范围,<sup id="cite_ref-77" class="reference"><a href="#cite_note-77">[73]</a></sup>北京市气象部门亦在2月24日通报称,截止当日北京空气质量已连续三天达到重度污染。<sup id="cite_ref-78" class="reference"><a href="#cite_note-78">[74]</a></sup>亚洲开发银行和清华大学发布《中华人民共和国国家环境分析》报告成北京市为世界十大空气污染城市之一。<sup id="cite_ref-79" class="reference"><a href="#cite_note-79">[75]</a></sup>
</p><p>飞絮则是北京每年4、5月間另一特有现象,其来源以<a href="/w/index.php?title=%E6%9D%A8%E7%B5%AE&action=edit&redlink=1" class="new" title="杨絮(页面不存在)">杨絮</a>為主,也有<a href="/w/index.php?title=%E6%9F%B3%E7%B5%AE&action=edit&redlink=1" class="new" title="柳絮(页面不存在)">柳絮</a>。由於北京城市道路绿化曾以<a href="/wiki/%E6%AF%9B%E7%99%BD%E6%9D%A8" title="毛白杨">毛白楊</a>作為主要树种,而其白絮极易随风飘扬,因此形成了北京春天漫天飞杨絮的景观,也造成了一定程度的环境污染。随着近年来北京市通過樹幹注射抑止劑、<a href="/wiki/%E5%AB%81%E6%8E%A5" title="嫁接">嫁接</a>以及用其他樹種逐漸取代毛白楊等方法治理楊柳飛絮,飞絮现象已逐漸得到控制<sup id="cite_ref-80" class="reference"><a href="#cite_note-80">[76]</a></sup>。
</p>
<div class="thumb tright"><div class="thumbinner" style="width:252px;"><a href="/wiki/File:Smog_in_Beijing_CBD.JPG" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/3b/Smog_in_Beijing_CBD.JPG/250px-Smog_in_Beijing_CBD.JPG" decoding="async" width="250" height="141" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/3b/Smog_in_Beijing_CBD.JPG/375px-Smog_in_Beijing_CBD.JPG 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/3b/Smog_in_Beijing_CBD.JPG/500px-Smog_in_Beijing_CBD.JPG 2x" data-file-width="4608" data-file-height="2592" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Smog_in_Beijing_CBD.JPG" class="internal" title="放大"></a></div>雾霾笼罩下的<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">北京商务中心区</a></div></div></div>
<p>2011年11月-12月,北京市遭遇了持续近一个月的烟霾天气,美国驻华大使馆测量的空气污染指数连续“爆表”,<sup id="cite_ref-asdfsd_81-0" class="reference"><a href="#cite_note-asdfsd-81">[77]</a></sup>然而北京市环保局发布的空气污染级别却为“轻度污染”,<sup id="cite_ref-82" class="reference"><a href="#cite_note-82">[78]</a></sup>引发公众疑虑。后有媒体爆料,当今世界上发达国家普遍开始采用的空气污染测量标准为PM2.5(直径2.5微米的空气颗粒,乃影响大气透明度的首要污染物,同时由于其粒径较小容易进入人体)。但由于中国当时采用的国家标准为PM10,因此无法做到全面防范和测量空气污染。<sup id="cite_ref-83" class="reference"><a href="#cite_note-83">[79]</a></sup><sup id="cite_ref-84" class="reference"><a href="#cite_note-84">[80]</a></sup>北京市环保局表示拒绝采纳和公布PM2.5的数值。<sup id="cite_ref-asdfsd_81-1" class="reference"><a href="#cite_note-asdfsd-81">[77]</a></sup>
</p><p>然而北京市环保局在2011年12月初声称北京当年空气质量乃史上最佳,引发轩然大波。有媒体将此新闻与北京空气污染的照片相对比以示嘲讽。<sup id="cite_ref-85" class="reference"><a href="#cite_note-85">[81]</a></sup>
</p><p>随着北京市空气质量的急剧恶化,舆论呼吁官方尽快将PM2.5作为国内测量标准<sup id="cite_ref-asdfsd_81-2" class="reference"><a href="#cite_note-asdfsd-81">[77]</a></sup>,迫于舆论的压力,环保部宣布将在2012年在京津地区开始试点PM2.5监测,并于2016年开始全国范围的推广。<sup id="cite_ref-86" class="reference"><a href="#cite_note-86">[82]</a></sup>2012年2月2日,北京市首次公布PM2.5日均浓度。<sup id="cite_ref-87" class="reference"><a href="#cite_note-87">[83]</a></sup>
</p><p>2013年1月13日,北京空氣污染程度創歷史紀錄。北京的空氣質量繼續惡化。官方機構建議兩千萬北京市民盡量不要出行。尤其是<a href="/wiki/%E5%85%92%E7%AB%A5" class="mw-redirect" title="兒童">兒童</a>及<a href="/wiki/%E7%97%85%E6%82%A3" class="mw-redirect" title="病患">病患</a>者則更應該盡量縮短外出時間。三天來,北京以及中國大陸其他各大北部城市持續受霧霾天氣影響,已經嚴重超過平時的空氣污染級別。<a href="/wiki/%E6%96%B0%E8%8F%AF%E7%A4%BE" class="mw-redirect" title="新華社">新華社</a>於當天發布信息稱,北京1月12日的PM2.5指數瀕臨“爆表”,空氣質量持續六級嚴重污染。同時,<a href="/wiki/%E7%BE%8E%E5%9B%BD%E9%A9%BB%E5%8D%8E%E5%A4%A7%E4%BD%BF%E9%A6%86" title="美国驻华大使馆">美國駐華大使館</a>在其使館內測量的空氣污染指數也於當天呈現出創紀錄的600點,甚至於當地時間下午一度達到699點。在此之前,美國駐華大使館測量北京空氣污染指數的最高值一直停留在500點左右,該指數為50點時代表空氣質量良好,超過300點就已經進入警戒級別。<sup id="cite_ref-88" class="reference"><a href="#cite_note-88">[84]</a></sup>
</p><p>2013年,北京的PM2.5年均浓度约为90微克,其中PM2.5浓度每立方米≤12微克(即美国1级标准)的时次占比约为10%,≤35微克(美国2级标准)约占30%,≤55微克(美国3级标准)约占45%,>150微克(重度污染)约占20%,>250微克(严重污染)约占5%,而>500微克约占0.5%,相较其他中国东部城市,北京的空气质量明显呈现多变和两极化的特点,对风向十分敏感。<sup id="cite_ref-89" class="reference"><a href="#cite_note-89">[85]</a></sup>
</p><p>北京市生态环境局称2019年北京空气质量是过去7年来最好。2019年,北京市<a href="/wiki/PM2.5" class="mw-redirect" title="PM2.5">PM2.5</a>年均浓度42微克/立方米,相比2018年的51微克/立方米又下降了9微克/立方米,创下了2013年监测以来的最低值,但仍然超过国家标准(35微克/立方米)20%。而且2019年全年,北京没有出现严重污染日,重污染日仅4天。2019年北京市<a href="/wiki/PM10" class="mw-redirect" title="PM10">PM10</a>、<a href="/wiki/%E4%BA%8C%E6%B0%A7%E5%8C%96%E6%B0%AE" title="二氧化氮">二氧化氮</a>和<a href="/wiki/%E4%BA%8C%E6%B0%A7%E5%8C%96%E7%A1%AB" title="二氧化硫">二氧化硫</a>年均浓度分别为68微克/立方米、37微克/立方米和4微克/立方米。其中,PM10、二氧化氮首次达到国家标准(70微克/立方米、40微克/立方米);二氧化硫稳定达到国家标准(60微克/立方米)。从空间分布上看,2019年PM10、PM2.5和二氧化氮仍呈现“南高北低”的梯度分布特征,二氧化硫全市均处于较低浓度水平。其中,2019年<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">密云区</a>、<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">怀柔区</a>PM2.5年均浓度分别为34微克/立方米、35微克/立方米,率先达到国家二级标准。南北污染差异虽然仍然存在,但已经明显缩小,由2013年的63微克/立方米降低至2019年的23微克/立方米,全市PM2.5逐步均匀化。<sup id="cite_ref-90" class="reference"><a href="#cite_note-90">[86]</a></sup>
</p><p>从中国北部和西北部沙漠侵蚀而来的沙尘让北京的天空常有烟霭及浮尘,每年春季初期甚至会有“<a href="/wiki/%E6%B2%99%E5%B0%98%E6%9A%B4" title="沙尘暴">沙尘暴</a>”现象,不过实际上一般达不到气象上沙尘暴的标准(即能见度不足1公里)。
</p>
<h2><span id=".E8.A1.8C.E6.94.BF.E5.8C.BA.E5.88.92"></span><span class="mw-headline" id="行政区划">行政区划</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=11" title="编辑章节:行政区划">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" class="mw-redirect" title="北京市行政区划">北京市行政区划</a></div>
<div role="note" class="hatnote navigation-not-searchable">参见:<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E5%8F%B2" title="北京行政区划史">北京行政区划史</a></div>
<p><a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">明</a><a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">清</a>時設置<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">順天府</a>管轄首都地區,地位與今日的北京市類似,但管轄面積不同。<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">民國</a>初年<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C" title="北洋政府">北洋政府</a>仍定都北京,1913年改<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">順天府</a>為<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">京兆地方</a>,範圍規格與<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">順天府</a>大致相同,直隸於中央。1928年6月,<a href="/wiki/%E5%8C%97%E4%BC%90%E5%86%9B" class="mw-redirect" title="北伐军">北伐軍</a>攻入北京,乃廢除<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">京兆地方</a>建制,改北京為北平,初設北平特別市,直隸<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%9C%8B%E6%B0%91%E6%94%BF%E5%BA%9C" class="mw-redirect" title="南京國民政府">南京國民政府</a>,後改稱北平市,隸屬於<a href="/wiki/%E8%A1%8C%E6%94%BF%E9%99%A2" title="行政院">行政院</a>。日據時期成立北京市政府,日本戰敗投降後恢復原北平市建制。北平市所轄範圍較之前<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">順天府</a>、<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">京兆地方</a>及今日北京市為小,大致包括今<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城区</a>、<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA" class="mw-redirect" title="东城区">东城区</a>全境,<a href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="朝阳区 (北京市)">朝阳区</a>大部、<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">海淀区</a>南半部、<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">石景山区</a>北部和<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">丰台区</a>南半部<sup id="cite_ref-91" class="reference"><a href="#cite_note-91">[87]</a></sup>。
</p><p>1949年<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B" class="mw-redirect" title="中華人民共和國">中華人民共和國</a>成立,定都北平,并改北平为北京。之后北京市辖范围几经扩大。1952年,<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北省</a>宛平县划归北京市。1956年,<a href="/wiki/%E6%98%8C%E5%B9%B3" class="mw-redirect" title="昌平">昌平</a>县划归北京市。1958年3月7日,将<a href="/wiki/%E9%80%9A%E5%8E%BF" class="mw-redirect" title="通县">通县</a>、<a href="/wiki/%E9%A1%BA%E4%B9%89" class="mw-redirect" title="顺义">顺义</a>、<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">大兴</a>、良乡、<a href="/wiki/%E6%88%BF%E5%B1%B1" class="mw-redirect" title="房山">房山</a>五个县区划归北京市。同年10月20日,<a href="/wiki/%E6%80%80%E6%9F%94" class="mw-redirect" title="怀柔">怀柔</a>、<a href="/wiki/%E5%AF%86%E4%BA%91" class="mw-redirect" title="密云">密云</a>、<a href="/wiki/%E5%B9%B3%E8%B0%B7" class="mw-redirect" title="平谷">平谷</a>、<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8E%BF" class="mw-redirect" title="延庆县">延庆</a>四个县又被划归北京市。至此形成今日北京市的轄界。截至2009年,北京辖16区、2<a href="/wiki/%E5%8E%BF" title="县">县</a>,乡级行政区划包括135<a href="/wiki/%E8%A1%97%E9%81%93" title="街道">街道</a>、142建制<a href="/wiki/%E9%95%87" class="mw-redirect" title="镇">镇</a>和40建制<a href="/wiki/%E9%84%89_(%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B)" class="mw-redirect" title="鄉 (中華人民共和國)">乡</a>(其中包括5个<a href="/wiki/%E6%B0%91%E6%97%8F%E4%B9%A1" title="民族乡">民族乡</a>)<sup id="cite_ref-92" class="reference"><a href="#cite_note-92">[88]</a></sup>。
</p><p>在現今北京市市轄區中,<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城</a>、<a href="/wiki/%E8%A5%BF%E5%9F%8E" class="mw-redirect" title="西城">西城</a>兩區位於城市的中心區域,管轄範圍也以今<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%8C%E7%8E%AF%E8%B7%AF" title="北京二环路">二環路</a>以内、清代舊城範圍為主,是传统意义上的市区。而随着北京<a href="/wiki/%E5%9F%8E%E5%B8%82%E5%8C%96" title="城市化">城市化</a>进程的加快,人口的增多和城市范围的扩张,<a href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="朝阳区 (北京市)">朝阳区</a>、<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">海淀区</a>、<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">丰台區</a>和<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">石景山区</a>四個近郊區的大部分地區也逐步被認同為市區,於是和原先的兩個<a href="/wiki/%E5%B8%82%E5%8C%BA" title="市区">城區</a>一起,形成了<a href="/wiki/%E5%9F%8E%E5%85%AD%E5%8C%BA" title="城六区">城六區</a>的概念。並且多数郊<a href="/wiki/%E5%8E%BF" title="县">县</a>也已先後改为<a href="/wiki/%E5%B8%82%E8%BD%84%E5%8D%80" class="mw-redirect" title="市轄區">市轄區</a><sup id="cite_ref-93" class="reference"><a href="#cite_note-93">[89]</a></sup>。规划中北京市城区范围是<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%94%E7%8E%AF%E8%B7%AF" title="北京五环路">五环</a>以内,面积约为667平方公里。
</p><p>2010年7月1日<a href="/wiki/%E5%9B%BD%E5%8A%A1%E9%99%A2" class="mw-redirect mw-disambig" title="国务院">国务院</a>批准撤销原<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城区</a>、<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城区</a>、<a href="/wiki/%E5%B4%87%E6%96%87%E5%8C%BA" title="崇文区">崇文区</a>、<a href="/wiki/%E5%AE%A3%E6%AD%A6%E5%8C%BA" title="宣武区">宣武区</a>四个区,由原<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城区</a>和<a href="/wiki/%E5%B4%87%E6%96%87%E5%8C%BA" title="崇文区">崇文区</a>合并成立新的<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城区</a>,<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城区</a>和<a href="/wiki/%E5%AE%A3%E6%AD%A6%E5%8C%BA" title="宣武区">宣武区</a>合并成立新的<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城区</a>。<sup id="cite_ref-94" class="reference"><a href="#cite_note-94">[90]</a></sup>这样北京市的中心城区合并为两个,城近郊结构就也由以前的“城八区”变为“城六区”。2015年11月,<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%8A%A1%E9%99%A2" title="中华人民共和国国务院">中华人民共和国国务院</a>已经批准北京市调整行政区划,<a href="/wiki/%E5%AF%86%E4%BA%91" class="mw-redirect" title="密云">密云</a>、<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">延庆</a>两县将撤县设区,至此北京将不再设有以“县”为名称的县级行政单位<sup id="cite_ref-95" class="reference"><a href="#cite_note-95">[91]</a></sup>。
</p><p>北京市的市辖区,按照功能划分成四层,从内到外依次是:首都功能核心区、城市功能拓展区、城市功能新区和生态涵养区。現今狭义的北京可僅指北京市区,大约就是<a href="/wiki/%E5%9F%8E%E5%85%AD%E5%8C%BA" title="城六区">城六区</a>的範圍,而广义的北京则代指包括郊区县在内隶属北京市政府管辖北京<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">直辖市</a>。
</p><p>北京市的城市建设风格是典型的<a href="/wiki/%E6%94%BE%E5%B0%84%E5%9E%8B%E5%9F%8E%E5%B8%82" title="放射型城市">放射型城市</a>,由五环路内的主城区和周边的大量<a href="/wiki/%E5%8D%AB%E6%98%9F%E5%9F%8E" class="mw-redirect" title="卫星城">卫星城</a>组成。距离主城区最近的一批卫星城,如<a href="/wiki/%E5%9B%9E%E9%BE%99%E8%A7%82%E5%9C%B0%E5%8C%BA" title="回龙观地区">回龙观</a>、<a href="/wiki/%E5%A4%A9%E9%80%9A%E8%8B%91" title="天通苑">天通苑</a>、海淀山后、石景山首钢,几乎与主城区相互连接;较远的<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83" title="北京城市副中心">副中心</a>、<a href="/wiki/%E4%BA%A6%E5%BA%84%E5%9C%B0%E5%8C%BA" title="亦庄地区">亦庄</a>、<a href="/wiki/%E9%BB%84%E6%9D%91%E5%9C%B0%E5%8C%BA" title="黄村地区">黄村</a>、房山燕化、<a href="/wiki/%E8%89%AF%E4%B9%A1%E5%9C%B0%E5%8C%BA" title="良乡地区">良乡</a>、门头沟城关、<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">昌平</a>、<a href="/wiki/%E6%B2%99%E6%B2%B3%E5%9C%B0%E5%8C%BA" title="沙河地区">沙河</a>、<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">延庆</a>、<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">怀柔</a>、<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">密云</a>、<a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">平谷</a>、<a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">顺义</a>、<a href="/wiki/%E9%95%BF%E8%BE%9B%E5%BA%97%E9%95%87" title="长辛店镇">长辛店</a>等十四个卫星城,以及<a href="/wiki/%E5%A4%A9%E7%AB%BA%E5%9C%B0%E5%8C%BA" title="天竺地区">天竺</a>、<a href="/wiki/%E7%A4%BC%E8%B4%A4%E9%95%87" title="礼贤镇">礼贤</a>两个空港区,在逐渐配合北京整体建设的同时也各有特色;更远的一些城镇,如<a href="/wiki/%E7%87%95%E9%83%8A%E9%95%87" title="燕郊镇">燕郊</a>、<a href="/wiki/%E8%93%9F%E5%B7%9E%E5%8C%BA" title="蓟州区">蓟州</a>、<a href="/wiki/%E5%94%90%E5%B1%B1%E5%B8%82" title="唐山市">唐山</a>、<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">廊坊</a>、<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">承德</a>、<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">保定</a>、<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a>、<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">张家口</a>、<a href="/wiki/%E9%9B%84%E5%AE%89%E6%96%B0%E5%8C%BA" title="雄安新区">雄安</a>,有时也被认为是北京的卫星城,虽然官方目前一般以“<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%86%80%E5%8D%8F%E5%90%8C%E5%8F%91%E5%B1%95" title="京津冀协同发展">京津冀协同发展</a>”表述这些地区与北京的关系。
</p>
<table class="wikitable" style="margin:1em auto 1em auto; width:90%; text-align:center">
<tbody><tr>
<th colspan="10"><b>北京市行政区划图</b>
</th></tr>
<tr>
<td colspan="10"><div class="center" style="position: relative">
<div role="img" class="nounderlines noresize" style="width: 600px; line-height: 1; text-align: center; background-color: #ffffff; position: relative;"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c4/Administrative_Division_Beijing.svg/600px-Administrative_Division_Beijing.svg.png" decoding="async" width="600" height="602" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c4/Administrative_Division_Beijing.svg/900px-Administrative_Division_Beijing.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c4/Administrative_Division_Beijing.svg/1200px-Administrative_Division_Beijing.svg.png 2x" data-file-width="1050" data-file-height="1054" />
<div style="position:absolute; left:287px; top:412px"><a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)"><span style="color: black;"><b>①</b></span></a></div>
<div style="position:absolute; left:269px; top:412px"><a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区"><span style="color: black;"><b>②</b></span></a></div>
<div style="position:absolute; left:314px; top:387px"><a href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="朝阳区 (北京市)"><span style="color: black;"><b>朝<br />阳<br />区</b></span></a></div>
<div style="position:absolute; left:224px; top:432px"><a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区"><span style="color: black;"><b>丰台区</b></span></a></div>
<div style="position:absolute; left:219px; top:402px"><a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区"><span style="color: black;"><b>③</b></span></a></div>
<div style="position:absolute; left:242px; top:360px"><a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区"><span style="color: black;"><b>海<br />淀<br />区</b></span></a></div>
<div style="position:absolute; left:94px; top:382px"><a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区"><span style="color: black;"><b>门头沟区</b></span></a></div>
<div style="position:absolute; left:114px; top:482px"><a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区"><span style="color: black;"><b>房山区</b></span></a></div>
<div style="position:absolute; left:354px; top:452px"><a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)"><span style="color: black;"><b>通州区</b></span></a></div>
<div style="position:absolute; left:354px; top:327px"><a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区"><span style="color: black;"><b>顺义区</b></span></a></div>
<div style="position:absolute; left:214px; top:302px"><a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区"><span style="color: black;"><b>昌平区</b></span></a></div>
<div style="position:absolute; left:264px; top:492px"><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区"><span style="color: black;"><b>大兴区</b></span></a></div>
<div style="position:absolute; left:339px; top:162px"><a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区"><span style="color: black;"><b>怀<br />柔<br />区</b></span></a></div>
<div style="position:absolute; left:464px; top:302px"><a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区"><span style="color: black;"><b>平谷区</b></span></a></div>
<div style="position:absolute; left:424px; top:177px"><a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区"><span style="color: black;"><b>密云区</b></span></a></div>
<div style="position:absolute; left:194px; top:202px"><a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区"><span style="color: black;"><b>延庆区</b></span></a></div>
<div style="position:absolute; left:94px; top:32px"><a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)"><span style="color: black;"><b>① 东城区</b></span></a></div>
<div style="position:absolute; left:94px; top:52px"><a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区"><span style="color: black;"><b>② 西城区</b></span></a></div>
<div style="position:absolute; left:94px; top:72px"><a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区"><span style="color: black;"><b>③ 石景山区</b></span></a></div>
</div>
</div>
</td></tr>
<tr class="nowrap">
<th rowspan="2">区划代码<sup id="cite_ref-96" class="reference"><a href="#cite_note-96">[92]</a></sup>
</th>
<th rowspan="2">区划名称
</th>
<th rowspan="2">汉语拼音
</th>
<th rowspan="2">面积<span id="noteTag-cite_ref-sup"><sup id="cite_ref-97" class="reference"><a href="#cite_note-97">[註 5]</a></sup></span><br />(平方公里)
</th>
<th rowspan="2">常住人口<span id="noteTag-cite_ref-sup"><sup id="cite_ref-98" class="reference"><a href="#cite_note-98">[註 6]</a></sup></span><sup id="cite_ref-99" class="reference"><a href="#cite_note-99">[93]</a></sup><br />(2018年末)
</th>
<th rowspan="2">政府驻地
</th>
<th colspan="4">乡级行政区划<sup id="cite_ref-100" class="reference"><a href="#cite_note-100">[94]</a></sup>
</th></tr>
<tr>
<th width="45">街道
</th>
<th width="45">镇
</th>
<th width="45">乡
</th>
<th width="45">民族乡
</th></tr>
<tr style="font-weight: bold">
<th>110000</th>
<th>北京市
</th>
<td>Běijīng Shì</td>
<td>16,406.16</td>
<td>21,542,000</td>
<td>通州区</td>
<td>152</td>
<td>143</td>
<td>33</td>
<td>5
</td></tr>
<tr bgcolor="lightblue">
<td colspan="10" style="text-align:center;"><b>— <a href="/wiki/%E5%B8%82%E8%BE%96%E5%8C%BA" title="市辖区">市辖区</a> —</b>
</td></tr>
<tr>
<th>110101</th>
<th><a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城区</a>
</th>
<td>Dōngchéng Qū</td>
<td>41.82</td>
<td>822,000</td>
<td><a href="/wiki/%E6%99%AF%E5%B1%B1%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="景山街道 (北京市)">景山街道</a></td>
<td>17</td>
<td></td>
<td></td>
<td>
</td></tr>
<tr>
<th>110102</th>
<th><a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城区</a>
</th>
<td>Xīchéng Qū</td>
<td>50.33</td>
<td>1,179,000</td>
<td><a href="/wiki/%E9%87%91%E8%9E%8D%E8%A1%97%E8%A1%97%E9%81%93" title="金融街街道">金融街街道</a></td>
<td>15</td>
<td></td>
<td></td>
<td>
</td></tr>
<tr>
<th>110105</th>
<th><a href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="朝阳区 (北京市)">朝阳区</a>
</th>
<td>Cháoyáng Qū</td>
<td>454.78</td>
<td>3,605,000</td>
<td><a href="/wiki/%E6%9C%9D%E5%A4%96%E8%A1%97%E9%81%93" title="朝外街道">朝外街道</a></td>
<td>24</td>
<td></td>
<td>18</td>
<td>1
</td></tr>
<tr>
<th>110106</th>
<th><a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">丰台区</a>
</th>
<td>Fēngtái Qū</td>
<td>305.53</td>
<td>2,105,000</td>
<td><a href="/wiki/%E4%B8%B0%E5%8F%B0%E8%A1%97%E9%81%93" title="丰台街道">丰台街道</a></td>
<td>16</td>
<td>2</td>
<td>3</td>
<td>
</td></tr>
<tr>
<th>110107</th>
<th><a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">石景山区</a>
</th>
<td>Shíjǐngshān Qū</td>
<td>84.38</td>
<td>590,000</td>
<td><a href="/wiki/%E9%B2%81%E8%B0%B7%E8%A1%97%E9%81%93" title="鲁谷街道">鲁谷街道</a></td>
<td>9</td>
<td></td>
<td></td>
<td>
</td></tr>
<tr>
<th>110108</th>
<th><a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">海淀区</a>
</th>
<td>Hǎidiàn Qū</td>
<td>430.77</td>
<td>3,358,000</td>
<td><a href="/wiki/%E6%B5%B7%E6%B7%80%E8%A1%97%E9%81%93" title="海淀街道">海淀街道</a></td>
<td>22</td>
<td>7</td>
<td></td>
<td>
</td></tr>
<tr>
<th>110109</th>
<th><a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">门头沟区</a>
</th>
<td>Méntóugōu Qū</td>
<td>1,447.85</td>
<td>331,000</td>
<td><a href="/wiki/%E5%A4%A7%E5%B3%AA%E8%A1%97%E9%81%93" title="大峪街道">大峪街道</a></td>
<td>4</td>
<td>9</td>
<td></td>
<td>
</td></tr>
<tr>
<th>110111</th>
<th><a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">房山区</a>
</th>
<td>Fángshān Qū</td>
<td>1,994.73</td>
<td>1,188,000</td>
<td><a href="/wiki/%E6%8B%B1%E8%BE%B0%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="拱辰街道 (北京市)">拱辰街道</a></td>
<td>8</td>
<td>14</td>
<td>6</td>
<td>
</td></tr>
<tr>
<th>110112</th>
<th><a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">通州区</a>
</th>
<td>Tōngzhōu Qū</td>
<td>905.79</td>
<td>1,578,000</td>
<td><a href="/wiki/%E5%8C%97%E8%8B%91%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="北苑街道 (北京市)">北苑街道</a></td>
<td>6</td>
<td>10</td>
<td></td>
<td>1
</td></tr>
<tr>
<th>110113</th>
<th><a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">顺义区</a>
</th>
<td>Shùnyì Qū</td>
<td>1,019.51</td>
<td>1,169,000</td>
<td><a href="/wiki/%E8%83%9C%E5%88%A9%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="胜利街道 (北京市)">胜利街道</a></td>
<td>6</td>
<td>19</td>
<td></td>
<td>
</td></tr>
<tr>
<th>110114</th>
<th><a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">昌平区</a>
</th>
<td>Chāngpíng Qū</td>
<td>1,342.47</td>
<td>2,108,000</td>
<td><a href="/wiki/%E5%9F%8E%E5%8C%97%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="城北街道 (北京市)">城北街道</a></td>
<td>8</td>
<td>14</td>
<td></td>
<td>
</td></tr>
<tr>
<th>110115</th>
<th><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">大兴区</a>
</th>
<td>Dàxīng Qū</td>
<td>1,036.34</td>
<td>1,796,000</td>
<td><a href="/wiki/%E5%85%B4%E4%B8%B0%E8%A1%97%E9%81%93" title="兴丰街道">兴丰街道</a></td>
<td>8</td>
<td>14</td>
<td></td>
<td>
</td></tr>
<tr>
<th>110116</th>
<th><a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">怀柔区</a>
</th>
<td>Huáiróu Qū</td>
<td>2,122.82</td>
<td>414,000</td>
<td><a href="/wiki/%E9%BE%99%E5%B1%B1%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="龙山街道 (北京市)">龙山街道</a></td>
<td>2</td>
<td>12</td>
<td></td>
<td>2
</td></tr>
<tr>
<th>110117</th>
<th><a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">平谷区</a>
</th>
<td>Pínggǔ Qū</td>
<td>948.24</td>
<td>456,000</td>
<td><a href="/wiki/%E6%BB%A8%E6%B2%B3%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="滨河街道 (北京市)">滨河街道</a></td>
<td>2</td>
<td>14</td>
<td>2</td>
<td>
</td></tr>
<tr>
<th>110118</th>
<th><a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">密云区</a>
</th>
<td>Mìyún Qū</td>
<td>2,225.92</td>
<td>495,000</td>
<td><a href="/wiki/%E9%BC%93%E6%A5%BC%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="鼓楼街道 (北京市)">鼓楼街道</a></td>
<td>2</td>
<td>17</td>
<td></td>
<td>1
</td></tr>
<tr>
<th>110119</th>
<th><a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">延庆区</a>
</th>
<td>Yánqìng Qū</td>
<td>1,994.88</td>
<td>348,000</td>
<td><a href="/wiki/%E5%84%92%E6%9E%97%E8%A1%97%E9%81%93" title="儒林街道">儒林街道</a></td>
<td>3</td>
<td>11</td>
<td>4</td>
<td>
</td></tr></tbody></table>
<h2><span id=".E6.94.BF.E6.B2.BB"></span><span class="mw-headline" id="政治">政治</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=12" title="编辑章节:政治">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%BA%9C" class="mw-redirect" title="北京市政府">北京市政府</a></div>
<link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r61200722/mw-parser-output/.tmulti"/><div class="thumb tmulti tright"><div class="thumbinner" style="width:292px;max-width:292px"><div class="trow"><div class="tsingle" style="width:140px;max-width:140px"><div class="thumbimage" style="height:183px;overflow:hidden"><a href="/wiki/File:1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/eb/1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg/138px-1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg" decoding="async" width="138" height="184" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/eb/1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg/207px-1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/eb/1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg/276px-1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg 2x" data-file-width="601" data-file-height="800" /></a></div><div class="thumbcaption text-align-center">1935年的北平市政府</div></div><div class="tsingle" style="width:148px;max-width:148px"><div class="thumbimage" style="height:183px;overflow:hidden"><a href="/wiki/File:Beijing_1948_JP.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/146px-Beijing_1948_JP.jpg" decoding="async" width="146" height="184" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/219px-Beijing_1948_JP.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/292px-Beijing_1948_JP.jpg 2x" data-file-width="6293" data-file-height="7933" /></a></div><div class="thumbcaption text-align-center">1940年代的北京城区</div></div></div></div></div>
<p>历史上,有明、清等数个朝代或政权在北京建政,因此北京有较长的建都史。目前,北京作为<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">首都</a>,是中华人民共和国的政治中心,不仅政党、立法、行政与军事等的常务机构聚集于北京,许多著名的政治事件如<a href="/wiki/%E4%BA%94%E5%9B%9B%E8%BF%90%E5%8A%A8" title="五四运动">五四运动</a>、<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">四五运动</a>、<a href="/wiki/%E5%85%AD%E5%9B%9B%E4%BA%8B%E4%BB%B6" title="六四事件">六四事件</a>等亦发生于此。
</p><p>1912年2月12日,清<a href="/wiki/%E9%9A%86%E8%A3%95%E5%A4%AA%E5%90%8E" title="隆裕太后">隆裕太后</a>在这里公布末代皇帝<a href="/wiki/%E7%88%B1%E6%96%B0%E8%A7%89%E7%BD%97%E6%BA%A5%E4%BB%AA" class="mw-redirect" title="爱新觉罗溥仪">爱新觉罗·溥仪</a>的退位诏书,标志着中国数千年<a href="/wiki/%E5%90%9B%E4%B8%BB%E4%B8%93%E5%88%B6" class="mw-redirect" title="君主专制">君主专制</a>的终结。1919年5月4日,<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C%E6%99%82%E6%9C%9F" title="北洋政府時期">北洋政府时期</a>,上千名北京高校学生云集<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8" title="天安门">天安门</a>附近,抗议“<a href="/wiki/%E4%BA%8C%E5%8D%81%E4%B8%80%E6%9D%A1" title="二十一条">二十一条</a>”等条约对中国的不平等对待,历史上称为“<a href="/wiki/%E4%BA%94%E5%9B%9B%E8%BF%90%E5%8A%A8" title="五四运动">五四运动</a>”。1935年12月9日,数千名北平高校学生發起抗日救国大规模游行,反对日本对华北“防共自治”,史称“<a href="/wiki/%E4%B8%80%E4%BA%8C%E4%B9%9D%E8%BF%90%E5%8A%A8" class="mw-redirect" title="一二九运动">一二九运动</a>”。1949年10月1日,<a href="/wiki/%E6%AF%9B%E6%B3%BD%E4%B8%9C" title="毛泽东">毛泽东</a>于<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8" title="天安门">天安门</a>城楼上向全世界宣布<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C_(1949%E2%80%931954)" class="mw-redirect" title="中华人民共和国中央人民政府 (1949–1954)">中华人民共和国中央人民政府</a>的成立,北京再次成为中国的政治中心。1976年4月5日,<a href="/wiki/%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="四人帮">四人帮</a>代表政府使用民兵对<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%B9%BF%E5%9C%BA" title="天安门广场">天安门广场</a>进行清场,将在天安门广场集会悼念<a href="/wiki/%E5%9B%BD%E5%8A%A1%E9%99%A2%E6%80%BB%E7%90%86" class="mw-redirect" title="国务院总理">国务院总理</a><a href="/wiki/%E5%91%A8%E6%81%A9%E6%9D%A5" title="周恩来">周恩来</a>的北京数万民众镇压下去。人民开始声讨“<a href="/wiki/%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="四人帮">四人帮</a>”,并由此引发反对“四人帮”的全国性强大群众抗议运动,史称“<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">四五运动</a>”。
</p><p>1989年,民眾自4月15日開始的對前任中共中央總書記胡耀邦的悼念活動演變為要求政府進行多方面改革的示威活動。6月4日,中國人民解放軍開進北京市內天安門廣場及周邊地區,採取武力鎮壓滯留的抗議學生与市民,並引發血腥衝突,造成學生及民眾傷亡,史稱「<a href="/wiki/%E5%85%AD%E5%9B%9B%E4%BA%8B%E4%BB%B6" title="六四事件">六四事件</a>」,隨後北京全城戒嚴長達半年。
</p><p>2015年12月30日,位于<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">通州区</a>的北京城市副中心行政办公区举行奠基仪式,2017年1月起各主要建筑主体结构陆续封顶。2019年1月10日晚,位于<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA" class="mw-redirect" title="东城区">东城区</a><a href="/wiki/%E6%AD%A3%E4%B9%89%E8%B7%AF" title="正义路">正义路</a>2号的北京市人民政府正式摘牌,大楼移交给档案馆<sup id="cite_ref-101" class="reference"><a href="#cite_note-101">[95]</a></sup>,1月11日,北京市人民政府机关与<a href="/wiki/%E4%B8%AD%E5%85%B1%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94" class="mw-redirect" title="中共北京市委">中共北京市委</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E4%BB%A3%E8%A1%A8%E5%A4%A7%E4%BC%9A%E5%B8%B8%E5%8A%A1%E5%A7%94%E5%91%98%E4%BC%9A" title="北京市人民代表大会常务委员会">北京市人大常委会</a>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国人民政治协商会议北京市委员会">政协北京市委员会</a>一同搬迁至<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83" title="北京城市副中心">北京城市副中心</a><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83%E8%A1%8C%E6%94%BF%E5%8A%9E%E5%85%AC%E5%8C%BA" title="北京城市副中心行政办公区">行政办公区</a>新址<sup id="cite_ref-102" class="reference"><a href="#cite_note-102">[96]</a></sup><sup id="cite_ref-103" class="reference"><a href="#cite_note-103">[97]</a></sup>。
</p>
<h3><span id=".E5.9B.9B.E5.A4.A7.E6.9C.BA.E6.9E.84"></span><span class="mw-headline" id="四大机构">四大机构</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=13" title="编辑章节:四大机构">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<table class="wikitable" style="margin:1em auto 1em auto; text-align:center">
<caption>北京市四大机构现任领导人
</caption>
<tbody><tr>
<th style="width:16%">机构
</th>
<th style="width:16%"><img alt="Danghui.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/Danghui.svg/25px-Danghui.svg.png" decoding="async" width="25" height="25" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/Danghui.svg/38px-Danghui.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/69/Danghui.svg/50px-Danghui.svg.png 2x" data-file-width="305" data-file-height="305" /><br /><a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国共产党北京市委员会">中国共产党<br />北京市委员会</a><br />书记
</th>
<th style="width:16%"><a href="/wiki/File:National_Emblem_of_the_People%27s_Republic_of_China_(2).svg" class="image" title="中华人民共和国国徽"><img alt="中华人民共和国国徽" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/25px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png" decoding="async" width="25" height="27" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/38px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/50px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 2x" data-file-width="900" data-file-height="976" /></a><br />北京市人民代表大会<br />常务委员会<br />主任
</th>
<th style="width:16%"><a href="/wiki/File:National_Emblem_of_the_People%27s_Republic_of_China_(2).svg" class="image" title="中华人民共和国国徽"><img alt="中华人民共和国国徽" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/25px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png" decoding="async" width="25" height="27" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/38px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/50px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 2x" data-file-width="900" data-file-height="976" /></a><br /><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">北京市人民政府</a><br /><br />市长
</th>
<th style="width:16%"><img alt="Charter of the Chinese People's Political Consultative Conference (CPPCC) logo.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c5/Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg/25px-Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg.png" decoding="async" width="25" height="25" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c5/Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg/38px-Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c5/Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg/50px-Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg.png 2x" data-file-width="739" data-file-height="750" /><br /><a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国人民政治协商会议北京市委员会">中国人民政治协商会议<br />北京市委员会</a><br />主席
</th></tr>
<tr>
<th>姓名
</th>
<td><a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">蔡奇</a><sup id="cite_ref-104" class="reference"><a href="#cite_note-104">[98]</a></sup>
</td>
<td><a href="/wiki/%E6%9D%8E%E4%BC%9F_(%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A%E4%B8%BB%E4%BB%BB)" title="李伟 (北京市人大常委会主任)">李伟</a><sup id="cite_ref-105" class="reference"><a href="#cite_note-105">[99]</a></sup>
</td>
<td><a href="/wiki/%E9%99%88%E5%90%89%E5%AE%81" title="陈吉宁">陈吉宁</a><sup id="cite_ref-106" class="reference"><a href="#cite_note-106">[100]</a></sup>
</td>
<td><a href="/wiki/%E5%90%89%E6%9E%97_(%E4%BA%BA%E7%89%A9)" title="吉林 (人物)">吉林</a><sup id="cite_ref-107" class="reference"><a href="#cite_note-107">[101]</a></sup>
</td></tr>
<tr>
<th>民族
</th>
<td><a href="/wiki/%E6%B1%89%E6%97%8F" title="汉族">汉族</a></td>
<td>汉族</td>
<td>汉族</td>
<td>汉族
</td></tr>
<tr>
<th>籍贯
</th>
<td><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">福建省</a><a href="/wiki/%E5%B0%A4%E6%BA%AA%E5%8E%BF" title="尤溪县">尤溪县</a></td>
<td><a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">江苏省</a><a href="/wiki/%E5%BC%A0%E5%AE%B6%E6%B8%AF%E5%B8%82" title="张家港市">张家港市</a></td>
<td><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">吉林省</a><a href="/wiki/%E6%A2%A8%E6%A0%91%E5%8E%BF" title="梨树县">梨树县</a></td>
<td><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a>
</td></tr>
<tr>
<th>出生日期
</th>
<td>1955年12月(65歲)</td>
<td>1958年1月(62歲-63歲)</td>
<td>1964年2月(56歲)</td>
<td>1962年4月(58歲)
</td></tr>
<tr>
<th>就任日期
</th>
<td>2017年5月</td>
<td>2017年1月</td>
<td>2018年1月</td>
<td>2013年1月
</td></tr></tbody></table>
<h2><span id=".E7.BB.8F.E6.B5.8E"></span><span class="mw-headline" id="经济">经济</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=14" title="编辑章节:经济">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%BB%8F%E6%B5%8E" class="mw-redirect" title="北京经济">北京经济</a></div>
<div class="thumb tright"><div class="thumbinner" style="width:302px;"><a href="/wiki/File:%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg/300px-%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg" decoding="async" width="300" height="93" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg/450px-%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg/600px-%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg 2x" data-file-width="5813" data-file-height="1800" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg" class="internal" title="放大"></a></div><a href="/wiki/%E4%B8%AD%E5%85%B3%E6%9D%91" title="中关村">中关村</a></div></div></div>
<div class="thumb tright"><div class="thumbinner" style="width:302px;"><a href="/wiki/File:Guomao_Skyline.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/53/Guomao_Skyline.jpg/300px-Guomao_Skyline.jpg" decoding="async" width="300" height="191" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/53/Guomao_Skyline.jpg/450px-Guomao_Skyline.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/53/Guomao_Skyline.jpg/600px-Guomao_Skyline.jpg 2x" data-file-width="1600" data-file-height="1017" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Guomao_Skyline.jpg" class="internal" title="放大"></a></div><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">北京商务中心区</a>天際線</div></div></div>
<h3><span id=".E7.B6.93.E6.BF.9F.E6.95.B8.E6.93.9A"></span><span class="mw-headline" id="經濟數據">經濟數據</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=15" title="编辑章节:經濟數據">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%B0%E5%8C%BA%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="北京市地区生产总值">北京市地区生产总值</a></div>
<p>2015年<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%B0%E5%8C%BA%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="北京市地区生产总值">北京市地区生产总值</a>22968.6亿元,同比增长6.9%;人均地区生产总值达10.6万元,约17064美元<sup id="cite_ref-108" class="reference"><a href="#cite_note-108">[102]</a></sup>。2015年北京第三产业比例达到80%左右,对经济贡献最大的主要是金融等产业。其中金融业增长18.1%,信息传输、软件和信息技术服务业增长12%,科学研究和技术服务业增长14.1%。2015年北京工业企业关停了326家,商品批发市场拆并、疏解了97家。<sup id="cite_ref-21jj_109-0" class="reference"><a href="#cite_note-21jj-109">[103]</a></sup>
</p><p>近年来,北京的房地产业与汽车工业持续发展<sup id="cite_ref-分省年度數據_110-0" class="reference"><a href="#cite_note-分省年度數據-110">[104]</a></sup>。北京市制造业有汽车产业、生物医药产业、光机电产业、微电子产业等<sup id="cite_ref-111" class="reference"><a href="#cite_note-111">[105]</a></sup>。2015年,北京旅遊業共接待海外遊客420萬人次,接待國內遊客2.7億人次。<sup id="cite_ref-gk_112-0" class="reference"><a href="#cite_note-gk-112">[106]</a></sup>2015年,北京前两大的出口市場是美國和香港,主要出口產品為機電產品及高科技產品。<sup id="cite_ref-gk_112-1" class="reference"><a href="#cite_note-gk-112">[106]</a></sup>截至2009年12月,北京市机动车保有量已经突破400万辆<sup id="cite_ref-113" class="reference"><a href="#cite_note-113">[107]</a></sup>。2015年全年,北京货运量28765.2万吨,客运量69923.1万人。年末全市机动车保有量561.9万辆。全年实现邮电业务总量990.9亿元。<sup id="cite_ref-2015公报_114-0" class="reference"><a href="#cite_note-2015公报-114">[108]</a></sup>
</p><p>北京存在区域发展极不平衡的现象。北京市有“南穷北富”的称呼<sup id="cite_ref-115" class="reference"><a href="#cite_note-115">[109]</a></sup>。据2008年统计,北京南城五区(<a href="/wiki/%E5%AE%A3%E6%AD%A6%E5%8C%BA" title="宣武区">宣武</a>、<a href="/wiki/%E5%B4%87%E6%96%87%E5%8C%BA" title="崇文区">崇文</a>、<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">丰台</a>、<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">房山</a>、<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">大兴</a>)的GDP总量不及北城五区(<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城</a>、<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城</a>、<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">海淀</a>、<a href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="朝阳区 (北京市)">朝阳</a>、<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">石景山</a>)的1/5,南城财政收入亦不及北城之1/4<sup id="cite_ref-116" class="reference"><a href="#cite_note-116">[110]</a></sup>。
</p><p>2004年北京市全年完成地方财政收入534亿元,连续8年保持20%以上的增长速度<sup id="cite_ref-117" class="reference"><a href="#cite_note-117">[111]</a></sup>。2009年,<a href="/wiki/%E5%8C%97%E4%BA%AC" class="mw-redirect" title="北京">北京</a>全市完成地方财政收入(一般预算)2026.8亿元,比上年增长10.3%。2013年,全市地方公共财政预算收入3661.1亿元,比上年增长10.4%,地方公共财政预算支出4173.66亿元,增长13.3%。<sup id="cite_ref-118" class="reference"><a href="#cite_note-118">[112]</a></sup>
</p>
<h3><span id="-.7Bzh:.E5.9F.BA.E7.A1.80.E8.AE.BE.E6.96.BD.3Bzh-hans:.E5.9F.BA.E7.A1.80.E8.AE.BE.E6.96.BD.3Bzh-hant:.E5.9F.BA.E7.A4.8E.E5.BB.BA.E8.A8.AD.7D-"></span><span class="mw-headline" id="-{zh:基础设施;zh-hans:基础设施;zh-hant:基礎建設}-">基础设施</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=16" title="编辑章节:基础设施">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%A4%E9%80%9A" class="mw-redirect" title="北京交通">北京交通</a></div>
<p>北京交通发达,是中国最大的铁路、公路及航空<a href="/wiki/%E4%BA%A4%E9%80%9A" title="交通">交通</a>中心,也是乃至整個<a href="/wiki/%E6%9D%B1%E4%BA%9E" class="mw-redirect" title="東亞">東亞</a>地區的重要交通樞紐,擁有完善的城市交通网。截至2019年底,北京共有1167km的<a href="/wiki/%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="高速公路">高速公路</a>和6162km城市道路(其中包括6條環路(二环至六环及<a href="/wiki/%E9%A6%96%E9%83%BD%E7%8E%AF%E7%BA%BF%E9%AB%98%E9%80%9F" class="mw-redirect" title="首都环线高速">大外环</a>)、15條<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E9%81%93" title="中华人民共和国国道">中國國道</a><span id="noteTag-cite_ref-sup"><sup id="cite_ref-119" class="reference"><a href="#cite_note-119">[註 7]</a></sup></span>),轨道交通线路699.3km,數條<a href="/wiki/%E9%90%B5%E8%B7%AF" class="mw-redirect" title="鐵路">鐵路</a>和2個<a href="/wiki/%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="國際機場">國際機場</a>,北京市汽車擁有量達到636.5萬<sup id="cite_ref-19年公报_120-0" class="reference"><a href="#cite_note-19年公报-120">[113]</a></sup>。
<a href="/wiki/%E6%94%BE%E5%B0%84%E5%9E%8B%E5%9F%8E%E5%B8%82" title="放射型城市">放射型城市</a>的单极<a href="/wiki/%E4%BA%A4%E9%80%9A" title="交通">交通</a>體系發展較城市發展相對滯後等多方面原因也使<a href="/wiki/%E4%BA%A4%E9%80%9A%E6%8B%A5%E5%A0%B5" class="mw-redirect" title="交通拥堵">交通擁堵</a>成為了北京長期面對的問題<sup id="cite_ref-121" class="reference"><a href="#cite_note-121">[114]</a></sup><sup id="cite_ref-122" class="reference"><a href="#cite_note-122">[115]</a></sup>。
</p>
<h4><span id=".E5.85.AC.E8.B7.AF"></span><span class="mw-headline" id="公路">公路</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=17" title="编辑章节:公路">编辑</a><span class="mw-editsection-bracket">]</span></span></h4>
<p>中國的公路网也是以北京为中心的辐射状。多条<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E9%81%93" title="中华人民共和国国道">中国国道</a>和<a href="/wiki/%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="高速公路">高速公路</a>均以北京为起点。2006年,<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E4%BA%A4%E9%80%9A%E9%83%A8" class="mw-redirect" title="中華人民共和國交通部">中華人民共和國交通部</a>和北京市政府共同於<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%96%80%E5%BB%A3%E5%A0%B4" class="mw-redirect" title="天安門廣場">天安門廣場</a><a href="/wiki/%E6%AD%A3%E9%98%B3%E9%97%A8" title="正阳门">正陽門</a>前設立<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%AC%E8%B7%AF%E9%9B%B6%E5%85%AC%E9%87%8C%E6%A0%87%E5%BF%97" title="中国公路零公里标志">中國公路零公里標誌</a>,作为国家干线公路总起点的象征<sup id="cite_ref-123" class="reference"><a href="#cite_note-123">[116]</a></sup>。
</p><p>北京城區的城市道路是典型的棋盤式格局,橫平豎直,這一道路網設計始於<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">金</a>,發展於<a href="/wiki/%E5%85%83%E6%9C%9D" title="元朝">元</a>,定型於<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">明</a><a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">清</a><sup id="cite_ref-124" class="reference"><a href="#cite_note-124">[117]</a></sup>。北京外圍的城市道路則是環形加放射性的格局。
</p>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks hlist collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3" style="background:#ccc;"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%B7%AF%E7%BD%91" title="Template:北京路网"><abbr title="查看该模板" style=";background:#ccc;;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E5%8C%97%E4%BA%AC%E8%B7%AF%E7%BD%91" title="Template talk:北京路网"><abbr title="讨论该模板" style=";background:#ccc;;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%8C%97%E4%BA%AC%E8%B7%AF%E7%BD%91&action=edit"><abbr title="编辑该模板" style=";background:#ccc;;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/File:Nuvola_apps_ksysv.png" class="image"><img alt="Nuvola apps ksysv.png" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a3/Nuvola_apps_ksysv.png/25px-Nuvola_apps_ksysv.png" decoding="async" width="25" height="25" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a3/Nuvola_apps_ksysv.png/38px-Nuvola_apps_ksysv.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a3/Nuvola_apps_ksysv.png/50px-Nuvola_apps_ksysv.png 2x" data-file-width="128" data-file-height="128" /></a> 北京路网</div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3" style="background:#ddd;"><div>参见:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%A4%E9%80%9A" title="北京市交通">北京市交通</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" class="mw-redirect" title="北京高速公路">北京高速公路</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="background:#ccc; line-height:1.1em;">主干道</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%95%BF%E5%AE%89%E8%A1%97" title="长安街">长安街</a></li>
<li><a href="/wiki/%E5%B9%B3%E5%AE%89%E5%A4%A7%E8%A1%97" title="平安大街">平安大街</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%AE%89%E5%A4%A7%E8%A1%97_(%E5%8C%97%E4%BA%AC)" class="mw-redirect" title="广安大街 (北京)">广安大街</a></li></ul>
</div></td><td class="navbox-image" rowspan="11" style="width:0%;padding:0px 0px 0px 2px"><div><a href="/wiki/File:Beijing_Liuhuanlu.jpg" class="image" title="北京环路"><img alt="北京环路" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e5/Beijing_Liuhuanlu.jpg/60px-Beijing_Liuhuanlu.jpg" decoding="async" width="60" height="45" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e5/Beijing_Liuhuanlu.jpg/90px-Beijing_Liuhuanlu.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e5/Beijing_Liuhuanlu.jpg/120px-Beijing_Liuhuanlu.jpg 2x" data-file-width="640" data-file-height="480" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="background:#ccc; line-height:1.1em;">快速路</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%8C%E7%8E%AF%E8%B7%AF" title="北京二环路">二环路</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%89%E7%8E%AF%E8%B7%AF" title="北京三环路">三环路</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9B%9B%E7%8E%AF%E8%B7%AF" title="北京四环路">四环路</a></li>
<li><i><a href="/w/index.php?title=%E5%A7%9A%E5%AE%B6%E5%9B%AD%E8%B7%AF&action=edit&redlink=1" class="new" title="姚家园路(页面不存在)">姚家园路</a></i></li>
<li><a href="/wiki/%E9%80%9A%E6%83%A0%E6%B2%B3%E5%8C%97%E8%B7%AF" title="通惠河北路">通惠河北路</a>-<a href="/wiki/%E4%BA%AC%E9%80%9A%E5%BF%AB%E9%80%9F%E8%B7%AF" title="京通快速路">京通快速路</a></li>
<li><a href="/wiki/%E5%B9%BF%E6%B8%A0%E8%B7%AF" title="广渠路">广渠路</a></li>
<li><a href="/wiki/%E5%BE%B7%E8%B3%A2%E8%B7%AF" title="德賢路">德贤路</a></li>
<li><a href="/w/index.php?title=%E8%8F%9C%E6%88%B7%E8%90%A5%E5%8D%97%E8%B7%AF&action=edit&redlink=1" class="new" title="菜户营南路(页面不存在)">菜户营南路</a></li>
<li><a href="/w/index.php?title=%E4%B8%B0%E5%8F%B0%E5%8C%97%E8%B7%AF&action=edit&redlink=1" class="new" title="丰台北路(页面不存在)">丰台北路</a></li>
<li><a href="/w/index.php?title=%E8%8E%B2%E7%9F%B3%E8%B7%AF&action=edit&redlink=1" class="new" title="莲石路(页面不存在)">莲石路</a></li>
<li><a href="/wiki/%E9%98%9C%E7%9F%B3%E8%B7%AF" title="阜石路">阜石路</a></li>
<li><a href="/wiki/%E7%B4%AB%E7%AB%B9%E9%99%A2%E8%B7%AF" title="紫竹院路">紫竹院路</a></li>
<li><a href="/wiki/%E4%B8%87%E6%B3%89%E6%B2%B3%E8%B7%AF" title="万泉河路">万泉河路</a></li>
<li><a href="/wiki/%E5%BE%B7%E8%83%9C%E9%97%A8%E5%A4%96%E5%A4%A7%E8%A1%97" title="德胜门外大街">德胜门外大街</a></li>
<li><a href="/wiki/%E5%AE%89%E7%AB%8B%E8%B7%AF" title="安立路">安立路</a></li>
<li><a href="/wiki/%E8%A5%BF%E7%9B%B4%E9%97%A8%E5%A4%96%E5%A4%A7%E8%A1%97" title="西直门外大街">西直门外大街</a></li>
<li><a href="/wiki/%E5%AD%A6%E9%99%A2%E8%B7%AF_(%E5%8C%97%E4%BA%AC)" title="学院路 (北京)">学院路</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="background:#ccc; line-height:1.1em;">国道</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/101%E5%9B%BD%E9%81%93" title="101国道">G101</a></li>
<li><a href="/wiki/102%E5%9B%BD%E9%81%93" title="102国道">G102</a></li>
<li><a href="/wiki/103%E5%9B%BD%E9%81%93" title="103国道">G103</a></li>
<li><a href="/wiki/104%E5%9B%BD%E9%81%93" title="104国道">G104</a></li>
<li><a href="/wiki/105%E5%9B%BD%E9%81%93" title="105国道">G105</a></li>
<li><a href="/wiki/106%E5%9B%BD%E9%81%93" title="106国道">G106</a></li>
<li><a href="/wiki/107%E5%9B%BD%E9%81%93" title="107国道">G107</a></li>
<li><a href="/wiki/108%E5%9B%BD%E9%81%93" title="108国道">G108</a></li>
<li><a href="/wiki/109%E5%9B%BD%E9%81%93" title="109国道">G109</a></li>
<li><a href="/wiki/110%E5%9B%BD%E9%81%93" title="110国道">G110</a></li>
<li><a href="/wiki/111%E5%9B%BD%E9%81%93" title="111国道">G111</a></li>
<li><a href="/wiki/230%E5%9B%BD%E9%81%93" title="230国道">G230</a></li>
<li><a href="/wiki/234%E5%9B%BD%E9%81%93" title="234国道">G234</a></li>
<li><a href="/wiki/335%E5%9B%BD%E9%81%93" title="335国道">G335</a></li>
<li><a href="/wiki/509%E5%9B%BD%E9%81%93" title="509国道">G509</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="background:#ccc; line-height:1.1em;">省道</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="text-align:center;">南北纵线</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E9%80%9A%E9%A1%BA%E8%B7%AF&action=edit&redlink=1" class="new" title="通顺路(页面不存在)">S201通顺</a></li>
<li><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="北京省道(页面不存在)">S202张采</a></li>
<li><a href="/w/index.php?title=%E9%A1%BA%E5%AF%86%E8%B7%AF&action=edit&redlink=1" class="new" title="顺密路(页面不存在)">S203顺密</a></li>
<li><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="北京省道(页面不存在)">S204密三</a></li>
<li><a href="/wiki/%E5%AF%86%E5%85%B3%E8%B7%AF" title="密关路">S205密关</a></li>
<li><a href="/w/index.php?title=%E5%B9%B3%E4%B8%89%E8%B7%AF&action=edit&redlink=1" class="new" title="平三路(页面不存在)">S206平三</a></li>
<li><a href="/w/index.php?title=%E9%80%9A%E6%B8%85%E8%B7%AF&action=edit&redlink=1" class="new" title="通清路(页面不存在)">S207通清(觅西)</a></li>
<li><a href="/w/index.php?title=%E9%98%8E%E6%B2%B3%E8%B7%AF&action=edit&redlink=1" class="new" title="阎河路(页面不存在)">S208阎河</a></li>
<li><a href="/w/index.php?title=%E7%9F%B3%E6%8B%85%E8%B7%AF&action=edit&redlink=1" class="new" title="石担路(页面不存在)">S209石担</a></li>
<li><a href="/w/index.php?title=%E4%B8%89%E6%B8%A9%E8%B7%AF&action=edit&redlink=1" class="new" title="三温路(页面不存在)">S210三温</a></li>
<li><a href="/w/index.php?title=%E6%96%8B%E5%B9%BD%E8%B7%AF&action=edit&redlink=1" class="new" title="斋幽路(页面不存在)">S211斋幽</a></li>
<li><a href="/w/index.php?title=%E6%98%8C%E8%B5%A4%E8%B7%AF&action=edit&redlink=1" class="new" title="昌赤路(页面不存在)">S212昌赤</a></li>
<li><a href="/w/index.php?title=%E5%AE%89%E5%9B%9B%E8%B7%AF&action=edit&redlink=1" class="new" title="安四路(页面不存在)">S213安四</a></li>
<li><a href="/w/index.php?title=%E5%A3%81%E5%AF%8C%E8%B7%AF&action=edit&redlink=1" class="new" title="壁富路(页面不存在)">S214壁富</a></li>
<li><a href="/w/index.php?title=%E4%BA%AC%E5%BC%80%E8%BE%85%E8%B7%AF&action=edit&redlink=1" class="new" title="京开辅路(页面不存在)">S215京开辅路</a></li>
<li><a href="/w/index.php?title=%E4%BA%AC%E8%97%8F%E8%BE%85%E8%B7%AF&action=edit&redlink=1" class="new" title="京藏辅路(页面不存在)">S216京藏辅路</a></li>
<li><a href="/w/index.php?title=%E5%BA%B7%E5%BC%A0%E8%B7%AF&action=edit&redlink=1" class="new" title="康张路(页面不存在)">S217康张</a></li>
<li><a href="/w/index.php?title=%E6%B8%A9%E5%8D%97%E8%B7%AF&action=edit&redlink=1" class="new" title="温南路(页面不存在)">S218温南</a></li>
<li><a href="/w/index.php?title=%E5%8D%97%E9%9B%81%E8%B7%AF&action=edit&redlink=1" class="new" title="南雁路(页面不存在)">S219南雁</a></li>
<li><a href="/w/index.php?title=%E9%B2%81%E5%9D%A8%E8%B7%AF&action=edit&redlink=1" class="new" title="鲁坨路(页面不存在)">S220鲁坨</a></li>
<li><a href="/w/index.php?title=%E5%AD%94%E5%85%B4%E8%B7%AF&action=edit&redlink=1" class="new" title="孔兴路(页面不存在)">S221孔兴</a></li>
<li><a href="/w/index.php?title=%E5%B4%94%E6%9D%8F%E8%B7%AF&action=edit&redlink=1" class="new" title="崔杏路(页面不存在)">S222崔杏</a></li>
<li><a href="/w/index.php?title=%E6%BC%B7%E6%B0%B8%E8%B7%AF&action=edit&redlink=1" class="new" title="漷永路(页面不存在)">S223漷永</a></li>
<li><a href="/w/index.php?title=%E6%9C%A8%E7%87%95%E8%B7%AF&action=edit&redlink=1" class="new" title="木燕路(页面不存在)">S224木燕</a></li>
<li><a href="/w/index.php?title=%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA%E4%B8%9C%E8%B7%AF&action=edit&redlink=1" class="new" title="首都机场东路(页面不存在)">S225机场东</a></li>
<li><a href="/w/index.php?title=%E9%A9%AC%E6%9C%B1%E8%B7%AF&action=edit&redlink=1" class="new" title="马朱路(页面不存在)">S226马朱</a></li>
<li><a href="/w/index.php?title=%E6%9D%A8%E9%9B%81%E8%B7%AF&action=edit&redlink=1" class="new" title="杨雁路(页面不存在)">S227杨雁</a></li>
<li><a href="/wiki/%E5%8D%97%E4%B8%AD%E8%BD%B4%E8%B7%AF" title="南中轴路">S228南中轴</a></li>
<li><a href="/w/index.php?title=%E9%80%9A%E6%80%80%E8%B7%AF&action=edit&redlink=1" class="new" title="通怀路(页面不存在)">S229通怀(宋梁)</a></li>
<li><a href="/w/index.php?title=%E5%B9%B3%E7%A8%8B%E8%B7%AF&action=edit&redlink=1" class="new" title="平程路(页面不存在)">S230平程</a></li>
<li><a href="/w/index.php?title=%E5%B9%B3%E5%85%B4%E8%B7%AF&action=edit&redlink=1" class="new" title="平兴路(页面不存在)">S231平兴</a></li>
<li><a href="/w/index.php?title=%E5%A6%AB%E5%B7%9D%E8%B7%AF&action=edit&redlink=1" class="new" title="妫川路(页面不存在)">S232妫川</a></li>
<li><a href="/w/index.php?title=%E6%80%80%E9%9B%81%E8%B7%AF&action=edit&redlink=1" class="new" title="怀雁路(页面不存在)">S233怀雁</a></li>
<li><a href="/w/index.php?title=%E5%BE%B7%E8%B4%A4%E8%B7%AF_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" class="new" title="德贤路 (北京)(页面不存在)">S234德贤</a></li>
<li><a href="/w/index.php?title=%E5%85%AB%E5%B3%AA%E8%B7%AF&action=edit&redlink=1" class="new" title="八峪路(页面不存在)">S235八峪</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align:center;">东西横线</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E5%BE%90%E5%B0%B9%E8%B7%AF&action=edit&redlink=1" class="new" title="徐尹路(页面不存在)">S301徐尹</a></li>
<li><a href="/w/index.php?title=%E9%80%9A%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="通马路(页面不存在)">S302通马</a></li>
<li><a href="/w/index.php?title=%E6%BC%B7%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="漷马路(页面不存在)">S303漷马</a></li>
<li><a href="/w/index.php?title=%E9%80%9A%E6%88%BF%E8%B7%AF&action=edit&redlink=1" class="new" title="通房路(页面不存在)">S304通房</a></li>
<li><a href="/w/index.php?title=%E9%A1%BA%E5%B9%B3%E8%B7%AF&action=edit&redlink=1" class="new" title="顺平路(页面不存在)">S305顺平</a></li>
<li><a href="/w/index.php?title=%E6%AD%A6%E5%85%B4%E8%B7%AF&action=edit&redlink=1" class="new" title="武兴路(页面不存在)">S306武兴</a></li>
<li><a href="/w/index.php?title=%E5%88%98%E7%94%B0%E8%B7%AF&action=edit&redlink=1" class="new" title="刘田路(页面不存在)">S307刘田</a></li>
<li><a href="/w/index.php?title=%E6%80%80%E9%95%BF%E8%B7%AF&action=edit&redlink=1" class="new" title="怀长路(页面不存在)">S308怀长</a></li>
<li><a href="/w/index.php?title=%E6%BB%A6%E8%B5%A4%E8%B7%AF&action=edit&redlink=1" class="new" title="滦赤路(页面不存在)">S309滦赤</a></li>
<li><a href="/w/index.php?title=%E7%90%89%E8%BE%9B%E8%B7%AF&action=edit&redlink=1" class="new" title="琉辛路(页面不存在)">S310琉辛</a></li>
<li><a href="/w/index.php?title=%E5%AF%86%E5%85%B4%E8%B7%AF&action=edit&redlink=1" class="new" title="密兴路(页面不存在)">S311密兴</a></li>
<li><a href="/w/index.php?title=%E6%9D%BE%E6%9B%B9%E8%B7%AF&action=edit&redlink=1" class="new" title="松曹路(页面不存在)">S312松曹</a></li>
<li><a href="/w/index.php?title=%E5%B2%B3%E7%90%89%E8%B7%AF&action=edit&redlink=1" class="new" title="岳琉路(页面不存在)">S313岳琉</a></li>
<li><a href="/w/index.php?title=%E5%B9%B3%E8%93%9F%E8%B7%AF&action=edit&redlink=1" class="new" title="平蓟路(页面不存在)">S314平蓟</a></li>
<li><a href="/w/index.php?title=%E4%BA%AC%E8%89%AF%E8%B7%AF&action=edit&redlink=1" class="new" title="京良路(页面不存在)">S315京良</a></li>
<li><a href="/w/index.php?title=%E5%85%B4%E8%89%AF%E8%B7%AF&action=edit&redlink=1" class="new" title="兴良路(页面不存在)">S316兴良</a></li>
<li><a href="/w/index.php?title=%E4%BA%AC%E5%91%A8%E8%B7%AF&action=edit&redlink=1" class="new" title="京周路(页面不存在)">S317京周</a></li>
<li><a href="/w/index.php?title=%E6%88%BF%E6%98%93%E8%B7%AF&action=edit&redlink=1" class="new" title="房易路(页面不存在)">S318房易</a></li>
<li><a href="/w/index.php?title=%E8%89%AF%E5%9D%A8%E8%B7%AF&action=edit&redlink=1" class="new" title="良坨路(页面不存在)">S319良坨</a></li>
<li><a href="/w/index.php?title=G108%E8%BE%85%E7%BA%BF&action=edit&redlink=1" class="new" title="G108辅线(页面不存在)">S320京昆路复线</a></li>
<li><a href="/w/index.php?title=%E9%A1%BA%E6%B2%99%E8%B7%AF&action=edit&redlink=1" class="new" title="顺沙路(页面不存在)">S321顺沙</a></li>
<li><a href="/w/index.php?title=%E9%BB%84%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="黄马路(页面不存在)">S322黄马</a></li>
<li><a href="/w/index.php?title=%E5%BB%B6%E7%90%89%E8%B7%AF&action=edit&redlink=1" class="new" title="延琉路(页面不存在)">S323延琉</a></li>
<li><a href="/w/index.php?title=%E6%B2%99%E9%98%B3%E8%B7%AF&action=edit&redlink=1" class="new" title="沙阳路(页面不存在)">S324沙阳</a></li>
<li><a href="/w/index.php?title=%E8%A5%BF%E5%AE%98%E8%B7%AF&action=edit&redlink=1" class="new" title="西官路(页面不存在)">S325西官</a></li>
<li><a href="/w/index.php?title=%E5%A4%A7%E4%BB%B6%E8%B7%AF&action=edit&redlink=1" class="new" title="大件路(页面不存在)">S326大件</a></li>
<li><a href="/w/index.php?title=%E5%AE%9A%E6%B3%97%E8%B7%AF&action=edit&redlink=1" class="new" title="定泗路(页面不存在)">S327定泗</a></li>
<li><a href="/w/index.php?title=%E8%89%AF%E4%B8%89%E8%B7%AF&action=edit&redlink=1" class="new" title="良三路(页面不存在)">S328良三</a></li>
<li><a href="/w/index.php?title=%E9%BB%84%E4%BA%A6%E8%B7%AF&action=edit&redlink=1" class="new" title="黄亦路(页面不存在)">S329黄亦</a></li>
<li><a href="/w/index.php?title=%E6%98%8C%E9%87%91%E8%B7%AF&action=edit&redlink=1" class="new" title="昌金路(页面不存在)">S330昌金</a></li>
<li><a href="/w/index.php?title=%E9%A1%BA%E5%B9%B3%E5%8D%97%E7%BA%BF&action=edit&redlink=1" class="new" title="顺平南线(页面不存在)">S331顺平南</a></li>
<li><a href="/w/index.php?title=%E9%BE%99%E5%A1%98%E8%B7%AF&action=edit&redlink=1" class="new" title="龙塘路(页面不存在)">S332龙塘</a></li>
<li><a href="/w/index.php?title=%E9%98%8E%E5%91%A8%E8%B7%AF&action=edit&redlink=1" class="new" title="阎周路(页面不存在)">S333阎周</a></li>
<li><a href="/w/index.php?title=%E7%99%BD%E9%A9%AC%E8%B7%AF%E8%A5%BF%E5%BB%B6&action=edit&redlink=1" class="new" title="白马路西延(页面不存在)">S334白马西延</a></li>
<li><a href="/w/index.php?title=%E7%99%BD%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="白马路(页面不存在)">S335白马</a></li>
<li><a href="/w/index.php?title=%E5%85%B4%E4%BA%A6%E8%B7%AF&action=edit&redlink=1" class="new" title="兴亦路(页面不存在)">S336兴亦</a></li>
<li><a href="/w/index.php?title=%E5%8C%97%E6%B8%85%E8%B7%AF&action=edit&redlink=1" class="new" title="北清路(页面不存在)">S337北清</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align:center;">原等级已变更</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E5%8D%81%E4%B8%89%E9%99%B5%E6%B0%B4%E5%BA%93%E8%B7%AF&action=edit&redlink=1" class="new" title="十三陵水库路(页面不存在)"><font color="gray"> 原S214十三陵水库</font></a></li>
<li><a href="/w/index.php?title=%E9%80%9A%E9%A6%99%E8%B7%AF&action=edit&redlink=1" class="new" title="通香路(页面不存在)"><font color="gray"> 原S301通香</font></a></li>
<li><a href="/w/index.php?title=%E6%80%80%E6%98%8C%E8%B7%AF&action=edit&redlink=1" class="new" title="怀昌路(页面不存在)"><font color="gray">原S307怀昌</font></a></li>
<li><a href="/w/index.php?title=%E5%AF%86%E4%BA%91%E6%B0%B4%E5%BA%93%E5%8D%97%E8%B7%AF&action=edit&redlink=1" class="new" title="密云水库南路(页面不存在)"><font color="gray">原S313密云水库南</font></a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="background:#ccc; line-height:1.1em;">高速公路</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="text-align:auto; background:#F0FFF0 ;">京津冀高速
 </th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left  "><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E4%BA%AC%E8%93%9F%E6%B4%A5%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京蓟津高速公路">S3201京蓟津</a>(<a href="/wiki/%E4%BA%AC%E5%B9%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京平高速公路">京平</a>|<a href="/w/index.php?title=%E8%93%9F%E5%B9%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="蓟平高速公路(页面不存在)">蓟平</a>)</li>
<li><a href="/wiki/%E5%A4%A7%E5%85%B4%E6%9C%BA%E5%9C%BA%E5%8C%97%E7%BA%BF" class="mw-redirect" title="大兴机场北线">S3300大兴机场北线</a></li>
<li><a href="/wiki/%E4%BA%AC%E6%B4%A5%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京津高速公路">S3301京津</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="北京大兴国际机场高速公路">S3501大兴机场高速</a></li>
<li><i><a href="/wiki/%E4%BA%AC%E8%94%9A%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京蔚高速公路">S3701京蔚</a></i></li>
<li><a href="/wiki/%E4%BA%AC%E7%A4%BC%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京礼高速公路">S3801京礼</a>(<a href="/wiki/%E5%85%B4%E5%BB%B6%E9%AB%98%E9%80%9F" class="mw-redirect" title="兴延高速">兴延</a>|<a href="/wiki/%E5%BB%B6%E5%B4%87%E9%AB%98%E9%80%9F" class="mw-redirect" title="延崇高速">延崇</a>)</li>
<li><i><a href="/wiki/%E4%BA%AC%E9%9B%84%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京雄高速公路">京雄</a></i></li>
<li><i><a href="/wiki/%E4%BA%AC%E5%BE%B7%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京德高速公路">京德</a>(大兴南北航站楼联络线)</i></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align:auto; background:#F0FFF0 ;">国道沿线高速</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left  "><div style="padding:0em 0.25em">
<ul><li><i><a href="/w/index.php?title=%E4%BA%AC%E5%AF%86%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="京密高速公路(页面不存在)">G101京密</a></i></li>
<li><a href="/wiki/%E9%80%9A%E7%87%95%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="通燕高速公路">G102通燕</a></li>
<li><a href="/wiki/%E4%BA%AC%E9%80%9A%E5%BF%AB%E9%80%9F%E8%B7%AF" title="京通快速路">G103京通</a></li>
<li><a href="/wiki/%E4%BA%AC%E5%BC%80%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京开高速公路">G106京开</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align:auto; background:#F0FFF0 ;">省级高速公路</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left  "><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E4%BA%AC%E6%89%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京承高速公路">S11京承</a></li>
<li><a href="/wiki/%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="首都机场高速公路">S12首都机场高速</a></li>
<li><i><a href="/w/index.php?title=%E6%98%8C%E8%B0%B7%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="昌谷高速公路(页面不存在)">S26昌谷</a></i></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E6%9C%BA%E5%9C%BA%E5%8C%97%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="北京机场北线高速公路">S28首都机场北线</a></li>
<li><i><a href="/w/index.php?title=%E5%AF%86%E9%87%87%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="密采高速公路(页面不存在)">S41密采</a></i></li>
<li><a href="/w/index.php?title=%E4%BA%AC%E9%80%9A%E9%80%9A%E7%87%95%E8%81%94%E7%BB%9C%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="京通通燕联络线高速公路(页面不存在)">S46京通通燕联络线</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%94%E7%8E%AF%E8%B7%AF" title="北京五环路">S50五环路</a></li>
<li><a href="/wiki/%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA%E7%AC%AC%E4%BA%8C%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="首都机场第二高速公路">S51首都机场二高速</a></li>
<li><a href="/w/index.php?title=%E4%BA%AC%E6%98%86%E9%AB%98%E9%80%9F%E8%81%94%E7%BB%9C%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="京昆高速联络线高速公路(页面不存在)">S66京昆联络线</a></li>
<li><i><a href="/w/index.php?title=%E7%87%95%E9%87%87%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="燕采高速公路(页面不存在)">S76燕采</a></i></li>
<li><i><a href="/wiki/%E5%AF%86%E6%B6%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="密涿高速公路">S80密涿</a></i></li>
<li><i><a href="/w/index.php?title=%E4%BA%91%E9%87%87%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" class="new" title="云采高速公路(页面不存在)">S86云采</a></i></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align:auto; background:#F0FFF0 ;">国家高速公路</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left  "><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E4%BA%AC%E5%93%88%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京哈高速公路">G1京哈</a>(<a href="/wiki/%E4%BA%AC%E7%80%8B%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京瀋高速公路">京沈</a>)</li>
<li><a href="/wiki/%E4%BA%AC%E7%A7%A6%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京秦高速公路">G01<sub>21</sub>京秦</a></li>
<li><a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京沪高速公路">G2京沪</a>(<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%A1%98%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京津塘高速公路">京津塘</a>)</li>
<li><a href="/wiki/%E4%BA%AC%E5%8F%B0%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京台高速公路">G3京台</a></li>
<li><a href="/wiki/%E4%BA%AC%E6%B8%AF%E6%BE%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京港澳高速公路">G4京港澳</a>(<a href="/wiki/%E4%BA%AC%E7%9F%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京石高速公路">京石</a>)</li>
<li><a href="/wiki/%E4%BA%AC%E6%98%86%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京昆高速公路">G5京昆</a>(<a href="/wiki/%E4%BA%AC%E7%9F%B3%E7%AC%AC%E4%BA%8C%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" class="mw-redirect" title="京石第二高速公路">京石二高速</a>)</li>
<li><a href="/wiki/%E4%BA%AC%E8%97%8F%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京藏高速公路">G6京藏</a>(<a href="/wiki/%E4%BA%AC%E5%BC%A0%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" class="mw-redirect" title="京张高速公路">京张</a>|<a href="/wiki/%E5%85%AB%E8%BE%BE%E5%B2%AD%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="八达岭高速公路">八达岭</a>)</li>
<li><a href="/wiki/%E4%BA%AC%E6%96%B0%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京新高速公路">G7京新</a>(<a href="/wiki/%E4%BA%AC%E5%8C%85%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" class="mw-redirect" title="京包高速公路">京包</a>)</li>
<li><a href="/wiki/%E5%A4%A7%E5%B9%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="大广高速公路">G45大广</a>(部分含<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京承高速公路">京承</a>、<a href="/wiki/%E4%BA%AC%E5%BC%80%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京开高速公路">京开</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AD%E7%8E%AF%E8%B7%AF" title="北京六环路">六环路</a>)</li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AD%E7%8E%AF%E8%B7%AF" title="北京六环路">G45<sub>01</sub>六环路</a></li>
<li><a href="/wiki/%E9%A6%96%E9%83%BD%E5%9C%B0%E5%8C%BA%E7%8E%AF%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="首都地区环线高速公路">G95首都环线</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="background:#ccc; line-height:1.1em;">特殊道路</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%9B%9E%E9%BE%99%E8%A7%82%E8%87%B3%E4%B8%8A%E5%9C%B0%E8%87%AA%E8%A1%8C%E8%BD%A6%E4%B8%93%E7%94%A8%E8%B7%AF" title="回龙观至上地自行车专用路">回龙观至上地自行车专用路</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3" style="background:#ddd;"><div><center><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%90%84%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E6%99%AE%E9%80%9A%E5%9B%BD%E7%9C%81%E5%B9%B2%E7%BA%BF%E5%85%AC%E8%B7%AF" title="Template:中华人民共和国各省级行政区普通国省干线公路">中国普通省道</a>:<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E5%85%AC%E8%B7%AF%E7%BD%91" class="mw-redirect" title="Template:北京公路网">京</a> | <a href="/w/index.php?title=Template:%E5%A4%A9%E6%B4%A5%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:天津省道(页面不存在)">津</a> | <a href="/w/index.php?title=Template:%E6%B2%B3%E5%8C%97%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:河北省道(页面不存在)">冀</a> | <a href="/w/index.php?title=Template:%E5%B1%B1%E8%A5%BF%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:山西省道(页面不存在)">晋</a> | <a href="/w/index.php?title=Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:内蒙古自治区省道(页面不存在)">蒙</a> | <a href="/w/index.php?title=Template:%E8%BE%BD%E5%AE%81%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:辽宁省道(页面不存在)">辽</a> | <a href="/w/index.php?title=Template:%E5%90%89%E6%9E%97%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:吉林省道(页面不存在)">吉</a> | <a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81%E9%81%93" title="Template:黑龙江省道">黑</a> | <a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E7%9C%81%E9%81%93" title="Template:上海省道">沪</a> | <a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E7%9C%81%E9%81%93" title="Template:江苏省道">苏</a> | <a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E7%9C%81%E9%81%93" title="Template:浙江省道">浙</a> | <a href="/w/index.php?title=Template:%E5%B1%B1%E4%B8%9C%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:山东省道(页面不存在)">鲁</a> | <a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E7%9C%81%E9%81%93" title="Template:安徽省道">皖</a> | <a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E7%9C%81%E9%81%93" title="Template:江西省道">赣</a> | <a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E7%9C%81%E9%81%93" title="Template:福建省道">闽</a> | <a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E7%9C%81%E9%81%93" title="Template:河南省道">豫</a> | <a href="/wiki/Template:%E6%B9%96%E5%8C%97%E7%9C%81%E9%81%93" title="Template:湖北省道">鄂</a> | <a href="/w/index.php?title=Template:%E6%B9%96%E5%8D%97%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:湖南省道(页面不存在)">湘</a> | <a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E7%9C%81%E9%81%93" title="Template:广东省道">粤</a> | <a href="/w/index.php?title=Template:%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:广西壮族自治区省道(页面不存在)">桂</a> | <a href="/w/index.php?title=Template:%E6%B5%B7%E5%8D%97%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:海南省道(页面不存在)">琼</a> | <a href="/w/index.php?title=Template:%E9%87%8D%E5%BA%86%E5%B8%82%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:重庆市省道(页面不存在)">渝</a> | <a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E7%9C%81%E9%81%93" title="Template:四川省道">川</a> | <a href="/w/index.php?title=Template:%E8%B4%B5%E5%B7%9E%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:贵州省道(页面不存在)">贵</a> | <a href="/w/index.php?title=Template:%E4%BA%91%E5%8D%97%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:云南省道(页面不存在)">滇</a> | <a href="/w/index.php?title=Template:%E8%A5%BF%E8%97%8F%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:西藏省道(页面不存在)">藏</a> | <a href="/wiki/Template:%E9%99%95%E8%A5%BF%E7%9C%81%E9%81%93" title="Template:陕西省道">陕</a> | <a href="/w/index.php?title=Template:%E7%94%98%E8%82%83%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:甘肃省道(页面不存在)">甘</a> | <a href="/w/index.php?title=Template:%E9%9D%92%E6%B5%B7%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:青海省道(页面不存在)">青</a> | <a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA%E7%9C%81%E9%81%93" title="Template:宁夏回族自治区省道">宁</a> | <a href="/w/index.php?title=Template:%E6%96%B0%E7%96%86%E7%9C%81%E9%81%93&action=edit&redlink=1" class="new" title="Template:新疆省道(页面不存在)">新</a> | 港 | 澳 | <i><a href="/wiki/Template:%E5%8F%B0%E7%81%A3%E7%9C%81%E9%81%93" title="Template:台灣省道">台</a></i></center></div></td></tr></tbody></table></td></tr></tbody></table>
<h4><span id=".E9.93.81.E8.B7.AF"></span><span class="mw-headline" id="铁路">铁路</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=18" title="编辑章节:铁路">编辑</a><span class="mw-editsection-bracket">]</span></span></h4>
<div role="note" class="hatnote navigation-not-searchable">参见:<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%93%81%E8%B7%AF%E6%9E%A2%E7%BA%BD" title="北京铁路枢纽">北京铁路枢纽</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">北京地铁</a></div>
<p>北京長期以來就是<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E9%90%B5%E8%B7%AF%E9%81%8B%E8%BC%B8" title="中華人民共和國鐵路運輸">中國鐵路</a>網的中心。北京铁路的历史可追溯至<a href="/wiki/%E6%99%9A%E6%B8%85" class="mw-redirect" title="晚清">晚清</a>,最早的铁路是由<a href="/wiki/%E8%A9%B9%E5%A4%A9%E4%BD%91" title="詹天佑">詹天佑</a>主持修建的<a href="/wiki/%E4%BA%AC%E5%BC%A0%E9%93%81%E8%B7%AF" title="京张铁路">京张铁路</a>,于1909年竣工,是第一条中国人自主修建的铁路。截至2018年底,北京共拥有1103公里的国家铁路<sup id="cite_ref-19年鉴_125-0" class="reference"><a href="#cite_note-19年鉴-125">[118]</a></sup>,普速铁路方面,<a href="/wiki/%E4%BA%AC%E5%93%88%E9%93%81%E8%B7%AF" title="京哈铁路">京哈线</a>、<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%93%81%E8%B7%AF" title="京沪铁路">京沪线</a>、<a href="/wiki/%E4%BA%AC%E4%B9%9D%E9%93%81%E8%B7%AF" title="京九铁路">京九线</a>、<a href="/wiki/%E4%BA%AC%E5%B9%BF%E9%93%81%E8%B7%AF" title="京广铁路">京广线</a>、<a href="/wiki/%E4%BA%AC%E5%8E%9F%E7%BA%BF" class="mw-redirect" title="京原线">京原线</a>、<a href="/wiki/%E4%BA%AC%E5%8C%85%E9%93%81%E8%B7%AF" title="京包铁路">京包线</a>、<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%93%81%E8%B7%AF" title="京承铁路">京承线</a>、<a href="/wiki/%E4%BA%AC%E9%80%9A%E9%93%81%E8%B7%AF" title="京通铁路">京通线</a>、<a href="/wiki/%E4%B8%B0%E6%B2%99%E9%93%81%E8%B7%AF" title="丰沙铁路">丰沙线</a>等铁路干线均汇集于此,另外<a href="/wiki/%E5%A4%A7%E7%A7%A6%E9%93%81%E8%B7%AF" title="大秦铁路">大秦线</a>亦途经北京。而經過北京的國際及跨境列車則可以連接<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港</a>、<a href="/wiki/%E8%92%99%E5%8F%A4%E5%9B%BD" title="蒙古国">蒙古</a>、<a href="/wiki/%E4%BF%84%E7%BE%85%E6%96%AF" class="mw-redirect" title="俄羅斯">俄羅斯</a>、<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">越南</a>及<a href="/wiki/%E6%9C%9D%E9%B2%9C%E6%B0%91%E4%B8%BB%E4%B8%BB%E4%B9%89%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="朝鲜民主主义人民共和国">北韓</a>等國家和地區。<a href="/wiki/%E9%AB%98%E9%80%9F%E9%90%B5%E8%B7%AF" title="高速鐵路">高速鐵路</a>方面,北京已建成<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京津城际铁路">京津城际鐵路</a>、<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%AB%98%E9%80%9F%E9%93%81%E8%B7%AF" title="京沪高速铁路">京沪高速铁路</a>、<a href="/wiki/%E4%BA%AC%E5%B9%BF%E9%AB%98%E9%80%9F%E9%93%81%E8%B7%AF" title="京广高速铁路">京广高速铁路</a>、<a href="/wiki/%E4%BA%AC%E9%9B%84%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京雄城际铁路">京雄城际铁路</a>、<a href="/wiki/%E4%BA%AC%E5%BC%A0%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京张城际铁路">京张城际铁路</a>,并有<a href="/wiki/%E4%BA%AC%E6%B2%88%E9%AB%98%E9%80%9F%E9%93%81%E8%B7%AF" class="mw-redirect" title="京沈高速铁路">京沈高速铁路</a>、<a href="/wiki/%E4%BA%AC%E5%94%90%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京唐城际铁路">京唐城际铁路</a>等线路在建。
</p><p>北京规划的10个全国客运枢纽<sup id="cite_ref-2035总规_126-0" class="reference"><a href="#cite_note-2035总规-126">[119]</a></sup>中8个为铁路客运枢纽,已建成的包括<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">北京站</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">北京西站</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E7%AB%99" title="北京南站">北京南站</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8C%97%E7%AB%99" title="北京北站">北京北站</a>和<a href="/wiki/%E6%B8%85%E6%B2%B3%E7%AB%99" title="清河站">清河站</a>,另有<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%9C%9D%E9%98%B3%E7%AB%99" title="北京朝阳站">北京朝阳站</a>、<a href="/wiki/%E4%B8%B0%E5%8F%B0%E7%AB%99" title="丰台站">丰台站</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83%E7%AB%99" title="北京城市副中心站">北京城市副中心站</a>在建,这些<a href="/wiki/%E7%81%AB%E8%BB%8A%E7%AB%99" class="mw-redirect" title="火車站">火車站</a>同時也都是北京市城市交通的重要樞紐。<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">北京站</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">北京西站</a>之間有<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E4%B8%8B%E7%9B%B4%E5%BE%84%E7%BA%BF" title="北京地下直径线">地下鐵路</a>連接。
</p><p><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">北京站</a>是北京建設最早的大型铁路客运站,在<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">北京西站</a>建成以前,北京站是北京最重要的车站,也是全亞洲客流量最大的车站,長期超负荷运转。1996年竣工的<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">北京西站</a>大大缓解了北京站的压力,目前北京西站主要負責<a href="/wiki/%E4%BA%AC%E4%B9%9D%E9%93%81%E8%B7%AF" title="京九铁路">京九线</a>和<a href="/wiki/%E4%BA%AC%E5%B9%BF%E9%93%81%E8%B7%AF" title="京广铁路">京广线</a>等路线的旅客列车客运业务,而原有的北京站則主要负责<a href="/wiki/%E4%BA%AC%E5%93%88%E9%93%81%E8%B7%AF" title="京哈铁路">京哈线</a>、<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%93%81%E8%B7%AF" title="京沪铁路">京沪线</a>、<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%93%81%E8%B7%AF" title="京承铁路">京承线</a>和<a href="/wiki/%E4%B8%B0%E6%B2%99%E9%93%81%E8%B7%AF" title="丰沙铁路">丰沙线</a>等路线的大多数旅客列车客运业务。截至2009年5月1日,<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">北京西站</a>每日有220車次始發或經停,而<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">北京站</a>則有177車次。<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">北京地铁</a>2号线途经北京站,而<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%819%E5%8F%B7%E7%BA%BF" title="北京地铁9号线">北京地鐵9號线</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%817%E5%8F%B7%E7%BA%BF" title="北京地铁7号线">北京地鐵7號线</a>都通過北京西站。在北京站和北京西站的附近,還設有諸多公交车的總站。2008年改造完成的<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E7%AB%99" title="北京南站">北京南站</a>,是<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%9F%8E%E9%9A%9B%E9%90%B5%E8%B7%AF" class="mw-redirect" title="京津城際鐵路">京津城際鐵路</a>和<a href="/wiki/%E4%BA%AC%E6%BB%AC%E9%AB%98%E9%80%9F%E9%90%B5%E8%B7%AF" class="mw-redirect" title="京滬高速鐵路">京滬高速鐵路</a>的起點和終點站。<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%814%E5%8F%B7%E7%BA%BF" title="北京地铁4号线">北京地鐵4號线</a>接駁<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E7%AB%99" title="北京南站">北京南站</a>地下月臺,可以實現無縫換乘,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%8114%E5%8F%B7%E7%BA%BF" title="北京地铁14号线">北京地铁14号线</a>亦途径北京南站。<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8C%97%E7%AB%99" title="北京北站">北京北站</a>主要负责<a href="/wiki/%E4%BA%AC%E5%8C%85%E5%AE%A2%E8%BF%90%E4%B8%93%E7%BA%BF" title="京包客运专线">京包客运专线</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E9%83%8A%E9%93%81%E8%B7%AF" title="北京市郊铁路">北京市郊铁路</a>的旅客列车客运业务,也是西直門交通樞紐的重要組成部分。在北京北站可以换乘北京地铁2号线、4号线和13号线。
</p><p>北京市其他主要铁路客运站還有<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%9C%E7%AB%99" title="北京东站">北京東站</a>、<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%97%E7%AB%99" title="昌平北站">昌平北站</a>、<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%97%E7%AB%99" title="怀柔北站">怀柔北站</a>、<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%97%E7%AB%99" title="密云北站">密云北站</a>、<a href="/wiki/%E9%80%9A%E5%B7%9E%E8%A5%BF%E7%AB%99" title="通州西站">通州西站</a>、<a href="/wiki/%E9%BB%84%E6%9D%91%E7%AB%99_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="黄村站 (北京市)">黃村站</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E7%AB%99" title="北京大兴站">北京大兴站</a>、<a href="/wiki/%E5%A4%A7%E5%85%B4%E6%9C%BA%E5%9C%BA%E7%AB%99" title="大兴机场站">大兴机场站</a>等车站。
在北京乘坐列车与购买火车票十分便捷,火车票代售点的数量为全中国第二,僅次於<a href="/wiki/%E5%BB%A3%E6%9D%B1%E7%9C%81" class="mw-redirect" title="廣東省">廣東省</a><sup id="cite_ref-127" class="reference"><a href="#cite_note-127">[120]</a></sup>,在各火車站还设有自动售取票机以方便旅客购买火车票和打印网络购买的火车票。持有第二代<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%B1%85%E6%B0%91%E8%BA%AB%E4%BB%BD%E8%AF%81" title="中华人民共和国居民身份证">中华人民共和国居民身份证</a>、<a href="/wiki/%E6%B8%AF%E6%BE%B3%E5%8F%B0%E5%B1%85%E6%B0%91%E5%B1%85%E4%BD%8F%E8%AF%81" title="港澳台居民居住证">港澳台居民居住证</a>、<a href="/wiki/%E5%A4%96%E5%9B%BD%E4%BA%BA%E6%B0%B8%E4%B9%85%E5%B1%85%E7%95%99%E8%BA%AB%E4%BB%BD%E8%AF%81" class="mw-redirect" title="外国人永久居留身份证">外国人永久居留身份证</a>的旅客也可直接在北京开行高铁、城际、动车组列车的火车站刷相应的证件乘坐高铁列车(G字头车次)、城际列车(C字头车次)和动车组列车(D字头车次),而无需持纸质火车票乘车。
</p><p>北京是<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B" class="mw-redirect" title="中華人民共和國">中国</a>第一座建设<a href="/wiki/%E5%9C%B0%E9%93%81" class="mw-redirect" title="地铁">地铁</a>的城市,始建于1965年7月1日。截止2019年底,<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">北京地铁</a>共有22条运营线路(包括2条机场轨道),
线路全长699<a href="/wiki/%E5%85%AC%E9%87%8C" title="公里">公里</a><sup id="cite_ref-19年公报_120-1" class="reference"><a href="#cite_note-19年公报-120">[113]</a></sup>,运营车站339座(换乘站不重复计算)。北京地鐵日均客流量突破1000萬人,并且在2017年4月28日创下单日客运量最高值,达到1280.27万人次,为世界最为繁忙的<a href="/wiki/%E5%9F%8E%E5%B8%82%E8%BD%A8%E9%81%93%E4%BA%A4%E9%80%9A%E7%B3%BB%E7%BB%9F" class="mw-redirect" title="城市轨道交通系统">城市轨道交通系统</a><sup id="cite_ref-128" class="reference"><a href="#cite_note-128">[121]</a></sup>。北京地鐵正在進行大規模建設,预计到2021年全市<a href="/wiki/%E8%BB%8C%E9%81%93%E4%BA%A4%E9%80%9A" class="mw-redirect" title="軌道交通">轨道交通</a>总里程将超过1000公里。
</p>
<h4><span id=".E8.88.AA.E7.A9.BA"></span><span class="mw-headline" id="航空">航空</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=19" title="编辑章节:航空">编辑</a><span class="mw-editsection-bracket">]</span></span></h4>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="北京機場">北京機場</a></div>
<div class="thumb tright"><div class="thumbinner" style="width:222px;"><a href="/wiki/File:Beijing_Capital_International_Airport_Terminal_2_20120915.JPG" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Beijing_Capital_International_Airport_Terminal_2_20120915.JPG/220px-Beijing_Capital_International_Airport_Terminal_2_20120915.JPG" decoding="async" width="220" height="138" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Beijing_Capital_International_Airport_Terminal_2_20120915.JPG/330px-Beijing_Capital_International_Airport_Terminal_2_20120915.JPG 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Beijing_Capital_International_Airport_Terminal_2_20120915.JPG/440px-Beijing_Capital_International_Airport_Terminal_2_20120915.JPG 2x" data-file-width="2560" data-file-height="1600" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Beijing_Capital_International_Airport_Terminal_2_20120915.JPG" class="internal" title="放大"></a></div>北京首都国际机场2号航站楼外观</div></div></div>
<div class="thumb tright"><div class="thumbinner" style="width:222px;"><a href="/wiki/File:Beijing_New_Airport.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Beijing_New_Airport.jpg/220px-Beijing_New_Airport.jpg" decoding="async" width="220" height="124" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Beijing_New_Airport.jpg/330px-Beijing_New_Airport.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Beijing_New_Airport.jpg/440px-Beijing_New_Airport.jpg 2x" data-file-width="5272" data-file-height="2962" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Beijing_New_Airport.jpg" class="internal" title="放大"></a></div>北京大興國際機場於2019年9月25日正式投入營運,為北京市的第二座国际机场</div></div></div>
<p><a href="/wiki/%E5%8C%97%E4%BA%AC%E9%A6%96%E9%83%BD%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="北京首都國際機場">北京首都國際機場</a>是中國地理位置重要的機場之一,位於顺義區(行政上由順義和朝陽二區共管),距離北京城區20公里。也是該市重要門戶,目前有三個航站、三條跑道、雙塔台、設計客運量為8200萬人次。幾經擴建,首都機場的第三航廈為目前世界第二大的單體<a href="/wiki/%E8%88%AA%E5%BB%88" class="mw-redirect" title="航廈">航廈</a><sup id="cite_ref-129" class="reference"><a href="#cite_note-129">[122]</a></sup>,同時也是中國國內擁有三條跑道的三個<a href="/wiki/%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="國際機場">國際機場</a>之一(另兩個為<a href="/wiki/%E4%B8%8A%E6%B5%B7%E6%B5%A6%E6%9D%B1%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="上海浦東國際機場">上海浦東國際機場</a>、<a href="/wiki/%E5%BB%A3%E5%B7%9E%E7%99%BD%E9%9B%B2%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="廣州白雲國際機場">廣州白雲國際機場</a>)<sup id="cite_ref-130" class="reference"><a href="#cite_note-130">[123]</a></sup>,作为中国四大门户枢纽机场之首,北京首都國際機場每天有超過70家航空公司的1,400個航班,與世界191個城市串聯。
2018年数据统计,首都机场旅客吞吐量超过1亿人次,为客運量居亚洲第一、世界第二的單一機場,如果以城市來看,略少於上海國內線<a href="/wiki/%E8%99%B9%E6%A9%8B%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="虹橋機場">虹橋機場</a>和國際線<a href="/wiki/%E6%B5%A6%E6%9D%B1%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="浦東機場">浦東機場</a>的運量總和(1.2亿人次),以及東京國內線<a href="/wiki/%E7%BE%BD%E7%94%B0%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="羽田機場">羽田機場</a>和國際線<a href="/wiki/%E6%88%90%E7%94%B0%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="成田機場">成田機場</a>的運量總和(1億700萬)。
</p><p><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA" title="北京大兴国际机场">北京大兴国际机场</a>是北京市的第二个国际机场,为华北地区重要的国际机场,位於<a href="/wiki/%E5%A4%A7%E8%88%88%E5%8D%80" class="mw-redirect" title="大興區">大興區</a>(行政上由<a class="mw-selflink selflink">北京市</a><a href="/wiki/%E5%A4%A7%E8%88%88%E5%8D%80" class="mw-redirect" title="大興區">大興區</a>和<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北省</a><a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">廊坊市</a>共管),距離北京城區46公里。大興機場目前擁有世界最大的單體<a href="/wiki/%E8%88%AA%E5%BB%88" class="mw-redirect" title="航廈">航廈</a>。大興機場將定位為大型國際航空樞紐,目前共有4條營運中的跑道(據遠程規劃將擴建至6條跑道),滿足年旅客吞吐量一億人次需求。机场及各項配套工程于2019年6月30日竣工验收,同年9月25日投入營運。
</p><p>除此之外,北京市另有數個規模相對較小的機場,包括:
</p>
<ul><li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E8%8B%91%E6%A9%9F%E5%A0%B4" class="mw-redirect" title="北京南苑機場">北京南苑機場</a>:建於1910年,位北京南郊,距市中心12公里,曾是中國聯合航空作为基地运营少量民航班机的军民两用機場,在大兴机场启用后已关闭。</li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E9%83%8A%E6%A9%9F%E5%A0%B4" title="北京西郊機場">北京西郊機場</a>:軍用機場,供中國國家領導人、黨政軍要員使用,不對民眾開放。</li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%89%AF%E4%B9%A1%E6%9C%BA%E5%9C%BA" title="北京良乡机场">北京良鄉機場</a>:軍用機場,規劃改為軍民貨運機場。</li></ul>
<h4><span id=".E5.9C.B0.E9.9D.A2.E5.85.AC.E4.BA.A4"></span><span class="mw-headline" id="地面公交">地面公交</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=20" title="编辑章节:地面公交">编辑</a><span class="mw-editsection-bracket">]</span></span></h4>
<p>為緩解城市<a href="/wiki/%E4%BA%A4%E9%80%9A%E6%8B%A5%E5%A0%B5" class="mw-redirect" title="交通拥堵">交通擁堵</a>問題及改善空氣質量,北京市自2005年起開始制定並實施優先發展<a href="/wiki/%E5%85%AC%E5%85%B1%E4%BA%A4%E9%80%9A" title="公共交通">公共交通</a>的政策<sup id="cite_ref-131" class="reference"><a href="#cite_note-131">[124]</a></sup>。
</p><p>1899年北京修建了中國第一條<a href="/wiki/%E6%9C%89%E8%BB%8C%E9%9B%BB%E8%BB%8A" title="有軌電車">有軌電車</a>,1935年又開闢了第一條<a href="/wiki/%E5%85%AC%E5%85%B1%E6%B1%BD%E8%BB%8A" title="公共汽車">公共汽車</a>线路,1956年開通第一條<a href="/wiki/%E7%84%A1%E8%BB%8C%E9%9B%BB%E8%BB%8A" title="無軌電車">無軌電車</a>線路。經過長期,尤其是近年快速的發展,北京公交已擁有各类运营车辆近3万辆,运营线路1158條(2019年),线网总长27632公里(2019年<sup id="cite_ref-19年公报_120-2" class="reference"><a href="#cite_note-19年公报-120">[113]</a></sup>),年总行驶里程17.53亿公里(2011年),总客运量客运总量48.88亿人次(2011年數據)。
</p>
<h4><span id=".E5.87.BA.E7.A7.9F.E8.BD.A6"></span><span class="mw-headline" id="出租车">出租车</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=21" title="编辑章节:出租车">编辑</a><span class="mw-editsection-bracket">]</span></span></h4>
<p>据统计,截至2006年4月,北京市黑车的数量甚至已经超过了合法的出租车数量<sup id="cite_ref-132" class="reference"><a href="#cite_note-132">[125]</a></sup>。2020年,北京市出租车总数约为7万辆<sup id="cite_ref-133" class="reference"><a href="#cite_note-133">[126]</a></sup>。
</p>
<h4><span id=".E9.82.AE.E7.94.B5"></span><span class="mw-headline" id="邮电">邮电</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=22" title="编辑章节:邮电">编辑</a><span class="mw-editsection-bracket">]</span></span></h4>
<p>2015年全年,北京货运量28765.2万吨,客运量69923.1万人。年末全市机动车保有量561.9万辆,民用汽车535万辆。其中,私人汽车440.3万辆,私人汽车中轿车316.5万辆。全年实现邮电业务总量990.9亿元。其中,邮政业务总量67.8亿元,电信业务总量923亿元。全年发送邮政函件6.1亿件,特快专递14.1亿件。年末固定电话用户达到784.6万户,固定电话主线普及率达到36.1线/百人。年末移动电话用户达到4051.9万户,移动电话普及率达到186.7户/百人。年末固定互联网宽带接入用户数达到469.1万户。<sup id="cite_ref-2015公报_114-1" class="reference"><a href="#cite_note-2015公报-114">[108]</a></sup>
</p>
<h3><span id=".E6.97.85.E6.B8.B8.E6.A5.AD"></span><span class="mw-headline" id="旅游業">旅游業</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=23" title="编辑章节:旅游業">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<div role="note" class="hatnote navigation-not-searchable">参见:<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9%E5%88%97%E8%A1%A8" title="北京旅游景点列表">北京旅游景点列表</a></div>
<p>北京市拥有丰富的旅游资源,包括2处<a href="/wiki/%E5%9B%BD%E5%AE%B6%E9%87%8D%E7%82%B9%E9%A3%8E%E6%99%AF%E5%90%8D%E8%83%9C%E5%8C%BA" class="mw-redirect" title="国家重点风景名胜区">国家重点风景名胜区</a>、1座<a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="国家历史文化名城">国家历史文化名城</a>、1座<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E6%9D%91" title="中国历史文化名村">中国历史文化名村</a>、99处<a href="/wiki/%E5%85%A8%E5%9B%BD%E9%87%8D%E7%82%B9%E6%96%87%E7%89%A9%E4%BF%9D%E6%8A%A4%E5%8D%95%E4%BD%8D" title="全国重点文物保护单位">全国重点文物保护单位</a>(含<a href="/wiki/%E9%95%BF%E5%9F%8E" title="长城">长城</a>和<a href="/wiki/%E4%BA%AC%E6%9D%AD%E5%A4%A7%E8%BF%90%E6%B2%B3" title="京杭大运河">京杭大运河</a>的北京段)、326处<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E6%96%87%E7%89%A9%E4%BF%9D%E6%8A%A4%E5%8D%95%E4%BD%8D" title="北京市文物保护单位">市级文物保护单位</a>等。全市共有7处<a href="/wiki/%E4%B8%96%E7%95%8C%E9%81%97%E4%BA%A7" title="世界遗产">世界遗产</a>,是世界上世界遗产最多的城市。这七处是:<a href="/wiki/%E9%95%BF%E5%9F%8E" title="长城">长城</a>、明清皇家宫殿的<a href="/wiki/%E6%95%85%E5%AE%AB" title="故宫">故宫</a>、北京的皇家园林的<a href="/wiki/%E9%A2%90%E5%92%8C%E5%9B%AD" title="颐和园">颐和园</a>、北京的皇家祭坛的<a href="/wiki/%E5%A4%A9%E5%9D%9B" title="天坛">天坛</a>、<a href="/wiki/%E6%98%8E%E6%B8%85%E7%9A%87%E5%AE%B6%E9%99%B5%E5%AF%9D" title="明清皇家陵寝">明清皇家陵寝</a>的<a href="/wiki/%E5%8D%81%E4%B8%89%E9%99%B5" class="mw-redirect" title="十三陵">十三陵</a>、<a href="/wiki/%E5%91%A8%E5%8F%A3%E5%BA%97" class="mw-redirect" title="周口店">周口店</a>北京猿人遗址以及<a href="/wiki/%E4%BA%AC%E6%9D%AD%E5%A4%A7%E8%BF%90%E6%B2%B3" title="京杭大运河">京杭大运河</a>。北京市于2018年全面启动<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E8%BD%B4%E7%BA%BF" title="北京中轴线">中轴线</a>整治规划,计划于2030年将<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E8%BD%B4%E7%BA%BF" title="北京中轴线">北京城中轴线</a>申报<a href="/wiki/%E4%B8%96%E7%95%8C%E6%96%87%E5%8C%96%E9%81%97%E4%BA%A7" class="mw-redirect" title="世界文化遗产">世界文化遗产</a>。国家重点风景名胜区有<a href="/wiki/%E5%85%AB%E8%BE%BE%E5%B2%AD" title="八达岭">八达岭</a>的<a href="/wiki/%E5%8D%81%E4%B8%89%E9%99%B5" class="mw-redirect" title="十三陵">十三陵</a>、<a href="/w/index.php?title=%E7%9F%B3%E8%8A%B1%E6%B4%9E&action=edit&redlink=1" class="new" title="石花洞(页面不存在)">石花洞</a>。中国历史文化名村有门头沟区斋堂镇的<a href="/wiki/%E7%88%A8%E5%BA%95%E4%B8%8B%E6%9D%91" title="爨底下村">爨底下村</a>。
</p>
<h2><span id=".E6.95.99.E8.82.B2"></span><span class="mw-headline" id="教育">教育</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=24" title="编辑章节:教育">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">参见:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E9%AB%98%E7%AD%89%E5%AD%A6%E6%A0%A1%E5%88%97%E8%A1%A8" title="北京市高等学校列表">北京市高等学校列表</a>和<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E7%A4%BA%E8%8C%83%E9%AB%98%E4%B8%AD" title="北京市示范高中">北京市示范高中</a></div>
<p>北京作為<a href="/wiki/%E5%85%83%E4%BB%A3" class="mw-redirect" title="元代">元</a><a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">明</a><a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">清</a>三代的京城,中國官方最高<a href="/wiki/%E5%AD%A6%E5%BA%9C" class="mw-redirect" title="学府">學府</a>和國家管理<a href="/wiki/%E6%95%99%E8%82%B2" title="教育">教育</a>的最高行政機構——<a href="/wiki/%E5%9C%8B%E5%AD%90%E7%9B%A3" class="mw-redirect" title="國子監">國子監</a>自1306年起就設在北京。
</p><p>至近代,<a href="/wiki/%E4%B8%AD%E5%9C%8B%E6%95%99%E8%82%B2%E5%8F%B2" class="mw-redirect" title="中國教育史">新式教育</a>興起,<a href="/wiki/%E5%9C%8B%E5%AD%90%E7%9B%A3" class="mw-redirect" title="國子監">國子監</a>和<a href="/wiki/%E7%A7%91%E8%88%89%E5%88%B6%E5%BA%A6" class="mw-redirect" title="科舉制度">科舉制度</a>被取消,而1898年中国近代第一所国立综合性大学<a href="/wiki/%E4%BA%AC%E5%B8%88%E5%A4%A7%E5%AD%A6%E5%A0%82" title="京师大学堂">京師大學堂</a>(今<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%B8" class="mw-redirect" title="北京大學">北京大學</a>)在北京成立<sup id="cite_ref-134" class="reference"><a href="#cite_note-134">[127]</a></sup>,同時行使全国最高教育行政机关的職能,取代了<a href="/wiki/%E5%9C%8B%E5%AD%90%E7%9B%A3" class="mw-redirect" title="國子監">國子監</a>的地位。民國時期,北京(北平)雖有一段時間不再作為<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中國</a>的<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">首都</a>,但仍是中国的文化教育中心<sup id="cite_ref-135" class="reference"><a href="#cite_note-135">[128]</a></sup>。
</p><p>時至今日,北京是中國擁有最多<a href="/wiki/%E9%AB%98%E7%AD%89%E9%99%A2%E6%A0%A1" class="mw-redirect" title="高等院校">高等院校</a>的城市,聚集了眾多著名<a href="/wiki/%E5%A4%A7%E5%AD%A6" class="mw-redirect" title="大学">大学</a>,更具有包括<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%B8" class="mw-redirect" title="北京大學">北京大學</a>、<a href="/wiki/%E6%B8%85%E8%8F%AF%E5%A4%A7%E5%AD%B8" class="mw-redirect" title="清華大學">清華大學</a>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E7%A7%91%E5%AD%A6%E9%99%A2%E5%A4%A7%E5%AD%A6" title="中国科学院大学">中国科学院大学</a>在内的幾所國際知名的高等學府。據統計,2009-2010年度北京共有<a href="/wiki/%E6%99%AE%E9%80%9A%E9%AB%98%E7%AD%89%E9%99%A2%E6%A0%A1" class="mw-redirect" title="普通高等院校">普通高等院校</a>88所(其中民办普通高校15所),<a href="/wiki/%E7%A0%94%E7%A9%B6%E7%94%9F" title="研究生">研究生</a>培养机构169家。
</p>
<h2><span id=".E4.BA.BA.E5.8F.A3"></span><span class="mw-headline" id="人口">人口</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=25" title="编辑章节:人口">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E4%BA%BA%E5%8F%A3&action=edit&redlink=1" class="new" title="北京人口(页面不存在)">北京人口</a></div>
<table class="toccolours" style="width:15em;border-spacing: 0;float:right;clear:right;margin:0.5em 0 1em 0.5em;"><tbody><tr><th class="navbox-title" colspan="3" style="padding:0.1em 0.25em;font-size:110%">歷史人口</th></tr><tr style="font-size:95%"><th style="border-bottom:1px solid black;padding:1px;width:3em">年份</th><th style="border-bottom:1px solid black;padding:1px 2px;text-align:right">人口</th><th style="border-bottom:1px solid black;padding:1px;text-align:right"><abbr title="百分比变化">±%</abbr></th></tr><tr><th style="text-align:center;padding:1px"><a href="/wiki/1953%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" class="mw-redirect" title="1953年中国大陆人口普查">1953</a></th><td style="text-align:right;padding:1px">2,768,149</td><td style="text-align:right;padding:1px">—    </td></tr><tr><th style="text-align:center;padding:1px"><a href="/wiki/1964%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" class="mw-redirect" title="1964年中国大陆人口普查">1964</a></th><td style="text-align:right;padding:1px">7,568,495</td><td style="text-align:right;padding:1px">+173.4%</td></tr><tr><th style="text-align:center;padding:1px"><a href="/wiki/1982%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" class="mw-redirect" title="1982年中国大陆人口普查">1982</a></th><td style="text-align:right;padding:1px">9,230,663</td><td style="text-align:right;padding:1px">+22.0%</td></tr><tr><th style="text-align:center;padding:1px"><a href="/wiki/1990%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" class="mw-redirect" title="1990年中国大陆人口普查">1990</a></th><td style="text-align:right;padding:1px">10,819,414</td><td style="text-align:right;padding:1px">+17.2%</td></tr><tr><th style="text-align:center;padding:1px;border-bottom:1px solid #bbbbbb"><a href="/wiki/2000%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" class="mw-redirect" title="2000年中国大陆人口普查">2000</a></th><td style="text-align:right;padding:1px;border-bottom:1px solid #bbbbbb">13,569,194</td><td style="text-align:right;padding:1px;border-bottom:1px solid #bbbbbb">+25.4%</td></tr><tr><th style="text-align:center;padding:1px"><a href="/wiki/2010%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" class="mw-redirect" title="2010年中国大陆人口普查">2010</a></th><td style="text-align:right;padding:1px">19,612,368</td><td style="text-align:right;padding:1px">+44.5%</td></tr><tr><th style="text-align:center;padding:1px">2018</th><td style="text-align:right;padding:1px">21,542,000</td><td style="text-align:right;padding:1px">+9.8%</td></tr><tr><td colspan="3" style="border-top:1px solid black;font-size:85%;text-align:left">来源:历次人口普查、北京市统计局</td></tr></tbody></table>
<p>截至2018年底,北京市人口2154.2万人,比2017年底的2170.7有所下降<sup id="cite_ref-136" class="reference"><a href="#cite_note-136">[129]</a></sup>。北京居民的平均预期寿命为74岁。中国56个民族的人口都在北京。绝大多数人口属于汉族。回族,满族和蒙古族人口分别超过1万人<sup id="cite_ref-137" class="reference"><a href="#cite_note-137">[130]</a></sup>。
</p>
<table class="wikitable sortable floatright" style="font-size:smaller;">
<caption><b>北京市各区人口数据(2017年末)</b><sup id="cite_ref-138" class="reference"><a href="#cite_note-138">[131]</a></sup>
</caption>
<tbody><tr>
<th class="unsortable" rowspan="2">区划名称
</th>
<th colspan="3">常住人口
</th>
<th rowspan="2">户籍人口<br />(万人)
</th></tr>
<tr>
<th style="width:60px;">总计<br />(万人)
</th>
<th style="width:50px;">比重<br />(%)
</th>
<th style="width:70px;">每平方公里<br />人口密度
</th></tr>
<tr style="text-align:right; font-weight:bold;">
<th>北京市
</th>
<td>2170.7</td>
<td>100</td>
<td>1323</td>
<td>1359.2
</td></tr>
<tr style="text-align:right;">
<th>东城区
</th>
<td>85.1</td>
<td>3.92</td>
<td>20330</td>
<td>96.7
</td></tr>
<tr style="text-align:right;">
<th>西城区
</th>
<td>122.0</td>
<td>5.62</td>
<td>24144</td>
<td>145.0
</td></tr>
<tr style="text-align:right;">
<th>朝阳区
</th>
<td>373.9</td>
<td>17.22</td>
<td>8216</td>
<td>209.8
</td></tr>
<tr style="text-align:right;">
<th>丰台区
</th>
<td>218.6</td>
<td>10.07</td>
<td>7148</td>
<td>113.9
</td></tr>
<tr style="text-align:right;">
<th>石景山区
</th>
<td>61.2</td>
<td>2.82</td>
<td>7258</td>
<td>38.2
</td></tr>
<tr style="text-align:right;">
<th>海淀区
</th>
<td>348.0</td>
<td>16.03</td>
<td>8079</td>
<td>235.4
</td></tr>
<tr style="text-align:right;">
<th>门头沟区
</th>
<td>32.2</td>
<td>1.48</td>
<td>222</td>
<td>24.9
</td></tr>
<tr style="text-align:right;">
<th>房山区
</th>
<td>115.4</td>
<td>5.32</td>
<td>580</td>
<td>81.9
</td></tr>
<tr style="text-align:right;">
<th>通州区
</th>
<td>150.8</td>
<td>6.95</td>
<td>1664</td>
<td>76.9
</td></tr>
<tr style="text-align:right;">
<th>顺义区
</th>
<td>112.8</td>
<td>5.20</td>
<td>1106</td>
<td>63.5
</td></tr>
<tr style="text-align:right;">
<th>昌平区
</th>
<td>206.3</td>
<td>9.50</td>
<td>1535</td>
<td>61.9
</td></tr>
<tr style="text-align:right;">
<th>大兴区
</th>
<td>176.1</td>
<td>8.11</td>
<td>1699</td>
<td>69.9
</td></tr>
<tr style="text-align:right;">
<th>怀柔区
</th>
<td>40.5</td>
<td>1.87</td>
<td>191</td>
<td>28.4
</td></tr>
<tr style="text-align:right;">
<th>平谷区
</th>
<td>44.8</td>
<td>2.06</td>
<td>472</td>
<td>40.4
</td></tr>
<tr style="text-align:right;">
<th>密云区
</th>
<td>49.0</td>
<td>2.26</td>
<td>220</td>
<td>43.7
</td></tr>
<tr style="text-align:right;">
<th>延庆区
</th>
<td>34.0</td>
<td>1.57</td>
<td>171</td>
<td>28.5
</td></tr></tbody></table>
<p>截至2013年年末,北京市常住人口為2144.9萬人。按<a href="/wiki/%E6%88%B6%E7%B1%8D" class="mw-redirect" title="戶籍">戶籍</a>劃分,户籍人口1316.3万人,常住外来人口802.7万人(38%)。按城鄉劃分,城镇人口1825.1万人,占常住人口的86.3%。全市常住人口<a href="/wiki/%E5%87%BA%E7%94%9F%E7%8E%87" title="出生率">出生率</a>8.93‰,<a href="/wiki/%E6%AD%BB%E4%BA%A1%E7%8E%87" title="死亡率">死亡率</a>4.52‰,<a href="/wiki/%E4%BA%BA%E5%8F%A3%E8%87%AA%E7%84%B6%E5%A2%9E%E9%95%BF%E7%8E%87" title="人口自然增长率">自然增长率</a>4.41‰。全市常住人口密度为1289人/平方公里<sup id="cite_ref-139" class="reference"><a href="#cite_note-139">[132]</a></sup>。北京市第六次全国人口普查资料显示:首都功能核心区、城市功能拓展区、城市发展新区、生态涵养发展区的人口密度分别为每平方公里23407人、7488人、958人、213人<sup id="cite_ref-140" class="reference"><a href="#cite_note-140">[133]</a></sup>。
</p><p>北京人口以<a href="/wiki/%E6%BC%A2%E6%97%8F" class="mw-redirect" title="漢族">漢族</a>為大多數,但同時包含全<a href="/wiki/%E4%B8%AD%E5%9B%BD" class="mw-redirect" title="中国">中国</a>56个<a href="/wiki/%E4%B8%AD%E5%9C%8B%E6%B0%91%E6%97%8F%E5%88%97%E8%A1%A8" title="中國民族列表">民族</a>,北京是<a href="/wiki/%E4%B8%AD%E5%9B%BD" class="mw-redirect" title="中国">中国</a>第一个聚集起56个民族的城市,其中<a href="/wiki/%E5%B0%91%E6%95%B0%E6%B0%91%E6%97%8F" title="少数民族">少数民族</a>以<a href="/wiki/%E6%BB%A1%E6%97%8F" title="满族">满族</a>、<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">回族</a>及<a href="/wiki/%E8%92%99%E5%8F%A4%E6%97%8F" title="蒙古族">蒙古族</a>為最多,人口數均过万。據統計,2009年除<a href="/wiki/%E6%BC%A2%E6%97%8F" class="mw-redirect" title="漢族">漢族</a>外的<a href="/wiki/%E5%B0%91%E6%95%B0%E6%B0%91%E6%97%8F" title="少数民族">少数民族</a>人口約為48萬人,占北京市总人口数的3.84%。
</p><p>北京也有相當數目的<a href="/wiki/%E5%A4%96%E5%9C%8B%E4%BA%BA" title="外國人">外國人</a>在此居住,外國人社群聚集的區域包括<a href="/wiki/%E5%8C%97%E4%BA%ACCBD" class="mw-redirect" title="北京CBD">北京CBD</a>(商務中心區)、<a href="/wiki/%E4%B8%89%E9%87%8C%E5%B1%AF" class="mw-redirect" title="三里屯">三里屯</a>、<a href="/wiki/%E6%9C%9B%E4%BA%AC" title="望京">望京</a>和<a href="/wiki/%E4%BA%94%E9%81%93%E5%8F%A3" title="五道口">五道口</a>附近。其中僅在北京居住的<a href="/wiki/%E9%9F%93%E5%9C%8B" class="mw-redirect" title="韓國">韓國</a>人數目就達20萬(2009年估計數字)<sup id="cite_ref-141" class="reference"><a href="#cite_note-141">[134]</a></sup>。
</p><p>根据2006年人口数据,北京人口最多的首十个姓氏依次是<a href="/wiki/%E7%8E%8B%E5%A7%93" title="王姓">王</a>(10.35%)、<a href="/wiki/%E5%BC%A0%E5%A7%93" class="mw-redirect" title="张姓">张</a>(9.4%)、<a href="/wiki/%E6%9D%8E%E5%A7%93" title="李姓">李</a>(8.54%)、<a href="/wiki/%E5%88%98%E5%A7%93" title="刘姓">刘</a>(6.91%)、<a href="/wiki/%E8%B5%B5%E5%A7%93" class="mw-redirect" title="赵姓">赵</a>(3.45%)、<a href="/wiki/%E6%9D%A8%E5%A7%93" title="杨姓">杨</a>、<a href="/wiki/%E9%99%88%E5%A7%93" title="陈姓">陈</a>、<a href="/wiki/%E5%AD%99%E5%A7%93" title="孙姓">孙</a>、<a href="/wiki/%E9%AB%98%E5%A7%93" title="高姓">高</a>、<a href="/wiki/%E9%A9%AC%E5%A7%93" title="马姓">马</a>。这个排名与<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8C%97%E6%96%B9" class="mw-redirect" title="中国北方">中国北方</a>其他大城市相若。
</p><p><a href="/wiki/%E5%8C%97%E6%BC%82%E6%97%8F" class="mw-redirect" title="北漂族">北漂族</a>是指来自非北京地区的、非北京户口、在北京生活和工作的外地人。北漂族在来京初期都很少有固定的住所,搬来搬去的,给人漂乎不定的感觉,其自身也因诸多原因而不能对于北京有更多的认同感,故此得名。
</p><p>如今北京市正面临着非常严重的人口问题。官方的调查报告指出,北京目前的人口规模已经超过了北京地区环境资源的承载极限,水、电、气、热、煤的供应常年紧张,特别是水资源短缺已经到了十分严重的程度,甚至以至于需要调用应急战略储备水源才能满足城市供水需要。粮油酱醋等生活必需品绝大部分亦需从外省调入,稳定保障供给的难度很大。且按照目前北京市的垃圾产量,全市之垃圾场将会在4-5年内全部被填满。同时引发的交通、住房、医疗、教育等问题也使整个城市不堪重负<sup id="cite_ref-142" class="reference"><a href="#cite_note-142">[135]</a></sup>。
</p><p>根据人口普查和抽查,北京市1995年以来一直是全国<a href="/wiki/%E6%80%BB%E5%92%8C%E7%94%9F%E8%82%B2%E7%8E%87" title="总和生育率">总和生育率</a>最低的一級行政區。2000年以来,北京市总和生育率处于0.66和0.71之间,不到世代更替水平的三分之一,不仅低于中国其他省份,但不少數據只計算擁有<a href="/wiki/%E6%88%B6%E7%B1%8D" class="mw-redirect" title="戶籍">戶籍</a>的北京人口。
</p>
<h2><span id=".E6.96.87.E5.8C.96"></span><span class="mw-headline" id="文化">文化</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=26" title="编辑章节:文化">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<p>北京是有着千年历史的<a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" class="mw-redirect" title="中国文化名城">中国文化名城</a>,同时也是现代中国的文化中心。北京聚集着全中国最重要的<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8D%9A%E7%89%A9%E9%A6%86%E5%88%97%E8%A1%A8" title="北京市博物馆列表">几座博物馆</a>,这些博物館涵蓋了中国悠久的历史知識及其與現在和未來的關聯。有些博物館则涵蓋了某些特定的策展範圍或是某一特定地區,有的則較為籠統。其中,<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%8D%9A%E7%89%A9%E9%A6%86" title="中国国家博物馆">中国国家博物馆</a><sup id="cite_ref-143" class="reference"><a href="#cite_note-143">[136]</a></sup><sup id="cite_ref-144" class="reference"><a href="#cite_note-144">[137]</a></sup>、<a href="/wiki/%E9%A6%96%E9%83%BD%E5%8D%9A%E7%89%A9%E9%A6%86" title="首都博物馆">首都博物馆</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%87%AA%E7%84%B6%E5%8D%9A%E7%89%A9%E9%A6%86" title="北京自然博物馆">北京自然博物館</a><sup id="cite_ref-145" class="reference"><a href="#cite_note-145">[138]</a></sup>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9C%B0%E8%B4%A8%E5%8D%9A%E7%89%A9%E9%A6%86" title="中国地质博物馆">中國地質博物館</a>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%88%AA%E7%A9%BA%E5%8D%9A%E7%89%A9%E9%A6%86" title="中国航空博物馆">中國航空博物館</a>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E7%A7%91%E5%AD%A6%E6%8A%80%E6%9C%AF%E9%A6%86" title="中国科学技术馆">中國科學技術館</a>、<a href="/wiki/%E6%95%85%E5%AE%AE%E5%8D%9A%E7%89%A9%E9%99%A2" class="mw-redirect" title="故宮博物院">故宮博物院</a><sup id="cite_ref-146" class="reference"><a href="#cite_note-146">[139]</a></sup>以其丰富的馆藏和典藏的权威而知名海内外,并吸引着众多的游客前来观摩欣赏。截至2014年底,北京市共有在北京市文物局註冊登記的博物館171家<sup id="cite_ref-147" class="reference"><a href="#cite_note-147">[140]</a></sup>。
</p>
<div class="thumb tnone" style="margin-left:auto;margin-right:auto;overflow:hidden;width:auto;max-width:1608px"><div class="thumbinner"><div class="noresize" style="overflow:auto;direction:rtl"><a href="/wiki/File:The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg" class="image" title="现藏于北京故宫博物院的王献之《中秋帖》卷"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg/1600px-The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg" decoding="async" width="1600" height="137" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg/2400px-The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e6/The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg/3200px-The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg 2x" data-file-width="6219" data-file-height="531" /></a></div><div class="thumbcaption"><div class="magnify"><a href="/wiki/File:The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg" title="File:The Calligraphy Model Mid-Autumn by Wang Xianzhi.jpg"> </a></div>现藏于北京<a href="/wiki/%E6%95%85%E5%AE%AB%E5%8D%9A%E7%89%A9%E9%99%A2" title="故宫博物院">故宫博物院</a>的<a href="/wiki/%E7%8E%8B%E7%8C%AE%E4%B9%8B" title="王献之">王献之</a>《<a href="/wiki/%E4%B8%AD%E7%A7%8B%E5%B8%96" title="中秋帖">中秋帖</a>》卷</div></div></div>
<h3><span id=".E6.96.87.E5.AD.A6"></span><span class="mw-headline" id="文学">文学</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=27" title="编辑章节:文学">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E4%BA%AC%E6%B4%BE" title="京派">京派</a></div>
<p>北京<a href="/wiki/%E4%BD%9C%E5%AE%B6" title="作家">作家</a>辈出,由此诞生名为<a href="/wiki/%E4%BA%AC%E6%B4%BE" title="京派">京派</a>的文学流派,并与以<a href="/wiki/%E4%B8%8A%E6%B5%B7" class="mw-redirect" title="上海">上海</a>为根据地的<a href="/wiki/%E6%B5%B7%E6%B4%BE_(%E6%96%87%E8%97%9D)" title="海派 (文藝)">海派</a>相对。京派文学家描寫的內容主要是人生,同時避談<a href="/wiki/%E6%94%BF%E6%B2%BB" title="政治">政治</a>。京派強調文學是純文學,要「和諧」、「節制」、「恰當」,包含<a href="/wiki/%E7%8F%BE%E5%AF%A6%E4%B8%BB%E7%BE%A9" class="mw-redirect" title="現實主義">現實主義</a>和<a href="/wiki/%E6%B5%AA%E6%BC%AB%E4%B8%BB%E7%BE%A9" class="mw-redirect" title="浪漫主義">浪漫主義</a>。京派的風格淳樸自然,回歸田園,寫人情美和人性美,融合鄉土文化,而語言則簡練、樸素、活潑、明淨。
</p><p>著名的京派<a href="/wiki/%E6%96%87%E5%AD%A6%E5%AE%B6" class="mw-redirect" title="文学家">文學家</a>有<a href="/wiki/%E7%B4%8D%E8%98%AD%E6%80%A7%E5%BE%B7" class="mw-redirect" title="納蘭性德">納蘭性德</a>、<a href="/wiki/%E7%BA%AA%E6%99%93%E5%B2%9A" class="mw-redirect" title="纪晓岚">纪晓岚</a>、<a href="/wiki/%E8%80%81%E8%88%8D" title="老舍">老舍</a>、<a href="/wiki/%E6%9E%97%E8%AF%AD%E5%A0%82" title="林语堂">林语堂</a>、<a href="/wiki/%E6%9E%97%E6%B5%B7%E9%9F%B3" title="林海音">林海音</a>、<a href="/wiki/%E7%AB%AF%E6%9C%A8%E8%95%BB%E8%89%AF" title="端木蕻良">端木蕻良</a>、<a href="/wiki/%E8%B4%9D%E5%AD%90" class="mw-redirect" title="贝子">贝子</a>、<a href="/wiki/%E5%94%90%E9%AD%AF%E5%AD%AB" title="唐魯孫">唐鲁孙</a>等。
</p><p>随着<a href="/wiki/%E5%8D%8E%E8%AF%AD" class="mw-redirect" title="华语">华语</a>文坛的发展和<a href="/wiki/%E4%B8%AD%E6%96%87" class="mw-redirect" title="中文">中文</a>的国际化,越来越多的华语作家包括<a href="/wiki/%E7%8E%8B%E8%92%99_(%E4%BD%9C%E5%AE%B6)" title="王蒙 (作家)">王蒙</a>、<a href="/wiki/%E6%B5%B7%E5%B2%A9" title="海岩">海岩</a>、<a href="/wiki/%E5%86%AF%E5%94%90_(%E4%BD%9C%E5%AE%B6)" title="冯唐 (作家)">冯唐</a>、<a href="/wiki/%E6%AD%A5%E9%9D%9E%E7%83%9F_(%E4%BD%9C%E5%AE%B6)" title="步非烟 (作家)">步非烟</a>、<a href="/wiki/%E6%B1%9F%E5%8D%97_(%E5%B0%8F%E8%AF%B4%E5%AE%B6)" title="江南 (小说家)">江南</a>和<a href="/wiki/%E5%AE%89%E6%84%8F%E5%A6%82" title="安意如">安意如</a>等,纷纷选择北京作为创作的中心,谱写众多优秀的中文文学。
</p>
<h3><span id=".E9.A5.AE.E9.A3.9F.E6.96.87.E5.8C.96"></span><span class="mw-headline" id="饮食文化">饮食文化</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=28" title="编辑章节:饮食文化">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<div class="thumb tright"><div class="thumbinner" style="width:222px;"><a href="/wiki/File:Beijing_DUck_sliced.jpeg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/24/Beijing_DUck_sliced.jpeg/220px-Beijing_DUck_sliced.jpeg" decoding="async" width="220" height="165" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/24/Beijing_DUck_sliced.jpeg/330px-Beijing_DUck_sliced.jpeg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/24/Beijing_DUck_sliced.jpeg/440px-Beijing_DUck_sliced.jpeg 2x" data-file-width="4032" data-file-height="3024" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Beijing_DUck_sliced.jpeg" class="internal" title="放大"></a></div>片好装盘的<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%83%A4%E9%B8%AD" title="北京烤鸭">北京烤鸭</a></div></div></div>
<p>現今的<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%8F%9C" class="mw-redirect" title="北京菜">北京菜</a>是由<a href="/wiki/%E9%AD%AF%E8%8F%9C" class="mw-redirect" title="魯菜">魯菜</a>、市肆菜、<a href="/wiki/%E8%AD%9A%E5%AE%B6%E8%8F%9C" class="mw-redirect" title="譚家菜">譚家菜</a>、<a href="/wiki/%E6%B8%85%E7%9C%9F%E8%8F%9C" title="清真菜">清真菜</a>和<a href="/wiki/%E5%AE%AE%E5%BB%B7%E8%8F%9C" title="宮廷菜">宮廷菜</a>五種風味的菜餚进行<a href="/wiki/%E5%8C%97%E4%BA%AC" class="mw-redirect" title="北京">北京</a>風味本地化后組合而成。<sup id="cite_ref-148" class="reference"><a href="#cite_note-148">[141]</a></sup>早期北京与<a href="/wiki/%E5%B1%B1%E6%9D%B1" class="mw-redirect" title="山東">山東</a>飲食習慣頗為相似,所以较多山东厨师,因而魯菜是京菜的基調。到了<a href="/wiki/%E8%BE%BD%E4%BB%A3" class="mw-redirect" title="辽代">遼代</a>及<a href="/wiki/%E5%85%83%E4%BB%A3" class="mw-redirect" title="元代">元代</a>之後,由於北京<a href="/wiki/%E8%92%99%E5%8F%A4%E6%97%8F" title="蒙古族">蒙古族</a>、<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">回族</a>等北方民族逐渐增多,京菜的風味受到其影響,因而增加了烹製<a href="/wiki/%E7%BE%8A%E8%82%89" title="羊肉">羊肉</a>菜餚的特點。至<a href="/wiki/%E6%98%8E%E4%BB%A3" class="mw-redirect" title="明代">明</a><a href="/wiki/%E6%B8%85" class="mw-redirect" title="清">清</a>兩代时,北京是全國的政經及文化中心,宮廷御廚和大臣的厨房都集中在北京,<a href="/wiki/%E7%83%B9%E8%B0%83" class="mw-redirect" title="烹调">烹調</a>技術也就不斷地提升,因此,全國各地主要的飲食風味也隨著齊聚於北京。北京菜肴烹調方法非常多元,以爆、<a href="/wiki/%E7%83%A4" title="烤">烤</a>、<a href="/wiki/%E6%B6%AE" title="涮">涮</a>、<a href="/wiki/%E6%BA%9C" title="溜">溜</a>、<a href="/wiki/%E7%82%B8" title="炸">炸</a>、<a href="/wiki/%E7%83%A7_(%E7%82%96%E7%85%AE%E6%B3%95)" class="mw-redirect" title="烧 (炖煮法)">燒</a>、<a href="/wiki/%E7%82%92" title="炒">炒</a>、<a href="/wiki/%E6%89%92" title="扒">扒</a>、<a href="/wiki/%E7%85%A8" title="煨">煨</a>、<a href="/wiki/%E7%84%96" class="mw-redirect" title="焖">燜</a>、<a href="/wiki/%E9%86%AC" title="醬">醬</a>、<a href="/wiki/%E6%8B%94%E4%B8%9D" title="拔丝">拔絲</a>、白煮等技法見長。其中的“爆”法,變化多樣,可分為油爆、醬爆、蔥爆、水爆、湯爆等。口味講究酥脆鮮嫩,清鮮爽口,且要做到色、香、味、形、器等五面俱全<sup id="cite_ref-149" class="reference"><a href="#cite_note-149">[142]</a></sup>。著名京菜有<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%83%A4%E9%B8%AD" title="北京烤鸭">北京烤鸭</a>、蔥爆豬肉、<a href="/wiki/%E4%BA%AC%E9%85%B1%E8%82%89%E4%B8%9D" title="京酱肉丝">京酱肉丝</a>、<a href="/wiki/%E6%B6%AE%E7%BE%8A%E8%82%89" title="涮羊肉">涮羊肉</a>、砂鍋魚翅等。老字号饭馆有<a href="/wiki/%E4%B8%9C%E6%9D%A5%E9%A1%BA" title="东来顺">东来顺</a>、<a href="/wiki/%E5%85%A8%E8%81%9A%E5%BE%B7" title="全聚德">全聚德</a>、<a href="/wiki/%E4%BE%BF%E5%AE%9C%E5%9D%8A" title="便宜坊">便宜坊</a>、<a href="/wiki/%E4%BB%BF%E8%86%B3%E9%A5%AD%E5%BA%84" title="仿膳饭庄">仿膳饭庄</a>等。
</p>
<h3><span id=".E8.A1.A8.E6.BC.94.E8.89.BA.E6.9C.AF"></span><span class="mw-headline" id="表演艺术">表演艺术</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=29" title="编辑章节:表演艺术">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>北京有很多地方特色的民风习俗。<a href="/wiki/%E4%BA%AC%E5%89%A7" title="京剧">京剧</a>深受部分京城老百姓的喜爱,在北京的街头,偶然可以听到路边传来抑扬顿挫的京戏段子。京剧的源头还要追溯到几种古老的地方戏剧,1790年,<a href="/wiki/%E5%AE%89%E5%BE%BD" class="mw-redirect" title="安徽">安徽</a>的四大地方戏班——三庆班、四喜班、春公班、和春班——先后进京献艺,获得空前成功。徽班常与来自<a href="/wiki/%E6%B9%96%E5%8C%97" class="mw-redirect" title="湖北">湖北</a>的汉调艺人合作演出,于是,一种以徽调“二簧”和汉调“<a href="/wiki/%E8%A5%BF%E7%9A%AE" title="西皮">西皮</a>”为主,兼收<a href="/wiki/%E6%98%86%E6%9B%B2" title="昆曲">昆曲</a>、<a href="/wiki/%E7%A7%A6%E8%85%94" title="秦腔">秦腔</a>、<a href="/wiki/%E6%88%8F%E6%9B%B2" title="戏曲">梆子</a>等地方戏精华的新剧种诞生了,这就是京剧。在200年的发展历程中,京剧在唱词、念白及字韵上越来越北京化,使用的<a href="/wiki/%E4%BA%8C%E8%83%A1" title="二胡">二胡</a>、<a href="/wiki/%E4%BA%AC%E8%83%A1" title="京胡">京胡</a>等乐器,也融合了多个民族的特色,终于成为一种成熟的艺术。京剧集歌唱、舞蹈、武打、音乐、美术、文学于一体。
</p><p>京剧舞台艺术在<a href="/wiki/%E6%96%87%E5%AD%A6" class="mw-redirect" title="文学">文学</a>、<a href="/wiki/%E8%A1%A8%E6%BC%94" title="表演">表演</a>、<a href="/wiki/%E9%9F%B3%E4%B9%90" title="音乐">音乐</a>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%88%8F%E6%9B%B2" class="mw-redirect" title="中国戏曲">唱腔</a>、锣鼓、<a href="/wiki/%E5%8C%96%E5%A6%86" title="化妆">化妆</a>、<a href="/wiki/%E8%84%B8%E8%B0%B1" class="mw-redirect" title="脸谱">脸谱</a>等各个方面,通过无数艺人的长期舞台实践,构成了一套互相制约、相得益彰的格律化和规范化的程式。它作为创造舞台形象的艺术手段是十分丰富的,而用法又是十分严格的。不能驾驭这些程式,就无法完成京剧舞台艺术的创造。由于京剧在形成之初,便进入了<a href="/wiki/%E5%AE%AE%E5%BB%B7" class="mw-redirect" title="宮廷">宫廷</a>,使它的发育成长不同于地方剧种。要求它所要表现的生活领域更宽,所要塑造的人物类型更多,对它的技艺的全面性、完整性也要求得更严,对它创造舞台形象的<a href="/wiki/%E7%BE%8E%E5%AD%A6" title="美学">美学</a>要求也更高。当然,同时也相应地使它的民间乡土气息减弱,纯朴、粗犷的风格特色相对淡薄。因而,它的表演艺术更趋于虚实结合的表现手法,最大限度地超脱了舞台空间和时间的限制,以达到“以形传神,形神兼备”的艺术境界。表演上要求精致细腻,处处入戏;唱腔上要求悠扬委婉,声情并茂;武戏则不以火爆勇猛取胜,而以“武戏文唱”见佳。2010年11月16日京剧被列入“<a href="/wiki/%E4%BA%BA%E7%B1%BB%E9%9D%9E%E7%89%A9%E8%B4%A8%E6%96%87%E5%8C%96%E9%81%97%E4%BA%A7%E4%BB%A3%E8%A1%A8%E4%BD%9C%E5%90%8D%E5%BD%95" title="人类非物质文化遗产代表作名录">人类非物质文化遗产代表作名录</a>”。
</p><p>除京剧外,北京还有<a href="/wiki/%E5%8F%8C%E7%B0%A7" title="双簧">双簧</a>、<a href="/wiki/%E7%9B%B8%E5%A3%B0" title="相声">相声</a>、<a href="/wiki/%E8%AF%84%E4%B9%A6" title="评书">评书</a>、<a href="/wiki/%E6%9D%82%E6%8A%80" class="mw-redirect" title="杂技">杂技</a>、<a href="/wiki/%E4%BA%AC%E9%9F%B5%E5%A4%A7%E9%BC%93" title="京韵大鼓">京韵大鼓</a>、<a href="/wiki/%E8%AF%9D%E5%89%A7" class="mw-redirect" title="话剧">话剧</a>、铁板快书、<a href="/wiki/%E6%99%AF%E6%B3%B0%E8%93%9D" class="mw-redirect" title="景泰蓝">景泰蓝</a>、牙雕、漆雕、蝈蝈笼和吹糖人等传统艺术。
</p><p>进入21世纪,北京已成为中国内地音乐产业的中心。内地音乐人多数选择来北京发展,很大程度上带动了北京音乐文化的繁荣。北京的摇滚界见证了中国摇滚乐的兴衰史,是中国摇滚音乐的心脏。随着时间的推移,摇滚已经风光不再,目前仅处于勉强维持阶段,但是在北京依然拥有数量众多的摇滚乐迷。北京的地下乐队众多、派别多样,主要在各酒吧演出,其中较知名的有<a href="/wiki/%E6%96%B0%E8%A3%A4%E5%AD%90" title="新裤子">新裤子</a>乐队、<a href="/w/index.php?title=%E5%9C%B0%E4%B8%8B%E5%A9%B4%E5%84%BF&action=edit&redlink=1" class="new" title="地下婴儿(页面不存在)">地下婴儿</a>、<a href="/wiki/%E5%8F%8D%E5%85%89%E9%95%9C" class="mw-redirect" title="反光镜">反光镜</a>、<a href="/wiki/%E7%89%9B%E5%A5%B6%E5%92%96%E5%95%A1_(%E6%A8%82%E9%9A%8A)" class="mw-redirect" title="牛奶咖啡 (樂隊)">牛奶咖啡</a>、<a href="/w/index.php?title=%E4%BE%BF%E5%88%A9%E5%95%86%E5%BA%97%E4%B9%90%E9%98%9F&action=edit&redlink=1" class="new" title="便利商店乐队(页面不存在)">便利商店乐队</a>等。北京音乐呈现非主流、叛逆、创新的文化特点。
</p>
<div class="thumb tright"><div class="thumbinner" style="width:252px;"><a href="/wiki/File:Beijing_national_stadium.jpg" class="image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Beijing_national_stadium.jpg/250px-Beijing_national_stadium.jpg" decoding="async" width="250" height="145" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Beijing_national_stadium.jpg/375px-Beijing_national_stadium.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Beijing_national_stadium.jpg/500px-Beijing_national_stadium.jpg 2x" data-file-width="1762" data-file-height="1019" /></a> <div class="thumbcaption"><div class="magnify"><a href="/wiki/File:Beijing_national_stadium.jpg" class="internal" title="放大"></a></div>北京<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA_(%E5%8C%97%E4%BA%AC)" title="国家体育场 (北京)">国家体育场</a>又被称作“鸟巢”,是2008年夏季奥运会,也是2022年冬季奧運會的主赛场地。现在也作为北京市区大型的表演中心使用。</div></div></div>
<p>北京艺术演出市场非常繁荣,每年都有超过10000场国内外<a href="/wiki/%E6%BC%94%E5%94%B1%E6%9C%83" class="mw-redirect" title="演唱會">演唱会</a>、<a href="/wiki/%E9%9F%B3%E4%B9%90%E4%BC%9A" class="mw-redirect" title="音乐会">音乐会</a>、<a href="/wiki/%E6%AD%8C%E5%89%A7" title="歌剧">歌剧</a>、<a href="/wiki/%E8%AF%9D%E5%89%A7" class="mw-redirect" title="话剧">话剧</a>在全市近百个场地上演。<sup id="cite_ref-150" class="reference"><a href="#cite_note-150">[143]</a></sup>世界各大著名交响乐团,以及<a href="/wiki/%E9%9B%85%E5%B0%BC" title="雅尼">雅尼</a>、<a href="/wiki/%E7%A5%9E%E7%A7%98%E5%9B%AD" title="神秘园">神秘园</a>、<a href="/wiki/%E5%B0%8F%E6%B3%BD%E5%BE%81%E5%B0%94" title="小泽征尔">小泽征尔</a>、<a href="/wiki/%E4%BC%8A%E6%89%8E%E5%85%8B%C2%B7%E5%B8%95%E5%B0%94%E6%9B%BC" title="伊扎克·帕尔曼">帕尔曼</a>等著名音乐家和团体均有来访北京。
</p><p>北京有举办一年一度的著名“三大国际演出季”,即为:北京国际音乐节、北京国际戏剧演出季和北京国际舞蹈季。北京国际音乐节于每年的10月中旬到11月中旬举办,期间有<a href="/wiki/%E6%9F%8F%E6%9E%97%E7%88%B1%E4%B9%90%E4%B9%90%E5%9B%A2" title="柏林爱乐乐团">柏林爱乐乐团</a>、<a href="/wiki/%E7%BA%BD%E7%BA%A6%E7%88%B1%E4%B9%90%E4%B9%90%E5%9B%A2" class="mw-redirect" title="纽约爱乐乐团">纽约爱乐乐团</a>、<a href="/wiki/%E4%B8%AD%E5%9B%BD%E7%88%B1%E4%B9%90%E4%B9%90%E5%9B%A2" class="mw-redirect" title="中国爱乐乐团">中国爱乐乐团</a>等国内外著名乐团,以及<a href="/wiki/%E4%BD%95%E5%A1%9E%C2%B7%E5%8D%A1%E9%9B%B7%E6%8B%89%E6%96%AF" title="何塞·卡雷拉斯">何塞·卡雷拉斯</a>、<a href="/wiki/%E5%85%8B%E9%87%8C%E6%96%AF%E6%89%98%E5%A4%AB%C2%B7%E6%BD%98%E5%BE%B7%E5%88%97%E8%8C%A8%E5%9F%BA" class="mw-redirect" title="克里斯托夫·潘德列茨基">潘德列茨基</a>、<a href="/wiki/%E9%A9%AC%E5%8F%8B%E5%8F%8B" class="mw-redirect" title="马友友">马友友</a>等著名音乐家的30多场艺术演出上演,涵盖了<a href="/wiki/%E4%BA%A4%E5%93%8D%E4%B9%90" class="mw-redirect" title="交响乐">交响乐</a>、<a href="/wiki/%E6%AD%8C%E5%89%A7" title="歌剧">歌剧</a>、<a href="/wiki/%E7%88%B5%E5%A3%AB%E4%B9%90" title="爵士乐">爵士乐</a>等等各种风格及形式的音乐。<sup id="cite_ref-151" class="reference"><a href="#cite_note-151">[144]</a></sup>北京国际戏剧演出季于每年春末夏初举办,来自世界各大洲国家及国内之戏剧团体在一个月内献上超过50场演出,<a href="/wiki/%E8%8E%8E%E6%8B%89%C2%B7%E5%B8%83%E8%8E%B1%E6%9B%BC" class="mw-redirect" title="莎拉·布莱曼">莎拉·布莱曼</a>等明星亦有受邀献唱。北京国际舞蹈季为冬季跨年举办,<span class="ilh-all" data-orig-title="英国皇家芭蕾舞团" data-lang-code="en" data-lang-name="英语" data-foreign-title="The Royal Ballet"><span class="ilh-page"><a href="/wiki/%E8%8B%B1%E5%9C%8B%E7%9A%87%E5%AE%B6%E8%8A%AD%E8%95%BE%E8%88%9E%E5%9C%98" class="mw-redirect" title="英國皇家芭蕾舞團">英国皇家芭蕾舞团</a></span><span class="noprint ilh-comment">(<span class="ilh-lang">英语</span><span class="ilh-colon">:</span><span class="ilh-link"><a href="https://en.wikipedia.org/wiki/The_Royal_Ballet" class="extiw" title="en:The Royal Ballet"><span lang="en" dir="auto">The Royal Ballet</span></a></span>)</span></span>等国际各大著名芭蕾舞团体均受邀参加。<sup id="cite_ref-152" class="reference"><a href="#cite_note-152">[145]</a></sup>
</p><p>北京市的主要演出场馆有:<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%A4%A7%E5%89%A7%E9%99%A2" class="mw-redirect" title="中国国家大剧院">中国国家大剧院</a>、<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA_(%E5%8C%97%E4%BA%AC)" title="国家体育场 (北京)">鸟巢</a>、<a href="/wiki/%E4%BF%9D%E5%88%A9%E5%89%A7%E9%99%A2" title="保利剧院">保利剧院</a>、<a href="/wiki/%E4%B8%AD%E5%B1%B1%E9%9F%B3%E4%B9%90%E5%A0%82" class="mw-redirect" title="中山音乐堂">中山音乐堂</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%9F%B3%E4%B9%90%E5%8E%85" title="北京音乐厅">北京音乐厅</a>、<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%A4%A7%E4%BC%9A%E5%A0%82" title="人民大会堂">人民大会堂</a>、<a href="/wiki/%E4%B8%9C%E6%96%B9%E5%85%88%E9%94%8B%E5%89%A7%E5%9C%BA" class="mw-redirect" title="东方先锋剧场">东方先锋剧场</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%BA%E6%B0%91%E8%89%BA%E6%9C%AF%E5%89%A7%E9%99%A2" title="北京人民艺术剧院">北京人艺小剧场</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B7%A5%E4%BA%BA%E4%BD%93%E8%82%B2%E5%9C%BA" title="北京工人体育场">北京工人体育场</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B7%A5%E4%BA%BA%E4%BD%93%E8%82%B2%E9%A6%86" title="北京工人体育馆">北京工人体育馆</a>、<a href="/wiki/%E9%A6%96%E9%83%BD%E4%BD%93%E8%82%B2%E9%A6%86" title="首都体育馆">首都体育馆</a>、<a href="/wiki/%E4%B8%B0%E5%8F%B0%E4%BD%93%E8%82%B2%E4%B8%AD%E5%BF%83" class="mw-redirect" title="丰台体育中心">丰台体育中心</a>等。
</p>
<h3><span id=".E8.89.BA.E6.9C.AF.E5.9B.AD.E5.8C.BA"></span><span class="mw-headline" id="艺术园区">艺术园区</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=30" title="编辑章节:艺术园区">编辑</a><span class="mw-editsection-bracket">]</span></span></h3>
<p>随着中国文化艺术与时尚产业的复兴,北京作为首都,是中国的<a href="/wiki/%E8%89%BA%E6%9C%AF" title="艺术">艺术</a>中心、<a href="/wiki/%E6%99%82%E5%B0%9A%E6%BD%AE%E6%B5%81" class="mw-redirect" title="時尚潮流">時尚潮流</a>中心和<a href="/wiki/%E6%96%87%E5%8C%96" title="文化">文化</a>中心。北京现当代艺术的地标为位于北京市朝阳区大山子地区的一个艺术园区,即<a href="/wiki/798%E8%89%BA%E6%9C%AF%E5%8C%BA" title="798艺术区">798艺术区</a>,原为<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%AC%AC%E4%B8%89%E6%97%A0%E7%BA%BF%E7%94%B5%E5%99%A8%E6%9D%90%E5%8E%82&action=edit&redlink=1" class="new" title="北京第三无线电器材厂(页面不存在)">北京第三无线电器材厂</a>,建筑多为<a href="/wiki/%E4%B8%9C%E5%BE%B7" class="mw-redirect" title="东德">东德</a>的<a href="/wiki/%E5%8C%85%E8%B1%AA%E6%96%AF" title="包豪斯">包豪斯</a>风格。1980年代到1990年代798厂逐渐衰落,从2002年开始,由于租金低廉,来自北京周边和北京以外的艺术家开始聚集于此,逐渐形成了一个艺术群落。2006年后,中国发展文化创意产业,因应北京建设世界城市的步伐,以798艺术区为中心,打造中国乃至世界的当代艺术中心,周边的<a href="/wiki/%E8%8D%89%E5%9C%BA%E5%9C%B0" title="草场地">草场地</a>、<a href="/wiki/%E7%8E%AF%E9%93%81" class="mw-redirect" title="环铁">环铁</a>乃至北京远郊的<a href="/w/index.php?title=%E5%AE%8B%E5%BA%84&action=edit&redlink=1" class="new" title="宋庄(页面不存在)">宋庄</a>均成为这一巨大艺术群落的一部分。
</p>
<h2><span id=".E4.BA.BA.E7.89.A9"></span><span class="mw-headline" id="人物">人物</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=31" title="编辑章节:人物">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主页面:<a href="/wiki/Category:%E5%8C%97%E4%BA%AC%E4%BA%BA" title="Category:北京人">Category:北京人</a></div>
<h2><span id=".E5.AE.97.E6.95.99"></span><span class="mw-headline" id="宗教">宗教</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=32" title="编辑章节:宗教">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable">主条目:<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%AE%97%E6%95%99%E6%B4%BB%E5%8A%A8%E5%9C%BA%E6%89%80%E5%88%97%E8%A1%A8" title="北京市宗教活动场所列表">北京市宗教活動場所列表</a></div>
<style data-mw-deduplicate="TemplateStyles:r51421762">body.skin-minerva .mw-parser-output .transborder{border:solid transparent}</style><div class="thumb tleft" style=""><div class="thumbinner" style="width:202px">
<div style="background-color:white;margin:auto;position:relative;width:200px;height:200px;overflow:hidden;border-radius:100px;border:1px solid black">
<div class="transborder" style="position:absolute;width:100px;line-height:0;left:0; top:0; border-width:0 200px 200px 0; border-color:#A1887F"></div><div class="transborder" style="position:absolute;width:100px;line-height:0;left:100px; top:100px; border-width:100px 0 0 2038.8140985341px; border-left-color:#000000"></div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 200px 100px 0;border-color:#000000"></div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 100px 200px 0;border-color:#000000"></div><div class="transborder" style="position:absolute;width:100px;line-height:0;left:100px; top:100px; border-width:100px 0 0 621.26544569249px; border-left-color:#FDD835"></div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 200px 100px 0;border-color:#FDD835"></div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 100px 200px 0;border-color:#FDD835"></div><div class="transborder" style="position:absolute;width:100px;line-height:0;left:100px; top:100px; border-width:100px 0 0 85.516791693412px; border-left-color:#F5F5F5"></div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 200px 100px 0;border-color:#F5F5F5"></div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 100px 200px 0;border-color:#F5F5F5"></div>
</div>
<div class="thumbcaption">
<p>北京宗教(2010)
</p>
<div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #F5F5F5;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E4%B8%AD%E5%9C%8B%E6%B0%91%E9%96%93%E4%BF%A1%E4%BB%B0" class="mw-redirect" title="中國民間信仰">中國民間信仰</a> 、<a href="/wiki/%E7%84%A1%E5%AE%97%E6%95%99" class="mw-redirect" title="無宗教">無宗教</a>或<a href="/wiki/%E7%84%A1%E7%A5%9E%E8%AB%96" class="mw-redirect" title="無神論">無神論</a>(86.26%)</div><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FDD835;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E4%BD%9B%E6%95%99" title="佛教">佛教</a>(11.2%)</div><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #000000;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E4%BC%8A%E6%96%AF%E8%98%AD%E6%95%99" class="mw-redirect" title="伊斯蘭教">伊斯蘭教</a>(1.76%)</div><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #A1887F;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E5%9F%BA%E7%9D%A3%E5%AE%97%E6%95%99" class="mw-redirect" title="基督宗教">基督宗教</a>(0.78%)</div>
</div>
</div></div>
<p>从古至今,各种原始宗教以及土生土长的道教都在北京繁衍和发展,外来的佛教、基督宗教、伊斯兰教等宗教亦相继在北京地区传播,并逐渐融入中华民族传统文化和北京历史文化中,逐渐形成了多元文化体系的北京宗教文化。北京现有宗教活动场所达100多处,拥有宗教信仰者50多万,以2000年北京市人口来计算,宗教信仰者约占4%。各大宗教在北京都建有自己的宗教活动场所和宗教院校,传承各自的宗教文化。<sup id="cite_ref-153" class="reference"><a href="#cite_note-153">[146]</a></sup>
</p><p>道教自东汉产生后,就开始在北京地区流传。北魏时期统治者以道教为国教。始建于唐朝的<a href="/wiki/%E5%A4%A9%E9%95%B7%E8%A7%80" class="mw-redirect" title="天長觀">天长观</a>是北京地区第一座道观。金元明清时期,道教在北京地区有着很大的影响。1957年4月,道教界第一次全国代表会议在北京召开,中国道教协会正式成立,由岳崇岱任第一届理事会会长<sup id="cite_ref-154" class="reference"><a href="#cite_note-154">[147]</a></sup>。
</p><p>东晋十六国时起,佛教传入北京地区。历朝帝王出于政治与信仰的需要,大多推崇佛教。1953年6月中国佛教协会在北京成立,圆瑛法师当选会长。2010年2月,中国佛教协会第八次全国代表大会在北京召开,传印长老当选为新一届中国佛教协会会长<sup id="cite_ref-155" class="reference"><a href="#cite_note-155">[148]</a></sup>。
</p><p>鸦片战争后,基督宗教逐渐在北京传播。北京市天主教爱国会、北京市天主教教务委员会、天主教北京教区三个机构是北京市天主教的三个机构,由北京市天主教爱国会负责北京市天主教的对外所有民事事务<sup id="cite_ref-156" class="reference"><a href="#cite_note-156">[149]</a></sup>。
</p><p>宋辽时期伊斯兰教传入北京。北京市历史最悠久的<a href="/wiki/%E7%89%9B%E8%A1%97%E7%A4%BC%E6%8B%9C%E5%AF%BA" title="牛街礼拜寺">牛街礼拜寺</a>始建于公元996年。元代,穆斯林大量进入中国。当时北京(元大都)有信仰伊斯兰教的“回回”逾万人,有清真寺35座。明政府对“保国有功的回回”始终以“敬礼勋臣”相待,敕建、重修了许多清真寺。目前北京大部分较为古老的清真寺,多为明代修建。清朝时期北京的伊斯兰教由内城向外城和近郊扩展,清真寺大量增加,伊斯兰教的影响加大,文化传播范围扩大。中华民国大陆时期,北京地区伊斯兰教发展缓慢。中华人民共和国成立后,特别是十一届三中全会后落实党的民族宗教政策,北京地区伊斯兰教迎来历史上的黄金时期。目前全市共有依法登记的清真寺70座<sup id="cite_ref-157" class="reference"><a href="#cite_note-157">[150]</a></sup>。
</p>
<h2><span id=".E4.BD.93.E8.82.B2"></span><span class="mw-headline" id="体育">体育</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=33" title="编辑章节:体育">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<p>北京曾举办许多国际赛事,包括<a href="/wiki/1990%E5%B9%B4%E4%BA%9A%E8%BF%90%E4%BC%9A" class="mw-redirect" title="1990年亚运会">1990年亚运会</a>、<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季奥林匹克运动会">2008年夏季奥林匹克运动会</a>及<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E6%AE%8B%E7%96%BE%E4%BA%BA%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季残疾人奥林匹克运动会">残疾人奥林匹克运动会</a>、<a href="/wiki/2015%E5%B9%B4%E4%B8%96%E7%95%8C%E7%94%B0%E5%BE%91%E9%8C%A6%E6%A8%99%E8%B3%BD" title="2015年世界田徑錦標賽">2015年世界田径锦标赛</a>。
</p><p><a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季奥林匹克运动会">2022年冬季奥林匹克运动会</a>及<a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E6%AE%8B%E7%96%BE%E4%BA%BA%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季残疾人奥林匹克运动会">残疾人奥林匹克运动会</a>将以北京的名义在北京市及<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">张家口市</a>举办,北京因此成为唯一一座已经举办过夏季奥运会,并将举办冬季奥运会的城市<sup id="cite_ref-158" class="reference"><a href="#cite_note-158">[151]</a></sup>。
</p>
<h2><span id=".E5.8F.8B.E5.A5.BD.E5.9F.8E.E5.B8.82"></span><span class="mw-headline" id="友好城市">友好城市</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=34" title="编辑章节:友好城市">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="note" class="hatnote navigation-not-searchable noprint">更详尽的列表见<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8F%8B%E5%A5%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="北京市友好城市列表">北京市友好城市列表</a>。</div>
<table class="wikitable" style="font-size:88%; text-align:left; width:100%;">
<tbody><tr>
<td colspan="3" style="text-align:center; background:#e3e3e3;"><b>与北京市结为友好城市的城市</b>
</td></tr>
<tr>
<td>
<div class="div-col columns column-count column-count-4" style="-moz-column-count: 4; -webkit-column-count: 4; column-count: 4;">
<dl><dt>欧洲</dt></dl>
<ul><li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_Serbia.svg/22px-Flag_of_Serbia.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_Serbia.svg/33px-Flag_of_Serbia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_Serbia.svg/44px-Flag_of_Serbia.svg.png 2x" data-file-width="945" data-file-height="630" /> </span><a href="/wiki/%E5%A1%9E%E5%B0%94%E7%BB%B4%E4%BA%9A" title="塞尔维亚">塞爾維亞</a><a href="/wiki/%E8%B4%9D%E5%B0%94%E6%A0%BC%E8%8E%B1%E5%BE%B7" title="贝尔格莱德">贝尔格莱德</a><br />(1980年10月14日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/22px-Flag_of_Spain.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/33px-Flag_of_Spain.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/44px-Flag_of_Spain.svg.png 2x" data-file-width="750" data-file-height="500" /> </span><a href="/wiki/%E8%A5%BF%E7%8F%AD%E7%89%99" title="西班牙">西班牙</a><a href="/wiki/%E9%A9%AC%E5%BE%B7%E9%87%8C" title="马德里">马德里</a><br />(1985年9月16日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E6%B3%95%E5%9C%8B" class="mw-redirect" title="法國">法國</a><a href="/wiki/%E6%B3%95%E5%85%B0%E8%A5%BF%E5%B2%9B" class="mw-redirect" title="法兰西岛">法兰西岛大区</a><br />(1987年7月2日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/22px-Flag_of_Germany.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/33px-Flag_of_Germany.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/44px-Flag_of_Germany.svg.png 2x" data-file-width="1000" data-file-height="600" /> </span><a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">德國</a><a href="/wiki/%E7%A7%91%E9%9A%86" title="科隆">科隆</a><br />(1987年9月14日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/49/Flag_of_Ukraine.svg/22px-Flag_of_Ukraine.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/49/Flag_of_Ukraine.svg/33px-Flag_of_Ukraine.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/49/Flag_of_Ukraine.svg/44px-Flag_of_Ukraine.svg.png 2x" data-file-width="1200" data-file-height="800" /> </span><a href="/wiki/%E4%B9%8C%E5%85%8B%E5%85%B0" title="乌克兰">烏克蘭</a><a href="/wiki/%E5%9F%BA%E8%BE%85" class="mw-redirect" title="基辅">基辅</a><br />(1993年12月13日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/22px-Flag_of_Germany.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/33px-Flag_of_Germany.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/44px-Flag_of_Germany.svg.png 2x" data-file-width="1000" data-file-height="600" /> </span><a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">德國</a><a href="/wiki/%E6%9F%8F%E6%9E%97" title="柏林">柏林</a><br />(1994年4月5日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/92/Flag_of_Belgium_%28civil%29.svg/22px-Flag_of_Belgium_%28civil%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/92/Flag_of_Belgium_%28civil%29.svg/33px-Flag_of_Belgium_%28civil%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/92/Flag_of_Belgium_%28civil%29.svg/44px-Flag_of_Belgium_%28civil%29.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E6%AF%94%E5%88%A9%E6%97%B6" title="比利时">比利時</a><a href="/wiki/%E5%B8%83%E9%B2%81%E5%A1%9E%E5%B0%94" title="布鲁塞尔">布鲁塞尔</a><br />(1994年9月22日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/22px-Flag_of_the_Netherlands.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/33px-Flag_of_the_Netherlands.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/44px-Flag_of_the_Netherlands.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E8%8D%B7%E5%85%B0" title="荷兰">荷蘭</a><a href="/wiki/%E9%98%BF%E5%A7%86%E6%96%AF%E7%89%B9%E4%B8%B9" title="阿姆斯特丹">阿姆斯特丹</a><br />(1994年10月29日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/22px-Flag_of_Russia.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/33px-Flag_of_Russia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/44px-Flag_of_Russia.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%BF%84%E7%BD%97%E6%96%AF" title="俄罗斯">俄羅斯</a><a href="/wiki/%E8%8E%AB%E6%96%AF%E7%A7%91" title="莫斯科">莫斯科</a><br />(1995年5月16日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E6%B3%95%E5%9C%8B" class="mw-redirect" title="法國">法國</a><a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">巴黎</a><br />(1997年10月23日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" data-file-width="1500" data-file-height="1000" /> </span><a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" class="mw-redirect" title="義大利">義大利</a><a href="/wiki/%E7%BD%97%E9%A9%AC" title="罗马">罗马</a><br />(1998年5月28日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/22px-Flag_of_Spain.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/33px-Flag_of_Spain.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/44px-Flag_of_Spain.svg.png 2x" data-file-width="750" data-file-height="500" /> </span><a href="/wiki/%E8%A5%BF%E7%8F%AD%E7%89%99" title="西班牙">西班牙</a><a href="/wiki/%E9%A9%AC%E5%BE%B7%E9%87%8C%E8%87%AA%E6%B2%BB%E5%8C%BA" title="马德里自治区">马德里自治区</a><br />(2005年1月17日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/22px-Flag_of_Greece.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/33px-Flag_of_Greece.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/44px-Flag_of_Greece.svg.png 2x" data-file-width="600" data-file-height="400" /> </span><a href="/wiki/%E5%B8%8C%E8%85%8A" title="希腊">希臘</a><a href="/wiki/%E9%9B%85%E5%85%B8" title="雅典">雅典</a><br />(2005年5月10日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Portugal.svg/22px-Flag_of_Portugal.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Portugal.svg/33px-Flag_of_Portugal.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Portugal.svg/44px-Flag_of_Portugal.svg.png 2x" data-file-width="600" data-file-height="400" /> </span><a href="/wiki/%E8%91%A1%E8%90%84%E7%89%99" title="葡萄牙">葡萄牙</a><a href="/wiki/%E9%87%8C%E6%96%AF%E6%9C%AC" title="里斯本">里斯本</a><br />(2007年)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Flag_of_Albania.svg/22px-Flag_of_Albania.svg.png" decoding="async" width="22" height="16" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Flag_of_Albania.svg/33px-Flag_of_Albania.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/36/Flag_of_Albania.svg/44px-Flag_of_Albania.svg.png 2x" data-file-width="980" data-file-height="700" /> </span><a href="/wiki/%E9%98%BF%E5%B0%94%E5%B7%B4%E5%B0%BC%E4%BA%9A" title="阿尔巴尼亚">阿尔巴尼亚</a><a href="/wiki/%E5%9C%B0%E6%8B%89%E9%82%A3" title="地拉那">地拉那</a><br />(2007年)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/45/Flag_of_Ireland.svg/22px-Flag_of_Ireland.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/45/Flag_of_Ireland.svg/33px-Flag_of_Ireland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/45/Flag_of_Ireland.svg/44px-Flag_of_Ireland.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E7%88%B1%E5%B0%94%E5%85%B0" title="爱尔兰">爱尔兰</a><a href="/wiki/%E9%83%BD%E6%9F%8F%E6%9E%97" title="都柏林">都柏林</a><br />(2011年)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c1/Flag_of_Hungary.svg/22px-Flag_of_Hungary.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c1/Flag_of_Hungary.svg/33px-Flag_of_Hungary.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c1/Flag_of_Hungary.svg/44px-Flag_of_Hungary.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E5%8C%88%E7%89%99%E5%88%A9" title="匈牙利">匈牙利</a><a href="/wiki/%E5%B8%83%E8%BE%BE%E4%BD%A9%E6%96%AF" title="布达佩斯">布达佩斯</a><br />(2005年6月16日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/73/Flag_of_Romania.svg/22px-Flag_of_Romania.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/73/Flag_of_Romania.svg/33px-Flag_of_Romania.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/73/Flag_of_Romania.svg/44px-Flag_of_Romania.svg.png 2x" data-file-width="600" data-file-height="400" /> </span><a href="/wiki/%E7%BE%85%E9%A6%AC%E5%B0%BC%E4%BA%9E" title="羅馬尼亞">羅馬尼亞</a><a href="/wiki/%E5%B8%83%E5%8A%A0%E5%8B%92%E6%96%AF%E7%89%B9" title="布加勒斯特">布加勒斯特</a><br />(2005年6月21日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国">英國</a><a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">伦敦</a><br />(2006年4月10日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/22px-Flag_of_Finland.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/33px-Flag_of_Finland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/44px-Flag_of_Finland.svg.png 2x" data-file-width="1800" data-file-height="1100" /> </span><a href="/wiki/%E8%8A%AC%E5%85%B0" title="芬兰">芬兰</a><a href="/wiki/%E8%B5%AB%E5%B0%94%E8%BE%9B%E5%9F%BA" title="赫尔辛基">赫尔辛基</a><br />(2006年)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9c/Flag_of_Denmark.svg/22px-Flag_of_Denmark.svg.png" decoding="async" width="22" height="17" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9c/Flag_of_Denmark.svg/33px-Flag_of_Denmark.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9c/Flag_of_Denmark.svg/44px-Flag_of_Denmark.svg.png 2x" data-file-width="512" data-file-height="387" /> </span><a href="/wiki/%E4%B8%B9%E9%BA%A6" title="丹麦">丹麥</a><a href="/wiki/%E5%93%A5%E6%9C%AC%E5%93%88%E6%A0%B9" title="哥本哈根">哥本哈根</a><br />(2012年6月26日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/84/Flag_of_Latvia.svg/22px-Flag_of_Latvia.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/84/Flag_of_Latvia.svg/33px-Flag_of_Latvia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/84/Flag_of_Latvia.svg/44px-Flag_of_Latvia.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E6%8B%89%E8%84%AB%E7%B6%AD%E4%BA%9E" title="拉脫維亞">拉脫維亞</a><a href="/wiki/%E9%87%8C%E5%8A%A0" title="里加">里加</a><br />(2017年9月15日)</li></ul>
<dl><dt>亚洲</dt></dl>
<ul><li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/22px-Flag_of_Japan.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/33px-Flag_of_Japan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/44px-Flag_of_Japan.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">日本</a><a href="/wiki/%E4%B8%9C%E4%BA%AC%E9%83%BD" class="mw-redirect" title="东京都">东京都</a><br />(1979年3月14日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/51/Flag_of_North_Korea.svg/22px-Flag_of_North_Korea.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/51/Flag_of_North_Korea.svg/33px-Flag_of_North_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/51/Flag_of_North_Korea.svg/44px-Flag_of_North_Korea.svg.png 2x" data-file-width="1600" data-file-height="800" /> </span><a href="/wiki/%E6%9C%9D%E9%B2%9C%E6%B0%91%E4%B8%BB%E4%B8%BB%E4%B9%89%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="朝鲜民主主义人民共和国">北韓</a><a href="/wiki/%E5%B9%B3%E5%A3%A4" title="平壤">平壤</a><br />(1986年10月18日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/21/Flag_of_Vietnam.svg/22px-Flag_of_Vietnam.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/21/Flag_of_Vietnam.svg/33px-Flag_of_Vietnam.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/21/Flag_of_Vietnam.svg/44px-Flag_of_Vietnam.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">越南</a><a href="/wiki/%E6%B2%B3%E5%86%85" class="mw-redirect" title="河内">河内</a><br />(1994年10月6日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/22px-Flag_of_South_Korea.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/33px-Flag_of_South_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/44px-Flag_of_South_Korea.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国">南韓</a><a href="/wiki/%E9%A6%96%E5%B0%94" class="mw-redirect" title="首尔">首尔</a><br />(1993年10月23日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Flag_of_Thailand.svg/22px-Flag_of_Thailand.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Flag_of_Thailand.svg/33px-Flag_of_Thailand.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Flag_of_Thailand.svg/44px-Flag_of_Thailand.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E6%B3%B0%E5%9B%BD" title="泰国">泰國</a><a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">曼谷</a><br />(1993年5月26日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Flag_of_Indonesia.svg/22px-Flag_of_Indonesia.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Flag_of_Indonesia.svg/33px-Flag_of_Indonesia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Flag_of_Indonesia.svg/44px-Flag_of_Indonesia.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E5%8D%B0%E5%BA%A6%E5%B0%BC%E8%A5%BF%E4%BA%9A" title="印度尼西亚">印尼</a><a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">雅加达</a><br />(1993年8月4日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/66/Flag_of_Malaysia.svg/22px-Flag_of_Malaysia.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/66/Flag_of_Malaysia.svg/33px-Flag_of_Malaysia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/66/Flag_of_Malaysia.svg/44px-Flag_of_Malaysia.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A" title="马来西亚">马来西亚</a><a href="/wiki/%E5%90%89%E9%9A%86%E5%9D%A1" title="吉隆坡">吉隆坡</a><br />(2009年1月15日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/32/Flag_of_Pakistan.svg/22px-Flag_of_Pakistan.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/32/Flag_of_Pakistan.svg/33px-Flag_of_Pakistan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/32/Flag_of_Pakistan.svg/44px-Flag_of_Pakistan.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E5%B7%B4%E5%9F%BA%E6%96%AF%E5%9D%A6" title="巴基斯坦">巴基斯坦</a><a href="/wiki/%E4%BC%8A%E6%96%AF%E5%85%B0%E5%A0%A1" title="伊斯兰堡">伊斯兰堡</a><br />(1992年10月8日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/22px-Flag_of_Turkey.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/33px-Flag_of_Turkey.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/44px-Flag_of_Turkey.svg.png 2x" data-file-width="1200" data-file-height="800" /> </span><a href="/wiki/%E5%9C%9F%E8%80%B3%E5%85%B6" title="土耳其">土耳其</a><a href="/wiki/%E5%AE%89%E5%8D%A1%E6%8B%89" title="安卡拉">安卡拉</a><br />(1990年6月20日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/99/Flag_of_the_Philippines.svg/22px-Flag_of_the_Philippines.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/99/Flag_of_the_Philippines.svg/33px-Flag_of_the_Philippines.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/99/Flag_of_the_Philippines.svg/44px-Flag_of_the_Philippines.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E8%8F%B2%E5%BE%8B%E5%AE%BE" title="菲律宾">菲律賓</a><a href="/wiki/%E9%A9%AC%E5%B0%BC%E6%8B%89" title="马尼拉">马尼拉</a><br />(2005年11月14日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Flag_of_Kazakhstan.svg/22px-Flag_of_Kazakhstan.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Flag_of_Kazakhstan.svg/33px-Flag_of_Kazakhstan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Flag_of_Kazakhstan.svg/44px-Flag_of_Kazakhstan.svg.png 2x" data-file-width="1000" data-file-height="500" /> </span><a href="/wiki/%E5%93%88%E8%90%A8%E5%85%8B%E6%96%AF%E5%9D%A6" title="哈萨克斯坦">哈萨克斯坦</a><a href="/wiki/%E5%8A%AA%E5%B0%94%E8%8B%8F%E4%B8%B9" class="mw-redirect" title="努尔苏丹">努尔苏丹</a><br />(2006年11月16日)</li></ul>
<dl><dt>非洲</dt></dl>
<ul><li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Flag_of_Egypt.svg/22px-Flag_of_Egypt.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Flag_of_Egypt.svg/33px-Flag_of_Egypt.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Flag_of_Egypt.svg/44px-Flag_of_Egypt.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E5%9F%83%E5%8F%8A" title="埃及">埃及</a><a href="/wiki/%E5%BC%80%E7%BD%97" title="开罗">开罗</a><br />(1990年10月28日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/af/Flag_of_South_Africa.svg/22px-Flag_of_South_Africa.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/af/Flag_of_South_Africa.svg/33px-Flag_of_South_Africa.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/af/Flag_of_South_Africa.svg/44px-Flag_of_South_Africa.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E5%8D%97%E9%9D%9E" title="南非">南非</a><a href="/wiki/%E8%B1%AA%E7%99%BB%E7%9C%81" title="豪登省">豪登省</a><br />(1998年5月28日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Flag_of_Malawi.svg/22px-Flag_of_Malawi.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Flag_of_Malawi.svg/33px-Flag_of_Malawi.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Flag_of_Malawi.svg/44px-Flag_of_Malawi.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E9%A9%AC%E6%8B%89%E7%BB%B4" title="马拉维">马拉维</a><a href="/wiki/%E5%88%A9%E9%9A%86%E5%9C%AD" title="利隆圭">利隆圭</a><br />(2008年1月15日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/71/Flag_of_Ethiopia.svg/22px-Flag_of_Ethiopia.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/71/Flag_of_Ethiopia.svg/33px-Flag_of_Ethiopia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/71/Flag_of_Ethiopia.svg/44px-Flag_of_Ethiopia.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E5%9F%83%E5%A1%9E%E4%BF%84%E6%AF%94%E4%BA%9A" title="埃塞俄比亚">衣索比亞</a><a href="/wiki/%E4%BA%9A%E7%9A%84%E6%96%AF%E4%BA%9A%E8%B4%9D%E5%B7%B4" title="亚的斯亚贝巴">亚的斯亚贝巴</a><br />(2008年1月15日)</li></ul>
<dl><dt>大洋洲</dt></dl>
<ul><li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/22px-Flag_of_Australia.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/33px-Flag_of_Australia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/44px-Flag_of_Australia.svg.png 2x" data-file-width="1280" data-file-height="640" /> </span><a href="/wiki/%E6%BE%B3%E5%A4%A7%E5%88%A9%E4%BA%9A" title="澳大利亚">澳大利亚</a><a href="/wiki/%E5%A0%AA%E5%9F%B9%E6%8B%89" title="堪培拉">堪培拉</a><br />(1979年3月14日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/3e/Flag_of_New_Zealand.svg/22px-Flag_of_New_Zealand.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/3e/Flag_of_New_Zealand.svg/33px-Flag_of_New_Zealand.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/3e/Flag_of_New_Zealand.svg/44px-Flag_of_New_Zealand.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E6%96%B0%E8%A5%BF%E5%85%B0" title="新西兰">新西蘭</a><a href="/wiki/%E6%83%A0%E7%81%B5%E9%A1%BF" title="惠灵顿">惠灵顿</a><br />(2006年)</li></ul>
<dl><dt>北美洲</dt></dl>
<ul><li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /> </span><a href="/wiki/%E7%BE%8E%E5%9C%8B" class="mw-redirect" title="美國">美國</a><a href="/wiki/%E7%BA%BD%E7%BA%A6" title="纽约">纽约</a><br />(1980年2月25日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /> </span><a href="/wiki/%E7%BE%8E%E5%9C%8B" class="mw-redirect" title="美國">美國</a><a href="/wiki/%E5%8D%8E%E7%9B%9B%E9%A1%BF%E5%93%A5%E4%BC%A6%E6%AF%94%E4%BA%9A%E7%89%B9%E5%8C%BA" title="华盛顿哥伦比亚特区">华盛顿</a><br />(1984年)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" data-file-width="512" data-file-height="256" /> </span><a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大">加拿大</a><a href="/wiki/%E6%B8%A5%E5%A4%AA%E5%8D%8E" class="mw-redirect" title="渥太华">渥太华</a><br />(1999年10月20日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/22px-Flag_of_Mexico.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/33px-Flag_of_Mexico.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/44px-Flag_of_Mexico.svg.png 2x" data-file-width="980" data-file-height="560" /> </span><a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5" title="墨西哥">墨西哥</a><a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5%E5%9F%8E" title="墨西哥城">墨西哥城</a><br />(2009年10月21日)</li></ul>
<dl><dt>南美洲</dt></dl>
<ul><li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Flag_of_Argentina.svg/22px-Flag_of_Argentina.svg.png" decoding="async" width="22" height="14" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Flag_of_Argentina.svg/33px-Flag_of_Argentina.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Flag_of_Argentina.svg/44px-Flag_of_Argentina.svg.png 2x" data-file-width="800" data-file-height="500" /> </span><a href="/wiki/%E9%98%BF%E6%A0%B9%E5%BB%B7" title="阿根廷">阿根廷</a><a href="/wiki/%E5%B8%83%E5%AE%9C%E8%AF%BA%E6%96%AF%E8%89%BE%E5%88%A9%E6%96%AF" class="mw-redirect" title="布宜诺斯艾利斯">布宜诺斯艾利斯</a><br />(1993年7月13日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/22px-Flag_of_Brazil.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/33px-Flag_of_Brazil.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/44px-Flag_of_Brazil.svg.png 2x" data-file-width="1060" data-file-height="742" /> </span><a href="/wiki/%E5%B7%B4%E8%A5%BF" title="巴西">巴西</a><a href="/wiki/%E9%87%8C%E7%BA%A6%E7%83%AD%E5%86%85%E5%8D%A2" title="里约热内卢">里约热内卢</a><br />(1986年11月24日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/cf/Flag_of_Peru.svg/22px-Flag_of_Peru.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/cf/Flag_of_Peru.svg/33px-Flag_of_Peru.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/cf/Flag_of_Peru.svg/44px-Flag_of_Peru.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E7%A7%98%E9%B2%81" title="秘鲁">秘魯</a><a href="/wiki/%E5%88%A9%E9%A9%AC" class="mw-redirect" title="利马">利马</a><br />(1983年11月21日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Flag_of_Cuba.svg/22px-Flag_of_Cuba.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Flag_of_Cuba.svg/33px-Flag_of_Cuba.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Flag_of_Cuba.svg/44px-Flag_of_Cuba.svg.png 2x" data-file-width="1200" data-file-height="600" /> </span><a href="/wiki/%E5%8F%A4%E5%B7%B4" title="古巴">古巴</a><a href="/wiki/%E5%93%88%E7%93%A6%E9%82%A3" title="哈瓦那">哈瓦那</a><br />(2005年9月24日)</li>
<li><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Chile.svg/22px-Flag_of_Chile.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Chile.svg/33px-Flag_of_Chile.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Chile.svg/44px-Flag_of_Chile.svg.png 2x" data-file-width="1500" data-file-height="1000" /> </span><a href="/wiki/%E6%99%BA%E5%88%A9" title="智利">智利</a><a href="/wiki/%E5%9C%A3%E5%9C%B0%E4%BA%9A%E5%93%A5_(%E6%99%BA%E5%88%A9)" title="圣地亚哥 (智利)">圣地亚哥</a><br />(2007年年末)<sup id="cite_ref-159" class="reference"><a href="#cite_note-159">[152]</a></sup></li></ul>
</div>
</td></tr></tbody></table>
<h2><span id=".E6.B3.A8.E9.87.8A"></span><span class="mw-headline" id="注释">注释</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=35" title="编辑章节:注释">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div id="references-NoteFoot"><ol class="references">
<li id="cite_note-3"><span class="mw-cite-backlink"><b><a href="#cite_ref-3">^</a></b></span> <span class="reference-text">市区指<a href="/wiki/%E5%9F%8E%E5%85%AD%E5%8C%BA" title="城六区">城六区</a>,即北京市中心城区和拓展区的东城区、西城区、海淀区、朝阳区、丰台区、石景山区六区,面积约为1381平方公里“城六区”就是以前的“城八区”,范围、面积没有改变。“城六区”是现代语境下的北京城。</span>
</li>
<li id="cite_note-16"><span class="mw-cite-backlink"><b><a href="#cite_ref-16">^</a></b></span> <span class="reference-text">与此同时,附近的无终县改名<a href="/wiki/%E6%B8%94%E9%98%B3%E9%83%A1" title="渔阳郡">渔阳</a>成为蓟州的<a href="/wiki/%E8%A1%8C%E6%94%BF%E4%B8%AD%E5%BF%83" title="行政中心">首府</a>,至1913年更用了<a href="/wiki/%E8%93%9F%E5%8E%BF" class="mw-redirect" title="蓟县">蓟县</a>的名称,今天属于<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a>境内,而非今天的北京市范围。所以<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8E%86%E5%8F%B2" title="中国历史">中国历史</a>上隋唐以前的蓟在今<a href="/wiki/%E5%8C%97%E4%BA%AC" class="mw-redirect" title="北京">北京</a>,隋唐以后的蓟在今<a href="/wiki/%E5%A4%A9%E6%B4%A5" class="mw-redirect" title="天津">天津</a>。</span>
</li>
<li id="cite_note-17"><span class="mw-cite-backlink"><b><a href="#cite_ref-17">^</a></b></span> <span class="reference-text">金大定二十九年公元1189年始建石桥,三年后的金章宗明昌三年公元1192年建成,当时称广利桥。</span>
</li>
<li id="cite_note-19"><span class="mw-cite-backlink"><b><a href="#cite_ref-19">^</a></b></span> <span class="reference-text"><a href="/wiki/%E5%8F%A4%E4%BB%A3%E7%AA%81%E5%8E%A5%E8%AA%9E" title="古代突厥語">突厥语</a>为Khanbalik,意为“汗城”,音译为<a href="/wiki/%E6%B1%97%E5%85%AB%E9%87%8C" class="mw-redirect" title="汗八里">汗八里</a>、甘巴力克。</span>
</li>
<li id="cite_note-97"><span class="mw-cite-backlink"><b><a href="#cite_ref-97">^</a></b></span> <span class="reference-text">土地面积为<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E5%85%A8%E5%9B%BD%E5%9C%9F%E5%9C%B0%E8%B0%83%E6%9F%A5" class="mw-redirect" title="第二次全国土地调查">第二次全国土地调查</a>结果数据。</span>
</li>
<li id="cite_note-98"><span class="mw-cite-backlink"><b><a href="#cite_ref-98">^</a></b></span> <span class="reference-text">常住人口为2018年北京市人口变动情况抽样调查数据。</span>
</li>
<li id="cite_note-119"><span class="mw-cite-backlink"><b><a href="#cite_ref-119">^</a></b></span> <span class="reference-text">另有一條國道<a href="/wiki/112%E5%9B%BD%E9%81%93" title="112国道">G112</a>環繞北京但不經過北京市範圍。</span>
</li>
</ol></div>
<h2><span id=".E5.8F.82.E8.80.83.E6.96.87.E7.8C.AE"></span><span class="mw-headline" id="参考文献">参考文献</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=36" title="编辑章节:参考文献">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div class="reflist columns references-column-width" style="-moz-column-width: 32em; -webkit-column-width: 32em; column-width: 32em; list-style-type: decimal;">
<ol class="references">
<li id="cite_note-1"><span class="mw-cite-backlink"><b><a href="#cite_ref-1">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://tjj.beijing.gov.cn/tjsj_31433/tjgb_31445/ndgb_31446/202003/t20200302_1673343.html">北京市2019年国民经济和社会发展统计公报</a>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%822019%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.genre=unknown&rft_id=http%3A%2F%2Ftjj.beijing.gov.cn%2Ftjsj_31433%2Ftjgb_31445%2Fndgb_31446%2F202003%2Ft20200302_1673343.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-2"><span class="mw-cite-backlink"><b><a href="#cite_ref-2">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://www.sohu.com/a/405202052_621014">2019年末北京各区县人口排名,你所在区县人口增多了吗?</a>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=2019%E5%B9%B4%E6%9C%AB%E5%8C%97%E4%BA%AC%E5%90%84%E5%8C%BA%E5%8E%BF%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%90%EF%BC%8C%E4%BD%A0%E6%89%E5%9C%A8%E5%8C%BA%E5%8E%BF%E4%BA%BA%E5%8F%A3%E5%A2%9E%E5%A4%9A%E4%BA%86%E5%90%97%EF%BC%9F&rft.genre=unknown&rft_id=https%3A%2F%2Fwww.sohu.com%2Fa%2F405202052_621014&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-4"><span class="mw-cite-backlink"><b><a href="#cite_ref-4">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://tjj.beijing.gov.cn/tjsj_31433/tjgb_31445/ndgb_31446/202003/t20200302_1673343.html">北京市2019年国民经济和社会发展统计公报</a>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%822019%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.genre=unknown&rft_id=http%3A%2F%2Ftjj.beijing.gov.cn%2Ftjsj_31433%2Ftjgb_31445%2Fndgb_31446%2F202003%2Ft20200302_1673343.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-autogenerated2-5"><span class="mw-cite-backlink"><b><a href="#cite_ref-autogenerated2_5-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.bbtnews.com.cn/2018/0225/230505.shtml">存档副本</a>. <span class="reference-accessdate"> [<span class="nowrap">2018-04-20</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20180420202857/http://www.bbtnews.com.cn/2018/0225/230505.shtml">存档</a>于2018-04-20).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5+%98%E6%A1%A3%E5%89%AF%E6%9C%AC&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bbtnews.com.cn%2F2018%2F0225%2F230505.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-6"><span class="mw-cite-backlink"><b><a href="#cite_ref-6">^</a></b></span> <span class="reference-text"><cite class="citation web">travelguide.michelin.com. <a rel="nofollow" class="external text" href="https://travelguide.michelin.com/asia/china/pekin">Travelguide Beijing</a>. travelguide.michelin.com. <span class="reference-accessdate"> [<span class="nowrap">2020-04-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200425095712/https://travelguide.michelin.com/asia/china/pekin">存档</a>于2020-04-25) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英语网页">(英语)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=travelguide.michelin.com&rft.btitle=Travelguide+Beijing&rft.genre=unknown&rft.pub=travelguide.michelin.com&rft_id=https%3A%2F%2Ftravelguide.michelin.com%2Fasia%2Fchina%2Fpekin&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-7"><span class="mw-cite-backlink"><b><a href="#cite_ref-7">^</a></b></span> <span class="reference-text"><cite class="citation web">马婧. <a rel="nofollow" class="external text" href="http://bj.people.com.cn/n2/2018/0605/c82839-31665914.html">北京总部企业5年增127家 500强总部企业北京全球最多</a>. 人民网. <span class="reference-accessdate"> [<span class="nowrap">2020-01-21</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%BB%E9%83%A8%E4%BC%81%E4%B8%9A5%E5%B9%B4%E5%A2%9E127%E5%AE%B6+500%E5%BC%BA%E6%BB%E9%83%A8%E4%BC%81%E4%B8%9A%E5%8C%97%E4%BA%AC%E5%85%A8%E7%90%83%E6%9C%E5%A4%9A&rft.au=%E9%A9%AC%E5%A9%A7&rft.genre=unknown&rft.jtitle=%E4%BA%BA%E6%B0%91%E7%BD%91&rft_id=http%3A%2F%2Fbj.people.com.cn%2Fn2%2F2018%2F0605%2Fc82839-31665914.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-2018年旅客破亿-8"><span class="mw-cite-backlink"><b><a href="#cite_ref-2018年旅客破亿_8-0">^</a></b></span> <span class="reference-text"><cite class="citation web">赵晓兵. <a rel="nofollow" class="external text" href="http://www.caacnews.com.cn/1/5/201812/t20181228_1263791.html">北京首都国际机场年旅客吞吐量突破1亿人次</a>. 中国民航网. 2018-12-28 <span class="reference-accessdate"> [<span class="nowrap">2018-12-28</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20181228223136/http://www.caacnews.com.cn/1/5/201812/t20181228_1263791.html">存档</a>于2018-12-28).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E8%B5%B5%E6%99%93%E5%85%B5&rft.btitle=%E5%8C%97%E4%BA%AC%E9%A6%96%E9%83%BD%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA%E5%B9%B4%E6%97%85%E5%AE%A2%E5%90%9E%E5%90%90%E9%87%8F%E7%AA%81%E7%A0%B41%E4%BA%BF%E4%BA%BA%E6%AC%A1&rft.date=2018-12-28&rft.genre=unknown&rft.pub=%E4%B8+%E5%9B%BD%E6%B0%91%E8%88%AA%E7%BD%91&rft_id=http%3A%2F%2Fwww.caacnews.com.cn%2F1%2F5%2F201812%2Ft20181228_1263791.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-9"><span class="mw-cite-backlink"><b><a href="#cite_ref-9">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://www.railwaygazette.com/transport-and-mobility-projects/beijing-metro-now-the-worlds-longest/55436.article">Beijing metro now the world’s longest</a>. Railway Gazette Group - Metro Report International. 2019-12-30 <span class="reference-accessdate"> [<span class="nowrap">2020-01-21</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20191230133940/https://www.railwaygazette.com/transport-and-mobility-projects/beijing-metro-now-the-worlds-longest/55436.article">存档</a>于2019-12-30).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=Beijing+metro+now+the+world%99s+longest&rft.date=2019-12-30&rft.genre=unknown&rft.jtitle=Railway+Gazette+Group+-+Metro+Report+International&rft_id=https%3A%2F%2Fwww.railwaygazette.com%2Ftransport-and-mobility-projects%2Fbeijing-metro-now-the-worlds-longest%2F55436.article&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-10"><span class="mw-cite-backlink"><b><a href="#cite_ref-10">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://www.railjournal.com/passenger/metros/beijing-metro-tops-699km-making-it-worlds-largest-network/">Beijing Metro tops 699km making it world's largest network</a>. International Railway Journal. 2019-12-30 <span class="reference-accessdate"> [<span class="nowrap">2020-01-21</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200106092302/https://www.railjournal.com/passenger/metros/beijing-metro-tops-699km-making-it-worlds-largest-network/">存档</a>于2020-01-06).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=Beijing+Metro+tops+699km+making+it+world%27s+largest+network&rft.date=2019-12-30&rft.genre=unknown&rft.jtitle=International+Railway+Journal&rft_id=https%3A%2F%2Fwww.railjournal.com%2Fpassenger%2Fmetros%2Fbeijing-metro-tops-699km-making-it-worlds-largest-network%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-11"><span class="mw-cite-backlink"><b><a href="#cite_ref-11">^</a></b></span> <span class="reference-text"><cite class="citation news">中国城市轨道交通年度报告课题组. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20160304222832/http://huoche.kuxun.cn/news-73978.html">北京地铁成世界最繁忙地铁之首 暑期客流每天破千万人次</a>. 北京: 酷讯. 2012 <span class="reference-accessdate"> [<span class="nowrap">2020-01-21</span>]</span>. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-7-5121-1009-0" title="Special:网络书源/978-7-5121-1009-0"><span title="国际标准书号">ISBN</span> 978-7-5121-1009-0</a>. (<a rel="nofollow" class="external text" href="http://huoche.kuxun.cn/news-73978.html">原始内容</a>存档于2016-03-04).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E6%88%90%E4%B8%96%E7%95%8C%E6%9C%E7%B9%81%E5%BF%99%E5%9C%B0%E9%93%81%E4%B9%E9%A6%96+%E6%9A%91%E6%9C%9F%E5%AE%A2%E6%B5%81%E6%AF%8F%E5%A4%A9%E7%A0%B4%E5%83%E4%B8%87%E4%BA%BA%E6%AC%A1&rft.au=%E4%B8+%E5%9B%BD%E5%9F%8E%E5%B8%82%E8%BD%A8%E9%81%93%E4%BA%A4%E9%9A%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%E8%AF%BE%E9%A2%98%E7%BB%84&rft.date=2012&rft.genre=article&rft.isbn=978-7-5121-1009-0&rft_id=http%3A%2F%2Fhuoche.kuxun.cn%2Fnews-73978.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-Beijing-12"><span class="mw-cite-backlink"><b><a href="#cite_ref-Beijing_12-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.gaokao.com/e/20150522/555e867ac971b.shtml"><bdi lang="zh">2015年北京市高校名单(共91所)</bdi></a>. gaokao.com. 2015-05-22 <span class="reference-accessdate"> [<span class="nowrap">2016-11-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20161130185436/http://www.gaokao.com/e/20150522/555e867ac971b.shtml">存档</a>于2016-11-30).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=2015%E5%B9%B4%E5%8C%97%E4%BA%AC%E5%B8%82%E9%AB%98%E6%A0%A1%E5%90%E5%95%EF%BC%88%E5%85%B191%E6%89%EF%BC%89&rft.date=2015-05-22&rft.genre=unknown&rft.pub=gaokao.com&rft_id=http%3A%2F%2Fwww.gaokao.com%2Fe%2F20150522%2F555e867ac971b.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-13"><span class="mw-cite-backlink"><b><a href="#cite_ref-13">^</a></b></span> <span class="reference-text"><cite class="citation book">徐晉如. <a rel="nofollow" class="external text" href="https://books.google.com.tw/books?id=gNdxAAAAIAAJ&q=%E6%B8%85%E8%8F%AF%E7%AC%AC%E4%B8%80%E5%8C%97%E5%A4%A7%E7%AC%AC%E4%BA%8C&dq=%E6%B8%85%E8%8F%AF%E7%AC%AC%E4%B8%80%E5%8C%97%E5%A4%A7%E7%AC%AC%E4%BA%8C&hl=zh-TW&sa=X&ved=0ahUKEwjf0P-TsqnVAhVLmJQKHQj5DEIQ6AEIJDAA">清華第一北大第二</a>. 北京: 台海出版社. 2006-12-08 <span class="reference-accessdate"> [<span class="nowrap">2017-07-27</span>]</span>. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/7-80141-295-8" title="Special:网络书源/7-80141-295-8"><span title="国际标准书号">ISBN</span> 7-80141-295-8</a> <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%BE%90%E6%99%89%E5%A6%82&rft.btitle=%E6%B8%85%E8%8F%AF%E7%AC%AC%E4%B8%E5%8C%97%E5%A4%A7%E7%AC%AC%E4%BA%8C&rft.date=2006-12-08&rft.genre=book&rft.isbn=7-80141-295-8&rft.place=%E5%8C%97%E4%BA%AC&rft.pub=%E5%8F%B0%E6%B5%B7%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=https%3A%2F%2Fbooks.google.com.tw%2Fbooks%3Fid%3DgNdxAAAAIAAJ%26q%3D%25E6%25B8%2585%25E8%258F%25AF%25E7%25AC%25AC%25E4%25B8%2580%25E5%258C%2597%25E5%25A4%25A7%25E7%25AC%25AC%25E4%25BA%258C%26dq%3D%25E6%25B8%2585%25E8%258F%25AF%25E7%25AC%25AC%25E4%25B8%2580%25E5%258C%2597%25E5%25A4%25A7%25E7%25AC%25AC%25E4%25BA%258C%26hl%3Dzh-TW%26sa%3DX%26ved%3D0ahUKEwjf0P-TsqnVAhVLmJQKHQj5DEIQ6AEIJDAA&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-14"><span class="mw-cite-backlink"><b><a href="#cite_ref-14">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20200824031341/https://www.lboro.ac.uk/gawc/world2020t.html">GaWC - The World According to GaWC 2020</a>. www.lboro.ac.uk. <span class="reference-accessdate"> [<span class="nowrap">2020-09-26</span>]</span>. (<a rel="nofollow" class="external text" href="https://www.lboro.ac.uk/gawc/world2020t.html">原始内容</a>存档于2020-08-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=GaWC+-+The+World+According+to+GaWC+2020&rft.genre=unknown&rft.jtitle=www.lboro.ac.uk&rft_id=https%3A%2F%2Fwww.lboro.ac.uk%2Fgawc%2Fworld2020t.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-15"><span class="mw-cite-backlink"><b><a href="#cite_ref-15">^</a></b></span> <span class="reference-text"><cite class="citation book">宋大川. 北京考古发现与研究 : 1949-2009 第1版. 北京: 科学出版社. 2009-09. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/9787030255693" title="Special:网络书源/9787030255693"><span title="国际标准书号">ISBN</span> 9787030255693</a>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%AE%E5%A4%A7%E5%B7%9D&rft.btitle=%E5%8C%97%E4%BA%AC%E8%83%E5%8F%A4%E5%8F%91%E7%8E%B0%E4%B8%8E%E7%A0%94%E7%A9%B6+%3A+1949-2009&rft.date=2009-09&rft.edition=%E7%AC%AC1%E7%89%88&rft.genre=book&rft.isbn=9787030255693&rft.place=%E5%8C%97%E4%BA%AC&rft.pub=%E7%A7%91%E5+%A6%E5%87%BA%E7%89%88%E7%A4%BE&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span> <span style="display:none;font-size:100%" class="error citation-comment">请检查<code style="color:inherit; border:inherit; padding:inherit;">|access-date=</code>中的日期值 (<a href="/wiki/Help:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF#bad_date" title="Help:引文格式1错误">帮助</a>); </span><span style="display:none;font-size:100%" class="error citation-comment">使用<code style="color:inherit; border:inherit; padding:inherit;">|accessdate=</code>需要含有<code style="color:inherit; border:inherit; padding:inherit;">|url=</code> (<a href="/wiki/Help:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF#accessdate_missing_url" title="Help:引文格式1错误">帮助</a>)</span></span>
</li>
<li id="cite_note-18"><span class="mw-cite-backlink"><b><a href="#cite_ref-18">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.zgswcn.com/2014/0610/414339.shtml">“实京师”与“徙流民” 北京历史上的人口变迁</a>. Zgswcn.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170904085741/http://www.zgswcn.com/2014/0610/414339.shtml">存档</a>于2017-09-04).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%9C%E5%AE%9E%E4%BA%AC%E5%B8%88%9D%E4%B8%8E%9C%E5%BE%99%E6%B5%81%E6%B0%91%9D+%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2%E4%B8%8A%E7%9A%84%E4%BA%BA%E5%8F%A3%E5%8F%98%E8%BF%81&rft.genre=unknown&rft.pub=Zgswcn.com&rft_id=http%3A%2F%2Fwww.zgswcn.com%2F2014%2F0610%2F414339.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-20"><span class="mw-cite-backlink"><b><a href="#cite_ref-20">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.china.com.cn/culture/txt/2007-07/30/content_8599134.htm">381年前北京王恭厂大爆炸之谜 僵尸都"裸体<span style="padding-right:0.2em;">"</span></a>. 中国网. 2007-07-30 <span class="reference-accessdate"> [<span class="nowrap">2014-02-17</span>]</span> <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">(中文)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=381%E5%B9%B4%E5%89%E5%8C%97%E4%BA%AC%E7%8E%E6%81+%E5%8E%82%E5%A4%A7%E7%88%86%E7%82%B8%E4%B9%E8%B0%9C+%E5%83%B5%E5%B0%B8%E9%83%BD%22%E8%A3%B8%E4%BD%93%22&rft.date=2007-07-30&rft.genre=unknown&rft.pub=%E4%B8+%E5%9B%BD%E7%BD%91&rft_id=http%3A%2F%2Fwww.china.com.cn%2Fculture%2Ftxt%2F2007-07%2F30%2Fcontent_8599134.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:0-21"><span class="mw-cite-backlink">^ <a href="#cite_ref-:0_21-0"><sup><b>17.0</b></sup></a> <a href="#cite_ref-:0_21-1"><sup><b>17.1</b></sup></a> <a href="#cite_ref-:0_21-2"><sup><b>17.2</b></sup></a></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.chinanews.com/cul/2013/12-03/5572670.shtml">专家谈明朝灭亡:鼠疫或为重要原因</a>. <a href="/wiki/%E4%B8%AD%E6%96%B0%E7%BD%91" class="mw-redirect" title="中新网">中新网</a>. <span class="reference-accessdate"> [<span class="nowrap">2020-12-29</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E4%B8%93%E5%AE%B6%E8%B0%88%E6%98%8E%E6%9C%9D%E7%81+%E4%BA%A1%EF%BC%9A%E9%BC%A0%E7%96%AB%E6%88%96%E4%B8%BA%E9%87%E8%A6%81%E5%8E%9F%E5%9B%A0&rft.genre=unknown&rft.pub=%E4%B8+%E6%96%B0%E7%BD%91&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fcul%2F2013%2F12-03%2F5572670.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span> <span class="error mw-ext-cite-error" lang="zh" dir="ltr">引用错误:带有name属性“:0”的<code><ref></code>标签用不同内容定义了多次</span></span>
</li>
<li id="cite_note-:1-22"><span class="mw-cite-backlink">^ <a href="#cite_ref-:1_22-0"><sup><b>18.0</b></sup></a> <a href="#cite_ref-:1_22-1"><sup><b>18.1</b></sup></a></span> <span class="reference-text"><cite class="citation journal"><a href="/wiki/%E6%9B%B9%E6%A0%91%E5%9F%BA" title="曹树基">曹树基</a>. <a rel="nofollow" class="external text" href="https://history.sjtu.edu.cn/SJTU/JDHistory/kindeditor/Upload/file/20200709/202007091001022470000.pdf">鼠疫流行与华北社会的变迁 (1580—1644 年)</a> <span style="font-size:85%;">(PDF)</span>. 《历史研究》. 1997, (1).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%BC%A0%E7%96%AB%E6%B5%81%E8%A1%8C%E4%B8%8E%E5%8E%E5%8C%97%E7%A4%BE%E4%BC%9A%E7%9A%84%E5%8F%98%E8%BF%81+%281580%941644+%E5%B9%B4%29&rft.au=%E6%9B%B9%E6%A0%91%E5%9F%BA&rft.date=1997&rft.genre=article&rft.issue=1&rft.jtitle=%E3%8A%E5%8E%86%E5%8F%B2%E7%A0%94%E7%A9%B6%E3&rft_id=https%3A%2F%2Fhistory.sjtu.edu.cn%2FSJTU%2FJDHistory%2Fkindeditor%2FUpload%2Ffile%2F20200709%2F202007091001022470000.pdf&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span> <span class="error mw-ext-cite-error" lang="zh" dir="ltr">引用错误:带有name属性“:1”的<code><ref></code>标签用不同内容定义了多次</span></span>
</li>
<li id="cite_note-:2-23"><span class="mw-cite-backlink">^ <a href="#cite_ref-:2_23-0"><sup><b>19.0</b></sup></a> <a href="#cite_ref-:2_23-1"><sup><b>19.1</b></sup></a></span> <span class="reference-text"><cite class="citation web"><a href="/wiki/%E9%82%B1%E4%BB%B2%E9%BA%9F" title="邱仲麟">邱仲麟</a>. <a rel="nofollow" class="external text" href="http://www.ihp.sinica.edu.tw/~bihp/75/75.2/chiu.htm">明代北京的瘟疫與帝國醫療體系的應變</a>. <a href="/wiki/%E4%B8%AD%E5%A4%AE%E7%A0%94%E7%A9%B6%E9%99%A2" title="中央研究院">中央研究院</a>. <span class="reference-accessdate"> [<span class="nowrap">2020-12-29</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E9%82%B1%E4%BB%B2%E9%BA%9F&rft.btitle=%E6%98%8E%E4%BB%A3%E5%8C%97%E4%BA%AC%E7%9A%84%E7%98%9F%E7%96%AB%E8%88%87%E5%B8%9D%E5%9C%E9%86%AB%E7%99%82%E9%AB%94%E7%B3%BB%E7%9A%84%E6%87%89%E8%AE%8A&rft.genre=unknown&rft.pub=%E4%B8+%E5%A4%AE%E7%A0%94%E7%A9%B6%E9%99%A2&rft_id=http%3A%2F%2Fwww.ihp.sinica.edu.tw%2F~bihp%2F75%2F75.2%2Fchiu.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span> <span class="error mw-ext-cite-error" lang="zh" dir="ltr">引用错误:带有name属性“:2”的<code><ref></code>标签用不同内容定义了多次</span></span>
</li>
<li id="cite_note-:3-24"><span class="mw-cite-backlink"><b><a href="#cite_ref-:3_24-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.xinhuanet.com/publish/2020-07/02/c_1210686600.htm">《中国抗疫简史》:面对灾难,我们自古从未低头!</a>. 新华出版社. 2020-07-02 <span class="reference-accessdate"> [<span class="nowrap">2020-12-29</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E3%8A%E4%B8+%E5%9B%BD%E6%8A%97%E7%96%AB%E7%AE%E5%8F%B2%E3%EF%BC%9A%E9%9D%A2%E5%AF%B9%E7%81%BE%E9%9A%BE%EF%BC%8C%E6%88%91%E4%BB%AC%E8%87%AA%E5%8F%A4%E4%BB%8E%E6%9C%AA%E4%BD%8E%E5%A4%B4%EF%BC%81&rft.date=2020-07-02&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=http%3A%2F%2Fwww.xinhuanet.com%2Fpublish%2F2020-07%2F02%2Fc_1210686600.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-1860年北京条约-25"><span class="mw-cite-backlink"><b><a href="#cite_ref-1860年北京条约_25-0">^</a></b></span> <span class="reference-text">《1860年北京条约》俄国 布克斯盖夫登男爵 著</span>
</li>
<li id="cite_note-bj-general-26"><span class="mw-cite-backlink">^ <a href="#cite_ref-bj-general_26-0"><sup><b>22.00</b></sup></a> <a href="#cite_ref-bj-general_26-1"><sup><b>22.01</b></sup></a> <a href="#cite_ref-bj-general_26-2"><sup><b>22.02</b></sup></a> <a href="#cite_ref-bj-general_26-3"><sup><b>22.03</b></sup></a> <a href="#cite_ref-bj-general_26-4"><sup><b>22.04</b></sup></a> <a href="#cite_ref-bj-general_26-5"><sup><b>22.05</b></sup></a> <a href="#cite_ref-bj-general_26-6"><sup><b>22.06</b></sup></a> <a href="#cite_ref-bj-general_26-7"><sup><b>22.07</b></sup></a> <a href="#cite_ref-bj-general_26-8"><sup><b>22.08</b></sup></a> <a href="#cite_ref-bj-general_26-9"><sup><b>22.09</b></sup></a> <a href="#cite_ref-bj-general_26-10"><sup><b>22.10</b></sup></a> <a href="#cite_ref-bj-general_26-11"><sup><b>22.11</b></sup></a> <a href="#cite_ref-bj-general_26-12"><sup><b>22.12</b></sup></a> <a href="#cite_ref-bj-general_26-13"><sup><b>22.13</b></sup></a> <a href="#cite_ref-bj-general_26-14"><sup><b>22.14</b></sup></a> <a href="#cite_ref-bj-general_26-15"><sup><b>22.15</b></sup></a> <a href="#cite_ref-bj-general_26-16"><sup><b>22.16</b></sup></a> <a href="#cite_ref-bj-general_26-17"><sup><b>22.17</b></sup></a> <a href="#cite_ref-bj-general_26-18"><sup><b>22.18</b></sup></a> <a href="#cite_ref-bj-general_26-19"><sup><b>22.19</b></sup></a></span> <span class="reference-text"><cite class="citation book">北京市地方志编纂委员会. 北京志·综合卷·总述·历史概要·大事记. <a href="/wiki/%E5%8C%97%E4%BA%AC%E5%87%BA%E7%89%88%E7%A4%BE" title="北京出版社">北京出版社</a>. 2013. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-7-200-09633-0" title="Special:网络书源/978-7-200-09633-0"><span title="国际标准书号">ISBN</span> 978-7-200-09633-0</a>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%B0%E6%96%B9%E5%BF%97%E7%BC%96%E7%BA%82%E5%A7%94%E5%91%98%E4%BC%9A&rft.btitle=%E5%8C%97%E4%BA%AC%E5%BF%97+%B7%E7%BB%BC%E5%90%88%E5%B7+%B7%E6%BB%E8%BF%B0+%B7%E5%8E%86%E5%8F%B2%E6%A6%82%E8%A6%81+%B7%E5%A4%A7%E4%BA%E8%AE%B0&rft.date=2013&rft.genre=book&rft.isbn=978-7-200-09633-0&rft.pub=%E5%8C%97%E4%BA%AC%E5%87%BA%E7%89%88%E7%A4%BE&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-27"><span class="mw-cite-backlink"><b><a href="#cite_ref-27">^</a></b></span> <span class="reference-text">中華民國史事日誌.中華民國八年己未.第437頁</span>
</li>
<li id="cite_note-28"><span class="mw-cite-backlink"><b><a href="#cite_ref-28">^</a></b></span> <span class="reference-text"><cite class="citation journal">許雪姬. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20180201011031/http://memo.cgu.edu.tw/cgjhsc/data_files/1-1%2003.pdf">1937至1947年在北京的台灣人</a> <span style="font-size:85%;">(PDF)</span>. 長庚人文社會學報. 2008年4月, <b>1</b> (1): 33–84 <span class="reference-accessdate"> [<span class="nowrap">2017-10-12</span>]</span>. <a rel="nofollow" class="external text" href="//www.worldcat.org/issn/2070-9455"><span title="国际标准连续出版物号">ISSN 2070-9455</span></a>. (<a rel="nofollow" class="external text" href="http://memo.cgu.edu.tw/cgjhsc/data_files/1-1%2003.pdf">原始内容</a> <span style="font-size:85%;">(pdf)</span>存档于2018-02-01).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=1937%E8%87%B31947%E5%B9%B4%E5%9C%A8%E5%8C%97%E4%BA%AC%E7%9A%84%E5%8F%B0%E7%81%A3%E4%BA%BA&rft.au=%E8%A8%B1%E9%9B%AA%E5%A7%AC&rft.date=2008-04&rft.genre=article&rft.issn=2070-9455&rft.issue=1&rft.jtitle=%E9%95%B7%E5%BA%9A%E4%BA%BA%E6%96%87%E7%A4%BE%E6%9C%83%E5+%B8%E5%A0%B1&rft.pages=33-84&rft.volume=1&rft_id=http%3A%2F%2Fmemo.cgu.edu.tw%2Fcgjhsc%2Fdata_files%2F1-1%252003.pdf&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-29"><span class="mw-cite-backlink"><b><a href="#cite_ref-29">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://vip.book.sina.com.cn/book/chapter_98283_62873.html">傅作义与北平和平解放简介</a>. 新浪读书. 2009-06-29 <span class="reference-accessdate"> [<span class="nowrap">2012-02-03</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20171116072032/http://vip.book.sina.com.cn/book/chapter_98283_62873.html">存档</a>于2017-11-16) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(简体)网页">(中文(简体))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%82%85%E4%BD%9C%E4%B9%89%E4%B8%8E%E5%8C%97%E5%B9%B3%E5%92%8C%E5%B9%B3%E8%A7%A3%E6%94%BE%E7%AE%E4%BB&rft.date=2009-06-29&rft.genre=unknown&rft.pub=%E6%96%B0%E6%B5%AA%E8%AF%BB%E4%B9%A6&rft_id=http%3A%2F%2Fvip.book.sina.com.cn%2Fbook%2Fchapter_98283_62873.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-30"><span class="mw-cite-backlink"><b><a href="#cite_ref-30">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20170312071847/http://dangshi.people.com.cn/GB/120280/9437260.html">共和国大阅兵</a>. 中国共产党新闻网. <span class="reference-accessdate"> [<span class="nowrap">2017-01-16</span>]</span>. (<a rel="nofollow" class="external text" href="http://dangshi.people.com.cn/GB/120280/9437260.html">原始内容</a>存档于2017-03-12).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%85%B1%E5%92%8C%E5%9B%BD%E5%A4%A7%E9%98%85%E5%85%B5&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E6%96%B0%E9%97%BB%E7%BD%91&rft_id=http%3A%2F%2Fdangshi.people.com.cn%2FGB%2F120280%2F9437260.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-31"><span class="mw-cite-backlink"><b><a href="#cite_ref-31">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.china.com.cn/fangtan/2009-12/09/content_19033074.htm?show=t">彭真与北京新城建设(上)</a>. 中国网. 2009-12-11 <span class="reference-accessdate"> [<span class="nowrap">2020-10-20</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%BD+%E7%9C%9F%E4%B8%8E%E5%8C%97%E4%BA%AC%E6%96%B0%E5%9F%8E%E5%BB%BA%E8%AE%BE%28%E4%B8%8A%29&rft.date=2009-12-11&rft.genre=unknown&rft.pub=%E4%B8+%E5%9B%BD%E7%BD%91&rft_id=http%3A%2F%2Fwww.china.com.cn%2Ffangtan%2F2009-12%2F09%2Fcontent_19033074.htm%3Fshow%3Dt&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-32"><span class="mw-cite-backlink"><b><a href="#cite_ref-32">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="https://news.sina.com.cn/c/2004-08-17/02303409390s.shtml">北京旧城保护调查之回顾</a>. <a href="/wiki/%E6%96%B0%E4%BA%AC%E6%8A%A5" title="新京报">新京报</a>. 2004-08-17 <span class="reference-accessdate"> [<span class="nowrap">2020-10-20</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%97%A7%E5%9F%8E%E4%BF%9D%E6%8A%A4%E8%B0%83%E6%9F%A5%E4%B9%E5%9B%9E%E9%A1%BE&rft.date=2004-08-17&rft.genre=article&rft.jtitle=%E6%96%B0%E4%BA%AC%E6%8A%A5&rft_id=https%3A%2F%2Fnews.sina.com.cn%2Fc%2F2004-08-17%2F02303409390s.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:12-33"><span class="mw-cite-backlink"><b><a href="#cite_ref-:12_33-0">^</a></b></span> <span class="reference-text"><cite class="citation book">熊景明; 宋永毅; 余國良. <a rel="nofollow" class="external text" href="https://books.google.com/books?id=diezDwAAQBAJ&pg=PR43&lpg=PR43&dq=%E7%BA%A2%E8%89%B2%E6%81%90%E6%80%96&source=bl&ots=W_IvRAEcEc&sig=ACfU3U0cfKW2t91VCadqDd1HUSHQDKuf5w&hl=en&ppis=_e&sa=X&ved=2ahUKEwiisLqpsKrmAhVCgK0KHVvUCUIQ6AEwBnoECAgQAQ#v=onepage&q=%E7%BA%A2%E8%89%B2%E6%81%90%E6%80%96%E4%B8%87%E5%B2%81&f=false">中外學者談文革</a>. The Chinese University Press. 2018-06-15. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-988-17563-3-6" title="Special:网络书源/978-988-17563-3-6"><span title="国际标准书号">ISBN</span> 978-988-17563-3-6</a> <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到俄语网页">(俄语)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E4%BD%99%E5%9C%E8%89%AF&rft.au=%E5%AE%E6%B0%B8%E6%AF%85&rft.au=%E7%86%8A%E6%99%AF%E6%98%8E&rft.btitle=%E4%B8+%E5%A4%96%E5+%B8%E8%85%E8%AB%87%E6%96%87%E9%9D%A9&rft.date=2018-06-15&rft.genre=book&rft.isbn=978-988-17563-3-6&rft.pub=The+Chinese+University+Press&rft_id=https%3A%2F%2Fbooks.google.com%2Fbooks%3Fid%3DdiezDwAAQBAJ%26pg%3DPR43%26lpg%3DPR43%26dq%3D%25E7%25BA%25A2%25E8%2589%25B2%25E6%2581%2590%25E6%2580%2596%26source%3Dbl%26ots%3DW_IvRAEcEc%26sig%3DACfU3U0cfKW2t91VCadqDd1HUSHQDKuf5w%26hl%3Den%26ppis%3D_e%26sa%3DX%26ved%3D2ahUKEwiisLqpsKrmAhVCgK0KHVvUCUIQ6AEwBnoECAgQAQ%23v%3Donepage%26q%3D%25E7%25BA%25A2%25E8%2589%25B2%25E6%2581%2590%25E6%2580%2596%25E4%25B8%2587%25E5%25B2%2581%26f%3Dfalse&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:15-34"><span class="mw-cite-backlink">^ <a href="#cite_ref-:15_34-0"><sup><b>30.0</b></sup></a> <a href="#cite_ref-:15_34-1"><sup><b>30.1</b></sup></a></span> <span class="reference-text"><cite class="citation web">王友琴. <a rel="nofollow" class="external text" href="http://www.yhcqw.com/33/8055.html">恐怖的“红八月”</a>. 炎黄春秋. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20191210070701/http://www.yhcqw.com/33/8055.html">存档</a>于2019-12-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E7%8E%E5%8F%E7%90%B4&rft.btitle=%E6%81%90%E6%96%E7%9A%84%9C%E7%BA%A2%E5%85%AB%E6%9C%88%9D&rft.genre=unknown&rft.pub=%E7%82%8E%E9%BB%84%E6%98%A5%E7%A7&rft_id=http%3A%2F%2Fwww.yhcqw.com%2F33%2F8055.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:14-35"><span class="mw-cite-backlink"><b><a href="#cite_ref-:14_35-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://www.rfa.org/mandarin/zhuanlan/xinlingzhilyu/wengebeiwanglu/m0816mind-08152013163142.html">47周年回放:再忆文革“八.一八”和 “红八月”</a>. Radio Free Asia. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20191210060415/https://www.rfa.org/mandarin/zhuanlan/xinlingzhilyu/wengebeiwanglu/m0816mind-08152013163142.html">存档</a>于2019-12-10) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=47%E5%91%A8%E5%B9%B4%E5%9B%9E%E6%94%BE%EF%BC%9A%E5%86%E5%BF%86%E6%96%87%E9%9D%A9%9C%E5%85%AB.%E4%B8%E5%85%AB%9D%E5%92%8C+%9C%E7%BA%A2%E5%85%AB%E6%9C%88%9D&rft.genre=unknown&rft.jtitle=Radio+Free+Asia&rft_id=https%3A%2F%2Fwww.rfa.org%2Fmandarin%2Fzhuanlan%2Fxinlingzhilyu%2Fwengebeiwanglu%2Fm0816mind-08152013163142.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-36"><span class="mw-cite-backlink"><b><a href="#cite_ref-36">^</a></b></span> <span class="reference-text"><cite class="citation web">杜钧福. <a rel="nofollow" class="external text" href="http://mjlsh.usc.cuhk.edu.hk/Book.aspx?cid=4&tid=1165">西纠</a>. 香港中文大学. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160804183418/http://mjlsh.usc.cuhk.edu.hk/Book.aspx?cid=4&tid=1165">存档</a>于2016-08-04).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E6%9D%9C%E9%92%A7%E7%A6%8F&rft.btitle=%E8%A5%BF%E7%BA%A0&rft.genre=unknown&rft.pub=%E9%A6%99%E6%B8%AF%E4%B8+%E6%96%87%E5%A4%A7%E5+%A6&rft_id=http%3A%2F%2Fmjlsh.usc.cuhk.edu.hk%2FBook.aspx%3Fcid%3D4%26tid%3D1165&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-37"><span class="mw-cite-backlink"><b><a href="#cite_ref-37">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.ifeng.com/history/shixueyuan/detail_2014_01/15/33042066_0.shtml">兰台说史第1期:揭秘宋彬彬道歉背后隐藏的历史</a>. 凤凰网. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20191120161145/http://news.ifeng.com/history/shixueyuan/detail_2014_01/15/33042066_0.shtml">存档</a>于2019-11-20).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%85%B0%E5%8F%B0%E8%AF%B4%E5%8F%B2%E7%AC%AC1%E6%9C%9F%EF%BC%9A%E6%8F+%E7%A7%98%E5%AE%E5%BD%AC%E5%BD%AC%E9%81%93%E6+%89%E8%83%8C%E5%90%8E%E9%9A%90%E8%97%8F%E7%9A%84%E5%8E%86%E5%8F%B2&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E7%BD%91&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fhistory%2Fshixueyuan%2Fdetail_2014_01%2F15%2F33042066_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-38"><span class="mw-cite-backlink"><b><a href="#cite_ref-38">^</a></b></span> <span class="reference-text"><cite class="citation web">孙言诚. <a rel="nofollow" class="external text" href="http://www.cnd.org/CR/ZK18/cr986.gb.html">谁制造了“红八月”的恐怖狂潮</a>. 华夏文摘. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200629132134/http://www.cnd.org/CR/ZK18/cr986.gb.html">存档</a>于2020-06-29).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5+%99%E8%A8%E8%AF%9A&rft.btitle=%E8%B0%81%E5%88%B6%E9%A0%E4%BA%86%9C%E7%BA%A2%E5%85%AB%E6%9C%88%9D%E7%9A%84%E6%81%90%E6%96%E7%82%E6%BD%AE&rft.genre=unknown&rft.pub=%E5%8E%E5%A4%8F%E6%96%87%E6%91%98&rft_id=http%3A%2F%2Fwww.cnd.org%2FCR%2FZK18%2Fcr986.gb.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:31-39"><span class="mw-cite-backlink"><b><a href="#cite_ref-:31_39-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://cpc.people.com.cn/GB/69112/75843/75871/5164013.html">第九章 颠倒乾坤的“文化大革命”--中国共产党新闻</a>. 人民网. <span class="reference-accessdate"> [<span class="nowrap">2020-02-15</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200629132151/http://cpc.people.com.cn/GB/69112/75843/75871/5164013.html">存档</a>于2020-06-29).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%AC%AC%E4%B9%9D%E7%AB%A0%E3%E9%A2%A0%E5%92%E4%B9%BE%E5%9D%A4%E7%9A%84%9C%E6%96%87%E5%8C%96%E5%A4%A7%E9%9D%A9%E5%91%BD%9D--%E4%B8+%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E6%96%B0%E9%97%BB&rft.genre=unknown&rft.pub=%E4%BA%BA%E6%B0%91%E7%BD%91&rft_id=http%3A%2F%2Fcpc.people.com.cn%2FGB%2F69112%2F75843%2F75871%2F5164013.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:17-40"><span class="mw-cite-backlink"><b><a href="#cite_ref-:17_40-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.ifengweekly.com/detil.php?id=604">怎样反思“红卫兵”</a>. 凤凰周刊. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20171016074817/http://ifengweekly.com/detil.php?id=604">存档</a>于2017-10-16).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%8E%E6%A0%B7%E5%8F%E6%9D%9C%E7%BA%A2%E5%AB%E5%85%B5%9D&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E5%91%A8%E5%88%8A&rft_id=http%3A%2F%2Fwww.ifengweekly.com%2Fdetil.php%3Fid%3D604&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:7-41"><span class="mw-cite-backlink"><b><a href="#cite_ref-:7_41-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.ifeng.com/history/zhiqing/ziliao/detail_2013_09/02/29238981_0.shtml">北京日报:1966年红卫兵在北京40天打死1772人</a>. 凤凰网. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20191210045130/http://news.ifeng.com/history/zhiqing/ziliao/detail_2013_09/02/29238981_0.shtml">存档</a>于2019-12-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5%EF%BC%9A1966%E5%B9%B4%E7%BA%A2%E5%AB%E5%85%B5%E5%9C%A8%E5%8C%97%E4%BA%AC40%E5%A4%A9%E6%89%93%E6+%BB1772%E4%BA%BA&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E7%BD%91&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fhistory%2Fzhiqing%2Fziliao%2Fdetail_2013_09%2F02%2F29238981_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:20-42"><span class="mw-cite-backlink"><b><a href="#cite_ref-:20_42-0">^</a></b></span> <span class="reference-text"><cite class="citation web">遇罗文. <a rel="nofollow" class="external text" href="http://ywang.uchicago.edu/history/daxintusa.htm">大兴屠杀调查</a>. 芝加哥大学. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20190507004605/http://ywang.uchicago.edu/history/daxintusa.htm">存档</a>于2019-05-07).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E9%81%87%E7%BD%97%E6%96%87&rft.btitle=%E5%A4%A7%E5%85%B4%E5%B1%A0%E6%9D%E8%B0%83%E6%9F%A5&rft.genre=unknown&rft.pub=%E8%8A%9D%E5%8A%A0%E5%93%A5%E5%A4%A7%E5+%A6&rft_id=http%3A%2F%2Fywang.uchicago.edu%2Fhistory%2Fdaxintusa.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:21-43"><span class="mw-cite-backlink"><b><a href="#cite_ref-:21_43-0">^</a></b></span> <span class="reference-text"><cite class="citation book">熊景明; 宋永毅; 余國良. <a rel="nofollow" class="external text" href="https://books.google.com/books?id=diezDwAAQBAJ&pg=PA62&lpg=PA62&dq=%E5%8C%97%E4%BA%AC+%E5%A6%82%E6%9E%9C%E4%BD%A0%E6%8A%8A%E6%89%93%E4%BA%BA%E7%9A%84%E4%BA%BA%E6%89%A3%E7%95%99%E8%B5%B7%E6%9D%A5%EF%BC%8C%E6%8D%95%E8%B5%B7%E6%9D%A5%EF%BC%8C%E4%BD%A0%E4%BB%AC%E5%B0%B1%E8%A6%81%E7%8A%AF%E9%94%99%E8%AF%AF&source=bl&ots=W_IwIwEeFa&sig=ACfU3U1_kr-aQqJfo7Tfvdq2bMgh9hdNiA&hl=en&ppis=_e&sa=X&ved=2ahUKEwjqwofPkKzmAhXEIDQIHdbODe8Q6AEwAHoECAkQAQ#v=onepage&q=%E5%8C%97%E4%BA%AC%20%E5%A6%82%E6%9E%9C%E4%BD%A0%E6%8A%8A%E6%89%93%E4%BA%BA%E7%9A%84%E4%BA%BA%E6%89%A3%E7%95%99%E8%B5%B7%E6%9D%A5%EF%BC%8C%E6%8D%95%E8%B5%B7%E6%9D%A5%EF%BC%8C%E4%BD%A0%E4%BB%AC%E5%B0%B1%E8%A6%81%E7%8A%AF%E9%94%99%E8%AF%AF&f=false">中外學者談文革</a>. The Chinese University Press. 2018-06-15. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-988-17563-3-6" title="Special:网络书源/978-988-17563-3-6"><span title="国际标准书号">ISBN</span> 978-988-17563-3-6</a> <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到俄语网页">(俄语)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E4%BD%99%E5%9C%E8%89%AF&rft.au=%E5%AE%E6%B0%B8%E6%AF%85&rft.au=%E7%86%8A%E6%99%AF%E6%98%8E&rft.btitle=%E4%B8+%E5%A4%96%E5+%B8%E8%85%E8%AB%87%E6%96%87%E9%9D%A9&rft.date=2018-06-15&rft.genre=book&rft.isbn=978-988-17563-3-6&rft.pub=The+Chinese+University+Press&rft_id=https%3A%2F%2Fbooks.google.com%2Fbooks%3Fid%3DdiezDwAAQBAJ%26pg%3DPA62%26lpg%3DPA62%26dq%3D%25E5%258C%2597%25E4%25BA%25AC%2B%25E5%25A6%2582%25E6%259E%259C%25E4%25BD%25A0%25E6%258A%258A%25E6%2589%2593%25E4%25BA%25BA%25E7%259A%2584%25E4%25BA%25BA%25E6%2589%25A3%25E7%2595%2599%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E6%258D%2595%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E4%25BD%25A0%25E4%25BB%25AC%25E5%25B0%25B1%25E8%25A6%2581%25E7%258A%25AF%25E9%2594%2599%25E8%25AF%25AF%26source%3Dbl%26ots%3DW_IwIwEeFa%26sig%3DACfU3U1_kr-aQqJfo7Tfvdq2bMgh9hdNiA%26hl%3Den%26ppis%3D_e%26sa%3DX%26ved%3D2ahUKEwjqwofPkKzmAhXEIDQIHdbODe8Q6AEwAHoECAkQAQ%23v%3Donepage%26q%3D%25E5%258C%2597%25E4%25BA%25AC%2520%25E5%25A6%2582%25E6%259E%259C%25E4%25BD%25A0%25E6%258A%258A%25E6%2589%2593%25E4%25BA%25BA%25E7%259A%2584%25E4%25BA%25BA%25E6%2589%25A3%25E7%2595%2599%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E6%258D%2595%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E4%25BD%25A0%25E4%25BB%25AC%25E5%25B0%25B1%25E8%25A6%2581%25E7%258A%25AF%25E9%2594%2599%25E8%25AF%25AF%26f%3Dfalse&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:8-44"><span class="mw-cite-backlink"><b><a href="#cite_ref-:8_44-0">^</a></b></span> <span class="reference-text"><cite class="citation web">宋永毅. <a rel="nofollow" class="external text" href="https://boxun.com/news/gb/z_special/2011/09/201109160825.shtml">文革中“非正常死亡”了多少人? ---- 读苏扬的《文革中中国农村的集体屠杀》</a>. 博讯. <span class="reference-accessdate"> [<span class="nowrap">2019-12-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20191210045125/https://boxun.com/news/gb/z_special/2011/09/201109160825.shtml">存档</a>于2019-12-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%AE%E6%B0%B8%E6%AF%85&rft.btitle=%E6%96%87%E9%9D%A9%E4%B8+%9C%E9%9D%9E%E6+%A3%E5%B8%B8%E6+%BB%E4%BA%A1%9D%E4%BA%86%E5%A4%9A%E5%B0%91%E4%BA%BA%EF%BC%9F+----+%E8%AF%BB%E8%8F%E6%89%AC%E7%9A%84%E3%8A%E6%96%87%E9%9D%A9%E4%B8+%E4%B8+%E5%9B%BD%E5%86%9C%E6%9D%91%E7%9A%84%E9%9B%86%E4%BD%93%E5%B1%A0%E6%9D%E3&rft.genre=unknown&rft.pub=%E5%9A%E8%AE%AF&rft_id=https%3A%2F%2Fboxun.com%2Fnews%2Fgb%2Fz_special%2F2011%2F09%2F201109160825.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-趙紫陽-45"><span class="mw-cite-backlink"><b><a href="#cite_ref-趙紫陽_45-0">^</a></b></span> <span class="reference-text"><cite class="citation book"><a href="/wiki/%E8%B6%99%E7%B4%AB%E9%99%BD" class="mw-redirect" title="趙紫陽">趙紫陽</a>. <a rel="nofollow" class="external text" href="https://books.google.com.tw/books?id=9ooub2kRkRQC&printsec=frontcover&hl=zh-TW#v=onepage&q&f=false">《改革歷程》 [Prisoner of the State: The Secret Journal of Premier Zhao Ziyang]</a>. 美國紐約: <a href="/wiki/%E8%A5%BF%E8%92%99%E8%88%87%E8%88%92%E6%96%AF%E7%89%B9" title="西蒙與舒斯特">西蒙與舒斯特</a>. 2009-05-19 <span class="reference-accessdate"> [<span class="nowrap">2013-12-28</span>]</span>. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-1439149386" title="Special:网络书源/978-1439149386"><span title="国际标准书号">ISBN</span> 978-1439149386</a>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20140106033000/http://books.google.com.tw/books?id=9ooub2kRkRQC&printsec=frontcover&hl=zh-TW#v=onepage&q&f=false">存档</a>于2014-01-06) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英语网页">(英语)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E8%B6%99%E7%B4%AB%E9%99%BD&rft.btitle=%E3%8A%E6%94%B9%E9%9D%A9%E6+%B7%E7%A8%E3&rft.date=2009-05-19&rft.genre=book&rft.isbn=978-1439149386&rft.place=%E7%BE%8E%E5%9C%E7%B4%90%E7%B4%84&rft.pub=%E8%A5%BF%E8%92%99%E8%88%87%E8%88%92%E6%96%AF%E7%89%B9&rft_id=https%3A%2F%2Fbooks.google.com.tw%2Fbooks%3Fid%3D9ooub2kRkRQC%26printsec%3Dfrontcover%26hl%3Dzh-TW%23v%3Donepage%26q%26f%3Dfalse&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-46"><span class="mw-cite-backlink"><b><a href="#cite_ref-46">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://sports.sina.com.cn/9811/112541.html">北京市正式宣布申办2008年奥运会</a>. <a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">新华社</a>. 1998-11-25 <span class="reference-accessdate"> [<span class="nowrap">2020-02-19</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200219044445/http://sports.sina.com.cn/9811/112541.html">存档</a>于2020-02-19).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E6+%A3%E5%BC%8F%E5%AE%A3%E5%B8%83%E7%94%B3%E5%8A%9E2008%E5%B9%B4%E5%A5%A5%E8%BF%90%E4%BC%9A&rft.date=1998-11-25&rft.genre=article&rft.jtitle=%E6%96%B0%E5%8E%E7%A4%BE&rft_id=http%3A%2F%2Fsports.sina.com.cn%2F9811%2F112541.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-47"><span class="mw-cite-backlink"><b><a href="#cite_ref-47">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="https://www.thepaper.cn/newsDetail_forward_2148156">口述中国|建筑师③贝聿铭:四合院是中国的代表建筑</a> 2018-06-06 澎湃新闻 贝聿铭/口述 王军/采访</span>
</li>
<li id="cite_note-灾情通报2-48"><span class="mw-cite-backlink"><b><a href="#cite_ref-灾情通报2_48-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20120727125100/http://news.163.com/12/0724/15/876J4NI700014JB6.html">北京暴雨造成倒塌房屋10660间</a>. 网易. <span class="reference-accessdate"> [<span class="nowrap">2012-07-25</span>]</span>. (<a rel="nofollow" class="external text" href="http://news.163.com/12/0724/15/876J4NI700014JB6.html">原始内容</a>存档于2012-07-27).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%9A%B4%E9%9B%A8%E9%A0%E6%88%90%E5%92%E5%A1%8C%E6%88%BF%E5%B110660%E9%97%B4&rft.genre=unknown&rft.pub=%E7%BD%91%E6%98%93&rft_id=http%3A%2F%2Fnews.163.com%2F12%2F0724%2F15%2F876J4NI700014JB6.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-人民网20120806-49"><span class="mw-cite-backlink"><b><a href="#cite_ref-人民网20120806_49-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20121109121351/http://xj.people.com.cn/n/2012/0806/c186332-17325550.html">北京7-21特大暴雨遇难者人数升至79人</a>. <a href="/wiki/%E4%BA%BA%E6%B0%91%E7%BD%91" title="人民网">人民网</a>. 2012年8月6日 <span class="reference-accessdate"> [2012年8月12日]</span>. (<a rel="nofollow" class="external text" href="http://xj.people.com.cn/n/2012/0806/c186332-17325550.html">原始内容</a>存档于2012年11月9日).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC7-21%E7%89%B9%E5%A4%A7%E6%9A%B4%E9%9B%A8%E9%81%87%E9%9A%BE%E8%85%E4%BA%BA%E6%95%B0%E5%87%E8%87%B379%E4%BA%BA&rft.date=2012-08-06&rft.genre=unknown&rft.pub=%E4%BA%BA%E6%B0%91%E7%BD%91&rft_id=http%3A%2F%2Fxj.people.com.cn%2Fn%2F2012%2F0806%2Fc186332-17325550.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-50"><span class="mw-cite-backlink"><b><a href="#cite_ref-50">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/07/120725_beijing_rain_weibo.shtml">网民质疑北京暴雨死亡人数</a>. BBC中文网. <span class="reference-accessdate"> [<span class="nowrap">2012-07-25</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20120725125028/http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/07/120725_beijing_rain_weibo.shtml">存档</a>于2012-07-25).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%BD%91%E6%B0%91%E8%B4%A8%E7%96%91%E5%8C%97%E4%BA%AC%E6%9A%B4%E9%9B%A8%E6+%BB%E4%BA%A1%E4%BA%BA%E6%95%B0&rft.genre=unknown&rft.pub=BBC%E4%B8+%E6%96%87%E7%BD%91&rft_id=http%3A%2F%2Fwww.bbc.co.uk%2Fzhongwen%2Fsimp%2Fchinese_news%2F2012%2F07%2F120725_beijing_rain_weibo.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-51"><span class="mw-cite-backlink"><b><a href="#cite_ref-51">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.chinanews.com/gn/2014/02-26/5887329.shtml">习近平北京考察提要求:遏制“摊大饼”式发展</a>. <a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">新华社</a>. 2014-02-26 <span class="reference-accessdate"> [<span class="nowrap">2020-10-20</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B9%A0%E8%BF%91%E5%B9%B3%E5%8C%97%E4%BA%AC%E8%83%E5%AF%9F%E6%8F%90%E8%A6%81%E6%B1%82%3A%E9%81%8F%E5%88%B6%9C%E6%91%8A%E5%A4%A7%E9%A5%BC%9D%E5%BC%8F%E5%8F%91%E5%B1%95&rft.date=2014-02-26&rft.genre=article&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fgn%2F2014%2F02-26%2F5887329.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-52"><span class="mw-cite-backlink"><b><a href="#cite_ref-52">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.xinhuanet.com/politics/2014-02/27/c_119538131.htm">打破"一亩三分地" 习近平就京津冀协同发展提七点要求</a>. <a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">新华社</a>. 2014-02-27 <span class="reference-accessdate"> [<span class="nowrap">2020-10-20</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E6%89%93%E7%A0%B4%22%E4%B8%E4%BA%A9%E4%B8%89%E5%88%86%E5%9C%B0%22+%E4%B9%A0%E8%BF%91%E5%B9%B3%E5%B0%B1%E4%BA%AC%E6%B4%A5%E5%86%E5%8F%E5%90%8C%E5%8F%91%E5%B1%95%E6%8F%90%E4%B8%83%E7%82%B9%E8%A6%81%E6%B1%82&rft.date=2014-02-27&rft.genre=article&rft_id=http%3A%2F%2Fwww.xinhuanet.com%2Fpolitics%2F2014-02%2F27%2Fc_119538131.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:25-53"><span class="mw-cite-backlink"><b><a href="#cite_ref-:25_53-0">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.bbc.com/zhongwen/simp/china/2015/12/151207_beijing_smog_red_alert">雾霾持续 北京首次启动重污染红色预警</a>. BBC 中文网. <span class="reference-accessdate"> [2015年12月21日]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20151210042117/http://www.bbc.com/zhongwen/simp/china/2015/12/151207_beijing_smog_red_alert">存档</a>于2015年12月10日).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%9B%BE%E9%9C%BE%E6%8C%81%E7%BB++%E5%8C%97%E4%BA%AC%E9%A6%96%E6%AC%A1%E5%90%AF%E5%8A%A8%E9%87%E6%B1%A1%E6%9F%93%E7%BA%A2%E8%89%B2%E9%A2%84%E8+%A6&rft.genre=article&rft.jtitle=BBC+%E4%B8+%E6%96%87%E7%BD%91&rft_id=http%3A%2F%2Fwww.bbc.com%2Fzhongwen%2Fsimp%2Fchina%2F2015%2F12%2F151207_beijing_smog_red_alert&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:13-54"><span class="mw-cite-backlink"><b><a href="#cite_ref-:13_54-0">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://cn.nytimes.com/china/20151208/c08china/">北京首次启动雾霾红色预警</a>. 中文纽约时报. <span class="reference-accessdate"> [<span class="nowrap">2015-12-21</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20151220031821/http://cn.nytimes.com/china/20151208/c08china/">存档</a>于2015-12-20).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E9%A6%96%E6%AC%A1%E5%90%AF%E5%8A%A8%E9%9B%BE%E9%9C%BE%E7%BA%A2%E8%89%B2%E9%A2%84%E8+%A6&rft.genre=article&rft.jtitle=%E4%B8+%E6%96%87%E7%BA%BD%E7%BA%A6%E6%97%B6%E6%8A%A5&rft_id=http%3A%2F%2Fcn.nytimes.com%2Fchina%2F20151208%2Fc08china%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-:5-55"><span class="mw-cite-backlink"><b><a href="#cite_ref-:5_55-0">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://news.sohu.com/20151219/n431864977.shtml">北京10天两次启动雾霾红色预警 天津河北不跟进</a>. 搜狐新闻. <span class="reference-accessdate"> [2015年12月21日]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20151222083928/http://news.sohu.com/20151219/n431864977.shtml">存档</a>于2015年12月22日).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC10%E5%A4%A9%E4%B8%A4%E6%AC%A1%E5%90%AF%E5%8A%A8%E9%9B%BE%E9%9C%BE%E7%BA%A2%E8%89%B2%E9%A2%84%E8+%A6+%E5%A4%A9%E6%B4%A5%E6%B2%B3%E5%8C%97%E4%B8%E8%B7%9F%E8%BF%9B&rft.genre=article&rft.jtitle=%E6%90%9C%E7%90%E6%96%B0%E9%97%BB&rft_id=http%3A%2F%2Fnews.sohu.com%2F20151219%2Fn431864977.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-56"><span class="mw-cite-backlink"><b><a href="#cite_ref-56">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://www.apdnews.com/news/76298.html">北京正式申办2022年冬奥会</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20160304212457/http://www.apdnews.com/news/76298.html">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,亚太日报,2014年3月17日</span>
</li>
<li id="cite_note-57"><span class="mw-cite-backlink"><b><a href="#cite_ref-57">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://china.cnr.cn/xwwgf/20170928/t20170928_523969507.shtml">北京城市总体规划获批复:加强“四个中心”功能建设</a>. <a href="/wiki/%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E5%B9%BF%E6%92%AD%E7%94%B5%E5%8F%B0" title="中央人民广播电台">中央人民广播电台</a>. 2017-09-28 <span class="reference-accessdate"> [<span class="nowrap">2020-09-16</span>]</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E6%BB%E4%BD%93%E8%A7%84%E5%88%92%E8%8E%B7%E6%89%B9%E5%A4%EF%BC%9A%E5%8A%A0%E5%BC%BA%9C%E5%9B%9B%E4%B8%AA%E4%B8+%E5%BF%83%9D%E5%8A%9F%E8%83%BD%E5%BB%BA%E8%AE%BE&rft.date=2017-09-28&rft.genre=article&rft_id=http%3A%2F%2Fchina.cnr.cn%2Fxwwgf%2F20170928%2Ft20170928_523969507.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-58"><span class="mw-cite-backlink"><b><a href="#cite_ref-58">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://society.people.com.cn/n1/2017/1123/c1008-29664636.html">北京大兴“11·18”火灾遇难者死因确定</a>. 人民网. 新华网. 2017-11-23 <span class="reference-accessdate"> [<span class="nowrap">2017-11-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20171201031113/http://society.people.com.cn/n1/2017/1123/c1008-29664636.html">存档</a>于2017-12-01).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%9C11+%B718%9D%E7%81%AB%E7%81%BE%E9%81%87%E9%9A%BE%E8%85%E6+%BB%E5%9B%A0%E7%A1%AE%E5%AE%9A&rft.date=2017-11-23&rft.genre=article&rft_id=http%3A%2F%2Fsociety.people.com.cn%2Fn1%2F2017%2F1123%2Fc1008-29664636.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-59"><span class="mw-cite-backlink"><b><a href="#cite_ref-59">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.zaobao.com/news/china/story20171125-813698">安全隐患清查整治引质疑 北京清理“低端人口”?</a>. <a href="/wiki/%E8%81%94%E5%90%88%E6%97%A9%E6%8A%A5" title="联合早报">联合早报</a>. 2017-11-25 <span class="reference-accessdate"> [<span class="nowrap">2017-11-27</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20190912130612/https://www.zaobao.com.sg/news/china/story20171125-813698">存档</a>于2019-09-12).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%AE%89%E5%85%A8%E9%9A%90%E6%82%A3%E6%B8%85%E6%9F%A5%E6%95%B4%E6%B2%BB%E5%BC%95%E8%B4%A8%E7%96%91+%E5%8C%97%E4%BA%AC%E6%B8%85%E7%90%86%9C%E4%BD%8E%E7%AB%AF%E4%BA%BA%E5%8F%A3%9D%EF%BC%9F&rft.date=2017-11-25&rft.genre=article&rft_id=http%3A%2F%2Fwww.zaobao.com%2Fnews%2Fchina%2Fstory20171125-813698&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-60"><span class="mw-cite-backlink"><b><a href="#cite_ref-60">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="https://www.jfdaily.com/news/detail?id=126682">北京市级行政中心正式迁入北京城市副中心</a>. <a href="/wiki/%E4%B8%8A%E8%A7%82%E6%96%B0%E9%97%BB" title="上观新闻">上观新闻</a>. 2019-01-11 <span class="reference-accessdate"> [<span class="nowrap">2020-09-16</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200916190345/https://www.jfdaily.com/news/detail?id=126682">存档</a>于2020-09-16).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BA%A7%E8%A1%8C%E6%94%BF%E4%B8+%E5%BF%83%E6+%A3%E5%BC%8F%E8%BF%81%E5%85%A5%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8+%E5%BF%83&rft.date=2019-01-11&rft.genre=article&rft.jtitle=%E4%B8%8A%E8%A7%82%E6%96%B0%E9%97%BB&rft_id=https%3A%2F%2Fwww.jfdaily.com%2Fnews%2Fdetail%3Fid%3D126682&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-61"><span class="mw-cite-backlink"><b><a href="#cite_ref-61">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://news.youth.cn/gn/202008/t20200825_12465879.htm">疫情几起几落,北京地坛医院打了三场硬仗</a>. 中国青年报客户端. 2020-08-25 <span class="reference-accessdate"> [<span class="nowrap">2020-08-27</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200917001221/http://news.youth.cn/gn/202008/t20200825_12465879.htm">存档</a>于2020-09-17).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E7%96%AB%E6%83%85%E5%87%A0%E8%B5%B7%E5%87%A0%E8%90%BD%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%9C%B0%E5%9D%9B%E5%8C%BB%E9%99%A2%E6%89%93%E4%BA%86%E4%B8%89%E5%9C%BA%E7%A1%AC%E4%BB%97&rft.date=2020-08-25&rft.genre=article&rft_id=http%3A%2F%2Fnews.youth.cn%2Fgn%2F202008%2Ft20200825_12465879.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-62"><span class="mw-cite-backlink"><b><a href="#cite_ref-62">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://news.ynet.com/2020/01/24/2345254t70.html">北京市启动重大突发公共卫生事件一级响应</a>. <a href="/wiki/%E5%8C%97%E4%BA%AC%E9%9D%92%E5%B9%B4%E6%8A%A5" title="北京青年报">北京青年报</a>. 2020-01-24 <span class="reference-accessdate"> [<span class="nowrap">2020-09-16</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200916195551/http://news.ynet.com/2020/01/24/2345254t70.html">存档</a>于2020-09-16).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%90%AF%E5%8A%A8%E9%87%E5%A4%A7%E7%AA%81%E5%8F%91%E5%85%AC%E5%85%B1%E5%AB%E7%94%9F%E4%BA%E4%BB%B6%E4%B8%E7%BA%A7%E5%93%E5%BA%94&rft.date=2020-01-24&rft.genre=article&rft.jtitle=%E5%8C%97%E4%BA%AC%E9%9D%92%E5%B9%B4%E6%8A%A5&rft_id=http%3A%2F%2Fnews.ynet.com%2F2020%2F01%2F24%2F2345254t70.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-63"><span class="mw-cite-backlink"><b><a href="#cite_ref-63">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.xinhuanet.com/2020-04/29/c_1125923588.htm">北京将重大突发公共卫生事件应急响应下调为二级响应</a>. <a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">新华社</a>. 2020-04-29 <span class="reference-accessdate"> [<span class="nowrap">2020-09-16</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200921034548/http://www.xinhuanet.com/2020-04/29/c_1125923588.htm">存档</a>于2020-09-21).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B0%86%E9%87%E5%A4%A7%E7%AA%81%E5%8F%91%E5%85%AC%E5%85%B1%E5%AB%E7%94%9F%E4%BA%E4%BB%B6%E5%BA%94%E6%A5%E5%93%E5%BA%94%E4%B8%E8%B0%83%E4%B8%BA%E4%BA%8C%E7%BA%A7%E5%93%E5%BA%94&rft.date=2020-04-29&rft.genre=article&rft_id=http%3A%2F%2Fwww.xinhuanet.com%2F2020-04%2F29%2Fc_1125923588.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-64"><span class="mw-cite-backlink"><b><a href="#cite_ref-64">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.bjd.com.cn/a/202006/05/WS5ed9fc3be4b00aba04d2025b.html">重磅!6月6日起,北京应急响应级别下调为三级</a>. 北京日报客户端. 2020-06-05 <span class="reference-accessdate"> [<span class="nowrap">2020-06-05</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200605112436/http://www.bjd.com.cn/a/202006/05/WS5ed9fc3be4b00aba04d2025b.html">存档</a>于2020-06-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%87%E7%A3%85%EF%BC%816%E6%9C%886%E6%97%A5%E8%B5%B7%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%BA%94%E6%A5%E5%93%E5%BA%94%E7%BA%A7%E5%88%AB%E4%B8%E8%B0%83%E4%B8%BA%E4%B8%89%E7%BA%A7&rft.date=2020-06-05&rft.genre=article&rft.jtitle=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5%E5%AE%A2%E6%88%B7%E7%AB%AF&rft_id=http%3A%2F%2Fwww.bjd.com.cn%2Fa%2F202006%2F05%2FWS5ed9fc3be4b00aba04d2025b.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-chinanews20200609-65"><span class="mw-cite-backlink"><b><a href="#cite_ref-chinanews20200609_65-0">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.bj.chinanews.com/news/2020/0609/77614.html">北京本地确诊病例“清零” 仅1例境外输入病例在院治疗</a>. 中国新闻网. 2020-06-09 <span class="reference-accessdate"> [<span class="nowrap">2020-06-10</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200610024759/http://www.bj.chinanews.com/news/2020/0609/77614.html">存档</a>于2020-06-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%9C%AC%E5%9C%B0%E7%A1%AE%E8%AF%8A%E7%97%85%E4%BE%9C%E6%B8%85%E9%9B%B6%9D+%E4%BB%851%E4%BE%E5%A2%83%E5%A4%96%E8%BE%93%E5%85%A5%E7%97%85%E4%BE%E5%9C%A8%E9%99%A2%E6%B2%BB%E7%96%97&rft.date=2020-06-09&rft.genre=article&rft.jtitle=%E4%B8+%E5%9B%BD%E6%96%B0%E9%97%BB%E7%BD%91&rft_id=http%3A%2F%2Fwww.bj.chinanews.com%2Fnews%2F2020%2F0609%2F77614.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-66"><span class="mw-cite-backlink"><b><a href="#cite_ref-66">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="https://www.bjd.com.cn/a/202007/19/WS5f140092e4b00aba04d27206.html">调级!北京市突发公共卫生事件应急响应级别调整到三级!</a>. 北京日报客户端. 2020-07-19 <span class="reference-accessdate"> [<span class="nowrap">2020-07-19</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200719104218/https://www.bjd.com.cn/a/202007/19/WS5f140092e4b00aba04d27206.html">存档</a>于2020-07-19).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E8%B0%83%E7%BA%A7%EF%BC%81%E5%8C%97%E4%BA%AC%E5%B8%82%E7%AA%81%E5%8F%91%E5%85%AC%E5%85%B1%E5%AB%E7%94%9F%E4%BA%E4%BB%B6%E5%BA%94%E6%A5%E5%93%E5%BA%94%E7%BA%A7%E5%88%AB%E8%B0%83%E6%95%B4%E5%88%B0%E4%B8%89%E7%BA%A7%EF%BC%81&rft.date=2020-07-19&rft.genre=article&rft_id=https%3A%2F%2Fwww.bjd.com.cn%2Fa%2F202007%2F19%2FWS5f140092e4b00aba04d27206.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-67"><span class="mw-cite-backlink"><b><a href="#cite_ref-67">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="https://www.chinanews.com/gn/2020/08-27/9276066.shtml">首都核心区控规获批 推动老城整体保护与有机更新</a>. <a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%96%B0%E9%97%BB%E7%A4%BE" title="中国新闻社">中国新闻社</a>. 2020-08-27 <span class="reference-accessdate"> [<span class="nowrap">2020-09-16</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200921034621/https://www.chinanews.com/gn/2020/08-27/9276066.shtml">存档</a>于2020-09-21).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%A6%96%E9%83%BD%E6%A0%B8%E5%BF%83%E5%8C%BA%E6%8E%A7%E8%A7%84%E8%8E%B7%E6%89%B9+%E6%8E%A8%E5%8A%A8%E8%81%E5%9F%8E%E6%95%B4%E4%BD%93%E4%BF%9D%E6%8A%A4%E4%B8%8E%E6%9C%89%E6%9C%BA%E6%9B%B4%E6%96%B0&rft.date=2020-08-27&rft.genre=article&rft_id=https%3A%2F%2Fwww.chinanews.com%2Fgn%2F2020%2F08-27%2F9276066.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-68"><span class="mw-cite-backlink"><b><a href="#cite_ref-68">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/rwbj/bjgm/bjfm/t648265.htm">北京風貌,首都之窗-北京市政務門戶網站</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-04-01</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20121209035606/http://www.beijing.gov.cn/rwbj/bjgm/bjfm/t648265.htm">存档</a>于2012-12-09).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E9%A2%A8%E8%B2%8C%EF%BC%8C%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97-%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%99%E9%96%E6%88%B6%E7%B6%B2%E7%AB%99&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Frwbj%2Fbjgm%2Fbjfm%2Ft648265.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-69"><span class="mw-cite-backlink"><b><a href="#cite_ref-69">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://soil.bjny.gov.cn/jbgk-dlgk-dxdm-1.html">基本概況-地形地貌,北京市土壤资源管理信息网</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-03-31</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20110423180438/http://soil.bjny.gov.cn/jbgk-dlgk-dxdm-1.html">存档</a>于2011-04-23).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9F%BA%E6%9C%AC%E6%A6%82%E6%B3%81-%E5%9C%B0%E5%BD%A2%E5%9C%B0%E8%B2%8C%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%9F%E5%A3%A4%E8%B5%84%E6%BA%90%E7%AE%A1%E7%90%86%E4%BF%A1%E6%81%AF%E7%BD%91&rft.genre=unknown&rft_id=http%3A%2F%2Fsoil.bjny.gov.cn%2Fjbgk-dlgk-dxdm-1.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-70"><span class="mw-cite-backlink"><b><a href="#cite_ref-70">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.china.com.cn/travel/txt/2008-07/09/content_15980706.htm">灵山 风景最为宜人的北京第一高峰,中国网</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-03-31</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160305035827/http://www.china.com.cn/travel/txt/2008-07/09/content_15980706.htm">存档</a>于2016-03-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%81%B5%E5%B1%B1+%E9%A3%8E%E6%99%AF%E6%9C%E4%B8%BA%E5%AE%9C%E4%BA%BA%E7%9A%84%E5%8C%97%E4%BA%AC%E7%AC%AC%E4%B8%E9%AB%98%E5%B3%B0%EF%BC%8C%E4%B8+%E5%9B%BD%E7%BD%91&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.china.com.cn%2Ftravel%2Ftxt%2F2008-07%2F09%2Fcontent_15980706.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-71"><span class="mw-cite-backlink"><b><a href="#cite_ref-71">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://soil.bjny.gov.cn/jbgk-dlgk-swtz.html">基本概況-水文特征,北京市土壤资源管理信息网</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-03-31</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20110310195756/http://soil.bjny.gov.cn/jbgk-dlgk-swtz.html">存档</a>于2011-03-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9F%BA%E6%9C%AC%E6%A6%82%E6%B3%81-%E6%B0%B4%E6%96%87%E7%89%B9%E5%BE%81%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%9F%E5%A3%A4%E8%B5%84%E6%BA%90%E7%AE%A1%E7%90%86%E4%BF%A1%E6%81%AF%E7%BD%91&rft.genre=unknown&rft_id=http%3A%2F%2Fsoil.bjny.gov.cn%2Fjbgk-dlgk-swtz.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-72"><span class="mw-cite-backlink"><b><a href="#cite_ref-72">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20110606203032/http://www.bjclimate.com/Article/ViewArticle.aspx?id=74">北京的气候,北京市氣候中心</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-04-01</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjclimate.com/Article/ViewArticle.aspx?id=74">原始内容</a>存档于2011-06-06).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%94%E5%99%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E6%B0%A3%E5%99%E4%B8+%E5%BF%83&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bjclimate.com%2FArticle%2FViewArticle.aspx%3Fid%3D74&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-73"><span class="mw-cite-backlink"><b><a href="#cite_ref-73">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.meworks.net/meworksv2a/meworks/page1.aspx?no=272746&step=1&newsno=71632">第九屆(北京)中國國際園林博覽會台灣園計劃及籌備(上)</a>. Meworks.net. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170405191136/http://www.meworks.net/meworksv2a/meworks/page1.aspx?no=272746&step=1&newsno=71632">存档</a>于2017-04-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%AC%AC%E4%B9%9D%E5%B1%86%EF%BC%88%E5%8C%97%E4%BA%AC%EF%BC%89%E4%B8+%E5%9C%E5%9C%E9%9A%9B%E5%9C%92%E6%9E%97%E5%9A%E8%A6%BD%E6%9C%83%E5%8F%B0%E7%81%A3%E5%9C%92%E8%A8%88%E5%8A%83%E5%8F%8A%E7%B1%8C%E5%82%99%28%E4%B8%8A%29&rft.genre=unknown&rft.pub=Meworks.net&rft_id=http%3A%2F%2Fwww.meworks.net%2Fmeworksv2a%2Fmeworks%2Fpage1.aspx%3Fno%3D272746%26step%3D1%26newsno%3D71632&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-74"><span class="mw-cite-backlink"><b><a href="#cite_ref-74">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.sohu.com/20100308/n270643243.shtml">钢搬迁任务将在今年末完成,解决2.2万人安置,搜狐新聞</a>. News.sohu.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160304194311/http://news.sohu.com/20100308/n270643243.shtml">存档</a>于2016-03-04).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E9%92%A2%E6%90%AC%E8%BF%81%E4%BB%BB%E5%8A%A1%E5%B0%86%E5%9C%A8%E4%BB%8A%E5%B9%B4%E6%9C%AB%E5%AE%8C%E6%88%90%2C%E8%A7%A3%E5%86%B32.2%E4%B8%87%E4%BA%BA%E5%AE%89%E7%BD%AE%2C%E6%90%9C%E7%90%E6%96%B0%E8%81%9E&rft.genre=unknown&rft.pub=News.sohu.com&rft_id=http%3A%2F%2Fnews.sohu.com%2F20100308%2Fn270643243.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-75"><span class="mw-cite-backlink"><b><a href="#cite_ref-75">^</a></b></span> <span class="reference-text">[http:/city.cctv.com/html/chengshijingji/78ffb830c262c92c561240150a2831b8.html 北京市政府採購千輛環保公交,央視網]</span>
</li>
<li id="cite_note-76"><span class="mw-cite-backlink"><b><a href="#cite_ref-76">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/life/2008-12/31/content_10584336.htm">北京将禁止黄标车进五环 按规定淘汰者可获补贴</a>. 新华网. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20091009222200/http://news.xinhuanet.com/life/2008-12/31/content_10584336.htm">存档</a>于2009-10-09).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B0%86%E7%A6%81%E6+%A2%E9%BB%84%E6%A0%87%E8%BD%A6%E8%BF%9B%E4%BA%94%E7%8E%AF+%E6%8C%89%E8%A7%84%E5%AE%9A%E6%B7%98%E6%B1%B0%E8%85%E5%8F%AF%E8%8E%B7%E8%A1%A5%E8%B4%B4&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flife%2F2008-12%2F31%2Fcontent_10584336.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-77"><span class="mw-cite-backlink"><b><a href="#cite_ref-77">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.google.com/hostednews/afp/article/ALeqM5h2oAJSt6fzSbhMkQGkeo7mFHJZdg?docId=CNG.d5279d4645145772cb4f2ed6de93e61f.21">Beijing air pollution off the charts, US says</a>. AFP. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20110228073848/http://www.google.com/hostednews/afp/article/ALeqM5h2oAJSt6fzSbhMkQGkeo7mFHJZdg?docId=CNG.d5279d4645145772cb4f2ed6de93e61f.21">存档</a>于2011-02-28).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=Beijing+air+pollution+off+the+charts%2C+US+says&rft.genre=unknown&rft.pub=AFP&rft_id=http%3A%2F%2Fwww.google.com%2Fhostednews%2Fafp%2Farticle%2FALeqM5h2oAJSt6fzSbhMkQGkeo7mFHJZdg%3FdocId%3DCNG.d5279d4645145772cb4f2ed6de93e61f.21&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-78"><span class="mw-cite-backlink"><b><a href="#cite_ref-78">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.qq.com/a/20110224/001032.htm">视频:北京接连三天雾霾缠身 空气质量持续超标</a>. 腾讯网. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20161025221534/http://news.qq.com/a/20110224/001032.htm">存档</a>于2016-10-25).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E8%A7%86%E9%A2%91%EF%BC%9A%E5%8C%97%E4%BA%AC%E6%8E%A5%E8%BF%9E%E4%B8%89%E5%A4%A9%E9%9B%BE%E9%9C%BE%E7%BC%A0%E8%BA%AB+%E7%A9%BA%E6%B0%94%E8%B4%A8%E9%87%8F%E6%8C%81%E7%BB+%E8%B6%85%E6%A0%87&rft.genre=unknown&rft.pub=%E8%85%BE%E8%AE%AF%E7%BD%91&rft_id=http%3A%2F%2Fnews.qq.com%2Fa%2F20110224%2F001032.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-79"><span class="mw-cite-backlink"><b><a href="#cite_ref-79">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20160304133823/http://sports.21cn.com/integrate/other/2013/01/15/14400120.shtml">全球10大空气污染城市太原居首 市民阴霾晨练</a>. Sports.21cn.com. 2013-01-15 <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (<a rel="nofollow" class="external text" href="http://sports.21cn.com/integrate/other/2013/01/15/14400120.shtml">原始内容</a>存档于2016-03-04).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%85%A8%E7%90%8310%E5%A4%A7%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E5%9F%8E%E5%B8%82%E5%A4%AA%E5%8E%9F%E5%B1%85%E9%A6%96+%E5%B8%82%E6%B0%91%E9%98%B4%E9%9C%BE%E6%99%A8%E7%BB%83&rft.date=2013-01-15&rft.genre=unknown&rft.pub=Sports.21cn.com&rft_id=http%3A%2F%2Fsports.21cn.com%2Fintegrate%2Fother%2F2013%2F01%2F15%2F14400120.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-80"><span class="mw-cite-backlink"><b><a href="#cite_ref-80">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.cnr.cn/gnxw/201004/t20100414_506284381.html">北京加大力度科学治理杨柳飞絮,中國廣播網</a>. News.cnr.cn. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160308024128/http://news.cnr.cn/gnxw/201004/t20100414_506284381.html">存档</a>于2016-03-08).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%8A%A0%E5%A4%A7%E5%8A%9B%E5%BA%A6%E7%A7%91%E5+%A6%E6%B2%BB%E7%90%86%E6%9D%A8%E6%9F%B3%E9%A3%9E%E7%B5%AE%EF%BC%8C%E4%B8+%E5%9C%E5%BB%A3%E6%92+%E7%B6%B2&rft.genre=unknown&rft.pub=News.cnr.cn&rft_id=http%3A%2F%2Fnews.cnr.cn%2Fgnxw%2F201004%2Ft20100414_506284381.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-asdfsd-81"><span class="mw-cite-backlink">^ <a href="#cite_ref-asdfsd_81-0"><sup><b>77.0</b></sup></a> <a href="#cite_ref-asdfsd_81-1"><sup><b>77.1</b></sup></a> <a href="#cite_ref-asdfsd_81-2"><sup><b>77.2</b></sup></a></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://env.people.com.cn/GB/16512409.html">PM2.5再惹争议</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20111207142112/http://env.people.com.cn/GB/16512409.html">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,人民网</span>
</li>
<li id="cite_note-82"><span class="mw-cite-backlink"><b><a href="#cite_ref-82">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://www.chinadaily.com.cn/hqgj/jryw/2011-11-01/content_4232542.html">北京市浓雾将加重空气污染</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20161023171231/http://www.chinadaily.com.cn/hqgj/jryw/2011-11-01/content_4232542.html">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,中国日报</span>
</li>
<li id="cite_note-83"><span class="mw-cite-backlink"><b><a href="#cite_ref-83">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://www.chinanews.com/gn/2011/12-16/3538146.shtml">专家称跨省空气污染控制会牵涉多方利益 并非易事</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20111218034810/http://www.chinanews.com/gn/2011/12-16/3538146.shtml">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,中国新闻网</span>
</li>
<li id="cite_note-84"><span class="mw-cite-backlink"><b><a href="#cite_ref-84">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://finance.ifeng.com/opinion/xzsuibi/20111101/4966491.shtml">谁来治理北京的空气污染</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20120529013516/http://finance.ifeng.com/opinion/xzsuibi/20111101/4966491.shtml">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,凤凰网</span>
</li>
<li id="cite_note-85"><span class="mw-cite-backlink"><b><a href="#cite_ref-85">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/society/2011-12/18/c_111252730.htm">北京市环保局称北京空气质量优良天数创历史最好水平</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20161023140227/http://news.xinhuanet.com/society/2011-12/18/c_111252730.htm">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,新华网</span>
</li>
<li id="cite_note-86"><span class="mw-cite-backlink"><b><a href="#cite_ref-86">^</a></b></span> <span class="reference-text"><a rel="nofollow" class="external text" href="http://epaper.jinghua.cn/html/2011-12/22/content_744304.htm">京津冀确定明年起监测PM2.5</a> <a rel="nofollow" class="external text" href="//web.archive.org/web/20120120083625/http://epaper.jinghua.cn/html/2011-12/22/content_744304.htm">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a>,京华时报</span>
</li>
<li id="cite_note-87"><span class="mw-cite-backlink"><b><a href="#cite_ref-87">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://money.163.com/12/0214/00/7Q6C7SAO00252G50.html">PM2.5标准向西方看齐不现实_网易财经</a>. Money.163.com. 2012-02-14 <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20161023133256/http://money.163.com/12/0214/00/7Q6C7SAO00252G50.html">存档</a>于2016-10-23).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=PM2.5%E6%A0%87%E5%87%86%E5%90%91%E8%A5%BF%E6%96%B9%E7%9C%E9%BD%90%E4%B8%E7%8E%B0%E5%AE%9E_%E7%BD%91%E6%98%93%E8%B4%A2%E7%BB%8F&rft.date=2012-02-14&rft.genre=unknown&rft.pub=Money.163.com&rft_id=http%3A%2F%2Fmoney.163.com%2F12%2F0214%2F00%2F7Q6C7SAO00252G50.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-88"><span class="mw-cite-backlink"><b><a href="#cite_ref-88">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.dw.de/%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E7%A8%8B%E5%BA%A6%E5%88%9B%E5%8E%86%E5%8F%B2%E7%BA%AA%E5%BD%95/a-16517011">北京空气污染程度创历史纪录 | 德国之声中文网中国新闻 | DW | 12.01.2013</a>. Dw.de. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20150322202037/http://www.dw.de/%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E7%A8%8B%E5%BA%A6%E5%88%9B%E5%8E%86%E5%8F%B2%E7%BA%AA%E5%BD%95/a-16517011">存档</a>于2015-03-22).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E7%A8%E5%BA%A6%E5%88%9B%E5%8E%86%E5%8F%B2%E7%BA%AA%E5%BD%95+%26%23124%3B+%E5%BE%B7%E5%9B%BD%E4%B9%E5%A3%B0%E4%B8+%E6%96%87%E7%BD%91%E4%B8+%E5%9B%BD%E6%96%B0%E9%97%BB+%26%23124%3B+DW+%26%23124%3B+12.01.2013&rft.genre=unknown&rft.pub=Dw.de&rft_id=http%3A%2F%2Fwww.dw.de%2F%25E5%258C%2597%25E4%25BA%25AC%25E7%25A9%25BA%25E6%25B0%2594%25E6%25B1%25A1%25E6%259F%2593%25E7%25A8%258B%25E5%25BA%25A6%25E5%2588%259B%25E5%258E%2586%25E5%258F%25B2%25E7%25BA%25AA%25E5%25BD%2595%2Fa-16517011&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-89"><span class="mw-cite-backlink"><b><a href="#cite_ref-89">^</a></b></span> <span class="reference-text">PM2.5年终大考:超标近两倍 <cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20140831130529/http://bjwb.bjd.com.cn/html/2014-01/02/content_139456.htm">存档副本</a>. <span class="reference-accessdate"> [<span class="nowrap">2014-09-18</span>]</span>. (<a rel="nofollow" class="external text" href="http://bjwb.bjd.com.cn/html/2014-01/02/content_139456.htm">原始内容</a>存档于2014-08-31).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5+%98%E6%A1%A3%E5%89%AF%E6%9C%AC&rft.genre=unknown&rft_id=http%3A%2F%2Fbjwb.bjd.com.cn%2Fhtml%2F2014-01%2F02%2Fcontent_139456.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-90"><span class="mw-cite-backlink"><b><a href="#cite_ref-90">^</a></b></span> <span class="reference-text"><cite class="citation web">北京日报. <a rel="nofollow" class="external text" href="http://www.gov.cn/xinwen/2020-01/04/content_5466420.htm">2019年北京空气质量7年来最好</a>. 中华人民共和国中央人民政府. <span class="reference-accessdate"> [<span class="nowrap">2020-05-30</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200615053953/http://www.gov.cn/xinwen/2020-01/04/content_5466420.htm">存档</a>于2020-06-15).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=2019%E5%B9%B4%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E8%B4%A8%E9%87%8F7%E5%B9%B4%E6%9D%A5%E6%9C%E5%A5%BD&rft.au=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8+%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C&rft_id=http%3A%2F%2Fwww.gov.cn%2Fxinwen%2F2020-01%2F04%2Fcontent_5466420.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-91"><span class="mw-cite-backlink"><b><a href="#cite_ref-91">^</a></b></span> <span class="reference-text">淩霄:民國時期的特別市,鐘山風雨,2009年3期</span>
</li>
<li id="cite_note-92"><span class="mw-cite-backlink"><b><a href="#cite_ref-92">^</a></b></span> <span class="reference-text">北京市統計局 國家統計局北京調查總隊編:《北京統計年鑒2009》,1-1行政區劃,中國統計出版社</span>
</li>
<li id="cite_note-93"><span class="mw-cite-backlink"><b><a href="#cite_ref-93">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://big5.china.com.cn/txt/2002-03/28/content_5124681.htm">北京懷柔平谷即將撤縣改區,中國網</a>. Big5.china.com.cn. 2002-03-28 <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20150910001413/http://big5.china.com.cn/txt/2002-03/28/content_5124681.htm">存档</a>于2015-09-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%87%B7%E6%9F%94%E5%B9%B3%E8%B0%B7%E5%B3%E5%B0%87%E6%92%A4%E7%B8%A3%E6%94%B9%E5%EF%BC%8C%E4%B8+%E5%9C%E7%B6%B2&rft.date=2002-03-28&rft.genre=unknown&rft.pub=Big5.china.com.cn&rft_id=http%3A%2F%2Fbig5.china.com.cn%2Ftxt%2F2002-03%2F28%2Fcontent_5124681.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-94"><span class="mw-cite-backlink"><b><a href="#cite_ref-94">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.qq.com/a/20100701/001724.htm">北京城4区合并正式获批 宣武崇文退出历史</a>. 新华网. 2010-07-01 <span class="reference-accessdate"> [<span class="nowrap">2017-05-20</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170805150345/http://news.qq.com/a/20100701/001724.htm">存档</a>于2017-08-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%9F%8E4%E5%8C%BA%E5%90%88%E5%B9%B6%E6+%A3%E5%BC%8F%E8%8E%B7%E6%89%B9+%E5%AE%A3%E6+%A6%E5%B4%87%E6%96%87%E9%E5%87%BA%E5%8E%86%E5%8F%B2&rft.date=2010-07-01&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.qq.com%2Fa%2F20100701%2F001724.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-95"><span class="mw-cite-backlink"><b><a href="#cite_ref-95">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://news.sina.com.cn/o/2015-11-13/doc-ifxkrwks3865811.shtml">北京撤销最后两个县:以后就是密云区、延庆区了</a>. 财经网. 2015-11-13 <span class="reference-accessdate"> [<span class="nowrap">2015-11-13</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20151117030122/http://news.sina.com.cn/o/2015-11-13/doc-ifxkrwks3865811.shtml">存档</a>于2015-11-17).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%92%A4%E9%94%E6%9C%E5%90%8E%E4%B8%A4%E4%B8%AA%E5%8E%BF%EF%BC%9A%E4%BB%A5%E5%90%8E%E5%B0%B1%E6%98%AF%E5%AF%86%E4%BA%91%E5%8C%BA%E3%81%E5%BB%B6%E5%BA%86%E5%8C%BA%E4%BA%86&rft.date=2015-11-13&rft.genre=article&rft_id=http%3A%2F%2Fnews.sina.com.cn%2Fo%2F2015-11-13%2Fdoc-ifxkrwks3865811.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-96"><span class="mw-cite-backlink"><b><a href="#cite_ref-96">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://files2.mca.gov.cn/cws/201502/20150225163817214.html">中华人民共和国县以上行政区划代码</a>. 中华人民共和国民政部. <span class="reference-accessdate"> [<span class="nowrap">2020-03-12</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20150402113603/http://files2.mca.gov.cn/cws/201502/20150225163817214.html">存档</a>于2015-04-02).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81&rft.genre=unknown&rft.pub=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E6%B0%91%E6%94%BF%E9%83%A8&rft_id=http%3A%2F%2Ffiles2.mca.gov.cn%2Fcws%2F201502%2F20150225163817214.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-99"><span class="mw-cite-backlink"><b><a href="#cite_ref-99">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20200317033233/http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm">《北京统计年鉴-2019》</a>. 北京市统计局. <span class="reference-accessdate"> [<span class="nowrap">2020-03-12</span>]</span>. (<a rel="nofollow" class="external text" href="http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm">原始内容</a>存档于2020-03-17).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E3%8A%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B4-2019%E3&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1&rft_id=http%3A%2F%2F202.96.40.155%2Fnj%2Fmain%2F2019-tjnj%2Fzk%2Findexch.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-100"><span class="mw-cite-backlink"><b><a href="#cite_ref-100">^</a></b></span> <span class="reference-text"><cite class="citation book">中华人民共和国民政部. 《中国民政统计年鉴2014》. 中国统计出版社. 2014.08. <a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-7-5037-7130-9" title="Special:网络书源/978-7-5037-7130-9"><span title="国际标准书号">ISBN</span> 978-7-5037-7130-9</a>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E6%B0%91%E6%94%BF%E9%83%A8&rft.btitle=%E3%8A%E4%B8+%E5%9B%BD%E6%B0%91%E6%94%BF%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42014%E3&rft.genre=book&rft.isbn=978-7-5037-7130-9&rft.pub=%E4%B8+%E5%9B%BD%E7%BB%9F%E8%AE%A1%E5%87%BA%E7%89%88%E7%A4%BE&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span> <span style="display:none;font-size:100%" class="error citation-comment">请检查<code style="color:inherit; border:inherit; padding:inherit;">|date=</code>中的日期值 (<a href="/wiki/Help:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF#bad_date" title="Help:引文格式1错误">帮助</a>)</span></span>
</li>
<li id="cite_note-101"><span class="mw-cite-backlink"><b><a href="#cite_ref-101">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://news.sina.com.cn/c/2019-01-10/doc-ihqhqcis5024778.shtml">北京市人民政府摘牌 城市副中心行政办公区将启用</a>. 环球网. 2019-01-10 <span class="reference-accessdate"> [<span class="nowrap">2019-01-11</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20190111081844/https://news.sina.com.cn/c/2019-01-10/doc-ihqhqcis5024778.shtml">存档</a>于2019-01-11).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C%E6%91%98%E7%89%8C+%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8+%E5%BF%83%E8%A1%8C%E6%94%BF%E5%8A%9E%E5%85%AC%E5%8C%BA%E5%B0%86%E5%90%AF%E7%94%A8&rft.date=2019-01-10&rft.genre=article&rft.jtitle=%E7%8E%AF%E7%90%83%E7%BD%91&rft_id=http%3A%2F%2Fnews.sina.com.cn%2Fc%2F2019-01-10%2Fdoc-ihqhqcis5024778.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-102"><span class="mw-cite-backlink"><b><a href="#cite_ref-102">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://news.sina.com.cn/c/2019-01-11/doc-ihqhqcis5083453.shtml">北京市政府机关搬迁至通州区 即日起在新址办公</a>. 新浪新闻综合. 2019-01-11 <span class="reference-accessdate"> [<span class="nowrap">2019-01-12</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20190111121548/https://news.sina.com.cn/c/2019-01-11/doc-ihqhqcis5083453.shtml">存档</a>于2019-01-11).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%BA%9C%E6%9C%BA%E5%85%B3%E6%90%AC%E8%BF%81%E8%87%B3%E9%9A%E5%B7%9E%E5%8C%BA+%E5%B3%E6%97%A5%E8%B5%B7%E5%9C%A8%E6%96%B0%E5%9D%E5%8A%9E%E5%85%AC&rft.date=2019-01-11&rft.genre=unknown&rft.pub=%E6%96%B0%E6%B5%AA%E6%96%B0%E9%97%BB%E7%BB%BC%E5%90%88&rft_id=https%3A%2F%2Fnews.sina.com.cn%2Fc%2F2019-01-11%2Fdoc-ihqhqcis5083453.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-103"><span class="mw-cite-backlink"><b><a href="#cite_ref-103">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20190111121603/http://shilingdao.beijing.gov.cn/library/191/10/738495/1577140/index.html">北京市级行政中心正式迁入城市副中心 蔡奇陈吉宁李伟吉林出席升旗仪式并揭牌</a>. 北京日报. 2019-01-11 <span class="reference-accessdate"> [<span class="nowrap">2019-01-11</span>]</span>. (<a rel="nofollow" class="external text" href="http://shilingdao.beijing.gov.cn/library/191/10/738495/1577140/index.html">原始内容</a>存档于2019-01-11).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BA%A7%E8%A1%8C%E6%94%BF%E4%B8+%E5%BF%83%E6+%A3%E5%BC%8F%E8%BF%81%E5%85%A5%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8+%E5%BF%83+%E8%94%A1%E5%A5%87%E9%99%88%E5%90%89%E5%AE%81%E6%9D%8E%E4%BC%9F%E5%90%89%E6%9E%97%E5%87%BA%E5%B8+%E5%87%E6%97%97%E4%BB%AA%E5%BC%8F%E5%B9%B6%E6%8F+%E7%89%8C&rft.date=2019-01-11&rft.genre=article&rft.jtitle=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5&rft_id=http%3A%2F%2Fshilingdao.beijing.gov.cn%2Flibrary%2F191%2F10%2F738495%2F1577140%2Findex.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-104"><span class="mw-cite-backlink"><b><a href="#cite_ref-104">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://news.china.com/domestic/945/20170527/30585359.html">蔡奇任北京市委书记 郭金龙不再兼任(图/简历)</a>. 新华网. 2017-05-27 <span class="reference-accessdate"> [<span class="nowrap">2018-02-24</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20180225064923/http://news.china.com/domestic/945/20170527/30585359.html">存档</a>于2018-02-25).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E8%94%A1%E5%A5%87%E4%BB%BB%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E4%B9%A6%E8%AE%B0+%E9%83+%E9%87%91%E9%BE%99%E4%B8%E5%86%E5%85%BC%E4%BB%BB%28%E5%9B%BE%2F%E7%AE%E5%8E%86%29&rft.date=2017-05-27&rft.genre=article&rft_id=http%3A%2F%2Fnews.china.com%2Fdomestic%2F945%2F20170527%2F30585359.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-105"><span class="mw-cite-backlink"><b><a href="#cite_ref-105">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20180224232716/http://news.163.com/17/0120/11/CB7JGJUD00018AOQ.html">李伟任北京市人大常委会主任(图/简历)</a>. 中国经济网(北京). 2017-01-20 <span class="reference-accessdate"> [<span class="nowrap">2018-02-24</span>]</span>. (<a rel="nofollow" class="external text" href="http://news.163.com/17/0120/11/CB7JGJUD00018AOQ.html">原始内容</a>存档于2018-02-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E6%9D%8E%E4%BC%9F%E4%BB%BB%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A%E4%B8%BB%E4%BB%BB%28%E5%9B%BE%2F%E7%AE%E5%8E%86%29&rft.date=2017-01-20&rft.genre=article&rft_id=http%3A%2F%2Fnews.163.com%2F17%2F0120%2F11%2FCB7JGJUD00018AOQ.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-106"><span class="mw-cite-backlink"><b><a href="#cite_ref-106">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://finance.sina.com.cn/roll/2018-01-30/doc-ifyqyesy4176553.shtml">北京新一届市长、副市长名单 陈吉宁当选市长</a>. 中国经济网. 2018-01-30 <span class="reference-accessdate"> [<span class="nowrap">2018-02-24</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20180225065047/http://finance.sina.com.cn/roll/2018-01-30/doc-ifyqyesy4176553.shtml">存档</a>于2018-02-25).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%96%B0%E4%B8%E5%B1%8A%E5%B8%82%E9%95%BF%E3%81%E5%89%AF%E5%B8%82%E9%95%BF%E5%90%E5%95+%E9%99%88%E5%90%89%E5%AE%81%E5%BD%93%E9%89%E5%B8%82%E9%95%BF&rft.date=2018-01-30&rft.genre=article&rft_id=http%3A%2F%2Ffinance.sina.com.cn%2Froll%2F2018-01-30%2Fdoc-ifyqyesy4176553.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-107"><span class="mw-cite-backlink"><b><a href="#cite_ref-107">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.gov.cn/rsrm/2013-01/25/content_2319695.htm">吉林当选北京市政协主席</a>. 新华社. 2013-01-25 <span class="reference-accessdate"> [<span class="nowrap">2018-02-24</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20180224232726/http://www.gov.cn/rsrm/2013-01/25/content_2319695.htm">存档</a>于2018-02-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%90%89%E6%9E%97%E5%BD%93%E9%89%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%8F%E4%B8%BB%E5%B8+&rft.date=2013-01-25&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%A4%BE&rft_id=http%3A%2F%2Fwww.gov.cn%2Frsrm%2F2013-01%2F25%2Fcontent_2319695.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-108"><span class="mw-cite-backlink"><b><a href="#cite_ref-108">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.chinanews.com/cj/2016/01-21/7726436.shtml">去年北京GDP增速6.9% 人均GDP超1.7万美元</a>. <span class="reference-accessdate"> [<span class="nowrap">2017-01-12</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170113150846/http://www.chinanews.com/cj/2016/01-21/7726436.shtml">存档</a>于2017-01-13).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8E%BB%E5%B9%B4%E5%8C%97%E4%BA%ACGDP%E5%A2%9E%E9%9F6.9%25+%E4%BA%BA%E5%9D%87GDP%E8%B6%851.7%E4%B8%87%E7%BE%8E%E5%85%83&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fcj%2F2016%2F01-21%2F7726436.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-21jj-109"><span class="mw-cite-backlink"><b><a href="#cite_ref-21jj_109-0">^</a></b></span> <span class="reference-text"><cite class="citation web">定军、吴靖、史梦怡. <a rel="nofollow" class="external text" href="http://www.21jingji.com/2016/1-22/3MMDA2NTFfMTM4Njc3Mg.html">北京晒2015成绩单:传统产业减速</a>. 21世纪经济报道. 2016-01-22 <span class="reference-accessdate"> [<span class="nowrap">2016-12-26</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20161226220807/http://www.21jingji.com/2016/1-22/3MMDA2NTFfMTM4Njc3Mg.html">存档</a>于2016-12-26).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%99%922015%E6%88%90%E7%BB%A9%E5%95%EF%BC%9A%E4%BC%A0%E7%BB%9F%E4%BA%A7%E4%B8%9A%E5%87%8F%E9%9F&rft.au=%E5%AE%9A%E5%86%9B%E3%81%E5%90%B4%E9%9D%96%E3%81%E5%8F%B2%E6%A2%A6%E6%A1&rft.date=2016-01-22&rft.genre=unknown&rft.jtitle=21%E4%B8%96%E7%BA%AA%E7%BB%8F%E6%B5%8E%E6%8A%A5%E9%81%93&rft_id=http%3A%2F%2Fwww.21jingji.com%2F2016%2F1-22%2F3MMDA2NTFfMTM4Njc3Mg.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-分省年度數據-110"><span class="mw-cite-backlink"><b><a href="#cite_ref-分省年度數據_110-0">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20150317160159/http://data.stats.gov.cn/workspace/index?m=fsnd">分省年度數據</a>. 中華人民共和國國家統計局. <span class="reference-accessdate"> [<span class="nowrap">2015-01-08</span>]</span>. (<a rel="nofollow" class="external text" href="http://data.stats.gov.cn/workspace/index?m=fsnd">原始内容</a>存档于2015-03-17) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">(中文)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%88%86%E7%9C%81%E5%B9%B4%E5%BA%A6%E6%95%B8%E6%93%9A&rft.genre=unknown&rft.pub=%E4%B8+%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%E5%9C%E5%AE%B6%E7%B5%B1%E8%A8%88%E5%B1&rft_id=http%3A%2F%2Fdata.stats.gov.cn%2Fworkspace%2Findex%3Fm%3Dfsnd&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-111"><span class="mw-cite-backlink"><b><a href="#cite_ref-111">^</a></b></span> <span class="reference-text">李京文, 何喜军《北京制造业发展史》.中国财政经济出版社,2010</span>
</li>
<li id="cite_note-gk-112"><span class="mw-cite-backlink">^ <a href="#cite_ref-gk_112-0"><sup><b>106.0</b></sup></a> <a href="#cite_ref-gk_112-1"><sup><b>106.1</b></sup></a></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://china-trade-research.hktdc.com/business-news/article/%E6%95%B8%E6%93%9A%E5%8F%8A%E6%8C%87%E6%95%B8/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A0%B4%E6%A6%82%E6%B3%81/ff/tc/1/1X000000/1X06BPU3.htm">北京市場概況</a>. China-trade-research.hktdc.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170805144658/http://china-trade-research.hktdc.com/business-news/article/%E6%95%B8%E6%93%9A%E5%8F%8A%E6%8C%87%E6%95%B8/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A0%B4%E6%A6%82%E6%B3%81/ff/tc/1/1X000000/1X06BPU3.htm">存档</a>于2017-08-05) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A0%B4%E6%A6%82%E6%B3%81&rft.genre=unknown&rft.pub=China-trade-research.hktdc.com&rft_id=http%3A%2F%2Fchina-trade-research.hktdc.com%2Fbusiness-news%2Farticle%2F%25E6%2595%25B8%25E6%2593%259A%25E5%258F%258A%25E6%258C%2587%25E6%2595%25B8%2F%25E5%258C%2597%25E4%25BA%25AC%25E5%25B8%2582%25E5%25A0%25B4%25E6%25A6%2582%25E6%25B3%2581%2Fff%2Ftc%2F1%2F1X000000%2F1X06BPU3.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-113"><span class="mw-cite-backlink"><b><a href="#cite_ref-113">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/auto/2009-12/18/content_12668015.htm">北京机动车保有量突破400万辆,新華網</a>. News.xinhuanet.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20141028173609/http://news.xinhuanet.com/auto/2009-12/18/content_12668015.htm">存档</a>于2014-10-28).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%9C%BA%E5%8A%A8%E8%BD%A6%E4%BF%9D%E6%9C%89%E9%87%8F%E7%AA%81%E7%A0%B4400%E4%B8%87%E8%BE%86%EF%BC%8C%E6%96%B0%E8%8F%AF%E7%B6%B2&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Fauto%2F2009-12%2F18%2Fcontent_12668015.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-2015公报-114"><span class="mw-cite-backlink">^ <a href="#cite_ref-2015公报_114-0"><sup><b>108.0</b></sup></a> <a href="#cite_ref-2015公报_114-1"><sup><b>108.1</b></sup></a></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20161226221556/http://www.bjstats.gov.cn/tjsj/tjgb/ndgb/201603/t20160329_346055.html">北京市2015年暨“十二五”时期国民经济和社会发展统计公报</a>. 北京统计信息网. 北京市统计局. 2016-02-15 <span class="reference-accessdate"> [<span class="nowrap">2016-12-26</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjstats.gov.cn/tjsj/tjgb/ndgb/201603/t20160329_346055.html">原始内容</a>存档于2016-12-26).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%822015%E5%B9%B4%E6%9A%A8%9C%E5%81%E4%BA%8C%E4%BA%94%9D%E6%97%B6%E6%9C%9F%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.date=2016-02-15&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E4%BF%A1%E6%81%AF%E7%BD%91&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Ftjsj%2Ftjgb%2Fndgb%2F201603%2Ft20160329_346055.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-115"><span class="mw-cite-backlink"><b><a href="#cite_ref-115">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/fortune/2007-05/19/content_6122037.htm">未来五年北京南城将变什么样</a>. 新华网. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20081014183709/http://news.xinhuanet.com/fortune/2007-05/19/content_6122037.htm">存档</a>于2008-10-14).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%9C%AA%E6%9D%A5%E4%BA%94%E5%B9%B4%E5%8C%97%E4%BA%AC%E5%97%E5%9F%8E%E5%B0%86%E5%8F%98%E4%BB%E4%B9%88%E6%A0%B7&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Ffortune%2F2007-05%2F19%2Fcontent_6122037.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-116"><span class="mw-cite-backlink"><b><a href="#cite_ref-116">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20110217132109/http://news.bjnews.com.cn/2009/0925/45171.shtml">北京南部要三年大变样 “南穷北富”有望缓解</a>. 新京报网站. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (<a rel="nofollow" class="external text" href="http://news.bjnews.com.cn/2009/0925/45171.shtml">原始内容</a>存档于2011-02-17).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%97%E9%83%A8%E8%A6%81%E4%B8%89%E5%B9%B4%E5%A4%A7%E5%8F%98%E6%A0%B7+%9C%E5%97%E7%A9%B7%E5%8C%97%E5%AF%8C%9D%E6%9C%89%E6%9C%9B%E7%BC%93%E8%A7%A3&rft.genre=unknown&rft.pub=%E6%96%B0%E4%BA%AC%E6%8A%A5%E7%BD%91%E7%AB%99&rft_id=http%3A%2F%2Fnews.bjnews.com.cn%2F2009%2F0925%2F45171.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-117"><span class="mw-cite-backlink"><b><a href="#cite_ref-117">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.sina.com.cn/c/2004-08-25/18274137286.shtml">北京经济概况</a>. News.sina.com.cn. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170113155042/http://news.sina.com.cn/c/2004-08-25/18274137286.shtml">存档</a>于2017-01-13).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%BB%8F%E6%B5%8E%E6%A6%82%E5%86%B5&rft.genre=unknown&rft.pub=News.sina.com.cn&rft_id=http%3A%2F%2Fnews.sina.com.cn%2Fc%2F2004-08-25%2F18274137286.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-118"><span class="mw-cite-backlink"><b><a href="#cite_ref-118">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20160405103546/http://www.beijing.gov.cn/rwbj/bjgm/sdjj/t648231.htm">首都经济</a>. Beijing.gov.cn. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/rwbj/bjgm/sdjj/t648231.htm">原始内容</a>存档于2016-04-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E9%A6%96%E9%83%BD%E7%BB%8F%E6%B5%8E&rft.genre=unknown&rft.pub=Beijing.gov.cn&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Frwbj%2Fbjgm%2Fsdjj%2Ft648231.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-19年公报-120"><span class="mw-cite-backlink">^ <a href="#cite_ref-19年公报_120-0"><sup><b>113.0</b></sup></a> <a href="#cite_ref-19年公报_120-1"><sup><b>113.1</b></sup></a> <a href="#cite_ref-19年公报_120-2"><sup><b>113.2</b></sup></a></span> <span class="reference-text"><cite class="citation web">北京市统计局、国家统计局北京调查总队. <a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/gongkai/shuju/tjgb/202003/t20200302_1838196.html">北京市2019年国民经济和社会发展统计公报</a>. 首都之窗. 2020-03-08 <span class="reference-accessdate"> [<span class="nowrap">2020-05-24</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200827102523/http://www.beijing.gov.cn/gongkai/shuju/tjgb/202003/t20200302_1838196.html">存档</a>于2020-08-27) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%822019%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.date=2020-03-08&rft.genre=unknown&rft.pub=%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Fgongkai%2Fshuju%2Ftjgb%2F202003%2Ft20200302_1838196.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-121"><span class="mw-cite-backlink"><b><a href="#cite_ref-121">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.urbansustrans.cn/info_detail.asp?id=1083">总结交通拥堵五大原因 筹备新北京交通体系,城市交通研究中心</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-04-01</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20110905121501/http://www.urbansustrans.cn/info_detail.asp?id=1083">存档</a>于2011-09-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%BB%E7%BB%93%E4%BA%A4%E9%9A%E6%A5%E5%A0%B5%E4%BA%94%E5%A4%A7%E5%8E%9F%E5%9B%A0+%E7+%B9%E5%A4%87%E6%96%B0%E5%8C%97%E4%BA%AC%E4%BA%A4%E9%9A%E4%BD%93%E7%B3%BB%EF%BC%8C%E5%9F%8E%E5%B8%82%E4%BA%A4%E9%9A%E7%A0%94%E7%A9%B6%E4%B8+%E5%BF%83&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.urbansustrans.cn%2Finfo_detail.asp%3Fid%3D1083&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-122"><span class="mw-cite-backlink"><b><a href="#cite_ref-122">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.cnr.cn/09zt/2010jjdflh/wyjy/201001/t20100125_505943311.html">2010年北京“兩會”:代表、委員議交通,中廣網</a>. Cnr.cn. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160307102936/http://www.cnr.cn/09zt/2010jjdflh/wyjy/201001/t20100125_505943311.html">存档</a>于2016-03-07).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=2010%E5%B9%B4%E5%8C%97%E4%BA%AC%9C%E5%85%A9%E6%9C%83%9D%EF%BC%9A%E4%BB%A3%E8%A1%A8%E3%81%E5%A7%94%E5%93%A1%E8+%B0%E4%BA%A4%E9%9A%EF%BC%8C%E4%B8+%E5%BB%A3%E7%B6%B2&rft.genre=unknown&rft.pub=Cnr.cn&rft_id=http%3A%2F%2Fwww.cnr.cn%2F09zt%2F2010jjdflh%2Fwyjy%2F201001%2Ft20100125_505943311.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-123"><span class="mw-cite-backlink"><b><a href="#cite_ref-123">^</a></b></span> <span class="reference-text"><cite class="citation web">冯蕾. <a rel="nofollow" class="external text" href="http://www.gmw.cn/01gmrb/2006-09/27/content_485833.htm">中国公路“零公里”标志亮相天安门广场,光明日報,2006年9月27日</a>. Gmw.cn. 2006-09-27 <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170930055840/http://www.gmw.cn/01gmrb/2006-09/27/content_485833.htm">存档</a>于2017-09-30).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%86%AF%E8%95%BE&rft.btitle=%E4%B8+%E5%9B%BD%E5%85%AC%E8%B7%AF%9C%E9%9B%B6%E5%85%AC%E9%87%8C%9D%E6%A0%87%E5%BF%97%E4%BA%AE%E7%9B%B8%E5%A4%A9%E5%AE%89%E9%97%A8%E5%B9%BF%E5%9C%BA%EF%BC%8C%E5%85%89%E6%98%8E%E6%97%A5%E5%A0%B1%EF%BC%8C2006%E5%B9%B49%E6%9C%8827%E6%97%A5&rft.date=2006-09-27&rft.genre=unknown&rft.pub=Gmw.cn&rft_id=http%3A%2F%2Fwww.gmw.cn%2F01gmrb%2F2006-09%2F27%2Fcontent_485833.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-124"><span class="mw-cite-backlink"><b><a href="#cite_ref-124">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.bjghy.com.cn/xslw/xslw_Detail.asp?UId=2">宋曉龍:北京历史文化名城保护的思考和定位,北京市城市规划设计研究院</a>. <span class="reference-accessdate"> [<span class="nowrap">2010-04-14</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20071118000246/http://www.bjghy.com.cn/xslw/xslw_Detail.asp?UId=2">存档</a>于2007-11-18).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%AE%E6%9B%89%E9%BE%EF%BC%9A%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%E5%9F%8E%E4%BF%9D%E6%8A%A4%E7%9A%84%E6%9D%E8%83%E5%92%8C%E5%AE%9A%E4%BD%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9F%8E%E5%B8%82%E8%A7%84%E5%88%92%E8%AE%BE%E8%AE%A1%E7%A0%94%E7%A9%B6%E9%99%A2&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bjghy.com.cn%2Fxslw%2Fxslw_Detail.asp%3FUId%3D2&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-19年鉴-125"><span class="mw-cite-backlink"><b><a href="#cite_ref-19年鉴_125-0">^</a></b></span> <span class="reference-text"><cite class="citation web">北京统计局. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20200317033233/http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm">北京统计年鉴2019</a>. 北京统计年鉴. <span class="reference-accessdate"> [<span class="nowrap">2020-03-12</span>]</span>. (<a rel="nofollow" class="external text" href="http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm">原始内容</a>存档于2020-03-17).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42019&rft.au=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B1&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B4&rft_id=http%3A%2F%2F202.96.40.155%2Fnj%2Fmain%2F2019-tjnj%2Fzk%2Findexch.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-2035总规-126"><span class="mw-cite-backlink"><b><a href="#cite_ref-2035总规_126-0">^</a></b></span> <span class="reference-text"><cite class="citation web">北京规划和国土资源委员会. <a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/gongkai/guihua/wngh/cqgh/201907/t20190701_100008.html">北京城市总体规划(2016年—2035年)</a>. 首都之窗. <span class="reference-accessdate"> [<span class="nowrap">2020-05-24</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200715214829/http://www.beijing.gov.cn/gongkai/guihua/wngh/cqgh/201907/t20190701_100008.html">存档</a>于2020-07-15).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E6%BB%E4%BD%93%E8%A7%84%E5%88%92%282016%E5%B9%B4%942035%E5%B9%B4%29&rft.au=%E5%8C%97%E4%BA%AC%E8%A7%84%E5%88%92%E5%92%8C%E5%9B%BD%E5%9C%9F%E8%B5%84%E6%BA%90%E5%A7%94%E5%91%98%E4%BC%9A&rft.genre=unknown&rft.jtitle=%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Fgongkai%2Fguihua%2Fwngh%2Fcqgh%2F201907%2Ft20190701_100008.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-127"><span class="mw-cite-backlink"><b><a href="#cite_ref-127">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://daishoudian.114piaowu.com/beijing/">全国火车票订票点大全,火车票订票电话</a>. Huoche.com.cn. 2016-12-20 <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170606042953/http://daishoudian.114piaowu.com/beijing/">存档</a>于2017-06-06) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%85%A8%E5%9B%BD%E7%81%AB%E8%BD%A6%E7%A5%A8%E8%AE%A2%E7%A5%A8%E7%82%B9%E5%A4%A7%E5%85%A8%2C%E7%81%AB%E8%BD%A6%E7%A5%A8%E8%AE%A2%E7%A5%A8%E7%94%B5%E8%AF%9D&rft.date=2016-12-20&rft.genre=unknown&rft.pub=Huoche.com.cn&rft_id=http%3A%2F%2Fdaishoudian.114piaowu.com%2Fbeijing%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-128"><span class="mw-cite-backlink"><b><a href="#cite_ref-128">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/local/2013-03/13/c_115001134.htm">北京地铁日客流1000万人次将成常态,新華網-北京日報,2013年03月13日</a>. News.xinhuanet.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160822191539/http://news.xinhuanet.com/local/2013-03/13/c_115001134.htm">存档</a>于2016-08-22).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E6%97%A5%E5%AE%A2%E6%B5%811000%E4%B8%87%E4%BA%BA%E6%AC%A1%E5%B0%86%E6%88%90%E5%B8%B8%E6%81%2C%E6%96%B0%E8%8F%AF%E7%B6%B2-%E5%8C%97%E4%BA%AC%E6%97%A5%E5%A0%B1%EF%BC%8C2013%E5%B9%B403%E6%9C%8813%E6%97%A5&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flocal%2F2013-03%2F13%2Fc_115001134.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-129"><span class="mw-cite-backlink"><b><a href="#cite_ref-129">^</a></b></span> <span class="reference-text"><cite class="citation web">CCTV.com央视国际网络有限公司版权所有. <a rel="nofollow" class="external text" href="http://news.cctv.com/china/20080229/100141.shtml">首都机场3号航站楼成世界最大单体航站楼,央視網</a>. News.cctv.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20160304213336/http://news.cctv.com/china/20080229/100141.shtml">存档</a>于2016-03-04).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=CCTV.com%E5%A4%AE%E8%A7%86%E5%9B%BD%E9%99%85%E7%BD%91%E7%BB%9C%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8%E7%89%88%E6%9D%83%E6%89%E6%9C%89&rft.btitle=%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA3%E5%8F%B7%E8%88%AA%E7%AB%99%E6%A5%BC%E6%88%90%E4%B8%96%E7%95%8C%E6%9C%E5%A4%A7%E5%95%E4%BD%93%E8%88%AA%E7%AB%99%E6%A5%BC%EF%BC%8C%E5%A4%AE%E8%A6%96%E7%B6%B2&rft.genre=unknown&rft.pub=News.cctv.com&rft_id=http%3A%2F%2Fnews.cctv.com%2Fchina%2F20080229%2F100141.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-130"><span class="mw-cite-backlink"><b><a href="#cite_ref-130">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20151226044435/http://gz.ifeng.com/zaobanche/detail_2015_02/06/3531219_0.shtml">白云机场第三跑道启用 成为国内第三个拥有三条跑道的机场</a>. Gz.ifeng.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (<a rel="nofollow" class="external text" href="http://gz.ifeng.com/zaobanche/detail_2015_02/06/3531219_0.shtml">原始内容</a>存档于2015-12-26).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%99%BD%E4%BA%91%E6%9C%BA%E5%9C%BA%E7%AC%AC%E4%B8%89%E8%B7%91%E9%81%93%E5%90%AF%E7%94%A8+%E6%88%90%E4%B8%BA%E5%9B%BD%E5%86%85%E7%AC%AC%E4%B8%89%E4%B8%AA%E6%A5%E6%9C%89%E4%B8%89%E6%9D%A1%E8%B7%91%E9%81%93%E7%9A%84%E6%9C%BA%E5%9C%BA&rft.genre=unknown&rft.pub=Gz.ifeng.com&rft_id=http%3A%2F%2Fgz.ifeng.com%2Fzaobanche%2Fdetail_2015_02%2F06%2F3531219_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-131"><span class="mw-cite-backlink"><b><a href="#cite_ref-131">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20170827235736/http://202.123.110.3/ztzl/ggjt/content_509491.htm">北京市委市政府高度重视优先发展公共交通工作,中華人民共和國中央人民政府門戶網站</a>. 202.123.110.3. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (<a rel="nofollow" class="external text" href="http://202.123.110.3/ztzl/ggjt/content_509491.htm">原始内容</a>存档于2017-08-27).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%B8%82%E6%94%BF%E5%BA%9C%E9%AB%98%E5%BA%A6%E9%87%E8%A7%86%E4%BC%98%E5%85%88%E5%8F%91%E5%B1%95%E5%85%AC%E5%85%B1%E4%BA%A4%E9%9A%E5%B7%A5%E4%BD%9C%2C%E4%B8+%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%E4%B8+%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C%E9%96%E6%88%B6%E7%B6%B2%E7%AB%99&rft.genre=unknown&rft.pub=202.123.110.3&rft_id=http%3A%2F%2F202.123.110.3%2Fztzl%2Fggjt%2Fcontent_509491.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-132"><span class="mw-cite-backlink"><b><a href="#cite_ref-132">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/fortune/2006-04/30/content_4494016.htm">直面北京“黑车”</a>. News.xinhuanet.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20161023133959/http://news.xinhuanet.com/fortune/2006-04/30/content_4494016.htm">存档</a>于2016-10-23).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%9B%B4%E9%9D%A2%E5%8C%97%E4%BA%AC%9C%E9%BB%91%E8%BD%A6%9D&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Ffortune%2F2006-04%2F30%2Fcontent_4494016.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-133"><span class="mw-cite-backlink"><b><a href="#cite_ref-133">^</a></b></span> <span class="reference-text"><cite class="citation web">北京日报. <a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/fuwu/bmfw/jtcx/ggts/201908/t20190817_1843991.html">2000辆换电出租车8月上路 2020年底三成出租车零排放</a>. 首都之窗. <span class="reference-accessdate"> [<span class="nowrap">2020-05-24</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20200524112534/http://www.beijing.gov.cn/fuwu/bmfw/jtcx/ggts/201908/t20190817_1843991.html">存档</a>于2020-05-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=2000%E8%BE%86%E6%A2%E7%94%B5%E5%87%BA%E7%A7%9F%E8%BD%A68%E6%9C%88%E4%B8%8A%E8%B7%AF+2020%E5%B9%B4%E5%BA%95%E4%B8%89%E6%88%90%E5%87%BA%E7%A7%9F%E8%BD%A6%E9%9B%B6%E6%8E%92%E6%94%BE&rft.au=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5&rft.genre=unknown&rft.jtitle=%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Ffuwu%2Fbmfw%2Fjtcx%2Fggts%2F201908%2Ft20190817_1843991.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-134"><span class="mw-cite-backlink"><b><a href="#cite_ref-134">^</a></b></span> <span class="reference-text">趙爾巽等:清史稿,卷一○七,志八二</span>
</li>
<li id="cite_note-135"><span class="mw-cite-backlink"><b><a href="#cite_ref-135">^</a></b></span> <span class="reference-text"><cite class="citation web">李铁虎. <a rel="nofollow" class="external text" href="http://www.bjma.gov.cn/bjma/300486/301443/306629/index.html">民国时期北京政治文化地位刍议</a>. 北京市档案信息网.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E6%B0%91%E5%9B%BD%E6%97%B6%E6%9C%9F%E5%8C%97%E4%BA%AC%E6%94%BF%E6%B2%BB%E6%96%87%E5%8C%96%E5%9C%B0%E4%BD%E5%88%E8%AE%AE&rft.au=%E6%9D%8E%E9%93%81%E8%99%8E&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E6%A1%A3%E6%A1%88%E4%BF%A1%E6%81%AF%E7%BD%91&rft_id=http%3A%2F%2Fwww.bjma.gov.cn%2Fbjma%2F300486%2F301443%2F306629%2Findex.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-136"><span class="mw-cite-backlink"><b><a href="#cite_ref-136">^</a></b></span> <span class="reference-text"><cite class="citation web">北京市统计局. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20190331090019/http://www.bjstats.gov.cn/tjsj/yjdsj/rk/2018/201901/t20190123_415576.html">全市年末常住人口</a>. 2019-01-23 <span class="reference-accessdate"> [<span class="nowrap">2019-03-31</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjstats.gov.cn/tjsj/yjdsj/rk/2018/201901/t20190123_415576.html">原始内容</a>存档于2019-03-31).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1&rft.btitle=%E5%85%A8%E5%B8%82%E5%B9%B4%E6%9C%AB%E5%B8%B8%E4%BD%8F%E4%BA%BA%E5%8F%A3&rft.date=2019-01-23&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Ftjsj%2Fyjdsj%2Frk%2F2018%2F201901%2Ft20190123_415576.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-137"><span class="mw-cite-backlink"><b><a href="#cite_ref-137">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://knowledgedatabase.info/the-basic-information-of-beijing/">The Basic Information of BeiJing - Knowledge Database</a>. Knowledge Database. 2018-08-14 <span class="reference-accessdate"> [<span class="nowrap">2018-08-15</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20180814103401/http://knowledgedatabase.info/the-basic-information-of-beijing/">存档</a>于2018-08-14) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到美国英语网页">(美国英语)</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=The+Basic+Information+of+BeiJing+-+Knowledge+Database&rft.date=2018-08-14&rft.genre=article&rft.jtitle=Knowledge+Database&rft_id=http%3A%2F%2Fknowledgedatabase.info%2Fthe-basic-information-of-beijing%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-138"><span class="mw-cite-backlink"><b><a href="#cite_ref-138">^</a></b></span> <span class="reference-text"><cite class="citation book">北京市统计局、国家统计局北京调查总队. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20181224170530/http://tjj.beijing.gov.cn/nj/main/2018-tjnj/zk/indexch.htm">北京统计年鉴2018</a>. 北京: 中国统计出版社、北京数通电子出版社. : 3–3 <span class="reference-accessdate"> [<span class="nowrap">2019-03-31</span>]</span>. (<a rel="nofollow" class="external text" href="http://tjj.beijing.gov.cn/nj/main/2018-tjnj/zk/indexch.htm">原始内容</a>存档于2018-12-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft.btitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42018&rft.genre=book&rft.pages=3-3&rft.place=%E5%8C%97%E4%BA%AC&rft.pub=%E4%B8+%E5%9B%BD%E7%BB%9F%E8%AE%A1%E5%87%BA%E7%89%88%E7%A4%BE%E3%81%E5%8C%97%E4%BA%AC%E6%95%B0%E9%9A%E7%94%B5%E5+%90%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=http%3A%2F%2Ftjj.beijing.gov.cn%2Fnj%2Fmain%2F2018-tjnj%2Fzk%2Findexch.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-139"><span class="mw-cite-backlink"><b><a href="#cite_ref-139">^</a></b></span> <span class="reference-text"><cite class="citation web">北京市统计局、国家统计局北京调查总队. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20140310101546/http://www.bjstats.gov.cn/xwgb/tjgb/ndgb/201402/t20140213_267744.htm">北京市2013年国民经济和社会发展统计公报</a>. 北京市统计局、国家统计局北京调查总队. 2013-02-13 <span class="reference-accessdate"> [<span class="nowrap">2013-03-10</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjstats.gov.cn/xwgb/tjgb/ndgb/201402/t20140213_267744.htm">原始内容</a>存档于2014-03-10) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%822013%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft.date=2013-02-13&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Fxwgb%2Ftjgb%2Fndgb%2F201402%2Ft20140213_267744.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-140"><span class="mw-cite-backlink"><b><a href="#cite_ref-140">^</a></b></span> <span class="reference-text"><cite class="citation web">北京市第六次人口普查办公室. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20140310101349/http://www.bjstats.gov.cn/lhzl/rkpc/201201/t20120109_218574.htm">北京市常住人口地区分布特点</a>. 北京市统计局、国家统计局北京调查总队. 2011-05-30 <span class="reference-accessdate"> [<span class="nowrap">2013-04-03</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjstats.gov.cn/lhzl/rkpc/201201/t20120109_218574.htm">原始内容</a>存档于2014-03-10) <span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">(中文(中国大陆))</span>.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%B8%B8%E4%BD%8F%E4%BA%BA%E5%8F%A3%E5%9C%B0%E5%8C%BA%E5%88%86%E5%B8%83%E7%89%B9%E7%82%B9&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%AC%AC%E5%85+%E6%AC%A1%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5%E5%8A%9E%E5%85%AC%E5%AE%A4&rft.date=2011-05-30&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Flhzl%2Frkpc%2F201201%2Ft20120109_218574.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-141"><span class="mw-cite-backlink"><b><a href="#cite_ref-141">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/overseas/2009-10/08/content_12193602.htm">在华居住韩国人达百万 北京人数最多达二十万,新華網</a>. News.xinhuanet.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20130724193221/http://news.xinhuanet.com/overseas/2009-10/08/content_12193602.htm">存档</a>于2013-07-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9C%A8%E5%8E%E5%B1%85%E4%BD%8F%E9%9F%A9%E5%9B%BD%E4%BA%BA%E8%BE%BE%E7%99%BE%E4%B8%87+%E5%8C%97%E4%BA%AC%E4%BA%BA%E6%95%B0%E6%9C%E5%A4%9A%E8%BE%BE%E4%BA%8C%E5%81%E4%B8%87%2C%E6%96%B0%E8%8F%AF%E7%B6%B2&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Foverseas%2F2009-10%2F08%2Fcontent_12193602.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-142"><span class="mw-cite-backlink"><b><a href="#cite_ref-142">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.xinhuanet.com/local/2011-02/21/c_121102340_2.htm">北京人口规模膨胀超资源极限 调控规模箭在弦上</a>. 新华网. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20110224072040/http://news.xinhuanet.com/local/2011-02/21/c_121102340_2.htm">存档</a>于2011-02-24).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E4%BA%BA%E5%8F%A3%E8%A7%84%E6%A8%A1%E8%86%A8%E8%83%E8%B6%85%E8%B5%84%E6%BA%90%E6%9E%81%E9%99%90+%E8%B0%83%E6%8E%A7%E8%A7%84%E6%A8%A1%E7%AE+%E5%9C%A8%E5%BC%A6%E4%B8%8A&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flocal%2F2011-02%2F21%2Fc_121102340_2.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-143"><span class="mw-cite-backlink"><b><a href="#cite_ref-143">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.chinanews.com/cul/2012/03-01/3711416.shtml">中国国家博物馆正式开馆</a>. 中新社. 2012-03-01 <span class="reference-accessdate"> [<span class="nowrap">2015-11-14</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20120302220956/http://www.chinanews.com/cul/2012/03-01/3711416.shtml">存档</a>于2012-03-02).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B8+%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9A%E7%89%A9%E9%A6%86%E6+%A3%E5%BC%8F%E5%BC%E9%A6%86&rft.date=2012-03-01&rft.genre=article&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fcul%2F2012%2F03-01%2F3711416.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-144"><span class="mw-cite-backlink"><b><a href="#cite_ref-144">^</a></b></span> <span class="reference-text"><cite class="citation news"><a rel="nofollow" class="external text" href="http://www.ecns.cn/2014/06-16/119275.shtml">4 China museums listed on world's top 20</a>. 中新网. 2014-06-16 <span class="reference-accessdate"> [<span class="nowrap">2015-11-14</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20140620094109/http://www.ecns.cn/2014/06-16/119275.shtml">存档</a>于2014-06-20).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=4+China+museums+listed+on+world%27s+top+20&rft.date=2014-06-16&rft.genre=article&rft_id=http%3A%2F%2Fwww.ecns.cn%2F2014%2F06-16%2F119275.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-145"><span class="mw-cite-backlink"><b><a href="#cite_ref-145">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20160810110451/http://bjfles.com/Item/3567.aspx">神奇的探索之旅——一年级北京自然博物馆社会实践活动,北京市海淀外国语实验学校,2013-03-21</a>. Bjfles.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjfles.com/Item/3567.aspx">原始内容</a>存档于2016-08-10).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%A5%9E%E5%A5%87%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B9%E6%97%85%94%94%E4%B8%E5%B9%B4%E7%BA%A7%E5%8C%97%E4%BA%AC%E8%87%AA%E7%84%B6%E5%9A%E7%89%A9%E9%A6%86%E7%A4%BE%E4%BC%9A%E5%AE%9E%E8%B7%B5%E6%B4%BB%E5%8A%A8%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E6%B5%B7%E6%B7%E5%A4%96%E5%9B%BD%E8%AF+%E5%AE%9E%E9%AA%8C%E5+%A6%E6%A0%A1%EF%BC%8C2013-03-21&rft.genre=unknown&rft.pub=Bjfles.com&rft_id=http%3A%2F%2Fwww.bjfles.com%2FItem%2F3567.aspx&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-146"><span class="mw-cite-backlink"><b><a href="#cite_ref-146">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.ifeng.com/mainland/detail_2012_08/25/17090984_0.shtml">故宫安保设施已14年没有升级</a>. 凤凰网. 2012-08-25 <span class="reference-accessdate"> [<span class="nowrap">2015-11-14</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20151117040323/http://news.ifeng.com/mainland/detail_2012_08/25/17090984_0.shtml">存档</a>于2015-11-17).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%95%85%E5%AE%AB%E5%AE%89%E4%BF%9D%E8%AE%BE%E6%96%BD%E5%B7%B214%E5%B9%B4%E6%B2%A1%E6%9C%89%E5%87%E7%BA%A7&rft.date=2012-08-25&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E7%BD%91&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fmainland%2Fdetail_2012_08%2F25%2F17090984_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-147"><span class="mw-cite-backlink"><b><a href="#cite_ref-147">^</a></b></span> <span class="reference-text"><cite class="citation web">2015年04月25日 15:09:14. <a rel="nofollow" class="external text" href="http://news.xinhuanet.com/local/2015-04/25/c_1115088357.htm">中国聚焦:中国阔步走进“博物馆时代”,新华网,2015-04-25</a>. News.xinhuanet.com. <span class="reference-accessdate"> [<span class="nowrap">2017-05-23</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20150820213454/http://news.xinhuanet.com/local/2015-04/25/c_1115088357.htm">存档</a>于2015-08-20).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=2015%E5%B9%B404%E6%9C%8825%E6%97%A5+15%3A09%3A14&rft.btitle=%E4%B8+%E5%9B%BD%E8%81%9A%E7%84%A6%EF%BC%9A%E4%B8+%E5%9B%BD%E9%98%94%E6+%A5%E8%B5%B0%E8%BF%9B%9C%E5%9A%E7%89%A9%E9%A6%86%E6%97%B6%E4%BB%A3%9D%EF%BC%8C%E6%96%B0%E5%8E%E7%BD%91%EF%BC%8C2015-04-25&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flocal%2F2015-04%2F25%2Fc_1115088357.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-148"><span class="mw-cite-backlink"><b><a href="#cite_ref-148">^</a></b></span> <span class="reference-text"><cite class="citation book">歐陽甫中. 北京菜. 2007.</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E6+%90%E9%99%BD%E7%94%AB%E4%B8+&rft.btitle=%E5%8C%97%E4%BA%AC%E8%8F%9C&rft.date=2007&rft.genre=book&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-149"><span class="mw-cite-backlink"><b><a href="#cite_ref-149">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://news.ifeng.com/gundong/detail_2014_03/26/35137478_0.shtml">在云南啖尽异域情调</a>. 云南信息报. 2014-03-26 <span class="reference-accessdate"> [<span class="nowrap">2017-09-16</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170916225255/http://news.ifeng.com/gundong/detail_2014_03/26/35137478_0.shtml">存档</a>于2017-09-16).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9C%A8%E4%BA%91%E5%97%E5%95%96%E5%B0%BD%E5%BC%82%E5%9F%9F%E6%83%85%E8%B0%83&rft.date=2014-03-26&rft.genre=unknown&rft.pub=%E4%BA%91%E5%97%E4%BF%A1%E6%81%AF%E6%8A%A5&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fgundong%2Fdetail_2014_03%2F26%2F35137478_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-150"><span class="mw-cite-backlink"><b><a href="#cite_ref-150">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20100819100056/http://www.ccmedu.com/bbs55_40092.html">北京文艺演出业现状及未来发展</a>. 北京文艺发展论坛. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.ccmedu.com/bbs55_40092.html">原始内容</a>存档于2010-08-19).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%96%87%E8%89%BA%E6%BC%94%E5%87%BA%E4%B8%9A%E7%8E%B0%E7%8A%B6%E5%8F%8A%E6%9C%AA%E6%9D%A5%E5%8F%91%E5%B1%95&rft.genre=unknown&rft.pub=%E5%8C%97%E4%BA%AC%E6%96%87%E8%89%BA%E5%8F%91%E5%B1%95%E8%AE%BA%E5%9D%9B&rft_id=http%3A%2F%2Fwww.ccmedu.com%2Fbbs55_40092.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-151"><span class="mw-cite-backlink"><b><a href="#cite_ref-151">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://ent.sina.com.cn/y/2008-04-28/16072006820.shtml">北京国际音乐节简介</a>. 新浪网. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20111011002322/http://ent.sina.com.cn/y/2008-04-28/16072006820.shtml">存档</a>于2011-10-11).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%9B%BD%E9%99%85%E9%9F%B3%E4%B9%90%E8%8A%82%E7%AE%E4%BB&rft.genre=unknown&rft.pub=%E6%96%B0%E6%B5%AA%E7%BD%91&rft_id=http%3A%2F%2Fent.sina.com.cn%2Fy%2F2008-04-28%2F16072006820.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-152"><span class="mw-cite-backlink"><b><a href="#cite_ref-152">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://art.china.cn/tslz/2009-11/23/content_3257433.htm">北京演出市场上的三大盛宴</a>. 艺术中国. <span class="reference-accessdate"> [<span class="nowrap">2011-08-29</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20140428023819/http://art.china.cn/tslz/2009-11/23/content_3257433.htm">存档</a>于2014-04-28).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%BC%94%E5%87%BA%E5%B8%82%E5%9C%BA%E4%B8%8A%E7%9A%84%E4%B8%89%E5%A4%A7%E7%9B%9B%E5%AE%B4&rft.genre=unknown&rft.pub=%E8%89%BA%E6%9C%AF%E4%B8+%E5%9B%BD&rft_id=http%3A%2F%2Fart.china.cn%2Ftslz%2F2009-11%2F23%2Fcontent_3257433.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-153"><span class="mw-cite-backlink"><b><a href="#cite_ref-153">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.china.com.cn/sports/zhuanti/2008ay/2008-07/11/content_15993221.htm">北京的宗教文化</a>. 中国网. 2008-07-11 <span class="reference-accessdate"> [<span class="nowrap">2017-01-16</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170416200611/http://www.china.com.cn/sports/zhuanti/2008ay/2008-07/11/content_15993221.htm">存档</a>于2017-04-16).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E5%AE%97%E6%95%99%E6%96%87%E5%8C%96&rft.date=2008-07-11&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%9B%BD%E7%BD%91&rft_id=http%3A%2F%2Fwww.china.com.cn%2Fsports%2Fzhuanti%2F2008ay%2F2008-07%2F11%2Fcontent_15993221.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-154"><span class="mw-cite-backlink"><b><a href="#cite_ref-154">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20170118032854/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/dj/index.shtml">中国道教概述</a>. 北京的民族与宗教. 北京市民族事务委员会. <span class="reference-accessdate"> [<span class="nowrap">2017-01-16</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/dj/index.shtml">原始内容</a>存档于2017-01-18).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B8+%E5%9B%BD%E9%81%93%E6%95%99%E6%A6%82%E8%BF%B0&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Fdj%2Findex.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-155"><span class="mw-cite-backlink"><b><a href="#cite_ref-155">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20170118032433/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/fj/index.shtml">中国佛教概述</a>. 北京的民族与宗教. 北京市民族事务委员会. <span class="reference-accessdate"> [<span class="nowrap">2017-01-16</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/fj/index.shtml#">原始内容</a>存档于2017-01-18).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B8+%E5%9B%BD%E4%BD%9B%E6%95%99%E6%A6%82%E8%BF%B0&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Ffj%2Findex.shtml%23&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-156"><span class="mw-cite-backlink"><b><a href="#cite_ref-156">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20170118032533/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/tzj/index.shtml">北京市天主教爱国会</a>. 北京的民族与宗教. 北京市民族事务委员会. <span class="reference-accessdate"> [<span class="nowrap">2017-01-16</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/tzj/index.shtml#">原始内容</a>存档于2017-01-18).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A4%A9%E4%B8%BB%E6%95%99%E7%88%B1%E5%9B%BD%E4%BC%9A&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Ftzj%2Findex.shtml%23&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-157"><span class="mw-cite-backlink"><b><a href="#cite_ref-157">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="https://web.archive.org/web/20170130005328/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/yslj/index.shtml">伊斯兰教简介</a>. 北京的民族与宗教. 北京市民族事务委员会. <span class="reference-accessdate"> [<span class="nowrap">2017-01-16</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/yslj/index.shtml#">原始内容</a>存档于2017-01-30).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%BC%8A%E6%96%AF%E5%85%B0%E6%95%99%E7%AE%E4%BB&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Fyslj%2Findex.shtml%23&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-158"><span class="mw-cite-backlink"><b><a href="#cite_ref-158">^</a></b></span> <span class="reference-text"><cite class="citation web"><a rel="nofollow" class="external text" href="http://www.chinanews.com/ty/2015/07-31/7440932.shtml">北京赢得2022年冬季奥运会举办权</a>. 中国新闻网. 2015-07-31 <span class="reference-accessdate"> [<span class="nowrap">2017-08-19</span>]</span>. (原始内容<a rel="nofollow" class="external text" href="https://web.archive.org/web/20170819190042/http://www.chinanews.com/ty/2015/07-31/7440932.shtml">存档</a>于2017-08-19).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E8%B5%A2%E5%BE%972022%E5%B9%B4%E5%86%AC%E5+%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BE%E5%8A%9E%E6%9D%83&rft.date=2015-07-31&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%9B%BD%E6%96%B0%E9%97%BB%E7%BD%91&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fty%2F2015%2F07-31%2F7440932.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
<li id="cite_note-159"><span class="mw-cite-backlink"><b><a href="#cite_ref-159">^</a></b></span> <span class="reference-text"><cite class="citation book">15-11 北京市市级友好城市. <a rel="nofollow" class="external text" href="https://web.archive.org/web/20170805145351/http://www.bjstats.gov.cn/nj/main/2016-tjnj/zk/html/CH15-11.xls">北京统计年鉴2016</a>. 北京市统计局 (中国统计出版社). <span class="reference-accessdate"> [<span class="nowrap">2017-01-15</span>]</span>. (<a rel="nofollow" class="external text" href="http://www.bjstats.gov.cn/nj/main/2016-tjnj/zk/html/CH15-11.xls">原始内容</a>存档于2017-08-05).</cite><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=15-11+%E5%8C%97%E4%BA%AC%E5%B8%82%E5%B8%82%E7%BA%A7%E5%8F%E5%A5%BD%E5%9F%8E%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42016&rft.genre=bookitem&rft.pub=%E4%B8+%E5%9B%BD%E7%BB%9F%E8%AE%A1%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Fnj%2Fmain%2F2016-tjnj%2Fzk%2Fhtml%2FCH15-11.xls&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span>
</li>
</ol></div>
<h2><span id=".E5.A4.96.E9.83.A8.E9.93.BE.E6.8E.A5"></span><span class="mw-headline" id="外部链接">外部链接</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=37" title="编辑章节:外部链接">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<table class="mbox-small plainlinks sistersitebox" style="border:1px solid #aaa;background-color:#f9f9f9;font-size:small;">
<tbody><tr>
<td class="mbox-image"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/30px-Commons-logo.svg.png" decoding="async" width="30" height="40" class="noviewer" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/45px-Commons-logo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/59px-Commons-logo.svg.png 2x" data-file-width="1024" data-file-height="1376" /></td>
<td class="mbox-text plainlist"><a href="/wiki/%E7%BB%B4%E5%9F%BA%E5%85%B1%E4%BA%AB%E8%B5%84%E6%BA%90" title="维基共享资源">维基共享资源</a>中相關的多媒體資源:<b><a class="external text" href="https://commons.wikimedia.org/wiki/%E5%8C%97%E4%BA%AC?uselang=zh">北京市</a></b>(<a class="external text" href="https://commons.wikimedia.org/wiki/Category:Beijing?uselang=zh">分類</a>)</td></tr></tbody></table>
<dl><dt>概况</dt></dl>
<ul><li>《<a href="/wiki/%E4%B8%96%E7%95%8C%E6%A6%82%E5%86%B5" title="世界概况">世界概况</a>》上有关<a rel="nofollow" class="external text" href="https://www.cia.gov/library/publications/the-world-factbook/geos/ch.html">Beijing</a>的条目</li></ul>
<dl><dt>官方</dt></dl>
<ul><li><a rel="nofollow" class="external text" href="http://www.beijing.gov.cn/">北京市人民政府网站</a><a rel="nofollow" class="external text" href="//web.archive.org/web/19981212023138/http://www.beijing.gov.cn/">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a><span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">(简体中文)</span><span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">(繁體中文)</span><span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英語网页">(英文)</span></li></ul>
<dl><dt>旅遊</dt></dl>
<ul><li><a rel="nofollow" class="external text" href="https://web.archive.org/web/20031229210524/http://www.bjta.gov.cn/">北京市旅游局</a></li>
<li><a rel="nofollow" class="external text" href="http://whlyj.beijing.gov.cn/">北京市文化和旅游局</a><a rel="nofollow" class="external text" href="//web.archive.org/web/20200528032942/http://whlyj.beijing.gov.cn/">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a></li>
<li><a rel="nofollow" class="external text" href="https://web.archive.org/web/20140818220225/http://www.mychinatours.com/beijing-travel/">北京市旅游指南</a><span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英語网页">(英文)</span></li>
<li><a rel="nofollow" class="external text" href="http://www.visitbeijing.com.cn/">北京旅游信息网</a><a rel="nofollow" class="external text" href="//web.archive.org/web/20080911065100/http://www.visitbeijing.com.cn/">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a></li>
<li><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Wikivoyage-Logo-v3-icon.svg/16px-Wikivoyage-Logo-v3-icon.svg.png" decoding="async" width="16" height="16" class="noviewer" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Wikivoyage-Logo-v3-icon.svg/24px-Wikivoyage-Logo-v3-icon.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Wikivoyage-Logo-v3-icon.svg/32px-Wikivoyage-Logo-v3-icon.svg.png 2x" data-file-width="193" data-file-height="193" /> <a href="/wiki/%E7%BB%B4%E5%9F%BA%E5%AF%BC%E6%B8%B8" title="维基导游">维基导游</a>中有關<a href="https://zh.wikivoyage.org/wiki/%E5%8C%97%E4%BA%AC" class="extiw" title="voy:北京">北京</a>的旅遊指南</li></ul>
<dl><dt>地图</dt></dl>
<ul><li><a rel="nofollow" class="external text" href="https://www.google.com/maps/place/Beijing">Google地图 - 北京市</a></li>
<li><a rel="nofollow" class="external text" href="https://web.archive.org/web/20200326073940/http://xzqh.info/lt/attachment/Mon_1704/25_171465_eb85a3f10f138fd.jpg">北京市全境行政区划与地形图</a></li></ul>
<dl><dt>照片</dt></dl>
<ul><li>Flickr - <a rel="nofollow" class="external text" href="http://www.flickr.com/photos/tags/beijing/clusters/">标签为北京的照片</a><a rel="nofollow" class="external text" href="//web.archive.org/web/20090218161610/http://www.flickr.com/photos/tags/beijing/clusters/">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a></li>
<li>Flickr - <a rel="nofollow" class="external text" href="http://www.flickr.com/groups/beijing/">北京群组</a><a rel="nofollow" class="external text" href="//web.archive.org/web/20090113164416/http://www.flickr.com/groups/beijing/">页面存档备份</a>,存于<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">互联网档案馆</a></li>
<li>Pinterest - <a rel="nofollow" class="external text" href="https://www.pinterest.com/search/pins/?q=beijing%20travel&term_meta%5B%5D=beijing%7Ctyped&term_meta%5B%5D=travel%7Ctyped">北京旅游照片</a></li>
<li><a rel="nofollow" class="external text" href="https://web.archive.org/web/20180705180525/https://qnachina.com/23923">圖集 / 再也回不去的老北京</a></li></ul>
<h2><span id=".E5.8F.82.E8.A7.81"></span><span class="mw-headline" id="参见">参见</span><span class="mw-editsection"><span class="mw-editsection-bracket">[</span><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=38" title="编辑章节:参见">编辑</a><span class="mw-editsection-bracket">]</span></span></h2>
<div role="navigation" aria-label="Portals" class="noprint portal plainlist tright" style="margin:0.5em 0 0.5em 1em;border:solid #aaa 1px">
<ul style="display:table;box-sizing:border-box;padding:0.1em;max-width:175px;background:#f9f9f9;font-size:85%;line-height:110%;font-weight:bold">
<li style="display:table-row"><span style="display:table-cell;padding:0.2em;vertical-align:middle;text-align:center"><a href="/wiki/File:China_dragon.svg" class="image"><img alt="icon" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b0/China_dragon.svg/32px-China_dragon.svg.png" decoding="async" width="32" height="21" class="noviewer" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b0/China_dragon.svg/48px-China_dragon.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b0/China_dragon.svg/64px-China_dragon.svg.png 2x" data-file-width="744" data-file-height="496" /></a></span><span style="display:table-cell;padding:0.2em 0.2em 0.2em 0.3em;vertical-align:middle"><a href="/wiki/Portal:%E4%B8%AD%E5%9B%BD" title="Portal:中国">中国主题</a></span></li>
<li style="display:table-row"><span style="display:table-cell;padding:0.2em;vertical-align:middle;text-align:center"><img alt="flag" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/32px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="32" height="21" class="noviewer thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/48px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/64px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /></span><span style="display:table-cell;padding:0.2em 0.2em 0.2em 0.3em;vertical-align:middle"><a href="/wiki/Portal:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="Portal:中华人民共和国">中华人民共和国主题</a></span></li>
<li style="display:table-row"><span style="display:table-cell;padding:0.2em;vertical-align:middle;text-align:center"><a href="/wiki/File:Beijing-name.svg" class="image"><img alt="icon" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Beijing-name.svg/32px-Beijing-name.svg.png" decoding="async" width="32" height="17" class="noviewer" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Beijing-name.svg/48px-Beijing-name.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/20/Beijing-name.svg/64px-Beijing-name.svg.png 2x" data-file-width="327" data-file-height="174" /></a></span><span style="display:table-cell;padding:0.2em 0.2em 0.2em 0.3em;vertical-align:middle"><a href="/wiki/Portal:%E5%8C%97%E4%BA%AC" title="Portal:北京">北京主题</a></span></li></ul></div>
<ul><li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2" title="北京历史">北京历史</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A9%B1" class="mw-redirect" title="北京話">北京話</a></li>
<li><a href="/wiki/%E5%8C%97%E5%B9%B3" class="mw-redirect" title="北平">北平</a></li>
<li><a href="/wiki/%E4%BA%AC%E5%89%A7%E5%90%8D%E5%AE%B6%E5%90%8D%E6%AE%B5%E5%88%97%E8%A1%A8" class="mw-redirect" title="京剧名家名段列表">京剧名家名段列表</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%87%AA%E7%84%B6%E4%BF%9D%E6%8A%A4%E5%8C%BA%E5%88%97%E8%A1%A8" class="mw-redirect" title="北京自然保护区列表">北京自然保护区列表</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E6%96%B0%E9%97%BB%E5%AA%92%E4%BD%93%E5%88%97%E8%A1%A8" class="mw-redirect" title="北京新闻媒体列表">北京新闻媒体列表</a>(包括报社、出版社、媒体等)</li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8C%BB%E7%96%97%E6%9C%BA%E6%9E%84%E5%88%97%E8%A1%A8" title="北京市医疗机构列表">北京市医疗机构列表</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%BA" class="mw-disambig" title="北京人">北京人</a>(<a href="/wiki/Category:%E5%8C%97%E4%BA%AC%E4%BA%BA" title="Category:北京人">分类</a>)</li>
<li><a href="/wiki/%E5%B0%8F%E8%A1%8C%E6%98%9F2045" title="小行星2045">小行星2045</a></li>
<li><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AC%E4%BA%A4300%E8%B7%AF" title="北京公交300路">北京市300路公共汽车</a></li></ul>
<div style="clear: both; height: 1em"></div>
<table class="navbox" style="text-align: center; width:80%; font-size:80%; margin:0.5em auto">
<caption>
</caption>
<tbody><tr>
<td style="width:0%; padding-right:5px" rowspan="5"><div class="center"><div class="floatnone"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/50px-Compass_rose_pale.svg.png" decoding="async" width="50" height="50" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/75px-Compass_rose_pale.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/100px-Compass_rose_pale.svg.png 2x" data-file-width="512" data-file-height="512" /></div></div>
</td>
<td style="width:33%"><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北省</a><a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">张家口市</a><a href="/wiki/%E8%B5%A4%E5%9F%8E%E5%8E%BF" title="赤城县">赤城县</a>
</td>
<td style="width:33%">河北省<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">承德市</a><a href="/wiki/%E4%B8%B0%E5%AE%81%E6%BB%A1%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8E%BF" title="丰宁满族自治县">丰宁满族自治县</a><br />
</td>
<td style="width:33%">河北省承德市<a href="/wiki/%E5%85%B4%E9%9A%86%E5%8E%BF" title="兴隆县">兴隆县</a>、<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%8E%BF" title="承德县">承德县</a>、<a href="/wiki/%E6%BB%A6%E5%B9%B3%E5%8E%BF" title="滦平县">滦平县</a>
</td>
<td style="width:0%; padding-left:5px" rowspan="5"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/50px-Compass_rose_pale.svg.png" decoding="async" width="50" height="50" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/75px-Compass_rose_pale.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/100px-Compass_rose_pale.svg.png 2x" data-file-width="512" data-file-height="512" />
</td></tr>
<tr>
<td style="width:33%" rowspan="3">河北省张家口市<a href="/wiki/%E6%B6%BF%E9%B9%BF%E5%8E%BF" title="涿鹿县">涿鹿县</a>、<a href="/wiki/%E6%80%80%E6%9D%A5%E5%8E%BF" title="怀来县">怀来县</a>
</td>
<td style="width:33%"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/44/North.svg/17px-North.svg.png" decoding="async" title="北" width="17" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/44/North.svg/26px-North.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/44/North.svg/34px-North.svg.png 2x" data-file-width="17" data-file-height="17" />
</td>
<td style="width:33%" rowspan="3"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a><a href="/wiki/%E8%93%9F%E5%B7%9E%E5%8C%BA" title="蓟州区">蓟州区</a>;<br />河北省<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">廊坊市</a><a href="/wiki/%E9%A6%99%E6%B2%B3%E5%8E%BF" title="香河县">香河县</a>、<a href="/wiki/%E5%A4%A7%E5%8E%82%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8E%BF" title="大厂回族自治县">大厂回族自治县</a>、<a href="/wiki/%E4%B8%89%E6%B2%B3%E5%B8%82" title="三河市">三河市</a>
</td></tr>
<tr>
<td style="width:33%">
<table style="width:100%">
<tbody><tr>
<td style="width:50%; text-align:right"><div class="floatright"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f0/West.svg/17px-West.svg.png" decoding="async" title="西" width="17" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f0/West.svg/26px-West.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f0/West.svg/34px-West.svg.png 2x" data-file-width="17" data-file-height="17" /></div>
</td>
<td style="width:0%; text-align: center" nowrap="nowrap">  <b>北京市</b>  
</td>
<td style="width:50%; text-align:left"><div class="floatleft"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Boxed_East_arrow.svg/17px-Boxed_East_arrow.svg.png" decoding="async" title="東" width="17" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Boxed_East_arrow.svg/26px-Boxed_East_arrow.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Boxed_East_arrow.svg/34px-Boxed_East_arrow.svg.png 2x" data-file-width="17" data-file-height="17" /></div>
</td></tr></tbody></table>
</td></tr>
<tr>
<td style="width:33%"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/South.svg/17px-South.svg.png" decoding="async" title="南" width="17" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/South.svg/26px-South.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/cd/South.svg/34px-South.svg.png 2x" data-file-width="17" data-file-height="17" />
</td></tr>
<tr>
<td style="width:33%">河北省<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">保定市</a><a href="/wiki/%E6%B6%9E%E6%B0%B4%E5%8E%BF" title="涞水县">涞水县</a>、<a href="/wiki/%E6%B6%BF%E5%B7%9E%E5%B8%82" title="涿州市">涿州市</a>
</td>
<td style="width:33%">河北省廊坊市<a href="/wiki/%E5%B9%BF%E9%98%B3%E5%8C%BA" title="广阳区">广阳区</a>、<a href="/wiki/%E5%9B%BA%E5%AE%89%E5%8E%BF" title="固安县">固安县</a>、<a href="/wiki/%E6%B0%B8%E6%B8%85%E5%8E%BF" title="永清县">永清县</a><br />
</td>
<td style="width:33%"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a><a href="/wiki/%E6%AD%A6%E6%B8%85%E5%8C%BA" title="武清区">武清区</a>
</td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><span style="float:left;width:8em;font-size:80%;margin-right:0.5em"> </span><div style="font-size:110%">北京相关导航模板</div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px;padding:0px;font-size:111%;"><div style="padding:0px;"><table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E8%80%81%E5%8C%97%E4%BA%AC%E5%9F%8E" title="Template:老北京城"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E8%80%81%E5%8C%97%E4%BA%AC%E5%9F%8E" title="Template talk:老北京城"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E8%80%81%E5%8C%97%E4%BA%AC%E5%9F%8E&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a class="mw-selflink selflink">老北京地名与历史文化主题</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div><a href="/wiki/Portal:%E5%8C%97%E4%BA%AC" title="Portal:北京">北京主题页</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">規劃</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E8%BD%B4%E7%BA%BF" title="北京中轴线">北京中軸綫</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%98%8E%E6%B8%85%E5%8C%97%E4%BA%AC%E5%9F%8E" title="明清北京城">北京城池</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%A2%99" title="北京城墙">北京城牆</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E9%97%A8" title="北京城门">北京城門</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%9A%87%E5%9F%8E" title="北京皇城">北京皇城</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E6%B8%85%E4%BB%A3%E7%8E%8B%E5%BA%9C" title="北京清代王府">北京王府</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%83%A1%E5%90%8C%E5%88%97%E8%A1%A8" title="北京胡同列表">北京胡同</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%89%8C%E6%A5%BC&action=edit&redlink=1" class="new" title="北京牌楼(页面不存在)">北京牌樓</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%9B%9B%E5%90%88%E9%99%A2" title="四合院">四合院</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2" title="北京历史"><span style="color:#00008B;">歷史</span></a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">县级:<a href="/wiki/%E8%93%9F%E5%8E%BF_(%E7%87%95%E5%9B%BD)" title="蓟县 (燕国)">薊縣(古代)</a>(<a href="/wiki/%E8%93%9F%E5%9F%8E" title="蓟城">薊城</a>)</span> <span class="nowrap">→ <a href="/wiki/%E8%93%9F%E5%9F%8E" title="蓟城">薊北縣</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9E%90%E6%B4%A5" class="mw-redirect" title="析津">析津县</a></span> <span class="nowrap">→ <a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8E%BF" class="mw-disambig" title="大兴县">大兴县</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%87%95%E9%83%BD" class="mw-redirect" title="燕都">燕都县</a></span> <span class="nowrap">→ <a href="/wiki/%E5%B9%BD%E9%83%BD%E5%8E%BF" title="幽都县">幽都县</a></span> <span class="nowrap">→ <a href="/wiki/%E5%AE%9B%E5%B9%B3%E7%B8%A3" title="宛平縣">宛平县</a><br />郡州路府市级:<a href="/wiki/%E7%87%95%E5%9B%BD" title="燕国">燕国</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%87%95%E5%9B%BD_(%E6%A5%9A%E6%B1%89%E6%88%98%E4%BA%89)" title="燕国 (楚汉战争)">燕国 (楚汉战争)</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">广阳郡</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BD%E5%B7%9E_(%E5%8D%81%E5%85%AD%E5%9B%BD)" class="mw-redirect" title="幽州 (十六国)">幽州</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%87%95%E4%BA%AC" class="mw-redirect" title="燕京">燕京</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%BE%BD%E5%8D%97%E4%BA%AC" title="辽南京">辽南京</a>(<a href="/wiki/%E5%8D%97%E4%BA%AC%E9%81%93" title="南京道">南京道</a><a href="/wiki/%E6%9E%90%E6%B4%A5%E5%BA%9C" title="析津府">析津府</a>) ·</span> <span class="nowrap"><a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">金中都</a>(<a href="/wiki/%E4%B8%AD%E9%83%BD%E8%B7%AF" title="中都路">中都路</a><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%BA%9C" title="大兴府">大兴府</a>) ·</span> <span class="nowrap"><a href="/wiki/%E5%85%83%E5%A4%A7%E9%83%BD" title="元大都">元大都</a>(<a href="/wiki/%E5%A4%A7%E9%83%BD%E8%B7%AF" title="大都路">大都路</a>) ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E5%B9%B3%E5%BA%9C" title="北平府">北平府</a>(<a href="/wiki/%E5%8C%97%E5%B9%B3" class="mw-redirect" title="北平">北平</a>) ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%AC%E5%B8%88" class="mw-redirect mw-disambig" title="京师">京师</a><a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">順天府</a>(北京) ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">京兆地方</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">北平市</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">傳統<br />藝術</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E6%98%86%E6%9B%B2" title="昆曲">昆曲</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%AC%E5%89%A7" title="京剧">京剧</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A9%95%E5%8A%87" class="mw-redirect" title="評劇">評劇</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B2%B3%E5%8C%97%E6%A2%86%E5%AD%90" title="河北梆子">河北梆子</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%AC%E9%9F%B5%E5%A4%A7%E9%BC%93" title="京韵大鼓">京韻大鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E6%B2%B3%E5%A4%A7%E9%BC%93" title="西河大鼓">西河大鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%A2%85%E8%8A%B1%E5%A4%A7%E9%BC%93" title="梅花大鼓">梅花大鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%AC%E4%B8%9C%E5%A4%A7%E9%BC%93" title="京东大鼓">京东大鼓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%90%AB%E7%81%AF%E5%A4%A7%E9%BC%93&action=edit&redlink=1" class="new" title="含灯大鼓(页面不存在)">含灯大鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%BB%91%E7%A8%BD%E5%A4%A7%E9%BC%93" title="滑稽大鼓">滑稽大鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%94%E9%9F%B3%E5%A4%A7%E9%BC%93" title="五音大鼓">五音大鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%90%B4%E4%B9%A6" title="北京琴书">北京琴書</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E8%A9%95%E6%9B%B8&action=edit&redlink=1" class="new" title="北京評書(页面不存在)">北京評書</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%9B%B8%E8%81%B2" class="mw-redirect" title="相聲">相聲</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8F%8C%E7%B0%A7" title="双簧">雙簧</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%85%AB%E8%A7%92%E9%BC%93" title="八角鼓">八角鼓</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%95%E5%BC%A6" title="单弦">單弦</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BF%AB%E6%9D%BF%E4%B9%A6" title="快板书">快板書</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%95%B0%E6%9D%A5%E5%AE%9D" title="数来宝">數來寶</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%99%BA%E5%8C%96%E5%AF%BA" title="智化寺">智化寺京音樂</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%99%AF%E6%B3%B0%E8%97%8D" title="景泰藍">景泰藍</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%B1%A1%E7%89%99%E9%9B%95%E5%88%BB&action=edit&redlink=1" class="new" title="象牙雕刻(页面不存在)">象牙雕刻</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9B%95%E6%BC%86" title="雕漆">雕漆</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%96%99%E5%99%A8&action=edit&redlink=1" class="new" title="料器(页面不存在)">料器</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%AC%E7%B9%A1" title="京繡">京綉</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%90%89%E7%92%83" title="琉璃">琉璃</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%8A%B1%E4%B8%9D%E9%95%B6%E5%B5%8C&action=edit&redlink=1" class="new" title="花丝镶嵌(页面不存在)">花丝镶嵌</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%87%91%E6%BC%86%E9%95%B6%E5%B5%8C&action=edit&redlink=1" class="new" title="金漆镶嵌(页面不存在)">金漆镶嵌</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%A2%A8%E7%AE%8F%E5%93%88&action=edit&redlink=1" class="new" title="風箏哈(页面不存在)">風箏哈</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%AC%83%E4%BA%BA" title="鬃人">鬃人</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%AF%9B%E7%8C%B4&action=edit&redlink=1" class="new" title="毛猴(页面不存在)">毛猴</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%BC%BB%E7%85%99%E5%A3%BA" class="mw-redirect" title="鼻煙壺">内畫鼻煙壺</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%81%9A%E5%85%83%E5%8F%B7" title="聚元号">聚元号</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E4%BA%AC%E4%BD%9C%E7%A1%AC%E6%9C%A8%E5%AE%B6%E5%85%B7&action=edit&redlink=1" class="new" title="京作硬木家具(页面不存在)">京作硬木家具</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%87%88%E5%BD%A9&action=edit&redlink=1" class="new" title="北京燈彩(页面不存在)">北京燈彩</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%8E%89%E9%9B%95&action=edit&redlink=1" class="new" title="北京玉雕(页面不存在)">北京玉雕</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%AE%AB%E6%AF%AF&action=edit&redlink=1" class="new" title="宫毯(页面不存在)">宫毯</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A9%E6%A1%A5" title="北京天桥">天橋</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E6%A1%A5%E5%85%AB%E6%80%AA" title="天桥八怪">天橋八怪</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%B3%96%E4%BA%BA" title="糖人">吹糖人</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%9D%A2%E4%BA%BA%E9%83%8E&action=edit&redlink=1" class="new" title="面人郎(页面不存在)">面人郎</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%8B%89%E6%B4%8B%E7%89%87" title="拉洋片">拉洋片</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%B3%BD%E6%B4%BB%E9%A9%A2&action=edit&redlink=1" class="new" title="賽活驢(页面不存在)">賽活驢</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%8A%80%E6%A7%8D%E5%88%BA%E5%96%89&action=edit&redlink=1" class="new" title="銀槍刺喉(页面不存在)">銀槍刺喉</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%8B%89%E7%A1%AC%E5%BC%93&action=edit&redlink=1" class="new" title="拉硬弓(页面不存在)">拉硬弓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E6%A9%8B%E6%91%94%E8%B7%A4&action=edit&redlink=1" class="new" title="天橋摔跤(页面不存在)">天橋摔跤</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8F%A4%E5%BD%A9%E6%88%B2%E6%B3%95&action=edit&redlink=1" class="new" title="古彩戲法(页面不存在)">古彩戲法</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9B%9C%E6%8A%80" title="雜技">雜技</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8F%A3%E6%8A%80" title="口技">口技</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E4%B8%AD%E5%B9%A1&action=edit&redlink=1" class="new" title="中幡(页面不存在)">中幡</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A7%E5%8A%9B%E4%B8%B8&action=edit&redlink=1" class="new" title="大力丸(页面不存在)">大力丸</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%80%81%E5%AD%97%E5%8F%B7" title="北京老字号"><span style="color:#00008B;">老字號</span></a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/w/index.php?title=%E9%B6%B4%E5%B9%B4%E5%A0%82&action=edit&redlink=1" class="new" title="鶴年堂(页面不存在)">鶴年堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%90%8C%E4%BB%81%E5%A0%82" title="同仁堂">同仁堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%95%B7%E6%98%A5%E5%A0%82&action=edit&redlink=1" class="new" title="長春堂(页面不存在)">長春堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%BE%B7%E5%A3%BD%E5%A0%82&action=edit&redlink=1" class="new" title="德壽堂(页面不存在)">德壽堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%A8%BB%E9%A6%99%E6%9D%91" title="北京稻香村">稻香村</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%A8%BB%E9%A6%99%E6%98%A5" title="稻香春">稻香春</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%85%A7%E8%81%AF%E9%99%9E" title="內聯陞">內聯陞</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%A6%AC%E8%81%9A%E6%BA%90&action=edit&redlink=1" class="new" title="馬聚源(页面不存在)">馬聚源</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%9B%9B%E9%8C%AB%E7%A6%8F" title="盛錫福">盛錫福</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%90%8C%E9%99%9E%E5%92%8C&action=edit&redlink=1" class="new" title="同陞和(页面不存在)">同陞和</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%AD%A5%E7%80%9B%E9%BD%8B&action=edit&redlink=1" class="new" title="步瀛齋(页面不存在)">步瀛齋</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%80%9A%E4%B8%89%E7%9B%8A&action=edit&redlink=1" class="new" title="通三益(页面不存在)">通三益</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%8E%8B%E9%BA%BB%E5%AD%90" title="王麻子">王麻子</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%85%AB%E5%A4%A7%E7%A5%A5&action=edit&redlink=1" class="new" title="八大祥(页面不存在)">八大祥</a>(<a href="/wiki/%E7%91%9E%E8%9A%A8%E7%A5%A5" title="瑞蚨祥">瑞蚨祥</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%91%9E%E7%94%9F%E7%A5%A5&action=edit&redlink=1" class="new" title="瑞生祥(页面不存在)">瑞生祥</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%91%9E%E5%A2%9E%E7%A5%A5&action=edit&redlink=1" class="new" title="瑞增祥(页面不存在)">瑞增祥</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%91%9E%E6%9E%97%E7%A5%A5&action=edit&redlink=1" class="new" title="瑞林祥(页面不存在)">瑞林祥</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%9B%8A%E5%92%8C%E7%A5%A5&action=edit&redlink=1" class="new" title="益和祥(页面不存在)">益和祥</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%BB%A3%E7%9B%9B%E7%A5%A5&action=edit&redlink=1" class="new" title="廣盛祥(页面不存在)">廣盛祥</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%A5%A5%E7%BE%A9%E8%99%9F" title="祥義號">祥義號</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%AC%99%E7%A5%A5%E7%9B%8A" title="謙祥益">謙祥益</a>) ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%80%E5%BE%97%E9%98%81" title="一得阁">一得閣</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%8D%A3%E5%AE%9D%E6%96%8B" title="荣宝斋">榮寶齋</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%88%B4%E6%9C%88%E8%BB%92&action=edit&redlink=1" class="new" title="戴月軒(页面不存在)">戴月軒</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%89%BF%E5%8F%A4%E9%BD%8B&action=edit&redlink=1" class="new" title="承古齋(页面不存在)">崇古齋</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BB%BA%E5%8D%8E%E7%9A%AE%E8%B4%A7%E6%9C%8D%E8%A3%85%E5%85%AC%E5%8F%B8" title="建华皮货服装公司">德源興</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BC%B5%E4%B8%80%E5%85%83" title="張一元">張一元</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E6%9E%97%E6%98%A5&action=edit&redlink=1" class="new" title="慶林春(页面不存在)">慶林春</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%90%B4%E8%A3%95%E6%B3%B0%E8%8C%B6%E4%B8%9A%E8%82%A1%E4%BB%BD%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8" class="mw-redirect" title="北京吴裕泰茶业股份有限公司">吳裕泰</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%85%83%E9%95%B7%E5%8E%9A&action=edit&redlink=1" class="new" title="元長厚(页面不存在)">元長厚</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E4%BA%A8%E5%BE%97%E5%88%A9%E9%90%98%E8%A1%A8%E5%BA%97&action=edit&redlink=1" class="new" title="亨得利鐘表店(页面不存在)">亨得利鐘表眼鏡商店</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A7%E6%98%8E%E7%9C%BC%E9%8F%A1%E5%BA%97&action=edit&redlink=1" class="new" title="大明眼鏡店(页面不存在)">大明眼鏡店</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A7%E6%98%8E%E7%9C%BC%E9%8F%A1%E5%BA%97&action=edit&redlink=1" class="new" title="大明眼鏡店(页面不存在)">精益眼鏡店</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%9B%9B%E5%A4%A7%E6%81%86&action=edit&redlink=1" class="new" title="四大恆(页面不存在)">四大恆</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B9%89%E5%88%A9" title="义利">義利</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%9B%99%E5%90%88%E7%9B%9B&action=edit&redlink=1" class="new" title="雙合盛(页面不存在)">雙合盛</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E6%83%A0%E9%BD%8B&action=edit&redlink=1" class="new" title="天惠齋(页面不存在)">天惠齋</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%9D%B1%E6%98%87%E5%B9%B3&action=edit&redlink=1" class="new" title="東昇平(页面不存在)">東昇平</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B8%85%E5%8D%8E%E5%9B%AD%E6%B5%B4%E6%B1%A0" title="清华园浴池">清華園浴池</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%B8%85%E8%8F%AF%E6%B1%A0&action=edit&redlink=1" class="new" title="清華池(页面不存在)">清華池</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%91%AB%E5%9B%AD%E5%AE%A2%E6%A0%88" title="鑫园客栈">鑫园澡堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%88%88%E8%8F%AF%E5%9C%92&action=edit&redlink=1" class="new" title="興華園(页面不存在)">興華園</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E5%B1%B1%E5%85%AC%E5%9B%AD" title="北京中山公园">來今雨軒</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">名勝</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8" title="天安门">天安門</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%95%85%E5%AE%AE" class="mw-redirect" title="故宮">故宮</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%AD%A3%E9%98%B3%E9%97%A8" title="正阳门">正陽門</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%99%AF%E5%B1%B1%E5%85%AC%E5%9B%AD" title="景山公园">景山</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E6%B5%B7%E5%85%AC%E5%9C%92" class="mw-redirect" title="北海公園">北海</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BB%80%E5%88%B9%E6%B5%B7" title="什刹海">什刹海</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B9%9D%E5%A3%87%E5%85%AB%E5%BB%9F" title="九壇八廟">九壇八廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%87%95%E4%BA%AC%E5%85%AB%E6%99%AF" title="燕京八景">燕京八景</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E6%A0%85%E6%A0%8F" title="大栅栏">大柵欄</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E9%BC%93%E6%A5%BC%E5%92%8C%E9%92%9F%E6%A5%BC" title="北京鼓楼和钟楼">鐘鼓樓</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A9%E6%A1%A5" title="北京天桥">天橋</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%90%89%E7%92%83%E5%8E%82" title="琉璃厂">琉璃廠</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%85%AB%E5%A4%A7%E8%83%A1%E5%90%8C" title="八大胡同">八大胡同</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">寺廟<br />與廟會</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AB%E5%88%B9%E4%B8%89%E5%B1%B1" title="北京八刹三山">八刹三山</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%95%85%E5%AE%AB%E5%A4%96%E5%85%AB%E5%BA%99" title="故宫外八庙">故宫外八庙</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E9%9A%86%E5%96%84%E6%8A%A4%E5%9B%BD%E5%AF%BA" title="大隆善护国寺">護國寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9A%86%E7%A6%8F%E5%AF%BA_(%E5%8C%97%E4%BA%AC)" title="隆福寺 (北京)">隆福寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A6%99%E5%BA%94%E5%AF%BA" title="妙应寺">白塔寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9B%8D%E5%92%8C%E5%AE%AE" class="mw-redirect" title="雍和宮">雍和宮</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%8A%A5%E5%9B%BD%E5%AF%BA_(%E5%8C%97%E4%BA%AC)" class="mw-redirect" title="报国寺 (北京)">報國寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%83%BD%E5%9C%9F%E5%9C%B0%E5%BB%9F" title="都土地廟">都土地廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%99%BD%E9%9B%B2%E8%A7%80" class="mw-redirect" title="白雲觀">白雲觀</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%9C%E5%B2%B3%E5%BA%99" title="北京东岳庙">東岳廟</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E4%BA%94%E9%A0%82&action=edit&redlink=1" class="new" title="五頂(页面不存在)">五頂</a>(<a href="/wiki/%E4%B8%9C%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="东顶娘娘庙">东顶</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="南顶娘娘庙">南顶</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E4%BB%81%E5%AE%AB" title="广仁宫">西顶</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="北顶娘娘庙">北顶</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%AD%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="中顶娘娘庙">中顶</a>) ·</span> <span class="nowrap"><a href="/wiki/%E8%9F%A0%E6%A1%83%E5%AE%AB" title="蟠桃宫">蟠桃宮</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8E%82%E7%94%B8%E5%BA%99%E4%BC%9A" title="厂甸庙会">厰甸</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E9%83%BD%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="北京都城隍廟">都城隍廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%9B%E5%B9%B3%E7%B8%A3%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="宛平縣城隍廟">宛平縣城隍廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E8%88%88%E7%B8%A3%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="大興縣城隍廟">大興縣城隍廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B1%9F%E5%8D%97%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="江南城隍廟">江南城隍廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%94%E9%A1%AF%E8%B2%A1%E7%A5%9E%E5%BB%9F" title="五顯財神廟">五顯財神廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B4%87%E5%85%83%E8%A7%82" title="崇元观">崇元觀</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%AA%E9%98%B3%E5%AE%AB_(%E5%B7%A6%E5%AE%89%E9%97%A8)" title="太阳宫 (左安门)">太陽宮</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E5%AE%81%E8%A7%82" title="广宁观">廣寧觀</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%8A%B1%E5%B8%82%E7%81%AB%E7%A5%9E%E5%BA%99" title="花市火神庙">花市火神廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%9C%B0%E5%AE%89%E9%97%A8%E7%81%AB%E7%A5%9E%E5%BA%99" title="地安门火神庙">地安門火神廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%83%BD%E7%81%B6%E5%90%9B%E5%BB%9F" title="都灶君廟">都灶君廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%99%AE%E6%B5%8E%E8%8D%AF%E7%8E%8B%E5%BA%99" title="普济药王庙">西藥王廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%A6%8F%E4%B8%96%E6%99%AE%E6%B5%8E%E8%8D%AF%E7%8E%8B%E5%BA%99" title="福世普济药王庙">東藥王廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%95%95%E5%B0%81%E8%97%A5%E7%8E%8B%E5%BB%9F" title="敕封藥王廟">南藥王廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E8%97%A5%E7%8E%8B%E5%BB%9F" title="北藥王廟">北藥王廟</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A6%99%E5%B3%B0%E5%B1%B1" title="妙峰山">妙峰山</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%AB%E9%AB%BB%E5%B1%B1_(%E5%B9%B3%E8%B0%B7)" title="丫髻山 (平谷)">丫髻山</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%89%9B%E8%A1%97%E7%A4%BC%E6%8B%9C%E5%AF%BA" title="牛街礼拜寺">牛街礼拜寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%9C%E5%9B%9B%E6%B8%85%E7%9C%9F%E5%AF%BA" title="东四清真寺">东四清真寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%8A%B1%E5%B8%82%E6%B8%85%E7%9C%9F%E5%AF%BA" title="花市清真寺">花市清真寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%A9%AC%E7%94%B8%E6%B8%85%E7%9C%9F%E5%AF%BA" title="马甸清真寺">马甸清真寺</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E4%BB%80%E5%BA%93%E5%A4%A9%E4%B8%BB%E5%A0%82" title="西什库天主堂">北堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%A3%E6%AD%A6%E9%97%A8%E5%A4%A9%E4%B8%BB%E5%A0%82" title="宣武门天主堂">南堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%8E%8B%E5%BA%9C%E4%BA%95%E5%A4%A9%E4%B8%BB%E5%A0%82" title="王府井天主堂">东堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E7%9B%B4%E9%97%A8%E5%A4%A9%E4%B8%BB%E5%A0%82" title="西直门天主堂">西堂</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%80%81%E5%8C%97%E4%BA%AC%E5%90%84%E5%9C%B0%E4%BC%9A%E9%A6%86%E5%88%97%E8%A1%A8" title="老北京各地会馆列表">會館</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E6%B9%96%E5%B9%BF%E4%BC%9A%E9%A6%86" title="北京湖广会馆">湖廣會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%AE%89%E5%BE%BD%E4%BC%9A%E9%A6%86" title="北京安徽会馆">安徽會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E6%B1%9F%E8%A5%BF%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京江西会馆(页面不存在)">江西會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E6%B9%96%E5%8D%97%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京湖南会馆(页面不存在)">湖南會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%9B%9B%E5%B7%9D%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京四川会馆(页面不存在)">四川會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%85%A8%E6%B5%99%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京全浙会馆(页面不存在)">全浙會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%A6%8F%E5%BB%BA%E4%BC%9A%E9%A6%86" title="北京福建会馆">福建會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%A6%8F%E5%BB%BA%E6%B1%80%E5%B7%9E%E4%BC%9A%E9%A6%86" title="北京福建汀州会馆">福建汀州會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%8D%97%E6%B5%B7%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京南海会馆(页面不存在)">南海會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%AE%89%E5%BA%86%E4%BC%9A%E9%A6%86" title="北京安庆会馆">安慶會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E6%B5%8F%E9%98%B3%E4%BC%9A%E9%A6%86" title="北京浏阳会馆">瀏陽會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%95%AA%E7%A6%BA%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京番禺会馆(页面不存在)">番禺會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E9%A1%BA%E5%BE%B7%E4%BC%9A%E9%A6%86" title="北京顺德会馆">順德會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B9%B3%E9%98%B3%E4%BC%9A%E9%A6%86" title="北京平阳会馆">平陽會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E5%B1%B1%E4%BC%9A%E9%A6%86" title="北京中山会馆">中山會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%B2%A4%E4%B8%9C%E6%96%B0%E9%A6%86" title="北京粤东新馆">粵東新舘</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%BB%8D%E5%85%B4%E4%BC%9A%E9%A6%86" title="北京绍兴会馆">紹興會館</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E4%BC%91%E5%AE%81%E4%BC%9A%E9%A6%86&action=edit&redlink=1" class="new" title="北京休宁会馆(页面不存在)">休寧會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E6%BD%AE%E5%B7%9E%E4%BC%9A%E9%A6%86" title="北京潮州会馆">潮州會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8F%B0%E6%B9%BE%E4%BC%9A%E9%A6%86" title="北京台湾会馆">台灣會館</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%AD%A3%E4%B9%99%E7%A5%A0" title="正乙祠">正乙祠</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">商場</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E9%9D%92%E4%BA%91%E9%98%81" title="青云阁">青雲閣</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8A%9D%E4%B8%9A%E5%9C%BA" title="北京劝业场">勸業場</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%9C%E5%AE%89%E5%B8%82%E5%9C%BA" title="东安市场">東安市場</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%A6%96%E5%96%84%E7%AC%AC%E4%B8%80%E6%A8%93&action=edit&redlink=1" class="new" title="首善第一樓(页面不存在)">首善第一樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E6%A9%8B%E5%B8%82%E5%A0%B4&action=edit&redlink=1" class="new" title="天橋市場(页面不存在)">天橋市場</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%A5%BF%E5%AE%89%E5%B8%82%E5%A0%B4&action=edit&redlink=1" class="new" title="西安市場(页面不存在)">西安市場</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E5%8D%95%E5%95%86%E5%9C%BA" title="西单商场">西單商場</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">戲院</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%B9%BF%E5%92%8C%E6%A5%BC" title="广和楼">廣和樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%99%AF%E6%B3%B0%E5%9C%92&action=edit&redlink=1" class="new" title="景泰園(页面不存在)">景泰園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%B3%B0%E8%8F%AF%E5%9C%92&action=edit&redlink=1" class="new" title="泰華園(页面不存在)">泰華園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%98%9C%E6%88%90%E5%9C%92&action=edit&redlink=1" class="new" title="阜成園(页面不存在)">阜成園</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E5%BE%B7%E6%A5%BC" title="广德楼">廣德樓</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%AD%E5%92%8C%E6%88%8F%E9%99%A2" title="中和戏院">中和戲院</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BA%86%E4%B9%90%E5%A4%A7%E6%88%8F%E9%99%A2" title="庆乐大戏院">慶樂戲園</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%89%E5%BA%86%E5%9B%AD" title="三庆园">三慶戲院</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%85%B6%E5%92%8C%E5%9C%92" title="慶和園">慶和園</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%85%A8%E6%99%AF%E5%8A%A8%E6%84%9F%E7%94%B5%E5%BD%B1%E9%99%A2_(%E5%8C%97%E4%BA%AC)" title="全景动感电影院 (北京)">同樂軒</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E8%A7%82%E6%A5%BC%E5%BD%B1%E5%9F%8E" title="大观楼影城">大亨軒</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E4%B9%90%E5%9B%AD%E5%A4%A7%E6%88%8F%E6%A5%BC" title="天乐园大戏楼">天樂茶園→華樂戲園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%A3%95%E8%88%88%E5%9C%92&action=edit&redlink=1" class="new" title="裕興園(页面不存在)">裕興園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A7%E8%88%9E%E8%87%BA_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" class="new" title="大舞臺 (北京)(页面不存在)">大舞臺</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%87%95%E5%96%9C%E5%A0%82&action=edit&redlink=1" class="new" title="燕喜堂(页面不存在)">燕喜堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%95%B7%E5%AE%89%E5%A4%A7%E6%88%B2%E9%99%A2" title="長安大戲院">長安大戲院</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%90%89%E7%A5%A5%E6%88%8F%E9%99%A2" title="吉祥戏院">吉祥戲院</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%96%8B%E6%98%8E%E6%88%B2%E9%99%A2" title="開明戲院">開明戲院</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E5%8D%95%E5%89%A7%E5%9C%BA" title="西单剧场">哈爾飛戲院</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%A6%96%E9%83%BD%E7%94%B5%E5%BD%B1%E9%99%A2" title="首都电影院">新新大戲院</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E6%98%A5%E5%9C%92&action=edit&redlink=1" class="new" title="慶春園(页面不存在)">慶春園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%BB%A3%E8%88%88%E5%9C%92&action=edit&redlink=1" class="new" title="廣興園(页面不存在)">廣興園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%98%A5%E4%BB%99%E5%9C%92&action=edit&redlink=1" class="new" title="春仙園(页面不存在)">春仙園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E9%A0%86%E5%9C%92&action=edit&redlink=1" class="new" title="慶順園(页面不存在)">慶順園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%A5%BF%E5%AE%89%E5%9C%92&action=edit&redlink=1" class="new" title="西安園(页面不存在)">西安園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E6%98%87%E5%9C%92&action=edit&redlink=1" class="new" title="慶昇園(页面不存在)">慶昇園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E5%92%8C%E5%9C%92&action=edit&redlink=1" class="new" title="天和園(页面不存在)">天和園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E5%8C%AF%E5%9C%92&action=edit&redlink=1" class="new" title="天匯園(页面不存在)">天匯園</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%AC%AC%E4%B8%80%E8%88%9E%E5%8F%B0_(%E5%8C%97%E4%BA%AC)" title="第一舞台 (北京)">第一舞臺</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E6%A1%A5%E6%9D%82%E6%8A%80%E5%89%A7%E5%9C%BA" title="天桥杂技剧场">萬盛軒</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%BE%B7%E4%BA%91%E7%A4%BE%E5%89%A7%E5%9C%BA" title="北京德云社剧场">天樂戲院</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%8C%B6%E9%A4%A8" class="mw-redirect" title="茶館"><span style="color:#00008B;">茶館</span></a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E6%BB%99%E8%BB%92&action=edit&redlink=1" class="new" title="天滙軒(页面不存在)">天滙軒</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%BB%99%E8%B1%90%E8%BB%92&action=edit&redlink=1" class="new" title="滙豐軒(页面不存在)">滙豐軒</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%BB%A3%E6%85%B6%E8%BB%92&action=edit&redlink=1" class="new" title="廣慶軒(页面不存在)">廣慶軒</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E5%92%8C%E6%A5%BC" title="广和楼">廣和茶園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%98%9C%E6%88%90%E8%8C%B6%E5%9C%92&action=edit&redlink=1" class="new" title="阜成茶園(页面不存在)">阜成茶園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%9D%B1%E5%92%8C%E9%A0%86&action=edit&redlink=1" class="new" title="東和順(页面不存在)">東和順</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%BE%8D%E6%B5%B7%E8%BB%92&action=edit&redlink=1" class="new" title="龍海軒(页面不存在)">龍海軒</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E7%9B%9B%E8%BB%92&action=edit&redlink=1" class="new" title="慶盛軒(页面不存在)">慶盛軒</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E7%A5%BF%E8%BB%92&action=edit&redlink=1" class="new" title="天祿軒(页面不存在)">天祿軒</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%AC%E8%8F%9C" title="京菜"><span style="color:#00008B;">京菜</span></a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E8%B0%AD%E5%AE%B6%E8%8F%9C" title="谭家菜">谭家菜</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8E%B2%E5%AE%B6%E8%8F%9C&action=edit&redlink=1" class="new" title="厲家菜(页面不存在)">厲家菜</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E7%83%A4%E9%B4%A8" class="mw-redirect" title="北京烤鴨">北京烤鴨</a>(<a href="/wiki/%E5%85%A8%E8%81%9A%E5%BE%B7" title="全聚德">全聚德</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BE%BF%E5%AE%9C%E5%9D%8A" title="便宜坊">便宜坊</a>) ·</span> <span class="nowrap"><a href="/wiki/%E6%B6%AE%E7%BE%8A%E8%82%89" title="涮羊肉">涮羊肉</a>(<a href="/wiki/%E4%B8%9C%E6%9D%A5%E9%A1%BA" title="东来顺">東來順</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8D%97%E4%BE%86%E9%A0%86&action=edit&redlink=1" class="new" title="南來順(页面不存在)">南來順</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8F%88%E4%B8%80%E9%A0%86&action=edit&redlink=1" class="new" title="又一順(页面不存在)">又一順</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%A5%BF%E4%BE%86%E9%A0%86&action=edit&redlink=1" class="new" title="西來順(页面不存在)">西來順</a>) ·</span> <span class="nowrap"><a href="/wiki/%E7%82%99%E5%AD%90%E7%83%A4%E8%82%89" title="炙子烤肉">炙子烤肉</a>(<a href="/wiki/%E7%83%A4%E8%82%89%E5%AD%A3" class="mw-redirect" title="烤肉季">烤肉季</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%83%A4%E8%82%89%E5%AE%9B&action=edit&redlink=1" class="new" title="烤肉宛(页面不存在)">烤肉宛</a>) ·</span> <span class="nowrap"><a href="/wiki/%E7%82%B8%E9%86%AC%E9%BA%B5" title="炸醬麵">炸醬麵</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%8C%E9%94%85%E5%A4%B4" title="二锅头">二鍋頭</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BB%BF%E8%86%B3%E9%A5%AD%E5%BA%84" title="仿膳饭庄">仿膳飯莊</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%8E%9A%E5%BE%B7%E7%A6%8F&action=edit&redlink=1" class="new" title="厚德福(页面不存在)">厚德福</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%9F%B3%E6%B3%89%E5%B1%85" title="柳泉居">柳泉居</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A3%B9%E6%9D%A1%E9%BE%99%E9%A5%AD%E5%BA%84" title="壹条龙饭庄">壹条龍</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%8E%89%E8%8F%AF%E5%8F%B0%E9%A3%AF%E8%8E%8A&action=edit&redlink=1" class="new" title="玉華台飯莊(页面不存在)">玉華台飯莊</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%85%A8%E7%B4%A0%E9%BD%8B&action=edit&redlink=1" class="new" title="全素齋(页面不存在)">全素齋</a>
</span>
</p>
<ul><li class="mw-empty-elt"></li></ul>
<p><span class="nowrap"><a href="/w/index.php?title=%E5%85%AB%E5%A4%A7%E6%A8%93&action=edit&redlink=1" class="new" title="八大樓(页面不存在)">八大樓</a>:<a href="/w/index.php?title=%E6%AD%A3%E9%99%BD%E6%A8%93&action=edit&redlink=1" class="new" title="正陽樓(页面不存在)">正陽樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%9D%B1%E8%88%88%E6%A8%93&action=edit&redlink=1" class="new" title="東興樓(页面不存在)">東興樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%B3%B0%E8%B1%90%E6%A8%93&action=edit&redlink=1" class="new" title="泰豐樓(页面不存在)">泰豐樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%AE%89%E7%A6%8F%E6%A8%93&action=edit&redlink=1" class="new" title="安福樓(页面不存在)">安福樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%87%B4%E7%BE%8E%E6%A8%93&action=edit&redlink=1" class="new" title="致美樓(页面不存在)">致美樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%B4%BB%E8%88%88%E6%A8%93&action=edit&redlink=1" class="new" title="鴻興樓(页面不存在)">鴻興樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%98%A5%E8%8F%AF%E6%A8%93&action=edit&redlink=1" class="new" title="春華樓(页面不存在)">春華樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%96%B0%E8%B1%90%E6%A8%93&action=edit&redlink=1" class="new" title="新豐樓(页面不存在)">新豐樓</a>
</span>
</p>
<ul><li class="mw-empty-elt"></li></ul>
<p><span class="nowrap"><a href="/w/index.php?title=%E5%8D%81%E5%A4%A7%E5%A0%82&action=edit&redlink=1" class="new" title="十大堂(页面不存在)">十大堂</a>:<a href="/w/index.php?title=%E6%83%A0%E8%B1%90%E5%A0%82&action=edit&redlink=1" class="new" title="惠豐堂(页面不存在)">惠豐堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%81%9A%E8%B3%A2%E5%A0%82&action=edit&redlink=1" class="new" title="聚賢堂(页面不存在)">聚賢堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%A6%8F%E5%AF%BF%E5%A0%82_(%E5%8C%97%E4%BA%AC)" title="福寿堂 (北京)">福壽堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A9%E7%A6%8F%E5%A0%82&action=edit&redlink=1" class="new" title="天福堂(页面不存在)">天福堂</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BC%9A%E8%B4%A4%E5%A0%82" title="会贤堂">會賢堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%A6%8F%E6%85%B6%E5%A0%82&action=edit&redlink=1" class="new" title="福慶堂(页面不存在)">福慶堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E5%92%8C%E5%A0%82&action=edit&redlink=1" class="new" title="慶和堂(页面不存在)">慶和堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%90%8C%E5%92%8C%E5%A0%82&action=edit&redlink=1" class="new" title="同和堂(页面不存在)">同和堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%90%8C%E8%88%88%E5%A0%82&action=edit&redlink=1" class="new" title="同興堂(页面不存在)">同興堂</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E8%B1%90%E5%A0%82&action=edit&redlink=1" class="new" title="慶豐堂(页面不存在)">慶豐堂</a>
</span>
</p>
<ul><li class="mw-empty-elt"></li></ul>
<p><span class="nowrap"><a href="/wiki/%E5%85%AB%E5%A4%A7%E5%B1%85" title="八大居">八大居</a>:<a href="/w/index.php?title=%E5%BB%A3%E5%92%8C%E5%B1%85&action=edit&redlink=1" class="new" title="廣和居(页面不存在)">廣和居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%A0%82%E9%8D%8B%E5%B1%85&action=edit&redlink=1" class="new" title="砂鍋居(页面不存在)">砂鍋居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%90%8C%E5%92%8C%E5%B1%85&action=edit&redlink=1" class="new" title="同和居(页面不存在)">同和居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%81%A9%E6%89%BF%E5%B1%85&action=edit&redlink=1" class="new" title="恩承居(页面不存在)">恩承居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%90%AC%E7%A6%8F%E5%B1%85&action=edit&redlink=1" class="new" title="萬福居(页面不存在)">萬福居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%A6%8F%E8%88%88%E5%B1%85&action=edit&redlink=1" class="new" title="福興居(页面不存在)">福興居</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E5%85%B4%E5%B1%85" title="天兴居">天興居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%90%AC%E8%88%88%E5%B1%85&action=edit&redlink=1" class="new" title="萬興居(页面不存在)">萬興居</a>
</span>
</p>
<ul><li class="mw-empty-elt"></li></ul>
<p><span class="nowrap"><a href="/w/index.php?title=%E5%85%AB%E5%A4%A7%E6%98%A5&action=edit&redlink=1" class="new" title="八大春(页面不存在)">八大春</a>:<a href="/w/index.php?title=%E6%96%B9%E5%A3%BA%E6%98%A5&action=edit&redlink=1" class="new" title="方壺春(页面不存在)">方壺春</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%9D%B1%E4%BA%9E%E6%98%A5&action=edit&redlink=1" class="new" title="東亞春(页面不存在)">東亞春</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%85%B6%E6%9E%97%E6%98%A5_(%E9%A3%AF%E8%8E%8A)&action=edit&redlink=1" class="new" title="慶林春 (飯莊)(页面不存在)">慶林春</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%B7%AE%E6%8F%9A%E6%98%A5&action=edit&redlink=1" class="new" title="淮揚春(页面不存在)">淮揚春</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%96%B0%E8%B7%AF%E6%98%A5&action=edit&redlink=1" class="new" title="新路春(页面不存在)">新路春</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A4%A7%E9%99%B8%E6%98%A5&action=edit&redlink=1" class="new" title="大陸春(页面不存在)">大陸春</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%98%A5%E5%9C%92_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" class="new" title="春園 (北京)(页面不存在)">春園</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%90%8C%E6%98%A5%E5%9C%92&action=edit&redlink=1" class="new" title="同春園(页面不存在)">同春園</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B0%8F%E5%90%83" class="mw-redirect" title="北京小吃"><span style="color:#00008B;">小吃</span></a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/w/index.php?title=%E6%8A%A4%E5%9B%BD%E5%AF%BA%E5%B0%8F%E5%90%83&action=edit&redlink=1" class="new" title="护国寺小吃(页面不存在)">护国寺小吃</a>(<a href="/wiki/%E8%B1%86%E6%B1%81" title="豆汁">豆汁</a>、<a href="/wiki/%E7%84%A6%E5%9C%88" title="焦圈">焦圈</a>、<a href="/wiki/%E8%B1%8C%E8%B1%86%E9%BB%84" title="豌豆黄">豌豆黄</a>、<a href="/wiki/%E8%89%BE%E7%AA%9D%E7%AA%9D" title="艾窝窝">艾窝窝</a>、<a href="/wiki/%E9%A9%B4%E6%89%93%E6%BB%9A" title="驴打滚">驴打滚</a>) ·</span> <span class="nowrap"><a href="/wiki/%E8%8C%AF%E8%8B%93%E5%A4%B9%E9%A5%BC" class="mw-redirect" title="茯苓夹饼">茯苓夹饼</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B1%B1%E6%A5%82%E7%B3%95" title="山楂糕">京糕</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A4%A1%E8%A3%A2%E7%81%AB%E7%83%A7" title="褡裢火烧">褡裢火烧</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%82%92%E8%82%9D" title="炒肝">炒肝</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%88%86%E8%82%9A" title="爆肚">爆肚</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%86%B0%E7%B3%96%E8%91%AB%E8%8A%A6" class="mw-redirect" title="冰糖葫芦">冰糖葫芦</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%81%8C%E8%82%A0_(%E5%8C%97%E4%BA%AC%E5%B0%8F%E5%90%83)" title="灌肠 (北京小吃)">煎灌肠</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%82%92%E7%96%99%E7%98%A9&action=edit&redlink=1" class="new" title="炒疙瘩(页面不存在)">炒疙瘩</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%99%BD%E6%B0%B4%E7%BE%8A%E5%A4%B4&action=edit&redlink=1" class="new" title="白水羊头(页面不存在)">白水羊头</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%B3%96%E5%8D%B7%E6%9E%9C&action=edit&redlink=1" class="new" title="糖卷果(页面不存在)">糖卷果</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9D%A2%E8%8C%B6" title="面茶">面茶</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A7%9C%E4%B8%9D%E6%8E%92%E5%8F%89&action=edit&redlink=1" class="new" title="姜丝排叉(页面不存在)">姜丝排叉</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A5%B6%E6%B2%B9%E7%82%B8%E7%B3%95" title="奶油炸糕">奶油炸糕</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%9C%9C%E9%BA%BB%E8%8A%B1" class="mw-redirect" title="蜜麻花">蜜麻花</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%A6%93%E5%AD%90%E9%BA%BB%E8%8A%B1&action=edit&redlink=1" class="new" title="馓子麻花(页面不存在)">馓子麻花</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%96%A9%E5%85%B6%E7%91%AA" class="mw-redirect" title="薩其瑪">萨其玛</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%B3%96%E7%81%AB%E7%83%A7&action=edit&redlink=1" class="new" title="糖火烧(页面不存在)">糖火烧</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%B1%86%E9%A6%85%E7%83%A7%E9%A5%BC&action=edit&redlink=1" class="new" title="豆馅烧饼(页面不存在)">豆馅烧饼</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%82%96%E5%90%8A%E5%AD%90&action=edit&redlink=1" class="new" title="炖吊子(页面不存在)">炖吊子</a><br /><a href="/w/index.php?title=%E9%A4%9B%E9%A3%A9%E4%BE%AF&action=edit&redlink=1" class="new" title="餛飩侯(页面不存在)">餛飩侯</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B0%8F%E8%82%A0%E9%99%88" title="小肠陈">小腸陳</a>(<a href="/wiki/%E5%8D%A4%E7%85%AE%E7%81%AB%E7%83%A7" title="卤煮火烧">卤煮火烧</a>) ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%A5%B6%E9%85%AA%E9%AD%8F&action=edit&redlink=1" class="new" title="奶酪魏(页面不存在)">奶酪魏</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%B9%B4%E7%B3%95%E6%A5%8A&action=edit&redlink=1" class="new" title="年糕楊(页面不存在)">年糕楊</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E5%B9%B4%E7%B3%95%E9%92%B1&action=edit&redlink=1" class="new" title="年糕钱(页面不存在)">年糕钱</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%88%86%E8%82%9A%E9%A6%AE" title="爆肚馮">爆肚馮</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%88%86%E8%82%9A%E6%BB%A1&action=edit&redlink=1" class="new" title="爆肚满(页面不存在)">爆肚满</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%88%86%E8%82%9A%E7%8E%8B&action=edit&redlink=1" class="new" title="爆肚王(页面不存在)">爆肚王</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%BE%8A%E5%A4%B4%E9%A9%AC&action=edit&redlink=1" class="new" title="羊头马(页面不存在)">羊头马</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%B1%86%E8%85%90%E8%85%A6%E7%99%BD&action=edit&redlink=1" class="new" title="豆腐腦白(页面不存在)">豆腐腦白</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%8C%B6%E6%B9%AF%E6%9D%8E&action=edit&redlink=1" class="new" title="茶湯李(页面不存在)">茶湯李</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%97%A8%E9%92%89%E6%9D%8E&action=edit&redlink=1" class="new" title="门钉李(页面不存在)">门钉李</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%91%9E%E5%AE%BE%E6%A5%BC" title="瑞宾楼">瑞賓樓</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%9C%88%E7%9B%9B%E9%BD%8B&action=edit&redlink=1" class="new" title="月盛齋(页面不存在)">月盛齋</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E5%85%B4%E5%B1%85" title="天兴居">天興居</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E9%8C%A6%E9%A6%A8&action=edit&redlink=1" class="new" title="錦馨(页面不存在)">錦馨</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E7%99%BD%E9%AD%81%E8%80%81%E8%99%9F&action=edit&redlink=1" class="new" title="白魁老號(页面不存在)">白魁老號</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E4%B8%8D%E8%80%81%E6%B3%89_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" class="new" title="不老泉 (北京)(页面不存在)">不老泉</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%83%BD%E4%B8%80%E8%99%95" title="都一處">都一處</a>(烧麦) ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E7%A6%8F%E5%8F%B7" title="天福号">天福號</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%85%AD%E5%BF%85%E5%B1%85" title="六必居">六必居</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E6%BA%90%E9%85%B1%E5%9B%AD" title="天源酱园">天源醬園</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%8E%8B%E8%87%B4%E5%92%8C" title="王致和">王致和</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%A1%82%E9%A6%A8%E9%BD%8B&action=edit&redlink=1" class="new" title="桂馨齋(页面不存在)">桂馨齋</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%BA%BB%E9%86%AC%E9%BA%B5" title="麻醬麵">麻醬麵</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">玩物</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E6%BA%9C%E9%B3%A5" class="mw-redirect" title="溜鳥">溜鳥</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%9B%90%E8%9B%90" class="mw-redirect" title="蛐蛐">斗蛐蛐</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%9D%88%E8%9D%88" class="mw-redirect" title="蝈蝈">蟈蟈</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%B8%BD%E5%AD%90" class="mw-redirect" title="鸽子">鴿子</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%87%91%E9%AD%9A" class="mw-redirect" title="金魚">金魚</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%B2%93" class="mw-redirect" title="貓">貓</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%A3%97" class="mw-redirect" title="棗">棗</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%9F%B3%E6%A6%B4" title="石榴">石榴</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%BE%E7%AB%B9%E6%A1%83" title="夾竹桃">夾竹桃</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%9F%BF%E5%AD%90" class="mw-redirect" title="柿子">柿子</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%8F%8A%E8%8A%B1" title="菊花">菊花</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%9B%BD%E6%A7%90" class="mw-redirect" title="国槐">國槐</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B5%B7%E6%A3%A0" title="海棠">海棠</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%AD%E5%9C%8B%E8%B1%A1%E6%A3%8B" class="mw-redirect" title="中國象棋">中國象棋</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%9C%8D%E6%A3%8B" class="mw-redirect" title="圍棋">圍棋</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%89%8C%E4%B9%9D" title="牌九">牌九</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%BA%BB%E5%B0%87" class="mw-redirect" title="麻將">麻將</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B9%9D%E4%B9%9D%E6%B6%88%E5%AF%92%E5%9B%BE" title="九九消寒图">九九消寒圖</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%AA%E6%A5%B5%E6%8B%B3" class="mw-redirect" title="太極拳">太極拳</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%A9%BA%E7%AB%B9" title="空竹">抖空竹</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%AF%BD%E5%AD%90" title="毽子">毽子</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E6%89%8B%E9%83%A8%E5%81%A5%E8%BA%AB%E7%90%83&action=edit&redlink=1" class="new" title="手部健身球(页面不存在)">核桃鐵球</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%87%88%E8%AC%8E" title="燈謎">燈謎</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AF%B9%E8%81%94" title="对联">對聯</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">言語</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A9%B1" class="mw-redirect" title="北京話">北京話</a> ·</span> <span class="nowrap"><a href="/w/index.php?title=%E8%80%81%E5%8C%97%E4%BA%AC%E5%8F%AB%E8%B3%A3&action=edit&redlink=1" class="new" title="老北京叫賣(页面不存在)">老北京叫賣</a>
</span></p>
</div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks hlist collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template talk:中华人民共和国省级行政区"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" class="mw-redirect" title="中華人民共和國行政區劃">一级行政区</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3"><div><a href="/wiki/%E4%B8%AD%E5%9B%BD%E9%A6%96%E9%83%BD" title="中国首都">首都</a>:<a class="mw-selflink selflink">北京市</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;">23 <a href="/wiki/%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B)" class="mw-redirect" title="省 (中華人民共和國)">省</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北省</a></li>
<li><a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">山西省</a></li>
<li><a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">辽宁省</a></li>
<li><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">吉林省</a></li>
<li><a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">黑龙江省</a></li>
<li><a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">江苏省</a></li>
<li><a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">浙江省</a></li>
<li><a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">安徽省</a></li>
<li><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">福建省</a><sup>1</sup></li>
<li><a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">江西省</a></li>
<li><a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">山东省</a></li>
<li><a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">河南省</a></li>
<li><a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">湖北省</a></li>
<li><a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">湖南省</a></li>
<li><a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">广东省</a><sup>1</sup></li>
<li><a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">海南省</a><sup>1</sup> <sup>2</sup></li>
<li><a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">四川省</a></li>
<li><a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">贵州省</a></li>
<li><a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">云南省</a></li>
<li><a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">陕西省</a></li>
<li><a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">甘肃省</a></li>
<li><a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">青海省</a></li>
<li><a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)"><span style="color:grey;">台湾省</span></a><sup>1</sup></li></ul>
</div></td><td class="navbox-image" rowspan="7" style="width:0%;padding:0px 0px 0px 2px"><div><a href="/wiki/File:Flag_of_the_People%27s_Republic_of_China.svg" class="image" title="中国国旗"><img alt="中国国旗" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/100px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="100" height="67" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/150px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/200px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;">5 <a href="/wiki/%E8%87%AA%E6%B2%BB%E5%8C%BA" title="自治区">自治区</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">内蒙古自治区</a></li>
<li><a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">广西壮族自治区</a></li>
<li><a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">西藏自治区</a><sup>3</sup></li>
<li><a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">宁夏回族自治区</a></li>
<li><a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">新疆维吾尔自治区</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;">4 <a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">直辖市</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a></li>
<li><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;"><span class="nowrap">2 <a href="/wiki/%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" title="特别行政区">特别行政区</a></span></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/File:Flag_of_Hong_Kong.svg" class="image"><img alt="Flag of Hong Kong.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5b/Flag_of_Hong_Kong.svg/25px-Flag_of_Hong_Kong.svg.png" decoding="async" width="25" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5b/Flag_of_Hong_Kong.svg/38px-Flag_of_Hong_Kong.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5b/Flag_of_Hong_Kong.svg/50px-Flag_of_Hong_Kong.svg.png 2x" data-file-width="900" data-file-height="600" /></a> <a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港特别行政区</a></li>
<li><a href="/wiki/File:Flag_of_Macau.svg" class="image"><img alt="Flag of Macau.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/63/Flag_of_Macau.svg/25px-Flag_of_Macau.svg.png" decoding="async" width="25" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/63/Flag_of_Macau.svg/38px-Flag_of_Macau.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/63/Flag_of_Macau.svg/50px-Flag_of_Macau.svg.png 2x" data-file-width="512" data-file-height="341" /></a> <a href="/wiki/%E6%BE%B3%E9%96%80" title="澳門">澳门特别行政区</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3" style="text-align: left; font-size: 90%;"><div>注1:<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">台湾省</a>絕大部分(钓鱼岛及其附属岛屿除外),<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">福建省</a>的<a href="/wiki/%E9%87%91%E9%96%80%E7%BE%A4%E5%B3%B6" class="mw-redirect" title="金門群島">金門</a>、<a href="/wiki/%E9%A6%AC%E7%A5%96%E5%88%97%E5%B3%B6" title="馬祖列島">馬祖</a>、<a href="/wiki/%E7%83%8F%E5%9D%B5%E9%84%89" title="烏坵鄉">烏坵</a>,<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">广东省</a>的<a href="/wiki/%E6%9D%B1%E6%B2%99%E7%BE%A4%E5%B3%B6" title="東沙群島">東沙</a>和<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">海南省</a><a href="/wiki/%E5%8D%97%E6%B2%99%E7%BE%A4%E5%B3%B6" class="mw-redirect" title="南沙群島">南沙群島</a>的<a href="/wiki/%E5%A4%AA%E5%B9%B3%E5%B3%B6" title="太平島">太平島</a>與<a href="/wiki/%E4%B8%AD%E6%B4%B2%E7%A4%81" title="中洲礁">中洲礁</a>现由<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a>实际控制。<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">台湾省</a>的<a href="/wiki/%E9%87%A3%E9%AD%9A%E8%87%BA%E5%88%97%E5%B6%BC" title="釣魚臺列嶼">钓鱼岛及其附属岛屿</a>现由<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">日本</a>实际控制。參阅<a href="/wiki/%E5%8F%B0%E6%B5%B7%E7%8F%BE%E7%8B%80" class="mw-redirect" title="台海現狀">台海現狀</a>、<a href="/wiki/%E5%85%A9%E5%B2%B8%E5%95%8F%E9%A1%8C" class="mw-redirect" title="兩岸問題">兩岸問題</a>和<a href="/wiki/%E9%92%93%E9%B1%BC%E5%B2%9B%E5%8F%8A%E5%85%B6%E9%99%84%E5%B1%9E%E5%B2%9B%E5%B1%BF%E4%B8%BB%E6%9D%83%E9%97%AE%E9%A2%98" class="mw-redirect" title="钓鱼岛及其附属岛屿主权问题">钓鱼岛及其附属岛屿主权问题</a>。
<p>注2:<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">海南省</a>部分区域现由<a href="/wiki/%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD" class="mw-redirect" title="中华民国">中华民国</a>、<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">越南</a>、<a href="/wiki/%E8%8F%B2%E5%BE%8B%E5%AE%BE" title="菲律宾">菲律宾</a>和<a href="/wiki/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A" title="马来西亚">马来西亚</a>实际控制,參阅<a href="/wiki/%E5%8D%97%E6%B5%B7%E8%AF%B8%E5%B2%9B" title="南海诸岛">南海诸岛</a>。
</p><p>注3:<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">西藏自治区</a>部分区域现由<a href="/wiki/%E5%8D%B0%E5%BA%A6" title="印度">印度</a>、<a href="/wiki/%E4%B8%8D%E4%B8%B9" title="不丹">不丹</a>实际控制,參阅<a href="/wiki/%E4%B8%AD%E5%8D%B0%E8%BE%B9%E7%95%8C%E9%97%AE%E9%A2%98" title="中印边界问题">中印边界问题</a>、<a href="/wiki/%E4%B8%AD%E4%B8%8D%E8%BE%B9%E7%95%8C%E4%BA%89%E8%AE%AE" title="中不边界争议">中不边界争议</a>。
</p>
参阅:<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">中华人民共和国行政区划</a>、<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">省级以上行政区变动</a>、<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区">副省级行政区</a>、<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">县级以上行政区列表</a>。<br /><hr /><div class="center"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">区划</a>索引:<a href="/wiki/Template:Division_levels_of_China" title="Template:Division levels of China">单位</a><small>(<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81" title="中华人民共和国行政区划代码">代码</a>)</small>:<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">省级</a><small>(<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">史</a>)</small>><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区"><i>副省级</i></a>><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">地级</a>><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">县级</a>:<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">京</a>|<a href="/wiki/Template:%E5%A4%A9%E6%B4%A5%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:天津行政区划">津</a>|<a href="/wiki/Template:%E6%B2%B3%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河北行政区划">冀</a>|<a href="/wiki/Template:%E5%B1%B1%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山西行政区划">晋</a>|<a href="/wiki/Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:内蒙古行政区划">蒙</a>|<a href="/wiki/Template:%E8%BE%BD%E5%AE%81%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:辽宁行政区划">辽</a>|<a href="/wiki/Template:%E5%90%89%E6%9E%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:吉林行政区划">吉</a>|<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:黑龙江行政区划">黑</a>|<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:上海行政区划">沪</a>|<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江苏行政区划">苏</a>|<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:浙江行政区划">浙</a>|<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:安徽行政区划">皖</a>|<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:福建行政区划">闽</a>|<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江西行政区划">赣</a>|<a href="/wiki/Template:%E5%B1%B1%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山东行政区划">鲁</a>|<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河南行政区划">豫</a>|<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖北行政区划">鄂</a>|<a href="/wiki/Template:%E6%B9%96%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖南行政区划">湘</a>|<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广东行政区划">粤</a>|<a href="/wiki/Template:%E5%B9%BF%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广西行政区划">桂</a>|<a href="/wiki/Template:%E6%B5%B7%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:海南行政区划">琼</a>|<a href="/wiki/Template:%E9%87%8D%E5%BA%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:重庆行政区划">渝</a>|<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:四川行政区划">川</a>|<a href="/wiki/Template:%E8%B4%B5%E5%B7%9E%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:贵州行政区划">贵</a>|<a href="/wiki/Template:%E4%BA%91%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:云南行政区划">云</a>|<a href="/wiki/Template:%E8%A5%BF%E8%97%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:西藏行政区划">藏</a>|<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:陕西行政区划">陕</a>|<a href="/wiki/Template:%E7%94%98%E8%82%83%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:甘肃行政区划">甘</a>|<a href="/wiki/Template:%E9%9D%92%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:青海行政区划">青</a>|<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:宁夏行政区划">宁</a>|<a href="/wiki/Template:%E6%96%B0%E7%96%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:新疆行政区划">新</a>|<a href="/wiki/Template:%E9%A6%99%E6%B8%AF%E5%8D%81%E5%85%AB%E5%8D%80" title="Template:香港十八區">港</a>|<a href="/wiki/Template:%E6%BE%B3%E9%96%80%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="Template:澳門行政區劃">澳</a>|<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">台</a></div></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template talk:北京行政区划"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a class="mw-selflink selflink">北京市</a><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="北京市行政區劃">行政区划</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3"><div>国别:<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a> <a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">市政府</a>所在地:<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">通州区</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;;background: #ececec;"><a href="/wiki/%E5%8E%BF%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="县级行政区">县级行政区</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;background: #ececec; text-align: center;"><div style="padding:0em 0.25em">16<a href="/wiki/%E5%B8%82%E8%BE%96%E5%8C%BA" title="市辖区">市辖区</a></div></td><td class="navbox-image" rowspan="3" style="width:0%;padding:0px 0px 0px 2px"><div><a href="/wiki/File:China_Beijing.svg" class="image"><img alt="China Beijing.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/80px-China_Beijing.svg.png" decoding="async" width="80" height="68" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/120px-China_Beijing.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/160px-China_Beijing.svg.png 2x" data-file-width="1000" data-file-height="850" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;"><a href="/wiki/%E5%B8%82%E8%BE%96%E5%8C%BA" title="市辖区">市辖区</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">东城区</a> · <span class="nowrap"><a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">西城区</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" class="mw-redirect" title="朝阳区 (北京市)">朝阳区</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">丰台区</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">石景山区</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">海淀区</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">门头沟区</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">房山区</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">大兴区</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">通州区</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">顺义区</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">昌平区</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">怀柔区</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">平谷区</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">密云区</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">延庆区</a></span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3" style="text-align: left; font-size: 80%;"><div>参见:<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">中华人民共和国县级以上行政区列表</a>、<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%B9%A1%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="北京市乡级以上行政区列表">北京市乡级以上行政区列表</a>、<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E5%B7%B2%E6%92%A4%E9%94%80%E5%8E%BF%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国北京市已撤销县级行政区">北京市已撤销县级行政区</a>。<br /><hr /><div class="center"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">区划</a>索引:<a href="/wiki/Template:Division_levels_of_China" title="Template:Division levels of China">单位</a><small>(<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81" title="中华人民共和国行政区划代码">代码</a>)</small>:<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">省级</a><small>(<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">史</a>)</small>><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区"><i>副省级</i></a>><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">地级</a>><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">县级</a>:<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">京</a>|<a href="/wiki/Template:%E5%A4%A9%E6%B4%A5%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:天津行政区划">津</a>|<a href="/wiki/Template:%E6%B2%B3%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河北行政区划">冀</a>|<a href="/wiki/Template:%E5%B1%B1%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山西行政区划">晋</a>|<a href="/wiki/Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:内蒙古行政区划">蒙</a>|<a href="/wiki/Template:%E8%BE%BD%E5%AE%81%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:辽宁行政区划">辽</a>|<a href="/wiki/Template:%E5%90%89%E6%9E%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:吉林行政区划">吉</a>|<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:黑龙江行政区划">黑</a>|<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:上海行政区划">沪</a>|<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江苏行政区划">苏</a>|<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:浙江行政区划">浙</a>|<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:安徽行政区划">皖</a>|<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:福建行政区划">闽</a>|<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江西行政区划">赣</a>|<a href="/wiki/Template:%E5%B1%B1%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山东行政区划">鲁</a>|<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河南行政区划">豫</a>|<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖北行政区划">鄂</a>|<a href="/wiki/Template:%E6%B9%96%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖南行政区划">湘</a>|<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广东行政区划">粤</a>|<a href="/wiki/Template:%E5%B9%BF%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广西行政区划">桂</a>|<a href="/wiki/Template:%E6%B5%B7%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:海南行政区划">琼</a>|<a href="/wiki/Template:%E9%87%8D%E5%BA%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:重庆行政区划">渝</a>|<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:四川行政区划">川</a>|<a href="/wiki/Template:%E8%B4%B5%E5%B7%9E%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:贵州行政区划">贵</a>|<a href="/wiki/Template:%E4%BA%91%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:云南行政区划">云</a>|<a href="/wiki/Template:%E8%A5%BF%E8%97%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:西藏行政区划">藏</a>|<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:陕西行政区划">陕</a>|<a href="/wiki/Template:%E7%94%98%E8%82%83%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:甘肃行政区划">甘</a>|<a href="/wiki/Template:%E9%9D%92%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:青海行政区划">青</a>|<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:宁夏行政区划">宁</a>|<a href="/wiki/Template:%E6%96%B0%E7%96%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:新疆行政区划">新</a>|<a href="/wiki/Template:%E9%A6%99%E6%B8%AF%E5%8D%81%E5%85%AB%E5%8D%80" title="Template:香港十八區">港</a>|<a href="/wiki/Template:%E6%BE%B3%E9%96%80%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="Template:澳門行政區劃">澳</a>|<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">台</a></div></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><span style="float:left;width:8em;font-size:80%;margin-right:0.5em"> </span><div style="font-size:110%"><a href="/wiki/%E4%B8%AD%E5%9B%BD" class="mw-redirect" title="中国">中国</a><a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%9C%9D%E4%BB%A3" title="中国朝代">历代</a><a href="/wiki/%E4%B8%AD%E5%9B%BD%E9%A6%96%E9%83%BD" title="中国首都">都城</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div><a href="/wiki/%E4%B8%AD%E5%9B%BD%E9%A6%96%E9%83%BD" title="中国首都">中国首都</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">古都<br />并称</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group">两都</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;"><div style="padding:0em 0.25em"><a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">长安</a> · <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a></span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">四大</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">长安</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">汴</a> ·</span> <span class="nowrap"><a class="mw-selflink selflink">燕</a>(明代,陈建)<br /><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">关中</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">建康</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">开封</a>(明末,顾炎武)<br /><a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">长安</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">金陵</a> ·</span> <span class="nowrap"><a class="mw-selflink selflink">燕都</a>(民国,朱偰)
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">五大</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">长安</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B1%B4%E4%BA%AC" class="mw-redirect" title="汴京">汴京</a> ·</span> <span class="nowrap"><a class="mw-selflink selflink">燕都</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">金陵</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">七大</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京</a> ·</span> <span class="nowrap"><a class="mw-selflink selflink">北京</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">开封</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">安阳</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group">十大</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京</a> ·</span> <span class="nowrap"><a class="mw-selflink selflink">北京</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">开封</a><br /><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">安阳</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">大同</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%85%88%E7%A7%A6" title="先秦">先秦</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%89%E7%9A%87%E4%BA%94%E5%B8%9D#五帝" title="三皇五帝">五帝</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">黃帝都有熊(疑為<a href="/wiki/%E8%A5%BF%E5%9D%A1%E9%81%97%E5%9D%80" title="西坡遗址">西坡遗址</a>) · <span class="nowrap">堯都平陽(疑為<a href="/wiki/%E9%99%B6%E5%AF%BA%E9%81%BA%E5%9D%80" title="陶寺遺址">陶寺遺址</a>)</span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%A4%8F%E6%9C%9D" title="夏朝">夏</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">(僅列出重要的)禹都<a href="/wiki/%E9%98%B3%E5%9F%8E%E5%8E%BF" title="阳城县">陽城</a>(疑為<a href="/wiki/%E7%8E%8B%E5%9F%8E%E5%B2%97%E5%8F%8A%E9%98%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="王城岗及阳城遗址">王城崗遺址</a>) · <span class="nowrap"><a href="/wiki/%E6%96%9F%E9%84%A9" title="斟鄩">斟鄩</a>(疑為<a href="/wiki/%E4%BA%8C%E9%87%8C%E5%A4%B4%E9%81%97%E5%9D%80" title="二里头遗址">二里头遗址</a>)</span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%95%86%E6%9C%9D" title="商朝">商</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E4%BA%B3" title="亳">亳</a><small><a href="/wiki/%E9%83%91%E5%B7%9E%E5%95%86%E5%9F%8E%E9%81%97%E5%9D%80" title="郑州商城遗址">[遗址]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E9%9A%9E" title="隞">隞(嚣)</a><small><a href="/wiki/%E5%B0%8F%E5%8F%8C%E6%A1%A5%E9%81%97%E5%9D%80" title="小双桥遗址">[遗址]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E7%9B%B8_(%E5%95%86%E6%9C%9D)" class="mw-redirect" title="相 (商朝)">相</a></span> <span class="nowrap">→ <a href="/wiki/%E5%BA%87" title="庇">庇</a></span> <span class="nowrap">→ <a href="/wiki/%E5%BA%87" title="庇">邢</a></span> <span class="nowrap">→ <a href="/wiki/%E5%95%86%E5%A5%84" title="商奄">奄</a></span> <span class="nowrap"><a href="/wiki/%E7%9B%98%E5%BA%9A%E8%BF%81%E6%AE%B7" title="盘庚迁殷">→</a> <a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">殷</a><small><a href="/wiki/%E6%AE%B7%E5%A2%9F" title="殷墟">[遗址]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E6%9C%9D%E6%AD%8C" title="朝歌">朝歌</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%91%A8%E6%9C%9D" title="周朝">周</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%B2%90%E9%82%91" class="mw-redirect" title="岐邑">岐邑</a></span> <span class="nowrap">→ <a href="/wiki/%E4%B8%B0%E4%BA%AC" class="mw-redirect" title="丰京">丰京</a></span> <span class="nowrap">→ <a href="/wiki/%E9%8E%AC%E4%BA%AC" title="鎬京">鎬京</a></span> <span class="nowrap"><a href="/wiki/%E5%B9%B3%E7%8E%8B%E4%B8%9C%E8%BF%81" title="平王东迁">→</a> <a href="/wiki/%E9%9B%92%E9%82%91" title="雒邑">雒邑</a>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E7%A7%A6%E6%9C%9D" title="秦朝">秦</a><br /><a href="/wiki/%E6%B1%89%E6%9C%9D" title="汉朝">汉</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E7%A7%A6%E6%9C%9D" title="秦朝">秦朝</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%92%B8%E9%99%BD%E7%B8%A3" title="咸陽縣">咸阳</a><small><a href="/wiki/%E5%92%B8%E9%98%B3%E5%9F%8E" class="mw-redirect" title="咸阳城">[遗址]</a></small></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B1%89%E6%9C%9D" title="汉朝">汉朝</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><sup><a href="/wiki/%E8%A5%BF%E6%B1%89" title="西汉">西汉</a>→<a href="/wiki/%E6%96%B0%E6%9C%9D" title="新朝">新朝</a></sup><a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">长安</a></span> <span class="nowrap">→ <sup><a href="/wiki/%E4%B8%9C%E6%B1%89" title="东汉">东汉</a></sup><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">雒陽</a><small><a href="/wiki/%E6%B1%89%E9%AD%8F%E6%B4%9B%E9%98%B3%E6%95%85%E5%9F%8E" title="汉魏洛阳故城">[遗址]</a></small></span> <span class="nowrap">→ <sup><a href="/wiki/%E6%B1%89%E7%8C%AE%E5%B8%9D" title="汉献帝">东汉献帝</a></sup><a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">长安</a></span> <span class="nowrap">→ <sup><a href="/wiki/%E6%B1%89%E7%8C%AE%E5%B8%9D" title="汉献帝">东汉献帝</a></sup><a href="/wiki/%E8%AE%B8%E6%98%8C%E5%B8%82" title="许昌市">许都</a><small><a href="/wiki/%E6%B1%89%E9%AD%8F%E8%AE%B8%E9%83%BD%E6%95%85%E5%9F%8E" title="汉魏许都故城">[遗址]</a></small>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%89%E5%9B%BD" title="三国">三国</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%9B%B9%E9%AD%8F%E4%BA%94%E9%83%BD" title="曹魏五都">曹魏五都</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><sup>长安</sup><small><a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">遗址</a></small> ·</span> <span class="nowrap"><sup><a href="/wiki/%E8%B0%AF%E9%83%A1" title="谯郡">谯都</a></sup> ·</span> <span class="nowrap"><sup>许都</sup><small><a href="/wiki/%E6%B1%89%E9%AD%8F%E8%AE%B8%E9%83%BD%E6%95%85%E5%9F%8E" title="汉魏许都故城">遗址</a></small> ·</span> <span class="nowrap"><sup>邺都</sup><small><a href="/wiki/%E9%82%BA%E5%9F%8E%E9%81%97%E5%9D%80" title="邺城遗址">遗址</a></small> ·</span> <span class="nowrap"><sup>洛阳</sup><small><a href="/wiki/%E6%B1%89%E9%AD%8F%E6%B4%9B%E9%98%B3%E6%95%85%E5%9F%8E" title="汉魏洛阳故城">遗址</a></small>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%97%E5%8C%97%E6%9C%9D" title="南北朝">南<br />北<br />朝</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%97%E5%8C%97%E6%9C%9D" title="南北朝">南朝</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><sup><a href="/wiki/%E5%88%98%E5%AE%8B" title="刘宋">宋</a>→<a href="/wiki/%E5%8D%97%E9%BD%90" title="南齐">齐</a>→<a href="/wiki/%E6%A2%81_(%E5%8D%97%E6%9C%9D)" title="梁 (南朝)">梁</a>→<a href="/wiki/%E9%99%88_(%E5%8D%97%E6%9C%9D)" class="mw-redirect" title="陈 (南朝)">陈</a></sup><a href="/wiki/%E5%85%AD%E6%9C%9D%E5%BB%BA%E5%BA%B7%E9%83%BD%E5%9F%8E%E9%81%97%E5%9D%80" title="六朝建康都城遗址">建康</a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%97%E5%8C%97%E6%9C%9D" title="南北朝">北朝</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<span class="nowrap"><a href="/wiki/%E7%9B%9B%E6%A8%82" title="盛樂">盛樂</a></span> <span class="nowrap">→ <a href="/wiki/%E5%B9%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="平城遗址">平城</a><small><a href="/wiki/%E5%B9%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="平城遗址">[遗址]</a></small></span><small> <span class="nowrap">→ </span></small><sup><a href="/wiki/%E5%8C%97%E9%AD%8F" title="北魏">北魏</a></sup><a href="/wiki/%E6%B1%89%E9%AD%8F%E6%B4%9B%E9%98%B3%E6%95%85%E5%9F%8E" title="汉魏洛阳故城">洛阳</a> · <span class="nowrap"><sup><a href="/wiki/%E4%B8%9C%E9%AD%8F" title="东魏">东魏</a></sup><a href="/wiki/%E9%82%BA%E5%9F%8E%E9%81%97%E5%9D%80" title="邺城遗址">邺</a> ·</span> <span class="nowrap"><sup><a href="/wiki/%E8%A5%BF%E9%AD%8F" title="西魏">西魏</a></sup><a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">长安</a> ·</span> <span class="nowrap"><sup><a href="/wiki/%E5%8C%97%E9%BD%90" title="北齐">北齐</a></sup><a href="/wiki/%E9%82%BA%E5%9F%8E%E9%81%97%E5%9D%80" title="邺城遗址">邺</a> ·</span> <span class="nowrap"><sup><a href="/wiki/%E5%8C%97%E5%91%A8" title="北周">北周</a></sup><a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">长安</a></span></div></td></tr></tbody></table><div>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E9%9A%8B%E6%9C%9D" title="隋朝">隋</a><br /><a href="/wiki/%E5%94%90%E6%9C%9D" title="唐朝">唐</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E8%A1%8C%E6%94%BF%E4%B8%AD%E5%BF%83" title="行政中心">统治中心</a>:<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">长安</a></span> <span class="nowrap">→ <a href="/wiki/%E5%94%90%E9%95%BF%E5%AE%89%E5%9F%8E" title="唐长安城">大兴→长安</a>(<a href="/wiki/%E8%83%A1%E5%A7%86%E4%B8%B9" title="胡姆丹">胡姆丹</a>)</span> <span class="nowrap">→ <sup><a href="/wiki/%E6%AD%A6%E5%91%A8" title="武周">武周</a></sup><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">神都</a></span> <span class="nowrap">→ <a href="/wiki/%E5%94%90%E9%95%BF%E5%AE%89%E5%9F%8E" title="唐长安城">长安</a></span> <span class="nowrap">→ <a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a></span> <span class="nowrap">→ <a href="/wiki/%E5%94%90%E9%95%BF%E5%AE%89%E5%9F%8E" title="唐长安城">长安</a></span> <span class="nowrap">→ <a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a><small><a href="/wiki/%E9%9A%8B%E5%94%90%E6%B4%9B%E9%98%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="隋唐洛阳城遗址">[遗址]</a></small>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%94%E4%BA%AC%E5%88%B6" title="五京制">五<br />京<br />制</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%94%90%E6%9C%9D" title="唐朝">唐</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">北京<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%BA%9C" title="太原府">太原府</a><small><a href="/wiki/%E6%99%8B%E9%98%B3%E5%8F%A4%E5%9F%8E%E9%81%97%E5%9D%80" title="晋阳古城遗址">[遗址]</a></small> ·</span> <span class="nowrap">东京<a href="/wiki/%E6%B2%B3%E5%8D%97%E5%BA%9C" title="河南府">河南府</a> ·</span> <span class="nowrap">中京<a href="/wiki/%E4%BA%AC%E5%85%86%E5%BA%9C" title="京兆府">京兆府</a> ·</span> <span class="nowrap">南京<a href="/wiki/%E6%88%90%E9%83%BD%E5%BA%9C" title="成都府">成都府</a> ·</span> <span class="nowrap">西京<a href="/wiki/%E9%B3%B3%E7%BF%94%E5%BA%9C" title="鳳翔府">鳳翔府</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B8%A4%E6%B5%B7%E5%9B%BD" title="渤海国">渤<br />海</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">上京<a href="/wiki/%E9%BE%99%E6%B3%89%E5%BA%9C" title="龙泉府">龙泉府</a><small><a href="/wiki/%E6%B8%A4%E6%B5%B7%E5%9B%BD%E4%B8%8A%E4%BA%AC%E9%BE%99%E6%B3%89%E5%BA%9C%E9%81%97%E5%9D%80" title="渤海国上京龙泉府遗址">[遗址]</a></small> ·</span> <span class="nowrap">东京<a href="/wiki/%E9%BE%99%E5%8E%9F%E5%BA%9C" title="龙原府">龙原府</a> ·</span> <span class="nowrap">中京<a href="/wiki/%E6%98%BE%E5%BE%B7%E5%BA%9C" title="显德府">显德府</a><small><a href="/wiki/%E6%B8%A4%E6%B5%B7%E4%B8%AD%E4%BA%AC%E5%9F%8E%E9%81%97%E5%9D%80" title="渤海中京城遗址">[遗址]</a></small> ·</span> <span class="nowrap">南京<a href="/wiki/%E5%8D%97%E6%B5%B7%E5%BA%9C" title="南海府">南海府</a> ·</span> <span class="nowrap">西京<a href="/wiki/%E9%B8%AD%E6%B8%8C%E5%BA%9C" title="鸭渌府">鸭绿府</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">辽</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">上京<a href="/wiki/%E4%B8%8A%E4%BA%AC%E4%B8%B4%E6%BD%A2%E5%BA%9C" title="上京临潢府">临潢府</a><small><a href="/wiki/%E8%BE%BD%E4%B8%8A%E4%BA%AC%E9%81%97%E5%9D%80" title="辽上京遗址">[遗址]</a></small> ·</span> <span class="nowrap">东京<a href="/wiki/%E8%BE%BD%E9%98%B3%E5%BA%9C" title="辽阳府">辽阳府</a> ·</span> <span class="nowrap">中京<a href="/wiki/%E5%A4%A7%E5%AE%9A%E5%BA%9C_(%E8%BE%BD%E6%9C%9D)" title="大定府 (辽朝)">大定府</a><small><a href="/wiki/%E8%BE%BD%E4%B8%AD%E4%BA%AC%E9%81%97%E5%9D%80" title="辽中京遗址">[遗址]</a></small> ·</span> <span class="nowrap"><a href="/wiki/%E8%BE%BD%E5%8D%97%E4%BA%AC" title="辽南京">南京析津府</a> ·</span> <span class="nowrap">西京<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%BA%9C" title="大同府">大同府</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">金</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">上京<a href="/wiki/%E6%9C%83%E5%AF%A7%E5%BA%9C" title="會寧府">会宁府</a><small><a href="/wiki/%E9%87%91%E4%B8%8A%E4%BA%AC%E4%BC%9A%E5%AE%81%E5%BA%9C%E9%81%97%E5%9D%80" title="金上京会宁府遗址">[遗址]</a></small> ·</span> <span class="nowrap"><a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">中都</a><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%BA%9C" title="大兴府">大兴府</a> ·</span> <span class="nowrap">南京→东京<a href="/wiki/%E8%BE%BD%E9%98%B3%E5%BA%9C" title="辽阳府">辽阳府</a> ·</span> <span class="nowrap">西京<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%BA%9C" title="大同府">大同府</a> ·</span> <span class="nowrap">北京<a href="/wiki/%E4%B8%B4%E6%BD%A2%E5%BA%9C" class="mw-redirect" title="临潢府">临潢府</a>→<a href="/wiki/%E5%A4%A7%E5%AE%9A%E5%BA%9C_(%E8%BE%BD%E6%9C%9D)" title="大定府 (辽朝)">大定府</a> ·</span> <span class="nowrap">南京<a href="/wiki/%E5%BC%80%E5%B0%81%E5%BA%9C" title="开封府">开封府</a>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%94%E4%BB%A3%E5%8D%81%E5%9B%BD" title="五代十国">五代<br />十国</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%94%E4%BB%A3%E5%8D%81%E5%9B%BD" title="五代十国">五代</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><sup><a href="/wiki/%E5%BE%8C%E6%A2%81" class="mw-redirect" title="後梁">後梁</a></sup><a href="/wiki/%E9%96%8B%E5%B0%81%E5%BA%9C" class="mw-redirect" title="開封府">開封府</a></span> <span class="nowrap">→ <sup><a href="/wiki/%E5%BE%8C%E5%94%90" class="mw-redirect" title="後唐">後唐</a></sup><a href="/wiki/%E6%B4%9B%E9%99%BD" class="mw-redirect" title="洛陽">洛陽</a></span> <span class="nowrap">→ <sup><a href="/wiki/%E5%90%8E%E6%99%8B" title="后晋">后晋</a>→<a href="/wiki/%E5%BE%8C%E6%BC%A2" title="後漢">後漢</a>→<a href="/wiki/%E5%BE%8C%E5%91%A8" class="mw-redirect" title="後周">後周</a></sup><a href="/wiki/%E9%96%8B%E5%B0%81%E5%BA%9C" class="mw-redirect" title="開封府">開封府</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%94%E4%BB%A3%E5%8D%81%E5%9B%BD" title="五代十国">十国</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><sup><a href="/wiki/%E5%8D%97%E5%94%90" title="南唐">南唐</a></sup><a href="/wiki/%E6%B1%9F%E5%AE%81%E5%BA%9C" title="江宁府">江宁府</a><small><a href="/wiki/%E9%87%91%E9%99%B5%E5%9F%8E" title="金陵城">[遗址]</a></small></span> <span class="nowrap">→ 南都<a href="/wiki/%E5%8D%97%E6%98%8C%E5%BA%9C" title="南昌府">南昌府</a> ·</span> <span class="nowrap"><sup><a href="/wiki/%E5%8C%97%E6%B1%89" title="北汉">北汉</a></sup><a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%BA%9C" title="太原府">太原府</a><small><a href="/wiki/%E6%99%8B%E9%98%B3%E5%8F%A4%E5%9F%8E%E9%81%97%E5%9D%80" title="晋阳古城遗址">[遗址]</a></small>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%A5%BF%E5%A4%8F" title="西夏">西夏</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">东京<a href="/wiki/%E5%85%B4%E5%BA%86%E5%BA%9C" title="兴庆府">兴庆府→中兴府</a> ·</span> <span class="nowrap">西京<a href="/wiki/%E8%A5%BF%E5%B9%B3%E5%BA%9C" title="西平府">西平府</a> ·</span> <span class="nowrap">辅郡<a href="/wiki/%E8%A5%BF%E5%87%89%E5%BA%9C" title="西凉府">西凉府</a>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%AE%8B%E6%9C%9D" title="宋朝">宋</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap">东京<a href="/wiki/%E5%BC%80%E5%B0%81%E5%BA%9C" title="开封府">开封府</a>(<a href="/wiki/%E6%B1%B4%E6%A2%81" title="汴梁">汴梁</a>)<small><a href="/wiki/%E5%8C%97%E5%AE%8B%E4%B8%9C%E4%BA%AC%E5%9F%8E%E9%81%97%E5%9D%80" title="北宋东京城遗址">[遗址]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">行在</a><a href="/wiki/%E4%B8%B4%E5%AE%89%E5%BA%9C_(%E6%B5%99%E6%B1%9F)" title="临安府 (浙江)">临安府</a><small><a href="/wiki/%E4%B8%B4%E5%AE%89%E5%9F%8E%E9%81%97%E5%9D%80" title="临安城遗址">[遗址]</a></small>、<a href="/wiki/%E8%A1%8C%E9%83%BD" class="mw-redirect" title="行都">行都</a><a href="/wiki/%E5%BB%BA%E5%BA%B7%E5%BA%9C" title="建康府">建康府</a> ·</span> <span class="nowrap">西京<a href="/wiki/%E6%B2%B3%E5%8D%97%E5%BA%9C" title="河南府">河南府</a> ·</span> <span class="nowrap">南京<a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E5%AE%8B%E6%9C%9D)" title="应天府 (宋朝)">应天府</a> ·</span> <span class="nowrap">北京<a href="/wiki/%E5%A4%A7%E5%90%8D%E5%BA%9C" title="大名府">大名府</a><small><a href="/wiki/%E5%A4%A7%E5%90%8D%E5%BA%9C%E6%95%85%E5%9F%8E" title="大名府故城">[遗址]</a></small>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%85%83%E6%9C%9D" title="元朝">元</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E8%92%99%E5%8F%A4%E5%B8%9D%E5%9B%BD" title="蒙古帝国"><b>大蒙古国</b></a>:<a href="/wiki/%E6%9B%B2%E9%9B%95%E9%98%BF%E5%85%B0" title="曲雕阿兰">曲雕阿兰</a></span> <span class="nowrap">→ <a href="/wiki/%E5%93%88%E6%8B%89%E5%92%8C%E6%9E%97" title="哈拉和林">哈拉和林</a></span> <span class="nowrap">→ 上都<small><a href="/wiki/%E5%85%83%E4%B8%8A%E9%83%BD" title="元上都">[遗址]</a></small><br /><a href="/wiki/%E5%A4%A7%E9%83%BD%E8%B7%AF" title="大都路">大都路</a><small><a href="/wiki/%E5%85%83%E5%A4%A7%E9%83%BD" title="元大都">大都(汗八里)</a></small> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%8A%E9%83%BD%E8%B7%AF" title="上都路">上都路</a><small><a href="/wiki/%E5%85%83%E4%B8%8A%E9%83%BD" title="元上都">[遗址]</a>(陪都)</small><br /><b><a href="/wiki/%E5%8C%97%E5%85%83" title="北元">北元</a></b>:上都<small><a href="/wiki/%E5%85%83%E4%B8%8A%E9%83%BD" title="元上都">[遗址]</a></small></span> <span class="nowrap">→ 应昌城<small><a href="/wiki/%E6%87%89%E6%98%8C%E5%9F%8E" title="應昌城">[遗址]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E5%93%88%E6%8B%89%E5%92%8C%E6%9E%97" title="哈拉和林">哈拉和林</a>
<br /><a href="/wiki/%E5%AF%9F%E5%93%88%E5%B0%94%E9%83%A8" title="察哈尔部">察哈尔部</a><a href="/wiki/%E6%9E%97%E4%B8%B9%E6%B1%97" title="林丹汗">林丹汗</a>:查干浩特<small><a href="/wiki/%E6%9F%A5%E5%B9%B2%E6%B5%A9%E7%89%B9%E5%9F%8E%E5%9D%80" title="查干浩特城址">[遗址]</a></small>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">明</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E4%B8%AD%E7%AB%8B%E5%BA%9C" title="中立府"><del><i>中都中立府</i></del></a><small><a href="/wiki/%E6%98%8E%E4%B8%AD%E9%83%BD%E9%81%97%E5%9D%80" title="明中都遗址">[遗址]</a></small> ·</span> <span class="nowrap"><a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">京师應天府</a><small>(后改为留都南京)</small><small><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%9F%8E" title="南京城">[遗址]</a></small></span> <span class="nowrap"><a href="/wiki/%E6%B0%B8%E4%B9%90%E8%BF%81%E9%83%BD" title="永乐迁都">→</a> 京师<a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a><small>(原为行在)<a href="/wiki/%E6%98%8E%E6%B8%85%E5%8C%97%E4%BA%AC%E5%9F%8E" title="明清北京城">[遗址]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">應天府</a></span> <span class="nowrap">→ <a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a><sup>
</sup></span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%97%E6%98%8E" title="南明">南明</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><sup><a href="/wiki/%E5%BC%98%E5%85%89" title="弘光">弘光</a></sup><a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">應天府</a> ·</span> <span class="nowrap"><sup><a href="/wiki/%E9%9A%86%E6%AD%A6" title="隆武">隆武</a></sup><a href="/wiki/%E7%A6%8F%E4%BA%AC" class="mw-redirect" title="福京">福京</a><a href="/wiki/%E5%A4%A9%E5%85%B4%E5%BA%9C" class="mw-redirect" title="天兴府">天兴府</a> ·</span> <span class="nowrap"><sup><a href="/wiki/%E7%BB%8D%E6%AD%A6" title="绍武">绍武</a></sup> ·</span> <span class="nowrap"><sup><a href="/wiki/%E6%B0%B8%E6%9B%86_(%E5%8D%97%E6%98%8E)" title="永曆 (南明)">永历</a></sup> ·</span> <span class="nowrap"><sup><a href="/wiki/%E4%B8%9C%E6%AD%A6_(%E5%B9%B4%E5%8F%B7)" title="东武 (年号)">东武</a></sup>
</span></p>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">清</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><b><a href="/wiki/%E5%90%8E%E9%87%91" title="后金">后金</a></b>:<a href="/wiki/%E8%B2%BB%E9%98%BF%E6%8B%89%E5%9F%8E" title="費阿拉城">费阿拉(佛阿拉)</a></span> <span class="nowrap">→ <a href="/wiki/%E8%B5%AB%E5%9B%BE%E9%98%BF%E6%8B%89%E5%9F%8E" title="赫图阿拉城">赫图阿拉(兴京)</a></span> <span class="nowrap">→ <a href="/wiki/%E7%95%8C%E8%97%A9%E5%9F%8E" title="界藩城">界藩城</a><small>(<a href="/wiki/%E8%A1%8C%E9%83%BD" class="mw-redirect" title="行都">行都</a>)</small></span> <span class="nowrap">→ <a href="/wiki/%E8%96%A9%E7%88%BE%E6%BB%B8%E5%9F%8E" title="薩爾滸城">薩爾滸城</a><small>(<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">行都</a>)</small></span> <span class="nowrap">→ <a href="/wiki/%E8%BE%BD%E9%98%B3%E5%9F%8E" title="辽阳城">辽阳</a></span> <span class="nowrap">→ <a href="/wiki/%E4%B8%9C%E4%BA%AC%E5%9F%8E" title="东京城">东京</a></span> <span class="nowrap">→ <a href="/wiki/%E7%9B%9B%E4%BA%AC%E5%9F%8E" title="盛京城">盛京</a><a href="/wiki/%E5%A5%89%E5%A4%A9%E5%BA%9C" title="奉天府">奉天府</a><small><a href="/wiki/%E7%9B%9B%E4%BA%AC%E5%9F%8E" title="盛京城">[遗址]</a></small><small>(后改为留都)</small><br />京师<a href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" class="mw-redirect" title="顺天府">顺天府</a><small><a href="/wiki/%E6%98%8E%E6%B8%85%E5%8C%97%E4%BA%AC%E5%9F%8E" title="明清北京城">[遗址]</a></small><small>[<b><a href="/wiki/%E5%A4%AA%E5%B9%B3%E5%A4%A9%E5%9B%BD" title="太平天国">太平天国</a></b>:<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">天京</a>]</small>
</span></p>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E9%A6%96%E9%83%BD" title="中華民國首都">民国</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<p><span class="nowrap"><a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C" title="北洋政府"><b>民初政府</b></a>:<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%BA%9C" title="南京府">南京府</a><small>(<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E8%87%A8%E6%99%82%E6%94%BF%E5%BA%9C_(1912%E5%B9%B4%EF%BC%8D1913%E5%B9%B4)" title="中華民國臨時政府 (1912年-1913年)">临时</a>)</small></span> <span class="nowrap">→ <a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">北京</a><br /><b><a href="/wiki/%E5%9C%8B%E6%B0%91%E6%94%BF%E5%BA%9C" title="國民政府">國民政府</a></b>:<a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣州市 (中華民國)">广州</a></span> <span class="nowrap">→ <a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉</a></span> <span class="nowrap">→ <a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">南京</a></span> <span class="nowrap">→ <a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳</a><small>(<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">行都</a>)、<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="西安市 (中華民國)">西京</a><small>(陪都)</small></small></span><small> <span class="nowrap">→ <a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="重慶市 (中華民國)">重庆</a><small>(<a href="/wiki/%E9%87%8D%E5%BA%86%E9%99%AA%E9%83%BD%E6%97%B6%E6%9C%9F" title="重庆陪都时期">陪都</a>)</small></span> <span class="nowrap">→ <a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">南京</a><small>(还都)</small><br /><small>[ <a href="/wiki/%E4%B8%AD%E5%8D%8E%E5%85%B1%E5%92%8C%E5%9B%BD" class="mw-redirect" title="中华共和国"><b>中华共和国</b></a>:<a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">福州</a>][ <a href="/wiki/%E4%B8%AD%E5%8D%8E%E8%8B%8F%E7%BB%B4%E5%9F%83%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华苏维埃共和国"><b>中华苏维埃共和国</b></a>:<a href="/wiki/%E7%91%9E%E9%87%91%E5%B8%82" title="瑞金市">瑞京</a>→<a href="/wiki/%E5%BF%97%E4%B8%B9%E5%8E%BF" title="志丹县">保安</a>→<a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">延安</a>]</small><br /><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E6%94%BF%E5%BA%9C" title="中華民國政府"><b>行宪政府</b></a>:<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">南京</a><small><a href="/wiki/%E5%8D%97%E4%BA%AC%E6%B0%91%E5%9B%BD%E5%BB%BA%E7%AD%91" title="南京民国建筑">[遗迹]</a></small></span> <span class="nowrap">→ <a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣州市 (中華民國)">广州</a></span> <span class="nowrap">→ <a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="重慶市 (中華民國)">重庆</a></span> <span class="nowrap">→ <a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a></span> <span class="nowrap">→ <a href="/wiki/%E8%87%BA%E5%8C%97%E5%B8%82" title="臺北市"><b>臺北</b></a><small>(<a href="/wiki/%E4%B8%AD%E5%A4%AE%E6%94%BF%E5%BA%9C%E6%89%80%E5%9C%A8%E5%9C%B0" title="中央政府所在地">中央政府所在地</a>)</small>
</span></small></p><small>
</small></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">共和国</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a class="mw-selflink selflink"><b>北京</b></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div>参见:<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8E%86%E5%8F%B2" title="中国历史">中国历史</a></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E6%AD%A3%E8%81%8C%E9%A2%86%E5%AF%BC%E4%BA%BA" title="Template:中华人民共和国北京市正职领导人"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E6%AD%A3%E8%81%8C%E9%A2%86%E5%AF%BC%E4%BA%BA" title="Template talk:中华人民共和国北京市正职领导人"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E6%AD%A3%E8%81%8C%E9%A2%86%E5%AF%BC%E4%BA%BA&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a class="mw-selflink selflink">北京市</a><a href="/wiki/%E5%85%9A%E5%92%8C%E5%9B%BD%E5%AE%B6%E6%94%BF%E5%BA%9C%E6%9C%BA%E6%9E%84" class="mw-redirect" title="党和国家政府机构">五大机构</a><a href="/wiki/%E7%9C%81%E9%83%A8%E7%BA%A7%E6%AD%A3%E8%81%8C" title="省部级正职">正职</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E9%A2%86%E5%AF%BC%E4%BA%BA" title="中华人民共和国省级行政区领导人">领导人</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国共产党北京市委员会">市委</a>书记</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%BD%AD%E7%9C%9F" title="彭真">彭 真</a> <span class="nowrap">→ <a href="/wiki/%E6%9D%8E%E9%9B%AA%E5%B3%B0" title="李雪峰">李雪峰</a></span> <span class="nowrap">→ <a href="/wiki/%E8%B0%A2%E5%AF%8C%E6%B2%BB" title="谢富治">谢富治</a></span> <span class="nowrap">→ <a href="/wiki/%E5%90%B4%E5%BE%B7" title="吴德">吴 德</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9E%97%E4%B9%8E%E5%8A%A0" title="林乎加">林乎加</a></span> <span class="nowrap">→ <a href="/wiki/%E6%AE%B5%E5%90%9B%E6%AF%85" title="段君毅">段君毅</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9D%8E%E9%94%A1%E9%93%AD" title="李锡铭">李锡铭</a></span> <span class="nowrap">→ <a href="/wiki/%E9%99%88%E5%B8%8C%E5%90%8C" title="陈希同">陈希同</a></span> <span class="nowrap">→ <a href="/wiki/%E5%B0%89%E5%81%A5%E8%A1%8C" title="尉健行">尉健行</a></span> <span class="nowrap">→ <a href="/wiki/%E8%B4%BE%E5%BA%86%E6%9E%97" title="贾庆林">贾庆林</a></span> <span class="nowrap">→ <a href="/wiki/%E5%88%98%E6%B7%87" title="刘淇">刘 淇</a></span> <span class="nowrap">→ <a href="/wiki/%E9%83%AD%E9%87%91%E9%BE%99" title="郭金龙">郭金龙</a></span> <span class="nowrap">→ <a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">蔡 奇</a></span></div></td><td class="navbox-image" rowspan="9" style="width:0%;padding:0px 0px 0px 2px"><div><a href="/wiki/File:China_Beijing.svg" class="image"><img alt="China Beijing.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/80px-China_Beijing.svg.png" decoding="async" width="80" height="68" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/120px-China_Beijing.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/160px-China_Beijing.svg.png 2x" data-file-width="1000" data-file-height="850" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E4%BB%A3%E8%A1%A8%E5%A4%A7%E4%BC%9A%E5%B8%B8%E5%8A%A1%E5%A7%94%E5%91%98%E4%BC%9A" title="北京市人民代表大会常务委员会">市人大常委会</a>主任</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E8%B4%BE%E5%BA%AD%E4%B8%89" title="贾庭三">贾庭三</a> <span class="nowrap">→ <a href="/wiki/%E8%B5%B5%E9%B9%8F%E9%A3%9E" title="赵鹏飞">赵鹏飞</a></span> <span class="nowrap">→ <a href="/wiki/%E5%BC%A0%E5%81%A5%E6%B0%91_(1931%E5%B9%B4)" title="张健民 (1931年)">张健民</a></span> <span class="nowrap">→ <a href="/wiki/%E4%BA%8E%E5%9D%87%E6%B3%A2" title="于均波">于均波</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9D%9C%E5%BE%B7%E5%8D%B0" title="杜德印">杜德印</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9D%8E%E4%BC%9F_(%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A%E4%B8%BB%E4%BB%BB)" title="李伟 (北京市人大常委会主任)">李 偉</a></span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">市人民政府</a>市长</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%8F%B6%E5%89%91%E8%8B%B1" title="叶剑英">叶剑英</a> <span class="nowrap">→ <a href="/wiki/%E8%81%82%E8%8D%A3%E8%87%BB" title="聂荣臻">聂荣臻</a></span> <span class="nowrap">→ <a href="/wiki/%E5%BD%AD%E7%9C%9F" title="彭真">彭 真</a></span> <span class="nowrap">→ <a href="/wiki/%E5%90%B4%E5%BE%B7" title="吴德">吴 德</a></span> <span class="nowrap">→ <a href="/wiki/%E8%B0%A2%E5%AF%8C%E6%B2%BB" title="谢富治">谢富治</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9E%97%E4%B9%8E%E5%8A%A0" title="林乎加">林乎加</a></span> <span class="nowrap">→ <a href="/wiki/%E7%84%A6%E8%8B%A5%E6%84%9A" title="焦若愚">焦若愚</a></span> <span class="nowrap">→ <a href="/wiki/%E9%99%88%E5%B8%8C%E5%90%8C" title="陈希同">陈希同</a></span> <span class="nowrap">→ <a href="/wiki/%E6%9D%8E%E5%85%B6%E7%82%8E" title="李其炎">李其炎</a></span> <span class="nowrap">→ <a href="/wiki/%E8%B4%BE%E5%BA%86%E6%9E%97" title="贾庆林">贾庆林</a></span> <span class="nowrap">→ <a href="/wiki/%E5%88%98%E6%B7%87" title="刘淇">刘 淇</a></span> <span class="nowrap">→ <a href="/wiki/%E5%AD%9F%E5%AD%A6%E5%86%9C" title="孟学农">孟学农</a></span> <span class="nowrap">→ <a href="/wiki/%E7%8E%8B%E5%B2%90%E5%B1%B1" title="王岐山">王岐山</a></span> <span class="nowrap">→ <a href="/wiki/%E9%83%AD%E9%87%91%E9%BE%99" title="郭金龙">郭金龙</a></span> <span class="nowrap">→ <a href="/wiki/%E7%8E%8B%E5%AE%89%E9%A1%BA" title="王安顺">王安顺</a></span> <span class="nowrap">→ <a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">蔡 奇</a></span> <span class="nowrap">→ <a href="/wiki/%E9%99%88%E5%90%89%E5%AE%81" title="陈吉宁">陈吉宁</a></span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国人民政治协商会议北京市委员会">市政协</a>主席</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%88%98%E4%BB%81" title="刘仁">刘 仁</a> <span class="nowrap">→ <a href="/wiki/%E4%B8%81%E5%9B%BD%E9%92%B0" title="丁国钰">丁国钰</a></span> <span class="nowrap">→ <a href="/wiki/%E8%B5%B5%E9%B9%8F%E9%A3%9E" title="赵鹏飞">赵鹏飞</a></span> <span class="nowrap">→ <a href="/wiki/%E5%88%98%E5%AF%BC%E7%94%9F" title="刘导生">刘导生</a></span> <span class="nowrap">→ <a href="/wiki/%E8%8C%83%E7%91%BE" title="范瑾">范 瑾</a></span> <span class="nowrap">→ <a href="/wiki/%E7%99%BD%E4%BB%8B%E5%A4%AB" title="白介夫">白介夫</a></span> <span class="nowrap">→ <a href="/wiki/%E7%8E%8B%E5%A4%A7%E6%98%8E" title="王大明">王大明</a></span> <span class="nowrap">→ <a href="/wiki/%E9%99%88%E5%B9%BF%E6%96%87" title="陈广文">陈广文</a></span> <span class="nowrap">→ <a href="/wiki/%E7%A8%8B%E4%B8%96%E5%B3%A8" title="程世峨">程世峨</a></span> <span class="nowrap">→ <a href="/wiki/%E9%98%B3%E5%AE%89%E6%B1%9F" title="阳安江">阳安江</a></span> <span class="nowrap">→ <a href="/wiki/%E7%8E%8B%E5%AE%89%E9%A1%BA" title="王安顺">王安顺</a></span> <span class="nowrap">→ <a href="/wiki/%E5%90%89%E6%9E%97_(%E4%BA%BA%E7%89%A9)" title="吉林 (人物)">吉 林</a></span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E7%9B%91%E5%AF%9F%E5%A7%94%E5%91%98%E4%BC%9A" title="北京市监察委员会">市监察委</a>主任</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%BC%A0%E7%A1%95%E8%BE%85" title="张硕辅">张硕辅</a> <span class="nowrap">→ <a href="/wiki/%E9%99%88%E9%9B%8D" title="陈雍">陈 雍</a></span></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国超大城市"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/w/index.php?title=Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82&action=edit&redlink=1" class="new" title="Template talk:中华人民共和国超大城市(页面不存在)"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国超大城市列表">超大城市</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px"><div style="padding:0em 0.25em"><a class="mw-selflink selflink">北京</a> · <span class="nowrap"><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉</a></span></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div>超大城市为城区常住人口超过1000万的<a href="/wiki/%E5%9F%8E%E5%B8%82" title="城市">城市</a></div></td></tr></tbody></table></td></tr></tbody></table>
<table class="navbox nav" width="100%">
<tbody><tr>
<th colspan="10" style="padding: 0.2em 1em 0.2em 1em; line-height: 1.3em;"><div class="plainlinks hlist navbar mini" style="float: left;"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%9C%80%E5%A4%9A%E7%9A%84%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国人口最多的城市"><abbr title="查看该模板">查</abbr></a></li><li class="nv-talk"><a href="/w/index.php?title=Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%9C%80%E5%A4%9A%E7%9A%84%E5%9F%8E%E5%B8%82&action=edit&redlink=1" class="new" title="Template talk:中华人民共和国人口最多的城市(页面不存在)"><abbr title="讨论该模板">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%9C%80%E5%A4%9A%E7%9A%84%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板">编</abbr></a></li></ul></div> <span style="font-size:120%;"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a>最大城市排名</span><br /><span style="font-weight:normal;"><small>数据来源:《中国城市建设统计年鉴2018》“城区人口”与“城区暂住人口”指标</small></span>
</th></tr>
<tr>
<th>
</th>
<th>排名
</th>
<th>城市名稱
</th>
<th><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">省市</a>
</th>
<th><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国城市列表">人口</a>
</th>
<th>排名
</th>
<th>城市名稱
</th>
<th><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">省市</a>
</th>
<th><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国城市列表">人口</a>
</th>
<th>
</th></tr>
<tr>
<td rowspan="10" align="center"><a href="/wiki/File:Lujiazui_2016.jpg" class="image" title="上海"><img alt="上海" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Lujiazui_2016.jpg/135px-Lujiazui_2016.jpg" decoding="async" width="135" height="90" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Lujiazui_2016.jpg/203px-Lujiazui_2016.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Lujiazui_2016.jpg/270px-Lujiazui_2016.jpg 2x" data-file-width="1800" data-file-height="1200" /></a><br /><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a><br />
<p><a href="/wiki/File:Beijing_skyline_from_northeast_4th_ring_road_(cropped).jpg" class="image" title="北京"><img alt="北京" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/da/Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg/135px-Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg" decoding="async" width="135" height="90" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/da/Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg/203px-Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/da/Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg/270px-Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg 2x" data-file-width="2755" data-file-height="1843" /></a><br /><a class="mw-selflink selflink">北京</a>
</p>
</td>
<td align="center" style="background:#f0f0f0;">1</td>
<td align="left"><b><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a></b></td>
<td align="left"><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">24,237,800</td>
<td align="center" style="background:#f0f0f0;">11</td>
<td align="left"><b><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京</a></b></td>
<td align="left"><a href="/wiki/%E6%B1%9F%E8%8B%8F" class="mw-redirect" title="江苏">江苏</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">6,572,000
</td>
<td rowspan="10" align="center"><a href="/wiki/File:Tianhe_CBD.jpg" class="image" title="广州"><img alt="广州" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Tianhe_CBD.jpg/135px-Tianhe_CBD.jpg" decoding="async" width="135" height="90" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Tianhe_CBD.jpg/203px-Tianhe_CBD.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Tianhe_CBD.jpg/270px-Tianhe_CBD.jpg 2x" data-file-width="3888" data-file-height="2592" /></a><br /><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州</a><br />
<p><a href="/wiki/File:Futian_District_2017.jpg" class="image" title="深圳"><img alt="深圳" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/46/Futian_District_2017.jpg/135px-Futian_District_2017.jpg" decoding="async" width="135" height="90" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/46/Futian_District_2017.jpg/203px-Futian_District_2017.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/46/Futian_District_2017.jpg/270px-Futian_District_2017.jpg 2x" data-file-width="3168" data-file-height="2112" /></a><br /><a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳</a>
</p>
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">2</td>
<td align="left"><b><a class="mw-selflink selflink">北京</a></b></td>
<td align="left"><a class="mw-selflink selflink">北京</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">18,634,000</td>
<td align="center" style="background:#f0f0f0;">12</td>
<td align="left"><b><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州</a></b></td>
<td align="left"><a href="/wiki/%E6%B5%99%E6%B1%9F" class="mw-redirect" title="浙江">浙江</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">6,504,900
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">3</td>
<td align="left"><b><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州</a></b></td>
<td align="left"><a href="/wiki/%E5%B9%BF%E4%B8%9C" class="mw-redirect" title="广东">广东</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">13,154,200</td>
<td align="center" style="background:#f0f0f0;">13</td>
<td align="left"><b><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州</a></b></td>
<td align="left"><a href="/wiki/%E6%B2%B3%E5%8D%97" class="mw-redirect" title="河南">河南</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">6,261,900
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">4</td>
<td align="left"><b><a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳</a></b></td>
<td align="left"><a href="/wiki/%E5%B9%BF%E4%B8%9C" class="mw-redirect" title="广东">广东</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">13,026,600</td>
<td align="center" style="background:#f0f0f0;">14</td>
<td align="left"><b><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安</a></b></td>
<td align="left"><a href="/wiki/%E9%99%95%E8%A5%BF" class="mw-redirect" title="陕西">陕西</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">5,866,100
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">5</td>
<td align="left"><b><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a></b></td>
<td align="left"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">12,968,100</td>
<td align="center" style="background:#f0f0f0;">15</td>
<td align="left"><b><a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">沈阳</a></b></td>
<td align="left"><a href="/wiki/%E8%BE%BD%E5%AE%81" class="mw-redirect" title="辽宁">辽宁</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">5,651,200
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">6</td>
<td align="left"><b><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆</a></b></td>
<td align="left"><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">11,488,000</td>
<td align="center" style="background:#f0f0f0;">16</td>
<td align="left"><b><a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">青岛</a></b></td>
<td align="left"><a href="/wiki/%E5%B1%B1%E4%B8%9C" class="mw-redirect" title="山东">山东</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">5,127,000
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">7</td>
<td align="left"><b><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉</a></b></td>
<td align="left"><a href="/wiki/%E6%B9%96%E5%8C%97" class="mw-redirect" title="湖北">湖北</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">9,180,000</td>
<td align="center" style="background:#f0f0f0;">17</td>
<td align="left"><b><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">哈尔滨</a></b></td>
<td align="left"><a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F" title="黑龙江">黑龙江</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">4,860,000
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">8</td>
<td align="left"><b><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a></b></td>
<td align="left"><a href="/wiki/%E5%9B%9B%E5%B7%9D" class="mw-redirect" title="四川">四川</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">8,379,700</td>
<td align="center" style="background:#f0f0f0;">18</td>
<td align="left"><b><a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">长春</a></b></td>
<td align="left"><a href="/wiki/%E5%90%89%E6%9E%97" class="mw-redirect" title="吉林">吉林</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">4,564,000
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">9</td>
<td align="left"><b><a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港</a></b></td>
<td align="left"><a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">7,448,900</td>
<td align="center" style="background:#f0f0f0;">19</td>
<td align="left"><b><a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">合肥</a></b></td>
<td align="left"><a href="/wiki/%E5%AE%89%E5%BE%BD" class="mw-redirect" title="安徽">安徽</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">4,292,400
</td></tr>
<tr>
<td align="center" style="background:#f0f0f0;">10</td>
<td align="left"><b><a href="/wiki/%E4%B8%9C%E8%8E%9E%E5%B8%82" title="东莞市">东莞</a></b></td>
<td align="left"><a href="/wiki/%E5%B9%BF%E4%B8%9C" class="mw-redirect" title="广东">广东</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">6,850,300</td>
<td align="center" style="background:#f0f0f0;">20</td>
<td align="left"><b><a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">济南</a></b></td>
<td align="left"><a href="/wiki/%E5%B1%B1%E4%B8%9C" class="mw-redirect" title="山东">山东</a></td>
<td style="text-align:right;padding:0 0.3em 0 0;">4,154,900
</td></tr>
</tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2" style="background: SaddleBrown; color:#ffffff;"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" class="mw-redirect" title="Template:国家历史文化名城"><abbr title="查看该模板" style=";background: SaddleBrown; color:#ffffff;;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" class="mw-redirect" title="Template talk:国家历史文化名城"><abbr title="讨论该模板" style=";background: SaddleBrown; color:#ffffff;;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E&action=edit"><abbr title="编辑该模板" style=";background: SaddleBrown; color:#ffffff;;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><span class="flagicon"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国"><img alt="中华人民共和国" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国"><span style="color:white;">中华人民共和国</span></a><a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="国家历史文化名城"><span style="color:white;">国家历史文化名城</span></a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2" style="background: Sienna; color:#ffffff;"><div><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%8A%A1%E9%99%A2" title="中华人民共和国国务院"><span style="color:white;">中华人民共和国国务院</span></a>公布,共<b>135</b>处(截至2018年5月2日):</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区"><span style="color:white;">华北</span></a><br />14</th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a class="mw-selflink selflink"><span style="color:white;">北 京</span></a> <sub>1</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市"><span style="color:white;">天 津</span></a> <sub>1</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省"><span style="color:white;">河 北</span></a> <sub>6</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">承德市</a></li>
<li><a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">保定市</a></li>
<li>石家庄市
<ul><li><a href="/wiki/%E6%AD%A3%E5%AE%9A%E5%8E%BF" title="正定县">正定县</a></li></ul></li>
<li><a href="/wiki/%E9%82%AF%E9%83%B8%E5%B8%82" title="邯郸市">邯郸市</a></li>
<li>秦皇岛市
<ul><li><a href="/wiki/%E5%B1%B1%E6%B5%B7%E5%85%B3%E5%8C%BA" title="山海关区">山海关区</a></li></ul></li>
<li>张家口市
<ul><li><a href="/wiki/%E8%94%9A%E5%8E%BF" title="蔚县">蔚县</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省"><span style="color:white;">山 西</span></a> <sub>6</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">大同市</a></li>
<li>晋中市
<ul><li><a href="/wiki/%E5%B9%B3%E9%81%A5%E5%8E%BF" title="平遥县">平遥县</a></li></ul></li>
<li>运城市
<ul><li><a href="/wiki/%E6%96%B0%E7%BB%9B%E5%8E%BF" title="新绛县">新绛县</a></li></ul></li>
<li>忻州市
<ul><li><a href="/wiki/%E4%BB%A3%E5%8E%BF" title="代县">代县</a></li></ul></li>
<li>晋中市
<ul><li><a href="/wiki/%E7%A5%81%E5%8E%BF" title="祁县">祁县</a></li></ul></li>
<li><a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">太原市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区"><span style="color:white;">内蒙古</span></a> <sub>1</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">呼和浩特市</a></div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%9C%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国东北地区"><span style="color:white;">东北</span></a><br />6</th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省"><span style="color:white;">辽 宁</span></a> <sub>1</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">沈阳市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省"><span style="color:white;">吉 林</span></a> <sub>3</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%90%89%E6%9E%97%E5%B8%82" title="吉林市">吉林市</a></li>
<li>通化市
<ul><li><a href="/wiki/%E9%9B%86%E5%AE%89%E5%B8%82" title="集安市">集安市</a></li></ul></li>
<li><a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">长春市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省"><span style="color:white;">黑龙江</span></a> <sub>2</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">哈尔滨市</a></li>
<li><a href="/wiki/%E9%BD%90%E9%BD%90%E5%93%88%E5%B0%94%E5%B8%82" title="齐齐哈尔市">齐齐哈尔市</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%8D%8E%E4%B8%9C%E5%9C%B0%E5%8C%BA" title="华东地区"><span style="color:white;">华东</span></a><br />47</th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市"><span style="color:white;">上 海</span></a> <sub>1</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省"><span style="color:white;">江 苏</span></a> <sub>13</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京市</a></li>
<li><a href="/wiki/%E8%8B%8F%E5%B7%9E%E5%B8%82" title="苏州市">苏州市</a></li>
<li><a href="/wiki/%E6%89%AC%E5%B7%9E%E5%B8%82" title="扬州市">扬州市</a></li>
<li><a href="/wiki/%E9%95%87%E6%B1%9F%E5%B8%82" title="镇江市">镇江市</a></li>
<li>苏州市
<ul><li><a href="/wiki/%E5%B8%B8%E7%86%9F%E5%B8%82" title="常熟市">常熟市</a></li></ul></li>
<li><a href="/wiki/%E5%BE%90%E5%B7%9E%E5%B8%82" title="徐州市">徐州市</a></li>
<li>淮安市
<ul><li><a href="/wiki/%E6%B7%AE%E5%AE%89%E5%8C%BA" title="淮安区">淮安区</a></li></ul></li>
<li><a href="/wiki/%E6%97%A0%E9%94%A1%E5%B8%82" title="无锡市">无锡市</a></li>
<li><a href="/wiki/%E5%8D%97%E9%80%9A%E5%B8%82" title="南通市">南通市</a></li>
<li>无锡市
<ul><li><a href="/wiki/%E5%AE%9C%E5%85%B4%E5%B8%82" title="宜兴市">宜兴市</a></li></ul></li>
<li><a href="/wiki/%E6%B3%B0%E5%B7%9E%E5%B8%82" title="泰州市">泰州市</a></li>
<li><a href="/wiki/%E5%B8%B8%E5%B7%9E%E5%B8%82" title="常州市">常州市</a></li>
<li>扬州市
<ul><li><a href="/wiki/%E9%AB%98%E9%82%AE%E5%B8%82" title="高邮市">高邮市</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省"><span style="color:white;">浙 江</span></a> <sub>10</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州市</a></li>
<li><a href="/wiki/%E7%BB%8D%E5%85%B4%E5%B8%82" title="绍兴市">绍兴市</a></li>
<li><a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">宁波市</a></li>
<li><a href="/wiki/%E8%A1%A2%E5%B7%9E%E5%B8%82" title="衢州市">衢州市</a></li>
<li>台州市
<ul><li><a href="/wiki/%E4%B8%B4%E6%B5%B7%E5%B8%82" title="临海市">临海市</a></li></ul></li>
<li><a href="/wiki/%E9%87%91%E5%8D%8E%E5%B8%82" title="金华市">金华市</a></li>
<li><a href="/wiki/%E5%98%89%E5%85%B4%E5%B8%82" title="嘉兴市">嘉兴市</a></li>
<li><a href="/wiki/%E6%B9%96%E5%B7%9E%E5%B8%82" title="湖州市">湖州市</a></li>
<li><a href="/wiki/%E6%B8%A9%E5%B7%9E%E5%B8%82" title="温州市">温州市</a></li>
<li>丽水市
<ul><li><a href="/wiki/%E9%BE%99%E6%B3%89%E5%B8%82" title="龙泉市">龙泉市</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省"><span style="color:white;">安 徽</span></a> <sub>5</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>黄山市
<ul><li><a href="/wiki/%E6%AD%99%E5%8E%BF" title="歙县">歙县</a></li></ul></li>
<li>淮南市
<ul><li><a href="/wiki/%E5%AF%BF%E5%8E%BF" title="寿县">寿县</a></li></ul></li>
<li><a href="/wiki/%E4%BA%B3%E5%B7%9E%E5%B8%82" title="亳州市">亳州市</a></li>
<li><a href="/wiki/%E5%AE%89%E5%BA%86%E5%B8%82" title="安庆市">安庆市</a></li>
<li>宣城市
<ul><li><a href="/wiki/%E7%BB%A9%E6%BA%AA%E5%8E%BF" title="绩溪县">绩溪县</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省"><span style="color:white;">山 东</span></a> <sub>10</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>济宁市
<ul><li><a href="/wiki/%E6%9B%B2%E9%98%9C%E5%B8%82" title="曲阜市">曲阜市</a></li></ul></li>
<li><a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">济南市</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">青岛市</a></li>
<li><a href="/wiki/%E8%81%8A%E5%9F%8E%E5%B8%82" title="聊城市">聊城市</a></li>
<li>济宁市
<ul><li><a href="/wiki/%E9%82%B9%E5%9F%8E%E5%B8%82" title="邹城市">邹城市</a></li></ul></li>
<li>淄博市
<ul><li><a href="/wiki/%E4%B8%B4%E6%B7%84%E5%8C%BA" title="临淄区">临淄区</a></li></ul></li>
<li><a href="/wiki/%E6%B3%B0%E5%AE%89%E5%B8%82" title="泰安市">泰安市</a></li>
<li><a href="/wiki/%E7%83%9F%E5%8F%B0%E5%B8%82" title="烟台市">烟台市</a>
<ul><li><a href="/wiki/%E8%93%AC%E8%8E%B1%E5%B8%82" class="mw-redirect" title="蓬莱市">蓬莱市</a></li></ul></li>
<li>潍坊市
<ul><li><a href="/wiki/%E9%9D%92%E5%B7%9E%E5%B8%82" title="青州市">青州市</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省"><span style="color:white;">福 建</span></a> <sub>4</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B3%89%E5%B7%9E%E5%B8%82" title="泉州市">泉州市</a></li>
<li><a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">福州市</a></li>
<li><a href="/wiki/%E6%BC%B3%E5%B7%9E%E5%B8%82" title="漳州市">漳州市</a></li>
<li>龙岩市
<ul><li><a href="/wiki/%E9%95%BF%E6%B1%80%E5%8E%BF" title="长汀县">长汀县</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省"><span style="color:white;">江 西</span></a> <sub>4</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%99%AF%E5%BE%B7%E9%95%87%E5%B8%82" title="景德镇市">景德镇市</a></li>
<li><a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">南昌市</a></li>
<li><a href="/wiki/%E8%B5%A3%E5%B7%9E%E5%B8%82" title="赣州市">赣州市</a></li>
<li>赣州市
<ul><li><a href="/wiki/%E7%91%9E%E9%87%91%E5%B8%82" title="瑞金市">瑞金市</a></li></ul></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E4%B8%AD%E5%8D%97%E5%9C%B0%E5%8C%BA" class="mw-redirect" title="中南地区"><span style="color:white;">中南</span></a><br />30</th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省"><span style="color:white;">河 南</span></a> <sub>8</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳市</a></li>
<li><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">开封市</a></li>
<li><a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">安阳市</a></li>
<li><a href="/wiki/%E5%8D%97%E9%98%B3%E5%B8%82" title="南阳市">南阳市</a></li>
<li>商丘市
<ul><li><a href="/wiki/%E7%9D%A2%E9%98%B3%E5%8C%BA" title="睢阳区">睢阳区</a></li></ul></li>
<li><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州市</a></li>
<li>鹤壁市
<ul><li><a href="/wiki/%E6%B5%9A%E5%8E%BF" title="浚县">浚县</a></li></ul></li>
<li><a href="/wiki/%E6%BF%AE%E9%98%B3%E5%B8%82" title="濮阳市">濮阳市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省"><span style="color:white;">湖 北</span></a> <sub>5</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>荆州市
<ul><li><a href="/wiki/%E8%8D%86%E5%B7%9E%E5%8C%BA" title="荆州区">荆州区</a></li></ul></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉市</a></li>
<li><a href="/wiki/%E8%A5%84%E9%98%B3%E5%B8%82" title="襄阳市">襄阳市</a></li>
<li><a href="/wiki/%E9%9A%8F%E5%B7%9E%E5%B8%82" title="随州市">随州市</a></li>
<li>荆门市
<ul><li><a href="/wiki/%E9%92%9F%E7%A5%A5%E5%B8%82" title="钟祥市">钟祥市</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省"><span style="color:white;">湖 南</span></a> <sub>4</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">长沙市</a></li>
<li><a href="/wiki/%E5%B2%B3%E9%98%B3%E5%B8%82" title="岳阳市">岳阳市</a></li>
<li>湘西土家族苗族自治州
<ul><li><a href="/wiki/%E5%87%A4%E5%87%B0%E5%8E%BF" title="凤凰县">凤凰县</a></li></ul></li>
<li><a href="/wiki/%E6%B0%B8%E5%B7%9E%E5%B8%82" title="永州市">永州市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省"><span style="color:white;">广 东</span></a> <sub>8</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州市</a></li>
<li><a href="/wiki/%E6%BD%AE%E5%B7%9E%E5%B8%82" title="潮州市">潮州市</a></li>
<li><a href="/wiki/%E8%82%87%E5%BA%86%E5%B8%82" title="肇庆市">肇庆市</a></li>
<li><a href="/wiki/%E4%BD%9B%E5%B1%B1%E5%B8%82" title="佛山市">佛山市</a></li>
<li><a href="/wiki/%E6%A2%85%E5%B7%9E%E5%B8%82" title="梅州市">梅州市</a></li>
<li>湛江市
<ul><li><a href="/wiki/%E9%9B%B7%E5%B7%9E%E5%B8%82" title="雷州市">雷州市</a></li></ul></li>
<li><a href="/wiki/%E4%B8%AD%E5%B1%B1%E5%B8%82" title="中山市">中山市</a></li>
<li><a href="/wiki/%E6%83%A0%E5%B7%9E%E5%B8%82" title="惠州市">惠州市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区"><span style="color:white;">广 西</span></a> <sub>3</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%A1%82%E6%9E%97%E5%B8%82" title="桂林市">桂林市</a></li>
<li><a href="/wiki/%E6%9F%B3%E5%B7%9E%E5%B8%82" title="柳州市">柳州市</a></li>
<li><a href="/wiki/%E5%8C%97%E6%B5%B7%E5%B8%82" title="北海市">北海市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省"><span style="color:white;">海 南</span></a> <sub>2</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>海口市
<ul><li><a href="/wiki/%E7%90%BC%E5%B1%B1%E5%8C%BA" title="琼山区">琼山区</a></li></ul></li>
<li><a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">海口市</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中国西南地区"><span style="color:white;">西南</span></a><br />20</th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省"><span style="color:white;">四 川</span></a> <sub>8</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都市</a></li>
<li><a href="/wiki/%E8%87%AA%E8%B4%A1%E5%B8%82" title="自贡市">自贡市</a></li>
<li><a href="/wiki/%E5%AE%9C%E5%AE%BE%E5%B8%82" title="宜宾市">宜宾市</a></li>
<li>南充市
<ul><li><a href="/wiki/%E9%98%86%E4%B8%AD%E5%B8%82" title="阆中市">阆中市</a></li></ul></li>
<li><a href="/wiki/%E4%B9%90%E5%B1%B1%E5%B8%82" title="乐山市">乐山市</a></li>
<li>成都市
<ul><li><a href="/wiki/%E9%83%BD%E6%B1%9F%E5%A0%B0%E5%B8%82" title="都江堰市">都江堰市</a></li></ul></li>
<li><a href="/wiki/%E6%B3%B8%E5%B7%9E%E5%B8%82" title="泸州市">泸州市</a></li>
<li>凉山彝族自治州
<ul><li><a href="/wiki/%E4%BC%9A%E7%90%86%E5%8E%BF" title="会理县">会理县</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市"><span style="color:white;">重 庆</span></a> <sub>1</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省"><span style="color:white;">贵 州</span></a> <sub>2</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%81%B5%E4%B9%89%E5%B8%82" title="遵义市">遵义市</a></li>
<li>黔东南苗族侗族自治州
<ul><li><a href="/wiki/%E9%95%87%E8%BF%9C%E5%8E%BF" title="镇远县">镇远县</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省"><span style="color:white;">云 南</span></a> <sub>6</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">昆明市</a></li>
<li>大理白族自治州
<ul><li><a href="/wiki/%E5%A4%A7%E7%90%86%E5%B8%82" title="大理市">大理市</a></li></ul></li>
<li><a href="/wiki/%E4%B8%BD%E6%B1%9F%E5%B8%82" title="丽江市">丽江市</a></li>
<li>红河哈尼族彝族自治州
<ul><li><a href="/wiki/%E5%BB%BA%E6%B0%B4%E5%8E%BF" title="建水县">建水县</a></li></ul></li>
<li>大理白族自治州
<ul><li><a href="/wiki/%E5%B7%8D%E5%B1%B1%E5%BD%9D%E6%97%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8E%BF" title="巍山彝族回族自治县">巍山彝族回族自治县</a></li></ul></li>
<li>曲靖市
<ul><li><a href="/wiki/%E4%BC%9A%E6%B3%BD%E5%8E%BF" title="会泽县">会泽县</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区"><span style="color:white;">西 藏</span></a> <sub>3</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%8B%89%E8%90%A8%E5%B8%82" title="拉萨市">拉萨市</a></li>
<li>日喀则市<a href="/wiki/%E6%A1%91%E7%8F%A0%E5%AD%9C%E5%8C%BA" title="桑珠孜区">桑珠孜区</a></li>
<li>日喀则市<a href="/wiki/%E6%B1%9F%E5%AD%9C%E5%8E%BF" title="江孜县">江孜县</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国西北地区"><span style="color:white;">西北</span></a><br />17</th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省"><span style="color:white;">陕 西</span></a> <sub>6</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安市</a></li>
<li><a href="/wiki/%E5%92%B8%E9%98%B3%E5%B8%82" title="咸阳市">咸阳市</a></li>
<li><a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">延安市</a></li>
<li>渭南市
<ul><li><a href="/wiki/%E9%9F%A9%E5%9F%8E%E5%B8%82" title="韩城市">韩城市</a></li></ul></li>
<li><a href="/wiki/%E6%A6%86%E6%9E%97%E5%B8%82" title="榆林市">榆林市</a></li>
<li><a href="/wiki/%E6%B1%89%E4%B8%AD%E5%B8%82" title="汉中市">汉中市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省"><span style="color:white;">甘 肃</span></a> <sub>4</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%AD%A6%E5%A8%81%E5%B8%82" title="武威市">武威市</a></li>
<li><a href="/wiki/%E5%BC%A0%E6%8E%96%E5%B8%82" title="张掖市">张掖市</a></li>
<li>酒泉市
<ul><li><a href="/wiki/%E6%95%A6%E7%85%8C%E5%B8%82" title="敦煌市">敦煌市</a></li></ul></li>
<li><a href="/wiki/%E5%A4%A9%E6%B0%B4%E5%B8%82" title="天水市">天水市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省"><span style="color:white;">青 海</span></a> <sub>1</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>黄南藏族自治州
<ul><li><a href="/wiki/%E5%90%8C%E4%BB%81%E5%B8%82" title="同仁市">同仁市</a></li></ul></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区"><span style="color:white;">宁 夏</span></a> <sub>1</sub></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">银川市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color: SaddleBrown; text-align: center;"><a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区"><span style="color:white;">新 疆</span></a> <sub>5</sub></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>喀什地区
<ul><li><a href="/wiki/%E5%96%80%E4%BB%80%E5%B8%82" title="喀什市">喀什市</a></li></ul></li>
<li>吐鲁番市
<ul><li><a href="/wiki/%E9%AB%98%E6%98%8C%E5%8C%BA" title="高昌区">高昌区</a></li></ul></li>
<li>伊犁哈萨克自治州
<ul><li><a href="/wiki/%E4%BC%8A%E5%AE%81%E5%B8%82" title="伊宁市">伊宁市</a></li>
<li><a href="/wiki/%E7%89%B9%E5%85%8B%E6%96%AF%E5%8E%BF" title="特克斯县">特克斯县</a></li></ul></li>
<li>阿克苏地区
<ul><li><a href="/wiki/%E5%BA%93%E8%BD%A6%E5%8E%BF" class="mw-redirect" title="库车县">库车县</a></li></ul></li></ul>
</div></td></tr></tbody></table><div></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD" title="Template:亞洲首都"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD" title="Template talk:亞洲首都"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E4%BA%9E%E6%B4%B2" class="mw-redirect" title="亞洲">亞洲</a><a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">首都</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div><i><b>粗斜體</b></i>为<a href="/wiki/%E6%9C%AA%E8%A2%AB%E6%99%AE%E9%81%8D%E6%89%BF%E8%AE%A4%E7%9A%84%E5%9B%BD%E5%AE%B6%E5%88%97%E8%A1%A8" class="mw-redirect" title="未被普遍承认的国家列表">未被国际普遍承认国家</a>的首都或未被国际普遍承认的首都。</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="width: 10%;"><b><a href="/wiki/%E4%B8%AD%E4%BA%9A" title="中亚">中亚</a></b></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><b><a href="/wiki/%E5%8A%AA%E5%B0%94-%E8%8B%8F%E4%B8%B9" class="mw-redirect" title="努尔-苏丹">努尔-苏丹</a></b>(<a href="/wiki/%E5%93%88%E8%90%A8%E5%85%8B%E6%96%AF%E5%9D%A6" title="哈萨克斯坦">哈萨克斯坦</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%AF%94%E4%BB%80%E5%87%AF%E5%85%8B" title="比什凯克">比什凯克</a></b>(<a href="/wiki/%E5%90%89%E5%B0%94%E5%90%89%E6%96%AF%E6%96%AF%E5%9D%A6" title="吉尔吉斯斯坦">吉尔吉斯斯坦</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%9D%9C%E5%B0%9A%E5%88%AB" title="杜尚别">杜尚别</a></b>(<a href="/wiki/%E5%A1%94%E5%90%89%E5%85%8B%E6%96%AF%E5%9D%A6" title="塔吉克斯坦">塔吉克斯坦</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%98%BF%E4%BB%80%E5%93%88%E5%B7%B4%E5%BE%B7" title="阿什哈巴德">阿什哈巴德</a></b>(<a href="/wiki/%E5%9C%9F%E5%BA%93%E6%9B%BC%E6%96%AF%E5%9D%A6" title="土库曼斯坦">土库曼斯坦</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%A1%94%E4%BB%80%E5%B9%B2" title="塔什干">塔什干</a></b>(<a href="/wiki/%E4%B9%8C%E5%85%B9%E5%88%AB%E5%85%8B%E6%96%AF%E5%9D%A6" title="乌兹别克斯坦">乌兹别克斯坦</a>)</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="width: 10%;"><b><a href="/wiki/%E6%9D%B1%E4%BA%9E" class="mw-redirect" title="東亞">東亞</a></b></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><b><a class="mw-selflink selflink">北京</a></b>(<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">東京</a></b><sup><small>1</small></sup>(<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">日本</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%B9%B3%E5%A3%A4" title="平壤">平壤</a></b>(<a href="/wiki/%E6%9C%9D%E9%B2%9C%E6%B0%91%E4%B8%BB%E4%B8%BB%E4%B9%89%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="朝鲜民主主义人民共和国">朝鲜</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%A6%96%E7%88%BE" title="首爾">首爾</a></b>(<a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国">韩国</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E4%B9%8C%E5%85%B0%E5%B7%B4%E6%89%98" title="乌兰巴托">乌兰巴托</a></b>(<a href="/wiki/%E8%92%99%E5%8F%A4%E5%9B%BD" title="蒙古国">蒙古</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E8%87%BA%E5%8C%97%E5%B8%82" title="臺北市">臺北</a></b></i><sup><small>2</small></sup>(<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a>)</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="width: 10%;"><b><a href="/wiki/%E5%8D%97%E4%BA%9E" class="mw-redirect" title="南亞">南亞</a></b></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><b><a href="/wiki/%E8%BE%BE%E5%8D%A1" title="达卡">达卡</a></b>(<a href="/wiki/%E5%AD%9F%E5%8A%A0%E6%8B%89%E5%9B%BD" title="孟加拉国">孟加拉</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%BB%B7%E5%B8%83" title="廷布">廷布</a></b>(<a href="/wiki/%E4%B8%8D%E4%B8%B9" title="不丹">不丹</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%96%B0%E5%BE%B7%E9%87%8C" title="新德里">新德里</a></b>(<a href="/wiki/%E5%8D%B0%E5%BA%A6" title="印度">印度</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%A6%AC%E7%B4%AF" title="馬累">马累</a></b>(<a href="/wiki/%E9%A9%AC%E5%B0%94%E4%BB%A3%E5%A4%AB" title="马尔代夫">马尔代夫</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%8A%A0%E5%BE%B7%E6%BB%BF%E9%83%BD" title="加德滿都">加德滿都</a></b>(<a href="/wiki/%E5%B0%BC%E6%B3%8A%E5%B0%94" title="尼泊尔">尼泊尔</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E4%BC%8A%E6%96%AF%E5%85%B0%E5%A0%A1" title="伊斯兰堡">伊斯兰堡</a></b>(<a href="/wiki/%E5%B7%B4%E5%9F%BA%E6%96%AF%E5%9D%A6" title="巴基斯坦">巴基斯坦</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%96%AF%E9%87%8C%E8%B3%88%E4%BA%9E%E7%93%A6%E5%BE%B7%E7%B4%8D%E6%99%AE%E6%8B%89%E7%A7%91%E7%89%B9" title="斯里賈亞瓦德納普拉科特">科特</a></b><sup><small>3</small></sup><span style="font-size:smaller;">(正式首都)</span>與<b><a href="/wiki/%E5%8F%AF%E5%80%AB%E5%9D%A1" title="可倫坡">科伦坡</a></b><span style="font-size:smaller;">(行政首都)</span>(<a href="/wiki/%E6%96%AF%E9%87%8C%E8%98%AD%E5%8D%A1" title="斯里蘭卡">斯里蘭卡</a>)</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="width: 10%;"><b><a href="/wiki/%E6%9D%B1%E5%8D%97%E4%BA%9E" class="mw-redirect" title="東南亞">東南亞</a></b></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><b><a href="/wiki/%E6%96%AF%E9%87%8C%E5%B7%B4%E5%8A%A0%E7%81%A3%E5%B8%82" class="mw-redirect" title="斯里巴加灣市">斯里巴加灣市</a></b>(<a href="/wiki/%E6%B1%B6%E8%8E%B1" title="汶莱">文莱</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%87%91%E8%BE%B9" title="金边">金边</a></b>(<a href="/wiki/%E6%9F%AC%E5%9F%94%E5%AF%A8" title="柬埔寨">柬埔寨</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%B8%9D%E5%8A%9B" title="帝力">帝力</a></b>(<a href="/wiki/%E4%B8%9C%E5%B8%9D%E6%B1%B6" title="东帝汶">东帝汶</a>)<sup><small>4</small></sup><span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">雅加达</a></b>(<a href="/wiki/%E5%8D%B0%E5%BA%A6%E5%B0%BC%E8%A5%BF%E4%BA%9A" title="印度尼西亚">印度尼西亚</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%B0%B8%E7%8F%8D" title="永珍">万象</a></b>(<a href="/wiki/%E8%80%81%E6%8C%9D" title="老挝">老挝</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%90%89%E9%9A%86%E5%9D%A1" title="吉隆坡">吉隆坡</a></b><span style="font-size:smaller;">(正式首都)</span>與<b><a href="/wiki/%E5%B8%83%E5%9F%8E" title="布城">布城</a></b><span style="font-size:smaller;">(行政首都)</span> (<a href="/wiki/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A" title="马来西亚">马来西亚</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%A5%88%E6%AF%94%E5%A4%9A" title="奈比多">内比都</a></b>(<a href="/wiki/%E7%BC%85%E7%94%B8" title="缅甸">缅甸</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%A9%AC%E5%B0%BC%E6%8B%89" title="马尼拉">马尼拉</a></b>(<a href="/wiki/%E8%8F%B2%E5%BE%8B%E5%AE%BE" title="菲律宾">菲律宾</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%96%B0%E5%8A%A0%E5%9D%A1" title="新加坡">新加坡</a><sup><small>5</small></sup></b><span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">曼谷</a></b>(<a href="/wiki/%E6%B3%B0%E5%9B%BD" title="泰国">泰国</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E6%B2%B3%E5%86%85" class="mw-redirect" title="河内">河内</a></b>(<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">越南</a>)</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="width: 10%;"><b><a href="/wiki/%E8%A5%BF%E4%BA%9E" class="mw-redirect" title="西亞">西亞</a></b></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><b><a href="/wiki/%E5%96%80%E5%B8%83%E5%B0%94" title="喀布尔">喀布尔</a></b>(<a href="/wiki/%E9%98%BF%E5%AF%8C%E6%B1%97" title="阿富汗">阿富汗</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E8%91%89%E9%87%8C%E6%BA%AB" title="葉里溫">埃里温</a></b>(<a href="/wiki/%E4%BA%9E%E7%BE%8E%E5%B0%BC%E4%BA%9E" title="亞美尼亞">亞美尼亞</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%B7%B4%E5%BA%93" title="巴库">巴库</a></b>(<a href="/wiki/%E9%98%BF%E5%A1%9E%E6%8B%9C%E7%96%86" title="阿塞拜疆">阿塞拜疆</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%BA%A6%E7%BA%B3%E9%BA%A6" title="麦纳麦">麦纳麦</a></b>(<a href="/wiki/%E5%B7%B4%E6%9E%97" title="巴林">巴林</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%B0%BC%E7%A7%91%E8%A5%BF%E4%BA%9A" title="尼科西亚">尼科西亚</a></b>(<a href="/wiki/%E8%B3%BD%E6%99%AE%E5%8B%92%E6%96%AF" title="賽普勒斯">塞浦路斯</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E7%AC%AC%E6%AF%94%E5%88%A9%E6%96%AF" title="第比利斯">第比利斯</a></b>(<a href="/wiki/%E6%A0%BC%E9%B2%81%E5%90%89%E4%BA%9A" title="格鲁吉亚">格鲁吉亚</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%BE%B7%E9%BB%91%E5%85%B0" title="德黑兰">德黑兰</a></b>(<a href="/wiki/%E4%BC%8A%E6%9C%97" title="伊朗">伊朗</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%B7%B4%E6%A0%BC%E8%BE%BE" title="巴格达">巴格达</a></b>(<a href="/wiki/%E4%BC%8A%E6%8B%89%E5%85%8B" title="伊拉克">伊拉克</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E8%80%B6%E8%B7%AF%E6%92%92%E5%86%B7" title="耶路撒冷">耶路撒冷</a></b></i><sup><small>6</small></sup>(<a href="/wiki/%E4%BB%A5%E8%89%B2%E5%88%97" title="以色列">以色列</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%AE%89%E6%9B%BC" title="安曼">安曼</a></b>(<a href="/wiki/%E7%BA%A6%E6%97%A6" title="约旦">约旦</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E7%A7%91%E5%A8%81%E7%89%B9%E5%9F%8E" title="科威特城">科威特城</a></b>(<a href="/wiki/%E7%A7%91%E5%A8%81%E7%89%B9" title="科威特">科威特</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E8%B4%9D%E9%B2%81%E7%89%B9" title="贝鲁特">贝鲁特</a></b>(<a href="/wiki/%E9%BB%8E%E5%B7%B4%E5%AB%A9" title="黎巴嫩">黎巴嫩</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%A9%AC%E6%96%AF%E5%96%80%E7%89%B9" title="马斯喀特">马斯喀特</a></b>(<a href="/wiki/%E9%98%BF%E6%9B%BC" title="阿曼">阿曼</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%A4%9A%E5%93%88" title="多哈">多哈</a></b>(<a href="/wiki/%E5%8D%A1%E5%A1%94%E5%B0%94" title="卡塔尔">卡塔尔</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%88%A9%E9%9B%85%E5%BE%B7" title="利雅德">利雅德</a></b>(<a href="/wiki/%E6%B2%99%E7%89%B9%E9%98%BF%E6%8B%89%E4%BC%AF" title="沙特阿拉伯">沙特阿拉伯</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%A4%A7%E9%A9%AC%E5%A3%AB%E9%9D%A9" title="大马士革">大马士革</a></b>(<a href="/wiki/%E5%8F%99%E5%88%A9%E4%BA%9A" title="叙利亚">叙利亚</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E5%AE%89%E5%8D%A1%E6%8B%89" title="安卡拉">安卡拉</a></b>(<a href="/wiki/%E5%9C%9F%E8%80%B3%E5%85%B6" title="土耳其">土耳其</a>)<sup><small>7</small></sup><span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E9%98%BF%E5%B8%83%E6%89%8E%E6%AF%94" title="阿布扎比">阿布扎比</a></b>(<a href="/wiki/%E9%98%BF%E6%8B%89%E4%BC%AF%E8%81%94%E5%90%88%E9%85%8B%E9%95%BF%E5%9B%BD" title="阿拉伯联合酋长国">阿拉伯联合酋长国</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <b><a href="/wiki/%E8%90%A8%E9%82%A3" title="萨那">萨那</a></b><sup><small>8</small></sup>(<a href="/wiki/%E4%B9%9F%E9%97%A8" title="也门">也门</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E8%8B%8F%E5%91%BC%E7%B1%B3" title="苏呼米">苏呼米</a></b></i>(<a href="/wiki/%E9%98%BF%E5%B8%83%E5%93%88%E5%85%B9" class="mw-redirect" title="阿布哈兹">阿布哈兹</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E6%96%AF%E6%8D%B7%E6%BD%98%E7%B4%8D%E5%85%8B%E7%89%B9" title="斯捷潘納克特">斯捷潘納克特</a></b></i>(<a href="/wiki/%E9%98%BF%E5%B0%94%E5%AF%9F%E8%B5%AB%E5%85%B1%E5%92%8C%E5%9B%BD" title="阿尔察赫共和国">阿尔察赫</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E8%80%B6%E8%B7%AF%E6%92%92%E5%86%B7" title="耶路撒冷">耶路撒冷</a></b></i><sup><small>9</small></sup>(<a href="/wiki/%E5%B7%B4%E5%8B%92%E6%96%AF%E5%9D%A6%E5%9C%8B" title="巴勒斯坦國">巴勒斯坦國</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E8%8C%A8%E6%AC%A3%E7%93%A6%E5%88%A9" title="茨欣瓦利">茨欣瓦利</a></b></i>(<a href="/wiki/%E5%8D%97%E5%A5%A5%E5%A1%9E%E6%A2%AF" title="南奥塞梯">南奥塞梯</a>)<span style="white-space:nowrap; font-weight:bold;"> ·</span> <i><b><a href="/wiki/%E5%8C%97%E5%B0%BC%E7%A7%91%E8%A5%BF%E4%BA%9A" title="北尼科西亚">北尼科西亚</a></b></i>(<a href="/wiki/%E5%8C%97%E8%B3%BD%E6%99%AE%E5%8B%92%E6%96%AF" title="北賽普勒斯">北賽普勒斯</a>)</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="width: 10%;">備註</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><div>
<p><sup>1</sup> 日本现在没有任何法律规定首都之地点,但东京都区部为日本的<a href="/wiki/%E4%B8%AD%E5%A4%AE%E6%94%BF%E5%BA%9C%E6%89%80%E5%9C%A8%E5%9C%B0" title="中央政府所在地">中央政府所在地</a>,因而使东京都被广泛认知为日本首都。此外日本在1950年制定过《首都建设法》,但已废除。1956年制定的《首都圈整备法》则将东京都、埼玉县、千叶县、神奈川县、茨城县、栃木县、群马县、山梨县规定为<a href="/wiki/%E9%A6%96%E9%83%BD%E5%9C%88_(%E6%97%A5%E6%9C%AC)" title="首都圈 (日本)">首都圈</a>。<br />
<sup>2</sup> 自1949年<a href="/wiki/%E6%B5%B7%E5%B3%BD%E5%85%A9%E5%B2%B8%E9%97%9C%E4%BF%82" title="海峽兩岸關係">海峽兩岸</a>分治後,<a href="/wiki/%E8%87%BA%E5%8C%97%E5%B8%82" title="臺北市">臺北市</a>普遍被中華民國官方及民間認定為首都。參見<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E9%A6%96%E9%83%BD" title="中華民國首都">中華民國首都</a>條目。<br />
<sup>3</sup> 全名為<a href="/wiki/%E6%96%AF%E9%87%8C%E8%B3%88%E4%BA%9E%E7%93%A6%E5%BE%B7%E7%B4%8D%E6%99%AE%E6%8B%89%E7%A7%91%E7%89%B9" title="斯里賈亞瓦德納普拉科特">斯里賈亞瓦德納普拉科特</a>。<br />
<sup>4</sup> 有時會被歸類為<a href="/wiki/%E7%BE%8E%E6%8B%89%E5%B0%BC%E8%A5%BF%E4%BA%9E" class="mw-redirect" title="美拉尼西亞">美拉尼西亞</a>群島之一。<br />
<sup>5</sup> 新加坡是<a href="/wiki/%E5%9F%8E%E9%82%A6%E5%9B%BD" class="mw-redirect" title="城邦国">城邦國</a>。<br />
<sup>6</sup> 国际一般公认以色列首都为<a href="/wiki/%E7%89%B9%E6%8B%89%E7%BB%B4%E5%A4%AB" title="特拉维夫">特拉维夫</a>。<br />
<sup>7</sup> 土耳其國土橫跨亞洲及<a href="/wiki/%E6%AD%90%E6%B4%B2" class="mw-redirect" title="歐洲">歐洲</a>,因而有時會被同時歸類為歐洲國家。<br />
<sup>8</sup> 因<a href="/wiki/%E8%90%A8%E9%82%A3" title="萨那">萨那</a>被<a href="/wiki/%E8%83%A1%E5%A1%9E%E8%BF%90%E5%8A%A8" title="胡塞运动">胡塞运动</a>占领,也门首都临时迁往<a href="/wiki/%E4%BA%9E%E4%B8%81" title="亞丁">亞丁</a>。<br />
<sup>9</sup> 耶路撒冷為巴勒斯坦國主張之首都,實際之<a href="/wiki/%E5%B7%B4%E5%8B%92%E6%96%AF%E5%9D%A6%E6%B0%91%E6%97%8F%E6%9D%83%E5%8A%9B%E6%9C%BA%E6%9E%84" title="巴勒斯坦民族权力机构">政府所在地</a>為<a href="/wiki/%E6%8B%89%E5%A7%86%E5%AE%89%E6%8B%89" title="拉姆安拉">拉姆安拉</a>。<br />
</p>
</div></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E5%A4%8F%E5%AD%A3%E5%A5%A7%E9%81%8B%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82" title="Template:夏季奧運會主辦城市"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/w/index.php?title=Template_talk:%E5%A4%8F%E5%AD%A3%E5%A5%A7%E9%81%8B%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82&action=edit&redlink=1" class="new" title="Template talk:夏季奧運會主辦城市(页面不存在)"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%A4%8F%E5%AD%A3%E5%A5%A7%E9%81%8B%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="夏季奥林匹克运动会">夏季奥林匹克运动会</a><a href="/wiki/%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="奧林匹克運動會主辦城市列表">主办城市</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-odd plainlist" style="width:100%;padding:0px;background:transparent;color:inherit;"><div style="padding:0px;"><table cellspacing="0" class="navbox-columns-table" style="text-align:left;width:100%;"><tbody><tr style="vertical-align:top;"><td style="padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/1896%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1896年夏季奥林匹克运动会">1896</a>:</b><span class="flagicon"><a href="/wiki/%E5%B8%8C%E8%85%8A" title="希腊"><img alt="希腊" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Greece_%281822-1978%29.svg/22px-Flag_of_Greece_%281822-1978%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Greece_%281822-1978%29.svg/33px-Flag_of_Greece_%281822-1978%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Greece_%281822-1978%29.svg/44px-Flag_of_Greece_%281822-1978%29.svg.png 2x" data-file-width="1200" data-file-height="800" /></a></span> <a href="/wiki/%E9%9B%85%E5%85%B8" title="雅典">雅典</a></li>
<li><b><a href="/wiki/1900%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1900年夏季奥林匹克运动会">1900</a>:</b><span class="flagicon"><a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國"><img alt="法國" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">巴黎</a></li>
<li><b><a href="/wiki/1904%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1904年夏季奥林匹克运动会">1904</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Flag_of_the_United_States_%281896%E2%80%931908%29.svg/22px-Flag_of_the_United_States_%281896%E2%80%931908%29.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Flag_of_the_United_States_%281896%E2%80%931908%29.svg/33px-Flag_of_the_United_States_%281896%E2%80%931908%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Flag_of_the_United_States_%281896%E2%80%931908%29.svg/44px-Flag_of_the_United_States_%281896%E2%80%931908%29.svg.png 2x" data-file-width="960" data-file-height="505" /></a></span> <a href="/wiki/%E5%9C%A3%E8%B7%AF%E6%98%93%E6%96%AF_(%E5%AF%86%E8%8B%8F%E9%87%8C%E5%B7%9E)" title="圣路易斯 (密苏里州)">圣路易斯</a></li>
<li><b><a href="/wiki/1908%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1908年夏季奥林匹克运动会">1908</a>:</b><span class="flagicon"><a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国"><img alt="英国" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" data-file-width="1200" data-file-height="600" /></a></span> <a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">伦敦</a></li>
<li><b><a href="/wiki/1912%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1912年夏季奥林匹克运动会">1912</a>:</b><span class="flagicon"><a href="/wiki/%E7%91%9E%E5%85%B8" title="瑞典"><img alt="瑞典" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Flag_of_Sweden.svg/22px-Flag_of_Sweden.svg.png" decoding="async" width="22" height="14" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Flag_of_Sweden.svg/33px-Flag_of_Sweden.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Flag_of_Sweden.svg/44px-Flag_of_Sweden.svg.png 2x" data-file-width="512" data-file-height="320" /></a></span> <a href="/wiki/%E6%96%AF%E5%BE%B7%E5%93%A5%E5%B0%94%E6%91%A9" title="斯德哥尔摩">斯德哥尔摩</a></li>
<li><del><b><a href="/wiki/1916%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1916年夏季奥林匹克运动会">1916</a>:</b><span class="flagicon"><a href="/wiki/%E5%BE%B7%E6%84%8F%E5%BF%97%E5%B8%9D%E5%9B%BD" title="德意志帝国"><img alt="德意志帝国" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Germany_%281867%E2%80%931919%29.svg/22px-Flag_of_Germany_%281867%E2%80%931919%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Germany_%281867%E2%80%931919%29.svg/33px-Flag_of_Germany_%281867%E2%80%931919%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Germany_%281867%E2%80%931919%29.svg/44px-Flag_of_Germany_%281867%E2%80%931919%29.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E6%9F%8F%E6%9E%97" title="柏林">柏林</a></del><sup>(注1)</sup></li>
<li><b><a href="/wiki/1920%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1920年夏季奥林匹克运动会">1920</a>:</b><span class="flagicon"><a href="/wiki/%E6%AF%94%E5%88%A9%E6%97%B6" title="比利时"><img alt="比利时" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Belgium.svg/22px-Flag_of_Belgium.svg.png" decoding="async" width="22" height="19" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Belgium.svg/33px-Flag_of_Belgium.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Belgium.svg/44px-Flag_of_Belgium.svg.png 2x" data-file-width="900" data-file-height="780" /></a></span> <a href="/wiki/%E5%AE%89%E7%89%B9%E5%8D%AB%E6%99%AE" title="安特卫普">安特卫普</a></li>
<li><b><a href="/wiki/1924%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1924年夏季奥林匹克运动会">1924</a>:</b><span class="flagicon"><a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國"><img alt="法國" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">巴黎</a></li>
<li><b><a href="/wiki/1928%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1928年夏季奥林匹克运动会">1928</a>:</b><span class="flagicon"><a href="/wiki/%E8%8D%B7%E5%85%B0" title="荷兰"><img alt="荷兰" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/22px-Flag_of_the_Netherlands.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/33px-Flag_of_the_Netherlands.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/44px-Flag_of_the_Netherlands.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E9%98%BF%E5%A7%86%E6%96%AF%E7%89%B9%E4%B8%B9" title="阿姆斯特丹">阿姆斯特丹</a></li></ul>
</div></td><td style="border-left:2px solid #fdfdfd;padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/1932%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1932年夏季奥林匹克运动会">1932</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f5/Flag_of_the_United_States_%281912-1959%29.svg/22px-Flag_of_the_United_States_%281912-1959%29.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f5/Flag_of_the_United_States_%281912-1959%29.svg/33px-Flag_of_the_United_States_%281912-1959%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f5/Flag_of_the_United_States_%281912-1959%29.svg/44px-Flag_of_the_United_States_%281912-1959%29.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E6%B4%9B%E6%9D%89%E7%9F%B6" title="洛杉矶">洛杉矶</a></li>
<li><b><a href="/wiki/1936%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1936年夏季奥林匹克运动会">1936</a>:</b><span class="flagicon"><a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国"><img alt="德国" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/22px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/33px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/44px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 2x" data-file-width="1000" data-file-height="600" /></a></span> <a href="/wiki/%E6%9F%8F%E6%9E%97" title="柏林">柏林</a></li>
<li><del><b><a href="/wiki/1940%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1940年夏季奥林匹克运动会">1940</a>:</b><span class="flagicon"><a href="/wiki/%E5%A4%A7%E6%97%A5%E6%9C%AC%E5%B8%9D%E5%9B%BD" title="大日本帝国"><img alt="大日本帝国" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" data-file-width="1000" data-file-height="700" /></a></span> <a href="/wiki/%E6%9D%B1%E4%BA%AC%E5%B8%82" title="東京市">東京</a>/<span class="flagicon"><a href="/wiki/%E8%8A%AC%E5%85%B0" title="芬兰"><img alt="芬兰" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/22px-Flag_of_Finland.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/33px-Flag_of_Finland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/44px-Flag_of_Finland.svg.png 2x" data-file-width="1800" data-file-height="1100" /></a></span><a href="/wiki/%E8%B5%AB%E5%B0%94%E8%BE%9B%E5%9F%BA" title="赫尔辛基">赫尔辛基</a></del><sup>(注2)</sup></li>
<li><del><b><a href="/wiki/1944%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1944年夏季奥林匹克运动会">1944</a>:</b><span class="flagicon"><a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国"><img alt="英国" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" data-file-width="1200" data-file-height="600" /></a></span> <a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">伦敦</a></del><sup>(注2)</sup></li>
<li><b><a href="/wiki/1948%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1948年夏季奥林匹克运动会">1948</a>:</b><span class="flagicon"><a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国"><img alt="英国" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" data-file-width="1200" data-file-height="600" /></a></span> <a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">伦敦</a></li>
<li><b><a href="/wiki/1952%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1952年夏季奥林匹克运动会">1952</a>:</b><span class="flagicon"><a href="/wiki/%E8%8A%AC%E5%85%B0" title="芬兰"><img alt="芬兰" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/22px-Flag_of_Finland.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/33px-Flag_of_Finland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/44px-Flag_of_Finland.svg.png 2x" data-file-width="1800" data-file-height="1100" /></a></span> <a href="/wiki/%E8%B5%AB%E5%B0%94%E8%BE%9B%E5%9F%BA" title="赫尔辛基">赫尔辛基</a></li>
<li><b><a href="/wiki/1956%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1956年夏季奥林匹克运动会">1956</a>:</b><span class="flagicon"><a href="/wiki/%E6%BE%B3%E5%A4%A7%E5%88%A9%E4%BA%9A" title="澳大利亚"><img alt="澳大利亚" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/22px-Flag_of_Australia.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/33px-Flag_of_Australia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/44px-Flag_of_Australia.svg.png 2x" data-file-width="1280" data-file-height="640" /></a></span> <a href="/wiki/%E5%A2%A8%E5%B0%94%E6%9C%AC" title="墨尔本">墨尔本</a></li>
<li><b><a href="/wiki/1960%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1960年夏季奥林匹克运动会">1960</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利"><img alt="義大利" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" data-file-width="1500" data-file-height="1000" /></a></span> <a href="/wiki/%E7%BD%97%E9%A9%AC" title="罗马">罗马</a></li>
<li><b><a href="/wiki/1964%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1964年夏季奥林匹克运动会">1964</a>:</b><span class="flagicon"><a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本"><img alt="日本" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" data-file-width="1000" data-file-height="700" /></a></span> <a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">东京</a></li></ul>
</div></td><td style="border-left:2px solid #fdfdfd;padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/1968%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1968年夏季奥林匹克运动会">1968</a>:</b><span class="flagicon"><a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5" title="墨西哥"><img alt="墨西哥" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/22px-Flag_of_Mexico.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/33px-Flag_of_Mexico.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/44px-Flag_of_Mexico.svg.png 2x" data-file-width="980" data-file-height="560" /></a></span> <a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5%E5%9F%8E" title="墨西哥城">墨西哥城</a></li>
<li><b><a href="/wiki/1972%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1972年夏季奥林匹克运动会">1972</a>:</b><span class="flagicon"><a href="/wiki/%E8%A5%BF%E5%BE%B7" title="西德"><img alt="西德" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/22px-Flag_of_Germany.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/33px-Flag_of_Germany.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/44px-Flag_of_Germany.svg.png 2x" data-file-width="1000" data-file-height="600" /></a></span> <a href="/wiki/%E6%85%95%E5%B0%BC%E9%BB%91" title="慕尼黑">慕尼黑</a></li>
<li><b><a href="/wiki/1976%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1976年夏季奥林匹克运动会">1976</a>:</b><span class="flagicon"><a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大"><img alt="加拿大" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" data-file-width="512" data-file-height="256" /></a></span> <a href="/wiki/%E8%92%99%E7%89%B9%E5%88%A9%E5%B0%94" title="蒙特利尔">蒙特利尔</a></li>
<li><b><a href="/wiki/1980%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1980年夏季奥林匹克运动会">1980</a>:</b><span class="flagicon"><a href="/wiki/%E8%8B%8F%E8%81%94" title="苏联"><img alt="苏联" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/ce/Flag_of_the_Soviet_Union_%28dark_version%29.svg/22px-Flag_of_the_Soviet_Union_%28dark_version%29.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/ce/Flag_of_the_Soviet_Union_%28dark_version%29.svg/33px-Flag_of_the_Soviet_Union_%28dark_version%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/ce/Flag_of_the_Soviet_Union_%28dark_version%29.svg/44px-Flag_of_the_Soviet_Union_%28dark_version%29.svg.png 2x" data-file-width="1200" data-file-height="600" /></a></span> <a href="/wiki/%E8%8E%AB%E6%96%AF%E7%A7%91" title="莫斯科">莫斯科</a></li>
<li><b><a href="/wiki/1984%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1984年夏季奥林匹克运动会">1984</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E6%B4%9B%E6%9D%89%E7%9F%B6" title="洛杉矶">洛杉矶</a></li>
<li><b><a href="/wiki/1988%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1988年夏季奥林匹克运动会">1988</a>:</b><span class="flagicon"><a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国"><img alt="大韩民国" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/22px-Flag_of_South_Korea.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/33px-Flag_of_South_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/44px-Flag_of_South_Korea.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E9%A6%96%E7%88%BE" title="首爾">漢城</a></li>
<li><b><a href="/wiki/1992%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1992年夏季奥林匹克运动会">1992</a>:</b><span class="flagicon"><a href="/wiki/%E8%A5%BF%E7%8F%AD%E7%89%99" title="西班牙"><img alt="西班牙" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/22px-Flag_of_Spain.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/33px-Flag_of_Spain.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/44px-Flag_of_Spain.svg.png 2x" data-file-width="750" data-file-height="500" /></a></span> <a href="/wiki/%E5%B7%B4%E5%A1%9E%E7%BD%97%E9%82%A3" title="巴塞罗那">巴塞罗那</a></li>
<li><b><a href="/wiki/1996%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1996年夏季奥林匹克运动会">1996</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E4%BA%9A%E7%89%B9%E5%85%B0%E5%A4%A7" title="亚特兰大">亚特兰大</a></li>
<li><b><a href="/wiki/2000%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2000年夏季奥林匹克运动会">2000</a>:</b><span class="flagicon"><a href="/wiki/%E6%BE%B3%E5%A4%A7%E5%88%A9%E4%BA%9A" title="澳大利亚"><img alt="澳大利亚" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/22px-Flag_of_Australia.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/33px-Flag_of_Australia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/44px-Flag_of_Australia.svg.png 2x" data-file-width="1280" data-file-height="640" /></a></span> <a href="/wiki/%E6%82%89%E5%B0%BC" title="悉尼">悉尼</a></li></ul>
</div></td><td style="border-left:2px solid #fdfdfd;padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/2004%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2004年夏季奥林匹克运动会">2004</a>:</b><span class="flagicon"><a href="/wiki/%E5%B8%8C%E8%85%8A" title="希腊"><img alt="希腊" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/22px-Flag_of_Greece.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/33px-Flag_of_Greece.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/44px-Flag_of_Greece.svg.png 2x" data-file-width="600" data-file-height="400" /></a></span> <a href="/wiki/%E9%9B%85%E5%85%B8" title="雅典">雅典</a></li>
<li><b><a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季奥林匹克运动会">2008</a>:</b><span class="flagicon"><a href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国"><img alt="中国" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a class="mw-selflink selflink">北京</a></li>
<li><b><a href="/wiki/2012%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2012年夏季奥林匹克运动会">2012</a>:</b><span class="flagicon"><a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国"><img alt="英国" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" data-file-width="1200" data-file-height="600" /></a></span> <a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">伦敦</a></li>
<li><b><a href="/wiki/2016%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" class="mw-redirect" title="2016年夏季奥林匹克运动会">2016</a>:</b><span class="flagicon"><a href="/wiki/%E5%B7%B4%E8%A5%BF" title="巴西"><img alt="巴西" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/22px-Flag_of_Brazil.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/33px-Flag_of_Brazil.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/44px-Flag_of_Brazil.svg.png 2x" data-file-width="1060" data-file-height="742" /></a></span> <a href="/wiki/%E9%87%8C%E7%BA%A6%E7%83%AD%E5%86%85%E5%8D%A2" title="里约热内卢">里约热内卢</a></li>
<li><i><b><a href="/wiki/2020%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2020年夏季奥林匹克运动会">2020</a>:</b><span class="flagicon"><a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本"><img alt="日本" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/22px-Flag_of_Japan.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/33px-Flag_of_Japan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/44px-Flag_of_Japan.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">东京</a><sup>(注3)</sup></i></li>
<li><i><b><a href="/wiki/2024%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2024年夏季奥林匹克运动会">2024</a>:</b><span class="flagicon"><a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國"><img alt="法國" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">巴黎</a></i></li>
<li><i><b><a href="/wiki/2028%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2028年夏季奥林匹克运动会">2028</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E6%B4%9B%E6%9D%89%E7%9F%B6" title="洛杉矶">洛杉矶</a></i></li>
<li><i><b><a href="/w/index.php?title=2032%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A&action=edit&redlink=1" class="new" title="2032年夏季奥林匹克运动会(页面不存在)">2032</a>:</b>尚未選出</i></li></ul>
</div></td></tr></tbody></table></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div><sup>(注1)</sup>因<a href="/wiki/%E7%AC%AC%E4%B8%80%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%98" title="第一次世界大战">第一次世界大战</a>取消;<sup>(注2)</sup>因<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%98" title="第二次世界大战">第二次世界大战</a>取消;<sup>(注3)</sup>受<a href="/wiki/2019%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85%E7%96%AB%E6%83%85" title="2019冠状病毒病疫情">2019冠状病毒病疫情</a>影响推迟,但仍保留原定名称</div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E5%86%AC%E5%AD%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Template:冬季奥运会主办城市"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/w/index.php?title=Template_talk:%E5%86%AC%E5%AD%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit&redlink=1" class="new" title="Template talk:冬季奥运会主办城市(页面不存在)"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%86%AC%E5%AD%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="冬季奥林匹克运动会">冬季奥林匹克运动会</a>主办城市</div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-odd plainlist" style="width:100%;padding:0px;background:transparent;color:inherit;"><div style="padding:0px;"><table cellspacing="0" class="navbox-columns-table" style="text-align:left;width:100%;"><tbody><tr style="vertical-align:top;"><td style="padding:0px;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/1924%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1924年冬季奥林匹克运动会">1924</a>:</b><span class="flagicon"><a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國"><img alt="法國" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E9%9C%9E%E6%85%95%E5%B0%BC" class="mw-redirect" title="霞慕尼">霞慕尼</a></li>
<li><b><a href="/wiki/1928%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1928年冬季奥林匹克运动会">1928</a>:</b><span class="flagicon"><a href="/wiki/%E7%91%9E%E5%A3%AB" title="瑞士"><img alt="瑞士" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/20px-Flag_of_Switzerland.svg.png" decoding="async" width="20" height="20" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/30px-Flag_of_Switzerland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/40px-Flag_of_Switzerland.svg.png 2x" data-file-width="512" data-file-height="512" /></a></span> <a href="/wiki/%E5%9C%A3%E8%8E%AB%E9%87%8C%E8%8C%A8" title="圣莫里茨">圣莫里茨</a></li>
<li><b><a href="/wiki/1932%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1932年冬季奥林匹克运动会">1932</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E6%99%AE%E8%90%8A%E8%A5%BF%E5%BE%B7%E6%B9%96" title="普萊西德湖">普萊西德湖</a></li>
<li><b><a href="/wiki/1936%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1936年冬季奥林匹克运动会">1936</a>:</b><span class="flagicon"><a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国"><img alt="德国" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/22px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/33px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/44px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 2x" data-file-width="1000" data-file-height="600" /></a></span> <a href="/wiki/%E5%8A%A0%E7%B1%B3%E6%96%BD-%E5%B8%95%E6%BB%95%E5%9F%BA%E5%85%B4" title="加米施-帕滕基兴">加米施-帕滕基兴</a></li>
<li><del><b><a href="/wiki/1940%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1940年冬季奥林匹克运动会">1940</a>:</b><span class="flagicon"><a href="/wiki/%E5%A4%A7%E6%97%A5%E6%9C%AC%E5%B8%9D%E5%9B%BD" title="大日本帝国"><img alt="大日本帝国" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" data-file-width="1000" data-file-height="700" /></a></span> <a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">札幌</a>/<span class="flagicon"><a href="/wiki/%E7%91%9E%E5%A3%AB" title="瑞士"><img alt="瑞士" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/20px-Flag_of_Switzerland.svg.png" decoding="async" width="20" height="20" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/30px-Flag_of_Switzerland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/40px-Flag_of_Switzerland.svg.png 2x" data-file-width="512" data-file-height="512" /></a></span> <a href="/wiki/%E5%9C%A3%E8%8E%AB%E9%87%8C%E8%8C%A8" title="圣莫里茨">圣莫里茨</a>/<span class="flagicon"><a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国"><img alt="德国" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/22px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png" decoding="async" width="22" height="13" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/33px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/44px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 2x" data-file-width="1000" data-file-height="600" /></a></span> <a href="/wiki/%E5%8A%A0%E7%B1%B3%E6%96%BD-%E5%B8%95%E6%BB%95%E5%9F%BA%E5%85%B4" title="加米施-帕滕基兴">加米施-帕滕基兴</a></del><sup>(注)</sup></li>
<li><del><b><a href="/wiki/1944%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" class="mw-redirect" title="1944年冬季奧林匹克運動會">1944</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利"><img alt="義大利" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Italy_%281861%E2%80%931946%29.svg/22px-Flag_of_Italy_%281861%E2%80%931946%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Italy_%281861%E2%80%931946%29.svg/33px-Flag_of_Italy_%281861%E2%80%931946%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Italy_%281861%E2%80%931946%29.svg/44px-Flag_of_Italy_%281861%E2%80%931946%29.svg.png 2x" data-file-width="1500" data-file-height="1000" /></a></span> <a href="/wiki/%E7%A7%91%E7%88%BE%E8%92%82%E7%B4%8D%E4%B8%B9%E4%BD%A9%E4%BD%90" title="科爾蒂納丹佩佐">科爾蒂納丹佩佐</a></del><sup>(注)</sup></li>
<li><b><a href="/wiki/1948%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1948年冬季奥林匹克运动会">1948</a>:</b><span class="flagicon"><a href="/wiki/%E7%91%9E%E5%A3%AB" title="瑞士"><img alt="瑞士" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/20px-Flag_of_Switzerland.svg.png" decoding="async" width="20" height="20" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/30px-Flag_of_Switzerland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/40px-Flag_of_Switzerland.svg.png 2x" data-file-width="512" data-file-height="512" /></a></span> <a href="/wiki/%E5%9C%A3%E8%8E%AB%E9%87%8C%E8%8C%A8" title="圣莫里茨">圣莫里茨</a></li></ul>
</div></td><td style="border-left:2px solid #fdfdfd;padding:0px;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/1952%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1952年冬季奥林匹克运动会">1952</a>:</b><span class="flagicon"><a href="/wiki/%E6%8C%AA%E5%A8%81" title="挪威"><img alt="挪威" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/22px-Flag_of_Norway.svg.png" decoding="async" width="22" height="16" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/33px-Flag_of_Norway.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/44px-Flag_of_Norway.svg.png 2x" data-file-width="1100" data-file-height="800" /></a></span> <a href="/wiki/%E5%A5%A5%E6%96%AF%E9%99%86" title="奥斯陆">奥斯陆</a></li>
<li><b><a href="/wiki/1956%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1956年冬季奥林匹克运动会">1956</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利"><img alt="義大利" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" data-file-width="1500" data-file-height="1000" /></a></span> <a href="/wiki/%E7%A7%91%E7%88%BE%E8%92%82%E7%B4%8D%E4%B8%B9%E4%BD%A9%E4%BD%90" title="科爾蒂納丹佩佐">科爾蒂納丹佩佐</a></li>
<li><b><a href="/wiki/1960%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1960年冬季奥林匹克运动会">1960</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E6%96%AF%E9%98%94%E8%B0%B7%E6%BB%91%E9%9B%AA%E6%B8%A1%E5%81%87%E8%83%9C%E5%9C%B0" title="斯阔谷滑雪渡假胜地">斯阔谷</a></li>
<li><b><a href="/wiki/1964%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1964年冬季奥林匹克运动会">1964</a>:</b><span class="flagicon"><a href="/wiki/%E5%A5%A5%E5%9C%B0%E5%88%A9" title="奥地利"><img alt="奥地利" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/22px-Flag_of_Austria.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/33px-Flag_of_Austria.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/44px-Flag_of_Austria.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E5%9B%A0%E6%96%AF%E5%B8%83%E9%B2%81%E5%85%8B" title="因斯布鲁克">因斯布鲁克</a></li>
<li><b><a href="/wiki/1968%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" class="mw-redirect" title="1968年冬季奧林匹克運動會">1968</a>:</b><span class="flagicon"><a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國"><img alt="法國" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E6%A0%BC%E5%8B%92%E8%AF%BA%E5%B8%83%E5%B0%94" title="格勒诺布尔">格勒诺布尔</a></li>
<li><b><a href="/wiki/1972%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" class="mw-redirect" title="1972年冬季奧林匹克運動會">1972</a>:</b><span class="flagicon"><a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本"><img alt="日本" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" data-file-width="1000" data-file-height="700" /></a></span> <a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">札幌</a></li>
<li><b><a href="/wiki/1976%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1976年冬季奥林匹克运动会">1976</a>:</b><span class="flagicon"><a href="/wiki/%E5%A5%A5%E5%9C%B0%E5%88%A9" title="奥地利"><img alt="奥地利" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/22px-Flag_of_Austria.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/33px-Flag_of_Austria.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/44px-Flag_of_Austria.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E5%9B%A0%E6%96%AF%E5%B8%83%E9%B2%81%E5%85%8B" title="因斯布鲁克">因斯布鲁克</a></li></ul>
</div></td><td style="border-left:2px solid #fdfdfd;padding:0px;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/1980%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1980年冬季奥林匹克运动会">1980</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E6%99%AE%E8%90%8A%E8%A5%BF%E5%BE%B7%E6%B9%96" title="普萊西德湖">普萊西德湖</a></li>
<li><b><a href="/wiki/1984%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1984年冬季奥林匹克运动会">1984</a>:</b><span class="flagicon"><a href="/wiki/%E5%8D%97%E6%96%AF%E6%8B%89%E5%A4%AB" title="南斯拉夫"><img alt="南斯拉夫" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/61/Flag_of_Yugoslavia_%281946-1992%29.svg/22px-Flag_of_Yugoslavia_%281946-1992%29.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/61/Flag_of_Yugoslavia_%281946-1992%29.svg/33px-Flag_of_Yugoslavia_%281946-1992%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/61/Flag_of_Yugoslavia_%281946-1992%29.svg/44px-Flag_of_Yugoslavia_%281946-1992%29.svg.png 2x" data-file-width="1200" data-file-height="600" /></a></span> <a href="/wiki/%E5%A1%9E%E6%8B%89%E8%80%B6%E4%BD%9B" title="塞拉耶佛">萨拉热窝</a></li>
<li><b><a href="/wiki/1988%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1988年冬季奥林匹克运动会">1988</a>:</b><span class="flagicon"><a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大"><img alt="加拿大" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" data-file-width="512" data-file-height="256" /></a></span> <a href="/wiki/%E5%8D%A1%E5%B0%94%E5%8A%A0%E9%87%8C" title="卡尔加里">卡尔加里</a></li>
<li><b><a href="/wiki/1992%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1992年冬季奥林匹克运动会">1992</a>:</b><span class="flagicon"><a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國"><img alt="法國" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E9%98%BF%E5%B0%94%E8%B4%9D%E7%BB%B4%E5%B0%94" title="阿尔贝维尔">阿尔贝维尔</a></li>
<li><b><a href="/wiki/1994%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1994年冬季奥林匹克运动会">1994</a>:</b><span class="flagicon"><a href="/wiki/%E6%8C%AA%E5%A8%81" title="挪威"><img alt="挪威" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/22px-Flag_of_Norway.svg.png" decoding="async" width="22" height="16" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/33px-Flag_of_Norway.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/44px-Flag_of_Norway.svg.png 2x" data-file-width="1100" data-file-height="800" /></a></span> <a href="/wiki/%E5%88%A9%E5%8B%92%E5%93%88%E9%BB%98%E5%B0%94" title="利勒哈默尔">利勒哈默尔</a></li>
<li><b><a href="/wiki/1998%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1998年冬季奥林匹克运动会">1998</a>:</b><span class="flagicon"><a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本"><img alt="日本" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/22px-Flag_of_Japan.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/33px-Flag_of_Japan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/44px-Flag_of_Japan.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E9%95%B7%E9%87%8E%E5%B8%82" title="長野市">長野</a></li>
<li><b><a href="/wiki/2002%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2002年冬季奥林匹克运动会">2002</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國"><img alt="美國" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" decoding="async" width="22" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" data-file-width="1235" data-file-height="650" /></a></span> <a href="/wiki/%E7%9B%90%E6%B9%96%E5%9F%8E" title="盐湖城">盐湖城</a></li></ul>
</div></td><td style="border-left:2px solid #fdfdfd;padding:0px;;;;width:10em;"><div>
<ul><li><b><a href="/wiki/2006%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2006年冬季奥林匹克运动会">2006</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利"><img alt="義大利" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" data-file-width="1500" data-file-height="1000" /></a></span> <a href="/wiki/%E9%83%BD%E7%81%B5" title="都灵">都灵</a></li>
<li><b><a href="/wiki/2010%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2010年冬季奥林匹克运动会">2010</a>:</b><span class="flagicon"><a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大"><img alt="加拿大" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" decoding="async" width="22" height="11" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" data-file-width="512" data-file-height="256" /></a></span> <a href="/wiki/%E6%BA%AB%E5%93%A5%E8%8F%AF" title="溫哥華">溫哥華</a></li>
<li><b><a href="/wiki/2014%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2014年冬季奥林匹克运动会">2014</a>:</b><span class="flagicon"><a href="/wiki/%E4%BF%84%E7%BD%97%E6%96%AF" title="俄罗斯"><img alt="俄罗斯" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/22px-Flag_of_Russia.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/33px-Flag_of_Russia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/44px-Flag_of_Russia.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E7%B4%A2%E5%A5%91" title="索契">索契</a></li>
<li><b><a href="/wiki/2018%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2018年冬季奥林匹克运动会">2018</a>:</b><span class="flagicon"><a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国"><img alt="大韩民国" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/22px-Flag_of_South_Korea.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/33px-Flag_of_South_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/44px-Flag_of_South_Korea.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a href="/wiki/%E5%B9%B3%E6%98%8C%E9%83%A1" title="平昌郡">平昌</a></li>
<li><i><b><a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季奥林匹克运动会">2022</a>:</b><span class="flagicon"><a href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国"><img alt="中国" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /></a></span> <a class="mw-selflink selflink">北京</a></i></li>
<li><i><b><a href="/wiki/2026%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" title="2026年冬季奧林匹克運動會">2026</a>:</b><span class="flagicon"><a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利"><img alt="義大利" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" data-file-width="1500" data-file-height="1000" /></a></span> <a href="/wiki/%E7%B1%B3%E8%98%AD" title="米蘭">米蘭</a>-<a href="/wiki/%E7%A7%91%E7%88%BE%E8%92%82%E7%B4%8D%E4%B8%B9%E4%BD%A9%E4%BD%90" title="科爾蒂納丹佩佐">科爾蒂納丹佩佐</a></i></li></ul>
</div></td></tr></tbody></table></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div><sup>(注)</sup>因<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%98" title="第二次世界大战">第二次世界大战</a>取消</div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks hlist collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Template:亚洲运动会主办城市"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/w/index.php?title=Template_talk:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit&redlink=1" class="new" title="Template talk:亚洲运动会主办城市(页面不存在)"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲运动会">亚洲运动会</a>主办城市</div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px;background:transparent;color:inherit;"><div style="padding:0px;"><table cellspacing="0" class="navbox-columns-table" style="text-align:left;width:auto;margin-left:auto;margin-right:auto;"></table></div></td><td class="navbox-image" rowspan="5" style="width:0%;padding:0px 0px 0px 2px;padding: 0 0.5em;"><div><a href="/wiki/File:Asian_Games_logo.svg" class="image" title="Asian Games logo"><img alt="Asian Games logo" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/19/Asian_Games_logo.svg/70px-Asian_Games_logo.svg.png" decoding="async" width="70" height="71" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/19/Asian_Games_logo.svg/105px-Asian_Games_logo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/19/Asian_Games_logo.svg/140px-Asian_Games_logo.svg.png 2x" data-file-width="400" data-file-height="406" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲运动会">夏季</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><b><a href="/wiki/1951%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1951年亚洲运动会">1951</a></b>:<a href="/wiki/%E5%BE%B7%E9%87%8C" title="德里">德里</a></li>
<li><b><a href="/wiki/1954%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1954年亚洲运动会">1954</a></b>:<a href="/wiki/%E9%A9%AC%E5%B0%BC%E6%8B%89" title="马尼拉">马尼拉</a></li>
<li><b><a href="/wiki/1958%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1958年亚洲运动会">1958</a></b>:<a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">东京</a></li>
<li><b><a href="/wiki/1962%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1962年亚洲运动会">1962</a></b>:<a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">雅加达</a></li>
<li><b><a href="/wiki/1966%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1966年亚洲运动会">1966</a></b>:<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">曼谷</a></li>
<li><b><a href="/wiki/1970%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1970年亚洲运动会">1970</a></b>:<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">曼谷</a></li>
<li><b><a href="/wiki/1974%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1974年亚洲运动会">1974</a></b>:<a href="/wiki/%E5%BE%B7%E9%BB%91%E5%85%B0" title="德黑兰">德黑兰</a></li>
<li><b><a href="/wiki/1978%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1978年亚洲运动会">1978</a></b>:<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">曼谷</a></li>
<li><b><a href="/wiki/1982%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1982年亚洲运动会">1982</a></b>:<a href="/wiki/%E5%BE%B7%E9%87%8C" title="德里">德里</a></li>
<li><b><a href="/wiki/1986%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1986年亚洲运动会">1986</a></b>:<a href="/wiki/%E9%A6%96%E7%88%BE" title="首爾">首爾</a></li>
<li><b><a href="/wiki/1990%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1990年亚洲运动会">1990</a></b>:<a class="mw-selflink selflink">北京</a></li>
<li><b><a href="/wiki/1994%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1994年亚洲运动会">1994</a></b>:<a href="/wiki/%E5%BB%A3%E5%B3%B6%E5%B8%82" title="廣島市">广岛</a></li>
<li><b><a href="/wiki/1998%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1998年亚洲运动会">1998</a></b>:<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">曼谷</a></li>
<li><b><a href="/wiki/2002%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2002年亚洲运动会">2002</a></b>:<a href="/wiki/%E9%87%9C%E5%B1%B1%E5%BB%A3%E5%9F%9F%E5%B8%82" title="釜山廣域市">釜山</a></li>
<li><b><a href="/wiki/2006%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2006年亚洲运动会">2006</a></b>:<a href="/wiki/%E5%A4%9A%E5%93%88" title="多哈">多哈</a></li>
<li><b><a href="/wiki/2010%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2010年亚洲运动会">2010</a></b>:<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州</a></li>
<li><b><a href="/wiki/2014%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2014年亚洲运动会">2014</a></b>:<a href="/wiki/%E4%BB%81%E5%B7%9D%E5%BB%A3%E5%9F%9F%E5%B8%82" title="仁川廣域市">仁川</a></li>
<li><b><a href="/wiki/2018%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2018年亚洲运动会">2018</a></b>:<a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">雅加达</a>-<a href="/wiki/%E5%B7%A8%E6%B8%AF" title="巨港">巨港</a></li>
<li><b><a href="/wiki/2022%E5%B9%B4%E4%BA%9E%E6%B4%B2%E9%81%8B%E5%8B%95%E6%9C%83" title="2022年亞洲運動會">2022</a></b>:<i><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州</a></i></li>
<li><b><a href="/wiki/2026%E5%B9%B4%E4%BA%9E%E6%B4%B2%E9%81%8B%E5%8B%95%E6%9C%83" title="2026年亞洲運動會">2026</a></b>:<i><a href="/wiki/%E5%90%8D%E5%8F%A4%E5%B1%8B%E5%B8%82" title="名古屋市">名古屋</a></i></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%9A%E6%B4%B2%E5%86%AC%E5%AD%A3%E8%BF%90%E5%8A%A8%E4%BC%9A" class="mw-redirect" title="亚洲冬季运动会">冬季</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><b><a href="/wiki/1986%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1986年亞洲冬季運動會">1986</a></b>:<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">札幌</a></li>
<li><b><a href="/wiki/1990%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1990年亞洲冬季運動會">1990</a></b>:<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">札幌</a></li>
<li><b><a href="/wiki/1996%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1996年亞洲冬季運動會">1996</a></b>:<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">哈尔滨</a></li>
<li><b><a href="/wiki/1999%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1999年亞洲冬季運動會">1999</a></b>:<a href="/wiki/%E6%B1%9F%E5%8E%9F%E9%81%93_(%E9%9F%93%E5%9C%8B)" title="江原道 (韓國)">江原</a></li>
<li><b><a href="/wiki/2003%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2003年亞洲冬季運動會">2003</a></b>:<a href="/wiki/%E9%9D%92%E6%A3%AE%E5%8E%BF" class="mw-redirect" title="青森县">青森</a></li>
<li><b><a href="/wiki/2007%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2007年亞洲冬季運動會">2007</a></b>:<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">长春</a></li>
<li><b><a href="/wiki/2011%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2011年亞洲冬季運動會">2011</a></b>:<a href="/wiki/%E5%8A%AA%E7%88%BE-%E8%98%87%E4%B8%B9" title="努爾-蘇丹">阿斯塔纳</a>-<a href="/wiki/%E9%98%BF%E6%8B%89%E6%9C%A8%E5%9C%96" title="阿拉木圖">阿拉木圖</a></li>
<li><b><a href="/wiki/2017%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2017年亞洲冬季運動會">2017</a></b>:<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">札幌</a></li></ul>
</div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2" style="background: khaki;"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80" title="Template:中國地理大區"><abbr title="查看该模板" style=";background: khaki;;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80" title="Template talk:中國地理大區"><abbr title="讨论该模板" style=";background: khaki;;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80&action=edit"><abbr title="编辑该模板" style=";background: khaki;;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80" title="中國地理大區">中國地理大區</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks collapsible uncollapsed navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="col" class="navbox-title" colspan="3" style=";background:#D8000F; color:#FFFFFF;"><span style="float:left;width:8em;font-size:80%;margin-right:0.5em"> </span><div style="font-size:110%"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国"><span style="color:white;">中华人民共和国</span></a>的分区</div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-image" rowspan="1" style="width:0%;padding:0px 2px 0px 0px"><div><a href="/wiki/File:Regions_of_China_Names_Chinese_Simp.svg" class="image"><img alt="Regions of China Names Chinese Simp.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bb/Regions_of_China_Names_Chinese_Simp.svg/300px-Regions_of_China_Names_Chinese_Simp.svg.png" decoding="async" width="300" height="245" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bb/Regions_of_China_Names_Chinese_Simp.svg/450px-Regions_of_China_Names_Chinese_Simp.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bb/Regions_of_China_Names_Chinese_Simp.svg/600px-Regions_of_China_Names_Chinese_Simp.svg.png 2x" data-file-width="857" data-file-height="699" /></a></div></td><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px"><div style="padding:0em 0.25em"><table><tbody><tr><td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #DAEA7B;color:black;font-size:small; width:1.5em"> </span> <b><a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区">华北</a></b></div></td><td align="left"><a class="mw-selflink selflink">北京</a> · <span class="nowrap"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">山西</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">內蒙古</a></span></td>
</tr><tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #8092D4;color:black;font-size:small; width:1.5em"> </span> <b><a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%9C%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国东北地区">东北</a></b></div></td><td align="left"><a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">辽宁</a> · <span class="nowrap"><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">吉林</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">黑龙江</a></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #99C1FB;color:black;font-size:small; width:1.5em"> </span> <b><a href="/wiki/%E5%8D%8E%E4%B8%9C%E5%9C%B0%E5%8C%BA" title="华东地区">华东</a></b></div></td><td align="left"><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a> · <span class="nowrap"><a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">江苏</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">浙江</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">安徽</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">福建</a><sup><small>1</small></sup> ·</span> <span class="nowrap"><a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">江西</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">山东</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)"><span style="color:grey;">台湾</span></a><sup><small>1</small></sup></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FADB4C;color:black;font-size:small; width:1.5em"> </span> <b><a href="/wiki/%E4%B8%AD%E5%8D%97%E5%9C%B0%E5%8C%BA" class="mw-redirect" title="中南地区">中南</a></b></div></td><td align="left"><a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">河南</a> · <span class="nowrap"><a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">湖北</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">湖南</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">广东</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">广西</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">海南</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%A6%99%E6%B8%AF%E7%89%B9%E5%88%A5%E8%A1%8C%E6%94%BF%E5%8D%80" class="mw-redirect" title="香港特別行政區">香港</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%BE%B3%E9%96%80%E7%89%B9%E5%88%A5%E8%A1%8C%E6%94%BF%E5%8D%80" class="mw-redirect" title="澳門特別行政區">澳門</a></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #DCA9E9;color:black;font-size:small; width:1.5em"> </span> <b><a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中国西南地区">西南</a></b></div></td><td align="left"><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆</a> · <span class="nowrap"><a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">四川</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">贵州</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">云南</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">西藏</a><sup><small>2</small></sup></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFCB78;color:black;font-size:small; width:1.5em"> </span> <b><a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国西北地区">西北</a></b></div></td><td align="left"><a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">陕西</a> · <span class="nowrap"><a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">甘肃</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">青海</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">宁夏</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">新疆</a></span></td>
</tr>
<tr><td colspan="2" align="left"><b>註:</b>
<p><span style="position: relative; top: 0.2em;"><sup>1</sup></span> <a href="/wiki/%E5%8F%B0%E6%B9%BE" class="mw-redirect" title="台湾">台湾</a>、<a href="/wiki/%E6%BE%8E%E6%B9%96" class="mw-redirect" title="澎湖">澎湖</a>、<a href="/wiki/%E9%87%91%E9%97%A8" class="mw-redirect" title="金门">金门</a>、<a href="/wiki/%E9%A6%AC%E7%A5%96%E5%88%97%E5%B3%B6" title="馬祖列島">马祖</a>等地实际仍由<a href="/wiki/%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD%E6%94%BF%E5%BA%9C" class="mw-redirect" title="中华民国政府">中华民国政府</a>管辖。关于台澎归属问题,详见<a href="/wiki/%E5%8F%B0%E6%B9%BE%E9%97%AE%E9%A2%98" class="mw-redirect" title="台湾问题">台灣问题</a>;关于金马归属问题,详见<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)#國共內戰再起" title="福建省 (中華民國)">金马地区沿革</a>。
</p>
<span style="position: relative; top: 0.2em;"><sup>2</sup></span> <a href="/wiki/%E8%97%8F%E5%8D%97%E5%9C%B0%E5%8D%80" title="藏南地區">藏南地區</a>現由<a href="/wiki/%E5%8D%B0%E5%BA%A6" title="印度">印度</a>實際管轄,詳見<a href="/wiki/%E4%B8%AD%E5%8D%B0%E9%82%8A%E7%95%8C%E5%95%8F%E9%A1%8C" class="mw-redirect" title="中印邊界問題">中印邊界問題</a>。</td>
</tr></tbody></table></div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td colspan="2" class="navbox-list navbox-even" style="width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="col" class="navbox-title" colspan="3" style=";background:#002864;color:white"><span style="float:left;width:8em;font-size:80%;margin-right:0.5em"> </span><div style="font-size:110%"><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國"><span style="color:white;">中華民國</span></a>的分区</div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-image" rowspan="1" style="width:0%;padding:0px 2px 0px 0px"><div><a href="/wiki/File:ROC_Geo_Regions_Text.png" class="image"><img alt="ROC Geo Regions Text.png" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fb/ROC_Geo_Regions_Text.png/300px-ROC_Geo_Regions_Text.png" decoding="async" width="300" height="250" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fb/ROC_Geo_Regions_Text.png/450px-ROC_Geo_Regions_Text.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fb/ROC_Geo_Regions_Text.png/600px-ROC_Geo_Regions_Text.png 2x" data-file-width="781" data-file-height="650" /></a></div></td><td colspan="2" class="navbox-list navbox-odd" style="width:100%;padding:0px"><div style="padding:0em 0.25em"><table><tbody><tr><td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #AAFFAA;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E5%8D%8E%E4%B8%AD%E5%9C%B0%E5%8C%BA" title="华中地区"><b>華中</b></a></div></td><td align="left"><a href="/wiki/%E6%B1%9F%E8%98%87%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="江蘇省 (中華民國)">江蘇</a> · <span class="nowrap"><a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="浙江省 (中華民國)">浙江</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="安徽省 (中華民國)">安徽</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="江西省 (中華民國)">江西</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="湖北省 (中華民國)">湖北</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="湖南省 (中華民國)">湖南</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="四川省 (中華民國)">四川</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">南京市</a> ·</span> <span class="nowrap"><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="上海市 (中華民國)">上海市</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82" class="mw-redirect" title="重慶市">重慶市</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%BC%A2%E5%8F%A3%E5%B8%82" title="漢口市">漢口市</a></span></td>
</tr><tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #AAFFFF;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E5%8D%8E%E5%8D%97%E5%9C%B0%E5%8C%BA" title="华南地区"><b>華南</b></a></div></td><td align="left"><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="福建省 (中華民國)">福建</a> · <span class="nowrap"><a href="/wiki/%E8%87%BA%E7%81%A3%E7%9C%81" title="臺灣省">臺灣</a><sup><small>1</small></sup> ·</span> <span class="nowrap"><a href="/wiki/%E5%BB%A3%E6%9D%B1%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣東省 (中華民國)">廣東</a><sup><small>3</small></sup> ·</span> <span class="nowrap"><a href="/wiki/%E5%BB%A3%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣西省 (中華民國)">廣西</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9B%B2%E5%8D%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="雲南省 (中華民國)">雲南</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%B2%B4%E5%B7%9E%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="貴州省 (中華民國)">貴州</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B5%B7%E5%8D%97%E7%89%B9%E5%88%A5%E8%A1%8C%E6%94%BF%E5%8D%80" title="海南特別行政區">海南特別行政區</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82" class="mw-redirect" title="廣州市">廣州市</a></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFFFAA;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区"><b>華北</b></a></div></td><td align="left"><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="河北省 (中華民國)">河北</a> · <span class="nowrap"><a href="/wiki/%E5%B1%B1%E6%9D%B1%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="山東省 (中華民國)">山東</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="河南省 (中華民國)">河南</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="山西省 (中華民國)">山西</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%99%9D%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="陝西省 (中華民國)">陝西</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%94%98%E8%82%85%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="甘肅省 (中華民國)">甘肅</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">北平市</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%9D%92%E5%B3%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="青島市 (中華民國)">青島市</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安市</a></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFD4AA;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E5%A1%9E%E5%8C%97" title="塞北"><b>塞北</b></a></div></td><td align="left"><a href="/wiki/%E5%AF%A7%E5%A4%8F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="寧夏省 (中華民國)">寧夏</a> · <span class="nowrap"><a href="/wiki/%E7%B6%8F%E9%81%A0%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="綏遠省 (中華民國)">綏遠</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AF%9F%E5%93%88%E7%88%BE%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="察哈爾省 (中華民國)">察哈爾</a> ·</span> <span class="nowrap"><a href="/wiki/%E7%86%B1%E6%B2%B3%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="熱河省 (中華民國)">熱河</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%92%99%E5%8F%A4%E5%9C%B0%E6%96%B9" title="蒙古地方">蒙古地方</a><sup><small>2</small></sup></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFAAAA;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E6%9D%B1%E5%8C%97%E6%96%B0%E7%9C%81%E5%8D%80%E6%96%B9%E6%A1%88" title="東北新省區方案"><b>東北</b></a></div></td><td align="left"><a href="/wiki/%E9%81%BC%E5%AF%A7%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="遼寧省 (中華民國)">遼寧</a> · <span class="nowrap"><a href="/wiki/%E5%AE%89%E6%9D%B1%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="安東省 (中華民國)">安東</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%81%BC%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" class="mw-redirect" title="遼北省 (中華民國)">遼北</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="吉林省 (中華民國)">吉林</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%9D%BE%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="松江省 (中華民國)">松江</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%90%88%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" class="mw-redirect" title="合江省 (中華民國)">合江</a> ·</span> <span class="nowrap"><a href="/wiki/%E9%BB%91%E9%BE%8D%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="黑龍江省 (中華民國)">黑龍江</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%AB%A9%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" class="mw-redirect" title="嫩江省 (中華民國)">嫩江</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%88%88%E5%AE%89%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="興安省 (中華民國)">興安</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%A4%A7%E9%80%A3%E5%B8%82" class="mw-redirect" title="大連市">大連市</a> ·</span> <span class="nowrap"><a href="/wiki/%E5%93%88%E7%88%BE%E6%BF%B1%E5%B8%82" class="mw-redirect" title="哈爾濱市">哈爾濱市</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">瀋陽市</a></span></td>
</tr>
<tr>
<td><div class="legend"><span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #D4AAFF;color:black;font-size:small; width:1.5em"> </span> <a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E9%83%A8" title="中国西部"><b>西部</b></a></div></td><td align="left"><a href="/wiki/%E8%A5%BF%E5%BA%B7%E7%9C%81" title="西康省">西康</a> · <span class="nowrap"><a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="青海省 (中華民國)">青海</a> ·</span> <span class="nowrap"><a href="/wiki/%E6%96%B0%E7%96%86%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="新疆省 (中華民國)">新疆</a> ·</span> <span class="nowrap"><a href="/wiki/%E8%A5%BF%E8%97%8F%E5%9C%B0%E6%96%B9" title="西藏地方">西藏地方</a></span></td>
</tr>
<tr>
<td colspan="2" align="left"><b>註:</b>此為1949年以前<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a>統治<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86" title="中国大陆">中国大陆</a>時所使用的分區,現已不再适用。
<p><span style="position: relative; top: 0.2em;"><sup>1</sup></span> 1912年中華民國成立之时台湾仍为<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">日本</a>属土,1945年日本戰敗投降后<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E6%94%BF%E5%BA%9C" title="中華民國政府">中華民國政府</a>接收並統治至今,詳見<a href="/wiki/%E5%8F%B0%E6%B9%BE%E5%85%89%E5%A4%8D" class="mw-redirect" title="台湾光复">台湾光复</a>、<a href="/wiki/%E5%8F%B0%E7%81%A3%E5%95%8F%E9%A1%8C" class="mw-redirect" title="台灣問題">台灣問題</a>。
</p><p><span style="position: relative; top: 0.2em;"><sup>2</sup></span> 即<a href="/wiki/%E5%A4%96%E8%92%99%E5%8F%A4" title="外蒙古">外蒙古</a>与<a href="/wiki/%E5%94%90%E5%8A%AA%E4%B9%8C%E6%A2%81%E6%B5%B7" title="唐努乌梁海">唐努乌梁海</a>地区,<a href="/wiki/%E5%A4%96%E8%92%99%E5%8F%A4" title="外蒙古">外蒙古</a>已成為主權獨立且受國際普遍承認之<a href="/wiki/%E8%92%99%E5%8F%A4%E5%9C%8B" class="mw-redirect" title="蒙古國">蒙古國</a>,中華民國政府亦然,並於2012年5月發新聞稿表示其非中華民國之「固有疆域」;<a href="/wiki/%E5%94%90%E5%8A%AA%E4%B9%8C%E6%A2%81%E6%B5%B7" title="唐努乌梁海">唐努乌梁海</a>地区于1921年成立<a href="/wiki/%E5%94%90%E5%8A%AA%EF%BC%8D%E5%9B%BE%E7%93%A6%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" class="mw-redirect" title="唐努-图瓦人民共和国">唐努-图瓦</a>,随后被<a href="/wiki/%E8%8B%8F%E8%81%94" title="苏联">苏联</a>吞并,<a href="/wiki/%E8%8B%8F%E8%81%94%E8%A7%A3%E4%BD%93" title="苏联解体">苏联解体</a>后被<a href="/wiki/%E4%BF%84%E7%BD%97%E6%96%AF" title="俄罗斯">俄罗斯</a>继承。
</p>
<span style="position: relative; top: 0.2em;"><sup>3</sup></span> 广东省的<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港</a>和<a href="/wiki/%E6%BE%B3%E9%97%A8" class="mw-redirect" title="澳门">澳门</a>彼時分别為<a href="/wiki/%E5%A4%A7%E8%8B%B1%E5%B8%9D%E5%9B%BD" title="大英帝国">英國</a>与<a href="/wiki/%E8%91%A1%E8%90%84%E7%89%99" title="葡萄牙">葡萄牙</a>殖民地,詳見<a href="/wiki/%E8%8B%B1%E5%B1%AC%E9%A6%99%E6%B8%AF" title="英屬香港">英屬香港</a>及<a href="/wiki/%E8%91%A1%E5%B1%9E%E6%BE%B3%E9%97%A8" class="mw-redirect" title="葡属澳门">葡属澳门</a>。</td>
</tr></tbody></table></div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2" style="background: khaki;"><div>另见:<b><a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9C%B0%E7%90%86" title="中国地理">中国地理</a></b></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="Template:中国直辖市"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="Template talk:中国直辖市"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/%E4%B8%AD%E5%9B%BD" class="mw-redirect" title="中国">中国</a><a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">直辖市</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;">附:<span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/22px-Flag_of_China_%281912%E2%80%931928%29.svg.png" decoding="async" width="22" height="14" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/33px-Flag_of_China_%281912%E2%80%931928%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/44px-Flag_of_China_%281912%E2%80%931928%29.svg.png 2x" data-file-width="960" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E5%A4%A7%E9%99%B8%E6%99%82%E6%9C%9F" title="中華民國大陸時期">中华民国</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><sub>(注)</sub><br /><sub>(1921年7月-1928年7月)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E4%BA%AC%E9%83%BD%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD)&action=edit&redlink=1" class="new" title="京都市 (中华民国)(页面不存在)">京都市</a><sub>(受内务总长监督)</sub></li>
<li><a href="/w/index.php?title=%E6%B4%A5%E6%B2%BD%E5%B8%82&action=edit&redlink=1" class="new" title="津沽市(页面不存在)">津沽市</a><sub>(受直隶省省长监督)</sub></li>
<li><a href="/w/index.php?title=%E6%B7%9E%E6%BB%AC%E5%B8%82&action=edit&redlink=1" class="new" title="淞滬市(页面不存在)">淞滬市</a><sub>(受江苏省省长监督)</sub></li>
<li><a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">青岛市</a><sub>(受山东省省长监督)</sub></li>
<li><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="哈尔滨特别市">哈尔滨特别市</a><sub>(受<a href="/wiki/%E4%B8%9C%E7%9C%81%E7%89%B9%E5%88%AB%E5%8C%BA%E8%A1%8C%E6%94%BF%E9%95%BF%E5%AE%98" title="东省特别区行政长官">东省特别区行政长官</a>监督)</sub></li>
<li><a href="/wiki/%E6%BC%A2%E5%8F%A3%E5%B8%82" title="漢口市">汉口市</a><sub>(受湖北省省长监督)</sub></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/22px-Flag_of_the_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/33px-Flag_of_the_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/44px-Flag_of_the_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1928年7月-1930年5月)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E4%BA%AC%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="南京特別市">南京特别市</a> <span class="nowrap">→ <a href="/wiki/%E9%A6%96%E9%83%BD%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="首都特別市">首都特别市</a></span></li>
<li><a href="/wiki/%E5%8C%97%E5%B9%B3%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="北平特別市">北平特别市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="天津特别市">天津特别市</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B3%B6%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="青島特別市">青岛特别市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="上海特别市">上海特别市</a></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="武汉特别市">武汉特别市</a> <span class="nowrap">→ <a href="/wiki/%E6%BC%A2%E5%8F%A3%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="漢口特別市">汉口特别市</a></span></li>
<li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="广州特别市">广州特别市</a></li>
<li><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="哈尔滨特别市">哈尔滨特别市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/22px-Flag_of_the_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/33px-Flag_of_the_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/44px-Flag_of_the_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">中華民國</a><a href="/wiki/%E9%99%A2%E8%BE%96%E5%B8%82" class="mw-redirect" title="院辖市">院辖市</a><br /><sub>(1930年5月-1949年)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">南京市</a></li>
<li><a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">北平市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="天津市 (中華民國)">天津市</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B3%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="青島市 (中華民國)">青岛市</a></li>
<li><a href="/wiki/%E8%A5%BF%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD)" class="mw-redirect" title="西京市 (中华民国)">西京市</a> <span class="nowrap">→ <a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="西安市 (中華民國)">西安市</a>(1948年改制)</span></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="上海市 (中華民國)">上海市</a></li>
<li><a href="/wiki/%E6%BC%A2%E5%8F%A3%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" class="mw-redirect" title="漢口市 (中華民國)">汉口市</a></li>
<li><a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣州市 (中華民國)">广州市</a></li>
<li><a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="重慶市 (中華民國)">重庆市</a>(1939年改制)</li>
<li><a href="/wiki/%E5%A4%A7%E9%80%A3%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="大連市 (中華民國)">大连市</a>(1945年改制)</li>
<li><a href="/wiki/%E5%93%88%E7%88%BE%E6%BF%B1%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="哈爾濱市 (中華民國)">哈尔滨市</a>(1947年改制)</li>
<li><a href="/wiki/%E7%80%8B%E9%99%BD%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="瀋陽市 (中華民國)">沈阳市</a>(1947年改制)</li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8c/Flag_of_Manchukuo.svg/22px-Flag_of_Manchukuo.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8c/Flag_of_Manchukuo.svg/33px-Flag_of_Manchukuo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8c/Flag_of_Manchukuo.svg/44px-Flag_of_Manchukuo.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E6%BB%A1%E6%B4%B2%E5%9B%BD" title="满洲国">滿洲國</a> <span class="nowrap">→ <a href="/wiki/%E6%BB%BF%E6%B4%B2%E5%B8%9D%E5%9C%8B" class="mw-redirect" title="滿洲帝國">满洲帝国</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1932年-1945年)</sub></span></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%95%BF%E6%98%A5%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="长春特别市">长春特别市</a> <span class="nowrap">→ <a href="/wiki/%E6%96%B0%E4%BA%AC" title="新京">新京特别市</a></span></li>
<li><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="哈尔滨特别市">哈尔滨特别市</a><sub>(1933年-1937年)</sub></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><a href="/wiki/File:Flag_of_Fujian_People%27s_Government.svg" class="image"><img alt="Flag of Fujian People's Government.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Fujian_People%27s_Government.svg/25px-Flag_of_Fujian_People%27s_Government.svg.png" decoding="async" width="25" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Fujian_People%27s_Government.svg/38px-Flag_of_Fujian_People%27s_Government.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Fujian_People%27s_Government.svg/50px-Flag_of_Fujian_People%27s_Government.svg.png 2x" data-file-width="900" data-file-height="600" /></a> <a href="/wiki/%E4%B8%AD%E5%8D%8E%E5%85%B1%E5%92%8C%E5%9B%BD" class="mw-redirect" title="中华共和国">中华共和国</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1933年-1934年)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E7%A6%8F%E5%B7%9E%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="福州特别市(页面不存在)">福州特别市</a></li>
<li><a href="/w/index.php?title=%E5%8E%A6%E9%97%A8%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="厦门特别市(页面不存在)">厦门特别市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><a href="/wiki/File:Flag_of_Mongol_United_Autonomous_Government_(1937-1939).svg" class="image"><img alt="Flag of Mongol United Autonomous Government (1937-1939).svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg/25px-Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg.png" decoding="async" width="25" height="15" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg/38px-Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg/50px-Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg.png 2x" data-file-width="737" data-file-height="434" /></a> <a href="/wiki/%E8%92%99%E5%8F%A4%E8%81%94%E7%9B%9F%E8%87%AA%E6%B2%BB%E6%94%BF%E5%BA%9C" title="蒙古联盟自治政府">蒙古联盟自治政府</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1937年-1939年)</sub></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E5%8E%9A%E5%92%8C%E8%B1%AA%E7%89%B9%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="厚和豪特特别市(页面不存在)">厚和豪特特别市</a> <span class="nowrap">→ <a href="/wiki/%E5%8E%9A%E5%92%8C%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="厚和特别市">厚和特别市</a></span></li>
<li><a href="/w/index.php?title=%E5%8C%85%E5%A4%B4%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="包头特别市(页面不存在)">包头特别市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><a href="/wiki/File:Flag_of_the_Mengjiang.svg" class="image"><img alt="Flag of the Mengjiang.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6d/Flag_of_the_Mengjiang.svg/25px-Flag_of_the_Mengjiang.svg.png" decoding="async" width="25" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6d/Flag_of_the_Mengjiang.svg/38px-Flag_of_the_Mengjiang.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6d/Flag_of_the_Mengjiang.svg/50px-Flag_of_the_Mengjiang.svg.png 2x" data-file-width="450" data-file-height="300" /></a> <a href="/wiki/%E8%92%99%E7%96%86%E8%81%94%E5%90%88%E8%87%AA%E6%B2%BB%E6%94%BF%E5%BA%9C" class="mw-redirect" title="蒙疆联合自治政府">蒙疆联合自治政府</a> <span class="nowrap">→ <a href="/wiki/%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E9%82%A6" class="mw-redirect" title="蒙古自治邦">蒙古自治邦</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1939年-1945年)</sub></span></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="张家口特别市">张家口特别市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國"><img alt="中華民國" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/22px-Flag_of_China_%281912%E2%80%931928%29.svg.png" decoding="async" width="22" height="14" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/33px-Flag_of_China_%281912%E2%80%931928%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/44px-Flag_of_China_%281912%E2%80%931928%29.svg.png 2x" data-file-width="960" data-file-height="600" /></a></span> <a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E8%87%A8%E6%99%82%E6%94%BF%E5%BA%9C_(1937%E2%80%931940)" class="mw-redirect" title="中華民國臨時政府 (1937–1940)">中华民国临时政府</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1937年-1940年)</sub></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="北京特别市(页面不存在)">北京特别市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="天津特别市">天津特别市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><a href="/wiki/File:Flag_of_Reformed_Government_of_the_Republic_of_China.svg" class="image"><img alt="Flag of Reformed Government of the Republic of China.svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Flag_of_Reformed_Government_of_the_Republic_of_China.svg/25px-Flag_of_Reformed_Government_of_the_Republic_of_China.svg.png" decoding="async" width="25" height="16" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Flag_of_Reformed_Government_of_the_Republic_of_China.svg/38px-Flag_of_Reformed_Government_of_the_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Flag_of_Reformed_Government_of_the_Republic_of_China.svg/50px-Flag_of_Reformed_Government_of_the_Republic_of_China.svg.png 2x" data-file-width="480" data-file-height="300" /></a> <a href="/wiki/%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD%E7%BB%B4%E6%96%B0%E6%94%BF%E5%BA%9C" class="mw-redirect" title="中华民国维新政府">中华民国维新政府</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1938年-1940年)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E4%BA%AC%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="南京特別市">南京特别市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="上海特别市">上海特别市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><a href="/wiki/File:Flag_of_the_Republic_of_China-Nanjing_(Peace,_Anti-Communism,_National_Construction).svg" class="image"><img alt="Flag of the Republic of China-Nanjing (Peace, Anti-Communism, National Construction).svg" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/08/Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg/25px-Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg.png" decoding="async" width="25" height="23" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/08/Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg/38px-Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/08/Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg/50px-Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg.png 2x" data-file-width="900" data-file-height="825" /></a> <a href="/wiki/%E6%B1%AA%E7%B2%BE%E5%8D%AB%E6%94%BF%E6%9D%83" title="汪精卫政权">汪精卫政权</a><a href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="特别市">特别市</a><br /><sub>(1940年-1945年)</sub></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E4%BA%AC%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="南京特別市">南京特别市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="上海特别市">上海特别市</a></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="武汉特别市">武汉特别市</a> <span class="nowrap">→ <a href="/wiki/%E6%BC%A2%E5%8F%A3%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="漢口特別市">汉口特别市</a></span></li>
<li><a href="/w/index.php?title=%E5%8E%A6%E9%97%A8%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="厦门特别市(页面不存在)">厦门特别市</a></li></ul>
</div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%8E%E5%8C%97%E6%94%BF%E5%8A%A1%E5%A7%94%E5%91%98%E4%BC%9A" title="华北政务委员会">华北政务委员会</a>直属</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" class="new" title="北京特别市(页面不存在)">北京特别市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E7%89%B9%E5%88%AB%E5%B8%82" class="mw-redirect" title="天津特别市">天津特别市</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B3%B6%E7%89%B9%E5%88%A5%E5%B8%82" class="mw-redirect" title="青島特別市">青岛特别市</a></li></ul>
</div></td></tr></tbody></table><div>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="中华人民共和国直辖市">直辖市</a><br /><sub>(1949年-1953年)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C_(1949%E5%B9%B4%EF%BC%8D1954%E5%B9%B4)" title="中華人民共和國中央人民政府 (1949年-1954年)">中央</a>直属</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/w/index.php?title=%E5%A4%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E7%9B%B4%E8%BE%96%E5%B8%82&action=edit&redlink=1" class="new" title="大行政区直辖市(页面不存在)">大区直属</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>华东:<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="南京市 (中华人民共和国直辖市)">南京市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a><br />中南:<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="武汉市 (中华人民共和国直辖市)">武汉市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="广州市 (中华人民共和国直辖市)">广州市</a><br />西南:<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆市</a><br />西北:<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="西安市 (中华人民共和国直辖市)">西安市</a><br /><a href="/wiki/%E4%B8%9C%E5%8C%97%E5%A4%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="东北大行政区">东北</a>:<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="沈阳市 (中华人民共和国直辖市)">沈阳市</a></li>
<li><a href="/wiki/%E6%97%85%E5%A4%A7%E5%B8%82" title="旅大市">旅大市</a></li>
<li><a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="鞍山市 (中华人民共和国直辖市)">鞍山市</a></li>
<li><a href="/wiki/%E6%8A%9A%E9%A1%BA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="抚顺市 (中华人民共和国直辖市)">抚顺市</a></li>
<li><a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="本溪市 (中华人民共和国直辖市)">本溪市</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="中华人民共和国直辖市">直辖市</a><br /><sub>(1953年-1954年)</sub></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a></li>
<li><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="南京市 (中华人民共和国直辖市)">南京市</a></li>
<li><a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="沈阳市 (中华人民共和国直辖市)">沈阳市</a></li>
<li><a href="/wiki/%E6%97%85%E5%A4%A7%E5%B8%82" title="旅大市">旅大市</a></li>
<li><a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="鞍山市 (中华人民共和国直辖市)">鞍山市</a></li>
<li><a href="/wiki/%E6%8A%9A%E9%A1%BA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="抚顺市 (中华人民共和国直辖市)">抚顺市</a></li>
<li><a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="本溪市 (中华人民共和国直辖市)">本溪市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="广州市 (中华人民共和国直辖市)">广州市</a></li>
<li><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆市</a></li>
<li><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="西安市 (中华人民共和国直辖市)">西安市</a></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="武汉市 (中华人民共和国直辖市)">武汉市</a></li>
<li><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="哈尔滨市 (中华人民共和国直辖市)">哈尔滨市</a></li>
<li><a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="长春市 (中华人民共和国直辖市)">长春市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: left;"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="中华人民共和国直辖市">直辖市</a><br /><sub>(1954年至今)</sub></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a><sub>(1958年–1967年划归河北省)</sub></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a></li>
<li><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆市</a><sub>(1954年–1997年划归四川省)</sub></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2"><div>参见:<a href="/w/index.php?title=%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82%E5%88%97%E8%A1%A8&action=edit&redlink=1" class="new" title="中国直辖市列表(页面不存在)">中国直辖市列表</a><br /><small>注:该“特别市”是1921年7月3日北洋政府頒布的《市自治制》中规定的和“普通市”相对的市,并不等同于直辖市。后来成立或拟成立的各特别市中,除<a href="/w/index.php?title=%E4%BA%AC%E9%83%BD%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD)&action=edit&redlink=1" class="new" title="京都市 (中华民国)(页面不存在)">京都市</a>受内务总长监督,尚可算作直辖市外,其余各特别市均受省级行政长官监督,并非直辖市。姑列于此,供参考。</small></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国中心城市"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Template talk:中华人民共和国中心城市"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a>中心<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%BB%BA%E5%88%B6" title="中华人民共和国城市建制">城市</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="国家中心城市">国家中心城市</a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="text-align: center;">2005年正式版</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州</a></li>
<li><a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">香港</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;">2010年草案版</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海</a></li>
<li><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;">2016年后续版</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉</a></li>
<li><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州</a></li>
<li><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安</a></li></ul>
</div></td></tr></tbody></table><div></div></td><td class="navbox-image" rowspan="3" style="width:0%;padding:0px 0px 0px 2px"><div><a href="/wiki/File:Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png" class="image"><img alt="Map of National central cities in the People's Republic of China.png" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d0/Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png/200px-Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png" decoding="async" width="200" height="163" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d0/Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png/300px-Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d0/Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png/400px-Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png 2x" data-file-width="2677" data-file-height="2183" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8C%BA%E5%9F%9F%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="区域中心城市">区域中心城市</a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group" style="text-align: center;">2005年正式版</th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">华北:<a href="/wiki/%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%B8%82" title="石家庄市">石家庄</a>
<ul><li><a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">太原</a></li>
<li><a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">呼和浩特</a><br />东北:<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">沈阳</a></li>
<li><a href="/wiki/%E5%A4%A7%E8%BF%9E%E5%B8%82" title="大连市">大连</a></li>
<li><a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">长春</a></li>
<li><a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">哈尔滨</a><br />华东:<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京</a></li>
<li><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州</a></li>
<li><a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">宁波</a></li>
<li><a href="/wiki/%E5%8E%A6%E9%97%A8%E5%B8%82" title="厦门市">厦门</a></li>
<li><a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">济南</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">青岛</a></li>
<li><a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">福州</a></li>
<li><a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">南昌</a></li>
<li><a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">合肥</a><br />中南:<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉</a></li>
<li><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州</a></li>
<li><a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳</a></li>
<li><a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">长沙</a></li>
<li><a href="/wiki/%E5%8D%97%E5%AE%81%E5%B8%82" title="南宁市">南宁</a></li>
<li><a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">海口</a><br />西南:<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆</a></li>
<li><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a></li>
<li><a href="/wiki/%E8%B4%B5%E9%98%B3%E5%B8%82" title="贵阳市">贵阳</a></li>
<li><a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">昆明</a><br />西北:<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安</a></li>
<li><a href="/wiki/%E5%85%B0%E5%B7%9E%E5%B8%82" title="兰州市">兰州</a></li>
<li><a href="/wiki/%E8%A5%BF%E5%AE%81%E5%B8%82" title="西宁市">西宁</a></li>
<li><a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">银川</a></li>
<li><a href="/wiki/%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%B8%82" title="乌鲁木齐市">乌鲁木齐</a></li></ul></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="text-align: center;">2010年草案版</th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"><a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">沈阳</a><small>(东北)</small>
<li><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京</a><small>(华东)</small></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉</a><small>(华中)</small></li>
<li><a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳</a><small>(华南)</small></li>
<li><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都</a><small>(西南)</small></li>
<li><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安</a><small>(西北)</small></li></div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3"><div>注:<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="国家中心城市">国家中心城市</a>在《<a href="/w/index.php?title=%E5%85%A8%E5%9B%BD%E5%9F%8E%E9%95%87%E4%BD%93%E7%B3%BB%E8%A7%84%E5%88%92%E7%BA%B2%E8%A6%81&action=edit&redlink=1" class="new" title="全国城镇体系规划纲要(页面不存在)">全国城镇体系规划纲要</a>(2005-2020年)》中称“<a href="/wiki/%E5%85%A8%E7%90%83%E5%9F%8E%E5%B8%82" title="全球城市">全球职能城市</a>”,概念略有不同。</div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks hlist collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="3"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区"><abbr title="查看该模板" style=";;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template talk:中华人民共和国地级以上行政区"><abbr title="讨论该模板" style=";;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA&action=edit"><abbr title="编辑该模板" style=";;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="22" height="15" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /> </span><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">中华人民共和国</a><a href="/wiki/%E5%9C%B0%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="地级行政区">地级</a>以上<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">行政区</a></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3"><div>
<ul><li>☆1个<a href="/wiki/%E5%89%AF%E7%9C%81%E7%BA%A7%E8%87%AA%E6%B2%BB%E5%B7%9E" title="副省级自治州">副省级自治州</a>、★15个<a href="/wiki/%E5%89%AF%E7%9C%81%E7%BA%A7%E5%B8%82" title="副省级市">副省级市</a>、✦5个<a href="/wiki/%E8%AE%A1%E5%88%92%E5%8D%95%E5%88%97%E5%B8%82" title="计划单列市">计划单列市</a>、✧18个<a href="/wiki/%E8%BE%83%E5%A4%A7%E7%9A%84%E5%B8%82" title="较大的市">经国务院批准的较大的市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%80%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="一级行政区">中央直属</a><br /><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%BB%BA%E5%88%B6" title="中华人民共和国城市建制">市域</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82#中华人民共和国" title="直辖市">直辖市</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">天津市</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a></li>
<li><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">重庆市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" title="特别行政区">特别行政区</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%A6%99%E6%B8%AF%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" class="mw-redirect" title="香港特别行政区">香港特别行政区</a></li>
<li><a href="/wiki/%E6%BE%B3%E9%97%A8%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" class="mw-redirect" title="澳门特别行政区">澳门特别行政区</a></li></ul>
</div></td></tr></tbody></table><div></div></td><td class="navbox-image" rowspan="13" style="width:0%;padding:0px 0px 0px 2px"><div><a href="/wiki/File:China_Prefectural-level_divisions_(PRC_claim).png" class="image"><img alt="China Prefectural-level divisions (PRC claim).png" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/China_Prefectural-level_divisions_%28PRC_claim%29.png/200px-China_Prefectural-level_divisions_%28PRC_claim%29.png" decoding="async" width="200" height="163" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/China_Prefectural-level_divisions_%28PRC_claim%29.png/300px-China_Prefectural-level_divisions_%28PRC_claim%29.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/China_Prefectural-level_divisions_%28PRC_claim%29.png/400px-China_Prefectural-level_divisions_%28PRC_claim%29.png 2x" data-file-width="2677" data-file-height="2179" /></a></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区">华北地区</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">河北</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%B8%82" title="石家庄市">石家庄市</a></li>
<li>✧<a href="/wiki/%E5%94%90%E5%B1%B1%E5%B8%82" title="唐山市">唐山市</a></li>
<li><a href="/wiki/%E7%A7%A6%E7%9A%87%E5%B2%9B%E5%B8%82" title="秦皇岛市">秦皇岛市</a></li>
<li>✧<a href="/wiki/%E9%82%AF%E9%83%B8%E5%B8%82" title="邯郸市">邯郸市</a></li>
<li><a href="/wiki/%E9%82%A2%E5%8F%B0%E5%B8%82" title="邢台市">邢台市</a></li>
<li><a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">保定市</a></li>
<li><a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">张家口市</a></li>
<li><a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">承德市</a></li>
<li><a href="/wiki/%E6%B2%A7%E5%B7%9E%E5%B8%82" title="沧州市">沧州市</a></li>
<li><a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">廊坊市</a></li>
<li><a href="/wiki/%E8%A1%A1%E6%B0%B4%E5%B8%82" title="衡水市">衡水市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">山西</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">太原市</a></li>
<li>✧<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">大同市</a></li>
<li><a href="/wiki/%E9%98%B3%E6%B3%89%E5%B8%82" title="阳泉市">阳泉市</a></li>
<li><a href="/wiki/%E9%95%BF%E6%B2%BB%E5%B8%82" title="长治市">长治市</a></li>
<li><a href="/wiki/%E6%99%8B%E5%9F%8E%E5%B8%82" title="晋城市">晋城市</a></li>
<li><a href="/wiki/%E6%9C%94%E5%B7%9E%E5%B8%82" title="朔州市">朔州市</a></li>
<li><a href="/wiki/%E6%99%8B%E4%B8%AD%E5%B8%82" title="晋中市">晋中市</a></li>
<li><a href="/wiki/%E8%BF%90%E5%9F%8E%E5%B8%82" title="运城市">运城市</a></li>
<li><a href="/wiki/%E5%BF%BB%E5%B7%9E%E5%B8%82" title="忻州市">忻州市</a></li>
<li><a href="/wiki/%E4%B8%B4%E6%B1%BE%E5%B8%82" title="临汾市">临汾市</a></li>
<li><a href="/wiki/%E5%90%95%E6%A2%81%E5%B8%82" title="吕梁市">吕梁市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">内蒙古</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">呼和浩特市</a></li>
<li>✧<a href="/wiki/%E5%8C%85%E5%A4%B4%E5%B8%82" title="包头市">包头市</a></li>
<li><a href="/wiki/%E4%B9%8C%E6%B5%B7%E5%B8%82" title="乌海市">乌海市</a></li>
<li><a href="/wiki/%E8%B5%A4%E5%B3%B0%E5%B8%82" title="赤峰市">赤峰市</a></li>
<li><a href="/wiki/%E9%80%9A%E8%BE%BD%E5%B8%82" title="通辽市">通辽市</a></li>
<li><a href="/wiki/%E9%84%82%E5%B0%94%E5%A4%9A%E6%96%AF%E5%B8%82" title="鄂尔多斯市">鄂尔多斯市</a></li>
<li><a href="/wiki/%E5%91%BC%E4%BC%A6%E8%B4%9D%E5%B0%94%E5%B8%82" title="呼伦贝尔市">呼伦贝尔市</a></li>
<li><a href="/wiki/%E5%B7%B4%E5%BD%A6%E6%B7%96%E5%B0%94%E5%B8%82" title="巴彦淖尔市">巴彦淖尔市</a></li>
<li><a href="/wiki/%E4%B9%8C%E5%85%B0%E5%AF%9F%E5%B8%83%E5%B8%82" title="乌兰察布市">乌兰察布市</a></li>
<li><a href="/wiki/%E5%85%B4%E5%AE%89%E7%9B%9F" title="兴安盟">兴安盟</a></li>
<li><a href="/wiki/%E9%94%A1%E6%9E%97%E9%83%AD%E5%8B%92%E7%9B%9F" title="锡林郭勒盟">锡林郭勒盟</a></li>
<li><a href="/wiki/%E9%98%BF%E6%8B%89%E5%96%84%E7%9B%9F" title="阿拉善盟">阿拉善盟</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%9C%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国东北地区">东北地区</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">辽宁</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">沈阳市</a></li>
<li>★✦✧<a href="/wiki/%E5%A4%A7%E8%BF%9E%E5%B8%82" title="大连市">大连市</a></li>
<li>✧<a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82" title="鞍山市">鞍山市</a></li>
<li>✧<a href="/wiki/%E6%8A%9A%E9%A1%BA%E5%B8%82" title="抚顺市">抚顺市</a></li>
<li>✧<a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82" title="本溪市">本溪市</a></li>
<li><a href="/wiki/%E4%B8%B9%E4%B8%9C%E5%B8%82" title="丹东市">丹东市</a></li>
<li><a href="/wiki/%E9%94%A6%E5%B7%9E%E5%B8%82" title="锦州市">锦州市</a></li>
<li><a href="/wiki/%E8%90%A5%E5%8F%A3%E5%B8%82" title="营口市">营口市</a></li>
<li><a href="/wiki/%E9%98%9C%E6%96%B0%E5%B8%82" title="阜新市">阜新市</a></li>
<li><a href="/wiki/%E8%BE%BD%E9%98%B3%E5%B8%82" title="辽阳市">辽阳市</a></li>
<li><a href="/wiki/%E7%9B%98%E9%94%A6%E5%B8%82" title="盘锦市">盘锦市</a></li>
<li><a href="/wiki/%E9%93%81%E5%B2%AD%E5%B8%82" title="铁岭市">铁岭市</a></li>
<li><a href="/wiki/%E6%9C%9D%E9%98%B3%E5%B8%82" title="朝阳市">朝阳市</a></li>
<li><a href="/wiki/%E8%91%AB%E8%8A%A6%E5%B2%9B%E5%B8%82" title="葫芦岛市">葫芦岛市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">吉林</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">长春市</a></li>
<li>✧<a href="/wiki/%E5%90%89%E6%9E%97%E5%B8%82" title="吉林市">吉林市</a></li>
<li><a href="/wiki/%E5%9B%9B%E5%B9%B3%E5%B8%82" title="四平市">四平市</a></li>
<li><a href="/wiki/%E8%BE%BD%E6%BA%90%E5%B8%82" title="辽源市">辽源市</a></li>
<li><a href="/wiki/%E9%80%9A%E5%8C%96%E5%B8%82" title="通化市">通化市</a></li>
<li><a href="/wiki/%E7%99%BD%E5%B1%B1%E5%B8%82" title="白山市">白山市</a></li>
<li><a href="/wiki/%E6%9D%BE%E5%8E%9F%E5%B8%82_(%E5%90%89%E6%9E%97%E7%9C%81)" title="松原市 (吉林省)">松原市</a></li>
<li><a href="/wiki/%E7%99%BD%E5%9F%8E%E5%B8%82" title="白城市">白城市</a></li>
<li><a href="/wiki/%E5%BB%B6%E8%BE%B9%E6%9C%9D%E9%B2%9C%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="延边朝鲜族自治州">延边朝鲜族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">黑龙江</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">哈尔滨市</a></li>
<li>✧<a href="/wiki/%E9%BD%90%E9%BD%90%E5%93%88%E5%B0%94%E5%B8%82" title="齐齐哈尔市">齐齐哈尔市</a></li>
<li><a href="/wiki/%E9%B8%A1%E8%A5%BF%E5%B8%82" title="鸡西市">鸡西市</a></li>
<li><a href="/wiki/%E9%B9%A4%E5%B2%97%E5%B8%82" title="鹤岗市">鹤岗市</a></li>
<li><a href="/wiki/%E5%8F%8C%E9%B8%AD%E5%B1%B1%E5%B8%82" title="双鸭山市">双鸭山市</a></li>
<li><a href="/wiki/%E5%A4%A7%E5%BA%86%E5%B8%82" title="大庆市">大庆市</a></li>
<li><a href="/wiki/%E4%BC%8A%E6%98%A5%E5%B8%82" title="伊春市">伊春市</a></li>
<li><a href="/wiki/%E4%BD%B3%E6%9C%A8%E6%96%AF%E5%B8%82" title="佳木斯市">佳木斯市</a></li>
<li><a href="/wiki/%E4%B8%83%E5%8F%B0%E6%B2%B3%E5%B8%82" title="七台河市">七台河市</a></li>
<li><a href="/wiki/%E7%89%A1%E4%B8%B9%E6%B1%9F%E5%B8%82" title="牡丹江市">牡丹江市</a></li>
<li><a href="/wiki/%E9%BB%91%E6%B2%B3%E5%B8%82" title="黑河市">黑河市</a></li>
<li><a href="/wiki/%E7%BB%A5%E5%8C%96%E5%B8%82" title="绥化市">绥化市</a></li>
<li><a href="/wiki/%E5%A4%A7%E5%85%B4%E5%AE%89%E5%B2%AD%E5%9C%B0%E5%8C%BA" title="大兴安岭地区">大兴安岭地区</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%8D%8E%E4%B8%9C%E5%9C%B0%E5%8C%BA" title="华东地区">华东地区</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">江苏</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京市</a></li>
<li>✧<a href="/wiki/%E6%97%A0%E9%94%A1%E5%B8%82" title="无锡市">无锡市</a></li>
<li>✧<a href="/wiki/%E5%BE%90%E5%B7%9E%E5%B8%82" title="徐州市">徐州市</a></li>
<li><a href="/wiki/%E5%B8%B8%E5%B7%9E%E5%B8%82" title="常州市">常州市</a></li>
<li>✧<a href="/wiki/%E8%8B%8F%E5%B7%9E%E5%B8%82" title="苏州市">苏州市</a></li>
<li><a href="/wiki/%E5%8D%97%E9%80%9A%E5%B8%82" title="南通市">南通市</a></li>
<li><a href="/wiki/%E8%BF%9E%E4%BA%91%E6%B8%AF%E5%B8%82" title="连云港市">连云港市</a></li>
<li><a href="/wiki/%E6%B7%AE%E5%AE%89%E5%B8%82" title="淮安市">淮安市</a></li>
<li><a href="/wiki/%E7%9B%90%E5%9F%8E%E5%B8%82" title="盐城市">盐城市</a></li>
<li><a href="/wiki/%E6%89%AC%E5%B7%9E%E5%B8%82" title="扬州市">扬州市</a></li>
<li><a href="/wiki/%E9%95%87%E6%B1%9F%E5%B8%82" title="镇江市">镇江市</a></li>
<li><a href="/wiki/%E6%B3%B0%E5%B7%9E%E5%B8%82" title="泰州市">泰州市</a></li>
<li><a href="/wiki/%E5%AE%BF%E8%BF%81%E5%B8%82" title="宿迁市">宿迁市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">浙江</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州市</a></li>
<li>★✦✧<a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">宁波市</a></li>
<li><a href="/wiki/%E6%B8%A9%E5%B7%9E%E5%B8%82" title="温州市">温州市</a></li>
<li><a href="/wiki/%E5%98%89%E5%85%B4%E5%B8%82" title="嘉兴市">嘉兴市</a></li>
<li><a href="/wiki/%E6%B9%96%E5%B7%9E%E5%B8%82" title="湖州市">湖州市</a></li>
<li><a href="/wiki/%E7%BB%8D%E5%85%B4%E5%B8%82" title="绍兴市">绍兴市</a></li>
<li><a href="/wiki/%E9%87%91%E5%8D%8E%E5%B8%82" title="金华市">金华市</a></li>
<li><a href="/wiki/%E8%A1%A2%E5%B7%9E%E5%B8%82" title="衢州市">衢州市</a></li>
<li><a href="/wiki/%E8%88%9F%E5%B1%B1%E5%B8%82" title="舟山市">舟山市</a></li>
<li><a href="/wiki/%E5%8F%B0%E5%B7%9E%E5%B8%82" title="台州市">台州市</a></li>
<li><a href="/wiki/%E4%B8%BD%E6%B0%B4%E5%B8%82" title="丽水市">丽水市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">安徽</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">合肥市</a></li>
<li><a href="/wiki/%E8%8A%9C%E6%B9%96%E5%B8%82" title="芜湖市">芜湖市</a></li>
<li><a href="/wiki/%E8%9A%8C%E5%9F%A0%E5%B8%82" title="蚌埠市">蚌埠市</a></li>
<li>✧<a href="/wiki/%E6%B7%AE%E5%8D%97%E5%B8%82" title="淮南市">淮南市</a></li>
<li><a href="/wiki/%E9%A9%AC%E9%9E%8D%E5%B1%B1%E5%B8%82" title="马鞍山市">马鞍山市</a></li>
<li><a href="/wiki/%E6%B7%AE%E5%8C%97%E5%B8%82" title="淮北市">淮北市</a></li>
<li><a href="/wiki/%E9%93%9C%E9%99%B5%E5%B8%82" title="铜陵市">铜陵市</a></li>
<li><a href="/wiki/%E5%AE%89%E5%BA%86%E5%B8%82" title="安庆市">安庆市</a></li>
<li><a href="/wiki/%E9%BB%84%E5%B1%B1%E5%B8%82" title="黄山市">黄山市</a></li>
<li><a href="/wiki/%E6%BB%81%E5%B7%9E%E5%B8%82" title="滁州市">滁州市</a></li>
<li><a href="/wiki/%E9%98%9C%E9%98%B3%E5%B8%82" title="阜阳市">阜阳市</a></li>
<li><a href="/wiki/%E5%AE%BF%E5%B7%9E%E5%B8%82" title="宿州市">宿州市</a></li>
<li><a href="/wiki/%E5%85%AD%E5%AE%89%E5%B8%82" title="六安市">六安市</a></li>
<li><a href="/wiki/%E4%BA%B3%E5%B7%9E%E5%B8%82" title="亳州市">亳州市</a></li>
<li><a href="/wiki/%E6%B1%A0%E5%B7%9E%E5%B8%82" title="池州市">池州市</a></li>
<li><a href="/wiki/%E5%AE%A3%E5%9F%8E%E5%B8%82" title="宣城市">宣城市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">福建</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">福州市</a></li>
<li>★✦<a href="/wiki/%E5%8E%A6%E9%97%A8%E5%B8%82" title="厦门市">厦门市</a></li>
<li><a href="/wiki/%E8%8E%86%E7%94%B0%E5%B8%82" title="莆田市">莆田市</a></li>
<li><a href="/wiki/%E4%B8%89%E6%98%8E%E5%B8%82" title="三明市">三明市</a></li>
<li><a href="/wiki/%E6%B3%89%E5%B7%9E%E5%B8%82" title="泉州市">泉州市</a></li>
<li><a href="/wiki/%E6%BC%B3%E5%B7%9E%E5%B8%82" title="漳州市">漳州市</a></li>
<li><a href="/wiki/%E5%8D%97%E5%B9%B3%E5%B8%82" title="南平市">南平市</a></li>
<li><a href="/wiki/%E9%BE%99%E5%B2%A9%E5%B8%82" title="龙岩市">龙岩市</a></li>
<li><a href="/wiki/%E5%AE%81%E5%BE%B7%E5%B8%82" title="宁德市">宁德市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">江西</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">南昌市</a></li>
<li><a href="/wiki/%E6%99%AF%E5%BE%B7%E9%95%87%E5%B8%82" title="景德镇市">景德镇市</a></li>
<li><a href="/wiki/%E8%90%8D%E4%B9%A1%E5%B8%82" title="萍乡市">萍乡市</a></li>
<li><a href="/wiki/%E4%B9%9D%E6%B1%9F%E5%B8%82" title="九江市">九江市</a></li>
<li><a href="/wiki/%E6%96%B0%E4%BD%99%E5%B8%82" title="新余市">新余市</a></li>
<li><a href="/wiki/%E9%B9%B0%E6%BD%AD%E5%B8%82" title="鹰潭市">鹰潭市</a></li>
<li><a href="/wiki/%E8%B5%A3%E5%B7%9E%E5%B8%82" title="赣州市">赣州市</a></li>
<li><a href="/wiki/%E5%90%89%E5%AE%89%E5%B8%82" title="吉安市">吉安市</a></li>
<li><a href="/wiki/%E5%AE%9C%E6%98%A5%E5%B8%82" title="宜春市">宜春市</a></li>
<li><a href="/wiki/%E6%8A%9A%E5%B7%9E%E5%B8%82" title="抚州市">抚州市</a></li>
<li><a href="/wiki/%E4%B8%8A%E9%A5%B6%E5%B8%82" title="上饶市">上饶市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">山东</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">济南市</a></li>
<li>★✦✧<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">青岛市</a></li>
<li>✧<a href="/wiki/%E6%B7%84%E5%8D%9A%E5%B8%82" title="淄博市">淄博市</a></li>
<li><a href="/wiki/%E6%9E%A3%E5%BA%84%E5%B8%82" title="枣庄市">枣庄市</a></li>
<li><a href="/wiki/%E4%B8%9C%E8%90%A5%E5%B8%82" title="东营市">东营市</a></li>
<li><a href="/wiki/%E7%83%9F%E5%8F%B0%E5%B8%82" title="烟台市">烟台市</a></li>
<li><a href="/wiki/%E6%BD%8D%E5%9D%8A%E5%B8%82" title="潍坊市">潍坊市</a></li>
<li><a href="/wiki/%E6%B5%8E%E5%AE%81%E5%B8%82" title="济宁市">济宁市</a></li>
<li><a href="/wiki/%E6%B3%B0%E5%AE%89%E5%B8%82" title="泰安市">泰安市</a></li>
<li><a href="/wiki/%E5%A8%81%E6%B5%B7%E5%B8%82" title="威海市">威海市</a></li>
<li><a href="/wiki/%E6%97%A5%E7%85%A7%E5%B8%82" title="日照市">日照市</a></li>
<li><a href="/wiki/%E4%B8%B4%E6%B2%82%E5%B8%82" title="临沂市">临沂市</a></li>
<li><a href="/wiki/%E5%BE%B7%E5%B7%9E%E5%B8%82" title="德州市">德州市</a></li>
<li><a href="/wiki/%E8%81%8A%E5%9F%8E%E5%B8%82" title="聊城市">聊城市</a></li>
<li><a href="/wiki/%E6%BB%A8%E5%B7%9E%E5%B8%82" title="滨州市">滨州市</a></li>
<li><a href="/wiki/%E8%8F%8F%E6%B3%BD%E5%B8%82" title="菏泽市">菏泽市</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%8D%97%E5%9C%B0%E5%8C%BA" class="mw-redirect" title="中南地区">中南地区</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">河南</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州市</a></li>
<li><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">开封市</a></li>
<li>✧<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳市</a></li>
<li><a href="/wiki/%E5%B9%B3%E9%A1%B6%E5%B1%B1%E5%B8%82" title="平顶山市">平顶山市</a></li>
<li><a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">安阳市</a></li>
<li><a href="/wiki/%E9%B9%A4%E5%A3%81%E5%B8%82" title="鹤壁市">鹤壁市</a></li>
<li><a href="/wiki/%E6%96%B0%E4%B9%A1%E5%B8%82" title="新乡市">新乡市</a></li>
<li><a href="/wiki/%E7%84%A6%E4%BD%9C%E5%B8%82" title="焦作市">焦作市</a></li>
<li><a href="/wiki/%E6%BF%AE%E9%98%B3%E5%B8%82" title="濮阳市">濮阳市</a></li>
<li><a href="/wiki/%E8%AE%B8%E6%98%8C%E5%B8%82" title="许昌市">许昌市</a></li>
<li><a href="/wiki/%E6%BC%AF%E6%B2%B3%E5%B8%82" title="漯河市">漯河市</a></li>
<li><a href="/wiki/%E4%B8%89%E9%97%A8%E5%B3%A1%E5%B8%82" title="三门峡市">三门峡市</a></li>
<li><a href="/wiki/%E5%8D%97%E9%98%B3%E5%B8%82" title="南阳市">南阳市</a></li>
<li><a href="/wiki/%E5%95%86%E4%B8%98%E5%B8%82" title="商丘市">商丘市</a></li>
<li><a href="/wiki/%E4%BF%A1%E9%98%B3%E5%B8%82" title="信阳市">信阳市</a></li>
<li><a href="/wiki/%E5%91%A8%E5%8F%A3%E5%B8%82" title="周口市">周口市</a></li>
<li><a href="/wiki/%E9%A9%BB%E9%A9%AC%E5%BA%97%E5%B8%82" title="驻马店市">驻马店市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">湖北</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉市</a></li>
<li><a href="/wiki/%E9%BB%84%E7%9F%B3%E5%B8%82" title="黄石市">黄石市</a></li>
<li><a href="/wiki/%E5%8D%81%E5%A0%B0%E5%B8%82" title="十堰市">十堰市</a></li>
<li><a href="/wiki/%E5%AE%9C%E6%98%8C%E5%B8%82" title="宜昌市">宜昌市</a></li>
<li><a href="/wiki/%E8%A5%84%E9%98%B3%E5%B8%82" title="襄阳市">襄阳市</a></li>
<li><a href="/wiki/%E9%84%82%E5%B7%9E%E5%B8%82" title="鄂州市">鄂州市</a></li>
<li><a href="/wiki/%E8%8D%86%E9%97%A8%E5%B8%82" title="荆门市">荆门市</a></li>
<li><a href="/wiki/%E5%AD%9D%E6%84%9F%E5%B8%82" title="孝感市">孝感市</a></li>
<li><a href="/wiki/%E8%8D%86%E5%B7%9E%E5%B8%82" title="荆州市">荆州市</a></li>
<li><a href="/wiki/%E9%BB%84%E5%86%88%E5%B8%82" title="黄冈市">黄冈市</a></li>
<li><a href="/wiki/%E5%92%B8%E5%AE%81%E5%B8%82" title="咸宁市">咸宁市</a></li>
<li><a href="/wiki/%E9%9A%8F%E5%B7%9E%E5%B8%82" title="随州市">随州市</a></li>
<li><a href="/wiki/%E6%81%A9%E6%96%BD%E5%9C%9F%E5%AE%B6%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="恩施土家族苗族自治州">恩施土家族苗族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">湖南</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">长沙市</a></li>
<li><a href="/wiki/%E6%A0%AA%E6%B4%B2%E5%B8%82" title="株洲市">株洲市</a></li>
<li><a href="/wiki/%E6%B9%98%E6%BD%AD%E5%B8%82" title="湘潭市">湘潭市</a></li>
<li><a href="/wiki/%E8%A1%A1%E9%98%B3%E5%B8%82" title="衡阳市">衡阳市</a></li>
<li><a href="/wiki/%E9%82%B5%E9%98%B3%E5%B8%82" title="邵阳市">邵阳市</a></li>
<li><a href="/wiki/%E5%B2%B3%E9%98%B3%E5%B8%82" title="岳阳市">岳阳市</a></li>
<li><a href="/wiki/%E5%B8%B8%E5%BE%B7%E5%B8%82" title="常德市">常德市</a></li>
<li><a href="/wiki/%E5%BC%A0%E5%AE%B6%E7%95%8C%E5%B8%82" title="张家界市">张家界市</a></li>
<li><a href="/wiki/%E7%9B%8A%E9%98%B3%E5%B8%82" title="益阳市">益阳市</a></li>
<li><a href="/wiki/%E9%83%B4%E5%B7%9E%E5%B8%82" title="郴州市">郴州市</a></li>
<li><a href="/wiki/%E6%B0%B8%E5%B7%9E%E5%B8%82" title="永州市">永州市</a></li>
<li><a href="/wiki/%E6%80%80%E5%8C%96%E5%B8%82" title="怀化市">怀化市</a></li>
<li><a href="/wiki/%E5%A8%84%E5%BA%95%E5%B8%82" title="娄底市">娄底市</a></li>
<li><a href="/wiki/%E6%B9%98%E8%A5%BF%E5%9C%9F%E5%AE%B6%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="湘西土家族苗族自治州">湘西土家族苗族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">广东</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州市</a></li>
<li><a href="/wiki/%E9%9F%B6%E5%85%B3%E5%B8%82" title="韶关市">韶关市</a></li>
<li>★✦<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳市</a></li>
<li><a href="/wiki/%E7%8F%A0%E6%B5%B7%E5%B8%82" title="珠海市">珠海市</a></li>
<li><a href="/wiki/%E6%B1%95%E5%A4%B4%E5%B8%82" title="汕头市">汕头市</a></li>
<li><a href="/wiki/%E4%BD%9B%E5%B1%B1%E5%B8%82" title="佛山市">佛山市</a></li>
<li><a href="/wiki/%E6%B1%9F%E9%97%A8%E5%B8%82" title="江门市">江门市</a></li>
<li><a href="/wiki/%E6%B9%9B%E6%B1%9F%E5%B8%82" title="湛江市">湛江市</a></li>
<li><a href="/wiki/%E8%8C%82%E5%90%8D%E5%B8%82" title="茂名市">茂名市</a></li>
<li><a href="/wiki/%E8%82%87%E5%BA%86%E5%B8%82" title="肇庆市">肇庆市</a></li>
<li><a href="/wiki/%E6%83%A0%E5%B7%9E%E5%B8%82" title="惠州市">惠州市</a></li>
<li><a href="/wiki/%E6%A2%85%E5%B7%9E%E5%B8%82" title="梅州市">梅州市</a></li>
<li><a href="/wiki/%E6%B1%95%E5%B0%BE%E5%B8%82" title="汕尾市">汕尾市</a></li>
<li><a href="/wiki/%E6%B2%B3%E6%BA%90%E5%B8%82" title="河源市">河源市</a></li>
<li><a href="/wiki/%E9%98%B3%E6%B1%9F%E5%B8%82" title="阳江市">阳江市</a></li>
<li><a href="/wiki/%E6%B8%85%E8%BF%9C%E5%B8%82" title="清远市">清远市</a></li>
<li><a href="/wiki/%E4%B8%9C%E8%8E%9E%E5%B8%82" title="东莞市">东莞市</a></li>
<li><a href="/wiki/%E4%B8%AD%E5%B1%B1%E5%B8%82" title="中山市">中山市</a></li>
<li><a href="/wiki/%E6%BD%AE%E5%B7%9E%E5%B8%82" title="潮州市">潮州市</a></li>
<li><a href="/wiki/%E6%8F%AD%E9%98%B3%E5%B8%82" title="揭阳市">揭阳市</a></li>
<li><a href="/wiki/%E4%BA%91%E6%B5%AE%E5%B8%82" title="云浮市">云浮市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">广西</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E5%AE%81%E5%B8%82" title="南宁市">南宁市</a></li>
<li><a href="/wiki/%E6%9F%B3%E5%B7%9E%E5%B8%82" title="柳州市">柳州市</a></li>
<li><a href="/wiki/%E6%A1%82%E6%9E%97%E5%B8%82" title="桂林市">桂林市</a></li>
<li><a href="/wiki/%E6%A2%A7%E5%B7%9E%E5%B8%82" title="梧州市">梧州市</a></li>
<li><a href="/wiki/%E5%8C%97%E6%B5%B7%E5%B8%82" title="北海市">北海市</a></li>
<li><a href="/wiki/%E9%98%B2%E5%9F%8E%E6%B8%AF%E5%B8%82" title="防城港市">防城港市</a></li>
<li><a href="/wiki/%E9%92%A6%E5%B7%9E%E5%B8%82" title="钦州市">钦州市</a></li>
<li><a href="/wiki/%E8%B4%B5%E6%B8%AF%E5%B8%82" title="贵港市">贵港市</a></li>
<li><a href="/wiki/%E7%8E%89%E6%9E%97%E5%B8%82" title="玉林市">玉林市</a></li>
<li><a href="/wiki/%E7%99%BE%E8%89%B2%E5%B8%82" title="百色市">百色市</a></li>
<li><a href="/wiki/%E8%B4%BA%E5%B7%9E%E5%B8%82" title="贺州市">贺州市</a></li>
<li><a href="/wiki/%E6%B2%B3%E6%B1%A0%E5%B8%82" title="河池市">河池市</a></li>
<li><a href="/wiki/%E6%9D%A5%E5%AE%BE%E5%B8%82" title="来宾市">来宾市</a></li>
<li><a href="/wiki/%E5%B4%87%E5%B7%A6%E5%B8%82" title="崇左市">崇左市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">海南</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">海口市</a></li>
<li><a href="/wiki/%E4%B8%89%E4%BA%9A%E5%B8%82" title="三亚市">三亚市</a></li>
<li><a href="/wiki/%E4%B8%89%E6%B2%99%E5%B8%82" title="三沙市">三沙市</a></li>
<li><a href="/wiki/%E5%84%8B%E5%B7%9E%E5%B8%82" title="儋州市">儋州市</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中国西南地区">西南地区</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">四川</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都市</a></li>
<li><a href="/wiki/%E8%87%AA%E8%B4%A1%E5%B8%82" title="自贡市">自贡市</a></li>
<li><a href="/wiki/%E6%94%80%E6%9E%9D%E8%8A%B1%E5%B8%82" title="攀枝花市">攀枝花市</a></li>
<li><a href="/wiki/%E6%B3%B8%E5%B7%9E%E5%B8%82" title="泸州市">泸州市</a></li>
<li><a href="/wiki/%E5%BE%B7%E9%98%B3%E5%B8%82" title="德阳市">德阳市</a></li>
<li><a href="/wiki/%E7%BB%B5%E9%98%B3%E5%B8%82" title="绵阳市">绵阳市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%85%83%E5%B8%82" title="广元市">广元市</a></li>
<li><a href="/wiki/%E9%81%82%E5%AE%81%E5%B8%82" title="遂宁市">遂宁市</a></li>
<li><a href="/wiki/%E5%86%85%E6%B1%9F%E5%B8%82" title="内江市">内江市</a></li>
<li><a href="/wiki/%E4%B9%90%E5%B1%B1%E5%B8%82" title="乐山市">乐山市</a></li>
<li><a href="/wiki/%E5%8D%97%E5%85%85%E5%B8%82" title="南充市">南充市</a></li>
<li><a href="/wiki/%E7%9C%89%E5%B1%B1%E5%B8%82" title="眉山市">眉山市</a></li>
<li><a href="/wiki/%E5%AE%9C%E5%AE%BE%E5%B8%82" title="宜宾市">宜宾市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%AE%89%E5%B8%82" title="广安市">广安市</a></li>
<li><a href="/wiki/%E8%BE%BE%E5%B7%9E%E5%B8%82" title="达州市">达州市</a></li>
<li><a href="/wiki/%E9%9B%85%E5%AE%89%E5%B8%82" title="雅安市">雅安市</a></li>
<li><a href="/wiki/%E5%B7%B4%E4%B8%AD%E5%B8%82" title="巴中市">巴中市</a></li>
<li><a href="/wiki/%E8%B5%84%E9%98%B3%E5%B8%82" title="资阳市">资阳市</a></li>
<li><a href="/wiki/%E9%98%BF%E5%9D%9D%E8%97%8F%E6%97%8F%E7%BE%8C%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="阿坝藏族羌族自治州">阿坝藏族羌族自治州</a></li>
<li><a href="/wiki/%E7%94%98%E5%AD%9C%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="甘孜藏族自治州">甘孜藏族自治州</a></li>
<li><a href="/wiki/%E5%87%89%E5%B1%B1%E5%BD%9D%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="凉山彝族自治州">凉山彝族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">贵州</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E8%B4%B5%E9%98%B3%E5%B8%82" title="贵阳市">贵阳市</a></li>
<li><a href="/wiki/%E5%85%AD%E7%9B%98%E6%B0%B4%E5%B8%82" title="六盘水市">六盘水市</a></li>
<li><a href="/wiki/%E9%81%B5%E4%B9%89%E5%B8%82" title="遵义市">遵义市</a></li>
<li><a href="/wiki/%E5%AE%89%E9%A1%BA%E5%B8%82" title="安顺市">安顺市</a></li>
<li><a href="/wiki/%E6%AF%95%E8%8A%82%E5%B8%82" title="毕节市">毕节市</a></li>
<li><a href="/wiki/%E9%93%9C%E4%BB%81%E5%B8%82" title="铜仁市">铜仁市</a></li>
<li><a href="/wiki/%E9%BB%94%E8%A5%BF%E5%8D%97%E5%B8%83%E4%BE%9D%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黔西南布依族苗族自治州">黔西南布依族苗族自治州</a></li>
<li><a href="/wiki/%E9%BB%94%E4%B8%9C%E5%8D%97%E8%8B%97%E6%97%8F%E4%BE%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黔东南苗族侗族自治州">黔东南苗族侗族自治州</a></li>
<li><a href="/wiki/%E9%BB%94%E5%8D%97%E5%B8%83%E4%BE%9D%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黔南布依族苗族自治州">黔南布依族苗族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">云南</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">昆明市</a></li>
<li><a href="/wiki/%E6%9B%B2%E9%9D%96%E5%B8%82" title="曲靖市">曲靖市</a></li>
<li><a href="/wiki/%E7%8E%89%E6%BA%AA%E5%B8%82" title="玉溪市">玉溪市</a></li>
<li><a href="/wiki/%E4%BF%9D%E5%B1%B1%E5%B8%82" title="保山市">保山市</a></li>
<li><a href="/wiki/%E6%98%AD%E9%80%9A%E5%B8%82" title="昭通市">昭通市</a></li>
<li><a href="/wiki/%E4%B8%BD%E6%B1%9F%E5%B8%82" title="丽江市">丽江市</a></li>
<li><a href="/wiki/%E6%99%AE%E6%B4%B1%E5%B8%82" title="普洱市">普洱市</a></li>
<li><a href="/wiki/%E4%B8%B4%E6%B2%A7%E5%B8%82" title="临沧市">临沧市</a></li>
<li><a href="/wiki/%E6%A5%9A%E9%9B%84%E5%BD%9D%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="楚雄彝族自治州">楚雄彝族自治州</a></li>
<li><a href="/wiki/%E7%BA%A2%E6%B2%B3%E5%93%88%E5%B0%BC%E6%97%8F%E5%BD%9D%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="红河哈尼族彝族自治州">红河哈尼族彝族自治州</a></li>
<li><a href="/wiki/%E6%96%87%E5%B1%B1%E5%A3%AE%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="文山壮族苗族自治州">文山壮族苗族自治州</a></li>
<li><a href="/wiki/%E8%A5%BF%E5%8F%8C%E7%89%88%E7%BA%B3%E5%82%A3%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="西双版纳傣族自治州">西双版纳傣族自治州</a></li>
<li><a href="/wiki/%E5%A4%A7%E7%90%86%E7%99%BD%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="大理白族自治州">大理白族自治州</a></li>
<li><a href="/wiki/%E5%BE%B7%E5%AE%8F%E5%82%A3%E6%97%8F%E6%99%AF%E9%A2%87%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="德宏傣族景颇族自治州">德宏傣族景颇族自治州</a></li>
<li><a href="/wiki/%E6%80%92%E6%B1%9F%E5%82%88%E5%83%B3%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="怒江傈僳族自治州">怒江傈僳族自治州</a></li>
<li><a href="/wiki/%E8%BF%AA%E5%BA%86%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="迪庆藏族自治州">迪庆藏族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">西藏</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%8B%89%E8%90%A8%E5%B8%82" title="拉萨市">拉萨市</a></li>
<li><a href="/wiki/%E6%97%A5%E5%96%80%E5%88%99%E5%B8%82" title="日喀则市">日喀则市</a></li>
<li><a href="/wiki/%E6%98%8C%E9%83%BD%E5%B8%82" title="昌都市">昌都市</a></li>
<li><a href="/wiki/%E6%9E%97%E8%8A%9D%E5%B8%82" title="林芝市">林芝市</a></li>
<li><a href="/wiki/%E5%B1%B1%E5%8D%97%E5%B8%82" title="山南市">山南市</a></li>
<li><a href="/wiki/%E9%82%A3%E6%9B%B2%E5%B8%82" title="那曲市">那曲市</a></li>
<li><a href="/wiki/%E9%98%BF%E9%87%8C%E5%9C%B0%E5%8C%BA" title="阿里地区">阿里地区</a></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国西北地区">西北地区</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em"></div><table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody><tr><th scope="row" class="navbox-group"><a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">陕西</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li>★<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安市</a></li>
<li><a href="/wiki/%E9%93%9C%E5%B7%9D%E5%B8%82" title="铜川市">铜川市</a></li>
<li><a href="/wiki/%E5%AE%9D%E9%B8%A1%E5%B8%82" title="宝鸡市">宝鸡市</a></li>
<li><a href="/wiki/%E5%92%B8%E9%98%B3%E5%B8%82" title="咸阳市">咸阳市</a></li>
<li><a href="/wiki/%E6%B8%AD%E5%8D%97%E5%B8%82" title="渭南市">渭南市</a></li>
<li><a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">延安市</a></li>
<li><a href="/wiki/%E6%B1%89%E4%B8%AD%E5%B8%82" title="汉中市">汉中市</a></li>
<li><a href="/wiki/%E6%A6%86%E6%9E%97%E5%B8%82" title="榆林市">榆林市</a></li>
<li><a href="/wiki/%E5%AE%89%E5%BA%B7%E5%B8%82" title="安康市">安康市</a></li>
<li><a href="/wiki/%E5%95%86%E6%B4%9B%E5%B8%82" title="商洛市">商洛市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">甘肃</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%85%B0%E5%B7%9E%E5%B8%82" title="兰州市">兰州市</a></li>
<li><a href="/wiki/%E5%98%89%E5%B3%AA%E5%85%B3%E5%B8%82" title="嘉峪关市">嘉峪关市</a></li>
<li><a href="/wiki/%E9%87%91%E6%98%8C%E5%B8%82" title="金昌市">金昌市</a></li>
<li><a href="/wiki/%E7%99%BD%E9%93%B6%E5%B8%82" title="白银市">白银市</a></li>
<li><a href="/wiki/%E5%A4%A9%E6%B0%B4%E5%B8%82" title="天水市">天水市</a></li>
<li><a href="/wiki/%E6%AD%A6%E5%A8%81%E5%B8%82" title="武威市">武威市</a></li>
<li><a href="/wiki/%E5%BC%A0%E6%8E%96%E5%B8%82" title="张掖市">张掖市</a></li>
<li><a href="/wiki/%E5%B9%B3%E5%87%89%E5%B8%82" title="平凉市">平凉市</a></li>
<li><a href="/wiki/%E9%85%92%E6%B3%89%E5%B8%82" title="酒泉市">酒泉市</a></li>
<li><a href="/wiki/%E5%BA%86%E9%98%B3%E5%B8%82" title="庆阳市">庆阳市</a></li>
<li><a href="/wiki/%E5%AE%9A%E8%A5%BF%E5%B8%82" title="定西市">定西市</a></li>
<li><a href="/wiki/%E9%99%87%E5%8D%97%E5%B8%82" title="陇南市">陇南市</a></li>
<li><a href="/wiki/%E4%B8%B4%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="临夏回族自治州">临夏回族自治州</a></li>
<li><a href="/wiki/%E7%94%98%E5%8D%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="甘南藏族自治州">甘南藏族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">青海</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E8%A5%BF%E5%AE%81%E5%B8%82" title="西宁市">西宁市</a></li>
<li><a href="/wiki/%E6%B5%B7%E4%B8%9C%E5%B8%82" title="海东市">海东市</a></li>
<li><a href="/wiki/%E6%B5%B7%E5%8C%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="海北藏族自治州">海北藏族自治州</a></li>
<li><a href="/wiki/%E9%BB%84%E5%8D%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黄南藏族自治州">黄南藏族自治州</a></li>
<li><a href="/wiki/%E6%B5%B7%E5%8D%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="海南藏族自治州">海南藏族自治州</a></li>
<li><a href="/wiki/%E6%9E%9C%E6%B4%9B%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="果洛藏族自治州">果洛藏族自治州</a></li>
<li><a href="/wiki/%E7%8E%89%E6%A0%91%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="玉树藏族自治州">玉树藏族自治州</a></li>
<li><a href="/wiki/%E6%B5%B7%E8%A5%BF%E8%92%99%E5%8F%A4%E6%97%8F%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="海西蒙古族藏族自治州">海西蒙古族藏族自治州</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">宁夏</a></th><td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">银川市</a></li>
<li><a href="/wiki/%E7%9F%B3%E5%98%B4%E5%B1%B1%E5%B8%82" title="石嘴山市">石嘴山市</a></li>
<li><a href="/wiki/%E5%90%B4%E5%BF%A0%E5%B8%82" title="吴忠市">吴忠市</a></li>
<li><a href="/wiki/%E5%9B%BA%E5%8E%9F%E5%B8%82" title="固原市">固原市</a></li>
<li><a href="/wiki/%E4%B8%AD%E5%8D%AB%E5%B8%82" title="中卫市">中卫市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group"><a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">新疆</a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%B8%82" title="乌鲁木齐市">乌鲁木齐市</a></li>
<li><a href="/wiki/%E5%85%8B%E6%8B%89%E7%8E%9B%E4%BE%9D%E5%B8%82" title="克拉玛依市">克拉玛依市</a></li>
<li><a href="/wiki/%E5%90%90%E9%B2%81%E7%95%AA%E5%B8%82" title="吐鲁番市">吐鲁番市</a></li>
<li><a href="/wiki/%E5%93%88%E5%AF%86%E5%B8%82" title="哈密市">哈密市</a></li>
<li><a href="/wiki/%E6%98%8C%E5%90%89%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="昌吉回族自治州">昌吉回族自治州</a></li>
<li><a href="/wiki/%E5%8D%9A%E5%B0%94%E5%A1%94%E6%8B%89%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%B7%9E" title="博尔塔拉蒙古自治州">博尔塔拉蒙古自治州</a></li>
<li><a href="/wiki/%E5%B7%B4%E9%9F%B3%E9%83%AD%E6%A5%9E%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%B7%9E" title="巴音郭楞蒙古自治州">巴音郭楞蒙古自治州</a></li>
<li><a href="/wiki/%E9%98%BF%E5%85%8B%E8%8B%8F%E5%9C%B0%E5%8C%BA" title="阿克苏地区">阿克苏地区</a></li>
<li><a href="/wiki/%E5%85%8B%E5%AD%9C%E5%8B%92%E8%8B%8F%E6%9F%AF%E5%B0%94%E5%85%8B%E5%AD%9C%E8%87%AA%E6%B2%BB%E5%B7%9E" title="克孜勒苏柯尔克孜自治州">克孜勒苏柯尔克孜自治州</a></li>
<li><a href="/wiki/%E5%96%80%E4%BB%80%E5%9C%B0%E5%8C%BA" title="喀什地区">喀什地区</a></li>
<li><a href="/wiki/%E5%92%8C%E7%94%B0%E5%9C%B0%E5%8C%BA" title="和田地区">和田地区</a></li>
<li>☆<a href="/wiki/%E4%BC%8A%E7%8A%81%E5%93%88%E8%90%A8%E5%85%8B%E8%87%AA%E6%B2%BB%E5%B7%9E" title="伊犁哈萨克自治州">伊犁哈萨克自治州</a>
<ul><li><a href="/wiki/%E5%A1%94%E5%9F%8E%E5%9C%B0%E5%8C%BA" title="塔城地区">塔城地区</a></li>
<li><a href="/wiki/%E9%98%BF%E5%8B%92%E6%B3%B0%E5%9C%B0%E5%8C%BA" title="阿勒泰地区">阿勒泰地区</a></li></ul></li></ul>
</div></td></tr></tbody></table><div></div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="3" style="text-align: left; font-size: 90%;"><div>
<ul><li>参见:<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">县级以上行政区列表</a></li>
<li><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%BB%BA%E5%88%B6" title="中华人民共和国城市建制">城市建制</a>、<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国城市列表">城市列表</a></li></ul>
<hr /><div class="center"><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">区划</a>索引:<a href="/wiki/Template:Division_levels_of_China" title="Template:Division levels of China">单位</a><small>(<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81" title="中华人民共和国行政区划代码">代码</a>)</small>:<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">省级</a><small>(<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">史</a>)</small>><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区"><i>副省级</i></a>><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">地级</a>><a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">县级</a>:<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">京</a>|<a href="/wiki/Template:%E5%A4%A9%E6%B4%A5%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:天津行政区划">津</a>|<a href="/wiki/Template:%E6%B2%B3%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河北行政区划">冀</a>|<a href="/wiki/Template:%E5%B1%B1%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山西行政区划">晋</a>|<a href="/wiki/Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:内蒙古行政区划">蒙</a>|<a href="/wiki/Template:%E8%BE%BD%E5%AE%81%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:辽宁行政区划">辽</a>|<a href="/wiki/Template:%E5%90%89%E6%9E%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:吉林行政区划">吉</a>|<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:黑龙江行政区划">黑</a>|<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:上海行政区划">沪</a>|<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江苏行政区划">苏</a>|<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:浙江行政区划">浙</a>|<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:安徽行政区划">皖</a>|<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:福建行政区划">闽</a>|<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江西行政区划">赣</a>|<a href="/wiki/Template:%E5%B1%B1%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山东行政区划">鲁</a>|<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河南行政区划">豫</a>|<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖北行政区划">鄂</a>|<a href="/wiki/Template:%E6%B9%96%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖南行政区划">湘</a>|<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广东行政区划">粤</a>|<a href="/wiki/Template:%E5%B9%BF%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广西行政区划">桂</a>|<a href="/wiki/Template:%E6%B5%B7%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:海南行政区划">琼</a>|<a href="/wiki/Template:%E9%87%8D%E5%BA%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:重庆行政区划">渝</a>|<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:四川行政区划">川</a>|<a href="/wiki/Template:%E8%B4%B5%E5%B7%9E%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:贵州行政区划">贵</a>|<a href="/wiki/Template:%E4%BA%91%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:云南行政区划">云</a>|<a href="/wiki/Template:%E8%A5%BF%E8%97%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:西藏行政区划">藏</a>|<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:陕西行政区划">陕</a>|<a href="/wiki/Template:%E7%94%98%E8%82%83%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:甘肃行政区划">甘</a>|<a href="/wiki/Template:%E9%9D%92%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:青海行政区划">青</a>|<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:宁夏行政区划">宁</a>|<a href="/wiki/Template:%E6%96%B0%E7%96%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:新疆行政区划">新</a>|<a href="/wiki/Template:%E9%A6%99%E6%B8%AF%E5%8D%81%E5%85%AB%E5%8D%80" title="Template:香港十八區">港</a>|<a href="/wiki/Template:%E6%BE%B3%E9%96%80%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="Template:澳門行政區劃">澳</a>|<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">台</a></div>
</div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="col" class="navbox-title" colspan="2" style="background:#3CB371; color:#ffffff;"><div class="plainlinks hlist navbar mini"><ul><li class="nv-view"><a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国国家园林城市"><abbr title="查看该模板" style=";background:#3CB371; color:#ffffff;;background:none transparent;border:none;">查</abbr></a></li><li class="nv-talk"><a href="/w/index.php?title=Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82&action=edit&redlink=1" class="new" title="Template talk:中华人民共和国国家园林城市(页面不存在)"><abbr title="讨论该模板" style=";background:#3CB371; color:#ffffff;;background:none transparent;border:none;">论</abbr></a></li><li class="nv-edit"><a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82&action=edit"><abbr title="编辑该模板" style=";background:#3CB371; color:#ffffff;;background:none transparent;border:none;">编</abbr></a></li></ul></div><div style="font-size:110%"><a href="/wiki/File:Flag_of_the_People%27s_Republic_of_China.svg" class="image" title="中华人民共和国国旗"><img alt="中华人民共和国国旗" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/25px-Flag_of_the_People%27s_Republic_of_China.svg.png" decoding="async" width="25" height="17" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/38px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/50px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" data-file-width="900" data-file-height="600" /></a> <a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国"><span style="color:white;">中华人民共和国</span></a><a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82" title="国家园林城市"><span style="color:white;">国家园林城市</span></a><span style="color:white;"></span></div></th></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2" style="background:#3CB371; color:#ffffff;"><div>国家园林城市是<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BD%8F%E6%88%BF%E5%92%8C%E5%9F%8E%E4%B9%A1%E5%BB%BA%E8%AE%BE%E9%83%A8" title="中华人民共和国住房和城乡建设部"><span style="color:white;">中华人民共和国住房和城乡建设部</span></a>设立的城市荣誉称号。</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a class="mw-selflink selflink"><span style="color:white;">北京市</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a class="mw-selflink selflink">北京市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省"><span style="color:white;">河北省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%94%90%E5%B1%B1%E5%B8%82" title="唐山市">唐山市</a></li>
<li><a href="/wiki/%E7%A7%A6%E7%9A%87%E5%B2%9B%E5%B8%82" title="秦皇岛市">秦皇岛市</a></li>
<li><a href="/wiki/%E9%82%AF%E9%83%B8%E5%B8%82" title="邯郸市">邯郸市</a></li>
<li><a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">廊坊市</a></li>
<li><a href="/wiki/%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%B8%82" title="石家庄市">石家庄市</a></li>
<li><a href="/wiki/%E8%BF%81%E5%AE%89%E5%B8%82" title="迁安市">迁安市</a></li>
<li><a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">承德市</a></li>
<li><a href="/wiki/%E6%AD%A6%E5%AE%89%E5%B8%82" title="武安市">武安市</a></li>
<li><a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">张家口市</a></li>
<li><a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">保定市</a></li>
<li><a href="/wiki/%E9%82%A2%E5%8F%B0%E5%B8%82" title="邢台市">邢台市</a></li>
<li><a href="/wiki/%E6%B2%A7%E5%B7%9E%E5%B8%82" title="沧州市">沧州市</a></li>
<li><a href="/wiki/%E8%BE%9B%E9%9B%86%E5%B8%82" title="辛集市">辛集市</a></li>
<li><a href="/wiki/%E9%BB%84%E9%AA%85%E5%B8%82" title="黄骅市">黄骅市</a></li>
<li><a href="/wiki/%E6%99%8B%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E5%9B%BD)" title="晋州市 (中国)">晋州市</a></li>
<li><a href="/wiki/%E4%BB%BB%E4%B8%98%E5%B8%82" title="任丘市">任丘市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省"><span style="color:white;">山西省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%95%BF%E6%B2%BB%E5%B8%82" title="长治市">长治市</a></li>
<li><a href="/wiki/%E6%99%8B%E5%9F%8E%E5%B8%82" title="晋城市">晋城市</a></li>
<li><a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">太原市</a></li>
<li><a href="/wiki/%E6%BD%9E%E5%9F%8E%E5%B8%82" class="mw-redirect" title="潞城市">潞城市</a></li>
<li><a href="/wiki/%E4%BE%AF%E9%A9%AC%E5%B8%82" title="侯马市">侯马市</a></li>
<li><a href="/wiki/%E9%98%B3%E6%B3%89%E5%B8%82" title="阳泉市">阳泉市</a></li>
<li><a href="/wiki/%E5%AD%9D%E4%B9%89%E5%B8%82" title="孝义市">孝义市</a></li>
<li><a href="/wiki/%E4%BB%8B%E4%BC%91%E5%B8%82" title="介休市">介休市</a></li>
<li><a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">大同市</a></li>
<li><a href="/wiki/%E6%9C%94%E5%B7%9E%E5%B8%82" title="朔州市">朔州市</a></li>
<li><a href="/wiki/%E6%B0%B8%E6%B5%8E%E5%B8%82" title="永济市">永济市</a></li>
<li><a href="/wiki/%E6%99%8B%E4%B8%AD%E5%B8%82" title="晋中市">晋中市</a></li>
<li><a href="/wiki/%E5%BF%BB%E5%B7%9E%E5%B8%82" title="忻州市">忻州市</a></li>
<li><a href="/wiki/%E8%BF%90%E5%9F%8E%E5%B8%82" title="运城市">运城市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区"><span style="color:white;">内蒙古自治区</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8C%85%E5%A4%B4%E5%B8%82" title="包头市">包头市</a></li>
<li><a href="/wiki/%E9%80%9A%E8%BE%BD%E5%B8%82" title="通辽市">通辽市</a></li>
<li><a href="/wiki/%E9%84%82%E5%B0%94%E5%A4%9A%E6%96%AF%E5%B8%82" title="鄂尔多斯市">鄂尔多斯市</a></li>
<li><a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">呼和浩特市</a></li>
<li><a href="/wiki/%E4%B9%8C%E6%B5%B7%E5%B8%82" title="乌海市">乌海市</a></li>
<li><a href="/wiki/%E4%B9%8C%E5%85%B0%E5%AF%9F%E5%B8%83%E5%B8%82" title="乌兰察布市">乌兰察布市</a></li>
<li><a href="/wiki/%E6%89%8E%E5%85%B0%E5%B1%AF%E5%B8%82" title="扎兰屯市">扎兰屯市</a></li>
<li><a href="/wiki/%E8%B5%A4%E5%B3%B0%E5%B8%82" title="赤峰市">赤峰市</a></li>
<li><a href="/wiki/%E5%B7%B4%E5%BD%A6%E6%B7%96%E5%B0%94%E5%B8%82" title="巴彦淖尔市">巴彦淖尔市</a></li>
<li><a href="/wiki/%E9%94%A1%E6%9E%97%E6%B5%A9%E7%89%B9%E5%B8%82" title="锡林浩特市">锡林浩特市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省"><span style="color:white;">辽宁省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%A4%A7%E8%BF%9E%E5%B8%82" title="大连市">大连市</a></li>
<li><a href="/wiki/%E8%91%AB%E8%8A%A6%E5%B2%9B%E5%B8%82" title="葫芦岛市">葫芦岛市</a></li>
<li><a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">沈阳市</a></li>
<li><a href="/wiki/%E8%B0%83%E5%85%B5%E5%B1%B1%E5%B8%82" title="调兵山市">调兵山市</a></li>
<li><a href="/wiki/%E9%93%81%E5%B2%AD%E5%B8%82" title="铁岭市">铁岭市</a></li>
<li><a href="/wiki/%E5%BC%80%E5%8E%9F%E5%B8%82" title="开原市">开原市</a></li>
<li><a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82" title="本溪市">本溪市</a></li>
<li><a href="/wiki/%E4%B8%B9%E4%B8%9C%E5%B8%82" title="丹东市">丹东市</a></li>
<li><a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82" title="鞍山市">鞍山市</a></li>
<li><a href="/wiki/%E7%9B%98%E9%94%A6%E5%B8%82" title="盘锦市">盘锦市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省"><span style="color:white;">吉林省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">长春市</a></li>
<li><a href="/wiki/%E5%90%89%E6%9E%97%E5%B8%82" title="吉林市">吉林市</a></li>
<li><a href="/wiki/%E5%9B%9B%E5%B9%B3%E5%B8%82" title="四平市">四平市</a></li>
<li><a href="/wiki/%E6%9D%BE%E5%8E%9F%E5%B8%82_(%E5%90%89%E6%9E%97%E7%9C%81)" title="松原市 (吉林省)">松原市</a></li>
<li><a href="/wiki/%E6%95%A6%E5%8C%96%E5%B8%82" title="敦化市">敦化市</a></li>
<li><a href="/wiki/%E5%BB%B6%E5%90%89%E5%B8%82" title="延吉市">延吉市</a></li>
<li><a href="/wiki/%E9%9B%86%E5%AE%89%E5%B8%82" title="集安市">集安市</a></li>
<li><a href="/wiki/%E7%8F%B2%E6%98%A5%E5%B8%82" title="珲春市">珲春市</a></li>
<li><a href="/wiki/%E6%A2%85%E6%B2%B3%E5%8F%A3%E5%B8%82" title="梅河口市">梅河口市</a></li>
<li><a href="/wiki/%E9%80%9A%E5%8C%96%E5%B8%82" title="通化市">通化市</a></li>
<li><a href="/wiki/%E5%A4%A7%E5%AE%89%E5%B8%82" title="大安市">大安市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省"><span style="color:white;">黑龙江省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E4%BC%8A%E6%98%A5%E5%B8%82" title="伊春市">伊春市</a></li>
<li><a href="/wiki/%E4%BD%B3%E6%9C%A8%E6%96%AF%E5%B8%82" title="佳木斯市">佳木斯市</a></li>
<li><a href="/wiki/%E4%B8%83%E5%8F%B0%E6%B2%B3%E5%B8%82" title="七台河市">七台河市</a></li>
<li><a href="/wiki/%E6%B5%B7%E6%9E%97%E5%B8%82" title="海林市">海林市</a></li>
<li><a href="/wiki/%E5%A4%A7%E5%BA%86%E5%B8%82" title="大庆市">大庆市</a></li>
<li><a href="/wiki/%E9%BB%91%E6%B2%B3%E5%B8%82" title="黑河市">黑河市</a></li>
<li><a href="/wiki/%E5%90%8C%E6%B1%9F%E5%B8%82" title="同江市">同江市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市"><span style="color:white;">上海市</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B5%A6%E4%B8%9C%E6%96%B0%E5%8C%BA" title="浦东新区">浦东新区</a></li>
<li><a href="/wiki/%E9%97%B5%E8%A1%8C%E5%8C%BA" title="闵行区">闵行区</a></li>
<li><a href="/wiki/%E9%87%91%E5%B1%B1%E5%8C%BA_(%E4%B8%8A%E6%B5%B7%E5%B8%82)" title="金山区 (上海市)">金山区</a></li>
<li><a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">上海市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省"><span style="color:white;">江苏省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">南京市</a></li>
<li><a href="/wiki/%E5%B8%B8%E7%86%9F%E5%B8%82" title="常熟市">常熟市</a></li>
<li><a href="/wiki/%E6%97%A0%E9%94%A1%E5%B8%82" title="无锡市">无锡市</a></li>
<li><a href="/wiki/%E6%89%AC%E5%B7%9E%E5%B8%82" title="扬州市">扬州市</a></li>
<li><a href="/wiki/%E8%8B%8F%E5%B7%9E%E5%B8%82" title="苏州市">苏州市</a></li>
<li><a href="/wiki/%E5%BC%A0%E5%AE%B6%E6%B8%AF%E5%B8%82" title="张家港市">张家港市</a></li>
<li><a href="/wiki/%E6%98%86%E5%B1%B1%E5%B8%82" title="昆山市">昆山市</a></li>
<li><a href="/wiki/%E5%BE%90%E5%B7%9E%E5%B8%82" title="徐州市">徐州市</a></li>
<li><a href="/wiki/%E9%95%87%E6%B1%9F%E5%B8%82" title="镇江市">镇江市</a></li>
<li><a href="/wiki/%E5%90%B4%E6%B1%9F%E5%8C%BA" title="吴江区">吴江区</a></li>
<li><a href="/wiki/%E5%AE%9C%E5%85%B4%E5%B8%82" title="宜兴市">宜兴市</a></li>
<li><a href="/wiki/%E5%A4%AA%E4%BB%93%E5%B8%82" title="太仓市">太仓市</a></li>
<li><a href="/wiki/%E5%B8%B8%E5%B7%9E%E5%B8%82" title="常州市">常州市</a></li>
<li><a href="/wiki/%E5%8D%97%E9%80%9A%E5%B8%82" title="南通市">南通市</a></li>
<li><a href="/wiki/%E6%B1%9F%E9%98%B4%E5%B8%82" title="江阴市">江阴市</a></li>
<li><a href="/wiki/%E6%B7%AE%E5%AE%89%E5%B8%82" title="淮安市">淮安市</a></li>
<li><a href="/wiki/%E5%AE%BF%E8%BF%81%E5%B8%82" title="宿迁市">宿迁市</a></li>
<li><a href="/wiki/%E6%B3%B0%E5%B7%9E%E5%B8%82" title="泰州市">泰州市</a></li>
<li><a href="/wiki/%E9%87%91%E5%9D%9B%E5%8C%BA" title="金坛区">金坛区</a></li>
<li><a href="/wiki/%E8%BF%9E%E4%BA%91%E6%B8%AF%E5%B8%82" title="连云港市">连云港市</a></li>
<li><a href="/wiki/%E5%A6%82%E7%9A%8B%E5%B8%82" title="如皋市">如皋市</a></li>
<li><a href="/wiki/%E6%B1%9F%E9%83%BD%E5%8C%BA" title="江都区">江都区</a></li>
<li><a href="/wiki/%E6%96%B0%E6%B2%82%E5%B8%82" title="新沂市">新沂市</a></li>
<li><a href="/wiki/%E4%B8%9C%E5%8F%B0%E5%B8%82" title="东台市">东台市</a></li>
<li><a href="/wiki/%E5%A4%A7%E4%B8%B0%E5%8C%BA" title="大丰区">大丰区</a></li>
<li><a href="/wiki/%E6%89%AC%E4%B8%AD%E5%B8%82" title="扬中市">扬中市</a></li>
<li><a href="/wiki/%E9%9D%96%E6%B1%9F%E5%B8%82" title="靖江市">靖江市</a></li>
<li><a href="/wiki/%E9%82%B3%E5%B7%9E%E5%B8%82" title="邳州市">邳州市</a></li>
<li><a href="/wiki/%E6%BA%A7%E9%98%B3%E5%B8%82" title="溧阳市">溧阳市</a></li>
<li><a href="/wiki/%E5%90%AF%E4%B8%9C%E5%B8%82" title="启东市">启东市</a></li>
<li><a href="/wiki/%E9%AB%98%E9%82%AE%E5%B8%82" title="高邮市">高邮市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省"><span style="color:white;">浙江省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">杭州市</a></li>
<li><a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">宁波市</a></li>
<li><a href="/wiki/%E7%BB%8D%E5%85%B4%E5%B8%82" title="绍兴市">绍兴市</a></li>
<li><a href="/wiki/%E5%AF%8C%E9%98%B3%E5%8C%BA" title="富阳区">富阳区</a></li>
<li><a href="/wiki/%E5%98%89%E5%85%B4%E5%B8%82" title="嘉兴市">嘉兴市</a></li>
<li><a href="/wiki/%E6%B9%96%E5%B7%9E%E5%B8%82" title="湖州市">湖州市</a></li>
<li><a href="/wiki/%E8%AF%B8%E6%9A%A8%E5%B8%82" title="诸暨市">诸暨市</a></li>
<li><a href="/wiki/%E4%B8%B4%E6%B5%B7%E5%B8%82" title="临海市">临海市</a></li>
<li><a href="/wiki/%E6%A1%90%E4%B9%A1%E5%B8%82" title="桐乡市">桐乡市</a></li>
<li><a href="/wiki/%E8%A1%A2%E5%B7%9E%E5%B8%82" title="衢州市">衢州市</a></li>
<li><a href="/wiki/%E4%B9%89%E4%B9%8C%E5%B8%82" title="义乌市">义乌市</a></li>
<li><a href="/wiki/%E4%B8%8A%E8%99%9E%E5%8C%BA" title="上虞区">上虞区</a></li>
<li><a href="/wiki/%E5%8F%B0%E5%B7%9E%E5%B8%82" title="台州市">台州市</a></li>
<li><a href="/wiki/%E5%B9%B3%E6%B9%96%E5%B8%82" title="平湖市">平湖市</a></li>
<li><a href="/wiki/%E6%B5%B7%E5%AE%81%E5%B8%82" title="海宁市">海宁市</a></li>
<li><a href="/wiki/%E4%BD%99%E5%A7%9A%E5%B8%82" title="余姚市">余姚市</a></li>
<li><a href="/wiki/%E6%B1%9F%E5%B1%B1%E5%B8%82" title="江山市">江山市</a></li>
<li><a href="/wiki/%E6%B8%A9%E5%B2%AD%E5%B8%82" title="温岭市">温岭市</a></li>
<li><a href="/wiki/%E9%87%91%E5%8D%8E%E5%B8%82" title="金华市">金华市</a></li>
<li><a href="/wiki/%E4%B8%BD%E6%B0%B4%E5%B8%82" title="丽水市">丽水市</a></li>
<li><a href="/wiki/%E5%BB%BA%E5%BE%B7%E5%B8%82" title="建德市">建德市</a></li>
<li><a href="/wiki/%E6%B8%A9%E5%B7%9E%E5%B8%82" title="温州市">温州市</a></li>
<li><a href="/wiki/%E4%B8%B4%E5%AE%89%E5%B8%82" class="mw-redirect" title="临安市">临安市</a></li>
<li><a href="/wiki/%E9%BE%99%E6%B3%89%E5%B8%82" title="龙泉市">龙泉市</a></li>
<li><a href="/wiki/%E6%85%88%E6%BA%AA%E5%B8%82" title="慈溪市">慈溪市</a></li>
<li><a href="/wiki/%E4%B8%9C%E9%98%B3%E5%B8%82" title="东阳市">东阳市</a></li>
<li><a href="/wiki/%E4%B9%90%E6%B8%85%E5%B8%82" title="乐清市">乐清市</a></li>
<li><a href="/wiki/%E7%91%9E%E5%AE%89%E5%B8%82" title="瑞安市">瑞安市</a></li>
<li><a href="/wiki/%E5%85%B0%E6%BA%AA%E5%B8%82" title="兰溪市">兰溪市</a></li>
<li><a href="/wiki/%E8%88%9F%E5%B1%B1%E5%B8%82" title="舟山市">舟山市</a></li>
<li><a href="/wiki/%E5%B5%8A%E5%B7%9E%E5%B8%82" title="嵊州市">嵊州市</a></li>
<li><a href="/wiki/%E6%B0%B8%E5%BA%B7%E5%B8%82" title="永康市">永康市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省"><span style="color:white;">安徽省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">合肥市</a></li>
<li><a href="/wiki/%E9%A9%AC%E9%9E%8D%E5%B1%B1%E5%B8%82" title="马鞍山市">马鞍山市</a></li>
<li><a href="/wiki/%E5%AE%89%E5%BA%86%E5%B8%82" title="安庆市">安庆市</a></li>
<li><a href="/wiki/%E9%BB%84%E5%B1%B1%E5%B8%82" title="黄山市">黄山市</a></li>
<li><a href="/wiki/%E6%B7%AE%E5%8C%97%E5%B8%82" title="淮北市">淮北市</a></li>
<li><a href="/wiki/%E6%B7%AE%E5%8D%97%E5%B8%82" title="淮南市">淮南市</a></li>
<li><a href="/wiki/%E9%93%9C%E9%99%B5%E5%B8%82" title="铜陵市">铜陵市</a></li>
<li><a href="/wiki/%E6%B1%A0%E5%B7%9E%E5%B8%82" title="池州市">池州市</a></li>
<li><a href="/wiki/%E8%8A%9C%E6%B9%96%E5%B8%82" title="芜湖市">芜湖市</a></li>
<li><a href="/wiki/%E5%85%AD%E5%AE%89%E5%B8%82" title="六安市">六安市</a></li>
<li><a href="/wiki/%E6%BB%81%E5%B7%9E%E5%B8%82" title="滁州市">滁州市</a></li>
<li><a href="/wiki/%E8%9A%8C%E5%9F%A0%E5%B8%82" title="蚌埠市">蚌埠市</a></li>
<li><a href="/wiki/%E5%AE%BF%E5%B7%9E%E5%B8%82" title="宿州市">宿州市</a></li>
<li><a href="/wiki/%E5%AE%A3%E5%9F%8E%E5%B8%82" title="宣城市">宣城市</a></li>
<li><a href="/wiki/%E5%AE%81%E5%9B%BD%E5%B8%82" title="宁国市">宁国市</a></li>
<li><a href="/wiki/%E5%B7%A2%E6%B9%96%E5%B8%82" title="巢湖市">巢湖市</a></li>
<li><a href="/wiki/%E6%98%8E%E5%85%89%E5%B8%82" title="明光市">明光市</a></li>
<li><a href="/wiki/%E6%A1%90%E5%9F%8E%E5%B8%82" title="桐城市">桐城市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省"><span style="color:white;">福建省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8E%A6%E9%97%A8%E5%B8%82" title="厦门市">厦门市</a></li>
<li><a href="/wiki/%E4%B8%89%E6%98%8E%E5%B8%82" title="三明市">三明市</a></li>
<li><a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">福州市</a></li>
<li><a href="/wiki/%E6%B3%89%E5%B7%9E%E5%B8%82" title="泉州市">泉州市</a></li>
<li><a href="/wiki/%E6%BC%B3%E5%B7%9E%E5%B8%82" title="漳州市">漳州市</a></li>
<li><a href="/wiki/%E6%B0%B8%E5%AE%89%E5%B8%82" title="永安市">永安市</a></li>
<li><a href="/wiki/%E8%8E%86%E7%94%B0%E5%B8%82" title="莆田市">莆田市</a></li>
<li><a href="/wiki/%E9%BE%99%E5%B2%A9%E5%B8%82" title="龙岩市">龙岩市</a></li>
<li><a href="/wiki/%E6%99%8B%E6%B1%9F%E5%B8%82" title="晋江市">晋江市</a></li>
<li><a href="/wiki/%E5%AE%81%E5%BE%B7%E5%B8%82" title="宁德市">宁德市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省"><span style="color:white;">江西省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%AE%9C%E6%98%A5%E5%B8%82" title="宜春市">宜春市</a></li>
<li><a href="/wiki/%E6%99%AF%E5%BE%B7%E9%95%87%E5%B8%82" title="景德镇市">景德镇市</a></li>
<li><a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">南昌市</a></li>
<li><a href="/wiki/%E6%96%B0%E4%BD%99%E5%B8%82" title="新余市">新余市</a></li>
<li><a href="/wiki/%E8%B5%A3%E5%B7%9E%E5%B8%82" title="赣州市">赣州市</a></li>
<li><a href="/wiki/%E8%90%8D%E4%B9%A1%E5%B8%82" title="萍乡市">萍乡市</a></li>
<li><a href="/wiki/%E5%90%89%E5%AE%89%E5%B8%82" title="吉安市">吉安市</a></li>
<li><a href="/wiki/%E4%B9%9D%E6%B1%9F%E5%B8%82" title="九江市">九江市</a></li>
<li><a href="/wiki/%E4%B8%8A%E9%A5%B6%E5%B8%82" title="上饶市">上饶市</a></li>
<li><a href="/wiki/%E9%B9%B0%E6%BD%AD%E5%B8%82" title="鹰潭市">鹰潭市</a></li>
<li><a href="/wiki/%E6%8A%9A%E5%B7%9E%E5%B8%82" title="抚州市">抚州市</a></li>
<li><a href="/wiki/%E8%B4%B5%E6%BA%AA%E5%B8%82" title="贵溪市">贵溪市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省"><span style="color:white;">山东省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%A8%81%E6%B5%B7%E5%B8%82" title="威海市">威海市</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">青岛市</a></li>
<li><a href="/wiki/%E7%83%9F%E5%8F%B0%E5%B8%82" title="烟台市">烟台市</a></li>
<li><a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">济南市</a></li>
<li><a href="/wiki/%E8%8D%A3%E6%88%90%E5%B8%82" title="荣成市">荣成市</a></li>
<li><a href="/wiki/%E6%97%A5%E7%85%A7%E5%B8%82" title="日照市">日照市</a></li>
<li><a href="/wiki/%E6%B7%84%E5%8D%9A%E5%B8%82" title="淄博市">淄博市</a></li>
<li><a href="/wiki/%E5%AF%BF%E5%85%89%E5%B8%82" title="寿光市">寿光市</a></li>
<li><a href="/wiki/%E6%96%B0%E6%B3%B0%E5%B8%82" title="新泰市">新泰市</a></li>
<li><a href="/wiki/%E8%83%B6%E5%8D%97%E5%B8%82" title="胶南市">胶南市</a></li>
<li><a href="/wiki/%E9%9D%92%E5%B7%9E%E5%B8%82" title="青州市">青州市</a></li>
<li><s><a href="/wiki/%E8%8E%B1%E8%8A%9C%E5%B8%82" title="莱芜市">莱芜市</a></s></li>
<li><a href="/wiki/%E8%83%B6%E5%B7%9E%E5%B8%82" title="胶州市">胶州市</a></li>
<li><a href="/wiki/%E4%B9%B3%E5%B1%B1%E5%B8%82" title="乳山市">乳山市</a></li>
<li><a href="/wiki/%E6%96%87%E7%99%BB%E5%8C%BA" title="文登区">文登区</a></li>
<li><a href="/wiki/%E6%BD%8D%E5%9D%8A%E5%B8%82" title="潍坊市">潍坊市</a></li>
<li><a href="/wiki/%E4%B8%B4%E6%B2%82%E5%B8%82" title="临沂市">临沂市</a></li>
<li><a href="/wiki/%E6%B3%B0%E5%AE%89%E5%B8%82" title="泰安市">泰安市</a></li>
<li><a href="/wiki/%E7%AB%A0%E4%B8%98%E5%B8%82" class="mw-redirect" title="章丘市">章丘市</a></li>
<li><a href="/wiki/%E8%82%A5%E5%9F%8E%E5%B8%82" title="肥城市">肥城市</a></li>
<li><a href="/wiki/%E4%B8%9C%E8%90%A5%E5%B8%82" title="东营市">东营市</a></li>
<li><a href="/wiki/%E6%B5%8E%E5%AE%81%E5%B8%82" title="济宁市">济宁市</a></li>
<li><a href="/wiki/%E8%81%8A%E5%9F%8E%E5%B8%82" title="聊城市">聊城市</a></li>
<li><a href="/wiki/%E9%BE%99%E5%8F%A3%E5%B8%82" title="龙口市">龙口市</a></li>
<li><a href="/wiki/%E6%B5%B7%E9%98%B3%E5%B8%82" title="海阳市">海阳市</a></li>
<li><a href="/wiki/%E5%BE%B7%E5%B7%9E%E5%B8%82" title="德州市">德州市</a></li>
<li><a href="/wiki/%E6%BB%A8%E5%B7%9E%E5%B8%82" title="滨州市">滨州市</a></li>
<li><a href="/wiki/%E8%8F%8F%E6%B3%BD%E5%B8%82" title="菏泽市">菏泽市</a></li>
<li><a href="/wiki/%E8%8E%B1%E5%B7%9E%E5%B8%82" title="莱州市">莱州市</a></li>
<li><a href="/wiki/%E8%AF%B8%E5%9F%8E%E5%B8%82" title="诸城市">诸城市</a></li>
<li><a href="/wiki/%E9%AB%98%E5%AF%86%E5%B8%82" title="高密市">高密市</a></li>
<li><a href="/wiki/%E6%9E%A3%E5%BA%84%E5%B8%82" title="枣庄市">枣庄市</a></li>
<li><a href="/wiki/%E6%BB%95%E5%B7%9E%E5%B8%82" title="滕州市">滕州市</a></li>
<li><a href="/wiki/%E5%AE%89%E4%B8%98%E5%B8%82" title="安丘市">安丘市</a></li>
<li><a href="/wiki/%E6%9B%B2%E9%98%9C%E5%B8%82" title="曲阜市">曲阜市</a></li>
<li><a href="/wiki/%E9%82%B9%E5%9F%8E%E5%B8%82" title="邹城市">邹城市</a></li>
<li><a href="/wiki/%E6%98%8C%E9%82%91%E5%B8%82" title="昌邑市">昌邑市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省"><span style="color:white;">河南省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%BF%AE%E9%98%B3%E5%B8%82" title="濮阳市">濮阳市</a></li>
<li><a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">洛阳市</a></li>
<li><a href="/wiki/%E6%BC%AF%E6%B2%B3%E5%B8%82" title="漯河市">漯河市</a></li>
<li><a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">郑州市</a></li>
<li><a href="/wiki/%E8%AE%B8%E6%98%8C%E5%B8%82" title="许昌市">许昌市</a></li>
<li><a href="/wiki/%E5%8D%97%E9%98%B3%E5%B8%82" title="南阳市">南阳市</a></li>
<li><a href="/wiki/%E7%84%A6%E4%BD%9C%E5%B8%82" title="焦作市">焦作市</a></li>
<li><a href="/wiki/%E5%81%83%E5%B8%88%E5%B8%82" title="偃师市">偃师市</a></li>
<li><a href="/wiki/%E6%96%B0%E4%B9%A1%E5%B8%82" title="新乡市">新乡市</a></li>
<li><a href="/wiki/%E6%B5%8E%E6%BA%90%E5%B8%82" title="济源市">济源市</a></li>
<li><a href="/wiki/%E8%88%9E%E9%92%A2%E5%B8%82" title="舞钢市">舞钢市</a></li>
<li><a href="/wiki/%E7%99%BB%E5%B0%81%E5%B8%82" title="登封市">登封市</a></li>
<li><a href="/wiki/%E4%B8%89%E9%97%A8%E5%B3%A1%E5%B8%82" title="三门峡市">三门峡市</a></li>
<li><a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">安阳市</a></li>
<li><a href="/wiki/%E5%95%86%E4%B8%98%E5%B8%82" title="商丘市">商丘市</a></li>
<li><a href="/wiki/%E5%B9%B3%E9%A1%B6%E5%B1%B1%E5%B8%82" title="平顶山市">平顶山市</a></li>
<li><a href="/wiki/%E5%B7%A9%E4%B9%89%E5%B8%82" title="巩义市">巩义市</a></li>
<li><a href="/wiki/%E4%BF%A1%E9%98%B3%E5%B8%82" title="信阳市">信阳市</a></li>
<li><a href="/wiki/%E9%A9%BB%E9%A9%AC%E5%BA%97%E5%B8%82" title="驻马店市">驻马店市</a></li>
<li><a href="/wiki/%E6%B0%B8%E5%9F%8E%E5%B8%82" title="永城市">永城市</a></li>
<li><a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">开封市</a></li>
<li><a href="/wiki/%E6%9E%97%E5%B7%9E%E5%B8%82" title="林州市">林州市</a></li>
<li><a href="/wiki/%E9%82%93%E5%B7%9E%E5%B8%82" title="邓州市">邓州市</a></li>
<li><a href="/wiki/%E9%B9%A4%E5%A3%81%E5%B8%82" title="鹤壁市">鹤壁市</a></li>
<li><a href="/wiki/%E6%B1%9D%E5%B7%9E%E5%B8%82" title="汝州市">汝州市</a></li>
<li><a href="/wiki/%E7%A6%B9%E5%B7%9E%E5%B8%82" title="禹州市">禹州市</a></li>
<li><a href="/wiki/%E8%8D%A5%E9%98%B3%E5%B8%82" title="荥阳市">荥阳市</a></li>
<li><a href="/wiki/%E5%91%A8%E5%8F%A3%E5%B8%82" title="周口市">周口市</a></li>
<li><a href="/wiki/%E6%96%B0%E9%83%91%E5%B8%82" title="新郑市">新郑市</a></li>
<li><a href="/wiki/%E9%95%BF%E8%91%9B%E5%B8%82" title="长葛市">长葛市</a></li>
<li><a href="/wiki/%E5%AD%9F%E5%B7%9E%E5%B8%82" title="孟州市">孟州市</a></li>
<li><a href="/wiki/%E9%A1%B9%E5%9F%8E%E5%B8%82" title="项城市">项城市</a></li>
<li><a href="/wiki/%E4%B9%89%E9%A9%AC%E5%B8%82" title="义马市">义马市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省"><span style="color:white;">湖北省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%81%E5%A0%B0%E5%B8%82" title="十堰市">十堰市</a></li>
<li><a href="/wiki/%E8%A5%84%E9%98%B3%E5%B8%82" title="襄阳市">襄阳市</a></li>
<li><a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">武汉市</a></li>
<li><a href="/wiki/%E5%AE%9C%E6%98%8C%E5%B8%82" title="宜昌市">宜昌市</a></li>
<li><a href="/wiki/%E9%BB%84%E7%9F%B3%E5%B8%82" title="黄石市">黄石市</a></li>
<li><a href="/wiki/%E5%AE%9C%E9%83%BD%E5%B8%82" title="宜都市">宜都市</a></li>
<li><a href="/wiki/%E9%84%82%E5%B7%9E%E5%B8%82" title="鄂州市">鄂州市</a></li>
<li><a href="/wiki/%E8%8D%86%E9%97%A8%E5%B8%82" title="荆门市">荆门市</a></li>
<li><a href="/wiki/%E8%8D%86%E5%B7%9E%E5%B8%82" title="荆州市">荆州市</a></li>
<li><a href="/wiki/%E5%92%B8%E5%AE%81%E5%B8%82" title="咸宁市">咸宁市</a></li>
<li><a href="/wiki/%E9%9A%8F%E5%B7%9E%E5%B8%82" title="随州市">随州市</a></li>
<li><a href="/wiki/%E5%BD%93%E9%98%B3%E5%B8%82" title="当阳市">当阳市</a></li>
<li><a href="/wiki/%E6%81%A9%E6%96%BD%E5%B8%82" title="恩施市">恩施市</a></li>
<li><a href="/wiki/%E4%BB%99%E6%A1%83%E5%B8%82" title="仙桃市">仙桃市</a></li>
<li><a href="/wiki/%E5%AD%9D%E6%84%9F%E5%B8%82" title="孝感市">孝感市</a></li>
<li><a href="/wiki/%E9%BB%84%E5%86%88%E5%B8%82" title="黄冈市">黄冈市</a></li>
<li><a href="/wiki/%E5%A4%A7%E5%86%B6%E5%B8%82" title="大冶市">大冶市</a></li>
<li><a href="/wiki/%E5%BA%94%E5%9F%8E%E5%B8%82" title="应城市">应城市</a></li>
<li><a href="/wiki/%E6%9D%BE%E6%BB%8B%E5%B8%82" title="松滋市">松滋市</a></li>
<li><a href="/wiki/%E8%B5%A4%E5%A3%81%E5%B8%82" title="赤壁市">赤壁市</a></li>
<li><a href="/wiki/%E6%BD%9C%E6%B1%9F%E5%B8%82" title="潜江市">潜江市</a></li>
<li><a href="/wiki/%E5%A4%A9%E9%97%A8%E5%B8%82" title="天门市">天门市</a></li>
<li><a href="/wiki/%E4%B8%B9%E6%B1%9F%E5%8F%A3%E5%B8%82" title="丹江口市">丹江口市</a></li>
<li><a href="/wiki/%E6%9E%9D%E6%B1%9F%E5%B8%82" title="枝江市">枝江市</a></li>
<li><a href="/wiki/%E5%AE%9C%E5%9F%8E%E5%B8%82" title="宜城市">宜城市</a></li>
<li><a href="/wiki/%E5%AE%89%E9%99%86%E5%B8%82" title="安陆市">安陆市</a></li>
<li><a href="/wiki/%E7%9F%B3%E9%A6%96%E5%B8%82" title="石首市">石首市</a></li>
<li><a href="/wiki/%E5%88%A9%E5%B7%9D%E5%B8%82" title="利川市">利川市</a></li>
<li><a href="/wiki/%E9%92%9F%E7%A5%A5%E5%B8%82" title="钟祥市">钟祥市</a></li>
<li><a href="/wiki/%E6%B4%AA%E6%B9%96%E5%B8%82" title="洪湖市">洪湖市</a></li>
<li><a href="/wiki/%E5%B9%BF%E6%B0%B4%E5%B8%82" title="广水市">广水市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省"><span style="color:white;">湖南省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%B8%B8%E5%BE%B7%E5%B8%82" title="常德市">常德市</a></li>
<li><a href="/wiki/%E5%B2%B3%E9%98%B3%E5%B8%82" title="岳阳市">岳阳市</a></li>
<li><a href="/wiki/%E6%A0%AA%E6%B4%B2%E5%B8%82" title="株洲市">株洲市</a></li>
<li><a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">长沙市</a></li>
<li><a href="/wiki/%E6%B9%98%E6%BD%AD%E5%B8%82" title="湘潭市">湘潭市</a></li>
<li><a href="/wiki/%E5%A8%84%E5%BA%95%E5%B8%82" title="娄底市">娄底市</a></li>
<li><a href="/wiki/%E9%83%B4%E5%B7%9E%E5%B8%82" title="郴州市">郴州市</a></li>
<li><a href="/wiki/%E8%A1%A1%E9%98%B3%E5%B8%82" title="衡阳市">衡阳市</a></li>
<li><a href="/wiki/%E8%B5%84%E5%85%B4%E5%B8%82" title="资兴市">资兴市</a></li>
<li><a href="/wiki/%E9%86%B4%E9%99%B5%E5%B8%82" title="醴陵市">醴陵市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省"><span style="color:white;">广东省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E7%8F%A0%E6%B5%B7%E5%B8%82" title="珠海市">珠海市</a></li>
<li><a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">深圳市</a></li>
<li><a href="/wiki/%E4%B8%AD%E5%B1%B1%E5%B8%82" title="中山市">中山市</a></li>
<li><a href="/wiki/%E4%BD%9B%E5%B1%B1%E5%B8%82" title="佛山市">佛山市</a></li>
<li><a href="/wiki/%E6%B1%9F%E9%97%A8%E5%B8%82" title="江门市">江门市</a></li>
<li><a href="/wiki/%E6%83%A0%E5%B7%9E%E5%B8%82" title="惠州市">惠州市</a></li>
<li><a href="/wiki/%E8%8C%82%E5%90%8D%E5%B8%82" title="茂名市">茂名市</a></li>
<li><a href="/wiki/%E8%82%87%E5%BA%86%E5%B8%82" title="肇庆市">肇庆市</a></li>
<li><a href="/wiki/%E5%BC%80%E5%B9%B3%E5%B8%82" title="开平市">开平市</a></li>
<li><a href="/wiki/%E6%B9%9B%E6%B1%9F%E5%B8%82" title="湛江市">湛江市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">广州市</a></li>
<li><a href="/wiki/%E4%B8%9C%E8%8E%9E%E5%B8%82" title="东莞市">东莞市</a></li>
<li><a href="/wiki/%E6%BD%AE%E5%B7%9E%E5%B8%82" title="潮州市">潮州市</a></li>
<li><a href="/wiki/%E9%9F%B6%E5%85%B3%E5%B8%82" title="韶关市">韶关市</a></li>
<li><a href="/wiki/%E6%A2%85%E5%B7%9E%E5%B8%82" title="梅州市">梅州市</a></li>
<li><a href="/wiki/%E6%B1%95%E5%A4%B4%E5%B8%82" title="汕头市">汕头市</a></li>
<li><a href="/wiki/%E9%98%B3%E6%B1%9F%E5%B8%82" title="阳江市">阳江市</a></li>
<li><a href="/wiki/%E6%B8%85%E8%BF%9C%E5%B8%82" title="清远市">清远市</a></li>
<li><a href="/wiki/%E6%B2%B3%E6%BA%90%E5%B8%82" title="河源市">河源市</a></li>
<li><a href="/wiki/%E4%BA%91%E6%B5%AE%E5%B8%82" title="云浮市">云浮市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区"><span style="color:white;">广西壮族自治区</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8D%97%E5%AE%81%E5%B8%82" title="南宁市">南宁市</a></li>
<li><a href="/wiki/%E6%A1%82%E6%9E%97%E5%B8%82" title="桂林市">桂林市</a></li>
<li><a href="/wiki/%E6%9F%B3%E5%B7%9E%E5%B8%82" title="柳州市">柳州市</a></li>
<li><a href="/wiki/%E5%8C%97%E6%B5%B7%E5%B8%82" title="北海市">北海市</a></li>
<li><a href="/wiki/%E7%99%BE%E8%89%B2%E5%B8%82" title="百色市">百色市</a></li>
<li><a href="/wiki/%E6%A2%A7%E5%B7%9E%E5%B8%82" title="梧州市">梧州市</a></li>
<li><a href="/wiki/%E5%8C%97%E6%B5%81%E5%B8%82" title="北流市">北流市</a></li>
<li><a href="/wiki/%E9%92%A6%E5%B7%9E%E5%B8%82" title="钦州市">钦州市</a></li>
<li><a href="/wiki/%E7%8E%89%E6%9E%97%E5%B8%82" title="玉林市">玉林市</a></li>
<li><a href="/wiki/%E9%98%B2%E5%9F%8E%E6%B8%AF%E5%B8%82" title="防城港市">防城港市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省"><span style="color:white;">海南省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">海口市</a></li>
<li><a href="/wiki/%E4%B8%89%E4%BA%9A%E5%B8%82" title="三亚市">三亚市</a></li>
<li><a href="/wiki/%E5%84%8B%E5%B7%9E%E5%B8%82" title="儋州市">儋州市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市"><span style="color:white;">重庆市</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%8C%97%E7%A2%9A%E5%8C%BA" title="北碚区">北碚区</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省"><span style="color:white;">四川省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%B3%A8%E7%9C%89%E5%B1%B1%E5%B8%82" title="峨眉山市">峨眉山市</a></li>
<li><a href="/wiki/%E7%BB%B5%E9%98%B3%E5%B8%82" title="绵阳市">绵阳市</a></li>
<li><a href="/wiki/%E9%83%BD%E6%B1%9F%E5%A0%B0%E5%B8%82" title="都江堰市">都江堰市</a></li>
<li><a href="/wiki/%E4%B9%90%E5%B1%B1%E5%B8%82" title="乐山市">乐山市</a></li>
<li><a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">成都市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%AE%89%E5%B8%82" title="广安市">广安市</a></li>
<li><a href="/wiki/%E5%8D%97%E5%85%85%E5%B8%82" title="南充市">南充市</a></li>
<li><a href="/wiki/%E9%81%82%E5%AE%81%E5%B8%82" title="遂宁市">遂宁市</a></li>
<li><a href="/wiki/%E8%87%AA%E8%B4%A1%E5%B8%82" title="自贡市">自贡市</a></li>
<li><a href="/wiki/%E5%BE%B7%E9%98%B3%E5%B8%82" title="德阳市">德阳市</a></li>
<li><a href="/wiki/%E7%9C%89%E5%B1%B1%E5%B8%82" title="眉山市">眉山市</a></li>
<li><a href="/wiki/%E6%B3%B8%E5%B7%9E%E5%B8%82" title="泸州市">泸州市</a></li>
<li><a href="/wiki/%E9%98%86%E4%B8%AD%E5%B8%82" title="阆中市">阆中市</a></li>
<li><a href="/wiki/%E6%94%80%E6%9E%9D%E8%8A%B1%E5%B8%82" title="攀枝花市">攀枝花市</a></li>
<li><a href="/wiki/%E8%B5%84%E9%98%B3%E5%B8%82" title="资阳市">资阳市</a></li>
<li><a href="/wiki/%E5%B9%BF%E5%85%83%E5%B8%82" title="广元市">广元市</a></li>
<li><a href="/wiki/%E5%AE%9C%E5%AE%BE%E5%B8%82" title="宜宾市">宜宾市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省"><span style="color:white;">贵州省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%81%B5%E4%B9%89%E5%B8%82" title="遵义市">遵义市</a></li>
<li><a href="/wiki/%E8%B4%B5%E9%98%B3%E5%B8%82" title="贵阳市">贵阳市</a></li>
<li><a href="/wiki/%E5%AE%89%E9%A1%BA%E5%B8%82" title="安顺市">安顺市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省"><span style="color:white;">云南省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%AE%89%E5%AE%81%E5%B8%82" title="安宁市">安宁市</a></li>
<li><a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">昆明市</a></li>
<li><a href="/wiki/%E7%8E%89%E6%BA%AA%E5%B8%82" title="玉溪市">玉溪市</a></li>
<li><a href="/wiki/%E6%99%AF%E6%B4%AA%E5%B8%82" title="景洪市">景洪市</a></li>
<li><a href="/wiki/%E4%B8%BD%E6%B1%9F%E5%B8%82" title="丽江市">丽江市</a></li>
<li><a href="/wiki/%E6%99%AE%E6%B4%B1%E5%B8%82" title="普洱市">普洱市</a></li>
<li><a href="/wiki/%E5%BC%80%E8%BF%9C%E5%B8%82" title="开远市">开远市</a></li>
<li><a href="/wiki/%E8%8A%92%E5%B8%82" title="芒市">芒市</a></li>
<li><a href="/wiki/%E6%9B%B2%E9%9D%96%E5%B8%82" title="曲靖市">曲靖市</a></li>
<li><a href="/wiki/%E5%A4%A7%E7%90%86%E5%B8%82" title="大理市">大理市</a></li>
<li><a href="/wiki/%E8%85%BE%E5%86%B2%E5%B8%82" title="腾冲市">腾冲市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区"><span style="color:white;">西藏自治区</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E6%8B%89%E8%90%A8%E5%B8%82" title="拉萨市">拉萨市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省"><span style="color:white;">陕西省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E5%AE%9D%E9%B8%A1%E5%B8%82" title="宝鸡市">宝鸡市</a></li>
<li><a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">西安市</a></li>
<li><a href="/wiki/%E5%92%B8%E9%98%B3%E5%B8%82" title="咸阳市">咸阳市</a></li>
<li><a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">延安市</a></li>
<li><a href="/wiki/%E6%B1%89%E4%B8%AD%E5%B8%82" title="汉中市">汉中市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省"><span style="color:white;">青海省</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E8%A5%BF%E5%AE%81%E5%B8%82" title="西宁市">西宁市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省"><span style="color:white;">甘肃省</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%87%91%E6%98%8C%E5%B8%82" title="金昌市">金昌市</a></li>
<li><a href="/wiki/%E6%95%A6%E7%85%8C%E5%B8%82" title="敦煌市">敦煌市</a></li>
<li><a href="/wiki/%E5%98%89%E5%B3%AA%E5%85%B3%E5%B8%82" title="嘉峪关市">嘉峪关市</a></li>
<li><a href="/wiki/%E7%8E%89%E9%97%A8%E5%B8%82" title="玉门市">玉门市</a></li>
<li><a href="/wiki/%E5%85%B0%E5%B7%9E%E5%B8%82" title="兰州市">兰州市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区"><span style="color:white;">宁夏回族自治区</span></a></th><td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">银川市</a></li>
<li><a href="/wiki/%E9%9D%92%E9%93%9C%E5%B3%A1%E5%B8%82" title="青铜峡市">青铜峡市</a></li>
<li><a href="/wiki/%E5%90%B4%E5%BF%A0%E5%B8%82" title="吴忠市">吴忠市</a></li>
<li><a href="/wiki/%E4%B8%AD%E5%8D%AB%E5%B8%82" title="中卫市">中卫市</a></li>
<li><a href="/wiki/%E7%81%B5%E6%AD%A6%E5%B8%82" title="灵武市">灵武市</a></li>
<li><a href="/wiki/%E7%9F%B3%E5%98%B4%E5%B1%B1%E5%B8%82" title="石嘴山市">石嘴山市</a></li>
<li><a href="/wiki/%E5%9B%BA%E5%8E%9F%E5%B8%82" title="固原市">固原市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><th scope="row" class="navbox-group" style="color: #ffffff; background-color:#3CB371; text-align: center;"><a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区"><span style="color:white;">新疆维吾尔自治区</span></a></th><td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><a href="/wiki/%E7%9F%B3%E6%B2%B3%E5%AD%90%E5%B8%82" title="石河子市">石河子市</a></li>
<li><a href="/wiki/%E5%BA%93%E5%B0%94%E5%8B%92%E5%B8%82" title="库尔勒市">库尔勒市</a></li>
<li><a href="/wiki/%E5%85%8B%E6%8B%89%E7%8E%9B%E4%BE%9D%E5%B8%82" title="克拉玛依市">克拉玛依市</a></li>
<li><a href="/wiki/%E6%98%8C%E5%90%89%E5%B8%82" title="昌吉市">昌吉市</a></li>
<li><a href="/wiki/%E5%A5%8E%E5%B1%AF%E5%B8%82" title="奎屯市">奎屯市</a></li>
<li><a href="/wiki/%E5%93%88%E5%AF%86%E5%B8%82" title="哈密市">哈密市</a></li>
<li><a href="/wiki/%E4%BC%8A%E5%AE%81%E5%B8%82" title="伊宁市">伊宁市</a></li>
<li><a href="/wiki/%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%B8%82" title="乌鲁木齐市">乌鲁木齐市</a></li>
<li><a href="/wiki/%E9%98%BF%E5%8B%92%E6%B3%B0%E5%B8%82" title="阿勒泰市">阿勒泰市</a></li>
<li><a href="/wiki/%E4%BA%94%E5%AE%B6%E6%B8%A0%E5%B8%82" title="五家渠市">五家渠市</a></li>
<li><a href="/wiki/%E9%98%9C%E5%BA%B7%E5%B8%82" title="阜康市">阜康市</a></li>
<li><a href="/wiki/%E5%8D%9A%E4%B9%90%E5%B8%82" title="博乐市">博乐市</a></li>
<li><a href="/wiki/%E5%90%90%E9%B2%81%E7%95%AA%E5%B8%82" title="吐鲁番市">吐鲁番市</a></li>
<li><a href="/wiki/%E9%98%BF%E6%8B%89%E5%B0%94%E5%B8%82" title="阿拉尔市">阿拉尔市</a></li>
<li><a href="/wiki/%E5%9B%BE%E6%9C%A8%E8%88%92%E5%85%8B%E5%B8%82" title="图木舒克市">图木舒克市</a></li></ul>
</div></td></tr><tr style="height:2px"><td colspan="3"></td></tr><tr><td class="navbox-abovebelow" colspan="2" style="background:#3CB371; color: #ffffff;"><div>注1:截至2019年公布第二十一批国家园林城市,<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BD%8F%E6%88%BF%E5%92%8C%E5%9F%8E%E4%B9%A1%E5%BB%BA%E8%AE%BE%E9%83%A8" title="中华人民共和国住房和城乡建设部">|<span style="color:white;">住建部</span></a>已经累计授予了376个国家园林城市,11个国家园林区。<br />注2:<s>划线者</s>为因行政区划调整撤销的城市。</div></td></tr></tbody></table></td></tr></tbody></table></div></td></tr></tbody></table></td></tr></tbody></table>
<table cellspacing="0" class="navbox" style="border-spacing:0"><tbody><tr><td style="padding:2px"><table cellspacing="0" class="nowraplinks hlist navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody><tr><th scope="row" class="navbox-group nowrap"><a href="/wiki/Help:%E8%A7%84%E8%8C%83%E6%8E%A7%E5%88%B6" title="Help:规范控制">规范控制</a> <a href="https://www.wikidata.org/wiki/Q956" title="編輯維基數據鏈接"><img alt="編輯維基數據鏈接" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/OOjs_UI_icon_edit-ltr-progressive.svg/10px-OOjs_UI_icon_edit-ltr-progressive.svg.png" decoding="async" width="10" height="10" style="vertical-align: text-top" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/OOjs_UI_icon_edit-ltr-progressive.svg/15px-OOjs_UI_icon_edit-ltr-progressive.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8a/OOjs_UI_icon_edit-ltr-progressive.svg/20px-OOjs_UI_icon_edit-ltr-progressive.svg.png 2x" data-file-width="20" data-file-height="20" /></a></th><td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px"><div style="padding:0em 0.25em">
<ul><li><span class="nowrap"> <a rel="nofollow" class="external text" href="https://www.worldcat.org/identities/containsVIAFID/312565158">WorldCat Identities</a></span></li>
<li><span class="nowrap"><a href="/wiki/%E8%97%9D%E8%A1%93%E8%88%87%E5%BB%BA%E7%AF%89%E7%B4%A2%E5%BC%95%E5%85%B8" title="藝術與建築索引典">AAT</a>: <span class="uid"><a rel="nofollow" class="external text" href="http://vocab.getty.edu/page/aat/300245351">300245351</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E6%B3%95%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%BE%E4%B9%A6%E9%A6%86" class="mw-redirect" title="法国国家图书馆">BNF</a>: <span class="uid"><a rel="nofollow" class="external text" href="http://catalogue.bnf.fr/ark:/12148/cb11957264c">cb11957264c</a> <a rel="nofollow" class="external text" href="http://data.bnf.fr/ark:/12148/cb11957264c">(data)</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E6%95%B4%E5%90%88%E8%A7%84%E8%8C%83%E6%96%87%E6%A1%A3" title="整合规范文档">GND</a>: <span class="uid"><a rel="nofollow" class="external text" href="https://d-nb.info/gnd/4075971-4">4075971-4</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E5%9C%8B%E9%9A%9B%E6%A8%99%E6%BA%96%E5%90%8D%E7%A8%B1%E8%AD%98%E5%88%A5%E7%A2%BC" title="國際標準名稱識別碼">ISNI</a>: <span class="uid"><a rel="nofollow" class="external text" href="http://isni.org/isni/0000000121597692">0000 0001 2159 7692</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E7%BE%8E%E5%9B%BD%E5%9B%BD%E4%BC%9A%E5%9B%BE%E4%B9%A6%E9%A6%86%E6%8E%A7%E5%88%B6%E5%8F%B7" title="美国国会图书馆控制号">LCCN</a>: <span class="uid"><a rel="nofollow" class="external text" href="http://id.loc.gov/authorities/names/n79076155">n79076155</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E5%9B%BD%E5%AE%B6%E6%A1%A3%E6%A1%88%E5%92%8C%E8%AE%B0%E5%BD%95%E7%AE%A1%E7%90%86%E5%B1%80" title="国家档案和记录管理局">NARA</a>: <span class="uid"><a rel="nofollow" class="external text" href="https://catalog.archives.gov/id/10036657">10036657</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E5%9C%8B%E7%AB%8B%E5%9C%8B%E6%9C%83%E5%9C%96%E6%9B%B8%E9%A4%A8" title="國立國會圖書館">NDL</a>: <span class="uid"><a rel="nofollow" class="external text" href="https://id.ndl.go.jp/auth/ndlna/00646810">00646810</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E6%8D%B7%E5%85%8B%E5%9B%BD%E5%AE%B6%E5%9B%BE%E4%B9%A6%E9%A6%86" class="mw-redirect" title="捷克国家图书馆">NKC</a>: <span class="uid"><a rel="nofollow" class="external text" href="https://aleph.nkp.cz/F/?func=find-c&local_base=aut&ccl_term=ica=ge130384&CON_LNG=ENG">ge130384</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E4%BB%A5%E8%89%B2%E5%88%97%E5%9B%BD%E5%AE%B6%E5%9B%BE%E4%B9%A6%E9%A6%86" title="以色列国家图书馆">NNL</a>: <span class="uid"><a rel="nofollow" class="external text" href="http://aleph.nli.org.il/F/?func=find-b&local_base=NNL10&find_code=SYS&con_lng=eng&request=000976022">000976022</a></span></span></li>
<li><span class="nowrap"><a href="/wiki/%E8%99%9A%E6%8B%9F%E5%9B%BD%E9%99%85%E8%A7%84%E8%8C%83%E6%96%87%E6%A1%A3" title="虚拟国际规范文档">VIAF</a>: <span class="uid"><a rel="nofollow" class="external text" href="https://viaf.org/viaf/312565158">312565158</a></span></span></li></ul>
</div></td></tr></tbody></table></td></tr></tbody></table>
<!--
NewPP limit report
Parsed by mw1401
Cached time: 20210109032017
Cache expiry: 86400
Dynamic content: true
Complications: []
CPU time usage: 3.848 seconds
Real time usage: 4.782 seconds
Preprocessor visited node count: 29346/1000000
Post‐expand include size: 2036601/2097152 bytes
Template argument size: 274762/2097152 bytes
Highest expansion depth: 22/40
Expensive parser function count: 25/500
Unstrip recursion depth: 0/20
Unstrip post‐expand size: 202785/5000000 bytes
Lua time usage: 1.006/10.000 seconds
Lua memory usage: 10095269/52428800 bytes
Lua Profile:
Scribunto_LuaSandboxCallback::getExpandedArgument 460 ms 32.9%
Scribunto_LuaSandboxCallback::find 220 ms 15.7%
? 100 ms 7.1%
<mw.lua:683> 80 ms 5.7%
Scribunto_LuaSandboxCallback::getEntity 80 ms 5.7%
recursiveClone <mwInit.lua:41> 60 ms 4.3%
tonumber 40 ms 2.9%
Scribunto_LuaSandboxCallback::newTitle 40 ms 2.9%
Scribunto_LuaSandboxCallback::getAllExpandedArguments 40 ms 2.9%
Scribunto_LuaSandboxCallback::plain 40 ms 2.9%
[others] 240 ms 17.1%
Number of Wikibase entities loaded: 1/400
-->
<!--
Transclusion expansion time report (%,ms,calls,template)
100.00% 3147.668 1 -total
41.47% 1305.187 44 Template:Navbox
26.25% 826.113 1 Template:Reflist
22.79% 717.504 1 Template:Template_group
15.20% 478.549 97 Template:Cite_web
10.64% 334.758 53 Template:Flag
7.93% 249.616 3 Template:Navbox_with_columns
7.24% 227.781 66 Template:Flagicon
5.92% 186.452 5 Template:Infobox
5.89% 185.443 1 Template:夏季奧運會主辦城市
-->
<!-- Saved in parser cache with key zhwiki:pcache:idhash:463-0!canonical!zh and timestamp 20210109032013 and revision id 63604485. Serialized with JSON.
-->
</div><noscript><img src="//zh.wikipedia.org/wiki/Special:CentralAutoLogin/start?type=1x1" alt="" title="" width="1" height="1" style="border: none; position: absolute;" /></noscript>
<div class="printfooter">取自“<a dir="ltr" href="https://zh.wikipedia.org/w/index.php?title=北京市&oldid=63604485">https://zh.wikipedia.org/w/index.php?title=北京市&oldid=63604485</a>”</div></div>
<div id="catlinks" class="catlinks" data-mw="interface"><div id="mw-normal-catlinks" class="mw-normal-catlinks"><a href="/wiki/Special:%E9%A1%B5%E9%9D%A2%E5%88%86%E7%B1%BB" title="Special:页面分类">分类</a>:<ul><li><a href="/wiki/Category:%E4%BD%BF%E7%94%A8%E4%BA%BA%E5%8F%A3%E6%A8%A1%E6%9D%BF%E7%9A%84%E9%A0%81%E9%9D%A2" title="Category:使用人口模板的頁面">使用人口模板的頁面</a></li><li><a href="/wiki/Category:%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E7%9C%81%E7%B4%9A%E8%A1%8C%E6%94%BF%E5%8D%80" title="Category:中華人民共和國省級行政區">中華人民共和國省級行政區</a></li><li><a href="/wiki/Category:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD" title="Category:亞洲首都">亞洲首都</a></li><li><a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82" title="Category:国家园林城市">国家园林城市</a></li><li><a href="/wiki/Category:%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E7%9B%B4%E8%BD%84%E5%B8%82" title="Category:中華人民共和國直轄市">中華人民共和國直轄市</a></li><li><a href="/wiki/Category:%E5%8C%97%E4%BA%AC%E5%B8%82" title="Category:北京市">北京市</a></li><li><a href="/wiki/Category:%E4%B8%AD%E5%9B%BD%E7%89%B9%E5%A4%A7%E5%9F%8E%E5%B8%82" title="Category:中国特大城市">中国特大城市</a></li><li><a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="Category:国家历史文化名城">国家历史文化名城</a></li><li><a href="/wiki/Category:%E4%BA%AC%E6%B4%A5%E5%86%80%E5%9F%8E%E5%B8%82%E7%BE%A4" title="Category:京津冀城市群">京津冀城市群</a></li><li><a href="/wiki/Category:%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Category:夏季奥林匹克运动会主办城市">夏季奥林匹克运动会主办城市</a></li><li><a href="/wiki/Category:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Category:亚洲运动会主办城市">亚洲运动会主办城市</a></li><li><a href="/wiki/Category:%E4%B8%AD%E5%9B%BD%E5%8E%86%E4%BB%A3%E5%9B%BD%E9%83%BD" title="Category:中国历代国都">中国历代国都</a></li><li><a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Category:国家中心城市">国家中心城市</a></li><li><a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E7%BB%8F%E6%B5%8E%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Category:国家经济中心城市">国家经济中心城市</a></li></ul></div><div id="mw-hidden-catlinks" class="mw-hidden-catlinks mw-hidden-cats-hidden">隐藏分类:<ul><li><a href="/wiki/Category:%E6%9C%89%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE%E9%94%99%E8%AF%AF%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:有参考文献错误的页面">有参考文献错误的页面</a></li><li><a href="/wiki/Category:CS1%E8%8B%B1%E8%AF%AD%E6%9D%A5%E6%BA%90_(en)" title="Category:CS1英语来源 (en)">CS1英语来源 (en)</a></li><li><a href="/wiki/Category:CS1%E5%90%AB%E6%9C%89%E4%B8%AD%E6%96%87%E6%96%87%E6%9C%AC_(zh)" title="Category:CS1含有中文文本 (zh)">CS1含有中文文本 (zh)</a></li><li><a href="/wiki/Category:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF%EF%BC%9A%E6%97%A5%E6%9C%9F" title="Category:引文格式1错误:日期">引文格式1错误:日期</a></li><li><a href="/wiki/Category:%E5%90%AB%E6%9C%89%E8%AE%BF%E9%97%AE%E6%97%A5%E6%9C%9F%E4%BD%86%E6%97%A0%E7%BD%91%E5%9D%80%E7%9A%84%E5%BC%95%E7%94%A8%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:含有访问日期但无网址的引用的页面">含有访问日期但无网址的引用的页面</a></li><li><a href="/wiki/Category:CS1%E4%BF%84%E8%AF%AD%E6%9D%A5%E6%BA%90_(ru)" title="Category:CS1俄语来源 (ru)">CS1俄语来源 (ru)</a></li><li><a href="/wiki/Category:CS1%E7%BE%8E%E5%9B%BD%E8%8B%B1%E8%AF%AD%E6%9D%A5%E6%BA%90_(en-us)" title="Category:CS1美国英语来源 (en-us)">CS1美国英语来源 (en-us)</a></li><li><a href="/wiki/Category:%E9%A1%B6%E6%B3%A8%E9%87%8D%E5%AE%9A%E5%90%91%E9%9C%80%E8%A6%81%E5%AE%A1%E9%98%85%E7%9A%84%E6%9D%A1%E7%9B%AE" title="Category:顶注重定向需要审阅的条目">顶注重定向需要审阅的条目</a></li><li><a href="/wiki/Category:%E7%BB%B4%E5%9F%BA%E6%95%B0%E6%8D%AE%E5%AD%98%E5%9C%A8%E5%9D%90%E6%A0%87%E6%95%B0%E6%8D%AE%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:维基数据存在坐标数据的页面">维基数据存在坐标数据的页面</a></li><li><a href="/wiki/Category:%E4%BD%BF%E7%94%A8%E5%A4%9A%E4%B8%AA%E5%9B%BE%E5%83%8F%E4%B8%94%E8%87%AA%E5%8A%A8%E7%BC%A9%E6%94%BE%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:使用多个图像且自动缩放的页面">使用多个图像且自动缩放的页面</a></li><li><a href="/wiki/Category:%E5%90%AB%E6%9C%89%E9%9D%9E%E4%B8%AD%E6%96%87%E5%85%A7%E5%AE%B9%E7%9A%84%E6%A2%9D%E7%9B%AE" title="Category:含有非中文內容的條目">含有非中文內容的條目</a></li><li><a href="/wiki/Category:%E5%B5%8C%E5%85%A5hAudio%E5%BE%AE%E6%A0%BC%E5%BC%8F%E7%9A%84%E6%A2%9D%E7%9B%AE" title="Category:嵌入hAudio微格式的條目">嵌入hAudio微格式的條目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABAAT%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含AAT标识符的维基百科条目">包含AAT标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABBNF%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含BNF标识符的维基百科条目">包含BNF标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABGND%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含GND标识符的维基百科条目">包含GND标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABISNI%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含ISNI标识符的维基百科条目">包含ISNI标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABLCCN%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含LCCN标识符的维基百科条目">包含LCCN标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABNARA%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NARA标识符的维基百科条目">包含NARA标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABNDL%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NDL标识符的维基百科条目">包含NDL标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABNKC%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NKC标识符的维基百科条目">包含NKC标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABNNL%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NNL标识符的维基百科条目">包含NNL标识符的维基百科条目</a></li><li><a href="/wiki/Category:%E5%8C%85%E5%90%ABVIAF%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含VIAF标识符的维基百科条目">包含VIAF标识符的维基百科条目</a></li></ul></div></div>
</div>
</div>
<div id='mw-data-after-content'>
<div class="read-more-container"></div>
</div>
<div id="mw-navigation">
<h2>导航菜单</h2>
<div id="mw-head">
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-personal" class="mw-portlet mw-portlet-personal vector-menu" aria-labelledby="p-personal-label" role="navigation"
>
<h3 id="p-personal-label">
<span>个人工具</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="pt-anonuserpage">没有登录</li><li id="pt-anontalk"><a href="/wiki/Special:%E6%88%91%E7%9A%84%E8%AE%A8%E8%AE%BA%E9%A1%B5" title="对于来自此IP地址编辑的讨论[n]" accesskey="n">讨论</a></li><li id="pt-anoncontribs"><a href="/wiki/Special:%E6%88%91%E7%9A%84%E8%B4%A1%E7%8C%AE" title="来自此IP地址的编辑列表[y]" accesskey="y">贡献</a></li><li id="pt-createaccount"><a href="/w/index.php?title=Special:%E5%88%9B%E5%BB%BA%E8%B4%A6%E6%88%B7&returnto=%E5%8C%97%E4%BA%AC%E5%B8%82" title="建议您创建一个账户并登录,但这不是强制的">创建账户</a></li><li id="pt-login"><a href="/w/index.php?title=Special:%E7%94%A8%E6%88%B7%E7%99%BB%E5%BD%95&returnto=%E5%8C%97%E4%BA%AC%E5%B8%82" title="建议你登录,尽管并非必须。[o]" accesskey="o">登录</a></li></ul>
</div>
</nav>
<div id="left-navigation">
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-namespaces" class="mw-portlet mw-portlet-namespaces vector-menu vector-menu-tabs" aria-labelledby="p-namespaces-label" role="navigation"
>
<h3 id="p-namespaces-label">
<span>名字空间</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="ca-nstab-main" class="selected"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" title="浏览条目正文[c]" accesskey="c">条目</a></li><li id="ca-talk"><a href="/wiki/Talk:%E5%8C%97%E4%BA%AC%E5%B8%82" rel="discussion" title="关于此页面的讨论[t]" accesskey="t">讨论</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-variants" class="mw-portlet mw-portlet-variants vector-menu vector-menu-dropdown" aria-labelledby="p-variants-label" role="navigation"
>
<input type="checkbox" class="vector-menu-checkbox" aria-labelledby="p-variants-label" />
<h3 id="p-variants-label">
<span>不转换</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="ca-varlang-0" class="selected"><a href="/zh/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh" hreflang="zh">不转换</a></li><li id="ca-varlang-1"><a href="/zh-hans/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hans" hreflang="zh-Hans">简体</a></li><li id="ca-varlang-2"><a href="/zh-hant/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hant" hreflang="zh-Hant">繁體</a></li><li id="ca-varlang-3"><a href="/zh-cn/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hans-CN" hreflang="zh-Hans-CN">大陆简体</a></li><li id="ca-varlang-4"><a href="/zh-hk/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hant-HK" hreflang="zh-Hant-HK">香港繁體</a></li><li id="ca-varlang-5"><a href="/zh-mo/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hant-MO" hreflang="zh-Hant-MO">澳門繁體</a></li><li id="ca-varlang-6"><a href="/zh-my/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hans-MY" hreflang="zh-Hans-MY">大马简体</a></li><li id="ca-varlang-7"><a href="/zh-sg/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hans-SG" hreflang="zh-Hans-SG">新加坡简体</a></li><li id="ca-varlang-8"><a href="/zh-tw/%E5%8C%97%E4%BA%AC%E5%B8%82" lang="zh-Hant-TW" hreflang="zh-Hant-TW">臺灣正體</a></li></ul>
</div>
</nav>
</div>
<div id="right-navigation">
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-views" class="mw-portlet mw-portlet-views vector-menu vector-menu-tabs" aria-labelledby="p-views-label" role="navigation"
>
<h3 id="p-views-label">
<span>视图</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="ca-view" class="selected"><a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82">阅读</a></li><li id="ca-edit"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit" title="编辑本页[e]" accesskey="e">编辑</a></li><li id="ca-history"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=history" title="本页面的早前版本。[h]" accesskey="h">查看历史</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-cactions" class="mw-portlet mw-portlet-cactions emptyPortlet vector-menu vector-menu-dropdown" aria-labelledby="p-cactions-label" role="navigation"
>
<input type="checkbox" class="vector-menu-checkbox" aria-labelledby="p-cactions-label" />
<h3 id="p-cactions-label">
<span>更多</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"></ul>
</div>
</nav>
<div id="p-search" role="search">
<h3 >
<label for="searchInput">搜索</label>
</h3>
<form action="/w/index.php" id="searchform">
<div id="simpleSearch" data-search-loc="header-navigation">
<input type="search" name="search" placeholder="搜索维基百科" autocapitalize="sentences" title="搜索维基百科[f]" accesskey="f" id="searchInput"/>
<input type="hidden" name="title" value="Special:搜索">
<input type="submit" name="fulltext" value="搜索" title="搜索含这些文字的页面" id="mw-searchButton" class="searchButton mw-fallbackSearchButton"/>
<input type="submit" name="go" value="前往" title="若相同标题存在,则直接前往该页面" id="searchButton" class="searchButton"/>
</div>
</form>
</div>
</div>
</div>
<div id="mw-panel">
<div id="p-logo" role="banner">
<a title="首页" class="mw-wiki-logo" href="/wiki/Wikipedia:%E9%A6%96%E9%A1%B5"></a>
</div>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-navigation" class="mw-portlet mw-portlet-navigation vector-menu vector-menu-portal portal portal-first" aria-labelledby="p-navigation-label" role="navigation"
>
<h3 id="p-navigation-label">
<span>导航</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="n-mainpage-description"><a href="/wiki/Wikipedia:%E9%A6%96%E9%A1%B5" title="访问首页[z]" accesskey="z">首页</a></li><li id="n-indexpage"><a href="/wiki/Wikipedia:%E5%88%86%E7%B1%BB%E7%B4%A2%E5%BC%95" title="以分类索引搜寻中文维基百科">分类索引</a></li><li id="n-Featured_content"><a href="/wiki/Portal:%E7%89%B9%E8%89%B2%E5%85%A7%E5%AE%B9" title="查看中文维基百科的特色内容">特色内容</a></li><li id="n-currentevents"><a href="/wiki/Portal:%E6%96%B0%E8%81%9E%E5%8B%95%E6%85%8B" title="提供当前新闻事件的背景资料">新闻动态</a></li><li id="n-recentchanges"><a href="/wiki/Special:%E6%9C%80%E8%BF%91%E6%9B%B4%E6%94%B9" title="列出维基百科中的最近修改[r]" accesskey="r">最近更改</a></li><li id="n-randompage"><a href="/wiki/Special:%E9%9A%8F%E6%9C%BA%E9%A1%B5%E9%9D%A2" title="随机载入一个页面[x]" accesskey="x">随机条目</a></li><li id="n-sitesupport"><a href="https://donate.wikimedia.org/?utm_source=donate&utm_medium=sidebar&utm_campaign=spontaneous&uselang=zh-hans" title="如果您在維基百科受益良多,您可以考慮資助我們">资助维基百科</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-help" class="mw-portlet mw-portlet-help vector-menu vector-menu-portal portal" aria-labelledby="p-help-label" role="navigation"
>
<h3 id="p-help-label">
<span>帮助</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="n-help"><a href="/wiki/Help:%E7%9B%AE%E5%BD%95" title="寻求帮助">帮助</a></li><li id="n-portal"><a href="/wiki/Wikipedia:%E7%A4%BE%E7%BE%A4%E9%A6%96%E9%A1%B5" title="关于本计划、你可以做什么、应该如何做">维基社群</a></li><li id="n-policy"><a href="/wiki/Wikipedia:%E6%96%B9%E9%87%9D%E8%88%87%E6%8C%87%E5%BC%95" title="查看维基百科的方针和指引">方针与指引</a></li><li id="n-villagepump"><a href="/wiki/Wikipedia:%E4%BA%92%E5%8A%A9%E5%AE%A2%E6%A0%88" title="参与维基百科社群的讨论">互助客栈</a></li><li id="n-Information_desk"><a href="/wiki/Wikipedia:%E7%9F%A5%E8%AF%86%E9%97%AE%E7%AD%94" title="解答任何与维基百科无关的问题的地方">知识问答</a></li><li id="n-conversion"><a href="/wiki/Wikipedia:%E5%AD%97%E8%AF%8D%E8%BD%AC%E6%8D%A2" title="提出字词转换请求">字词转换</a></li><li id="n-IRC"><a href="/wiki/Wikipedia:IRC%E8%81%8A%E5%A4%A9%E9%A2%91%E9%81%93">IRC即时聊天</a></li><li id="n-contact"><a href="/wiki/Wikipedia:%E8%81%94%E7%BB%9C%E6%88%91%E4%BB%AC" title="如何联络维基百科">联络我们</a></li><li id="n-about"><a href="/wiki/Wikipedia:%E5%85%B3%E4%BA%8E" title="查看维基百科的简介">关于维基百科</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-tb" class="mw-portlet mw-portlet-tb vector-menu vector-menu-portal portal" aria-labelledby="p-tb-label" role="navigation"
>
<h3 id="p-tb-label">
<span>工具</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="t-whatlinkshere"><a href="/wiki/Special:%E9%93%BE%E5%85%A5%E9%A1%B5%E9%9D%A2/%E5%8C%97%E4%BA%AC%E5%B8%82" title="列出所有与本页相链的页面[j]" accesskey="j">链入页面</a></li><li id="t-recentchangeslinked"><a href="/wiki/Special:%E9%93%BE%E5%87%BA%E6%9B%B4%E6%94%B9/%E5%8C%97%E4%BA%AC%E5%B8%82" rel="nofollow" title="页面链出所有页面的更改[k]" accesskey="k">相关更改</a></li><li id="t-upload"><a href="/wiki/Project:%E4%B8%8A%E4%BC%A0" title="上传图像或多媒体文件[u]" accesskey="u">上传文件</a></li><li id="t-specialpages"><a href="/wiki/Special:%E7%89%B9%E6%AE%8A%E9%A1%B5%E9%9D%A2" title="全部特殊页面的列表[q]" accesskey="q">特殊页面</a></li><li id="t-permalink"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&oldid=63604485" title="本页面该版本的固定链接">固定链接</a></li><li id="t-info"><a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=info" title="关于此页面的更多信息">页面信息</a></li><li id="t-cite"><a href="/w/index.php?title=Special:%E5%BC%95%E7%94%A8%E6%AD%A4%E9%A1%B5%E9%9D%A2&page=%E5%8C%97%E4%BA%AC%E5%B8%82&id=63604485&wpFormIdentifier=titleform" title="关于如何引用本页的信息">引用本页</a></li><li id="t-wikibase"><a href="https://www.wikidata.org/wiki/Special:EntityPage/Q956" title="查看连接的数据存储库项[g]" accesskey="g">维基数据项</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-electronpdfservice-sidebar-portlet-heading" class="mw-portlet mw-portlet-electronpdfservice-sidebar-portlet-heading vector-menu vector-menu-portal portal" aria-labelledby="p-electronpdfservice-sidebar-portlet-heading-label" role="navigation"
>
<h3 id="p-electronpdfservice-sidebar-portlet-heading-label">
<span>打印/导出</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li id="electron-print_pdf"><a href="/w/index.php?title=Special:DownloadAsPdf&page=%E5%8C%97%E4%BA%AC%E5%B8%82&action=show-download-screen">下载为PDF</a></li><li id="t-print"><a href="javascript:print();" rel="alternate" title="本页面的可打印版本[p]" accesskey="p">打印页面</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-wikibase-otherprojects" class="mw-portlet mw-portlet-wikibase-otherprojects vector-menu vector-menu-portal portal" aria-labelledby="p-wikibase-otherprojects-label" role="navigation"
>
<h3 id="p-wikibase-otherprojects-label">
<span>在其他项目中</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li class="wb-otherproject-link wb-otherproject-commons"><a href="https://commons.wikimedia.org/wiki/Category:Beijing" hreflang="en">维基共享资源</a></li><li class="wb-otherproject-link wb-otherproject-wikinews"><a href="https://zh.wikinews.org/wiki/Category:%E5%8C%97%E4%BA%AC" hreflang="zh">维基新闻</a></li><li class="wb-otherproject-link wb-otherproject-wikiquote"><a href="https://zh.wikiquote.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="zh">维基语录</a></li><li class="wb-otherproject-link wb-otherproject-wikivoyage"><a href="https://zh.wikivoyage.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="zh">维基导游</a></li></ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav id="p-lang" class="mw-portlet mw-portlet-lang vector-menu vector-menu-portal portal" aria-labelledby="p-lang-label" role="navigation"
>
<h3 id="p-lang-label">
<span>其他语言</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list"><li class="interlanguage-link interwiki-ace"><a href="https://ace.wikipedia.org/wiki/Beijing" title="Beijing – 亚齐语" lang="ace" hreflang="ace" class="interlanguage-link-target">Acèh</a></li><li class="interlanguage-link interwiki-ady"><a href="https://ady.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 阿迪格语" lang="ady" hreflang="ady" class="interlanguage-link-target">Адыгабзэ</a></li><li class="interlanguage-link interwiki-af"><a href="https://af.wikipedia.org/wiki/Beijing" title="Beijing – 南非荷兰语" lang="af" hreflang="af" class="interlanguage-link-target">Afrikaans</a></li><li class="interlanguage-link interwiki-als"><a href="https://als.wikipedia.org/wiki/Peking" title="Peking – Alemannisch" lang="gsw" hreflang="gsw" class="interlanguage-link-target">Alemannisch</a></li><li class="interlanguage-link interwiki-am"><a href="https://am.wikipedia.org/wiki/%E1%89%A4%E1%8B%AA%E1%8C%82%E1%8A%95%E1%8C%8D" title="ቤዪጂንግ – 阿姆哈拉语" lang="am" hreflang="am" class="interlanguage-link-target">አማርኛ</a></li><li class="interlanguage-link interwiki-an"><a href="https://an.wikipedia.org/wiki/Pequ%C3%ADn" title="Pequín – 阿拉贡语" lang="an" hreflang="an" class="interlanguage-link-target">Aragonés</a></li><li class="interlanguage-link interwiki-ang"><a href="https://ang.wikipedia.org/wiki/Pecing" title="Pecing – 古英语" lang="ang" hreflang="ang" class="interlanguage-link-target">Ænglisc</a></li><li class="interlanguage-link interwiki-ar"><a href="https://ar.wikipedia.org/wiki/%D8%A8%D9%83%D9%8A%D9%86" title="بكين – 阿拉伯语" lang="ar" hreflang="ar" class="interlanguage-link-target">العربية</a></li><li class="interlanguage-link interwiki-ary"><a href="https://ary.wikipedia.org/wiki/%D9%BE%D9%8A%D9%83%D9%8A%D9%86" title="پيكين – Moroccan Arabic" lang="ary" hreflang="ary" class="interlanguage-link-target">الدارجة</a></li><li class="interlanguage-link interwiki-arz"><a href="https://arz.wikipedia.org/wiki/%D8%A8%D9%8A%D9%83%D9%8A%D9%86" title="بيكين – Egyptian Arabic" lang="arz" hreflang="arz" class="interlanguage-link-target">مصرى</a></li><li class="interlanguage-link interwiki-as"><a href="https://as.wikipedia.org/wiki/%E0%A6%AC%E0%A7%87%E0%A6%87%E0%A6%9C%E0%A6%BF%E0%A6%82" title="বেইজিং – 阿萨姆语" lang="as" hreflang="as" class="interlanguage-link-target">অসমীয়া</a></li><li class="interlanguage-link interwiki-ast"><a href="https://ast.wikipedia.org/wiki/Beix%C3%ADn" title="Beixín – 阿斯图里亚斯语" lang="ast" hreflang="ast" class="interlanguage-link-target">Asturianu</a></li><li class="interlanguage-link interwiki-awa"><a href="https://awa.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99%E0%A5%8D" title="बेइजिङ् – 阿瓦德语" lang="awa" hreflang="awa" class="interlanguage-link-target">अवधी</a></li><li class="interlanguage-link interwiki-ay"><a href="https://ay.wikipedia.org/wiki/Pekin" title="Pekin – 艾马拉语" lang="ay" hreflang="ay" class="interlanguage-link-target">Aymar aru</a></li><li class="interlanguage-link interwiki-az"><a href="https://az.wikipedia.org/wiki/Pekin" title="Pekin – 阿塞拜疆语" lang="az" hreflang="az" class="interlanguage-link-target">Azərbaycanca</a></li><li class="interlanguage-link interwiki-azb"><a href="https://azb.wikipedia.org/wiki/%D9%BE%DA%A9%D9%86" title="پکن – South Azerbaijani" lang="azb" hreflang="azb" class="interlanguage-link-target">تۆرکجه</a></li><li class="interlanguage-link interwiki-ba"><a href="https://ba.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 巴什基尔语" lang="ba" hreflang="ba" class="interlanguage-link-target">Башҡортса</a></li><li class="interlanguage-link interwiki-bar"><a href="https://bar.wikipedia.org/wiki/Peking" title="Peking – Bavarian" lang="bar" hreflang="bar" class="interlanguage-link-target">Boarisch</a></li><li class="interlanguage-link interwiki-bat-smg"><a href="https://bat-smg.wikipedia.org/wiki/Pek%C4%97ns" title="Pekėns – Samogitian" lang="sgs" hreflang="sgs" class="interlanguage-link-target">Žemaitėška</a></li><li class="interlanguage-link interwiki-bcl"><a href="https://bcl.wikipedia.org/wiki/Pekin" title="Pekin – Central Bikol" lang="bcl" hreflang="bcl" class="interlanguage-link-target">Bikol Central</a></li><li class="interlanguage-link interwiki-be"><a href="https://be.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D1%96%D0%BD" title="Пекін – 白俄罗斯语" lang="be" hreflang="be" class="interlanguage-link-target">Беларуская</a></li><li class="interlanguage-link interwiki-be-x-old"><a href="https://be-tarask.wikipedia.org/wiki/%D0%9F%D1%8D%D0%BA%D1%96%D0%BD" title="Пэкін – Belarusian (Taraškievica orthography)" lang="be-tarask" hreflang="be-tarask" class="interlanguage-link-target">Беларуская (тарашкевіца)</a></li><li class="interlanguage-link interwiki-bg"><a href="https://bg.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 保加利亚语" lang="bg" hreflang="bg" class="interlanguage-link-target">Български</a></li><li class="interlanguage-link interwiki-bh"><a href="https://bh.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%82%E0%A4%97" title="बीजिंग – Bhojpuri" lang="bh" hreflang="bh" class="interlanguage-link-target">भोजपुरी</a></li><li class="interlanguage-link interwiki-bi"><a href="https://bi.wikipedia.org/wiki/Beijing" title="Beijing – 比斯拉马语" lang="bi" hreflang="bi" class="interlanguage-link-target">Bislama</a></li><li class="interlanguage-link interwiki-bjn"><a href="https://bjn.wikipedia.org/wiki/P%C3%A9ycing" title="Péycing – Banjar" lang="bjn" hreflang="bjn" class="interlanguage-link-target">Banjar</a></li><li class="interlanguage-link interwiki-bm"><a href="https://bm.wikipedia.org/wiki/Beijing" title="Beijing – 班巴拉语" lang="bm" hreflang="bm" class="interlanguage-link-target">Bamanankan</a></li><li class="interlanguage-link interwiki-bn"><a href="https://bn.wikipedia.org/wiki/%E0%A6%AC%E0%A7%87%E0%A6%87%E0%A6%9C%E0%A6%BF%E0%A6%82" title="বেইজিং – 孟加拉语" lang="bn" hreflang="bn" class="interlanguage-link-target">বাংলা</a></li><li class="interlanguage-link interwiki-bo"><a href="https://bo.wikipedia.org/wiki/%E0%BD%94%E0%BD%BA%E0%BC%8B%E0%BD%85%E0%BD%B2%E0%BD%84%E0%BC%8B%E0%BD%82%E0%BE%B2%E0%BD%BC%E0%BD%84%E0%BC%8B%E0%BD%81%E0%BE%B1%E0%BD%BA%E0%BD%A2%E0%BC%8D" title="པེ་ཅིང་གྲོང་ཁྱེར། – 藏语" lang="bo" hreflang="bo" class="interlanguage-link-target">བོད་ཡིག</a></li><li class="interlanguage-link interwiki-bpy"><a href="https://bpy.wikipedia.org/wiki/%E0%A6%AC%E0%A7%87%E0%A6%87%E0%A6%9C%E0%A6%BF%E0%A6%82" title="বেইজিং – Bishnupriya" lang="bpy" hreflang="bpy" class="interlanguage-link-target">বিষ্ণুপ্রিয়া মণিপুরী</a></li><li class="interlanguage-link interwiki-br"><a href="https://br.wikipedia.org/wiki/Beijing" title="Beijing – 布列塔尼语" lang="br" hreflang="br" class="interlanguage-link-target">Brezhoneg</a></li><li class="interlanguage-link interwiki-bs"><a href="https://bs.wikipedia.org/wiki/Peking" title="Peking – 波斯尼亚语" lang="bs" hreflang="bs" class="interlanguage-link-target">Bosanski</a></li><li class="interlanguage-link interwiki-bxr"><a href="https://bxr.wikipedia.org/wiki/%D0%91%D1%8D%D1%8D%D0%B6%D1%8D%D0%BD" title="Бээжэн – Russia Buriat" lang="bxr" hreflang="bxr" class="interlanguage-link-target">Буряад</a></li><li class="interlanguage-link interwiki-ca"><a href="https://ca.wikipedia.org/wiki/Pequ%C3%ADn" title="Pequín – 加泰罗尼亚语" lang="ca" hreflang="ca" class="interlanguage-link-target">Català</a></li><li class="interlanguage-link interwiki-cbk-zam"><a href="https://cbk-zam.wikipedia.org/wiki/Pek%C3%ADn" title="Pekín – Chavacano" lang="cbk" hreflang="cbk" class="interlanguage-link-target">Chavacano de Zamboanga</a></li><li class="interlanguage-link interwiki-cdo"><a href="https://cdo.wikipedia.org/wiki/B%C3%A1e%CC%A4k-g%C4%ADng" title="Báe̤k-gĭng – Min Dong Chinese" lang="cdo" hreflang="cdo" class="interlanguage-link-target">Mìng-dĕ̤ng-ngṳ̄</a></li><li class="interlanguage-link interwiki-ce"><a href="https://ce.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 车臣语" lang="ce" hreflang="ce" class="interlanguage-link-target">Нохчийн</a></li><li class="interlanguage-link interwiki-ceb"><a href="https://ceb.wikipedia.org/wiki/Pekin" title="Pekin – 宿务语" lang="ceb" hreflang="ceb" class="interlanguage-link-target">Cebuano</a></li><li class="interlanguage-link interwiki-ch"><a href="https://ch.wikipedia.org/wiki/Beijing" title="Beijing – 查莫罗语" lang="ch" hreflang="ch" class="interlanguage-link-target">Chamoru</a></li><li class="interlanguage-link interwiki-chy"><a href="https://chy.wikipedia.org/wiki/Beijing" title="Beijing – 夏延语" lang="chy" hreflang="chy" class="interlanguage-link-target">Tsetsêhestâhese</a></li><li class="interlanguage-link interwiki-ckb"><a href="https://ckb.wikipedia.org/wiki/%D9%BE%DB%8E%DA%A9%DB%95%D9%86" title="پێکەن – 中库尔德语" lang="ckb" hreflang="ckb" class="interlanguage-link-target">کوردی</a></li><li class="interlanguage-link interwiki-crh"><a href="https://crh.wikipedia.org/wiki/Pekin" title="Pekin – 克里米亚土耳其语" lang="crh" hreflang="crh" class="interlanguage-link-target">Qırımtatarca</a></li><li class="interlanguage-link interwiki-cs"><a href="https://cs.wikipedia.org/wiki/Peking" title="Peking – 捷克语" lang="cs" hreflang="cs" class="interlanguage-link-target">Čeština</a></li><li class="interlanguage-link interwiki-cv"><a href="https://cv.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 楚瓦什语" lang="cv" hreflang="cv" class="interlanguage-link-target">Чӑвашла</a></li><li class="interlanguage-link interwiki-cy"><a href="https://cy.wikipedia.org/wiki/Beijing" title="Beijing – 威尔士语" lang="cy" hreflang="cy" class="interlanguage-link-target">Cymraeg</a></li><li class="interlanguage-link interwiki-da"><a href="https://da.wikipedia.org/wiki/Beijing" title="Beijing – 丹麦语" lang="da" hreflang="da" class="interlanguage-link-target">Dansk</a></li><li class="interlanguage-link interwiki-de badge-Q17437796 badge-featuredarticle" title="典范条目"><a href="https://de.wikipedia.org/wiki/Peking" title="Peking – 德语" lang="de" hreflang="de" class="interlanguage-link-target">Deutsch</a></li><li class="interlanguage-link interwiki-diq"><a href="https://diq.wikipedia.org/wiki/Pekin" title="Pekin – Zazaki" lang="diq" hreflang="diq" class="interlanguage-link-target">Zazaki</a></li><li class="interlanguage-link interwiki-dsb"><a href="https://dsb.wikipedia.org/wiki/Peking" title="Peking – 下索布语" lang="dsb" hreflang="dsb" class="interlanguage-link-target">Dolnoserbski</a></li><li class="interlanguage-link interwiki-dty"><a href="https://dty.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" title="बेइजिङ – Doteli" lang="dty" hreflang="dty" class="interlanguage-link-target">डोटेली</a></li><li class="interlanguage-link interwiki-dv"><a href="https://dv.wikipedia.org/wiki/%DE%84%DE%A9%DE%96%DE%A8%DE%82%DE%B0%DE%8E" title="ބީޖިންގ – 迪维希语" lang="dv" hreflang="dv" class="interlanguage-link-target">ދިވެހިބަސް</a></li><li class="interlanguage-link interwiki-ee"><a href="https://ee.wikipedia.org/wiki/Beijing" title="Beijing – 埃维语" lang="ee" hreflang="ee" class="interlanguage-link-target">Eʋegbe</a></li><li class="interlanguage-link interwiki-el"><a href="https://el.wikipedia.org/wiki/%CE%A0%CE%B5%CE%BA%CE%AF%CE%BD%CE%BF" title="Πεκίνο – 希腊语" lang="el" hreflang="el" class="interlanguage-link-target">Ελληνικά</a></li><li class="interlanguage-link interwiki-en"><a href="https://en.wikipedia.org/wiki/Beijing" title="Beijing – 英语" lang="en" hreflang="en" class="interlanguage-link-target">English</a></li><li class="interlanguage-link interwiki-eo"><a href="https://eo.wikipedia.org/wiki/Pekino" title="Pekino – 世界语" lang="eo" hreflang="eo" class="interlanguage-link-target">Esperanto</a></li><li class="interlanguage-link interwiki-es"><a href="https://es.wikipedia.org/wiki/Pek%C3%ADn" title="Pekín – 西班牙语" lang="es" hreflang="es" class="interlanguage-link-target">Español</a></li><li class="interlanguage-link interwiki-et"><a href="https://et.wikipedia.org/wiki/Peking" title="Peking – 爱沙尼亚语" lang="et" hreflang="et" class="interlanguage-link-target">Eesti</a></li><li class="interlanguage-link interwiki-eu"><a href="https://eu.wikipedia.org/wiki/Pekin" title="Pekin – 巴斯克语" lang="eu" hreflang="eu" class="interlanguage-link-target">Euskara</a></li><li class="interlanguage-link interwiki-ext"><a href="https://ext.wikipedia.org/wiki/Pequ%C3%ADn" title="Pequín – Extremaduran" lang="ext" hreflang="ext" class="interlanguage-link-target">Estremeñu</a></li><li class="interlanguage-link interwiki-fa"><a href="https://fa.wikipedia.org/wiki/%D9%BE%DA%A9%D9%86" title="پکن – 波斯语" lang="fa" hreflang="fa" class="interlanguage-link-target">فارسی</a></li><li class="interlanguage-link interwiki-fi badge-Q17559452 badge-recommendedarticle" title="推荐条目"><a href="https://fi.wikipedia.org/wiki/Peking" title="Peking – 芬兰语" lang="fi" hreflang="fi" class="interlanguage-link-target">Suomi</a></li><li class="interlanguage-link interwiki-fiu-vro"><a href="https://fiu-vro.wikipedia.org/wiki/Peking" title="Peking – võro" lang="vro" hreflang="vro" class="interlanguage-link-target">Võro</a></li><li class="interlanguage-link interwiki-fj"><a href="https://fj.wikipedia.org/wiki/Beijig" title="Beijig – 斐济语" lang="fj" hreflang="fj" class="interlanguage-link-target">Na Vosa Vakaviti</a></li><li class="interlanguage-link interwiki-fo"><a href="https://fo.wikipedia.org/wiki/Beijing" title="Beijing – 法罗语" lang="fo" hreflang="fo" class="interlanguage-link-target">Føroyskt</a></li><li class="interlanguage-link interwiki-fr badge-Q17437798 badge-goodarticle" title="优良条目"><a href="https://fr.wikipedia.org/wiki/P%C3%A9kin" title="Pékin – 法语" lang="fr" hreflang="fr" class="interlanguage-link-target">Français</a></li><li class="interlanguage-link interwiki-frp"><a href="https://frp.wikipedia.org/wiki/P%C3%A8quin" title="Pèquin – Arpitan" lang="frp" hreflang="frp" class="interlanguage-link-target">Arpetan</a></li><li class="interlanguage-link interwiki-frr"><a href="https://frr.wikipedia.org/wiki/Peking" title="Peking – 北弗里西亚语" lang="frr" hreflang="frr" class="interlanguage-link-target">Nordfriisk</a></li><li class="interlanguage-link interwiki-fy"><a href="https://fy.wikipedia.org/wiki/Peking" title="Peking – 西弗里西亚语" lang="fy" hreflang="fy" class="interlanguage-link-target">Frysk</a></li><li class="interlanguage-link interwiki-ga"><a href="https://ga.wikipedia.org/wiki/B%C3%A9ising" title="Béising – 爱尔兰语" lang="ga" hreflang="ga" class="interlanguage-link-target">Gaeilge</a></li><li class="interlanguage-link interwiki-gan"><a href="https://gan.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC" title="北京 – 赣语" lang="gan" hreflang="gan" class="interlanguage-link-target">贛語</a></li><li class="interlanguage-link interwiki-gcr"><a href="https://gcr.wikipedia.org/wiki/P%C3%A9ken" title="Péken – Guianan Creole" lang="gcr" hreflang="gcr" class="interlanguage-link-target">Kriyòl gwiyannen</a></li><li class="interlanguage-link interwiki-gd"><a href="https://gd.wikipedia.org/wiki/Beijing" title="Beijing – 苏格兰盖尔语" lang="gd" hreflang="gd" class="interlanguage-link-target">Gàidhlig</a></li><li class="interlanguage-link interwiki-gl"><a href="https://gl.wikipedia.org/wiki/Pequ%C3%ADn" title="Pequín – 加利西亚语" lang="gl" hreflang="gl" class="interlanguage-link-target">Galego</a></li><li class="interlanguage-link interwiki-gn"><a href="https://gn.wikipedia.org/wiki/Pek%C4%A9" title="Pekĩ – 瓜拉尼语" lang="gn" hreflang="gn" class="interlanguage-link-target">Avañe'ẽ</a></li><li class="interlanguage-link interwiki-gu"><a href="https://gu.wikipedia.org/wiki/%E0%AA%AA%E0%AB%87%E0%AA%87%E0%AA%9A%E0%AA%BF%E0%AA%82%E0%AA%97" title="પેઇચિંગ – 古吉拉特语" lang="gu" hreflang="gu" class="interlanguage-link-target">ગુજરાતી</a></li><li class="interlanguage-link interwiki-gv"><a href="https://gv.wikipedia.org/wiki/Beijing" title="Beijing – 马恩语" lang="gv" hreflang="gv" class="interlanguage-link-target">Gaelg</a></li><li class="interlanguage-link interwiki-ha"><a href="https://ha.wikipedia.org/wiki/Beijing" title="Beijing – 豪萨语" lang="ha" hreflang="ha" class="interlanguage-link-target">Hausa</a></li><li class="interlanguage-link interwiki-hak"><a href="https://hak.wikipedia.org/wiki/Pet-k%C3%AEn" title="Pet-kîn – 客家语" lang="hak" hreflang="hak" class="interlanguage-link-target">客家語/Hak-kâ-ngî</a></li><li class="interlanguage-link interwiki-haw"><a href="https://haw.wikipedia.org/wiki/Beijing" title="Beijing – 夏威夷语" lang="haw" hreflang="haw" class="interlanguage-link-target">Hawaiʻi</a></li><li class="interlanguage-link interwiki-he"><a href="https://he.wikipedia.org/wiki/%D7%91%D7%99%D7%99%D7%92%27%D7%99%D7%A0%D7%92" title="בייג'ינג – 希伯来语" lang="he" hreflang="he" class="interlanguage-link-target">עברית</a></li><li class="interlanguage-link interwiki-hi"><a href="https://hi.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%82%E0%A4%97" title="बीजिंग – 印地语" lang="hi" hreflang="hi" class="interlanguage-link-target">हिन्दी</a></li><li class="interlanguage-link interwiki-hif"><a href="https://hif.wikipedia.org/wiki/Beijing" title="Beijing – Fiji Hindi" lang="hif" hreflang="hif" class="interlanguage-link-target">Fiji Hindi</a></li><li class="interlanguage-link interwiki-hr"><a href="https://hr.wikipedia.org/wiki/Peking" title="Peking – 克罗地亚语" lang="hr" hreflang="hr" class="interlanguage-link-target">Hrvatski</a></li><li class="interlanguage-link interwiki-hsb"><a href="https://hsb.wikipedia.org/wiki/Peking" title="Peking – 上索布语" lang="hsb" hreflang="hsb" class="interlanguage-link-target">Hornjoserbsce</a></li><li class="interlanguage-link interwiki-ht"><a href="https://ht.wikipedia.org/wiki/Peken" title="Peken – 海地克里奥尔语" lang="ht" hreflang="ht" class="interlanguage-link-target">Kreyòl ayisyen</a></li><li class="interlanguage-link interwiki-hu badge-Q17437796 badge-featuredarticle" title="典范条目"><a href="https://hu.wikipedia.org/wiki/Peking" title="Peking – 匈牙利语" lang="hu" hreflang="hu" class="interlanguage-link-target">Magyar</a></li><li class="interlanguage-link interwiki-hy"><a href="https://hy.wikipedia.org/wiki/%D5%8A%D5%A5%D5%AF%D5%AB%D5%B6" title="Պեկին – 亚美尼亚语" lang="hy" hreflang="hy" class="interlanguage-link-target">Հայերեն</a></li><li class="interlanguage-link interwiki-ia"><a href="https://ia.wikipedia.org/wiki/Beijing" title="Beijing – 国际语" lang="ia" hreflang="ia" class="interlanguage-link-target">Interlingua</a></li><li class="interlanguage-link interwiki-id"><a href="https://id.wikipedia.org/wiki/Beijing" title="Beijing – 印度尼西亚语" lang="id" hreflang="id" class="interlanguage-link-target">Bahasa Indonesia</a></li><li class="interlanguage-link interwiki-ie"><a href="https://ie.wikipedia.org/wiki/Beijing" title="Beijing – 国际文字(E)" lang="ie" hreflang="ie" class="interlanguage-link-target">Interlingue</a></li><li class="interlanguage-link interwiki-ilo"><a href="https://ilo.wikipedia.org/wiki/Beijing" title="Beijing – 伊洛卡诺语" lang="ilo" hreflang="ilo" class="interlanguage-link-target">Ilokano</a></li><li class="interlanguage-link interwiki-inh"><a href="https://inh.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 印古什语" lang="inh" hreflang="inh" class="interlanguage-link-target">ГӀалгӀай</a></li><li class="interlanguage-link interwiki-io"><a href="https://io.wikipedia.org/wiki/Beijing" title="Beijing – 伊多语" lang="io" hreflang="io" class="interlanguage-link-target">Ido</a></li><li class="interlanguage-link interwiki-is"><a href="https://is.wikipedia.org/wiki/Beijing" title="Beijing – 冰岛语" lang="is" hreflang="is" class="interlanguage-link-target">Íslenska</a></li><li class="interlanguage-link interwiki-it"><a href="https://it.wikipedia.org/wiki/Pechino" title="Pechino – 意大利语" lang="it" hreflang="it" class="interlanguage-link-target">Italiano</a></li><li class="interlanguage-link interwiki-ja"><a href="https://ja.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" title="北京市 – 日语" lang="ja" hreflang="ja" class="interlanguage-link-target">日本語</a></li><li class="interlanguage-link interwiki-jam"><a href="https://jam.wikipedia.org/wiki/Biejing" title="Biejing – Jamaican Creole English" lang="jam" hreflang="jam" class="interlanguage-link-target">Patois</a></li><li class="interlanguage-link interwiki-jbo"><a href="https://jbo.wikipedia.org/wiki/beidjin" title="beidjin – 逻辑语" lang="jbo" hreflang="jbo" class="interlanguage-link-target">La .lojban.</a></li><li class="interlanguage-link interwiki-jv"><a href="https://jv.wikipedia.org/wiki/Beijing" title="Beijing – 爪哇语" lang="jv" hreflang="jv" class="interlanguage-link-target">Jawa</a></li><li class="interlanguage-link interwiki-ka"><a href="https://ka.wikipedia.org/wiki/%E1%83%9E%E1%83%94%E1%83%99%E1%83%98%E1%83%9C%E1%83%98" title="პეკინი – 格鲁吉亚语" lang="ka" hreflang="ka" class="interlanguage-link-target">ქართული</a></li><li class="interlanguage-link interwiki-kaa"><a href="https://kaa.wikipedia.org/wiki/Pekin" title="Pekin – 卡拉卡尔帕克语" lang="kaa" hreflang="kaa" class="interlanguage-link-target">Qaraqalpaqsha</a></li><li class="interlanguage-link interwiki-kab"><a href="https://kab.wikipedia.org/wiki/Pekin" title="Pekin – 卡拜尔语" lang="kab" hreflang="kab" class="interlanguage-link-target">Taqbaylit</a></li><li class="interlanguage-link interwiki-kbp"><a href="https://kbp.wikipedia.org/wiki/Peek%C9%9B%C9%9B" title="Peekɛɛ – Kabiye" lang="kbp" hreflang="kbp" class="interlanguage-link-target">Kabɩyɛ</a></li><li class="interlanguage-link interwiki-kg"><a href="https://kg.wikipedia.org/wiki/Beijing_(kizunga)" title="Beijing (kizunga) – 刚果语" lang="kg" hreflang="kg" class="interlanguage-link-target">Kongo</a></li><li class="interlanguage-link interwiki-ki"><a href="https://ki.wikipedia.org/wiki/Beijing" title="Beijing – 吉库尤语" lang="ki" hreflang="ki" class="interlanguage-link-target">Gĩkũyũ</a></li><li class="interlanguage-link interwiki-kk"><a href="https://kk.wikipedia.org/wiki/%D0%91%D0%B5%D0%B9%D0%B6%D1%96%D2%A3" title="Бейжің – 哈萨克语" lang="kk" hreflang="kk" class="interlanguage-link-target">Қазақша</a></li><li class="interlanguage-link interwiki-km"><a href="https://km.wikipedia.org/wiki/%E1%9E%94%E1%9F%89%E1%9F%81%E1%9E%80%E1%9E%B6%E1%9F%86%E1%9E%84" title="ប៉េកាំង – 高棉语" lang="km" hreflang="km" class="interlanguage-link-target">ភាសាខ្មែរ</a></li><li class="interlanguage-link interwiki-kn"><a href="https://kn.wikipedia.org/wiki/%E0%B2%AC%E0%B3%80%E0%B2%9C%E0%B2%BF%E0%B2%82%E0%B2%97%E0%B3%8D" title="ಬೀಜಿಂಗ್ – 卡纳达语" lang="kn" hreflang="kn" class="interlanguage-link-target">ಕನ್ನಡ</a></li><li class="interlanguage-link interwiki-ko"><a href="https://ko.wikipedia.org/wiki/%EB%B2%A0%EC%9D%B4%EC%A7%95%EC%8B%9C" title="베이징시 – 韩语" lang="ko" hreflang="ko" class="interlanguage-link-target">한국어</a></li><li class="interlanguage-link interwiki-ku"><a href="https://ku.wikipedia.org/wiki/Beijing" title="Beijing – 库尔德语" lang="ku" hreflang="ku" class="interlanguage-link-target">Kurdî</a></li><li class="interlanguage-link interwiki-kv"><a href="https://kv.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 科米语" lang="kv" hreflang="kv" class="interlanguage-link-target">Коми</a></li><li class="interlanguage-link interwiki-kw"><a href="https://kw.wikipedia.org/wiki/Beijing" title="Beijing – 康沃尔语" lang="kw" hreflang="kw" class="interlanguage-link-target">Kernowek</a></li><li class="interlanguage-link interwiki-ky"><a href="https://ky.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 柯尔克孜语" lang="ky" hreflang="ky" class="interlanguage-link-target">Кыргызча</a></li><li class="interlanguage-link interwiki-la"><a href="https://la.wikipedia.org/wiki/Pechinum" title="Pechinum – 拉丁语" lang="la" hreflang="la" class="interlanguage-link-target">Latina</a></li><li class="interlanguage-link interwiki-lad"><a href="https://lad.wikipedia.org/wiki/Peking" title="Peking – 拉迪诺语" lang="lad" hreflang="lad" class="interlanguage-link-target">Ladino</a></li><li class="interlanguage-link interwiki-lb"><a href="https://lb.wikipedia.org/wiki/Peking" title="Peking – 卢森堡语" lang="lb" hreflang="lb" class="interlanguage-link-target">Lëtzebuergesch</a></li><li class="interlanguage-link interwiki-lez"><a href="https://lez.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 列兹金语" lang="lez" hreflang="lez" class="interlanguage-link-target">Лезги</a></li><li class="interlanguage-link interwiki-li"><a href="https://li.wikipedia.org/wiki/Peking" title="Peking – 林堡语" lang="li" hreflang="li" class="interlanguage-link-target">Limburgs</a></li><li class="interlanguage-link interwiki-lij"><a href="https://lij.wikipedia.org/wiki/Pechin" title="Pechin – Ligurian" lang="lij" hreflang="lij" class="interlanguage-link-target">Ligure</a></li><li class="interlanguage-link interwiki-lld"><a href="https://lld.wikipedia.org/wiki/Beijing" title="Beijing – Ladin" lang="lld" hreflang="lld" class="interlanguage-link-target">Ladin</a></li><li class="interlanguage-link interwiki-lmo"><a href="https://lmo.wikipedia.org/wiki/Pechin" title="Pechin – Lombard" lang="lmo" hreflang="lmo" class="interlanguage-link-target">Lumbaart</a></li><li class="interlanguage-link interwiki-ln"><a href="https://ln.wikipedia.org/wiki/Beij%C3%ADng" title="Beijíng – 林加拉语" lang="ln" hreflang="ln" class="interlanguage-link-target">Lingála</a></li><li class="interlanguage-link interwiki-lo"><a href="https://lo.wikipedia.org/wiki/%E0%BA%9B%E0%BA%B1%E0%BA%81%E0%BA%81%E0%BA%B4%E0%BB%88%E0%BA%87" title="ປັກກິ່ງ – 老挝语" lang="lo" hreflang="lo" class="interlanguage-link-target">ລາວ</a></li><li class="interlanguage-link interwiki-lrc"><a href="https://lrc.wikipedia.org/wiki/%D9%BE%DA%A9%D9%B1%D9%86" title="پکٱن – 北卢尔语" lang="lrc" hreflang="lrc" class="interlanguage-link-target">لۊری شومالی</a></li><li class="interlanguage-link interwiki-lt"><a href="https://lt.wikipedia.org/wiki/Pekinas" title="Pekinas – 立陶宛语" lang="lt" hreflang="lt" class="interlanguage-link-target">Lietuvių</a></li><li class="interlanguage-link interwiki-lv"><a href="https://lv.wikipedia.org/wiki/Pekina" title="Pekina – 拉脱维亚语" lang="lv" hreflang="lv" class="interlanguage-link-target">Latviešu</a></li><li class="interlanguage-link interwiki-mai"><a href="https://mai.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" title="बेइजिङ – 迈蒂利语" lang="mai" hreflang="mai" class="interlanguage-link-target">मैथिली</a></li><li class="interlanguage-link interwiki-mg"><a href="https://mg.wikipedia.org/wiki/Beijing" title="Beijing – 马拉加斯语" lang="mg" hreflang="mg" class="interlanguage-link-target">Malagasy</a></li><li class="interlanguage-link interwiki-mhr"><a href="https://mhr.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – Eastern Mari" lang="mhr" hreflang="mhr" class="interlanguage-link-target">Олык марий</a></li><li class="interlanguage-link interwiki-mi"><a href="https://mi.wikipedia.org/wiki/Beijing" title="Beijing – 毛利语" lang="mi" hreflang="mi" class="interlanguage-link-target">Māori</a></li><li class="interlanguage-link interwiki-min"><a href="https://min.wikipedia.org/wiki/Beijing" title="Beijing – 米南佳保语" lang="min" hreflang="min" class="interlanguage-link-target">Minangkabau</a></li><li class="interlanguage-link interwiki-mk"><a href="https://mk.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD%D0%B3" title="Пекинг – 马其顿语" lang="mk" hreflang="mk" class="interlanguage-link-target">Македонски</a></li><li class="interlanguage-link interwiki-ml"><a href="https://ml.wikipedia.org/wiki/%E0%B4%AC%E0%B5%86%E0%B4%AF%E0%B5%8D%E2%80%8C%E0%B4%9C%E0%B4%BF%E0%B4%99%E0%B5%8D%E0%B4%99%E0%B5%8D%E2%80%8C" title="ബെയ്ജിങ്ങ് – 马拉雅拉姆语" lang="ml" hreflang="ml" class="interlanguage-link-target">മലയാളം</a></li><li class="interlanguage-link interwiki-mn"><a href="https://mn.wikipedia.org/wiki/%D0%91%D1%8D%D1%8D%D0%B6%D0%B8%D0%BD" title="Бээжин – 蒙古语" lang="mn" hreflang="mn" class="interlanguage-link-target">Монгол</a></li><li class="interlanguage-link interwiki-mr"><a href="https://mr.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%82%E0%A4%97" title="बीजिंग – 马拉地语" lang="mr" hreflang="mr" class="interlanguage-link-target">मराठी</a></li><li class="interlanguage-link interwiki-ms"><a href="https://ms.wikipedia.org/wiki/Beijing" title="Beijing – 马来语" lang="ms" hreflang="ms" class="interlanguage-link-target">Bahasa Melayu</a></li><li class="interlanguage-link interwiki-mwl"><a href="https://mwl.wikipedia.org/wiki/Pequin" title="Pequin – 米兰德斯语" lang="mwl" hreflang="mwl" class="interlanguage-link-target">Mirandés</a></li><li class="interlanguage-link interwiki-my"><a href="https://my.wikipedia.org/wiki/%E1%80%95%E1%80%B1%E1%80%80%E1%80%BB%E1%80%84%E1%80%BA%E1%80%B8%E1%80%99%E1%80%BC%E1%80%AD%E1%80%AF%E1%80%B7" title="ပေကျင်းမြို့ – 缅甸语" lang="my" hreflang="my" class="interlanguage-link-target">မြန်မာဘာသာ</a></li><li class="interlanguage-link interwiki-myv"><a href="https://myv.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD_%D0%BE%D1%88" title="Пекин ош – 厄尔兹亚语" lang="myv" hreflang="myv" class="interlanguage-link-target">Эрзянь</a></li><li class="interlanguage-link interwiki-mzn"><a href="https://mzn.wikipedia.org/wiki/%D9%BE%DA%A9%D9%86" title="پکن – 马赞德兰语" lang="mzn" hreflang="mzn" class="interlanguage-link-target">مازِرونی</a></li><li class="interlanguage-link interwiki-na"><a href="https://na.wikipedia.org/wiki/Beijing" title="Beijing – 瑙鲁语" lang="na" hreflang="na" class="interlanguage-link-target">Dorerin Naoero</a></li><li class="interlanguage-link interwiki-ne"><a href="https://ne.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" title="बेइजिङ – 尼泊尔语" lang="ne" hreflang="ne" class="interlanguage-link-target">नेपाली</a></li><li class="interlanguage-link interwiki-new"><a href="https://new.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" title="बेइजिङ – 尼瓦尔语" lang="new" hreflang="new" class="interlanguage-link-target">नेपाल भाषा</a></li><li class="interlanguage-link interwiki-nl"><a href="https://nl.wikipedia.org/wiki/Peking" title="Peking – 荷兰语" lang="nl" hreflang="nl" class="interlanguage-link-target">Nederlands</a></li><li class="interlanguage-link interwiki-nn"><a href="https://nn.wikipedia.org/wiki/Beijing" title="Beijing – 挪威尼诺斯克语" lang="nn" hreflang="nn" class="interlanguage-link-target">Norsk nynorsk</a></li><li class="interlanguage-link interwiki-no badge-Q17437796 badge-featuredarticle" title="典范条目"><a href="https://no.wikipedia.org/wiki/Beijing" title="Beijing – 书面挪威语" lang="nb" hreflang="nb" class="interlanguage-link-target">Norsk bokmål</a></li><li class="interlanguage-link interwiki-nov"><a href="https://nov.wikipedia.org/wiki/Beyjing" title="Beyjing – Novial" lang="nov" hreflang="nov" class="interlanguage-link-target">Novial</a></li><li class="interlanguage-link interwiki-nrm"><a href="https://nrm.wikipedia.org/wiki/P%C3%A9q%C3%B9in" title="Péqùin – Norman" lang="nrf" hreflang="nrf" class="interlanguage-link-target">Nouormand</a></li><li class="interlanguage-link interwiki-nso"><a href="https://nso.wikipedia.org/wiki/Beijing" title="Beijing – 北索托语" lang="nso" hreflang="nso" class="interlanguage-link-target">Sesotho sa Leboa</a></li><li class="interlanguage-link interwiki-ny"><a href="https://ny.wikipedia.org/wiki/Beijing" title="Beijing – 齐切瓦语" lang="ny" hreflang="ny" class="interlanguage-link-target">Chi-Chewa</a></li><li class="interlanguage-link interwiki-oc"><a href="https://oc.wikipedia.org/wiki/Pequin" title="Pequin – 奥克语" lang="oc" hreflang="oc" class="interlanguage-link-target">Occitan</a></li><li class="interlanguage-link interwiki-olo"><a href="https://olo.wikipedia.org/wiki/Pekin" title="Pekin – Livvi-Karelian" lang="olo" hreflang="olo" class="interlanguage-link-target">Livvinkarjala</a></li><li class="interlanguage-link interwiki-om"><a href="https://om.wikipedia.org/wiki/Beejiingi" title="Beejiingi – 奥罗莫语" lang="om" hreflang="om" class="interlanguage-link-target">Oromoo</a></li><li class="interlanguage-link interwiki-or"><a href="https://or.wikipedia.org/wiki/%E0%AC%AC%E0%AD%87%E0%AC%9C%E0%AC%BF%E0%AC%82" title="ବେଜିଂ – 奥里亚语" lang="or" hreflang="or" class="interlanguage-link-target">ଓଡ଼ିଆ</a></li><li class="interlanguage-link interwiki-os"><a href="https://os.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 奥塞梯语" lang="os" hreflang="os" class="interlanguage-link-target">Ирон</a></li><li class="interlanguage-link interwiki-pa"><a href="https://pa.wikipedia.org/wiki/%E0%A8%AC%E0%A9%80%E0%A8%9C%E0%A8%BF%E0%A9%B0%E0%A8%97" title="ਬੀਜਿੰਗ – 旁遮普语" lang="pa" hreflang="pa" class="interlanguage-link-target">ਪੰਜਾਬੀ</a></li><li class="interlanguage-link interwiki-pam"><a href="https://pam.wikipedia.org/wiki/Beijing" title="Beijing – 邦板牙语" lang="pam" hreflang="pam" class="interlanguage-link-target">Kapampangan</a></li><li class="interlanguage-link interwiki-pap"><a href="https://pap.wikipedia.org/wiki/Bejing" title="Bejing – 帕皮阿门托语" lang="pap" hreflang="pap" class="interlanguage-link-target">Papiamentu</a></li><li class="interlanguage-link interwiki-pcd"><a href="https://pcd.wikipedia.org/wiki/P%C3%A9kin" title="Pékin – Picard" lang="pcd" hreflang="pcd" class="interlanguage-link-target">Picard</a></li><li class="interlanguage-link interwiki-pdc"><a href="https://pdc.wikipedia.org/wiki/Beijing" title="Beijing – Pennsylvania German" lang="pdc" hreflang="pdc" class="interlanguage-link-target">Deitsch</a></li><li class="interlanguage-link interwiki-pih"><a href="https://pih.wikipedia.org/wiki/Beijing" title="Beijing – Norfuk / Pitkern" lang="pih" hreflang="pih" class="interlanguage-link-target">Norfuk / Pitkern</a></li><li class="interlanguage-link interwiki-pl"><a href="https://pl.wikipedia.org/wiki/Pekin" title="Pekin – 波兰语" lang="pl" hreflang="pl" class="interlanguage-link-target">Polski</a></li><li class="interlanguage-link interwiki-pms"><a href="https://pms.wikipedia.org/wiki/Pechin" title="Pechin – Piedmontese" lang="pms" hreflang="pms" class="interlanguage-link-target">Piemontèis</a></li><li class="interlanguage-link interwiki-pnb"><a href="https://pnb.wikipedia.org/wiki/%D8%A8%DB%8C%D8%AC%D9%86%DA%AF" title="بیجنگ – Western Punjabi" lang="pnb" hreflang="pnb" class="interlanguage-link-target">پنجابی</a></li><li class="interlanguage-link interwiki-ps"><a href="https://ps.wikipedia.org/wiki/%D8%A8%DB%8C%D8%AC%D9%86%DA%AB" title="بیجنګ – 普什图语" lang="ps" hreflang="ps" class="interlanguage-link-target">پښتو</a></li><li class="interlanguage-link interwiki-pt"><a href="https://pt.wikipedia.org/wiki/Pequim" title="Pequim – 葡萄牙语" lang="pt" hreflang="pt" class="interlanguage-link-target">Português</a></li><li class="interlanguage-link interwiki-qu"><a href="https://qu.wikipedia.org/wiki/Pikkin" title="Pikkin – 克丘亚语" lang="qu" hreflang="qu" class="interlanguage-link-target">Runa Simi</a></li><li class="interlanguage-link interwiki-rmy"><a href="https://rmy.wikipedia.org/wiki/Pekenk" title="Pekenk – Vlax Romani" lang="rmy" hreflang="rmy" class="interlanguage-link-target">Romani čhib</a></li><li class="interlanguage-link interwiki-ro"><a href="https://ro.wikipedia.org/wiki/Beijing" title="Beijing – 罗马尼亚语" lang="ro" hreflang="ro" class="interlanguage-link-target">Română</a></li><li class="interlanguage-link interwiki-roa-tara"><a href="https://roa-tara.wikipedia.org/wiki/Pechine" title="Pechine – Tarantino" lang="nap-x-tara" hreflang="nap-x-tara" class="interlanguage-link-target">Tarandíne</a></li><li class="interlanguage-link interwiki-ru"><a href="https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 俄语" lang="ru" hreflang="ru" class="interlanguage-link-target">Русский</a></li><li class="interlanguage-link interwiki-rue"><a href="https://rue.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D1%96%D0%BD%D2%91" title="Пекінґ – Rusyn" lang="rue" hreflang="rue" class="interlanguage-link-target">Русиньскый</a></li><li class="interlanguage-link interwiki-sa"><a href="https://sa.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%99%E0%A5%8D%E0%A4%97%E0%A5%8D" title="बीजिङ्ग् – 梵语" lang="sa" hreflang="sa" class="interlanguage-link-target">संस्कृतम्</a></li><li class="interlanguage-link interwiki-sah"><a href="https://sah.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 萨哈语" lang="sah" hreflang="sah" class="interlanguage-link-target">Саха тыла</a></li><li class="interlanguage-link interwiki-sat"><a href="https://sat.wikipedia.org/wiki/%E1%B1%B5%E1%B1%AE%E1%B1%A1%E1%B1%A4%E1%B1%9D" title="ᱵᱮᱡᱤᱝ – 桑塔利语" lang="sat" hreflang="sat" class="interlanguage-link-target">ᱥᱟᱱᱛᱟᱲᱤ</a></li><li class="interlanguage-link interwiki-sc"><a href="https://sc.wikipedia.org/wiki/Beijing" title="Beijing – 萨丁语" lang="sc" hreflang="sc" class="interlanguage-link-target">Sardu</a></li><li class="interlanguage-link interwiki-scn"><a href="https://scn.wikipedia.org/wiki/Pechinu" title="Pechinu – 西西里语" lang="scn" hreflang="scn" class="interlanguage-link-target">Sicilianu</a></li><li class="interlanguage-link interwiki-sco"><a href="https://sco.wikipedia.org/wiki/Beijing" title="Beijing – 苏格兰语" lang="sco" hreflang="sco" class="interlanguage-link-target">Scots</a></li><li class="interlanguage-link interwiki-se"><a href="https://se.wikipedia.org/wiki/Peking" title="Peking – 北方萨米语" lang="se" hreflang="se" class="interlanguage-link-target">Davvisámegiella</a></li><li class="interlanguage-link interwiki-sh badge-Q17437796 badge-featuredarticle" title="典范条目"><a href="https://sh.wikipedia.org/wiki/Peking" title="Peking – 塞尔维亚-克罗地亚语" lang="sh" hreflang="sh" class="interlanguage-link-target">Srpskohrvatski / српскохрватски</a></li><li class="interlanguage-link interwiki-si"><a href="https://si.wikipedia.org/wiki/%E0%B6%B6%E0%B7%99%E0%B6%BA%E0%B7%92%E0%B6%A2%E0%B7%92%E0%B6%82" title="බෙයිජිං – 僧伽罗语" lang="si" hreflang="si" class="interlanguage-link-target">සිංහල</a></li><li class="interlanguage-link interwiki-simple"><a href="https://simple.wikipedia.org/wiki/Beijing" title="Beijing – Simple English" lang="en-simple" hreflang="en-simple" class="interlanguage-link-target">Simple English</a></li><li class="interlanguage-link interwiki-sk"><a href="https://sk.wikipedia.org/wiki/Peking" title="Peking – 斯洛伐克语" lang="sk" hreflang="sk" class="interlanguage-link-target">Slovenčina</a></li><li class="interlanguage-link interwiki-sl"><a href="https://sl.wikipedia.org/wiki/Peking" title="Peking – 斯洛文尼亚语" lang="sl" hreflang="sl" class="interlanguage-link-target">Slovenščina</a></li><li class="interlanguage-link interwiki-sn"><a href="https://sn.wikipedia.org/wiki/Beijing" title="Beijing – 绍纳语" lang="sn" hreflang="sn" class="interlanguage-link-target">ChiShona</a></li><li class="interlanguage-link interwiki-so"><a href="https://so.wikipedia.org/wiki/Beijing" title="Beijing – 索马里语" lang="so" hreflang="so" class="interlanguage-link-target">Soomaaliga</a></li><li class="interlanguage-link interwiki-sq"><a href="https://sq.wikipedia.org/wiki/Pekini" title="Pekini – 阿尔巴尼亚语" lang="sq" hreflang="sq" class="interlanguage-link-target">Shqip</a></li><li class="interlanguage-link interwiki-sr badge-Q17437796 badge-featuredarticle" title="典范条目"><a href="https://sr.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD%D0%B3" title="Пекинг – 塞尔维亚语" lang="sr" hreflang="sr" class="interlanguage-link-target">Српски / srpski</a></li><li class="interlanguage-link interwiki-srn"><a href="https://srn.wikipedia.org/wiki/Beijing" title="Beijing – 苏里南汤加语" lang="srn" hreflang="srn" class="interlanguage-link-target">Sranantongo</a></li><li class="interlanguage-link interwiki-stq"><a href="https://stq.wikipedia.org/wiki/Peking" title="Peking – Saterland Frisian" lang="stq" hreflang="stq" class="interlanguage-link-target">Seeltersk</a></li><li class="interlanguage-link interwiki-su"><a href="https://su.wikipedia.org/wiki/B%C3%A9ijing" title="Béijing – 巽他语" lang="su" hreflang="su" class="interlanguage-link-target">Sunda</a></li><li class="interlanguage-link interwiki-sv"><a href="https://sv.wikipedia.org/wiki/Peking" title="Peking – 瑞典语" lang="sv" hreflang="sv" class="interlanguage-link-target">Svenska</a></li><li class="interlanguage-link interwiki-sw"><a href="https://sw.wikipedia.org/wiki/Beijing" title="Beijing – 斯瓦希里语" lang="sw" hreflang="sw" class="interlanguage-link-target">Kiswahili</a></li><li class="interlanguage-link interwiki-szl"><a href="https://szl.wikipedia.org/wiki/Bejd%C5%BCing" title="Bejdżing – Silesian" lang="szl" hreflang="szl" class="interlanguage-link-target">Ślůnski</a></li><li class="interlanguage-link interwiki-ta"><a href="https://ta.wikipedia.org/wiki/%E0%AE%AA%E0%AF%86%E0%AE%AF%E0%AF%8D%E0%AE%9C%E0%AE%BF%E0%AE%99%E0%AF%8D" title="பெய்ஜிங் – 泰米尔语" lang="ta" hreflang="ta" class="interlanguage-link-target">தமிழ்</a></li><li class="interlanguage-link interwiki-te"><a href="https://te.wikipedia.org/wiki/%E0%B0%AC%E0%B1%80%E0%B0%9C%E0%B0%BF%E0%B0%82%E0%B0%97%E0%B1%8D" title="బీజింగ్ – 泰卢固语" lang="te" hreflang="te" class="interlanguage-link-target">తెలుగు</a></li><li class="interlanguage-link interwiki-tg"><a href="https://tg.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 塔吉克语" lang="tg" hreflang="tg" class="interlanguage-link-target">Тоҷикӣ</a></li><li class="interlanguage-link interwiki-th"><a href="https://th.wikipedia.org/wiki/%E0%B8%9B%E0%B8%B1%E0%B8%81%E0%B8%81%E0%B8%B4%E0%B9%88%E0%B8%87" title="ปักกิ่ง – 泰语" lang="th" hreflang="th" class="interlanguage-link-target">ไทย</a></li><li class="interlanguage-link interwiki-tk"><a href="https://tk.wikipedia.org/wiki/Pekin" title="Pekin – 土库曼语" lang="tk" hreflang="tk" class="interlanguage-link-target">Türkmençe</a></li><li class="interlanguage-link interwiki-tl"><a href="https://tl.wikipedia.org/wiki/Beijing" title="Beijing – 他加禄语" lang="tl" hreflang="tl" class="interlanguage-link-target">Tagalog</a></li><li class="interlanguage-link interwiki-tn"><a href="https://tn.wikipedia.org/wiki/Beijing" title="Beijing – 茨瓦纳语" lang="tn" hreflang="tn" class="interlanguage-link-target">Setswana</a></li><li class="interlanguage-link interwiki-to"><a href="https://to.wikipedia.org/wiki/Beijing" title="Beijing – 汤加语" lang="to" hreflang="to" class="interlanguage-link-target">Lea faka-Tonga</a></li><li class="interlanguage-link interwiki-tpi"><a href="https://tpi.wikipedia.org/wiki/Beijing" title="Beijing – 托克皮辛语" lang="tpi" hreflang="tpi" class="interlanguage-link-target">Tok Pisin</a></li><li class="interlanguage-link interwiki-tr"><a href="https://tr.wikipedia.org/wiki/Pekin" title="Pekin – 土耳其语" lang="tr" hreflang="tr" class="interlanguage-link-target">Türkçe</a></li><li class="interlanguage-link interwiki-ts"><a href="https://ts.wikipedia.org/wiki/Beyijingi" title="Beyijingi – 聪加语" lang="ts" hreflang="ts" class="interlanguage-link-target">Xitsonga</a></li><li class="interlanguage-link interwiki-tt"><a href="https://tt.wikipedia.org/wiki/%D0%A5%D0%B0%D0%BD%D0%B1%D0%B0%D0%BB%D1%8B%D0%BA" title="Ханбалык – 鞑靼语" lang="tt" hreflang="tt" class="interlanguage-link-target">Татарча/tatarça</a></li><li class="interlanguage-link interwiki-tum"><a href="https://tum.wikipedia.org/wiki/Beijing" title="Beijing – 通布卡语" lang="tum" hreflang="tum" class="interlanguage-link-target">ChiTumbuka</a></li><li class="interlanguage-link interwiki-tw"><a href="https://tw.wikipedia.org/wiki/Beijing" title="Beijing – 契维语" lang="tw" hreflang="tw" class="interlanguage-link-target">Twi</a></li><li class="interlanguage-link interwiki-udm"><a href="https://udm.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" title="Пекин – 乌德穆尔特语" lang="udm" hreflang="udm" class="interlanguage-link-target">Удмурт</a></li><li class="interlanguage-link interwiki-ug"><a href="https://ug.wikipedia.org/wiki/%D8%A8%DB%90%D9%8A%D8%AC%D9%89%DA%AD_%D8%B4%DB%95%DA%BE%D9%89%D8%B1%D9%89" title="بېيجىڭ شەھىرى – 维吾尔语" lang="ug" hreflang="ug" class="interlanguage-link-target">ئۇيغۇرچە / Uyghurche</a></li><li class="interlanguage-link interwiki-uk"><a href="https://uk.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D1%96%D0%BD" title="Пекін – 乌克兰语" lang="uk" hreflang="uk" class="interlanguage-link-target">Українська</a></li><li class="interlanguage-link interwiki-ur"><a href="https://ur.wikipedia.org/wiki/%D8%A8%DB%8C%D8%AC%D9%86%DA%AF" title="بیجنگ – 乌尔都语" lang="ur" hreflang="ur" class="interlanguage-link-target">اردو</a></li><li class="interlanguage-link interwiki-uz"><a href="https://uz.wikipedia.org/wiki/Pekin" title="Pekin – 乌兹别克语" lang="uz" hreflang="uz" class="interlanguage-link-target">Oʻzbekcha/ўзбекча</a></li><li class="interlanguage-link interwiki-vec"><a href="https://vec.wikipedia.org/wiki/Pechin" title="Pechin – Venetian" lang="vec" hreflang="vec" class="interlanguage-link-target">Vèneto</a></li><li class="interlanguage-link interwiki-vep"><a href="https://vep.wikipedia.org/wiki/Pekin" title="Pekin – 维普森语" lang="vep" hreflang="vep" class="interlanguage-link-target">Vepsän kel’</a></li><li class="interlanguage-link interwiki-vi"><a href="https://vi.wikipedia.org/wiki/B%E1%BA%AFc_Kinh" title="Bắc Kinh – 越南语" lang="vi" hreflang="vi" class="interlanguage-link-target">Tiếng Việt</a></li><li class="interlanguage-link interwiki-vo"><a href="https://vo.wikipedia.org/wiki/Beycing" title="Beycing – 沃拉普克语" lang="vo" hreflang="vo" class="interlanguage-link-target">Volapük</a></li><li class="interlanguage-link interwiki-wa"><a href="https://wa.wikipedia.org/wiki/Pekin" title="Pekin – 瓦隆语" lang="wa" hreflang="wa" class="interlanguage-link-target">Walon</a></li><li class="interlanguage-link interwiki-war"><a href="https://war.wikipedia.org/wiki/Beijing" title="Beijing – 瓦瑞语" lang="war" hreflang="war" class="interlanguage-link-target">Winaray</a></li><li class="interlanguage-link interwiki-wo"><a href="https://wo.wikipedia.org/wiki/Beijing" title="Beijing – 沃洛夫语" lang="wo" hreflang="wo" class="interlanguage-link-target">Wolof</a></li><li class="interlanguage-link interwiki-wuu"><a href="https://wuu.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC" title="北京 – 吴语" lang="wuu" hreflang="wuu" class="interlanguage-link-target">吴语</a></li><li class="interlanguage-link interwiki-xal"><a href="https://xal.wikipedia.org/wiki/%D0%91%D3%99%D3%99%D2%97%D2%A3_%D0%B1%D0%B0%D0%BB%D2%BB%D1%81%D0%BD" title="Бәәҗң балһсн – 卡尔梅克语" lang="xal" hreflang="xal" class="interlanguage-link-target">Хальмг</a></li><li class="interlanguage-link interwiki-xmf"><a href="https://xmf.wikipedia.org/wiki/%E1%83%9E%E1%83%94%E1%83%99%E1%83%98%E1%83%9C%E1%83%98" title="პეკინი – Mingrelian" lang="xmf" hreflang="xmf" class="interlanguage-link-target">მარგალური</a></li><li class="interlanguage-link interwiki-yi"><a href="https://yi.wikipedia.org/wiki/%D7%91%D7%99%D7%99%D7%96%D7%A9%D7%99%D7%A0%D7%92" title="בייזשינג – 意第绪语" lang="yi" hreflang="yi" class="interlanguage-link-target">ייִדיש</a></li><li class="interlanguage-link interwiki-yo"><a href="https://yo.wikipedia.org/wiki/Beijing" title="Beijing – 约鲁巴语" lang="yo" hreflang="yo" class="interlanguage-link-target">Yorùbá</a></li><li class="interlanguage-link interwiki-za"><a href="https://za.wikipedia.org/wiki/Baekging" title="Baekging – 壮语" lang="za" hreflang="za" class="interlanguage-link-target">Vahcuengh</a></li><li class="interlanguage-link interwiki-zea"><a href="https://zea.wikipedia.org/wiki/Peking" title="Peking – Zeelandic" lang="zea" hreflang="zea" class="interlanguage-link-target">Zeêuws</a></li><li class="interlanguage-link interwiki-zh-classical"><a href="https://zh-classical.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" title="北京市 – Classical Chinese" lang="lzh" hreflang="lzh" class="interlanguage-link-target">文言</a></li><li class="interlanguage-link interwiki-zh-min-nan"><a href="https://zh-min-nan.wikipedia.org/wiki/Pak-kia%E2%81%BF-chh%C4%AB" title="Pak-kiaⁿ-chhī – Chinese (Min Nan)" lang="nan" hreflang="nan" class="interlanguage-link-target">Bân-lâm-gú</a></li><li class="interlanguage-link interwiki-zh-yue"><a href="https://zh-yue.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC" title="北京 – Cantonese" lang="yue" hreflang="yue" class="interlanguage-link-target">粵語</a></li><li class="interlanguage-link interwiki-zu"><a href="https://zu.wikipedia.org/wiki/Beijing" title="Beijing – 祖鲁语" lang="zu" hreflang="zu" class="interlanguage-link-target">IsiZulu</a></li></ul>
<div class="after-portlet after-portlet-lang"><span class="wb-langlinks-edit wb-langlinks-link"><a href="https://www.wikidata.org/wiki/Special:EntityPage/Q956#sitelinks-wikipedia" title="编辑跨语言链接" class="wbc-editpage">编辑链接</a></span></div>
</div>
</nav>
</div>
</div>
<footer id="footer" class="mw-footer" role="contentinfo" >
<ul id="footer-info" >
<li id="footer-info-lastmod"> 本页面最后修订于2021年1月6日 (星期三) 07:09。</li>
<li id="footer-info-copyright">本站的全部文字在<a rel="license" href="//zh.wikipedia.org/wiki/Wikipedia:CC-BY-SA-3.0%E5%8D%8F%E8%AE%AE%E6%96%87%E6%9C%AC" title="Wikipedia:CC-BY-SA-3.0协议文本">知识共享 署名-相同方式共享 3.0协议</a><a rel="license" href="//creativecommons.org/licenses/by-sa/3.0/deed.zh" style="display:none;"></a>之条款下提供,附加条款亦可能应用。(请参阅<a href="//foundation.wikimedia.org/wiki/Terms_of_Use">使用条款</a>)<br />
Wikipedia®和维基百科标志是<a href="//wikimediafoundation.org">维基媒体基金会</a>的注册商标;维基™是维基媒体基金会的商标。<br />
维基媒体基金会是按美国国內稅收法501(c)(3)登记的<a href="//donate.wikimedia.org/wiki/Tax_deductibility">非营利慈善机构</a>。<br /></li>
</ul>
<ul id="footer-places" >
<li id="footer-places-privacy"><a href="https://foundation.wikimedia.org/wiki/Privacy_policy" class="extiw" title="wmf:Privacy policy">隐私政策</a></li>
<li id="footer-places-about"><a href="/wiki/Wikipedia:%E5%85%B3%E4%BA%8E" title="Wikipedia:关于">关于维基百科</a></li>
<li id="footer-places-disclaimer"><a href="/wiki/Wikipedia:%E5%85%8D%E8%B4%A3%E5%A3%B0%E6%98%8E" title="Wikipedia:免责声明">免责声明</a></li>
<li id="footer-places-mobileview"><a href="//zh.m.wikipedia.org/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&mobileaction=toggle_view_mobile" class="noprint stopMobileRedirectToggle">手机版视图</a></li>
<li id="footer-places-developers"><a href="https://www.mediawiki.org/wiki/Special:MyLanguage/How_to_contribute">开发者</a></li>
<li id="footer-places-statslink"><a href="https://stats.wikimedia.org/#/zh.wikipedia.org">统计</a></li>
<li id="footer-places-cookiestatement"><a href="https://foundation.wikimedia.org/wiki/Cookie_statement">Cookie声明</a></li>
</ul>
<ul id="footer-icons" class="noprint">
<li id="footer-copyrightico"><a href="https://wikimediafoundation.org/"><img src="/static/images/footer/wikimedia-button.png" srcset="/static/images/footer/wikimedia-button-1.5x.png 1.5x, /static/images/footer/wikimedia-button-2x.png 2x" width="88" height="31" alt="Wikimedia Foundation" loading="lazy" /></a></li>
<li id="footer-poweredbyico"><a href="https://www.mediawiki.org/"><img src="/static/images/footer/poweredby_mediawiki_88x31.png" alt="Powered by MediaWiki" srcset="/static/images/footer/poweredby_mediawiki_132x47.png 1.5x, /static/images/footer/poweredby_mediawiki_176x62.png 2x" width="88" height="31" loading="lazy"/></a></li>
</ul>
<div style="clear: both;"></div>
</footer>
<script>(RLQ=window.RLQ||[]).push(function(){mw.config.set({"wgPageParseReport":{"limitreport":{"cputime":"3.848","walltime":"4.782","ppvisitednodes":{"value":29346,"limit":1000000},"postexpandincludesize":{"value":2036601,"limit":2097152},"templateargumentsize":{"value":274762,"limit":2097152},"expansiondepth":{"value":22,"limit":40},"expensivefunctioncount":{"value":25,"limit":500},"unstrip-depth":{"value":0,"limit":20},"unstrip-size":{"value":202785,"limit":5000000},"entityaccesscount":{"value":1,"limit":400},"timingprofile":["100.00% 3147.668 1 -total"," 41.47% 1305.187 44 Template:Navbox"," 26.25% 826.113 1 Template:Reflist"," 22.79% 717.504 1 Template:Template_group"," 15.20% 478.549 97 Template:Cite_web"," 10.64% 334.758 53 Template:Flag"," 7.93% 249.616 3 Template:Navbox_with_columns"," 7.24% 227.781 66 Template:Flagicon"," 5.92% 186.452 5 Template:Infobox"," 5.89% 185.443 1 Template:夏季奧運會主辦城市"]},"scribunto":{"limitreport-timeusage":{"value":"1.006","limit":"10.000"},"limitreport-memusage":{"value":10095269,"limit":52428800},"limitreport-profile":[["Scribunto_LuaSandboxCallback::getExpandedArgument","460","32.9"],["Scribunto_LuaSandboxCallback::find","220","15.7"],["?","100","7.1"],["\u003Cmw.lua:683\u003E","80","5.7"],["Scribunto_LuaSandboxCallback::getEntity","80","5.7"],["recursiveClone \u003CmwInit.lua:41\u003E","60","4.3"],["tonumber","40","2.9"],["Scribunto_LuaSandboxCallback::newTitle","40","2.9"],["Scribunto_LuaSandboxCallback::getAllExpandedArguments","40","2.9"],["Scribunto_LuaSandboxCallback::plain","40","2.9"],["[others]","240","17.1"]]},"cachereport":{"origin":"mw1401","timestamp":"20210109032017","ttl":86400,"transientcontent":true}}});});</script>
<script type="application/ld+json">{"@context":"https:\/\/schema.org","@type":"Article","name":"\u5317\u4eac\u5e02","url":"https:\/\/zh.wikipedia.org\/wiki\/%E5%8C%97%E4%BA%AC%E5%B8%82","sameAs":"http:\/\/www.wikidata.org\/entity\/Q956","mainEntity":"http:\/\/www.wikidata.org\/entity\/Q956","author":{"@type":"Organization","name":"\u7ef4\u57fa\u5a92\u4f53\u9879\u76ee\u8d21\u732e\u8005"},"publisher":{"@type":"Organization","name":"Wikimedia Foundation, Inc.","logo":{"@type":"ImageObject","url":"https:\/\/www.wikimedia.org\/static\/images\/wmf-hor-googpub.png"}},"datePublished":"2003-03-22T14:53:23Z","dateModified":"2021-01-06T07:09:44Z","image":"https:\/\/upload.wikimedia.org\/wikipedia\/commons\/f\/f2\/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg","headline":"\u4e2d\u534e\u4eba\u6c11\u5171\u548c\u56fd\u7684\u9996\u90fd\u548c\u4e00\u4e2a\u76f4\u8f96\u5e02"}</script>
<script>(RLQ=window.RLQ||[]).push(function(){mw.config.set({"wgBackendResponseTime":309,"wgHostname":"mw1387"});});</script>
</body></html>
但如你所见,数据可读性并不怎么好,请求返回的内容没有很好的展示 HTML 的树形结构。为改善可读性,Python 提供了另一个很棒的 BeautifulSoup 库。
BeautifulSoup 是用来解析 HTML 树形结构并提取 HTML 内容的一个库。_更多爬虫内容见教程_
用的时候把得到的答复文本传给 BeautifulSoup(),它会创建自己的“soup”对象。调用 BeautifulSoup 对象的 prettify() 解析 HTML 内容树
from bs4 import BeautifulSoup
web_text = BeautifulSoup(web_resp.text, 'html.parser')
print(web_text.prettify())
<!DOCTYPE html>
<html class="client-nojs" dir="ltr" lang="zh">
<head>
<meta charset="utf-8"/>
<title>
北京市 - 维基百科,自由的百科全书
</title>
<script>
document.documentElement.className="client-js";RLCONF={"wgBreakFrames":!1,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"zh","wgMonthNames":["","1月","2月","3月","4月","5月","6月","7月","8月","9月","10月","11月","12月"],"wgRequestId":"X-ld-wpAAL8AAvn2aXcAAACI","wgCSPNonce":!1,"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":!1,"wgNamespaceNumber":0,"wgPageName":"北京市","wgTitle":"北京市","wgCurRevisionId":63604485,"wgRevisionId":63604485,"wgArticleId":463,"wgIsArticle":!0,"wgIsRedirect":!1,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["有参考文献错误的页面","CS1英语来源 (en)","CS1含有中文文本 (zh)","引文格式1错误:日期","含有访问日期但无网址的引用的页面","CS1俄语来源 (ru)","CS1美国英语来源 (en-us)","顶注重定向需要审阅的条目","维基数据存在坐标数据的页面","使用多个图像且自动缩放的页面",
"含有非中文內容的條目","嵌入hAudio微格式的條目","包含AAT标识符的维基百科条目","包含BNF标识符的维基百科条目","包含GND标识符的维基百科条目","包含ISNI标识符的维基百科条目","包含LCCN标识符的维基百科条目","包含NARA标识符的维基百科条目","包含NDL标识符的维基百科条目","包含NKC标识符的维基百科条目","包含NNL标识符的维基百科条目","包含VIAF标识符的维基百科条目","使用人口模板的頁面","中華人民共和國省級行政區","亞洲首都","国家园林城市","中華人民共和國直轄市","北京市","中国特大城市","国家历史文化名城","京津冀城市群","夏季奥林匹克运动会主办城市","亚洲运动会主办城市","中国历代国都","国家中心城市","国家经济中心城市"],"wgPageContentLanguage":"zh","wgPageContentModel":"wikitext","wgRelevantPageName":"北京市","wgRelevantArticleId":463,"wgUserVariant":"zh",
"wgIsProbablyEditable":!0,"wgRelevantPageIsProbablyEditable":!0,"wgRestrictionEdit":[],"wgRestrictionMove":[],"wgMediaViewerOnClick":!0,"wgMediaViewerEnabledByDefault":!0,"wgPopupsReferencePreviews":!1,"wgPopupsConflictsWithNavPopupGadget":!1,"wgPopupsConflictsWithRefTooltipsGadget":!0,"wgVisualEditor":{"pageLanguageCode":"zh","pageLanguageDir":"ltr","pageVariantFallbacks":["zh-hans","zh-hant","zh-cn","zh-tw","zh-hk","zh-sg","zh-mo","zh-my"]},"wgMFDisplayWikibaseDescriptions":{"search":!0,"nearby":!0,"watchlist":!0,"tagline":!0},"wgWMESchemaEditAttemptStepOversample":!1,"wgULSCurrentAutonym":"中文","wgNoticeProject":"wikipedia","wgCoordinates":{"lat":39.90555555555555,"lon":116.3913888888889},"wgCentralAuthMobileDomain":!1,"wgEditSubmitButtonLabelPublish":!0,"wgULSPosition":"interlanguage","wgWikibaseItemId":"Q956"};RLSTATE={"ext.gadget.large-font":"ready","ext.globalCssJs.user.styles":"ready","site.styles":"ready","noscript":"ready","user.styles":
"ready","ext.globalCssJs.user":"ready","user":"ready","user.options":"loading","ext.cite.styles":"ready","skins.vector.styles.legacy":"ready","jquery.tablesorter.styles":"ready","ext.visualEditor.desktopArticleTarget.noscript":"ready","ext.uls.interlanguage":"ready","ext.wikimediaBadges":"ready","wikibase.client.init":"ready"};RLPAGEMODULES=["ext.cite.ux-enhancements","site","mediawiki.page.ready","jquery.tablesorter","mediawiki.toc","skins.vector.legacy.js","ext.gadget.edit0","ext.gadget.Edittools-refToolbar","ext.gadget.WikiMiniAtlas","ext.gadget.ReferenceTooltips","ext.gadget.UnihanTooltips","ext.gadget.variant-link-fix","ext.gadget.FixedTopBottomLink","ext.gadget.confirm-logout","ext.gadget.shortURL","ext.gadget.Difflink","ext.gadget.AdvancedSiteNotices","ext.gadget.hideConversionTab","ext.gadget.internalLinkHelper-altcolor","ext.gadget.noteTA","ext.gadget.noteTAvector","ext.gadget.NavFrame","ext.gadget.collapsibleTables","ext.gadget.notifyConversion",
"ext.centralauth.centralautologin","mmv.head","mmv.bootstrap.autostart","ext.popups","ext.visualEditor.desktopArticleTarget.init","ext.visualEditor.targetLoader","ext.eventLogging","ext.wikimediaEvents","ext.navigationTiming","ext.uls.compactlinks","ext.uls.interface","ext.cx.eventlogging.campaigns","ext.centralNotice.geoIP","ext.centralNotice.startUp"];
</script>
<script>
(RLQ=window.RLQ||[]).push(function(){mw.loader.implement("user.options@1hzgi",function($,jQuery,require,module){/*@nomin*/mw.user.tokens.set({"patrolToken":"+\\","watchToken":"+\\","csrfToken":"+\\"});
});});
</script>
<link href="/w/load.php?lang=zh&modules=ext.cite.styles%7Cext.uls.interlanguage%7Cext.visualEditor.desktopArticleTarget.noscript%7Cext.wikimediaBadges%7Cjquery.tablesorter.styles%7Cskins.vector.styles.legacy%7Cwikibase.client.init&only=styles&skin=vector" rel="stylesheet"/>
<script async="" src="/w/load.php?lang=zh&modules=startup&only=scripts&raw=1&skin=vector">
</script>
<meta content="" name="ResourceLoaderDynamicStyles"/>
<link href="/w/load.php?lang=zh&modules=ext.gadget.large-font&only=styles&skin=vector" rel="stylesheet"/>
<link href="/w/load.php?lang=zh&modules=site.styles&only=styles&skin=vector" rel="stylesheet"/>
<meta content="MediaWiki 1.36.0-wmf.25" name="generator"/>
<meta content="origin" name="referrer"/>
<meta content="origin-when-crossorigin" name="referrer"/>
<meta content="origin-when-cross-origin" name="referrer"/>
<meta content="https://upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/1200px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg" property="og:image"/>
<link href="//upload.wikimedia.org" rel="preconnect"/>
<link href="//zh.m.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" media="only screen and (max-width: 720px)" rel="alternate"/>
<link href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit" rel="alternate" title="编辑本页" type="application/x-wiki"/>
<link href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit" rel="edit" title="编辑本页"/>
<link href="/static/apple-touch/wikipedia.png" rel="apple-touch-icon"/>
<link href="/static/favicon/wikipedia.ico" rel="shortcut icon"/>
<link href="/w/opensearch_desc.php" rel="search" title="Wikipedia (zh)" type="application/opensearchdescription+xml"/>
<link href="//zh.wikipedia.org/w/api.php?action=rsd" rel="EditURI" type="application/rsd+xml"/>
<link href="/zh/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh" rel="alternate"/>
<link href="/zh-hans/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans" rel="alternate"/>
<link href="/zh-hant/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant" rel="alternate"/>
<link href="/zh-cn/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans-CN" rel="alternate"/>
<link href="/zh-hk/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant-HK" rel="alternate"/>
<link href="/zh-mo/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant-MO" rel="alternate"/>
<link href="/zh-my/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans-MY" rel="alternate"/>
<link href="/zh-sg/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans-SG" rel="alternate"/>
<link href="/zh-tw/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant-TW" rel="alternate"/>
<link href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="x-default" rel="alternate"/>
<link href="//creativecommons.org/licenses/by-sa/3.0/" rel="license"/>
<link href="https://zh.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" rel="canonical"/>
<link href="//login.wikimedia.org" rel="dns-prefetch"/>
<link href="//meta.wikimedia.org" rel="dns-prefetch"/>
</head>
<body class="mediawiki ltr sitedir-ltr mw-hide-empty-elt ns-0 ns-subject mw-editable page-北京市 rootpage-北京市 skin-vector action-view skin-vector-legacy">
<div class="noprint" id="mw-page-base">
</div>
<div class="noprint" id="mw-head-base">
</div>
<div class="mw-body" id="content" role="main">
<a id="top">
</a>
<div class="mw-body-content" id="siteNotice">
<!-- CentralNotice -->
</div>
<div class="mw-indicators mw-body-content">
<div class="mw-indicator" id="mw-indicator-noteTA-d455684c">
<img alt="本页使用了标题或全文手工转换" data-file-height="20" data-file-width="32" decoding="async" height="22" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/Zh_conversion_icon_m.svg/35px-Zh_conversion_icon_m.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/Zh_conversion_icon_m.svg/53px-Zh_conversion_icon_m.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/cd/Zh_conversion_icon_m.svg/70px-Zh_conversion_icon_m.svg.png 2x" title="本页使用了标题或全文手工转换" width="35"/>
</div>
</div>
<h1 class="firstHeading" id="firstHeading" lang="zh">
北京市
</h1>
<div class="mw-body-content" id="bodyContent">
<div class="noprint" id="siteSub">
维基百科,自由的百科全书
</div>
<div id="contentSub">
</div>
<div id="contentSub2">
</div>
<div id="jump-to-nav">
</div>
<a class="mw-jump-link" href="#mw-head">
跳到导航
</a>
<a class="mw-jump-link" href="#searchInput">
跳到搜索
</a>
<div class="mw-content-ltr" dir="ltr" id="mw-content-text" lang="zh">
<div class="mw-parser-output">
<div class="noteTA" id="noteTA-d455684c">
<div class="noteTA-group">
<div data-noteta-group="地名" data-noteta-group-source="module">
</div>
</div>
<div class="noteTA-local">
<div data-noteta-code="zh-hans:丰台; zh-hant:豐臺;">
</div>
<div data-noteta-code="zh-hant:衚衕; zh-hans:胡同;">
</div>
<div data-noteta-code="zh-hans:哈瓦那;zh-tw:哈瓦那;zh-hk:夏灣拿;zh-cn:哈瓦那;">
</div>
</div>
</div>
<div class="hatnote navigation-not-searchable" role="note">
<a href="/wiki/Wikipedia:%E6%B6%88%E6%AD%A7%E4%B9%89" title="Wikipedia:消歧义">
<img alt="Disambig gray.svg" data-file-height="168" data-file-width="220" decoding="async" height="19" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5f/Disambig_gray.svg/25px-Disambig_gray.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5f/Disambig_gray.svg/38px-Disambig_gray.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5f/Disambig_gray.svg/50px-Disambig_gray.svg.png 2x" width="25"/>
</a>
「
<b>
北平
</b>
」重定向至此。关于其他用法,请见「
<b>
<a href="/wiki/%E5%8C%97%E5%B9%B3_(%E6%B6%88%E6%AD%A7%E7%BE%A9)" title="北平 (消歧義)">
北平 (消歧义)
</a>
</b>
」。
</div>
<p>
<span style="font-size: small;">
<span id="coordinates">
<a class="mw-redirect" href="/wiki/%E5%9C%B0%E7%90%86%E5%9D%90%E6%A0%87" title="地理坐标">
坐标
</a>
:
<span class="plainlinks nourlexpansion">
<a class="external text" href="//tools.wmflabs.org/geohack/geohack.php?language=zh&pagename=%E5%8C%97%E4%BA%AC%E5%B8%82&params=39_54_20_N_116_23_29_E_region:CN-11_type:adm1st&title=%E5%8C%97%E4%BA%AC%E5%B8%82">
<span class="geo-default">
<span class="geo-dms" title="此地的地图、航拍照片和其他数据">
<span class="latitude">
39°54′20″N
</span>
<span class="longitude">
116°23′29″E
</span>
</span>
</span>
<span class="geo-multi-punct">
/
</span>
<span class="geo-nondefault">
<span class="vcard">
<span class="geo-dec" title="此地的地图、航拍照片和其他数据">
39.90556°N 116.39139°E
</span>
<span style="display:none">
/
<span class="geo">
39.90556; 116.39139
</span>
</span>
<span style="display:none">
(
<span class="fn org">
北京市
</span>
)
</span>
</span>
</span>
</a>
</span>
</span>
</span>
</p>
<table class="infobox geography vcard" style="width:23em; font-size:85%;">
<tbody>
<tr>
<td class="mergedtoprow" colspan="2" style="line-height:1.25em; text-align:center;font-size:1.3em;">
<b>
北京市
</b>
</td>
</tr>
<tr>
<td colspan="2" style="background-color:#cddeff; font-weight:bold; text-align:center;">
<span class="nowrap">
<b>
<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">
直辖市
</a>
</b>
</span>
</td>
</tr>
<tr>
<td colspan="2" style="text-align:center;">
<style data-mw-deduplicate="TemplateStyles:r61200722/mw-parser-output/.tmulti">
.mw-parser-output .tmulti .thumbinner{display:flex;flex-direction:column}.mw-parser-output .tmulti .trow{display:flex;flex-direction:row;clear:left;flex-wrap:wrap;width:100%;box-sizing:border-box}.mw-parser-output .tmulti .tsingle{margin:1px;float:left}.mw-parser-output .tmulti .theader{clear:both;font-weight:bold;text-align:center;align-self:center;background-color:transparent;width:100%}.mw-parser-output .tmulti .thumbcaption{text-align:left;background-color:transparent}.mw-parser-output .tmulti .text-align-left{text-align:left}.mw-parser-output .tmulti .text-align-right{text-align:right}.mw-parser-output .tmulti .text-align-center{text-align:center}@media all and (max-width:720px){.mw-parser-output .tmulti .thumbinner{width:100%!important;box-sizing:border-box;max-width:none!important;align-items:center}.mw-parser-output .tmulti .trow{justify-content:center}.mw-parser-output .tmulti .tsingle{float:none!important;max-width:100%!important;box-sizing:border-box;text-align:center}.mw-parser-output .tmulti .thumbcaption{text-align:center}}
</style>
<div class="thumb tmulti tnone center">
<div class="thumbinner" style="width:272px;max-width:272px;border:none">
<div class="trow">
<div class="tsingle" style="width:270px;max-width:270px">
<div class="thumbimage" style="border:1;;height:120px;overflow:hidden">
<a class="image" href="/wiki/File:Beijing_skyline_from_northeast_4th_ring_road.jpg">
<img alt="" data-file-height="3190" data-file-width="7091" decoding="async" height="121" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/64/Beijing_skyline_from_northeast_4th_ring_road.jpg/268px-Beijing_skyline_from_northeast_4th_ring_road.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/64/Beijing_skyline_from_northeast_4th_ring_road.jpg/402px-Beijing_skyline_from_northeast_4th_ring_road.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/64/Beijing_skyline_from_northeast_4th_ring_road.jpg/536px-Beijing_skyline_from_northeast_4th_ring_road.jpg 2x" width="268"/>
</a>
</div>
</div>
</div>
<div class="trow">
<div class="tsingle" style="width:178px;max-width:178px">
<div class="thumbimage" style="border:1;;height:132px;overflow:hidden">
<a class="image" href="/wiki/File:Flickr_-_archer10_(Dennis)_-_China-6123.jpg">
<img alt="" data-file-height="2448" data-file-width="3264" decoding="async" height="132" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/176px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/264px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f2/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg/352px-Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg 2x" width="176"/>
</a>
</div>
</div>
<div class="tsingle" style="width:90px;max-width:90px">
<div class="thumbimage" style="border:1;;height:132px;overflow:hidden">
<a class="image" href="/wiki/File:The_Great_Wall_of_China_-_Badaling.jpg">
<img alt="" data-file-height="3072" data-file-width="2048" decoding="async" height="132" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/The_Great_Wall_of_China_-_Badaling.jpg/88px-The_Great_Wall_of_China_-_Badaling.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/The_Great_Wall_of_China_-_Badaling.jpg/132px-The_Great_Wall_of_China_-_Badaling.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/The_Great_Wall_of_China_-_Badaling.jpg/176px-The_Great_Wall_of_China_-_Badaling.jpg 2x" width="88"/>
</a>
</div>
</div>
</div>
<div class="trow">
<div class="tsingle" style="width:97px;max-width:97px">
<div class="thumbimage" style="border:1;;height:95px;overflow:hidden">
<a class="image" href="/wiki/File:TempleofHeaven-HallofPrayer_(square).jpg">
<img alt="" data-file-height="1303" data-file-width="1303" decoding="async" height="95" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/TempleofHeaven-HallofPrayer_%28square%29.jpg/95px-TempleofHeaven-HallofPrayer_%28square%29.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/TempleofHeaven-HallofPrayer_%28square%29.jpg/143px-TempleofHeaven-HallofPrayer_%28square%29.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/69/TempleofHeaven-HallofPrayer_%28square%29.jpg/190px-TempleofHeaven-HallofPrayer_%28square%29.jpg 2x" width="95"/>
</a>
</div>
</div>
<div class="tsingle" style="width:171px;max-width:171px">
<div class="thumbimage" style="border:1;;height:95px;overflow:hidden">
<a class="image" href="/wiki/File:Hall_of_Supreme_Harmony,_Forbidden_City,_from_southeast.jpg">
<img alt="" data-file-height="3402" data-file-width="6048" decoding="async" height="95" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg/169px-Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg/254px-Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg/338px-Hall_of_Supreme_Harmony%2C_Forbidden_City%2C_from_southeast.jpg 2x" width="169"/>
</a>
</div>
</div>
</div>
<div class="trow">
<div class="tsingle" style="width:136px;max-width:136px">
<div class="thumbimage" style="border:1;;height:86px;overflow:hidden">
<a class="image" href="/wiki/File:Beijing_National_Stadium_1.jpg">
<img alt="" data-file-height="662" data-file-width="1024" decoding="async" height="87" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e0/Beijing_National_Stadium_1.jpg/134px-Beijing_National_Stadium_1.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e0/Beijing_National_Stadium_1.jpg/201px-Beijing_National_Stadium_1.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e0/Beijing_National_Stadium_1.jpg/268px-Beijing_National_Stadium_1.jpg 2x" width="134"/>
</a>
</div>
</div>
<div class="tsingle" style="width:132px;max-width:132px">
<div class="thumbimage" style="border:1;;height:86px;overflow:hidden">
<a class="image" href="/wiki/File:%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg">
<img alt="" data-file-height="2835" data-file-width="4252" decoding="async" height="87" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/ee/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg/130px-%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/ee/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg/195px-%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/ee/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg/260px-%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C%E5%8D%97%E5%8C%BA.jpg 2x" width="130"/>
</a>
</div>
</div>
</div>
<div class="trow">
<div class="tsingle" style="width:270px;max-width:270px">
<div class="thumbimage" style="border:1;;height:123px;overflow:hidden">
<a class="image" href="/wiki/File:National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg">
<img alt="" data-file-height="747" data-file-width="1620" decoding="async" height="124" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a5/National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg/268px-National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a5/National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg/402px-National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a5/National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg/536px-National_Centre_for_the_Performing_Arts_and_Great_Hall_of_the_People.jpg 2x" width="268"/>
</a>
</div>
</div>
</div>
</div>
</div>
北京市风光(顺时针方向):
<br/>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">
北京CBD
</a>
天际线、
<a class="mw-redirect" href="/wiki/%E5%85%AB%E8%BE%BE%E5%B2%AD%E9%95%BF%E5%9F%8E" title="八达岭长城">
八達嶺長城
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E6%95%85%E5%AE%AE" title="北京故宮">
北京故宮
</a>
<a href="/wiki/%E5%A4%AA%E5%92%8C%E6%AE%BF" title="太和殿">
太和殿
</a>
、
<a href="/wiki/%E4%B8%89%E9%87%8C%E5%B1%AF%E5%A4%AA%E5%8F%A4%E9%87%8C" title="三里屯太古里">
三里屯太古里
</a>
、
<a class="mw-redirect" href="/wiki/%E4%BA%BA%E6%B0%91%E5%A4%A7%E6%9C%83%E5%A0%82" title="人民大會堂">
人民大會堂
</a>
(左)與
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%A4%A7%E5%89%A7%E9%99%A2" title="国家大剧院">
国家大剧院
</a>
(右)夜景、
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA_(%E5%8C%97%E4%BA%AC)" title="国家体育场 (北京)">
国家体育场
</a>
、
<a href="/wiki/%E5%A4%A9%E5%9D%9B" title="天坛">
天坛
</a>
祈年殿、
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%9F%8E%E6%A5%BC" title="天安门城楼">
天安门城楼
</a>
</td>
</tr>
<tr>
<td colspan="2" style="text-align:center;">
<a class="image" href="/wiki/File:Beijing_in_China_(%2Ball_claims_hatched).svg" title="图中高亮显示的是北京市">
<img alt="图中高亮显示的是北京市" data-file-height="940" data-file-width="1181" decoding="async" height="239" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/0e/Beijing_in_China_%28%2Ball_claims_hatched%29.svg/300px-Beijing_in_China_%28%2Ball_claims_hatched%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/0e/Beijing_in_China_%28%2Ball_claims_hatched%29.svg/450px-Beijing_in_China_%28%2Ball_claims_hatched%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/0e/Beijing_in_China_%28%2Ball_claims_hatched%29.svg/600px-Beijing_in_China_%28%2Ball_claims_hatched%29.svg.png 2x" width="300"/>
</a>
</td>
</tr>
<tr>
<td style="width:38%;">
<b>
简称
</b>
</td>
<td>
<b>
京
</b>
</td>
</tr>
<tr style="display:none">
<td style="width:38%;">
<b>
名称起源
</b>
</td>
<td>
</td>
</tr>
<tr>
<td style="width:38%;">
<b>
国家
</b>
</td>
<td>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
</td>
</tr>
<tr>
<td>
<b>
政府所在地
</b>
</td>
<td>
<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">
通州区
</a>
</td>
</tr>
<tr>
<td>
<b>
最大区县
</b>
</td>
<td>
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">
密云区
</a>
</td>
</tr>
<tr>
<td>
<b>
主要领导人
</b>
</td>
<td>
</td>
</tr>
<tr class="mergedrow">
<td>
-
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%B8%82%E5%A7%94%E4%B9%A6%E8%AE%B0" title="市委书记">
市委书记
</a>
</span>
</td>
<td>
<a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">
蔡奇
</a>
</td>
</tr>
<tr class="mergedrow">
<td>
<span class="nowrap">
-
<a class="mw-redirect" href="/wiki/%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A" title="人大常委会">
人大常委会
</a>
主任
</span>
</td>
<td>
<a class="mw-redirect" href="/wiki/%E6%9D%8E%E4%BC%9F_(%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%B8%B8%E5%A7%94)" title="李伟 (北京市委常委)">
李偉
</a>
</td>
</tr>
<tr class="mergedrow">
<td>
-
<span class="nowrap">
<a href="/wiki/%E5%B8%82%E9%95%BF" title="市长">
市长
</a>
</span>
</td>
<td>
<a href="/wiki/%E9%99%88%E5%90%89%E5%AE%81" title="陈吉宁">
陈吉宁
</a>
</td>
</tr>
<tr class="mergedbottomrow">
<td>
-
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%94%BF%E5%8D%8F" title="政协">
政协
</a>
主席
</span>
</td>
<td>
<a href="/wiki/%E5%90%89%E6%9E%97_(%E4%BA%BA%E7%89%A9)" title="吉林 (人物)">
吉林
</a>
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E9%9D%A2%E7%A7%AF" title="面积">
面积
</a>
</b>
</td>
<td>
16,411 km²(
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%90%84%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E9%9D%A2%E7%A7%AF%E5%88%97%E8%A1%A8" title="中华人民共和国各省级行政区面积列表">
第29位
</a>
)
</td>
</tr>
<tr class="mergedrow">
<td>
-占全国
</td>
<td>
0.174%
</td>
</tr>
<tr class="mergedbottomrow" style="display:none">
<td>
-占水域
</td>
<td>
%
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E4%BA%BA%E5%8F%A3" title="人口">
人口
</a>
</b>
<sub>
(2019)
</sub>
</td>
<td>
2153.6万
<br/>
<p>
-城镇 1865万
<sup class="reference" id="cite_ref-1">
<a href="#cite_note-1">
[1]
</a>
</sup>
<br/>
-市区 1123.6万
<sup class="reference" id="cite_ref-2">
<a href="#cite_note-2">
[2]
</a>
</sup>
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-3">
<a href="#cite_note-3">
[註 1]
</a>
</sup>
</span>
</p>
</td>
</tr>
<tr class="mergedrow" style="display:none">
<td>
-
<a href="/wiki/%E4%BA%BA%E5%8F%A3%E5%AF%86%E5%BA%A6" title="人口密度">
密度
</a>
</td>
<td>
/km²
</td>
</tr>
<tr class="mergedbottomrow" style="display:none">
<td>
-占全国
</td>
<td>
%
</td>
</tr>
<tr style="display:none">
<td>
<b>
<a href="/wiki/%E6%80%BB%E5%92%8C%E7%94%9F%E8%82%B2%E7%8E%87" title="总和生育率">
总和生育率
</a>
</b>
<sub>
(2010)
</sub>
</td>
<td>
(
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%90%84%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E6%80%BB%E5%92%8C%E7%94%9F%E8%82%B2%E7%8E%87%E8%A1%A8" title="中华人民共和国各省级行政区总和生育率表">
第位
</a>
)
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E6%96%B9%E8%A8%80" title="方言">
方言
</a>
</b>
</td>
<td>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%AF%9D" title="北京话">
北京话
</a>
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E5%9B%BD%E5%86%85%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="国内生产总值">
GDP
</a>
</b>
<sub>
(2019)
</sub>
</td>
<td>
<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%B8%81" title="人民币">
¥
</a>
35371.3亿人民币
<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%B8%81" title="人民币">
元
</a>
<sup class="reference" id="cite_ref-4">
<a href="#cite_note-4">
[3]
</a>
</sup>
<br/>
约合5350亿
<span style="white-space: nowrap">
美元
</span>
</td>
</tr>
<tr class="mergedrow">
<td>
-
<a class="mw-redirect" href="/wiki/%E4%BA%BA%E5%9D%87%E5%9B%BD%E5%86%85%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="人均国内生产总值">
人均
</a>
</td>
<td>
¥16.4万人民币
<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%B8%81" title="人民币">
元
</a>
<br/>
约合24800
<span style="white-space: nowrap">
美元
</span>
</td>
</tr>
<tr class="mergedbottomrow" style="display:none">
<td>
-占全国
</td>
<td>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%9C%B0%E5%8C%BA%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC%E5%88%97%E8%A1%A8" title="中华人民共和国省级行政区地区生产总值列表">
%
</a>
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E4%BA%BA%E7%B1%BB%E5%8F%91%E5%B1%95%E6%8C%87%E6%95%B0" title="人类发展指数">
HDI
</a>
</b>
<sub>
(2017)
</sub>
</td>
<td>
0.887(
<span style="background:#007F00;color:#FFFFFF;">
极高
</span>
,
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E4%BA%BA%E7%B1%BB%E5%8F%91%E5%B1%95%E6%8C%87%E6%95%B0%E5%88%97%E8%A1%A8" title="中国省级行政区人类发展指数列表">
第1位
</a>
)
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E4%B8%AD%E5%9C%8B%E6%B0%91%E6%97%8F%E5%88%97%E8%A1%A8" title="中國民族列表">
主要民族
</a>
</b>
</td>
<td>
<a href="/wiki/%E6%B1%89%E6%97%8F" title="汉族">
汉族
</a>
96%
<br/>
<a href="/wiki/%E6%BB%A1%E6%97%8F" title="满族">
满族
</a>
2%
<br/>
<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">
回族
</a>
1.6%
<br/>
<a href="/wiki/%E8%92%99%E5%8F%A4%E6%97%8F" title="蒙古族">
蒙古族
</a>
0.3%
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%A2%83%E5%86%85%E5%9C%B0%E5%8C%BA%E9%82%AE%E6%94%BF%E7%BC%96%E7%A0%81%E5%88%97%E8%A1%A8" title="中华人民共和国境内地区邮政编码列表">
邮政编码
</a>
</b>
</td>
<td>
100000
</td>
</tr>
<tr>
<td>
<b>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7" title="中华人民共和国电话区号">
电话区号
</a>
</b>
</td>
<td>
<a class="mw-redirect" href="/wiki/%E5%9B%BD%E9%99%85%E5%86%A0%E7%A0%81" title="国际冠码">
+
</a>
<a href="/wiki/%E5%9B%BD%E9%99%85%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7%E5%88%97%E8%A1%A8" title="国际电话区号列表">
86
</a>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7" title="中华人民共和国电话区号">
(0)10
</a>
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E5%B8%82%E6%A0%91" title="市树">
市树
</a>
</b>
</td>
<td>
<a href="/wiki/%E4%BE%A7%E6%9F%8F" title="侧柏">
侧柏
</a>
、
<a class="mw-redirect" href="/wiki/%E5%9B%BD%E6%A7%90" title="国槐">
国槐
</a>
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E5%B8%82%E8%8A%B1" title="市花">
市花
</a>
</b>
</td>
<td>
<a href="/wiki/%E6%9C%88%E5%AD%A3" title="月季">
月季
</a>
、
<a href="/wiki/%E8%8F%8A%E8%8A%B1" title="菊花">
菊花
</a>
</td>
</tr>
<tr>
<td>
<b>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%BD%A6%E8%BE%86%E7%89%8C%E7%85%A7" title="中华人民共和国车辆牌照">
车辆号牌
</a>
</b>
</td>
<td>
京A, C, E, F, H, J, K, L, M, N, P, Q
<br/>
京B(出租车)
<br/>
京G,Y(郊区)
<br/>
京O,D(警察和政府)
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E5%8E%BF%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="县级行政区">
县级行政区
</a>
</b>
</td>
<td>
16个
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/%E4%B9%A1%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="乡级行政区">
乡级行政区
</a>
</b>
</td>
<td>
322个
</td>
</tr>
<tr>
<td>
<b>
<a href="/wiki/ISO_3166-2" title="ISO 3166-2">
ISO 3166-2
</a>
</b>
</td>
<td>
CN-BJ
</td>
</tr>
<tr>
<td colspan="2" style="text-align:center;">
<b>
政府门户网站
</b>
<br/>
<a class="external text" href="http://www.beijing.gov.cn/" rel="nofollow">
首都之窗
</a>
</td>
</tr>
<tr>
<td colspan="2">
<span style="font-size:smaller;">
<b>
人口与GDP数据的参考文献:
</b>
</span>
<div style="padding-left:2em;">
<small>
<div>
<ul>
<li>
2010年2月26日,中国之声《央广新闻》14时15分报道
</li>
</ul>
</div>
</small>
</div>
<span style="font-size:smaller;">
<b>
民族数据的参考文献:
</b>
</span>
<div style="padding-left:2em;">
<small>
<div>
<li>
2010年8月20日,新华网-新华新闻报道
</li>
</div>
</small>
</div>
</td>
</tr>
</tbody>
</table>
<table class="infobox" style="width: 22em; text-align:left; font-size:small; line-height:1.5em;">
<tbody>
<tr>
<td colspan="2" style="text-align:center;font-size: 125%; background-color: #b0c4de;">
<b>
北京市
</b>
</td>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; white-space: nowrap; font-size: small;">
<a href="/wiki/%E6%B1%89%E8%AF%AD" title="汉语">
汉语
</a>
</th>
<td style="font-size: small; width: 50%;;">
<span style="font-size: 1rem; width: 50%;">
<span lang="zh-hani">
北京
</span>
</span>
</td>
</tr>
<tr>
<td colspan="2" style="text-align:center;font-size: small; width: 50%;;">
</td>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
<a href="/wiki/%E6%B1%89%E8%AF%AD%E6%8B%BC%E9%9F%B3" title="汉语拼音">
汉语拼音
</a>
</th>
<td style="width: 50%; text-align: left;">
<style data-mw-deduplicate="TemplateStyles:r58929728">
.mw-parser-output .sans-serif{font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,Lato,"Helvetica Neue",Helvetica,Arial,sans-serif}
</style>
<span class="sans-serif">
Běijīng
<br/>
<span class="unicode haudio">
<span class="fn">
<span style="white-space:nowrap">
<a href="/wiki/File:Zh-Beijing.ogg" title="关于这个音频文件">
<img alt="关于这个音频文件" data-file-height="20" data-file-width="20" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/11px-Loudspeaker.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/17px-Loudspeaker.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/22px-Loudspeaker.svg.png 2x" width="11"/>
</a>
</span>
<a class="internal" href="//upload.wikimedia.org/wikipedia/commons/8/8a/Zh-Beijing.ogg" title="Zh-Beijing.ogg">
发音
</a>
</span>
<small class="metadata audiolinkinfo" style="cursor:help;">
<sup>
<a class="mw-redirect" href="/wiki/Wikipedia:%E5%AA%92%E9%AB%94%E5%B9%AB%E5%8A%A9" title="Wikipedia:媒體幫助">
<span style="cursor:help;">
帮助
</span>
</a>
·
<a href="/wiki/File:Zh-Beijing.ogg" title="File:Zh-Beijing.ogg">
<span style="cursor:help;">
信息
</span>
</a>
</sup>
</small>
</span>
</span>
</td>
</tr>
<tr style="display:none">
<td colspan="2">
</td>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; white-space: nowrap; font-size: small;">
<a href="/wiki/%E9%83%B5%E6%94%BF%E5%BC%8F%E6%8B%BC%E9%9F%B3" title="郵政式拼音">
郵政式拼音
</a>
</th>
<td style="font-size: small; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
Peking
</span>
</td>
</tr>
<tr>
<td colspan="2" style="text-align:center;font-size: small; width: 50%;;">
<table cellspacing="3" class="collapsible collapsed" style="border-spacing:3px;padding:0;border:none;margin:-3px;width:auto;min-width:100%;font-size:small;clear:none;float:none;background-color:transparent">
<tbody>
<tr>
<th colspan="2" style="text-align:center;font-size:125%;font-weight:bold;font-size: 100%; text-align: left; background-color: #f9ffbc">
标音
</th>
</tr>
<tr>
<th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;">
<a href="/wiki/%E5%AE%98%E8%AF%9D" title="官话">
官话
</a>
</th>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a href="/wiki/%E6%B1%89%E8%AF%AD%E6%8B%BC%E9%9F%B3" title="汉语拼音">
汉语拼音
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
Běijīng
<br/>
<span class="unicode haudio">
<span class="fn">
<span style="white-space:nowrap">
<a href="/wiki/File:Zh-Beijing.ogg" title="关于这个音频文件">
<img alt="关于这个音频文件" data-file-height="20" data-file-width="20" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/11px-Loudspeaker.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/17px-Loudspeaker.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8a/Loudspeaker.svg/22px-Loudspeaker.svg.png 2x" width="11"/>
</a>
</span>
<a class="internal" href="//upload.wikimedia.org/wikipedia/commons/8/8a/Zh-Beijing.ogg" title="Zh-Beijing.ogg">
发音
</a>
</span>
<small class="metadata audiolinkinfo" style="cursor:help;">
<sup>
<a class="mw-redirect" href="/wiki/Wikipedia:%E5%AA%92%E9%AB%94%E5%B9%AB%E5%8A%A9" title="Wikipedia:媒體幫助">
<span style="cursor:help;">
帮助
</span>
</a>
·
<a href="/wiki/File:Zh-Beijing.ogg" title="File:Zh-Beijing.ogg">
<span style="cursor:help;">
信息
</span>
</a>
</sup>
</small>
</span>
</span>
</td>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a href="/wiki/%E5%A8%81%E5%A6%A5%E7%91%AA%E6%8B%BC%E9%9F%B3" title="威妥瑪拼音">
威妥瑪拼音
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
Pei
<sup>
3
</sup>
ching
<sup>
1
</sup>
or Pei
<sup>
3
</sup>
-ching
<sup>
1
</sup>
</span>
</td>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a href="/wiki/%E6%B3%A8%E9%9F%B3%E7%AC%A6%E8%99%9F" title="注音符號">
注音符號
</a>
</th>
<td style="text-align: left; width: 50%;;">
ㄅㄟˇ ㄐㄧㄥ
</td>
</tr>
<tr>
<th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;">
<a href="/wiki/%E5%AE%98%E8%AF%9D" title="官话">
其他官话
</a>
</th>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC%E5%AE%98%E8%AF%9D" title="南京官话">
南京官话
</a>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E8%A9%B1%E6%8B%89%E4%B8%81%E5%8C%96%E6%96%B9%E6%A1%88#輸入法方案" title="南京話拉丁化方案">
拼音
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
bä
<sup>
5
</sup>
jin
<sup>
1
</sup>
</span>
</td>
</tr>
<tr>
<th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;">
<a href="/wiki/%E9%97%BD%E8%AF%AD" title="闽语">
闽语
</a>
</th>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a href="/wiki/%E9%97%BD%E5%8D%97%E8%AF%AD" title="闽南语">
闽南语
</a>
<a href="/wiki/%E7%99%BD%E8%A9%B1%E5%AD%97" title="白話字">
白話字
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
Pak-kiaⁿ
</span>
</td>
</tr>
<tr>
<th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;">
<a href="/wiki/%E5%90%B4%E8%AF%AD" title="吴语">
吴语
</a>
</th>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a href="/wiki/%E5%90%B4%E8%AF%AD" title="吴语">
拉丁化
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
poh
<sup>
入
</sup>
cin
<sup>
平
</sup>
</span>
</td>
</tr>
<tr>
<th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;">
<a href="/wiki/%E7%B2%A4%E8%AF%AD" title="粤语">
粤语
</a>
</th>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a class="mw-redirect" href="/wiki/%E7%B2%B5%E6%8B%BC" title="粵拼">
粵拼
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
bak
<sup>
1
</sup>
ging
<sup>
1
</sup>
</span>
</td>
</tr>
<tr>
<th colspan="2" style="text-align:center;background-color: #dcffc9; font-size: small;">
<a href="/wiki/%E5%AE%A2%E5%AE%B6%E8%AF%9D" title="客家话">
客家话
</a>
</th>
</tr>
<tr>
<th scope="row" style="text-align:left;font-weight:normal; width: 50%; white-space: nowrap;">
-
<a href="/wiki/%E5%AE%A2%E5%AE%B6%E8%A9%B1%E6%8B%BC%E9%9F%B3%E6%96%B9%E6%A1%88" title="客家話拼音方案">
客家话拼音
</a>
</th>
<td style="text-align: left; width: 50%;;">
<link href="mw-data:TemplateStyles:r58929728" rel="mw-deduplicated-inline-style"/>
<span class="sans-serif">
Pet-kîn
</span>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<p>
<b>
北京市
</b>
,通称
<b>
北京
</b>
(
<a href="/wiki/%E6%B1%89%E8%AF%AD%E6%8B%BC%E9%9F%B3" title="汉语拼音">
汉语拼音
</a>
:
<i>
Běijīng
</i>
;
<a class="mw-redirect" href="/wiki/%E9%82%AE%E6%94%BF%E5%BC%8F%E6%8B%BC%E9%9F%B3" title="邮政式拼音">
邮政式拼音
</a>
:Peking),简称“
<b>
京
</b>
”,是
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B" title="中華人民共和國">
中華人民共和國
</a>
的
<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">
首都
</a>
及
<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">
直辖市
</a>
,是中國大陸的
<a href="/wiki/%E6%94%BF%E6%B2%BB" title="政治">
政治
</a>
、
<a href="/wiki/%E6%96%87%E5%8C%96" title="文化">
文化
</a>
、科技和国际交往中心,是
<a href="/wiki/%E6%8C%89%E5%B8%82%E5%9F%9F%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%88%97%E7%9A%84%E4%B8%96%E7%95%8C%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="按市域人口排列的世界城市列表">
世界人口第三多的城市
</a>
和
<a href="/wiki/%E5%85%A8%E7%90%83%E9%A6%96%E9%83%BD%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%90%8D" title="全球首都人口排名">
人口最多的首都
</a>
,具有重要的国际影响力。北京位於
<a class="mw-redirect" href="/wiki/%E8%8F%AF%E5%8C%97%E5%B9%B3%E5%8E%9F" title="華北平原">
華北平原
</a>
的西北边缘,背靠
<a href="/wiki/%E7%87%95%E5%B1%B1" title="燕山">
燕山
</a>
,有
<a href="/wiki/%E6%B0%B8%E5%AE%9A%E6%B2%B3" title="永定河">
永定河
</a>
流经
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E6%B1%A0" title="北京城池">
老城
</a>
西南,毗邻
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
、
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北省
</a>
,为
<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%86%80%E5%9F%8E%E5%B8%82%E7%BE%A4" title="京津冀城市群">
京津冀城市群
</a>
的重要组成部分。
</p>
<p>
北京是中国
<a class="mw-redirect" href="/wiki/%E5%9B%9B%E5%A4%A7%E5%8F%A4%E9%83%BD" title="四大古都">
古都
</a>
之一,是拥有三千余年建城历史、八百六十余年建都史的
<a class="mw-redirect" href="/wiki/%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="历史文化名城">
历史文化名城
</a>
,有
<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">
辽
</a>
、
<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">
金
</a>
、
<a href="/wiki/%E5%85%83%E6%9C%9D" title="元朝">
元
</a>
、
<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">
明
</a>
、
<a class="mw-redirect" href="/wiki/%E6%B8%85" title="清">
清
</a>
五个
<a href="/wiki/%E6%9C%9D%E4%BB%A3" title="朝代">
朝代
</a>
在此定都,及数个政权建政于此。
<a href="/wiki/%E7%89%A7%E9%87%8E%E4%B9%8B%E6%88%98" title="牧野之战">
公元前1122年
</a>
<a href="/wiki/%E5%91%A8%E6%AD%A6%E7%8E%8B" title="周武王">
周武王
</a>
灭
<a href="/wiki/%E5%95%86%E6%9C%9D" title="商朝">
商
</a>
后,封宗室
<a href="/wiki/%E5%8F%AC%E5%85%AC%E5%A5%AD" title="召公奭">
召公奭
</a>
于
<a href="/wiki/%E7%87%95%E5%9B%BD" title="燕国">
燕国
</a>
,是为北京建城之始。金中都时期人口超过一百万,为元、明、清三代的北京城的建设奠定了基础。1949年,北京被定为
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
首都,此后曾发生了
<a href="/wiki/%E7%BA%A2%E5%85%AB%E6%9C%88" title="红八月">
红八月
</a>
、
<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">
四五运动
</a>
、
<a class="mw-redirect" href="/wiki/%E5%85%AD%E5%9B%9B%E5%A4%A9%E5%AE%89%E9%97%A8%E4%BA%8B%E4%BB%B6" title="六四天安门事件">
六四天安门事件
</a>
等各种重大事件。北京荟萃了自元明清以来的近世
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E6%96%87%E5%8C%96" title="中华文化">
中华文化
</a>
,拥有众多历史名胜古迹和人文景观,拥有7项
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%96%E7%95%8C%E9%81%97%E4%BA%A7" title="中国世界遗产">
世界遗产
</a>
,是世界上拥有
<a href="/wiki/%E6%96%87%E5%8C%96%E9%81%97%E4%BA%A7" title="文化遗产">
文化遗产
</a>
项目数最多的城市。在中国过去的八个世纪里,几乎北京所有的主要建筑都拥有不可磨灭的历史意义。北京古迹众多,著名的有
<a class="mw-redirect" href="/wiki/%E7%B4%AB%E7%A6%81%E5%9F%8E" title="紫禁城">
紫禁城
</a>
、
<a href="/wiki/%E5%A4%A9%E5%9D%9B" title="天坛">
天坛
</a>
、
<a href="/wiki/%E9%A2%90%E5%92%8C%E5%9B%AD" title="颐和园">
颐和园
</a>
、
<a href="/wiki/%E5%9C%86%E6%98%8E%E5%9B%AD" title="圆明园">
圆明园
</a>
、
<a href="/wiki/%E5%8C%97%E6%B5%B7%E5%85%AC%E5%9B%AD" title="北海公园">
北海公园
</a>
等;
<a href="/wiki/%E8%83%A1%E5%90%8C" title="胡同">
胡同
</a>
和
<a href="/wiki/%E5%9B%9B%E5%90%88%E9%99%A2" title="四合院">
四合院
</a>
作为北京老城的典型民居形式,已经是北京历史重要的文化符号
<sup class="reference" id="cite_ref-autogenerated2_5-0">
<a href="#cite_note-autogenerated2-5">
[4]
</a>
</sup>
。北京是中国重要的旅游城镇之一,被《
<a href="/wiki/%E7%B1%B3%E5%85%B6%E6%9E%97" title="米其林">
米其林
</a>
旅游指南》评为“三星级旅游推荐”(最高级别)
<sup class="reference" id="cite_ref-6">
<a href="#cite_note-6">
[5]
</a>
</sup>
。
</p>
<p>
北京在中国大陸的政治、经贸、文化、教育和科技领域拥有显著影响力,为中国大陸绝大多数
<a href="/wiki/%E5%9B%BD%E6%9C%89%E4%BC%81%E4%B8%9A" title="国有企业">
国有企业
</a>
总部所在地,并且拥有全球最多的
<a href="/wiki/%E8%B4%A2%E5%AF%8C%E4%B8%96%E7%95%8C500%E5%BC%BA" title="财富世界500强">
财富世界500强
</a>
企业总部
<sup class="reference" id="cite_ref-7">
<a href="#cite_note-7">
[6]
</a>
</sup>
,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">
北京商务中心区
</a>
聚集有大量国际性金融商务办公设施及
<a class="mw-redirect" href="/wiki/%E6%91%A9%E5%A4%A9%E5%A4%A7%E6%A5%BC" title="摩天大楼">
摩天大楼
</a>
,
<a href="/wiki/%E4%B8%AD%E5%85%B3%E6%9D%91" title="中关村">
中关村地区
</a>
则集中了中国大陸重要的高新技术产业。北京是
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E9%90%B5%E8%B7%AF%E9%81%8B%E8%BC%B8" title="中華人民共和國鐵路運輸">
中国大陸铁路运输
</a>
和
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%AC%E8%B7%AF" title="中国公路">
公路运输
</a>
的枢纽城市之一,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%A6%96%E9%83%BD%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA" title="北京首都国际机场">
北京首都国际机场
</a>
的旅客吞吐量位居世界第二
<sup class="reference" id="cite_ref-2018年旅客破亿_8-0">
<a href="#cite_note-2018年旅客破亿-8">
[7]
</a>
</sup>
,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">
北京地铁
</a>
则是世界上运营里程最长、客运量最多的
<a class="mw-redirect" href="/wiki/%E5%9F%8E%E5%B8%82%E8%BD%A8%E9%81%93%E4%BA%A4%E9%80%9A%E7%B3%BB%E7%BB%9F" title="城市轨道交通系统">
城市轨道交通系统
</a>
<sup class="reference" id="cite_ref-9">
<a href="#cite_note-9">
[8]
</a>
</sup>
<sup class="reference" id="cite_ref-10">
<a href="#cite_note-10">
[9]
</a>
</sup>
<sup class="reference" id="cite_ref-11">
<a href="#cite_note-11">
[10]
</a>
</sup>
。北京是中国大陸拥有最多
<a class="mw-redirect" href="/wiki/%E9%AB%98%E7%AD%89%E9%99%A2%E6%A0%A1" title="高等院校">
高等院校
</a>
的城市
<sup class="reference" id="cite_ref-Beijing_12-0">
<a href="#cite_note-Beijing-12">
[11]
</a>
</sup>
,校址位于北京的
<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6" title="清华大学">
清华大学
</a>
和
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%A6" title="北京大学">
北京大学
</a>
被视为中国大陸顶尖大学的代表
<sup class="reference" id="cite_ref-13">
<a href="#cite_note-13">
[12]
</a>
</sup>
。北京在全球政治、经济等社会活动中处于重要地位并具有主导辐射带动能力,在GaWC
<a href="/wiki/%E5%85%A8%E7%90%83%E5%9F%8E%E5%B8%82" title="全球城市">
全球城市
</a>
排行中排名第6,在中華人民共和国中,仅次于
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港
</a>
和
<a class="mw-redirect" href="/wiki/%E4%B8%8A%E6%B5%B7" title="上海">
上海
</a>
<sup class="reference" id="cite_ref-14">
<a href="#cite_note-14">
[13]
</a>
</sup>
。
</p>
<div aria-labelledby="mw-toc-heading" class="toc" id="toc" role="navigation">
<input class="toctogglecheckbox" id="toctogglecheckbox" role="button" style="display:none" type="checkbox"/>
<div class="toctitle" dir="ltr" lang="zh">
<h2 id="mw-toc-heading">
目录
</h2>
<span class="toctogglespan">
<label class="toctogglelabel" for="toctogglecheckbox">
</label>
</span>
</div>
<ul>
<li class="toclevel-1 tocsection-1">
<a href="#名称">
<span class="tocnumber">
1
</span>
<span class="toctext">
名称
</span>
</a>
</li>
<li class="toclevel-1 tocsection-2">
<a href="#历史">
<span class="tocnumber">
2
</span>
<span class="toctext">
历史
</span>
</a>
<ul>
<li class="toclevel-2 tocsection-3">
<a href="#史前">
<span class="tocnumber">
2.1
</span>
<span class="toctext">
史前
</span>
</a>
</li>
<li class="toclevel-2 tocsection-4">
<a href="#古代">
<span class="tocnumber">
2.2
</span>
<span class="toctext">
古代
</span>
</a>
</li>
<li class="toclevel-2 tocsection-5">
<a href="#近代">
<span class="tocnumber">
2.3
</span>
<span class="toctext">
近代
</span>
</a>
</li>
<li class="toclevel-2 tocsection-6">
<a href="#文化大革命期间">
<span class="tocnumber">
2.4
</span>
<span class="toctext">
文化大革命期间
</span>
</a>
</li>
<li class="toclevel-2 tocsection-7">
<a href="#现当代">
<span class="tocnumber">
2.5
</span>
<span class="toctext">
现当代
</span>
</a>
</li>
</ul>
</li>
<li class="toclevel-1 tocsection-8">
<a href="#地理">
<span class="tocnumber">
3
</span>
<span class="toctext">
地理
</span>
</a>
<ul>
<li class="toclevel-2 tocsection-9">
<a href="#氣候">
<span class="tocnumber">
3.1
</span>
<span class="toctext">
氣候
</span>
</a>
</li>
<li class="toclevel-2 tocsection-10">
<a href="#空气污染">
<span class="tocnumber">
3.2
</span>
<span class="toctext">
空气污染
</span>
</a>
</li>
</ul>
</li>
<li class="toclevel-1 tocsection-11">
<a href="#行政区划">
<span class="tocnumber">
4
</span>
<span class="toctext">
行政区划
</span>
</a>
</li>
<li class="toclevel-1 tocsection-12">
<a href="#政治">
<span class="tocnumber">
5
</span>
<span class="toctext">
政治
</span>
</a>
<ul>
<li class="toclevel-2 tocsection-13">
<a href="#四大机构">
<span class="tocnumber">
5.1
</span>
<span class="toctext">
四大机构
</span>
</a>
</li>
</ul>
</li>
<li class="toclevel-1 tocsection-14">
<a href="#经济">
<span class="tocnumber">
6
</span>
<span class="toctext">
经济
</span>
</a>
<ul>
<li class="toclevel-2 tocsection-15">
<a href="#經濟數據">
<span class="tocnumber">
6.1
</span>
<span class="toctext">
經濟數據
</span>
</a>
</li>
<li class="toclevel-2 tocsection-16">
<a href="#-{zh:基础设施;zh-hans:基础设施;zh-hant:基礎建設}-">
<span class="tocnumber">
6.2
</span>
<span class="toctext">
基础设施
</span>
</a>
<ul>
<li class="toclevel-3 tocsection-17">
<a href="#公路">
<span class="tocnumber">
6.2.1
</span>
<span class="toctext">
公路
</span>
</a>
</li>
<li class="toclevel-3 tocsection-18">
<a href="#铁路">
<span class="tocnumber">
6.2.2
</span>
<span class="toctext">
铁路
</span>
</a>
</li>
<li class="toclevel-3 tocsection-19">
<a href="#航空">
<span class="tocnumber">
6.2.3
</span>
<span class="toctext">
航空
</span>
</a>
</li>
<li class="toclevel-3 tocsection-20">
<a href="#地面公交">
<span class="tocnumber">
6.2.4
</span>
<span class="toctext">
地面公交
</span>
</a>
</li>
<li class="toclevel-3 tocsection-21">
<a href="#出租车">
<span class="tocnumber">
6.2.5
</span>
<span class="toctext">
出租车
</span>
</a>
</li>
<li class="toclevel-3 tocsection-22">
<a href="#邮电">
<span class="tocnumber">
6.2.6
</span>
<span class="toctext">
邮电
</span>
</a>
</li>
</ul>
</li>
<li class="toclevel-2 tocsection-23">
<a href="#旅游業">
<span class="tocnumber">
6.3
</span>
<span class="toctext">
旅游業
</span>
</a>
</li>
</ul>
</li>
<li class="toclevel-1 tocsection-24">
<a href="#教育">
<span class="tocnumber">
7
</span>
<span class="toctext">
教育
</span>
</a>
</li>
<li class="toclevel-1 tocsection-25">
<a href="#人口">
<span class="tocnumber">
8
</span>
<span class="toctext">
人口
</span>
</a>
</li>
<li class="toclevel-1 tocsection-26">
<a href="#文化">
<span class="tocnumber">
9
</span>
<span class="toctext">
文化
</span>
</a>
<ul>
<li class="toclevel-2 tocsection-27">
<a href="#文学">
<span class="tocnumber">
9.1
</span>
<span class="toctext">
文学
</span>
</a>
</li>
<li class="toclevel-2 tocsection-28">
<a href="#饮食文化">
<span class="tocnumber">
9.2
</span>
<span class="toctext">
饮食文化
</span>
</a>
</li>
<li class="toclevel-2 tocsection-29">
<a href="#表演艺术">
<span class="tocnumber">
9.3
</span>
<span class="toctext">
表演艺术
</span>
</a>
</li>
<li class="toclevel-2 tocsection-30">
<a href="#艺术园区">
<span class="tocnumber">
9.4
</span>
<span class="toctext">
艺术园区
</span>
</a>
</li>
</ul>
</li>
<li class="toclevel-1 tocsection-31">
<a href="#人物">
<span class="tocnumber">
10
</span>
<span class="toctext">
人物
</span>
</a>
</li>
<li class="toclevel-1 tocsection-32">
<a href="#宗教">
<span class="tocnumber">
11
</span>
<span class="toctext">
宗教
</span>
</a>
</li>
<li class="toclevel-1 tocsection-33">
<a href="#体育">
<span class="tocnumber">
12
</span>
<span class="toctext">
体育
</span>
</a>
</li>
<li class="toclevel-1 tocsection-34">
<a href="#友好城市">
<span class="tocnumber">
13
</span>
<span class="toctext">
友好城市
</span>
</a>
</li>
<li class="toclevel-1 tocsection-35">
<a href="#注释">
<span class="tocnumber">
14
</span>
<span class="toctext">
注释
</span>
</a>
</li>
<li class="toclevel-1 tocsection-36">
<a href="#参考文献">
<span class="tocnumber">
15
</span>
<span class="toctext">
参考文献
</span>
</a>
</li>
<li class="toclevel-1 tocsection-37">
<a href="#外部链接">
<span class="tocnumber">
16
</span>
<span class="toctext">
外部链接
</span>
</a>
</li>
<li class="toclevel-1 tocsection-38">
<a href="#参见">
<span class="tocnumber">
17
</span>
<span class="toctext">
参见
</span>
</a>
</li>
</ul>
</div>
<h2>
<span id=".E5.90.8D.E7.A7.B0">
</span>
<span class="mw-headline" id="名称">
名称
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=1" title="编辑章节:名称">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<p>
曾先后被称为
<a href="/wiki/%E8%93%9F%E5%9F%8E" title="蓟城">
蓟城
</a>
、
<a class="mw-redirect" href="/wiki/%E7%87%95%E9%83%BD" title="燕都">
燕中都
</a>
、燕京、
<a class="mw-redirect" href="/wiki/%E8%93%9F%E5%8E%BF%E5%9F%8E" title="蓟县城">
蓟县
</a>
、
<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">
广阳郡
</a>
、
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E9%98%B3%E5%9B%BD" title="广阳国">
广阳国
</a>
、
<a class="mw-redirect" href="/wiki/%E5%B9%BD%E5%B7%9E" title="幽州">
幽州
</a>
、
<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">
燕国
</a>
、
<a href="/wiki/%E7%87%95%E9%83%A1" title="燕郡">
燕郡
</a>
、
<a href="/wiki/%E6%B6%BF%E9%83%A1" title="涿郡">
涿郡
</a>
、
<a class="mw-redirect" href="/wiki/%E8%8C%83%E9%98%B3%E8%8A%82%E5%BA%A6%E4%BD%BF" title="范阳节度使">
范阳
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8D%A2%E9%BE%99%E8%8A%82%E5%BA%A6%E4%BD%BF" title="卢龙节度使">
卢龙
</a>
、南京
<a href="/wiki/%E5%B9%BD%E9%83%BD%E5%BA%9C" title="幽都府">
幽都府
</a>
、南京
<a href="/wiki/%E6%9E%90%E6%B4%A5%E5%BA%9C" title="析津府">
析津府
</a>
、
<a href="/wiki/%E7%87%95%E5%B1%B1%E5%BA%9C%E8%B7%AF" title="燕山府路">
燕山府路
</a>
、
<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">
中都大兴府
</a>
、
<a href="/wiki/%E4%B8%AD%E9%83%BD%E8%B7%AF" title="中都路">
中都路
</a>
、
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E9%83%BD" title="大都">
大都路
</a>
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%BA%9C" title="大兴府">
大兴府
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8C%97%E5%B9%B3" title="北平">
北平府
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC" title="北京">
北京
</a>
、
<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">
京师
</a>
、
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
、
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
京兆地方
</a>
、
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">
北平特别市
</a>
等。现名北京市。有京城、京都、
<a class="mw-disambig" href="/wiki/%E4%BA%AC%E7%95%BF" title="京畿">
京畿
</a>
、京兆等非正式称呼。
</p>
<h2>
<span id=".E5.8E.86.E5.8F.B2">
</span>
<span class="mw-headline" id="历史">
历史
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=2" title="编辑章节:历史">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2" title="北京历史">
北京历史
</a>
</div>
<h3>
<span id=".E5.8F.B2.E5.89.8D">
</span>
<span class="mw-headline" id="史前">
史前
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=3" title="编辑章节:史前">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
距今60万年-2万年的时间内,北京地区处于
<a href="/wiki/%E6%97%A7%E7%9F%B3%E5%99%A8%E6%97%B6%E4%BB%A3" title="旧石器时代">
旧石器时代
</a>
,在周口店发现了旧石器时代早期
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E7%9B%B4%E7%AB%8B%E4%BA%BA" title="北京直立人">
北京直立人
</a>
、中期
<a class="new" href="/w/index.php?title=%E6%96%B0%E6%B4%9E%E4%BA%BA&action=edit&redlink=1" title="新洞人(页面不存在)">
新洞人
</a>
和晚期
<a href="/wiki/%E5%B1%B1%E9%A1%B6%E6%B4%9E%E4%BA%BA" title="山顶洞人">
山顶洞人
</a>
的典型遗址。北京地区在不晚于1万年前已经开始进入
<a href="/wiki/%E6%96%B0%E7%9F%B3%E5%99%A8%E6%97%B6%E4%BB%A3" title="新石器时代">
新石器时代
</a>
。当时该地区人类定居生活固定化,逐渐从山洞中迁徙出来,到平原地区定居
<sup class="reference" id="cite_ref-15">
<a href="#cite_note-15">
[14]
</a>
</sup>
。
</p>
<h3>
<span id=".E5.8F.A4.E4.BB.A3">
</span>
<span class="mw-headline" id="古代">
古代
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=4" title="编辑章节:古代">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
北京作为城市的历史可以追溯到3,000年前。
<a href="/wiki/%E8%A5%BF%E5%91%A8" title="西周">
西周
</a>
初年,
<a href="/wiki/%E5%91%A8%E6%AD%A6%E7%8E%8B" title="周武王">
周武王
</a>
封
<a href="/wiki/%E5%8F%AC%E5%85%AC%E5%A5%AD" title="召公奭">
召公奭
</a>
于
<a class="mw-redirect" href="/wiki/%E7%87%95%E5%9C%8B" title="燕國">
燕國
</a>
。燕国早期都城位于今
<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">
房山区
</a>
<a href="/wiki/%E7%90%89%E7%92%83%E6%B2%B3%E9%81%97%E5%9D%80" title="琉璃河遗址">
琉璃河遗址
</a>
。一些学者将琉璃河古城视为北京城的源头。据《史记》,周武王封尧的后人建立
<a href="/wiki/%E8%96%8A%E5%9C%8B" title="薊國">
蓟国
</a>
,都城为蓟。春秋时期,燕灭蓟,将都城迁至蓟。蓟城的具体位置尚有争议。郦道元《水经注》认为,蓟城的位置就在今天的北京。1950年代起,北京
<a href="/wiki/%E5%AE%A3%E6%AD%A6%E9%97%A8" title="宣武门">
宣武门
</a>
至
<a href="/wiki/%E5%92%8C%E5%B9%B3%E9%97%A8_(%E5%8C%97%E4%BA%AC)" title="和平门 (北京)">
和平门
</a>
一带的基建工程中发现了大量的春秋时代至西汉的陶井,学者据此认为蓟城的位置就在这一带,认为蓟城是北京城的起源。然而,这一区域并未发现西周时代的遗存,西周时蓟城的位置仍然未知。
</p>
<p>
前222年,
<a href="/wiki/%E7%A7%A6%E5%9B%BD" title="秦国">
秦国
</a>
灭燕后,设北京为
<a class="mw-redirect" href="/wiki/%E8%93%9F%E5%8E%BF" title="蓟县">
蓟县
</a>
,为
<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">
广阳郡
</a>
郡治。汉
<a href="/wiki/%E5%85%83%E5%87%A4" title="元凤">
元凤
</a>
元年广阳郡蓟县属
<a class="mw-redirect" href="/wiki/%E5%B9%BD%E5%B7%9E" title="幽州">
幽州
</a>
管辖。
<a href="/wiki/%E6%9C%AC%E5%A7%8B" title="本始">
本始
</a>
元年更名为
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E9%98%B3%E5%9B%BD" title="广阳国">
广阳国
</a>
首府。
<a href="/wiki/%E4%B8%9C%E6%B1%89" title="东汉">
东汉
</a>
<a class="mw-redirect" href="/wiki/%E5%85%89%E6%AD%A6%E5%B8%9D" title="光武帝">
光武
</a>
改制时,置幽州
<a href="/wiki/%E5%88%BA%E5%8F%B2" title="刺史">
刺史
</a>
部于蓟县。永元八年复为
<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">
广阳郡
</a>
治所。
<a href="/wiki/%E8%A5%BF%E6%99%8B" title="西晋">
西晋
</a>
时,朝廷改广阳郡为燕国,而幽州迁至
<a href="/wiki/%E8%8C%83%E9%98%B3" title="范阳">
范阳
</a>
。
<a class="mw-redirect" href="/wiki/%E5%8D%81%E5%85%AD%E5%9B%BD" title="十六国">
十六国
</a>
<a href="/wiki/%E5%90%8E%E8%B5%B5" title="后赵">
后赵
</a>
时,幽州驻所迁回蓟县,燕国改设为燕郡,历经
<a href="/wiki/%E5%89%8D%E7%87%95" title="前燕">
前燕
</a>
、
<a href="/wiki/%E5%89%8D%E7%A7%A6" title="前秦">
前秦
</a>
、
<a href="/wiki/%E5%8C%97%E7%87%95" title="北燕">
北燕
</a>
、
<a class="mw-redirect" href="/wiki/%E5%90%8E%E7%87%95" title="后燕">
后燕
</a>
和
<a href="/wiki/%E5%8C%97%E9%AD%8F" title="北魏">
北魏
</a>
的统治而不变。
</p>
<p>
<a href="/wiki/%E9%9A%8B%E6%9C%9D" title="隋朝">
隋朝
</a>
开皇三年(583年)废除燕郡。但很快在大业三年(607年),
<a href="/wiki/%E9%9A%8B%E6%9C%9D" title="隋朝">
隋朝
</a>
改
<a class="mw-redirect" href="/wiki/%E5%B9%BD%E5%B7%9E" title="幽州">
幽州
</a>
为
<a href="/wiki/%E6%B6%BF%E9%83%A1" title="涿郡">
涿郡
</a>
。
<a href="/wiki/%E5%94%90%E6%9C%9D" title="唐朝">
唐朝
</a>
<a href="/wiki/%E6%AD%A6%E5%BE%B7" title="武德">
武德
</a>
年间,
<a href="/wiki/%E6%B6%BF%E9%83%A1" title="涿郡">
涿郡
</a>
复称为
<a class="mw-redirect" href="/wiki/%E5%B9%BD%E5%B7%9E" title="幽州">
幽州
</a>
。贞观元年,幽州划归
<a href="/wiki/%E6%B2%B3%E5%8C%97%E9%81%93" title="河北道">
河北道
</a>
监察区。后北京成为
<a class="mw-redirect" href="/wiki/%E8%8C%83%E9%98%B3%E8%8A%82%E5%BA%A6%E4%BD%BF" title="范阳节度使">
范阳节度使
</a>
的驻地。
<a class="mw-redirect" href="/wiki/%E5%AE%89%E5%8F%B2%E4%B9%8B%E4%B9%B1" title="安史之乱">
安史之乱
</a>
期间,杂胡
<a class="mw-redirect" href="/wiki/%E5%AE%89%E7%A6%84%E5%B1%B1" title="安禄山">
安禄山
</a>
在
<a class="mw-redirect" href="/wiki/%E8%8C%83%E9%99%BD" title="范陽">
范陽
</a>
(今日
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC" title="北京">
北京
</a>
、
<a class="mw-redirect" href="/wiki/%E4%BF%9D%E5%AE%9A" title="保定">
保定
</a>
附近)称
<a href="/wiki/%E7%9A%87%E5%B8%9D" title="皇帝">
帝
</a>
,建国号为“
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E7%87%95" title="大燕">
大燕
</a>
”。唐朝平乱后,复置幽州,归
<a class="mw-redirect" href="/wiki/%E5%8D%A2%E9%BE%99%E8%8A%82%E5%BA%A6%E4%BD%BF" title="卢龙节度使">
卢龙节度使
</a>
节制
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-16">
<a href="#cite_note-16">
[註 2]
</a>
</sup>
</span>
。
<a class="mw-redirect" href="/wiki/%E4%BA%94%E4%BB%A3" title="五代">
五代
</a>
初期,军阀
<a class="mw-redirect" href="/wiki/%E5%88%98%E4%BB%81%E6%81%AD" title="刘仁恭">
刘仁恭
</a>
割据此地,后其子
<a class="mw-redirect" href="/wiki/%E5%88%98%E5%AE%88%E5%85%89" title="刘守光">
刘守光
</a>
称燕王,被
<a href="/wiki/%E5%90%8E%E5%94%90" title="后唐">
后唐
</a>
消灭。
<a href="/wiki/%E5%90%8E%E6%99%8B" title="后晋">
后晋
</a>
的建立者
<a class="mw-redirect" href="/wiki/%E6%B2%99%E9%99%80%E4%BA%BA" title="沙陀人">
沙陀人
</a>
<a href="/wiki/%E7%9F%B3%E6%95%AC%E7%91%AD" title="石敬瑭">
石敬瑭
</a>
为了打败后唐,投降
<a href="/wiki/%E5%A5%91%E4%B8%B9%E4%BA%BA" title="契丹人">
契丹人
</a>
,将
<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">
燕云十六州
</a>
在后晋天福元年(936年)送给
<a class="mw-redirect" href="/wiki/%E5%A5%91%E4%B8%B9" title="契丹">
契丹
</a>
,并向契丹称自己為
<a class="mw-redirect" href="/wiki/%E5%85%92%E7%9A%87%E5%B8%9D" title="兒皇帝">
儿皇帝
</a>
。石敬瑭割让包括今北京在内的
<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">
燕云十六州
</a>
为辽国或
<a class="mw-redirect" href="/wiki/%E9%87%91%E5%9B%BD" title="金国">
金国
</a>
后来对
<a class="mw-redirect" href="/wiki/%E5%90%8E%E6%B1%89" title="后汉">
后汉
</a>
、
<a href="/wiki/%E5%90%8E%E5%91%A8" title="后周">
后周
</a>
、
<a href="/wiki/%E5%AE%8B%E6%9C%9D" title="宋朝">
宋朝
</a>
威胁打开了门户。
</p>
<p>
<a href="/wiki/%E5%8C%97%E5%AE%8B" title="北宋">
北宋
</a>
初年,
<a href="/wiki/%E5%AE%8B%E5%A4%AA%E5%AE%97" title="宋太宗">
宋太宗
</a>
在
<a href="/wiki/%E9%AB%98%E6%A2%81%E6%B2%B3" title="高梁河">
高梁河
</a>
(今北京市
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
海淀区
</a>
)与
<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">
辽
</a>
战斗,意图收复
<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">
燕云十六州
</a>
未果。
<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">
辽朝
</a>
于
<a href="/wiki/%E4%BC%9A%E5%90%8C_(%E5%B9%B4%E5%8F%B7)" title="会同 (年号)">
会同元年
</a>
起在北京地区建立了陪都,号
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC%E5%B9%BD%E9%83%BD%E5%BA%9C" title="南京幽都府">
南京幽都府
</a>
;
<a href="/wiki/%E9%96%8B%E6%B3%B0_(%E9%81%BC)" title="開泰 (遼)">
开泰元年
</a>
改号
<a href="/wiki/%E6%9E%90%E6%B4%A5%E5%BA%9C" title="析津府">
析津府
</a>
。北宋末年,宋联金灭辽后收复
<a href="/wiki/%E7%87%95%E9%9B%B2%E5%8D%81%E5%85%AD%E5%B7%9E" title="燕雲十六州">
燕云十六州
</a>
,并设置
<a href="/wiki/%E7%87%95%E5%B1%B1%E5%BA%9C%E8%B7%AF" title="燕山府路">
燕山府路
</a>
和
<a class="mw-redirect" href="/wiki/%E9%9B%B2%E4%B8%AD%E5%BA%9C%E8%B7%AF" title="雲中府路">
云中府路
</a>
,北京属于燕山府路。
<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">
金朝
</a>
以
<a href="/wiki/%E5%BC%B5%E8%A6%BA" title="張覺">
张觉
</a>
事件为借口大举攻宋,再次出兵
<a href="/wiki/%E7%87%95%E5%B1%B1%E5%BA%9C" title="燕山府">
燕山府
</a>
。
<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">
金朝
</a>
<a href="/wiki/%E8%B4%9E%E5%85%83_(%E9%87%91%E6%9C%9D)" title="贞元 (金朝)">
贞元
</a>
元年(1153年),
<a class="mw-redirect" href="/wiki/%E5%AE%8C%E9%A2%9C%E4%BA%AE" title="完颜亮">
完颜亮
</a>
正式迁都于北京,改燕京为圣都,不久又称
<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">
中都大兴府
</a>
,这是北京历史上第一次成为中国的首都,至今已有八百余年建都史。
<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">
金中都
</a>
的建成使北京成为当时世界上最繁华的商业大都市,人口超过一百万,城内居住着众多部族,东西方众多文化在这里交流融合,北京从此成为国际性都市。完颜亮在中都之东开通了潞河,潞城因此改名
<a href="/wiki/%E9%80%9A%E5%B7%9E_(%E5%8C%97%E4%BA%AC)" title="通州 (北京)">
通州
</a>
,西面则建成
<a href="/wiki/%E5%8D%A2%E6%B2%9F%E6%A1%A5" title="卢沟桥">
卢沟桥
</a>
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-17">
<a href="#cite_note-17">
[註 3]
</a>
</sup>
</span>
,使西南陆路各种货物可以直接进入中都。金代还首创了漕运形式,即从水路运送粮米到京城。
</p>
<p>
蒙古帝国
<a href="/wiki/%E6%88%90%E5%90%89%E6%80%9D%E6%B1%97" title="成吉思汗">
成吉思汗
</a>
麾下大将
<a href="/wiki/%E6%9C%A8%E5%8D%8E%E9%BB%8E" title="木华黎">
木华黎
</a>
从1214年农历五月开始到1215年农历五月攻下金中都,对中都整整围困了将近一年之久。城破后展开了为期一个月的大屠杀,超过百万人殒命,又纵火焚城,几乎彻底毁灭了这座城市
<sup class="reference" id="cite_ref-18">
<a href="#cite_note-18">
[15]
</a>
</sup>
。金朝著名大词人
<a href="/wiki/%E5%85%83%E5%A5%BD%E9%97%AE" title="元好问">
元好问
</a>
的胞兄元好古也在屠城中丧命。
<a href="/wiki/%E5%BF%BD%E5%BF%85%E7%83%88" title="忽必烈">
忽必烈
</a>
1260年即位後,決定以漢地作為統治基礎,將燕京定為首都,至元元年(1264年)改稱中都路大兴府。至元九年(1272年),中都大兴府正式改名为
<a href="/wiki/%E5%85%83%E5%A4%A7%E9%83%BD" title="元大都">
大都路
</a>
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-19">
<a href="#cite_note-19">
[註 4]
</a>
</sup>
</span>
。
</p>
<p>
<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">
明朝
</a>
初年,
<a href="/wiki/%E6%9C%B1%E5%85%83%E7%92%8B" title="朱元璋">
朱元璋
</a>
以
<a class="mw-redirect" href="/wiki/%E9%87%91%E9%99%B5" title="金陵">
金陵
</a>
<a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">
应天府
</a>
(今
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京市
</a>
)为京师,大都路于洪武元年八月被明軍收復,改称为北平府,同年十月应军事需要划归
<a class="mw-redirect" href="/wiki/%E5%B1%B1%E4%B8%9C" title="山东">
山东
</a>
<a class="mw-redirect" href="/wiki/%E8%A1%8C%E7%9C%81" title="行省">
行省
</a>
。洪武二年三月,改为北平
<a href="/wiki/%E6%89%BF%E5%AE%A3%E5%B8%83%E6%94%BF%E4%BD%BF%E5%8F%B8" title="承宣布政使司">
承宣布政使司
</a>
驻地。燕王
<a class="mw-redirect" href="/wiki/%E6%9C%B1%E6%A3%A3" title="朱棣">
朱棣
</a>
经
<a class="mw-redirect" href="/wiki/%E9%9D%96%E9%9A%BE" title="靖难">
靖难
</a>
之变夺得皇位后,于
<a href="/wiki/%E6%B0%B8%E4%B9%90_(%E6%98%8E%E6%9C%9D)" title="永乐 (明朝)">
永乐
</a>
元年(1402年)升
<a class="mw-redirect" href="/wiki/%E7%87%95%E4%BA%AC" title="燕京">
燕京
</a>
北平为北京,暫稱“
<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">
行在
</a>
”(
<a href="/wiki/%E5%A4%A9%E5%AD%90" title="天子">
天子
</a>
行銮驻跸的所在,就称“行在”)且在北伐時常驻于此,现在的北京也从此得名。朱棣行在北京后,一改元態,北京城秩序井然,繁榮安樂。永乐十九年正月,明成祖
<a class="mw-redirect" href="/wiki/%E6%9C%B1%E6%A3%A3" title="朱棣">
朱棣
</a>
正式
<a class="mw-redirect" href="/wiki/%E6%B0%B8%E6%A8%82%E9%81%B7%E9%83%BD" title="永樂遷都">
移鼎燕京
</a>
,以燕京为
<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">
京师
</a>
,稱為「北京」。金陵应天府则作为
<a class="mw-redirect" href="/wiki/%E7%95%99%E9%83%BD" title="留都">
留都
</a>
,称
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC" title="南京">
南京
</a>
。
<a href="/wiki/%E6%98%8E%E4%BB%81%E5%AE%97" title="明仁宗">
明仁宗
</a>
及
<a href="/wiki/%E6%98%8E%E5%AE%A3%E5%AE%97" title="明宣宗">
明宣宗
</a>
的时期,因
<a href="/wiki/%E7%9A%87%E5%B8%9D" title="皇帝">
皇帝
</a>
個人的喜好因素,北京之
<a class="mw-redirect mw-disambig" href="/wiki/%E4%BA%AC%E5%B8%88" title="京师">
京师
</a>
地位一度降為
<a href="/wiki/%E5%90%9B%E4%B8%BB" title="君主">
君主
</a>
暫幸之
<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">
行在
</a>
,复稱金陵应天府為南京,
<a href="/wiki/%E6%98%8E%E8%8B%B1%E5%AE%97" title="明英宗">
明英宗
</a>
親政後,
<a href="/wiki/%E6%AD%A3%E7%BB%9F_(%E5%B9%B4%E5%8F%B7)" title="正统 (年号)">
正統
</a>
七年(1441年)時才恢復燕京京师的地位。
</p>
<p>
1626年5月30日,北京西南隅的工部王恭厂火药库发生
<a href="/wiki/%E7%8E%8B%E6%81%AD%E5%BB%A0%E5%A4%A7%E7%88%86%E7%82%B8" title="王恭廠大爆炸">
王恭厰大爆炸
</a>
,死伤2万多人
<sup class="reference" id="cite_ref-20">
<a href="#cite_note-20">
[16]
</a>
</sup>
,原因不明,朝野震惊,中外骇然,
<a href="/wiki/%E6%98%8E%E7%86%B9%E5%AE%97" title="明熹宗">
明熹宗
</a>
下了一道
<a href="/wiki/%E7%BD%AA%E5%B7%B1%E8%AF%8F" title="罪己诏">
罪己诏
</a>
,表示要痛加省醒,告诫大小臣工“务要竭虑洗心办事,痛加反省”,并下旨发府库万两黄金赈灾。1643年,北京内爆发
<a href="/wiki/%E6%98%8E%E6%9C%AB%E5%A4%A7%E9%BC%A0%E7%96%AB" title="明末大鼠疫">
明末大鼠疫
</a>
重大疫情、造成20多万人死亡,被认为是明朝灭亡的重要因素之一
<sup class="reference" id="cite_ref-:0_21-0">
<a href="#cite_note-:0-21">
[17]
</a>
</sup>
<sup class="reference" id="cite_ref-:1_22-0">
<a href="#cite_note-:1-22">
[18]
</a>
</sup>
<sup class="reference" id="cite_ref-:2_23-0">
<a href="#cite_note-:2-23">
[19]
</a>
</sup>
<sup class="reference" id="cite_ref-:3_24-0">
<a href="#cite_note-:3-24">
[20]
</a>
</sup>
。1644年4月25日,
<a href="/wiki/%E6%9D%8E%E8%87%AA%E6%88%90" title="李自成">
李自成
</a>
攻陷北京,
<a class="mw-redirect" href="/wiki/%E5%B4%87%E7%A5%AF%E5%B8%9D" title="崇祯帝">
崇祯帝
</a>
在
<a class="mw-redirect" href="/wiki/%E7%85%A4%E5%B1%B1" title="煤山">
煤山
</a>
<a class="mw-redirect" href="/wiki/%E8%87%AA%E7%B8%8A" title="自縊">
自縊
</a>
,
<a href="/wiki/%E7%94%B2%E7%94%B3%E4%B9%8B%E8%AE%8A" title="甲申之變">
明朝滅亡
</a>
。清朝
<a class="mw-redirect" href="/wiki/%E9%A0%86%E6%B2%BB%E5%B8%9D" title="順治帝">
順治帝
</a>
<a href="/wiki/%E6%98%8E%E6%B8%85%E6%88%98%E4%BA%89" title="明清战争">
入关
</a>
后即迁都北京,亦称为京师
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
,属
<a href="/wiki/%E7%9B%B4%E9%9A%B6%E7%9C%81" title="直隶省">
直隶省
</a>
。清廷在北京实行旗民分居政策,即满汉蒙
<a href="/wiki/%E5%85%AB%E6%97%97" title="八旗">
八旗
</a>
居住内城,非旗籍
<a class="mw-redirect" href="/wiki/%E6%B1%89%E4%BA%BA" title="汉人">
汉人
</a>
和
<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">
回民
</a>
居住外城。
<a class="mw-redirect" href="/wiki/%E5%85%AB%E6%97%97%E5%88%B6%E5%BA%A6" title="八旗制度">
旗人
</a>
事务由
<a class="mw-redirect" href="/wiki/%E4%B9%9D%E9%97%A8%E6%8F%90%E7%9D%A3" title="九门提督">
九門提督
</a>
管理,而
<a href="/wiki/%E6%B1%89%E6%97%8F" title="汉族">
汉族
</a>
、
<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">
回族
</a>
事务则交给
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
<a class="mw-redirect" href="/wiki/%E8%A1%99%E9%97%A8" title="衙门">
衙门
</a>
管理。
</p>
<h3>
<span id=".E8.BF.91.E4.BB.A3">
</span>
<span class="mw-headline" id="近代">
近代
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=5" title="编辑章节:近代">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
1853年8月28日,
<a class="mw-redirect" href="/wiki/%E5%A4%AA%E5%B9%B3%E5%86%9B" title="太平军">
太平军
</a>
攻克
<a href="/wiki/%E4%B8%B4%E6%B4%BA%E5%85%B3%E9%95%87" title="临洺关镇">
临洺关镇
</a>
,北京大批人口逃离,全城戒严,人心惶惶之际,物价飞腾,米珠薪桂,一片混乱。
</p>
<p>
1860年9月21日,
<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E9%B8%A6%E7%89%87%E6%88%98%E4%BA%89" title="第二次鸦片战争">
英法联军
</a>
在
<a href="/wiki/%E5%85%AB%E9%87%8C%E6%A9%8B%E4%B9%8B%E6%88%B0" title="八里橋之戰">
八里桥之战
</a>
中打败清军,随后攻破北京城,放火烧毁
<a class="mw-redirect" href="/wiki/%E5%9C%93%E6%98%8E%E5%9C%92" title="圓明園">
圆明园
</a>
,
<a href="/wiki/%E5%92%B8%E4%B8%B0%E5%B8%9D" title="咸丰帝">
咸丰帝
</a>
逃至
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">
承德
</a>
。10月至11月,清政府与英法俄在
<a href="/wiki/%E7%A4%BC%E9%83%A8" title="礼部">
礼部
</a>
衙门签订《
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%9D%A1%E7%BA%A6" title="北京条约">
北京条约
</a>
》,外国
<a href="/wiki/%E4%BD%BF%E8%8A%82" title="使节">
使节
</a>
和
<a href="/wiki/%E5%9F%BA%E7%9D%A3%E6%95%99" title="基督教">
基督教
</a>
<a href="/wiki/%E4%BC%A0%E6%95%99%E5%A3%AB" title="传教士">
传教士
</a>
得到特许允进北京,在城内各处兴建
<a href="/wiki/%E6%95%99%E5%A0%82" title="教堂">
教堂
</a>
,使馆则集中在
<a href="/wiki/%E4%B8%9C%E4%BA%A4%E6%B0%91%E5%B7%B7" title="东交民巷">
东交民巷
</a>
<sup class="reference" id="cite_ref-1860年北京条约_25-0">
<a href="#cite_note-1860年北京条约-25">
[21]
</a>
</sup>
。1888年,北京第一条
<a class="mw-redirect" href="/wiki/%E9%93%81%E8%B7%AF" title="铁路">
铁路
</a>
<a href="/wiki/%E8%A5%BF%E8%8B%91%E9%93%81%E8%B7%AF" title="西苑铁路">
西苑铁路
</a>
在
<a href="/wiki/%E4%B8%AD%E5%8D%97%E6%B5%B7" title="中南海">
中南海
</a>
建成,但该铁路并非营业性质
<sup class="reference" id="cite_ref-bj-general_26-0">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:73
</sup>
,已于1925年被拆除,此后北京的第一条营业铁路为1897年通车的
<a href="/wiki/%E6%B4%A5%E8%8A%A6%E9%93%81%E8%B7%AF" title="津芦铁路">
津芦铁路
</a>
<sup class="reference" id="cite_ref-bj-general_26-1">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:72
</sup>
。
</p>
<p>
1900年6月,
<a href="/wiki/%E4%B9%89%E5%92%8C%E5%9B%A2%E8%BF%90%E5%8A%A8" title="义和团运动">
义和团
</a>
进入北京,烧毁城内教堂,并围攻各国使馆。8月,
<a href="/wiki/%E5%85%AB%E5%9C%8B%E8%81%AF%E8%BB%8D" title="八國聯軍">
八国联军
</a>
攻占北京,解救被义和团围攻的各国公使。1901年8月,八国联军从北京撤军。9月7日,清政府同西方签订《
<a href="/wiki/%E8%BE%9B%E4%B8%91%E6%9D%A1%E7%BA%A6" title="辛丑条约">
辛丑条约
</a>
》。同年,西便门和东便门城墙上各开一铁路豁口,成为对北京城墙最早的改造
<sup class="reference" id="cite_ref-bj-general_26-2">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:72
</sup>
。1902年1月,
<a href="/wiki/%E6%85%88%E7%A6%A7%E5%A4%AA%E5%90%8E" title="慈禧太后">
慈禧太后
</a>
和
<a href="/wiki/%E5%85%89%E7%BB%AA%E5%B8%9D" title="光绪帝">
光绪帝
</a>
回到北京下
<a href="/wiki/%E7%BD%AA%E5%B7%B1%E8%AF%8F" title="罪己诏">
罪己诏
</a>
。1909年,连接北京至
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">
张家口
</a>
的
<a href="/wiki/%E4%BA%AC%E5%BC%A0%E9%93%81%E8%B7%AF" title="京张铁路">
京张铁路
</a>
在
<a href="/wiki/%E8%A9%B9%E5%A4%A9%E4%BD%91" title="詹天佑">
詹天佑
</a>
的主持下建成通车
<sup class="reference" id="cite_ref-bj-general_26-3">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:73
</sup>
。1911年3月30日,
<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6" title="清华大学">
清华大学
</a>
成立。
</p>
<link href="mw-data:TemplateStyles:r61200722/mw-parser-output/.tmulti" rel="mw-deduplicated-inline-style"/>
<div class="thumb tmulti tleft">
<div class="thumbinner" style="width:272px;max-width:272px">
<div class="trow">
<div class="tsingle" style="width:164px;max-width:164px">
<div class="thumbimage" style="height:128px;overflow:hidden">
<a class="image" href="/wiki/File:ROC_Div_City_Peiping_2.svg">
<img alt="" data-file-height="535" data-file-width="677" decoding="async" height="128" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/13/ROC_Div_City_Peiping_2.svg/162px-ROC_Div_City_Peiping_2.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/13/ROC_Div_City_Peiping_2.svg/243px-ROC_Div_City_Peiping_2.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/13/ROC_Div_City_Peiping_2.svg/324px-ROC_Div_City_Peiping_2.svg.png 2x" width="162"/>
</a>
</div>
<div class="thumbcaption text-align-center">
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
北平市
</div>
</div>
<div class="tsingle" style="width:104px;max-width:104px">
<div class="thumbimage" style="height:128px;overflow:hidden">
<a class="image" href="/wiki/File:Beijing_1948_JP.jpg">
<img alt="" data-file-height="7933" data-file-width="6293" decoding="async" height="129" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/102px-Beijing_1948_JP.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/153px-Beijing_1948_JP.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/204px-Beijing_1948_JP.jpg 2x" width="102"/>
</a>
</div>
<div class="thumbcaption text-align-center">
1940年代的北京城區
</div>
</div>
</div>
</div>
</div>
<p>
1912年1月1日,
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
在
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC" title="南京">
南京
</a>
成立,同年3月迁都北京。民国伊始,北京仍依清制称
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
,至民国三年,改为
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
京兆地方
</a>
,直辖于
<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C" title="北洋政府">
北洋政府
</a>
。这一时期,北京新建了
<a class="mw-redirect" href="/wiki/%E6%9C%89%E8%BD%A8%E7%94%B5%E8%BD%A6" title="有轨电车">
有轨电车
</a>
系统和一批现代的文化教育机构,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%9A%87%E5%9F%8E" title="北京皇城">
北京皇城
</a>
的城墙也逐步被拆除,但内外城仅被局部改造
<sup class="reference" id="cite_ref-bj-general_26-4">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:74
</sup>
。1919年北京因
<a class="mw-redirect" href="/wiki/%E5%B1%B1%E4%B8%9C%E9%97%AE%E9%A2%98" title="山东问题">
山东问题
</a>
爆发
<a href="/wiki/%E4%BA%94%E5%9B%9B%E8%BF%90%E5%8A%A8" title="五四运动">
五四运动
</a>
,学生放火燒了
<a href="/wiki/%E6%9B%B9%E6%B1%9D%E9%9C%96" title="曹汝霖">
曹汝霖
</a>
的
<a href="/wiki/%E8%B5%B5%E5%AE%B6%E6%A5%BC" title="赵家楼">
住宅
</a>
<sup class="reference" id="cite_ref-27">
<a href="#cite_note-27">
[23]
</a>
</sup>
。1920年5月7日,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E8%8B%91%E6%9C%BA%E5%9C%BA" title="北京南苑机场">
北京南苑机场
</a>
开通北京首条民用航空线路
<sup class="reference" id="cite_ref-bj-general_26-5">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:74
</sup>
。1928年
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BC%90%E6%88%98%E4%BA%89" title="北伐战争">
北伐战争
</a>
后,
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E9%A6%96%E9%83%BD" title="中華民國首都">
中華民國首都
</a>
迁回南京,京兆地方改名为
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">
北平特别市
</a>
。1930年6月,北平降格为
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="河北省 (中華民國)">
河北省
</a>
省辖市,同年12月复升为
<a class="mw-redirect" href="/wiki/%E9%99%A2%E8%BE%96%E5%B8%82" title="院辖市">
院辖市
</a>
。这一时期,北京尽管不具
<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">
首都
</a>
的地位,但在
<a href="/wiki/%E6%95%99%E8%82%B2" title="教育">
教育
</a>
方面仍有关键的优势,被国际人士称为“中国的
<a href="/wiki/%E6%B3%A2%E5%A3%AB%E9%A1%BF" title="波士顿">
波士顿
</a>
”。1937年
<a class="mw-redirect" href="/wiki/%E4%B8%83%C2%B7%E4%B8%83%E4%BA%8B%E5%8F%98" title="七·七事变">
七·七事变
</a>
后,北平被
<a class="mw-redirect" href="/wiki/%E6%97%A5%E8%BB%8D" title="日軍">
日軍
</a>
占领,将北平改名为北京
<sup class="reference" id="cite_ref-28">
<a href="#cite_note-28">
[24]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:40
</sup>
。1945年
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E6%97%A5%E6%9C%AC%E5%B8%9D%E5%9C%8B" title="大日本帝國">
日本
</a>
宣布向
<a href="/wiki/%E5%90%8C%E7%9B%9F%E5%9C%8B_(%E7%AC%AC%E4%BA%8C%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%B0)" title="同盟國 (第二次世界大戰)">
同盟国
</a>
投降,
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%8A%97%E6%97%A5%E6%88%98%E4%BA%89" title="中国抗日战争">
中国抗日战争
</a>
结束。同年8月21日第十一战区
<a class="mw-redirect" href="/wiki/%E5%AD%99%E8%BF%9E%E4%BB%B2" title="孙连仲">
孙连仲
</a>
部接收北京,并更名北平。
</p>
<div class="thumb tleft">
<div class="thumbinner" style="width:152px;">
<a class="image" href="/wiki/File:Jinianbei.jpg">
<img alt="" class="thumbimage" data-file-height="1200" data-file-width="800" decoding="async" height="225" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/30/Jinianbei.jpg/150px-Jinianbei.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/30/Jinianbei.jpg/225px-Jinianbei.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/30/Jinianbei.jpg/300px-Jinianbei.jpg 2x" width="150"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Jinianbei.jpg" title="放大">
</a>
</div>
<a href="/wiki/%E4%BA%BA%E6%B0%91%E8%8B%B1%E9%9B%84%E7%BA%AA%E5%BF%B5%E7%A2%91" title="人民英雄纪念碑">
人民英雄纪念碑
</a>
,为纪念中国近现代史上的牺牲的人民英雄而建。
</div>
</div>
</div>
<p>
1949年1月31日,
<a href="/wiki/%E5%82%85%E4%BD%9C%E4%B9%89" title="傅作义">
傅作义
</a>
与
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A" title="中国共产党">
中国共产党
</a>
达成和平协议,率
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E5%9C%8B%E8%BB%8D" title="中華民國國軍">
中華民國國軍
</a>
25万人改投中共,
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%92%8C%E5%B9%B3%E8%A7%A3%E6%94%BE" title="北平和平解放">
北平和平解放
</a>
<sup class="reference" id="cite_ref-29">
<a href="#cite_note-29">
[25]
</a>
</sup>
。同年9月27日
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE" title="中国人民政治协商会议">
中国人民政治协商会议
</a>
第一届全体会议通过《
<a href="/wiki/%E5%85%B3%E4%BA%8E%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E9%83%BD%E3%80%81%E7%BA%AA%E5%B9%B4%E3%80%81%E5%9B%BD%E6%AD%8C%E3%80%81%E5%9B%BD%E6%97%97%E7%9A%84%E5%86%B3%E8%AE%AE" title="关于中华人民共和国国都、纪年、国歌、国旗的决议">
决议
</a>
》,将
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
的国都定于北平,復名为北京。1949年10月1日,
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C_(1949%E2%80%931954)" title="中华人民共和国中央人民政府 (1949–1954)">
中央人民政府
</a>
在北京
<a class="mw-redirect" href="/wiki/%E5%BC%80%E5%9B%BD%E5%A4%A7%E5%85%B8" title="开国大典">
宣告成立
</a>
。此后,天安门广场上举行过多次
<a href="/wiki/%E9%98%85%E5%85%B5" title="阅兵">
阅兵
</a>
<sup class="reference" id="cite_ref-30">
<a href="#cite_note-30">
[26]
</a>
</sup>
。1949年11月21日,北京市封闭了全市的所有妓院
<sup class="reference" id="cite_ref-bj-general_26-6">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:83
</sup>
。1950年2月,建筑学家
<a href="/wiki/%E6%A2%81%E6%80%9D%E6%88%90" title="梁思成">
梁思成
</a>
和
<a href="/wiki/%E9%99%88%E5%8D%A0%E7%A5%A5" title="陈占祥">
陈占祥
</a>
联手提出《
<a href="/wiki/%E6%A2%81%E9%99%88%E6%96%B9%E6%A1%88" title="梁陈方案">
关于中央人民政府行政中心区位置的建议
</a>
》,建议在
<a href="/wiki/%E5%85%AC%E4%B8%BB%E5%9D%9F" title="公主坟">
公主坟
</a>
以东、
<a href="/wiki/%E6%9C%88%E5%9D%9B" title="月坛">
月坛
</a>
以西的适中地点(即
<a href="/wiki/%E4%B8%89%E9%87%8C%E6%B2%B3_(%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A5%BF%E5%9F%8E%E5%8C%BA)" title="三里河 (北京市西城区)">
三里河
</a>
一带)建设首都行政中心区域
<sup class="reference" id="cite_ref-31">
<a href="#cite_note-31">
[27]
</a>
</sup>
,但最终北京市采纳的是朱兆雪、赵冬日“以天安门为中心逐步扩建、改建”的意见,导致城墙于1953年至60年代被逐步拆除
<sup class="reference" id="cite_ref-32">
<a href="#cite_note-32">
[28]
</a>
</sup>
。
</p>
<h3>
<span id=".E6.96.87.E5.8C.96.E5.A4.A7.E9.9D.A9.E5.91.BD.E6.9C.9F.E9.97.B4">
</span>
<span class="mw-headline" id="文化大革命期间">
文化大革命期间
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=6" title="编辑章节:文化大革命期间">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a href="/wiki/%E7%BA%A2%E5%85%AB%E6%9C%88" title="红八月">
红八月
</a>
、
<a href="/wiki/%E5%A4%A7%E5%85%B4%E4%BA%8B%E4%BB%B6" title="大兴事件">
大兴事件
</a>
、
<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6%E7%99%BE%E6%97%A5%E5%A4%A7%E6%AD%A6%E6%96%97" title="清华大学百日大武斗">
清华大学百日大武斗
</a>
和
<a href="/wiki/%E6%96%87%E5%8C%96%E5%A4%A7%E9%9D%A9%E5%91%BD" title="文化大革命">
文化大革命
</a>
</div>
<p>
1966年8月18日,
<a href="/wiki/%E6%AF%9B%E6%B3%BD%E4%B8%9C" title="毛泽东">
毛泽东
</a>
在
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%9F%8E%E6%A5%BC" title="天安门城楼">
天安门城楼
</a>
上接见了红卫兵代表
<a href="/wiki/%E5%AE%8B%E5%BD%AC%E5%BD%AC" title="宋彬彬">
宋彬彬
</a>
,红卫兵受到鼓舞,“
<a class="new" href="/w/index.php?title=%E9%A6%96%E9%83%BD%E7%BA%A2%E5%8D%AB%E5%85%B5%E7%BA%A0%E5%AF%9F%E9%98%9F%E8%A5%BF%E5%9F%8E%E5%88%86%E9%98%9F&action=edit&redlink=1" title="首都红卫兵纠察队西城分队(页面不存在)">
西纠
</a>
”等红卫兵组织相继成立,
<a href="/wiki/%E7%BA%A2%E5%85%AB%E6%9C%88" title="红八月">
北京的文革屠杀
</a>
逐渐展开
<sup class="reference" id="cite_ref-:0_21-1">
<a href="#cite_note-:0-21">
[17]
</a>
</sup>
<sup class="reference" id="cite_ref-:12_33-0">
<a href="#cite_note-:12-33">
[29]
</a>
</sup>
<sup class="reference" id="cite_ref-:15_34-0">
<a href="#cite_note-:15-34">
[30]
</a>
</sup>
<sup class="reference" id="cite_ref-:14_35-0">
<a href="#cite_note-:14-35">
[31]
</a>
</sup>
<sup class="reference" id="cite_ref-36">
<a href="#cite_note-36">
[32]
</a>
</sup>
<sup class="reference" id="cite_ref-37">
<a href="#cite_note-37">
[33]
</a>
</sup>
<sup class="reference" id="cite_ref-38">
<a href="#cite_note-38">
[34]
</a>
</sup>
。据1980年官方数据,在1966年8-9月间,在北京市有1772人被
<a href="/wiki/%E7%BA%A2%E5%8D%AB%E5%85%B5" title="红卫兵">
红卫兵
</a>
打死,其中包括很多学校的老师和校长,另有至少33695户被抄家、85196个家庭被驱逐出北京
<sup class="reference" id="cite_ref-:0_21-2">
<a href="#cite_note-:0-21">
[17]
</a>
</sup>
<sup class="reference" id="cite_ref-:15_34-1">
<a href="#cite_note-:15-34">
[30]
</a>
</sup>
<sup class="reference" id="cite_ref-:31_39-0">
<a href="#cite_note-:31-39">
[35]
</a>
</sup>
<sup class="reference" id="cite_ref-:17_40-0">
<a href="#cite_note-:17-40">
[36]
</a>
</sup>
<sup class="reference" id="cite_ref-:2_23-1">
<a href="#cite_note-:2-23">
[19]
</a>
</sup>
<sup class="reference" id="cite_ref-:7_41-0">
<a href="#cite_note-:7-41">
[37]
</a>
</sup>
;此外,受到北京市区红卫兵杀戮的影响,北京
<a class="mw-disambig" href="/wiki/%E5%A4%A7%E5%85%B4%E5%8E%BF" title="大兴县">
大兴县
</a>
从8月27日至9月1日爆发了“
<a href="/wiki/%E5%A4%A7%E5%85%B4%E4%BA%8B%E4%BB%B6" title="大兴事件">
大兴事件
</a>
”,数天内先后有325人遭屠杀,最大的80岁,最小的才38天,有22户人家被杀绝
<sup class="reference" id="cite_ref-:1_22-1">
<a href="#cite_note-:1-22">
[18]
</a>
</sup>
<sup class="reference" id="cite_ref-:20_42-0">
<a href="#cite_note-:20-42">
[38]
</a>
</sup>
<sup class="reference" id="cite_ref-:21_43-0">
<a href="#cite_note-:21-43">
[39]
</a>
</sup>
。亦有学者指出,1985年官方统计显示,北京屠杀实际死亡人数上万
<sup class="reference" id="cite_ref-:8_44-0">
<a href="#cite_note-:8-44">
[40]
</a>
</sup>
。此后北京市仍有多起
<a href="/wiki/%E6%AD%A6%E6%96%97" title="武斗">
武斗
</a>
事件发生,如1968年的
<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%A4%A7%E5%AD%A6%E7%99%BE%E6%97%A5%E5%A4%A7%E6%AD%A6%E6%96%97" title="清华大学百日大武斗">
清华大学百日大武斗
</a>
,城市建设也处于极度混乱之中,城市规划更无法正常编制
<sup class="reference" id="cite_ref-bj-general_26-7">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:95
</sup>
。
</p>
<p>
1969年10月1日,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E4%B8%80%E6%9C%9F%E5%B7%A5%E7%A8%8B" title="北京地铁一期工程">
北京地铁一期工程
</a>
通车。1976年1月8日,国务院总理
<a href="/wiki/%E5%91%A8%E6%81%A9%E6%9D%A5" title="周恩来">
周恩来
</a>
<a href="/wiki/%E5%91%A8%E6%81%A9%E6%9D%A5%E4%B9%8B%E6%AD%BB" title="周恩来之死">
病逝于
</a>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E8%A7%A3%E6%94%BE%E5%86%9B%E7%AC%AC%E4%B8%89%E3%80%87%E4%BA%94%E5%8C%BB%E9%99%A2" title="中国人民解放军第三〇五医院">
中国人民解放军第三〇五医院
</a>
,此后由于民众对
<a href="/wiki/%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="四人帮">
四人帮
</a>
的不满情绪,
<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">
四五运动
</a>
在北京爆发。9月9日,毛泽东在中南海
<a href="/wiki/%E6%AF%9B%E6%B3%BD%E4%B8%9C%E4%B9%8B%E6%AD%BB" title="毛泽东之死">
病逝
</a>
,一个月后发生
<a href="/wiki/%E7%B2%89%E7%A2%8E%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="粉碎四人帮">
怀仁堂政变
</a>
,“四人帮”被捕。
</p>
<h3>
<span id=".E7.8E.B0.E5.BD.93.E4.BB.A3">
</span>
<span class="mw-headline" id="现当代">
现当代
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=7" title="编辑章节:现当代">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
文化大革命结束后,北京市的
<a href="/wiki/%E6%94%B9%E9%9D%A9%E5%BC%80%E6%94%BE" title="改革开放">
改革开放
</a>
首先从京郊农村改革开始,1984年北京市农村种植业已有97%的生产队实现
<a href="/wiki/%E5%AE%B6%E5%BA%AD%E8%81%94%E4%BA%A7%E6%89%BF%E5%8C%85%E8%B4%A3%E4%BB%BB%E5%88%B6" title="家庭联产承包责任制">
家庭联产承包责任制
</a>
<sup class="reference" id="cite_ref-bj-general_26-8">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:115
</sup>
。
</p>
<p>
1982年7月22日,北京市编制《北京城市建设总体规划方案》,该方案明确北京市的性质为“全国的政治中心和文化中心”,1983年获批
<sup class="reference" id="cite_ref-bj-general_26-9">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:133
</sup>
,此后北京市的城市建设迅速发展,一改此前“重生产、轻生活”的思维。
</p>
<p>
1987年,北京市提出“打通两厢,缓解中央”,开始大规模建设城市道路
<sup class="reference" id="cite_ref-bj-general_26-10">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:141
</sup>
。次年,北京市新技术产业开发试验区在
<a href="/wiki/%E4%B8%AD%E5%85%B3%E6%9D%91" title="中关村">
中关村
</a>
成立
<sup class="reference" id="cite_ref-bj-general_26-11">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:144
</sup>
。
</p>
<p>
1989年爆发
<a class="mw-redirect" href="/wiki/%E5%85%AD%E5%9B%9B%E5%A4%A9%E5%AE%89%E9%97%A8%E4%BA%8B%E4%BB%B6" title="六四天安门事件">
六四天安门事件
</a>
,学生自该年4月
<a href="/wiki/%E8%83%A1%E8%80%80%E9%82%A6%E4%B9%8B%E6%AD%BB" title="胡耀邦之死">
胡耀邦逝世
</a>
后占领
<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%B9%BF%E5%9C%BA" title="天安门广场">
天安门广场
</a>
长达51天,6月4日被执政党中国共产党派遣军队出动坦克等作战武器,武力镇压
<sup class="reference" id="cite_ref-趙紫陽_45-0">
<a href="#cite_note-趙紫陽-45">
[41]
</a>
</sup>
,此事件造成多人伤亡,从1989年5月20日起在北京市部分地区实行的戒严直至1990年1月11日才正式解除。
</p>
<p>
1990年,北京市成功举办
<a href="/wiki/1990%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1990年亚洲运动会">
第11届
</a>
<a href="/wiki/%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲运动会">
亚洲运动会
</a>
,1991年开始
<a href="/wiki/2000%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E7%94%B3%E5%8A%9E%E8%BF%87%E7%A8%8B" title="2000年夏季奥林匹克运动会申办过程">
着手申办
</a>
<a href="/wiki/2000%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2000年夏季奥林匹克运动会">
2000年夏季奥林匹克运动会
</a>
<sup class="reference" id="cite_ref-bj-general_26-12">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:547
</sup>
,但1993年9月以两票之差不敌悉尼。1992年7月10日,当时处于规划阶段的亦庄工业区更名为
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%BB%8F%E6%B5%8E%E6%8A%80%E6%9C%AF%E5%BC%80%E5%8F%91%E5%8C%BA" title="北京经济技术开发区">
北京经济技术开发区
</a>
<sup class="reference" id="cite_ref-bj-general_26-13">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:552
</sup>
。
</p>
<p>
1993年10月,《北京城市总体规划(1991-2010年)》获国务院批准
<sup class="reference" id="cite_ref-bj-general_26-14">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:136
</sup>
。
</p>
<p>
1994年9月,北京市举办了
<a class="new" href="/w/index.php?title=1994%E5%B9%B4%E8%BF%9C%E4%B8%9C%E5%8F%8A%E5%8D%97%E5%A4%AA%E5%B9%B3%E6%B4%8B%E6%AE%8B%E7%96%BE%E4%BA%BA%E8%BF%90%E5%8A%A8%E4%BC%9A&action=edit&redlink=1" title="1994年远东及南太平洋残疾人运动会(页面不存在)">
第6届
</a>
<a href="/wiki/%E8%BF%9C%E4%B8%9C%E5%8F%8A%E5%8D%97%E5%A4%AA%E5%B9%B3%E6%B4%8B%E6%AE%8B%E7%96%BE%E4%BA%BA%E8%BF%90%E5%8A%A8%E4%BC%9A" title="远东及南太平洋残疾人运动会">
远东及南太平洋残疾人运动会
</a>
。
</p>
<p>
1995年,北京又承办了联合国
<a href="/wiki/%E7%AC%AC%E5%9B%9B%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A6%87%E5%A5%B3%E5%A4%A7%E4%BC%9A" title="第四次世界妇女大会">
第四次世界妇女大会
</a>
,通过《北京宣言》和《行动纲领》,同年北京市开始实行每周五天工作制
<sup class="reference" id="cite_ref-bj-general_26-15">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:566
</sup>
。
</p>
<p>
1996年1月21日,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">
北京西站
</a>
开通运营,北京市电话号码同年5月8日由七位升至八位
<sup class="reference" id="cite_ref-bj-general_26-16">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:573
</sup>
。
</p>
<p>
1997年,北京市先后开通首条
<a href="/wiki/%E5%85%AC%E8%BB%8A%E5%B0%88%E7%94%A8%E9%81%93" title="公車專用道">
公交专用车道
</a>
<sup class="reference" id="cite_ref-bj-general_26-17">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:579
</sup>
和
<a href="/wiki/%E7%A9%BA%E8%AA%BF%E5%B7%B4%E5%A3%AB" title="空調巴士">
空調巴士
</a>
线路
<sup class="reference" id="cite_ref-bj-general_26-18">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:580
</sup>
。
</p>
<p>
1998年11月25日,北京市正式启动
<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季奥林匹克运动会">
2008年夏季奥林匹克运动会
</a>
的
<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E7%94%B3%E5%8A%9E%E8%BF%87%E7%A8%8B" title="2008年夏季奥林匹克运动会申办过程">
申办工作
</a>
<sup class="reference" id="cite_ref-46">
<a href="#cite_note-46">
[42]
</a>
</sup>
。
</p>
<p>
1999年6月,建筑界名家
<a href="/wiki/%E8%B4%9D%E8%81%BF%E9%93%AD" title="贝聿铭">
贝聿铭
</a>
与
<a href="/wiki/%E5%90%B3%E8%89%AF%E9%8F%9E" title="吳良鏞">
吳良鏞
</a>
、
<a href="/wiki/%E5%91%A8%E5%B9%B2%E5%B3%99" title="周干峙">
周干峙
</a>
、
<a href="/wiki/%E5%BC%A0%E5%BC%80%E6%B5%8E" title="张开济">
张开济
</a>
、
<a href="/wiki/%E5%8D%8E%E6%8F%BD%E6%B4%AA" title="华揽洪">
华揽洪
</a>
、
<a href="/wiki/%E9%83%91%E5%AD%9D%E7%87%AE" title="郑孝燮">
郑孝燮
</a>
、
<a href="/wiki/%E7%BD%97%E5%93%B2%E6%96%87" title="罗哲文">
罗哲文
</a>
、
<a href="/wiki/%E9%98%AE%E4%BB%AA%E4%B8%89" title="阮仪三">
阮仪三
</a>
联名向
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">
北京市政府
</a>
提交意见书《在急速发展中要审慎地保护北京历史文化名城》,指出应该顺应历史文化名城保护与发展的客观规律,对北京旧城进行积极的、慎重的保护与改善,而不是“加速改造”,建议编订具有法律效力的完整的《北京历史文化名城保护规划》
<sup class="reference" id="cite_ref-47">
<a href="#cite_note-47">
[43]
</a>
</sup>
,同年中关村科技园区管理委员会正式成立,
<a href="/wiki/%E5%B9%B3%E5%AE%89%E5%A4%A7%E8%A1%97" title="平安大街">
平安大街
</a>
和
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E5%A4%8D%E5%85%AB%E7%BA%BF" title="北京地铁复八线">
北京地铁复八线
</a>
等重大基础设施也正式完工
<sup class="reference" id="cite_ref-bj-general_26-19">
<a href="#cite_note-bj-general-26">
[22]
</a>
</sup>
<sup class="reference" style="white-space:nowrap;">
:592
</sup>
。
</p>
<p>
2001年,北京市赢得
<a class="mw-redirect" href="/wiki/%E7%AC%AC29%E5%B1%8A%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="第29届奥林匹克运动会">
第29届奥林匹克运动会
</a>
主办权,同年举办了
<a href="/wiki/2001%E5%B9%B4%E5%A4%8F%E5%AD%A3%E4%B8%96%E7%95%8C%E5%A4%A7%E5%AD%B8%E9%81%8B%E5%8B%95%E6%9C%83" title="2001年夏季世界大學運動會">
第21届世界大学生运动会
</a>
,第29届奥运会和
<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E6%AE%8B%E7%96%BE%E4%BA%BA%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季残疾人奥林匹克运动会">
第13届残奥会
</a>
则分别于2008年8月和9月成功举办。
</p>
<p>
2012年7月21日,北京发生
<a href="/wiki/2012%E5%B9%B4%E5%8C%97%E4%BA%AC%E7%89%B9%E5%A4%A7%E6%9A%B4%E9%9B%A8" title="2012年北京特大暴雨">
特大暴雨
</a>
,79人死亡
<sup class="reference" id="cite_ref-灾情通报2_48-0">
<a href="#cite_note-灾情通报2-48">
[44]
</a>
</sup>
<sup class="reference" id="cite_ref-人民网20120806_49-0">
<a href="#cite_note-人民网20120806-49">
[45]
</a>
</sup>
<sup class="reference" id="cite_ref-50">
<a href="#cite_note-50">
[46]
</a>
</sup>
。
</p>
<p>
2014年,北京市被中央政府增加了“科技创新中心”的城市战略定位
<sup class="reference" id="cite_ref-51">
<a href="#cite_note-51">
[47]
</a>
</sup>
,
<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%86%80%E5%8D%8F%E5%90%8C%E5%8F%91%E5%B1%95" title="京津冀协同发展">
京津冀协同发展
</a>
也被提升至国家战略层面
<sup class="reference" id="cite_ref-52">
<a href="#cite_note-52">
[48]
</a>
</sup>
。该年11月10日至11日,北京市举行
<a href="/wiki/2014%E5%B9%B4%E4%B8%AD%E5%9B%BDAPEC%E5%B3%B0%E4%BC%9A" title="2014年中国APEC峰会">
APEC峰会
</a>
。2015年至2016年,北京发生
<a href="/wiki/2015%E5%B9%B4%E8%87%B32016%E5%B9%B4%E5%86%AC%E4%B8%AD%E5%9B%BD%E5%8C%97%E4%BA%AC%E9%9B%BE%E9%9C%BE%E4%BA%8B%E4%BB%B6" title="2015年至2016年冬中国北京雾霾事件">
严重的空气污染
</a>
<sup class="reference" id="cite_ref-:25_53-0">
<a href="#cite_note-:25-53">
[49]
</a>
</sup>
<sup class="reference" id="cite_ref-:13_54-0">
<a href="#cite_note-:13-54">
[50]
</a>
</sup>
<sup class="reference" id="cite_ref-:5_55-0">
<a href="#cite_note-:5-55">
[51]
</a>
</sup>
。
</p>
<p>
2015年,北京市获得
<a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季奥林匹克运动会">
2022年冬季奥林匹克运动会
</a>
主办权
<sup class="reference" id="cite_ref-56">
<a href="#cite_note-56">
[52]
</a>
</sup>
,将成为全球第一个既举办过夏季奥运会,又举办过冬季奥运会的城市。
</p>
<p>
2016年,国务院印发《北京加强全国科技创新中心建设总体方案》。
</p>
<p>
2017年9月,《北京城市总体规划(2016年—2035年)》获批,将北京市定位为全国政治中心、文化中心、国际交往中心、科技创新中心,同时指出“老城不能再拆”
<sup class="reference" id="cite_ref-57">
<a href="#cite_note-57">
[53]
</a>
</sup>
。11月18日,北京
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">
大兴区
</a>
<a href="/wiki/%E8%A5%BF%E7%BA%A2%E9%97%A8%E5%9C%B0%E5%8C%BA" title="西红门地区">
西红门镇
</a>
新建庄二村新康东路8号聚福缘公寓发生一场
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E2%80%9C11%C2%B718%E2%80%9D%E7%81%AB%E7%81%BE" title="北京大兴“11·18”火灾">
重大火灾
</a>
,19人遇难
<sup class="reference" id="cite_ref-58">
<a href="#cite_note-58">
[54]
</a>
</sup>
,此后北京市政府展开颇具争议的
<a class="mw-redirect" href="/wiki/2017%E5%B9%B4%E5%8C%97%E4%BA%AC%E5%AE%89%E5%85%A8%E9%9A%90%E6%82%A3%E6%8E%92%E6%9F%A5%E6%95%B4%E6%94%B9%E6%B4%BB%E5%8A%A8" title="2017年北京安全隐患排查整改活动">
安全隐患排查整改活动
</a>
<sup class="reference" id="cite_ref-59">
<a href="#cite_note-59">
[55]
</a>
</sup>
。
</p>
<p>
2019年1月11日,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">
北京市人民政府
</a>
正式迁至通州区
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83" title="北京城市副中心">
北京城市副中心
</a>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83%E8%A1%8C%E6%94%BF%E5%8A%9E%E5%85%AC%E5%8C%BA" title="北京城市副中心行政办公区">
行政办公区
</a>
<sup class="reference" id="cite_ref-60">
<a href="#cite_note-60">
[56]
</a>
</sup>
。
</p>
<p>
2020年1月12日,
<a href="/wiki/%E9%A6%96%E9%83%BD%E5%8C%BB%E7%A7%91%E5%A4%A7%E5%AD%A6%E9%99%84%E5%B1%9E%E5%8C%97%E4%BA%AC%E5%9C%B0%E5%9D%9B%E5%8C%BB%E9%99%A2" title="首都医科大学附属北京地坛医院">
首都医科大学附属北京地坛医院
</a>
收治两名
<a href="/wiki/2019%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85" title="2019冠状病毒病">
2019冠状病毒病
</a>
疑似患者,2019冠状病毒病疫情
<a href="/wiki/2019%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85%E5%8C%97%E4%BA%AC%E5%B8%82%E7%96%AB%E6%83%85" title="2019冠状病毒病北京市疫情">
在北京爆发
</a>
<sup class="reference" id="cite_ref-61">
<a href="#cite_note-61">
[57]
</a>
</sup>
,北京市也于该年1月24日启动重大突发公共卫生事件一级响应
<sup class="reference" id="cite_ref-62">
<a href="#cite_note-62">
[58]
</a>
</sup>
,此后随着疫情缓和,北京市于4月30日将重大突发公共卫生事件应急响应级别下调至二级响应
<sup class="reference" id="cite_ref-63">
<a href="#cite_note-63">
[59]
</a>
</sup>
,6月6日更一度下调至三级响应
<sup class="reference" id="cite_ref-64">
<a href="#cite_note-64">
[60]
</a>
</sup>
,本地确诊病例也于6月8日暂时清零
<sup class="reference" id="cite_ref-chinanews20200609_65-0">
<a href="#cite_note-chinanews20200609-65">
[61]
</a>
</sup>
,但6月11日爆发的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%96%B0%E5%8F%91%E5%9C%B0%E5%86%9C%E4%BA%A7%E5%93%81%E6%89%B9%E5%8F%91%E5%B8%82%E5%9C%BA" title="北京新发地农产品批发市场">
北京新发地农产品批发市场
</a>
<a href="/wiki/2020%E5%B9%B4%E5%8C%97%E4%BA%AC%E6%96%B0%E5%8F%91%E5%9C%B0%E5%86%9C%E4%BA%A7%E5%93%81%E6%89%B9%E5%8F%91%E5%B8%82%E5%9C%BA%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85%E8%81%9A%E9%9B%86%E6%80%A7%E7%96%AB%E6%83%85" title="2020年北京新发地农产品批发市场冠状病毒病聚集性疫情">
聚集性疫情
</a>
使得北京市再次进入二级响应状态,相关确诊病例至7月6日已累计335例,此后未有增长,7月20日北京市将应急响应机制再次下调至三级
<sup class="reference" id="cite_ref-66">
<a href="#cite_note-66">
[62]
</a>
</sup>
,此后北京市仍保持疫情防控常态化状态。8月27日,国务院批复了涉及东城、西城两区的《首都功能核心区控制性详细规划(街区层面)(2018年-2035年)》
<sup class="reference" id="cite_ref-67">
<a href="#cite_note-67">
[63]
</a>
</sup>
。
</p>
<h2>
<span id=".E5.9C.B0.E7.90.86">
</span>
<span class="mw-headline" id="地理">
地理
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=8" title="编辑章节:地理">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E7%90%86" title="北京地理">
北京地理
</a>
</div>
<div class="thumb tright">
<div class="thumbinner" style="width:252px;">
<a class="image" href="/wiki/File:Beijing_satellite_image,_LandSat-5,_2010-08-08.jpg">
<img alt="" class="thumbimage" data-file-height="2479" data-file-width="2566" decoding="async" height="242" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/42/Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg/250px-Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/42/Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg/375px-Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/42/Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg/500px-Beijing_satellite_image%2C_LandSat-5%2C_2010-08-08.jpg 2x" width="250"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Beijing_satellite_image,_LandSat-5,_2010-08-08.jpg" title="放大">
</a>
</div>
北京卫星照片,拍摄于2010年8月。
</div>
</div>
</div>
<p>
北京市位于
<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%B9%B3%E5%8E%9F" title="华北平原">
华北平原
</a>
的西北边缘,背靠
<a href="/wiki/%E5%A4%AA%E8%A1%8C%E5%B1%B1" title="太行山">
太行山
</a>
余脉和
<a href="/wiki/%E7%87%95%E5%B1%B1" title="燕山">
燕山
</a>
山脉,面对辽阔的
<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%B9%B3%E5%8E%9F" title="华北平原">
华北平原
</a>
,东南距
<a href="/wiki/%E6%B8%A4%E6%B5%B7" title="渤海">
渤海
</a>
約150公里。市域东西宽约160公里,南北长约176公里,土地面积16411平方公里,其中平原面积6338平方公里,占38.6%;山区面积10072平方公里,占61.4%
<sup class="reference" id="cite_ref-68">
<a href="#cite_note-68">
[64]
</a>
</sup>
。北京地势总体上上西北高,东南低。全市地貌由西北山地和东南平原两大地貌单元组成。北京市平均
<a href="/wiki/%E6%B5%B7%E6%8B%94" title="海拔">
海拔
</a>
高度43.5米
<sup class="reference" id="cite_ref-69">
<a href="#cite_note-69">
[65]
</a>
</sup>
,其中平原的海拔高度在20~60米,而山地一般海拔1000~1500米,全市最高峰为位于
<a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">
门头沟区
</a>
西北部的东灵山,海拔2303米
<sup class="reference" id="cite_ref-70">
<a href="#cite_note-70">
[66]
</a>
</sup>
。北京沒有天然湖泊,天然河道自西向东有
<a href="/wiki/%E6%8B%92%E9%A9%AC%E6%B2%B3" title="拒马河">
拒马河
</a>
、
<a href="/wiki/%E6%B0%B8%E5%AE%9A%E6%B2%B3" title="永定河">
永定河
</a>
、
<a href="/wiki/%E5%8C%97%E8%BF%90%E6%B2%B3" title="北运河">
北运河
</a>
、
<a href="/wiki/%E6%BD%AE%E7%99%BD%E6%B2%B3" title="潮白河">
潮白河
</a>
、蓟运河五大
<a href="/wiki/%E6%B0%B4%E7%B3%BB" title="水系">
水系
</a>
,均屬
<a href="/wiki/%E6%B5%B7%E6%B2%B3" title="海河">
海河
</a>
流域
<sup class="reference" id="cite_ref-71">
<a href="#cite_note-71">
[67]
</a>
</sup>
。
</p>
<h3>
<span id=".E6.B0.A3.E5.80.99">
</span>
<span class="mw-headline" id="氣候">
氣候
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=9" title="编辑章节:氣候">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
北京市地处
<a class="mw-redirect" href="/wiki/%E6%9A%96%E6%B8%A9%E5%B8%A6" title="暖温带">
暖温带
</a>
<a class="new" href="/w/index.php?title=%E5%8D%8A%E6%BF%95%E6%BD%A4%E5%9C%B0%E5%8C%BA&action=edit&redlink=1" title="半濕潤地区(页面不存在)">
半濕潤地区
</a>
,
<a class="mw-redirect" href="/wiki/%E6%B0%94%E5%80%99" title="气候">
气候
</a>
属于
<a href="/wiki/%E6%B8%A9%E5%B8%A6%E5%AD%A3%E9%A3%8E%E6%B0%94%E5%80%99" title="温带季风气候">
暖温带半湿润大陆性季风气候
</a>
,
<sup class="reference" id="cite_ref-72">
<a href="#cite_note-72">
[68]
</a>
</sup>
平原地区平均年降水量约600毫米,市区代表站最大年降水量为1404.6毫米,最大24小时降水量为404.2毫米,平均年最大积雪深度为7.5厘米,历史最大积雪深度33.5厘米。北京四季分明,
<a href="/wiki/%E6%98%A5%E5%AD%A3" title="春季">
春季
</a>
多風和沙尘,
<a href="/wiki/%E5%A4%8F%E5%AD%A3" title="夏季">
夏季
</a>
炎熱多雨,
<a href="/wiki/%E7%A7%8B%E5%AD%A3" title="秋季">
秋季
</a>
晴朗干燥,
<a href="/wiki/%E5%86%AC%E5%AD%A3" title="冬季">
冬季
</a>
寒冷且大风猛烈。其中春季和秋季很短,大概一个月出头左右;而夏季和冬季则很长,各接近五个月。北京季风性特征明显,全年60%的降水集中在夏季的7、8月份,而其他季节空气较为干燥。年平均气温約為12.9 °C。最冷月(1月)平均气温为−3.1 °C,最热月(7月)平均气温为26.7 °C。极端最低气温为−33.2 °C(1980年1月30日佛爷顶),极端最高气温43.5 °C(1961年6月10日房山区)。市区极端最低气温为−27.4 °C(1966年2月22日),市区极端最高气温41.9 °C(1999年7月24日)。
</p>
<p>
<br/>
</p>
<table class="wikitable collapsible" style="width:90%; text-align:center; font-size:90%; line-height: 1.2em; margin:auto;">
<tbody>
<tr>
<th colspan="14">
北京市(平均数据1986-2015年,极端数据1951-2017年)气候平均数据
</th>
</tr>
<tr>
<th>
月份
</th>
<th>
1月
</th>
<th>
2月
</th>
<th>
3月
</th>
<th>
4月
</th>
<th>
5月
</th>
<th>
6月
</th>
<th>
7月
</th>
<th>
8月
</th>
<th>
9月
</th>
<th>
10月
</th>
<th>
11月
</th>
<th>
12月
</th>
<th style="border-left-width:medium">
全年
</th>
</tr>
<tr>
<th height="16">
历史最高温℃(℉)
</th>
<td style="background:#FFBB77;color:#000000;text-align:center;">
14.3
<br/>
(57.7)
</td>
<td style="background:#FF952C;color:#000000;text-align:center;">
19.8
<br/>
(67.6)
</td>
<td style="background:#FF5200;color:#000000;text-align:center;">
29.5
<br/>
(85.1)
</td>
<td style="background:#FF3700;color:#000000;text-align:center;">
33.5
<br/>
(92.3)
</td>
<td style="background:#FF0200;color:#FFFFFF;text-align:center;">
41.1
<br/>
(106)
</td>
<td style="background:#FF0600;color:#FFFFFF;text-align:center;">
40.6
<br/>
(105.1)
</td>
<td style="background:#F90000;color:#FFFFFF;text-align:center;">
41.9
<br/>
(107.4)
</td>
<td style="background:#FF1600;color:#FFFFFF;text-align:center;">
38.3
<br/>
(100.9)
</td>
<td style="background:#FF2C00;color:#000000;text-align:center;">
35.0
<br/>
(95)
</td>
<td style="background:#FF4800;color:#000000;text-align:center;">
31.0
<br/>
(87.8)
</td>
<td style="background:#FF7D00;color:#000000;text-align:center;">
23.3
<br/>
(73.9)
</td>
<td style="background:#FF9730;color:#000000;text-align:center;">
19.5
<br/>
(67.1)
</td>
<td style="background:#F90000;color:#FFFFFF;text-align:center; border-left-width:medium">
41.9
<br/>
(107.4)
</td>
</tr>
<tr>
<th height="16">
平均高温℃(℉)
</th>
<td style="background:#F2F2FF;color:#000000;text-align:center;">
2.1
<br/>
(35.8)
</td>
<td style="background:#FFF6ED;color:#000000;text-align:center;">
5.8
<br/>
(42.4)
</td>
<td style="background:#FFC78F;color:#000000;text-align:center;">
12.6
<br/>
(54.7)
</td>
<td style="background:#FF8F1F;color:#000000;text-align:center;">
20.7
<br/>
(69.3)
</td>
<td style="background:#FF6400;color:#000000;text-align:center;">
26.9
<br/>
(80.4)
</td>
<td style="background:#FF4B00;color:#000000;text-align:center;">
30.5
<br/>
(86.9)
</td>
<td style="background:#FF4400;color:#000000;text-align:center;">
31.5
<br/>
(88.7)
</td>
<td style="background:#FF4B00;color:#000000;text-align:center;">
30.5
<br/>
(86.9)
</td>
<td style="background:#FF6900;color:#000000;text-align:center;">
26.2
<br/>
(79.2)
</td>
<td style="background:#FF9831;color:#000000;text-align:center;">
19.4
<br/>
(66.9)
</td>
<td style="background:#FFD7AF;color:#000000;text-align:center;">
10.3
<br/>
(50.5)
</td>
<td style="background:#FBFBFF;color:#000000;text-align:center;">
3.8
<br/>
(38.8)
</td>
<td style="background:#FF9F3F;color:#000000;text-align:center; border-left-width:medium">
18.4
<br/>
(65.1)
</td>
</tr>
<tr>
<th height="16">
每日平均气温℃(℉)
</th>
<td style="background:#D7D7FF;color:#000000;text-align:center;">
−2.9
<br/>
(26.8)
</td>
<td style="background:#E8E8FF;color:#000000;text-align:center;">
0.4
<br/>
(32.7)
</td>
<td style="background:#FFEDDC;color:#000000;text-align:center;">
7.0
<br/>
(44.6)
</td>
<td style="background:#FFB76F;color:#000000;text-align:center;">
14.9
<br/>
(58.8)
</td>
<td style="background:#FF8D1B;color:#000000;text-align:center;">
21.0
<br/>
(69.8)
</td>
<td style="background:#FF7100;color:#000000;text-align:center;">
25.0
<br/>
(77)
</td>
<td style="background:#FF6400;color:#000000;text-align:center;">
26.9
<br/>
(80.4)
</td>
<td style="background:#FF6C00;color:#000000;text-align:center;">
25.8
<br/>
(78.4)
</td>
<td style="background:#FF8E1E;color:#000000;text-align:center;">
20.8
<br/>
(69.4)
</td>
<td style="background:#FFBE7E;color:#000000;text-align:center;">
13.8
<br/>
(56.8)
</td>
<td style="background:#FFFAF6;color:#000000;text-align:center;">
5.1
<br/>
(41.2)
</td>
<td style="background:#E1E1FF;color:#000000;text-align:center;">
−0.9
<br/>
(30.4)
</td>
<td style="background:#FFC388;color:#000000;text-align:center; border-left-width:medium">
13.1
<br/>
(55.6)
</td>
</tr>
<tr>
<th height="16">
平均低温℃(℉)
</th>
<td style="background:#C0C0FF;color:#000000;text-align:center;">
−7.1
<br/>
(19.2)
</td>
<td style="background:#CFCFFF;color:#000000;text-align:center;">
−4.3
<br/>
(24.3)
</td>
<td style="background:#EFEFFF;color:#000000;text-align:center;">
1.6
<br/>
(34.9)
</td>
<td style="background:#FFE0C2;color:#000000;text-align:center;">
8.9
<br/>
(48)
</td>
<td style="background:#FFB76F;color:#000000;text-align:center;">
14.9
<br/>
(58.8)
</td>
<td style="background:#FF952C;color:#000000;text-align:center;">
19.8
<br/>
(67.6)
</td>
<td style="background:#FF8104;color:#000000;text-align:center;">
22.7
<br/>
(72.9)
</td>
<td style="background:#FF8811;color:#000000;text-align:center;">
21.7
<br/>
(71.1)
</td>
<td style="background:#FFAF60;color:#000000;text-align:center;">
16.0
<br/>
(60.8)
</td>
<td style="background:#FFE1C3;color:#000000;text-align:center;">
8.8
<br/>
(47.8)
</td>
<td style="background:#E9E9FF;color:#000000;text-align:center;">
0.6
<br/>
(33.1)
</td>
<td style="background:#CCCCFF;color:#000000;text-align:center;">
−4.9
<br/>
(23.2)
</td>
<td style="background:#FFE5CC;color:#000000;text-align:center; border-left-width:medium">
8.2
<br/>
(46.8)
</td>
</tr>
<tr>
<th height="16">
历史最低温℃(℉)
</th>
<td style="background:#6B6BFF;color:#000000;text-align:center;">
−22.8
<br/>
(−9)
</td>
<td style="background:#5252FF;color:#FFFFFF;text-align:center;">
−27.4
<br/>
(−17.3)
</td>
<td style="background:#9595FF;color:#000000;text-align:center;">
−15.0
<br/>
(5)
</td>
<td style="background:#D5D5FF;color:#000000;text-align:center;">
−3.2
<br/>
(26.2)
</td>
<td style="background:#F4F4FF;color:#000000;text-align:center;">
2.5
<br/>
(36.5)
</td>
<td style="background:#FFDAB5;color:#000000;text-align:center;">
9.8
<br/>
(49.6)
</td>
<td style="background:#FFB46A;color:#000000;text-align:center;">
15.3
<br/>
(59.5)
</td>
<td style="background:#FFCF9F;color:#000000;text-align:center;">
11.4
<br/>
(52.5)
</td>
<td style="background:#FAFAFF;color:#000000;text-align:center;">
3.7
<br/>
(38.7)
</td>
<td style="background:#D3D3FF;color:#000000;text-align:center;">
−3.5
<br/>
(25.7)
</td>
<td style="background:#A4A4FF;color:#000000;text-align:center;">
−12.3
<br/>
(9.9)
</td>
<td style="background:#8383FF;color:#000000;text-align:center;">
−18.3
<br/>
(−0.9)
</td>
<td style="background:#5252FF;color:#FFFFFF;text-align:center; border-left-width:medium">
−27.4
<br/>
(−17.3)
</td>
</tr>
<tr>
<th height="16">
平均
<a href="/wiki/%E9%99%8D%E6%B0%B4" title="降水">
降水
</a>
量㎜(英寸)
</th>
<td style="background:#FAFFFA;color:#000000;text-align:center;">
2.7
<br/>
(0.106)
</td>
<td style="background:#F6FFF6;color:#000000;text-align:center;">
5.0
<br/>
(0.197)
</td>
<td style="background:#EFFFEF;color:#000000;text-align:center;">
10.2
<br/>
(0.402)
</td>
<td style="background:#DBFFDB;color:#000000;text-align:center;">
23.1
<br/>
(0.909)
</td>
<td style="background:#C4FFC4;color:#000000;text-align:center;">
39.0
<br/>
(1.535)
</td>
<td style="background:#88FF88;color:#000000;text-align:center;">
76.7
<br/>
(3.02)
</td>
<td style="background:#03FF03;color:#000000;text-align:center;">
168.8
<br/>
(6.646)
</td>
<td style="background:#4BFF4B;color:#000000;text-align:center;">
120.2
<br/>
(4.732)
</td>
<td style="background:#A6FFA6;color:#000000;text-align:center;">
57.4
<br/>
(2.26)
</td>
<td style="background:#DBFFDB;color:#000000;text-align:center;">
24.1
<br/>
(0.949)
</td>
<td style="background:#EAFFEA;color:#000000;text-align:center;">
13.1
<br/>
(0.516)
</td>
<td style="background:#FBFFFB;color:#000000;text-align:center;">
2.4
<br/>
(0.094)
</td>
<td style="background:#BAFFBA;color:#000000;text-align:center; border-left-width:medium">
542.7
<br/>
(21.366)
</td>
</tr>
<tr>
<th height="16">
平均降水日数
<span class="nowrap" style="font-size:90%;">
(≥ 0.1 mm)
</span>
</th>
<td style="background:#E8E8FF;color:#000000;text-align:center;">
1.8
</td>
<td style="background:#DFDFFF;color:#000000;text-align:center;">
2.3
</td>
<td style="background:#D6D6FF;color:#000000;text-align:center;">
3.3
</td>
<td style="background:#C3C3FF;color:#000000;text-align:center;">
4.7
</td>
<td style="background:#B3B3FF;color:#000000;text-align:center;">
6.1
</td>
<td style="background:#8080FF;color:#000000;text-align:center;">
9.9
</td>
<td style="background:#6161FF;color:#FFFFFF;text-align:center;">
12.8
</td>
<td style="background:#7878FF;color:#000000;text-align:center;">
10.9
</td>
<td style="background:#9E9EFF;color:#000000;text-align:center;">
7.6
</td>
<td style="background:#C3C3FF;color:#000000;text-align:center;">
4.8
</td>
<td style="background:#DADAFF;color:#000000;text-align:center;">
2.9
</td>
<td style="background:#E6E6FF;color:#000000;text-align:center;">
2.0
</td>
<td style="background:#B6B6FF;color:#000000;text-align:center; border-left-width:medium">
69.1
</td>
</tr>
<tr>
<th height="16">
平均
<a class="mw-redirect" href="/wiki/%E7%9B%B8%E5%AF%B9%E6%B9%BF%E5%BA%A6" title="相对湿度">
相对湿度
</a>
(%)
</th>
<td style="background:#5656FF;color:#FFFFFF;text-align:center;">
44
</td>
<td style="background:#5A5AFF;color:#FFFFFF;text-align:center;">
43
</td>
<td style="background:#6262FF;color:#FFFFFF;text-align:center;">
41
</td>
<td style="background:#5A5AFF;color:#FFFFFF;text-align:center;">
43
</td>
<td style="background:#4343FF;color:#FFFFFF;text-align:center;">
49
</td>
<td style="background:#1D1DFF;color:#FFFFFF;text-align:center;">
59
</td>
<td style="background:#0000F2;color:#FFFFFF;text-align:center;">
70
</td>
<td style="background:#0000EA;color:#FFFFFF;text-align:center;">
72
</td>
<td style="background:#0606FF;color:#FFFFFF;text-align:center;">
65
</td>
<td style="background:#2121FF;color:#FFFFFF;text-align:center;">
58
</td>
<td style="background:#3030FF;color:#FFFFFF;text-align:center;">
54
</td>
<td style="background:#4B4BFF;color:#FFFFFF;text-align:center;">
47
</td>
<td style="background:#3131FF;color:#FFFFFF;text-align:center; border-left-width:medium">
53.8
</td>
</tr>
<tr>
<th height="16">
每月平均
<a class="mw-redirect" href="/wiki/%E6%97%A5%E7%85%A7%E6%97%B6%E6%95%B0" title="日照时数">
日照时数
</a>
</th>
<td style="background:#D4D400;color:#000000;text-align:center;">
186.2
</td>
<td style="background:#D9D900;color:#000000;text-align:center;">
188.1
</td>
<td style="background:#DDDD00;color:#000000;text-align:center;">
227.5
</td>
<td style="background:#E3E300;color:#000000;text-align:center;">
242.8
</td>
<td style="background:#E7E700;color:#000000;text-align:center;">
267.6
</td>
<td style="background:#DFDF00;color:#000000;text-align:center;">
225.6
</td>
<td style="background:#D6D600;color:#000000;text-align:center;">
194.5
</td>
<td style="background:#D9D900;color:#000000;text-align:center;">
208.2
</td>
<td style="background:#DADA00;color:#000000;text-align:center;">
207.5
</td>
<td style="background:#D8D800;color:#000000;text-align:center;">
205.2
</td>
<td style="background:#D1D100;color:#000000;text-align:center;">
174.5
</td>
<td style="background:#CECE00;color:#000000;text-align:center;">
172.3
</td>
<td style="background:#DADA00;color:#000000;text-align:center; border-left-width:medium">
2,500
</td>
</tr>
<tr>
<td colspan="14" style="text-align:center;font-size:95%;">
来源:
<a class="external text" href="http://cdc.cma.gov.cn/dataSetLogger.do?changeFlag=dataLogger" rel="nofollow">
中国气象局 国家气象信息中心
</a>
</td>
</tr>
</tbody>
</table>
<h3>
<span id=".E7.A9.BA.E6.B0.94.E6.B1.A1.E6.9F.93">
</span>
<span class="mw-headline" id="空气污染">
空气污染
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=10" title="编辑章节:空气污染">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
北京的空气污染长期为人诟病。空气的主要
<a class="new" href="/w/index.php?title=%E6%B1%A1%E6%9F%93%E6%BA%90&action=edit&redlink=1" title="污染源(页面不存在)">
污染源
</a>
为工业废气及
<a class="new" href="/w/index.php?title=%E6%B1%BD%E8%BD%A6%E5%B0%BE%E6%B0%94&action=edit&redlink=1" title="汽车尾气(页面不存在)">
汽车尾气
</a>
排放。根据
<a class="mw-redirect" href="/wiki/%E8%81%94%E5%90%88%E5%9B%BD%E7%8E%AF%E5%A2%83%E8%A7%84%E5%88%92%E7%BD%B2" title="联合国环境规划署">
联合国环境规划署
</a>
统计,
<a class="mw-disambig" href="/wiki/%E5%8C%97%E4%BA%AC%E6%94%BF%E5%BA%9C" title="北京政府">
北京政府
</a>
近年来花费超过1700亿
<a href="/wiki/%E7%BE%8E%E5%85%83" title="美元">
美元
</a>
治理
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC" title="北京">
北京
</a>
的环境污染
<sup class="reference" id="cite_ref-73">
<a href="#cite_note-73">
[69]
</a>
</sup>
,同時也實行了一系列提升北京市空氣質量的措施。這些措施包括將
<a class="mw-redirect" href="/wiki/%E9%A6%96%E9%92%A2%E6%80%BB%E5%85%AC%E5%8F%B8" title="首钢总公司">
首钢总公司
</a>
分批遷移至
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北省
</a>
,並關閉很多对环境造成高污染的企业
<sup class="reference" id="cite_ref-74">
<a href="#cite_note-74">
[70]
</a>
</sup>
;使用天然气、电力等清洁能源的節能環保公交车
<sup class="reference" id="cite_ref-75">
<a href="#cite_note-75">
[71]
</a>
</sup>
;限制政府和私人汽车行驶;大幅降低公交车、地铁票价以鼓励北京市民尽可能利用公共交通工具出行;在北京奥运期间,利用可再生能源来对约20%的奥运场地进行电力供应;禁止尾气排放污染量大的的“黄标车”进入市区;
<sup class="reference" id="cite_ref-76">
<a href="#cite_note-76">
[72]
</a>
</sup>
在北京周边的
<a class="mw-redirect" href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4" title="内蒙古">
内蒙古
</a>
、
<a class="mw-redirect" href="/wiki/%E5%B1%B1%E8%A5%BF" title="山西">
山西
</a>
等地大力植树以提高绿化率等。
</p>
<p>
奥运会之后,北京的空气质量并未因此而好转,2011年2月21日,美国驻华大使馆录得的北京空气污染指数已超过了正常的可测量范围,
<sup class="reference" id="cite_ref-77">
<a href="#cite_note-77">
[73]
</a>
</sup>
北京市气象部门亦在2月24日通报称,截止当日北京空气质量已连续三天达到重度污染。
<sup class="reference" id="cite_ref-78">
<a href="#cite_note-78">
[74]
</a>
</sup>
亚洲开发银行和清华大学发布《中华人民共和国国家环境分析》报告成北京市为世界十大空气污染城市之一。
<sup class="reference" id="cite_ref-79">
<a href="#cite_note-79">
[75]
</a>
</sup>
</p>
<p>
飞絮则是北京每年4、5月間另一特有现象,其来源以
<a class="new" href="/w/index.php?title=%E6%9D%A8%E7%B5%AE&action=edit&redlink=1" title="杨絮(页面不存在)">
杨絮
</a>
為主,也有
<a class="new" href="/w/index.php?title=%E6%9F%B3%E7%B5%AE&action=edit&redlink=1" title="柳絮(页面不存在)">
柳絮
</a>
。由於北京城市道路绿化曾以
<a href="/wiki/%E6%AF%9B%E7%99%BD%E6%9D%A8" title="毛白杨">
毛白楊
</a>
作為主要树种,而其白絮极易随风飘扬,因此形成了北京春天漫天飞杨絮的景观,也造成了一定程度的环境污染。随着近年来北京市通過樹幹注射抑止劑、
<a href="/wiki/%E5%AB%81%E6%8E%A5" title="嫁接">
嫁接
</a>
以及用其他樹種逐漸取代毛白楊等方法治理楊柳飛絮,飞絮现象已逐漸得到控制
<sup class="reference" id="cite_ref-80">
<a href="#cite_note-80">
[76]
</a>
</sup>
。
</p>
<div class="thumb tright">
<div class="thumbinner" style="width:252px;">
<a class="image" href="/wiki/File:Smog_in_Beijing_CBD.JPG">
<img alt="" class="thumbimage" data-file-height="2592" data-file-width="4608" decoding="async" height="141" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/3b/Smog_in_Beijing_CBD.JPG/250px-Smog_in_Beijing_CBD.JPG" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/3b/Smog_in_Beijing_CBD.JPG/375px-Smog_in_Beijing_CBD.JPG 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/3b/Smog_in_Beijing_CBD.JPG/500px-Smog_in_Beijing_CBD.JPG 2x" width="250"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Smog_in_Beijing_CBD.JPG" title="放大">
</a>
</div>
雾霾笼罩下的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">
北京商务中心区
</a>
</div>
</div>
</div>
<p>
2011年11月-12月,北京市遭遇了持续近一个月的烟霾天气,美国驻华大使馆测量的空气污染指数连续“爆表”,
<sup class="reference" id="cite_ref-asdfsd_81-0">
<a href="#cite_note-asdfsd-81">
[77]
</a>
</sup>
然而北京市环保局发布的空气污染级别却为“轻度污染”,
<sup class="reference" id="cite_ref-82">
<a href="#cite_note-82">
[78]
</a>
</sup>
引发公众疑虑。后有媒体爆料,当今世界上发达国家普遍开始采用的空气污染测量标准为PM2.5(直径2.5微米的空气颗粒,乃影响大气透明度的首要污染物,同时由于其粒径较小容易进入人体)。但由于中国当时采用的国家标准为PM10,因此无法做到全面防范和测量空气污染。
<sup class="reference" id="cite_ref-83">
<a href="#cite_note-83">
[79]
</a>
</sup>
<sup class="reference" id="cite_ref-84">
<a href="#cite_note-84">
[80]
</a>
</sup>
北京市环保局表示拒绝采纳和公布PM2.5的数值。
<sup class="reference" id="cite_ref-asdfsd_81-1">
<a href="#cite_note-asdfsd-81">
[77]
</a>
</sup>
</p>
<p>
然而北京市环保局在2011年12月初声称北京当年空气质量乃史上最佳,引发轩然大波。有媒体将此新闻与北京空气污染的照片相对比以示嘲讽。
<sup class="reference" id="cite_ref-85">
<a href="#cite_note-85">
[81]
</a>
</sup>
</p>
<p>
随着北京市空气质量的急剧恶化,舆论呼吁官方尽快将PM2.5作为国内测量标准
<sup class="reference" id="cite_ref-asdfsd_81-2">
<a href="#cite_note-asdfsd-81">
[77]
</a>
</sup>
,迫于舆论的压力,环保部宣布将在2012年在京津地区开始试点PM2.5监测,并于2016年开始全国范围的推广。
<sup class="reference" id="cite_ref-86">
<a href="#cite_note-86">
[82]
</a>
</sup>
2012年2月2日,北京市首次公布PM2.5日均浓度。
<sup class="reference" id="cite_ref-87">
<a href="#cite_note-87">
[83]
</a>
</sup>
</p>
<p>
2013年1月13日,北京空氣污染程度創歷史紀錄。北京的空氣質量繼續惡化。官方機構建議兩千萬北京市民盡量不要出行。尤其是
<a class="mw-redirect" href="/wiki/%E5%85%92%E7%AB%A5" title="兒童">
兒童
</a>
及
<a class="mw-redirect" href="/wiki/%E7%97%85%E6%82%A3" title="病患">
病患
</a>
者則更應該盡量縮短外出時間。三天來,北京以及中國大陸其他各大北部城市持續受霧霾天氣影響,已經嚴重超過平時的空氣污染級別。
<a class="mw-redirect" href="/wiki/%E6%96%B0%E8%8F%AF%E7%A4%BE" title="新華社">
新華社
</a>
於當天發布信息稱,北京1月12日的PM2.5指數瀕臨“爆表”,空氣質量持續六級嚴重污染。同時,
<a href="/wiki/%E7%BE%8E%E5%9B%BD%E9%A9%BB%E5%8D%8E%E5%A4%A7%E4%BD%BF%E9%A6%86" title="美国驻华大使馆">
美國駐華大使館
</a>
在其使館內測量的空氣污染指數也於當天呈現出創紀錄的600點,甚至於當地時間下午一度達到699點。在此之前,美國駐華大使館測量北京空氣污染指數的最高值一直停留在500點左右,該指數為50點時代表空氣質量良好,超過300點就已經進入警戒級別。
<sup class="reference" id="cite_ref-88">
<a href="#cite_note-88">
[84]
</a>
</sup>
</p>
<p>
2013年,北京的PM2.5年均浓度约为90微克,其中PM2.5浓度每立方米≤12微克(即美国1级标准)的时次占比约为10%,≤35微克(美国2级标准)约占30%,≤55微克(美国3级标准)约占45%,>150微克(重度污染)约占20%,>250微克(严重污染)约占5%,而>500微克约占0.5%,相较其他中国东部城市,北京的空气质量明显呈现多变和两极化的特点,对风向十分敏感。
<sup class="reference" id="cite_ref-89">
<a href="#cite_note-89">
[85]
</a>
</sup>
</p>
<p>
北京市生态环境局称2019年北京空气质量是过去7年来最好。2019年,北京市
<a class="mw-redirect" href="/wiki/PM2.5" title="PM2.5">
PM2.5
</a>
年均浓度42微克/立方米,相比2018年的51微克/立方米又下降了9微克/立方米,创下了2013年监测以来的最低值,但仍然超过国家标准(35微克/立方米)20%。而且2019年全年,北京没有出现严重污染日,重污染日仅4天。2019年北京市
<a class="mw-redirect" href="/wiki/PM10" title="PM10">
PM10
</a>
、
<a href="/wiki/%E4%BA%8C%E6%B0%A7%E5%8C%96%E6%B0%AE" title="二氧化氮">
二氧化氮
</a>
和
<a href="/wiki/%E4%BA%8C%E6%B0%A7%E5%8C%96%E7%A1%AB" title="二氧化硫">
二氧化硫
</a>
年均浓度分别为68微克/立方米、37微克/立方米和4微克/立方米。其中,PM10、二氧化氮首次达到国家标准(70微克/立方米、40微克/立方米);二氧化硫稳定达到国家标准(60微克/立方米)。从空间分布上看,2019年PM10、PM2.5和二氧化氮仍呈现“南高北低”的梯度分布特征,二氧化硫全市均处于较低浓度水平。其中,2019年
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">
密云区
</a>
、
<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">
怀柔区
</a>
PM2.5年均浓度分别为34微克/立方米、35微克/立方米,率先达到国家二级标准。南北污染差异虽然仍然存在,但已经明显缩小,由2013年的63微克/立方米降低至2019年的23微克/立方米,全市PM2.5逐步均匀化。
<sup class="reference" id="cite_ref-90">
<a href="#cite_note-90">
[86]
</a>
</sup>
</p>
<p>
从中国北部和西北部沙漠侵蚀而来的沙尘让北京的天空常有烟霭及浮尘,每年春季初期甚至会有“
<a href="/wiki/%E6%B2%99%E5%B0%98%E6%9A%B4" title="沙尘暴">
沙尘暴
</a>
”现象,不过实际上一般达不到气象上沙尘暴的标准(即能见度不足1公里)。
</p>
<h2>
<span id=".E8.A1.8C.E6.94.BF.E5.8C.BA.E5.88.92">
</span>
<span class="mw-headline" id="行政区划">
行政区划
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=11" title="编辑章节:行政区划">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="北京市行政区划">
北京市行政区划
</a>
</div>
<div class="hatnote navigation-not-searchable" role="note">
参见:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E5%8F%B2" title="北京行政区划史">
北京行政区划史
</a>
</div>
<p>
<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">
明
</a>
<a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">
清
</a>
時設置
<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">
順天府
</a>
管轄首都地區,地位與今日的北京市類似,但管轄面積不同。
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
民國
</a>
初年
<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C" title="北洋政府">
北洋政府
</a>
仍定都北京,1913年改
<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">
順天府
</a>
為
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
京兆地方
</a>
,範圍規格與
<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">
順天府
</a>
大致相同,直隸於中央。1928年6月,
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BC%90%E5%86%9B" title="北伐军">
北伐軍
</a>
攻入北京,乃廢除
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
京兆地方
</a>
建制,改北京為北平,初設北平特別市,直隸
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC%E5%9C%8B%E6%B0%91%E6%94%BF%E5%BA%9C" title="南京國民政府">
南京國民政府
</a>
,後改稱北平市,隸屬於
<a href="/wiki/%E8%A1%8C%E6%94%BF%E9%99%A2" title="行政院">
行政院
</a>
。日據時期成立北京市政府,日本戰敗投降後恢復原北平市建制。北平市所轄範圍較之前
<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">
順天府
</a>
、
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
京兆地方
</a>
及今日北京市為小,大致包括今
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城区
</a>
、
<a class="mw-redirect" href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA" title="东城区">
东城区
</a>
全境,
<a class="mw-redirect" href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="朝阳区 (北京市)">
朝阳区
</a>
大部、
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
海淀区
</a>
南半部、
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
石景山区
</a>
北部和
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">
丰台区
</a>
南半部
<sup class="reference" id="cite_ref-91">
<a href="#cite_note-91">
[87]
</a>
</sup>
。
</p>
<p>
1949年
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B" title="中華人民共和國">
中華人民共和國
</a>
成立,定都北平,并改北平为北京。之后北京市辖范围几经扩大。1952年,
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北省
</a>
宛平县划归北京市。1956年,
<a class="mw-redirect" href="/wiki/%E6%98%8C%E5%B9%B3" title="昌平">
昌平
</a>
县划归北京市。1958年3月7日,将
<a class="mw-redirect" href="/wiki/%E9%80%9A%E5%8E%BF" title="通县">
通县
</a>
、
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E4%B9%89" title="顺义">
顺义
</a>
、
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">
大兴
</a>
、良乡、
<a class="mw-redirect" href="/wiki/%E6%88%BF%E5%B1%B1" title="房山">
房山
</a>
五个县区划归北京市。同年10月20日,
<a class="mw-redirect" href="/wiki/%E6%80%80%E6%9F%94" title="怀柔">
怀柔
</a>
、
<a class="mw-redirect" href="/wiki/%E5%AF%86%E4%BA%91" title="密云">
密云
</a>
、
<a class="mw-redirect" href="/wiki/%E5%B9%B3%E8%B0%B7" title="平谷">
平谷
</a>
、
<a class="mw-redirect" href="/wiki/%E5%BB%B6%E5%BA%86%E5%8E%BF" title="延庆县">
延庆
</a>
四个县又被划归北京市。至此形成今日北京市的轄界。截至2009年,北京辖16区、2
<a href="/wiki/%E5%8E%BF" title="县">
县
</a>
,乡级行政区划包括135
<a href="/wiki/%E8%A1%97%E9%81%93" title="街道">
街道
</a>
、142建制
<a class="mw-redirect" href="/wiki/%E9%95%87" title="镇">
镇
</a>
和40建制
<a class="mw-redirect" href="/wiki/%E9%84%89_(%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B)" title="鄉 (中華人民共和國)">
乡
</a>
(其中包括5个
<a href="/wiki/%E6%B0%91%E6%97%8F%E4%B9%A1" title="民族乡">
民族乡
</a>
)
<sup class="reference" id="cite_ref-92">
<a href="#cite_note-92">
[88]
</a>
</sup>
。
</p>
<p>
在現今北京市市轄區中,
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城
</a>
、
<a class="mw-redirect" href="/wiki/%E8%A5%BF%E5%9F%8E" title="西城">
西城
</a>
兩區位於城市的中心區域,管轄範圍也以今
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%8C%E7%8E%AF%E8%B7%AF" title="北京二环路">
二環路
</a>
以内、清代舊城範圍為主,是传统意义上的市区。而随着北京
<a href="/wiki/%E5%9F%8E%E5%B8%82%E5%8C%96" title="城市化">
城市化
</a>
进程的加快,人口的增多和城市范围的扩张,
<a class="mw-redirect" href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="朝阳区 (北京市)">
朝阳区
</a>
、
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
海淀区
</a>
、
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">
丰台區
</a>
和
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
石景山区
</a>
四個近郊區的大部分地區也逐步被認同為市區,於是和原先的兩個
<a href="/wiki/%E5%B8%82%E5%8C%BA" title="市区">
城區
</a>
一起,形成了
<a href="/wiki/%E5%9F%8E%E5%85%AD%E5%8C%BA" title="城六区">
城六區
</a>
的概念。並且多数郊
<a href="/wiki/%E5%8E%BF" title="县">
县
</a>
也已先後改为
<a class="mw-redirect" href="/wiki/%E5%B8%82%E8%BD%84%E5%8D%80" title="市轄區">
市轄區
</a>
<sup class="reference" id="cite_ref-93">
<a href="#cite_note-93">
[89]
</a>
</sup>
。规划中北京市城区范围是
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%94%E7%8E%AF%E8%B7%AF" title="北京五环路">
五环
</a>
以内,面积约为667平方公里。
</p>
<p>
2010年7月1日
<a class="mw-redirect mw-disambig" href="/wiki/%E5%9B%BD%E5%8A%A1%E9%99%A2" title="国务院">
国务院
</a>
批准撤销原
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城区
</a>
、
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城区
</a>
、
<a href="/wiki/%E5%B4%87%E6%96%87%E5%8C%BA" title="崇文区">
崇文区
</a>
、
<a href="/wiki/%E5%AE%A3%E6%AD%A6%E5%8C%BA" title="宣武区">
宣武区
</a>
四个区,由原
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城区
</a>
和
<a href="/wiki/%E5%B4%87%E6%96%87%E5%8C%BA" title="崇文区">
崇文区
</a>
合并成立新的
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城区
</a>
,
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城区
</a>
和
<a href="/wiki/%E5%AE%A3%E6%AD%A6%E5%8C%BA" title="宣武区">
宣武区
</a>
合并成立新的
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城区
</a>
。
<sup class="reference" id="cite_ref-94">
<a href="#cite_note-94">
[90]
</a>
</sup>
这样北京市的中心城区合并为两个,城近郊结构就也由以前的“城八区”变为“城六区”。2015年11月,
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%8A%A1%E9%99%A2" title="中华人民共和国国务院">
中华人民共和国国务院
</a>
已经批准北京市调整行政区划,
<a class="mw-redirect" href="/wiki/%E5%AF%86%E4%BA%91" title="密云">
密云
</a>
、
<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">
延庆
</a>
两县将撤县设区,至此北京将不再设有以“县”为名称的县级行政单位
<sup class="reference" id="cite_ref-95">
<a href="#cite_note-95">
[91]
</a>
</sup>
。
</p>
<p>
北京市的市辖区,按照功能划分成四层,从内到外依次是:首都功能核心区、城市功能拓展区、城市功能新区和生态涵养区。現今狭义的北京可僅指北京市区,大约就是
<a href="/wiki/%E5%9F%8E%E5%85%AD%E5%8C%BA" title="城六区">
城六区
</a>
的範圍,而广义的北京则代指包括郊区县在内隶属北京市政府管辖北京
<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">
直辖市
</a>
。
</p>
<p>
北京市的城市建设风格是典型的
<a href="/wiki/%E6%94%BE%E5%B0%84%E5%9E%8B%E5%9F%8E%E5%B8%82" title="放射型城市">
放射型城市
</a>
,由五环路内的主城区和周边的大量
<a class="mw-redirect" href="/wiki/%E5%8D%AB%E6%98%9F%E5%9F%8E" title="卫星城">
卫星城
</a>
组成。距离主城区最近的一批卫星城,如
<a href="/wiki/%E5%9B%9E%E9%BE%99%E8%A7%82%E5%9C%B0%E5%8C%BA" title="回龙观地区">
回龙观
</a>
、
<a href="/wiki/%E5%A4%A9%E9%80%9A%E8%8B%91" title="天通苑">
天通苑
</a>
、海淀山后、石景山首钢,几乎与主城区相互连接;较远的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83" title="北京城市副中心">
副中心
</a>
、
<a href="/wiki/%E4%BA%A6%E5%BA%84%E5%9C%B0%E5%8C%BA" title="亦庄地区">
亦庄
</a>
、
<a href="/wiki/%E9%BB%84%E6%9D%91%E5%9C%B0%E5%8C%BA" title="黄村地区">
黄村
</a>
、房山燕化、
<a href="/wiki/%E8%89%AF%E4%B9%A1%E5%9C%B0%E5%8C%BA" title="良乡地区">
良乡
</a>
、门头沟城关、
<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">
昌平
</a>
、
<a href="/wiki/%E6%B2%99%E6%B2%B3%E5%9C%B0%E5%8C%BA" title="沙河地区">
沙河
</a>
、
<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">
延庆
</a>
、
<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">
怀柔
</a>
、
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">
密云
</a>
、
<a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">
平谷
</a>
、
<a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">
顺义
</a>
、
<a href="/wiki/%E9%95%BF%E8%BE%9B%E5%BA%97%E9%95%87" title="长辛店镇">
长辛店
</a>
等十四个卫星城,以及
<a href="/wiki/%E5%A4%A9%E7%AB%BA%E5%9C%B0%E5%8C%BA" title="天竺地区">
天竺
</a>
、
<a href="/wiki/%E7%A4%BC%E8%B4%A4%E9%95%87" title="礼贤镇">
礼贤
</a>
两个空港区,在逐渐配合北京整体建设的同时也各有特色;更远的一些城镇,如
<a href="/wiki/%E7%87%95%E9%83%8A%E9%95%87" title="燕郊镇">
燕郊
</a>
、
<a href="/wiki/%E8%93%9F%E5%B7%9E%E5%8C%BA" title="蓟州区">
蓟州
</a>
、
<a href="/wiki/%E5%94%90%E5%B1%B1%E5%B8%82" title="唐山市">
唐山
</a>
、
<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">
廊坊
</a>
、
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">
承德
</a>
、
<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">
保定
</a>
、
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
、
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">
张家口
</a>
、
<a href="/wiki/%E9%9B%84%E5%AE%89%E6%96%B0%E5%8C%BA" title="雄安新区">
雄安
</a>
,有时也被认为是北京的卫星城,虽然官方目前一般以“
<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%86%80%E5%8D%8F%E5%90%8C%E5%8F%91%E5%B1%95" title="京津冀协同发展">
京津冀协同发展
</a>
”表述这些地区与北京的关系。
</p>
<table class="wikitable" style="margin:1em auto 1em auto; width:90%; text-align:center">
<tbody>
<tr>
<th colspan="10">
<b>
北京市行政区划图
</b>
</th>
</tr>
<tr>
<td colspan="10">
<div class="center" style="position: relative">
<div class="nounderlines noresize" role="img" style="width: 600px; line-height: 1; text-align: center; background-color: #ffffff; position: relative;">
<img alt="" data-file-height="1054" data-file-width="1050" decoding="async" height="602" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c4/Administrative_Division_Beijing.svg/600px-Administrative_Division_Beijing.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c4/Administrative_Division_Beijing.svg/900px-Administrative_Division_Beijing.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c4/Administrative_Division_Beijing.svg/1200px-Administrative_Division_Beijing.svg.png 2x" width="600"/>
<div style="position:absolute; left:287px; top:412px">
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
<span style="color: black;">
<b>
①
</b>
</span>
</a>
</div>
<div style="position:absolute; left:269px; top:412px">
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
<span style="color: black;">
<b>
②
</b>
</span>
</a>
</div>
<div style="position:absolute; left:314px; top:387px">
<a class="mw-redirect" href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="朝阳区 (北京市)">
<span style="color: black;">
<b>
朝
<br/>
阳
<br/>
区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:224px; top:432px">
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">
<span style="color: black;">
<b>
丰台区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:219px; top:402px">
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
<span style="color: black;">
<b>
③
</b>
</span>
</a>
</div>
<div style="position:absolute; left:242px; top:360px">
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
<span style="color: black;">
<b>
海
<br/>
淀
<br/>
区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:94px; top:382px">
<a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">
<span style="color: black;">
<b>
门头沟区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:114px; top:482px">
<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">
<span style="color: black;">
<b>
房山区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:354px; top:452px">
<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">
<span style="color: black;">
<b>
通州区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:354px; top:327px">
<a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">
<span style="color: black;">
<b>
顺义区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:214px; top:302px">
<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">
<span style="color: black;">
<b>
昌平区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:264px; top:492px">
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">
<span style="color: black;">
<b>
大兴区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:339px; top:162px">
<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">
<span style="color: black;">
<b>
怀
<br/>
柔
<br/>
区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:464px; top:302px">
<a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">
<span style="color: black;">
<b>
平谷区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:424px; top:177px">
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">
<span style="color: black;">
<b>
密云区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:194px; top:202px">
<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">
<span style="color: black;">
<b>
延庆区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:94px; top:32px">
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
<span style="color: black;">
<b>
① 东城区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:94px; top:52px">
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
<span style="color: black;">
<b>
② 西城区
</b>
</span>
</a>
</div>
<div style="position:absolute; left:94px; top:72px">
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
<span style="color: black;">
<b>
③ 石景山区
</b>
</span>
</a>
</div>
</div>
</div>
</td>
</tr>
<tr class="nowrap">
<th rowspan="2">
区划代码
<sup class="reference" id="cite_ref-96">
<a href="#cite_note-96">
[92]
</a>
</sup>
</th>
<th rowspan="2">
区划名称
</th>
<th rowspan="2">
汉语拼音
</th>
<th rowspan="2">
面积
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-97">
<a href="#cite_note-97">
[註 5]
</a>
</sup>
</span>
<br/>
(平方公里)
</th>
<th rowspan="2">
常住人口
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-98">
<a href="#cite_note-98">
[註 6]
</a>
</sup>
</span>
<sup class="reference" id="cite_ref-99">
<a href="#cite_note-99">
[93]
</a>
</sup>
<br/>
(2018年末)
</th>
<th rowspan="2">
政府驻地
</th>
<th colspan="4">
乡级行政区划
<sup class="reference" id="cite_ref-100">
<a href="#cite_note-100">
[94]
</a>
</sup>
</th>
</tr>
<tr>
<th width="45">
街道
</th>
<th width="45">
镇
</th>
<th width="45">
乡
</th>
<th width="45">
民族乡
</th>
</tr>
<tr style="font-weight: bold">
<th>
110000
</th>
<th>
北京市
</th>
<td>
Běijīng Shì
</td>
<td>
16,406.16
</td>
<td>
21,542,000
</td>
<td>
通州区
</td>
<td>
152
</td>
<td>
143
</td>
<td>
33
</td>
<td>
5
</td>
</tr>
<tr bgcolor="lightblue">
<td colspan="10" style="text-align:center;">
<b>
—
<a href="/wiki/%E5%B8%82%E8%BE%96%E5%8C%BA" title="市辖区">
市辖区
</a>
—
</b>
</td>
</tr>
<tr>
<th>
110101
</th>
<th>
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城区
</a>
</th>
<td>
Dōngchéng Qū
</td>
<td>
41.82
</td>
<td>
822,000
</td>
<td>
<a href="/wiki/%E6%99%AF%E5%B1%B1%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="景山街道 (北京市)">
景山街道
</a>
</td>
<td>
17
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110102
</th>
<th>
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城区
</a>
</th>
<td>
Xīchéng Qū
</td>
<td>
50.33
</td>
<td>
1,179,000
</td>
<td>
<a href="/wiki/%E9%87%91%E8%9E%8D%E8%A1%97%E8%A1%97%E9%81%93" title="金融街街道">
金融街街道
</a>
</td>
<td>
15
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110105
</th>
<th>
<a class="mw-redirect" href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="朝阳区 (北京市)">
朝阳区
</a>
</th>
<td>
Cháoyáng Qū
</td>
<td>
454.78
</td>
<td>
3,605,000
</td>
<td>
<a href="/wiki/%E6%9C%9D%E5%A4%96%E8%A1%97%E9%81%93" title="朝外街道">
朝外街道
</a>
</td>
<td>
24
</td>
<td>
</td>
<td>
18
</td>
<td>
1
</td>
</tr>
<tr>
<th>
110106
</th>
<th>
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">
丰台区
</a>
</th>
<td>
Fēngtái Qū
</td>
<td>
305.53
</td>
<td>
2,105,000
</td>
<td>
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E8%A1%97%E9%81%93" title="丰台街道">
丰台街道
</a>
</td>
<td>
16
</td>
<td>
2
</td>
<td>
3
</td>
<td>
</td>
</tr>
<tr>
<th>
110107
</th>
<th>
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
石景山区
</a>
</th>
<td>
Shíjǐngshān Qū
</td>
<td>
84.38
</td>
<td>
590,000
</td>
<td>
<a href="/wiki/%E9%B2%81%E8%B0%B7%E8%A1%97%E9%81%93" title="鲁谷街道">
鲁谷街道
</a>
</td>
<td>
9
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110108
</th>
<th>
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
海淀区
</a>
</th>
<td>
Hǎidiàn Qū
</td>
<td>
430.77
</td>
<td>
3,358,000
</td>
<td>
<a href="/wiki/%E6%B5%B7%E6%B7%80%E8%A1%97%E9%81%93" title="海淀街道">
海淀街道
</a>
</td>
<td>
22
</td>
<td>
7
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110109
</th>
<th>
<a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">
门头沟区
</a>
</th>
<td>
Méntóugōu Qū
</td>
<td>
1,447.85
</td>
<td>
331,000
</td>
<td>
<a href="/wiki/%E5%A4%A7%E5%B3%AA%E8%A1%97%E9%81%93" title="大峪街道">
大峪街道
</a>
</td>
<td>
4
</td>
<td>
9
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110111
</th>
<th>
<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">
房山区
</a>
</th>
<td>
Fángshān Qū
</td>
<td>
1,994.73
</td>
<td>
1,188,000
</td>
<td>
<a href="/wiki/%E6%8B%B1%E8%BE%B0%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="拱辰街道 (北京市)">
拱辰街道
</a>
</td>
<td>
8
</td>
<td>
14
</td>
<td>
6
</td>
<td>
</td>
</tr>
<tr>
<th>
110112
</th>
<th>
<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">
通州区
</a>
</th>
<td>
Tōngzhōu Qū
</td>
<td>
905.79
</td>
<td>
1,578,000
</td>
<td>
<a href="/wiki/%E5%8C%97%E8%8B%91%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="北苑街道 (北京市)">
北苑街道
</a>
</td>
<td>
6
</td>
<td>
10
</td>
<td>
</td>
<td>
1
</td>
</tr>
<tr>
<th>
110113
</th>
<th>
<a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">
顺义区
</a>
</th>
<td>
Shùnyì Qū
</td>
<td>
1,019.51
</td>
<td>
1,169,000
</td>
<td>
<a href="/wiki/%E8%83%9C%E5%88%A9%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="胜利街道 (北京市)">
胜利街道
</a>
</td>
<td>
6
</td>
<td>
19
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110114
</th>
<th>
<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">
昌平区
</a>
</th>
<td>
Chāngpíng Qū
</td>
<td>
1,342.47
</td>
<td>
2,108,000
</td>
<td>
<a href="/wiki/%E5%9F%8E%E5%8C%97%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="城北街道 (北京市)">
城北街道
</a>
</td>
<td>
8
</td>
<td>
14
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110115
</th>
<th>
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">
大兴区
</a>
</th>
<td>
Dàxīng Qū
</td>
<td>
1,036.34
</td>
<td>
1,796,000
</td>
<td>
<a href="/wiki/%E5%85%B4%E4%B8%B0%E8%A1%97%E9%81%93" title="兴丰街道">
兴丰街道
</a>
</td>
<td>
8
</td>
<td>
14
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<th>
110116
</th>
<th>
<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">
怀柔区
</a>
</th>
<td>
Huáiróu Qū
</td>
<td>
2,122.82
</td>
<td>
414,000
</td>
<td>
<a href="/wiki/%E9%BE%99%E5%B1%B1%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="龙山街道 (北京市)">
龙山街道
</a>
</td>
<td>
2
</td>
<td>
12
</td>
<td>
</td>
<td>
2
</td>
</tr>
<tr>
<th>
110117
</th>
<th>
<a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">
平谷区
</a>
</th>
<td>
Pínggǔ Qū
</td>
<td>
948.24
</td>
<td>
456,000
</td>
<td>
<a href="/wiki/%E6%BB%A8%E6%B2%B3%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="滨河街道 (北京市)">
滨河街道
</a>
</td>
<td>
2
</td>
<td>
14
</td>
<td>
2
</td>
<td>
</td>
</tr>
<tr>
<th>
110118
</th>
<th>
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">
密云区
</a>
</th>
<td>
Mìyún Qū
</td>
<td>
2,225.92
</td>
<td>
495,000
</td>
<td>
<a class="mw-redirect" href="/wiki/%E9%BC%93%E6%A5%BC%E8%A1%97%E9%81%93_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="鼓楼街道 (北京市)">
鼓楼街道
</a>
</td>
<td>
2
</td>
<td>
17
</td>
<td>
</td>
<td>
1
</td>
</tr>
<tr>
<th>
110119
</th>
<th>
<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">
延庆区
</a>
</th>
<td>
Yánqìng Qū
</td>
<td>
1,994.88
</td>
<td>
348,000
</td>
<td>
<a href="/wiki/%E5%84%92%E6%9E%97%E8%A1%97%E9%81%93" title="儒林街道">
儒林街道
</a>
</td>
<td>
3
</td>
<td>
11
</td>
<td>
4
</td>
<td>
</td>
</tr>
</tbody>
</table>
<h2>
<span id=".E6.94.BF.E6.B2.BB">
</span>
<span class="mw-headline" id="政治">
政治
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=12" title="编辑章节:政治">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%BA%9C" title="北京市政府">
北京市政府
</a>
</div>
<link href="mw-data:TemplateStyles:r61200722/mw-parser-output/.tmulti" rel="mw-deduplicated-inline-style"/>
<div class="thumb tmulti tright">
<div class="thumbinner" style="width:292px;max-width:292px">
<div class="trow">
<div class="tsingle" style="width:140px;max-width:140px">
<div class="thumbimage" style="height:183px;overflow:hidden">
<a class="image" href="/wiki/File:1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg">
<img alt="" data-file-height="800" data-file-width="601" decoding="async" height="184" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/eb/1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg/138px-1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/eb/1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg/207px-1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/eb/1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg/276px-1935%E5%B9%B4%E5%8C%97%E5%B9%B3%E5%B8%82%E6%94%BF%E5%BA%9C.jpg 2x" width="138"/>
</a>
</div>
<div class="thumbcaption text-align-center">
1935年的北平市政府
</div>
</div>
<div class="tsingle" style="width:148px;max-width:148px">
<div class="thumbimage" style="height:183px;overflow:hidden">
<a class="image" href="/wiki/File:Beijing_1948_JP.jpg">
<img alt="" data-file-height="7933" data-file-width="6293" decoding="async" height="184" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/146px-Beijing_1948_JP.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/219px-Beijing_1948_JP.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Beijing_1948_JP.jpg/292px-Beijing_1948_JP.jpg 2x" width="146"/>
</a>
</div>
<div class="thumbcaption text-align-center">
1940年代的北京城区
</div>
</div>
</div>
</div>
</div>
<p>
历史上,有明、清等数个朝代或政权在北京建政,因此北京有较长的建都史。目前,北京作为
<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">
首都
</a>
,是中华人民共和国的政治中心,不仅政党、立法、行政与军事等的常务机构聚集于北京,许多著名的政治事件如
<a href="/wiki/%E4%BA%94%E5%9B%9B%E8%BF%90%E5%8A%A8" title="五四运动">
五四运动
</a>
、
<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">
四五运动
</a>
、
<a href="/wiki/%E5%85%AD%E5%9B%9B%E4%BA%8B%E4%BB%B6" title="六四事件">
六四事件
</a>
等亦发生于此。
</p>
<p>
1912年2月12日,清
<a href="/wiki/%E9%9A%86%E8%A3%95%E5%A4%AA%E5%90%8E" title="隆裕太后">
隆裕太后
</a>
在这里公布末代皇帝
<a class="mw-redirect" href="/wiki/%E7%88%B1%E6%96%B0%E8%A7%89%E7%BD%97%E6%BA%A5%E4%BB%AA" title="爱新觉罗溥仪">
爱新觉罗·溥仪
</a>
的退位诏书,标志着中国数千年
<a class="mw-redirect" href="/wiki/%E5%90%9B%E4%B8%BB%E4%B8%93%E5%88%B6" title="君主专制">
君主专制
</a>
的终结。1919年5月4日,
<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C%E6%99%82%E6%9C%9F" title="北洋政府時期">
北洋政府时期
</a>
,上千名北京高校学生云集
<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8" title="天安门">
天安门
</a>
附近,抗议“
<a href="/wiki/%E4%BA%8C%E5%8D%81%E4%B8%80%E6%9D%A1" title="二十一条">
二十一条
</a>
”等条约对中国的不平等对待,历史上称为“
<a href="/wiki/%E4%BA%94%E5%9B%9B%E8%BF%90%E5%8A%A8" title="五四运动">
五四运动
</a>
”。1935年12月9日,数千名北平高校学生發起抗日救国大规模游行,反对日本对华北“防共自治”,史称“
<a class="mw-redirect" href="/wiki/%E4%B8%80%E4%BA%8C%E4%B9%9D%E8%BF%90%E5%8A%A8" title="一二九运动">
一二九运动
</a>
”。1949年10月1日,
<a href="/wiki/%E6%AF%9B%E6%B3%BD%E4%B8%9C" title="毛泽东">
毛泽东
</a>
于
<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8" title="天安门">
天安门
</a>
城楼上向全世界宣布
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C_(1949%E2%80%931954)" title="中华人民共和国中央人民政府 (1949–1954)">
中华人民共和国中央人民政府
</a>
的成立,北京再次成为中国的政治中心。1976年4月5日,
<a href="/wiki/%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="四人帮">
四人帮
</a>
代表政府使用民兵对
<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8%E5%B9%BF%E5%9C%BA" title="天安门广场">
天安门广场
</a>
进行清场,将在天安门广场集会悼念
<a class="mw-redirect" href="/wiki/%E5%9B%BD%E5%8A%A1%E9%99%A2%E6%80%BB%E7%90%86" title="国务院总理">
国务院总理
</a>
<a href="/wiki/%E5%91%A8%E6%81%A9%E6%9D%A5" title="周恩来">
周恩来
</a>
的北京数万民众镇压下去。人民开始声讨“
<a href="/wiki/%E5%9B%9B%E4%BA%BA%E5%B8%AE" title="四人帮">
四人帮
</a>
”,并由此引发反对“四人帮”的全国性强大群众抗议运动,史称“
<a href="/wiki/%E5%9B%9B%E4%BA%94%E8%BF%90%E5%8A%A8" title="四五运动">
四五运动
</a>
”。
</p>
<p>
1989年,民眾自4月15日開始的對前任中共中央總書記胡耀邦的悼念活動演變為要求政府進行多方面改革的示威活動。6月4日,中國人民解放軍開進北京市內天安門廣場及周邊地區,採取武力鎮壓滯留的抗議學生与市民,並引發血腥衝突,造成學生及民眾傷亡,史稱「
<a href="/wiki/%E5%85%AD%E5%9B%9B%E4%BA%8B%E4%BB%B6" title="六四事件">
六四事件
</a>
」,隨後北京全城戒嚴長達半年。
</p>
<p>
2015年12月30日,位于
<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">
通州区
</a>
的北京城市副中心行政办公区举行奠基仪式,2017年1月起各主要建筑主体结构陆续封顶。2019年1月10日晚,位于
<a class="mw-redirect" href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA" title="东城区">
东城区
</a>
<a href="/wiki/%E6%AD%A3%E4%B9%89%E8%B7%AF" title="正义路">
正义路
</a>
2号的北京市人民政府正式摘牌,大楼移交给档案馆
<sup class="reference" id="cite_ref-101">
<a href="#cite_note-101">
[95]
</a>
</sup>
,1月11日,北京市人民政府机关与
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%85%B1%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94" title="中共北京市委">
中共北京市委
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E4%BB%A3%E8%A1%A8%E5%A4%A7%E4%BC%9A%E5%B8%B8%E5%8A%A1%E5%A7%94%E5%91%98%E4%BC%9A" title="北京市人民代表大会常务委员会">
北京市人大常委会
</a>
、
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国人民政治协商会议北京市委员会">
政协北京市委员会
</a>
一同搬迁至
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83" title="北京城市副中心">
北京城市副中心
</a>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83%E8%A1%8C%E6%94%BF%E5%8A%9E%E5%85%AC%E5%8C%BA" title="北京城市副中心行政办公区">
行政办公区
</a>
新址
<sup class="reference" id="cite_ref-102">
<a href="#cite_note-102">
[96]
</a>
</sup>
<sup class="reference" id="cite_ref-103">
<a href="#cite_note-103">
[97]
</a>
</sup>
。
</p>
<h3>
<span id=".E5.9B.9B.E5.A4.A7.E6.9C.BA.E6.9E.84">
</span>
<span class="mw-headline" id="四大机构">
四大机构
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=13" title="编辑章节:四大机构">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<table class="wikitable" style="margin:1em auto 1em auto; text-align:center">
<caption>
北京市四大机构现任领导人
</caption>
<tbody>
<tr>
<th style="width:16%">
机构
</th>
<th style="width:16%">
<img alt="Danghui.svg" data-file-height="305" data-file-width="305" decoding="async" height="25" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/Danghui.svg/25px-Danghui.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/69/Danghui.svg/38px-Danghui.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/69/Danghui.svg/50px-Danghui.svg.png 2x" width="25"/>
<br/>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国共产党北京市委员会">
中国共产党
<br/>
北京市委员会
</a>
<br/>
书记
</th>
<th style="width:16%">
<a class="image" href="/wiki/File:National_Emblem_of_the_People%27s_Republic_of_China_(2).svg" title="中华人民共和国国徽">
<img alt="中华人民共和国国徽" data-file-height="976" data-file-width="900" decoding="async" height="27" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/25px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/38px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/50px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 2x" width="25"/>
</a>
<br/>
北京市人民代表大会
<br/>
常务委员会
<br/>
主任
</th>
<th style="width:16%">
<a class="image" href="/wiki/File:National_Emblem_of_the_People%27s_Republic_of_China_(2).svg" title="中华人民共和国国徽">
<img alt="中华人民共和国国徽" data-file-height="976" data-file-width="900" decoding="async" height="27" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/25px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/38px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg/50px-National_Emblem_of_the_People%27s_Republic_of_China_%282%29.svg.png 2x" width="25"/>
</a>
<br/>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">
北京市人民政府
</a>
<br/>
<br/>
市长
</th>
<th style="width:16%">
<img alt="Charter of the Chinese People's Political Consultative Conference (CPPCC) logo.svg" data-file-height="750" data-file-width="739" decoding="async" height="25" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c5/Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg/25px-Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c5/Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg/38px-Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c5/Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg/50px-Charter_of_the_Chinese_People%27s_Political_Consultative_Conference_%28CPPCC%29_logo.svg.png 2x" width="25"/>
<br/>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国人民政治协商会议北京市委员会">
中国人民政治协商会议
<br/>
北京市委员会
</a>
<br/>
主席
</th>
</tr>
<tr>
<th>
姓名
</th>
<td>
<a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">
蔡奇
</a>
<sup class="reference" id="cite_ref-104">
<a href="#cite_note-104">
[98]
</a>
</sup>
</td>
<td>
<a href="/wiki/%E6%9D%8E%E4%BC%9F_(%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A%E4%B8%BB%E4%BB%BB)" title="李伟 (北京市人大常委会主任)">
李伟
</a>
<sup class="reference" id="cite_ref-105">
<a href="#cite_note-105">
[99]
</a>
</sup>
</td>
<td>
<a href="/wiki/%E9%99%88%E5%90%89%E5%AE%81" title="陈吉宁">
陈吉宁
</a>
<sup class="reference" id="cite_ref-106">
<a href="#cite_note-106">
[100]
</a>
</sup>
</td>
<td>
<a href="/wiki/%E5%90%89%E6%9E%97_(%E4%BA%BA%E7%89%A9)" title="吉林 (人物)">
吉林
</a>
<sup class="reference" id="cite_ref-107">
<a href="#cite_note-107">
[101]
</a>
</sup>
</td>
</tr>
<tr>
<th>
民族
</th>
<td>
<a href="/wiki/%E6%B1%89%E6%97%8F" title="汉族">
汉族
</a>
</td>
<td>
汉族
</td>
<td>
汉族
</td>
<td>
汉族
</td>
</tr>
<tr>
<th>
籍贯
</th>
<td>
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
福建省
</a>
<a href="/wiki/%E5%B0%A4%E6%BA%AA%E5%8E%BF" title="尤溪县">
尤溪县
</a>
</td>
<td>
<a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">
江苏省
</a>
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E6%B8%AF%E5%B8%82" title="张家港市">
张家港市
</a>
</td>
<td>
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">
吉林省
</a>
<a href="/wiki/%E6%A2%A8%E6%A0%91%E5%8E%BF" title="梨树县">
梨树县
</a>
</td>
<td>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</td>
</tr>
<tr>
<th>
出生日期
</th>
<td>
1955年12月(65歲)
</td>
<td>
1958年1月(62歲-63歲)
</td>
<td>
1964年2月(56歲)
</td>
<td>
1962年4月(58歲)
</td>
</tr>
<tr>
<th>
就任日期
</th>
<td>
2017年5月
</td>
<td>
2017年1月
</td>
<td>
2018年1月
</td>
<td>
2013年1月
</td>
</tr>
</tbody>
</table>
<h2>
<span id=".E7.BB.8F.E6.B5.8E">
</span>
<span class="mw-headline" id="经济">
经济
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=14" title="编辑章节:经济">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E7%BB%8F%E6%B5%8E" title="北京经济">
北京经济
</a>
</div>
<div class="thumb tright">
<div class="thumbinner" style="width:302px;">
<a class="image" href="/wiki/File:%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg">
<img alt="" class="thumbimage" data-file-height="1800" data-file-width="5813" decoding="async" height="93" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg/300px-%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg/450px-%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg/600px-%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg 2x" width="300"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:%E4%B8%AD%E5%85%B3%E6%9D%91%E7%A7%91%E6%8A%80%E5%9B%AD%E5%85%A8%E6%99%AF%E5%9B%BE.jpg" title="放大">
</a>
</div>
<a href="/wiki/%E4%B8%AD%E5%85%B3%E6%9D%91" title="中关村">
中关村
</a>
</div>
</div>
</div>
<div class="thumb tright">
<div class="thumbinner" style="width:302px;">
<a class="image" href="/wiki/File:Guomao_Skyline.jpg">
<img alt="" class="thumbimage" data-file-height="1017" data-file-width="1600" decoding="async" height="191" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/53/Guomao_Skyline.jpg/300px-Guomao_Skyline.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/53/Guomao_Skyline.jpg/450px-Guomao_Skyline.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/53/Guomao_Skyline.jpg/600px-Guomao_Skyline.jpg 2x" width="300"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Guomao_Skyline.jpg" title="放大">
</a>
</div>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%95%86%E5%8A%A1%E4%B8%AD%E5%BF%83%E5%8C%BA" title="北京商务中心区">
北京商务中心区
</a>
天際線
</div>
</div>
</div>
<h3>
<span id=".E7.B6.93.E6.BF.9F.E6.95.B8.E6.93.9A">
</span>
<span class="mw-headline" id="經濟數據">
經濟數據
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=15" title="编辑章节:經濟數據">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%B0%E5%8C%BA%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="北京市地区生产总值">
北京市地区生产总值
</a>
</div>
<p>
2015年
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%B0%E5%8C%BA%E7%94%9F%E4%BA%A7%E6%80%BB%E5%80%BC" title="北京市地区生产总值">
北京市地区生产总值
</a>
22968.6亿元,同比增长6.9%;人均地区生产总值达10.6万元,约17064美元
<sup class="reference" id="cite_ref-108">
<a href="#cite_note-108">
[102]
</a>
</sup>
。2015年北京第三产业比例达到80%左右,对经济贡献最大的主要是金融等产业。其中金融业增长18.1%,信息传输、软件和信息技术服务业增长12%,科学研究和技术服务业增长14.1%。2015年北京工业企业关停了326家,商品批发市场拆并、疏解了97家。
<sup class="reference" id="cite_ref-21jj_109-0">
<a href="#cite_note-21jj-109">
[103]
</a>
</sup>
</p>
<p>
近年来,北京的房地产业与汽车工业持续发展
<sup class="reference" id="cite_ref-分省年度數據_110-0">
<a href="#cite_note-分省年度數據-110">
[104]
</a>
</sup>
。北京市制造业有汽车产业、生物医药产业、光机电产业、微电子产业等
<sup class="reference" id="cite_ref-111">
<a href="#cite_note-111">
[105]
</a>
</sup>
。2015年,北京旅遊業共接待海外遊客420萬人次,接待國內遊客2.7億人次。
<sup class="reference" id="cite_ref-gk_112-0">
<a href="#cite_note-gk-112">
[106]
</a>
</sup>
2015年,北京前两大的出口市場是美國和香港,主要出口產品為機電產品及高科技產品。
<sup class="reference" id="cite_ref-gk_112-1">
<a href="#cite_note-gk-112">
[106]
</a>
</sup>
截至2009年12月,北京市机动车保有量已经突破400万辆
<sup class="reference" id="cite_ref-113">
<a href="#cite_note-113">
[107]
</a>
</sup>
。2015年全年,北京货运量28765.2万吨,客运量69923.1万人。年末全市机动车保有量561.9万辆。全年实现邮电业务总量990.9亿元。
<sup class="reference" id="cite_ref-2015公报_114-0">
<a href="#cite_note-2015公报-114">
[108]
</a>
</sup>
</p>
<p>
北京存在区域发展极不平衡的现象。北京市有“南穷北富”的称呼
<sup class="reference" id="cite_ref-115">
<a href="#cite_note-115">
[109]
</a>
</sup>
。据2008年统计,北京南城五区(
<a href="/wiki/%E5%AE%A3%E6%AD%A6%E5%8C%BA" title="宣武区">
宣武
</a>
、
<a href="/wiki/%E5%B4%87%E6%96%87%E5%8C%BA" title="崇文区">
崇文
</a>
、
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">
丰台
</a>
、
<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">
房山
</a>
、
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">
大兴
</a>
)的GDP总量不及北城五区(
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城
</a>
、
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城
</a>
、
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
海淀
</a>
、
<a class="mw-redirect" href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="朝阳区 (北京市)">
朝阳
</a>
、
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
石景山
</a>
)的1/5,南城财政收入亦不及北城之1/4
<sup class="reference" id="cite_ref-116">
<a href="#cite_note-116">
[110]
</a>
</sup>
。
</p>
<p>
2004年北京市全年完成地方财政收入534亿元,连续8年保持20%以上的增长速度
<sup class="reference" id="cite_ref-117">
<a href="#cite_note-117">
[111]
</a>
</sup>
。2009年,
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC" title="北京">
北京
</a>
全市完成地方财政收入(一般预算)2026.8亿元,比上年增长10.3%。2013年,全市地方公共财政预算收入3661.1亿元,比上年增长10.4%,地方公共财政预算支出4173.66亿元,增长13.3%。
<sup class="reference" id="cite_ref-118">
<a href="#cite_note-118">
[112]
</a>
</sup>
</p>
<h3>
<span id="-.7Bzh:.E5.9F.BA.E7.A1.80.E8.AE.BE.E6.96.BD.3Bzh-hans:.E5.9F.BA.E7.A1.80.E8.AE.BE.E6.96.BD.3Bzh-hant:.E5.9F.BA.E7.A4.8E.E5.BB.BA.E8.A8.AD.7D-">
</span>
<span class="mw-headline" id="-{zh:基础设施;zh-hans:基础设施;zh-hant:基礎建設}-">
基础设施
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=16" title="编辑章节:基础设施">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%A4%E9%80%9A" title="北京交通">
北京交通
</a>
</div>
<p>
北京交通发达,是中国最大的铁路、公路及航空
<a href="/wiki/%E4%BA%A4%E9%80%9A" title="交通">
交通
</a>
中心,也是乃至整個
<a class="mw-redirect" href="/wiki/%E6%9D%B1%E4%BA%9E" title="東亞">
東亞
</a>
地區的重要交通樞紐,擁有完善的城市交通网。截至2019年底,北京共有1167km的
<a href="/wiki/%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="高速公路">
高速公路
</a>
和6162km城市道路(其中包括6條環路(二环至六环及
<a class="mw-redirect" href="/wiki/%E9%A6%96%E9%83%BD%E7%8E%AF%E7%BA%BF%E9%AB%98%E9%80%9F" title="首都环线高速">
大外环
</a>
)、15條
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E9%81%93" title="中华人民共和国国道">
中國國道
</a>
<span id="noteTag-cite_ref-sup">
<sup class="reference" id="cite_ref-119">
<a href="#cite_note-119">
[註 7]
</a>
</sup>
</span>
),轨道交通线路699.3km,數條
<a class="mw-redirect" href="/wiki/%E9%90%B5%E8%B7%AF" title="鐵路">
鐵路
</a>
和2個
<a class="mw-redirect" href="/wiki/%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" title="國際機場">
國際機場
</a>
,北京市汽車擁有量達到636.5萬
<sup class="reference" id="cite_ref-19年公报_120-0">
<a href="#cite_note-19年公报-120">
[113]
</a>
</sup>
。
<a href="/wiki/%E6%94%BE%E5%B0%84%E5%9E%8B%E5%9F%8E%E5%B8%82" title="放射型城市">
放射型城市
</a>
的单极
<a href="/wiki/%E4%BA%A4%E9%80%9A" title="交通">
交通
</a>
體系發展較城市發展相對滯後等多方面原因也使
<a class="mw-redirect" href="/wiki/%E4%BA%A4%E9%80%9A%E6%8B%A5%E5%A0%B5" title="交通拥堵">
交通擁堵
</a>
成為了北京長期面對的問題
<sup class="reference" id="cite_ref-121">
<a href="#cite_note-121">
[114]
</a>
</sup>
<sup class="reference" id="cite_ref-122">
<a href="#cite_note-122">
[115]
</a>
</sup>
。
</p>
<h4>
<span id=".E5.85.AC.E8.B7.AF">
</span>
<span class="mw-headline" id="公路">
公路
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=17" title="编辑章节:公路">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h4>
<p>
中國的公路网也是以北京为中心的辐射状。多条
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E9%81%93" title="中华人民共和国国道">
中国国道
</a>
和
<a href="/wiki/%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="高速公路">
高速公路
</a>
均以北京为起点。2006年,
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E4%BA%A4%E9%80%9A%E9%83%A8" title="中華人民共和國交通部">
中華人民共和國交通部
</a>
和北京市政府共同於
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E5%AE%89%E9%96%80%E5%BB%A3%E5%A0%B4" title="天安門廣場">
天安門廣場
</a>
<a href="/wiki/%E6%AD%A3%E9%98%B3%E9%97%A8" title="正阳门">
正陽門
</a>
前設立
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%AC%E8%B7%AF%E9%9B%B6%E5%85%AC%E9%87%8C%E6%A0%87%E5%BF%97" title="中国公路零公里标志">
中國公路零公里標誌
</a>
,作为国家干线公路总起点的象征
<sup class="reference" id="cite_ref-123">
<a href="#cite_note-123">
[116]
</a>
</sup>
。
</p>
<p>
北京城區的城市道路是典型的棋盤式格局,橫平豎直,這一道路網設計始於
<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">
金
</a>
,發展於
<a href="/wiki/%E5%85%83%E6%9C%9D" title="元朝">
元
</a>
,定型於
<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">
明
</a>
<a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">
清
</a>
<sup class="reference" id="cite_ref-124">
<a href="#cite_note-124">
[117]
</a>
</sup>
。北京外圍的城市道路則是環形加放射性的格局。
</p>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks hlist collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col" style="background:#ccc;">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%B7%AF%E7%BD%91" title="Template:北京路网">
<abbr style=";background:#ccc;;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E5%8C%97%E4%BA%AC%E8%B7%AF%E7%BD%91" title="Template talk:北京路网">
<abbr style=";background:#ccc;;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%8C%97%E4%BA%AC%E8%B7%AF%E7%BD%91&action=edit">
<abbr style=";background:#ccc;;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a class="image" href="/wiki/File:Nuvola_apps_ksysv.png">
<img alt="Nuvola apps ksysv.png" data-file-height="128" data-file-width="128" decoding="async" height="25" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a3/Nuvola_apps_ksysv.png/25px-Nuvola_apps_ksysv.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a3/Nuvola_apps_ksysv.png/38px-Nuvola_apps_ksysv.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a3/Nuvola_apps_ksysv.png/50px-Nuvola_apps_ksysv.png 2x" width="25"/>
</a>
北京路网
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3" style="background:#ddd;">
<div>
参见:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%A4%E9%80%9A" title="北京市交通">
北京市交通
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="北京高速公路">
北京高速公路
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="background:#ccc; line-height:1.1em;">
主干道
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%95%BF%E5%AE%89%E8%A1%97" title="长安街">
长安街
</a>
</li>
<li>
<a href="/wiki/%E5%B9%B3%E5%AE%89%E5%A4%A7%E8%A1%97" title="平安大街">
平安大街
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E5%AE%89%E5%A4%A7%E8%A1%97_(%E5%8C%97%E4%BA%AC)" title="广安大街 (北京)">
广安大街
</a>
</li>
</ul>
</div>
</td>
<td class="navbox-image" rowspan="11" style="width:0%;padding:0px 0px 0px 2px">
<div>
<a class="image" href="/wiki/File:Beijing_Liuhuanlu.jpg" title="北京环路">
<img alt="北京环路" data-file-height="480" data-file-width="640" decoding="async" height="45" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e5/Beijing_Liuhuanlu.jpg/60px-Beijing_Liuhuanlu.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e5/Beijing_Liuhuanlu.jpg/90px-Beijing_Liuhuanlu.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e5/Beijing_Liuhuanlu.jpg/120px-Beijing_Liuhuanlu.jpg 2x" width="60"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="background:#ccc; line-height:1.1em;">
快速路
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%8C%E7%8E%AF%E8%B7%AF" title="北京二环路">
二环路
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%89%E7%8E%AF%E8%B7%AF" title="北京三环路">
三环路
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9B%9B%E7%8E%AF%E8%B7%AF" title="北京四环路">
四环路
</a>
</li>
<li>
<i>
<a class="new" href="/w/index.php?title=%E5%A7%9A%E5%AE%B6%E5%9B%AD%E8%B7%AF&action=edit&redlink=1" title="姚家园路(页面不存在)">
姚家园路
</a>
</i>
</li>
<li>
<a href="/wiki/%E9%80%9A%E6%83%A0%E6%B2%B3%E5%8C%97%E8%B7%AF" title="通惠河北路">
通惠河北路
</a>
-
<a href="/wiki/%E4%BA%AC%E9%80%9A%E5%BF%AB%E9%80%9F%E8%B7%AF" title="京通快速路">
京通快速路
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E6%B8%A0%E8%B7%AF" title="广渠路">
广渠路
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E8%B3%A2%E8%B7%AF" title="德賢路">
德贤路
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E8%8F%9C%E6%88%B7%E8%90%A5%E5%8D%97%E8%B7%AF&action=edit&redlink=1" title="菜户营南路(页面不存在)">
菜户营南路
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%B8%B0%E5%8F%B0%E5%8C%97%E8%B7%AF&action=edit&redlink=1" title="丰台北路(页面不存在)">
丰台北路
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E8%8E%B2%E7%9F%B3%E8%B7%AF&action=edit&redlink=1" title="莲石路(页面不存在)">
莲石路
</a>
</li>
<li>
<a href="/wiki/%E9%98%9C%E7%9F%B3%E8%B7%AF" title="阜石路">
阜石路
</a>
</li>
<li>
<a href="/wiki/%E7%B4%AB%E7%AB%B9%E9%99%A2%E8%B7%AF" title="紫竹院路">
紫竹院路
</a>
</li>
<li>
<a href="/wiki/%E4%B8%87%E6%B3%89%E6%B2%B3%E8%B7%AF" title="万泉河路">
万泉河路
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E8%83%9C%E9%97%A8%E5%A4%96%E5%A4%A7%E8%A1%97" title="德胜门外大街">
德胜门外大街
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E7%AB%8B%E8%B7%AF" title="安立路">
安立路
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E7%9B%B4%E9%97%A8%E5%A4%96%E5%A4%A7%E8%A1%97" title="西直门外大街">
西直门外大街
</a>
</li>
<li>
<a href="/wiki/%E5%AD%A6%E9%99%A2%E8%B7%AF_(%E5%8C%97%E4%BA%AC)" title="学院路 (北京)">
学院路
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="background:#ccc; line-height:1.1em;">
国道
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/101%E5%9B%BD%E9%81%93" title="101国道">
G101
</a>
</li>
<li>
<a href="/wiki/102%E5%9B%BD%E9%81%93" title="102国道">
G102
</a>
</li>
<li>
<a href="/wiki/103%E5%9B%BD%E9%81%93" title="103国道">
G103
</a>
</li>
<li>
<a href="/wiki/104%E5%9B%BD%E9%81%93" title="104国道">
G104
</a>
</li>
<li>
<a href="/wiki/105%E5%9B%BD%E9%81%93" title="105国道">
G105
</a>
</li>
<li>
<a href="/wiki/106%E5%9B%BD%E9%81%93" title="106国道">
G106
</a>
</li>
<li>
<a href="/wiki/107%E5%9B%BD%E9%81%93" title="107国道">
G107
</a>
</li>
<li>
<a href="/wiki/108%E5%9B%BD%E9%81%93" title="108国道">
G108
</a>
</li>
<li>
<a href="/wiki/109%E5%9B%BD%E9%81%93" title="109国道">
G109
</a>
</li>
<li>
<a href="/wiki/110%E5%9B%BD%E9%81%93" title="110国道">
G110
</a>
</li>
<li>
<a href="/wiki/111%E5%9B%BD%E9%81%93" title="111国道">
G111
</a>
</li>
<li>
<a href="/wiki/230%E5%9B%BD%E9%81%93" title="230国道">
G230
</a>
</li>
<li>
<a href="/wiki/234%E5%9B%BD%E9%81%93" title="234国道">
G234
</a>
</li>
<li>
<a href="/wiki/335%E5%9B%BD%E9%81%93" title="335国道">
G335
</a>
</li>
<li>
<a href="/wiki/509%E5%9B%BD%E9%81%93" title="509国道">
G509
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="background:#ccc; line-height:1.1em;">
省道
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="text-align:center;">
南北纵线
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E9%80%9A%E9%A1%BA%E8%B7%AF&action=edit&redlink=1" title="通顺路(页面不存在)">
S201通顺
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%9C%81%E9%81%93&action=edit&redlink=1" title="北京省道(页面不存在)">
S202张采
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%A1%BA%E5%AF%86%E8%B7%AF&action=edit&redlink=1" title="顺密路(页面不存在)">
S203顺密
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%9C%81%E9%81%93&action=edit&redlink=1" title="北京省道(页面不存在)">
S204密三
</a>
</li>
<li>
<a href="/wiki/%E5%AF%86%E5%85%B3%E8%B7%AF" title="密关路">
S205密关
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%B9%B3%E4%B8%89%E8%B7%AF&action=edit&redlink=1" title="平三路(页面不存在)">
S206平三
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%80%9A%E6%B8%85%E8%B7%AF&action=edit&redlink=1" title="通清路(页面不存在)">
S207通清(觅西)
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%98%8E%E6%B2%B3%E8%B7%AF&action=edit&redlink=1" title="阎河路(页面不存在)">
S208阎河
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E7%9F%B3%E6%8B%85%E8%B7%AF&action=edit&redlink=1" title="石担路(页面不存在)">
S209石担
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%B8%89%E6%B8%A9%E8%B7%AF&action=edit&redlink=1" title="三温路(页面不存在)">
S210三温
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%96%8B%E5%B9%BD%E8%B7%AF&action=edit&redlink=1" title="斋幽路(页面不存在)">
S211斋幽
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%98%8C%E8%B5%A4%E8%B7%AF&action=edit&redlink=1" title="昌赤路(页面不存在)">
S212昌赤
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%AE%89%E5%9B%9B%E8%B7%AF&action=edit&redlink=1" title="安四路(页面不存在)">
S213安四
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%A3%81%E5%AF%8C%E8%B7%AF&action=edit&redlink=1" title="壁富路(页面不存在)">
S214壁富
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E5%BC%80%E8%BE%85%E8%B7%AF&action=edit&redlink=1" title="京开辅路(页面不存在)">
S215京开辅路
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E8%97%8F%E8%BE%85%E8%B7%AF&action=edit&redlink=1" title="京藏辅路(页面不存在)">
S216京藏辅路
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%BA%B7%E5%BC%A0%E8%B7%AF&action=edit&redlink=1" title="康张路(页面不存在)">
S217康张
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%B8%A9%E5%8D%97%E8%B7%AF&action=edit&redlink=1" title="温南路(页面不存在)">
S218温南
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8D%97%E9%9B%81%E8%B7%AF&action=edit&redlink=1" title="南雁路(页面不存在)">
S219南雁
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%B2%81%E5%9D%A8%E8%B7%AF&action=edit&redlink=1" title="鲁坨路(页面不存在)">
S220鲁坨
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%AD%94%E5%85%B4%E8%B7%AF&action=edit&redlink=1" title="孔兴路(页面不存在)">
S221孔兴
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%B4%94%E6%9D%8F%E8%B7%AF&action=edit&redlink=1" title="崔杏路(页面不存在)">
S222崔杏
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%BC%B7%E6%B0%B8%E8%B7%AF&action=edit&redlink=1" title="漷永路(页面不存在)">
S223漷永
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%9C%A8%E7%87%95%E8%B7%AF&action=edit&redlink=1" title="木燕路(页面不存在)">
S224木燕
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA%E4%B8%9C%E8%B7%AF&action=edit&redlink=1" title="首都机场东路(页面不存在)">
S225机场东
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%A9%AC%E6%9C%B1%E8%B7%AF&action=edit&redlink=1" title="马朱路(页面不存在)">
S226马朱
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%9D%A8%E9%9B%81%E8%B7%AF&action=edit&redlink=1" title="杨雁路(页面不存在)">
S227杨雁
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E4%B8%AD%E8%BD%B4%E8%B7%AF" title="南中轴路">
S228南中轴
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%80%9A%E6%80%80%E8%B7%AF&action=edit&redlink=1" title="通怀路(页面不存在)">
S229通怀(宋梁)
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%B9%B3%E7%A8%8B%E8%B7%AF&action=edit&redlink=1" title="平程路(页面不存在)">
S230平程
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%B9%B3%E5%85%B4%E8%B7%AF&action=edit&redlink=1" title="平兴路(页面不存在)">
S231平兴
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%A6%AB%E5%B7%9D%E8%B7%AF&action=edit&redlink=1" title="妫川路(页面不存在)">
S232妫川
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%80%80%E9%9B%81%E8%B7%AF&action=edit&redlink=1" title="怀雁路(页面不存在)">
S233怀雁
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%BE%B7%E8%B4%A4%E8%B7%AF_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" title="德贤路 (北京)(页面不存在)">
S234德贤
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%85%AB%E5%B3%AA%E8%B7%AF&action=edit&redlink=1" title="八峪路(页面不存在)">
S235八峪
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align:center;">
东西横线
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E5%BE%90%E5%B0%B9%E8%B7%AF&action=edit&redlink=1" title="徐尹路(页面不存在)">
S301徐尹
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%80%9A%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" title="通马路(页面不存在)">
S302通马
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%BC%B7%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" title="漷马路(页面不存在)">
S303漷马
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%80%9A%E6%88%BF%E8%B7%AF&action=edit&redlink=1" title="通房路(页面不存在)">
S304通房
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%A1%BA%E5%B9%B3%E8%B7%AF&action=edit&redlink=1" title="顺平路(页面不存在)">
S305顺平
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%AD%A6%E5%85%B4%E8%B7%AF&action=edit&redlink=1" title="武兴路(页面不存在)">
S306武兴
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%88%98%E7%94%B0%E8%B7%AF&action=edit&redlink=1" title="刘田路(页面不存在)">
S307刘田
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%80%80%E9%95%BF%E8%B7%AF&action=edit&redlink=1" title="怀长路(页面不存在)">
S308怀长
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%BB%A6%E8%B5%A4%E8%B7%AF&action=edit&redlink=1" title="滦赤路(页面不存在)">
S309滦赤
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E7%90%89%E8%BE%9B%E8%B7%AF&action=edit&redlink=1" title="琉辛路(页面不存在)">
S310琉辛
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%AF%86%E5%85%B4%E8%B7%AF&action=edit&redlink=1" title="密兴路(页面不存在)">
S311密兴
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%9D%BE%E6%9B%B9%E8%B7%AF&action=edit&redlink=1" title="松曹路(页面不存在)">
S312松曹
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%B2%B3%E7%90%89%E8%B7%AF&action=edit&redlink=1" title="岳琉路(页面不存在)">
S313岳琉
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%B9%B3%E8%93%9F%E8%B7%AF&action=edit&redlink=1" title="平蓟路(页面不存在)">
S314平蓟
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E8%89%AF%E8%B7%AF&action=edit&redlink=1" title="京良路(页面不存在)">
S315京良
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%85%B4%E8%89%AF%E8%B7%AF&action=edit&redlink=1" title="兴良路(页面不存在)">
S316兴良
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E5%91%A8%E8%B7%AF&action=edit&redlink=1" title="京周路(页面不存在)">
S317京周
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%88%BF%E6%98%93%E8%B7%AF&action=edit&redlink=1" title="房易路(页面不存在)">
S318房易
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E8%89%AF%E5%9D%A8%E8%B7%AF&action=edit&redlink=1" title="良坨路(页面不存在)">
S319良坨
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=G108%E8%BE%85%E7%BA%BF&action=edit&redlink=1" title="G108辅线(页面不存在)">
S320京昆路复线
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%A1%BA%E6%B2%99%E8%B7%AF&action=edit&redlink=1" title="顺沙路(页面不存在)">
S321顺沙
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%BB%84%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" title="黄马路(页面不存在)">
S322黄马
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%BB%B6%E7%90%89%E8%B7%AF&action=edit&redlink=1" title="延琉路(页面不存在)">
S323延琉
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%B2%99%E9%98%B3%E8%B7%AF&action=edit&redlink=1" title="沙阳路(页面不存在)">
S324沙阳
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E8%A5%BF%E5%AE%98%E8%B7%AF&action=edit&redlink=1" title="西官路(页面不存在)">
S325西官
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%A4%A7%E4%BB%B6%E8%B7%AF&action=edit&redlink=1" title="大件路(页面不存在)">
S326大件
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%AE%9A%E6%B3%97%E8%B7%AF&action=edit&redlink=1" title="定泗路(页面不存在)">
S327定泗
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E8%89%AF%E4%B8%89%E8%B7%AF&action=edit&redlink=1" title="良三路(页面不存在)">
S328良三
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%BB%84%E4%BA%A6%E8%B7%AF&action=edit&redlink=1" title="黄亦路(页面不存在)">
S329黄亦
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%98%8C%E9%87%91%E8%B7%AF&action=edit&redlink=1" title="昌金路(页面不存在)">
S330昌金
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%A1%BA%E5%B9%B3%E5%8D%97%E7%BA%BF&action=edit&redlink=1" title="顺平南线(页面不存在)">
S331顺平南
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%BE%99%E5%A1%98%E8%B7%AF&action=edit&redlink=1" title="龙塘路(页面不存在)">
S332龙塘
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%98%8E%E5%91%A8%E8%B7%AF&action=edit&redlink=1" title="阎周路(页面不存在)">
S333阎周
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E7%99%BD%E9%A9%AC%E8%B7%AF%E8%A5%BF%E5%BB%B6&action=edit&redlink=1" title="白马路西延(页面不存在)">
S334白马西延
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E7%99%BD%E9%A9%AC%E8%B7%AF&action=edit&redlink=1" title="白马路(页面不存在)">
S335白马
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%85%B4%E4%BA%A6%E8%B7%AF&action=edit&redlink=1" title="兴亦路(页面不存在)">
S336兴亦
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8C%97%E6%B8%85%E8%B7%AF&action=edit&redlink=1" title="北清路(页面不存在)">
S337北清
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align:center;">
原等级已变更
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E5%8D%81%E4%B8%89%E9%99%B5%E6%B0%B4%E5%BA%93%E8%B7%AF&action=edit&redlink=1" title="十三陵水库路(页面不存在)">
<font color="gray">
原S214十三陵水库
</font>
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E9%80%9A%E9%A6%99%E8%B7%AF&action=edit&redlink=1" title="通香路(页面不存在)">
<font color="gray">
原S301通香
</font>
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%80%80%E6%98%8C%E8%B7%AF&action=edit&redlink=1" title="怀昌路(页面不存在)">
<font color="gray">
原S307怀昌
</font>
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%AF%86%E4%BA%91%E6%B0%B4%E5%BA%93%E5%8D%97%E8%B7%AF&action=edit&redlink=1" title="密云水库南路(页面不存在)">
<font color="gray">
原S313密云水库南
</font>
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="background:#ccc; line-height:1.1em;">
高速公路
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="text-align:auto; background:#F0FFF0 ;">
京津冀高速
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left ">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E4%BA%AC%E8%93%9F%E6%B4%A5%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京蓟津高速公路">
S3201京蓟津
</a>
(
<a href="/wiki/%E4%BA%AC%E5%B9%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京平高速公路">
京平
</a>
|
<a class="new" href="/w/index.php?title=%E8%93%9F%E5%B9%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="蓟平高速公路(页面不存在)">
蓟平
</a>
)
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E5%85%B4%E6%9C%BA%E5%9C%BA%E5%8C%97%E7%BA%BF" title="大兴机场北线">
S3300大兴机场北线
</a>
</li>
<li>
<a href="/wiki/%E4%BA%AC%E6%B4%A5%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京津高速公路">
S3301京津
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="北京大兴国际机场高速公路">
S3501大兴机场高速
</a>
</li>
<li>
<i>
<a href="/wiki/%E4%BA%AC%E8%94%9A%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京蔚高速公路">
S3701京蔚
</a>
</i>
</li>
<li>
<a href="/wiki/%E4%BA%AC%E7%A4%BC%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京礼高速公路">
S3801京礼
</a>
(
<a class="mw-redirect" href="/wiki/%E5%85%B4%E5%BB%B6%E9%AB%98%E9%80%9F" title="兴延高速">
兴延
</a>
|
<a class="mw-redirect" href="/wiki/%E5%BB%B6%E5%B4%87%E9%AB%98%E9%80%9F" title="延崇高速">
延崇
</a>
)
</li>
<li>
<i>
<a href="/wiki/%E4%BA%AC%E9%9B%84%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京雄高速公路">
京雄
</a>
</i>
</li>
<li>
<i>
<a href="/wiki/%E4%BA%AC%E5%BE%B7%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京德高速公路">
京德
</a>
(大兴南北航站楼联络线)
</i>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align:auto; background:#F0FFF0 ;">
国道沿线高速
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left ">
<div style="padding:0em 0.25em">
<ul>
<li>
<i>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E5%AF%86%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="京密高速公路(页面不存在)">
G101京密
</a>
</i>
</li>
<li>
<a href="/wiki/%E9%80%9A%E7%87%95%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="通燕高速公路">
G102通燕
</a>
</li>
<li>
<a href="/wiki/%E4%BA%AC%E9%80%9A%E5%BF%AB%E9%80%9F%E8%B7%AF" title="京通快速路">
G103京通
</a>
</li>
<li>
<a href="/wiki/%E4%BA%AC%E5%BC%80%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京开高速公路">
G106京开
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align:auto; background:#F0FFF0 ;">
省级高速公路
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left ">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京承高速公路">
S11京承
</a>
</li>
<li>
<a href="/wiki/%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="首都机场高速公路">
S12首都机场高速
</a>
</li>
<li>
<i>
<a class="new" href="/w/index.php?title=%E6%98%8C%E8%B0%B7%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="昌谷高速公路(页面不存在)">
S26昌谷
</a>
</i>
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%9C%BA%E5%9C%BA%E5%8C%97%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="北京机场北线高速公路">
S28首都机场北线
</a>
</li>
<li>
<i>
<a class="new" href="/w/index.php?title=%E5%AF%86%E9%87%87%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="密采高速公路(页面不存在)">
S41密采
</a>
</i>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E9%80%9A%E9%80%9A%E7%87%95%E8%81%94%E7%BB%9C%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="京通通燕联络线高速公路(页面不存在)">
S46京通通燕联络线
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%94%E7%8E%AF%E8%B7%AF" title="北京五环路">
S50五环路
</a>
</li>
<li>
<a href="/wiki/%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA%E7%AC%AC%E4%BA%8C%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="首都机场第二高速公路">
S51首都机场二高速
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E6%98%86%E9%AB%98%E9%80%9F%E8%81%94%E7%BB%9C%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="京昆高速联络线高速公路(页面不存在)">
S66京昆联络线
</a>
</li>
<li>
<i>
<a class="new" href="/w/index.php?title=%E7%87%95%E9%87%87%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="燕采高速公路(页面不存在)">
S76燕采
</a>
</i>
</li>
<li>
<i>
<a href="/wiki/%E5%AF%86%E6%B6%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="密涿高速公路">
S80密涿
</a>
</i>
</li>
<li>
<i>
<a class="new" href="/w/index.php?title=%E4%BA%91%E9%87%87%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF&action=edit&redlink=1" title="云采高速公路(页面不存在)">
S86云采
</a>
</i>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align:auto; background:#F0FFF0 ;">
国家高速公路
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;width:auto; text-align:left ">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E4%BA%AC%E5%93%88%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京哈高速公路">
G1京哈
</a>
(
<a href="/wiki/%E4%BA%AC%E7%80%8B%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京瀋高速公路">
京沈
</a>
)
</li>
<li>
<a href="/wiki/%E4%BA%AC%E7%A7%A6%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京秦高速公路">
G01
<sub>
21
</sub>
京秦
</a>
</li>
<li>
<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京沪高速公路">
G2京沪
</a>
(
<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%A1%98%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京津塘高速公路">
京津塘
</a>
)
</li>
<li>
<a href="/wiki/%E4%BA%AC%E5%8F%B0%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京台高速公路">
G3京台
</a>
</li>
<li>
<a href="/wiki/%E4%BA%AC%E6%B8%AF%E6%BE%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京港澳高速公路">
G4京港澳
</a>
(
<a href="/wiki/%E4%BA%AC%E7%9F%B3%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京石高速公路">
京石
</a>
)
</li>
<li>
<a href="/wiki/%E4%BA%AC%E6%98%86%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京昆高速公路">
G5京昆
</a>
(
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E7%9F%B3%E7%AC%AC%E4%BA%8C%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京石第二高速公路">
京石二高速
</a>
)
</li>
<li>
<a href="/wiki/%E4%BA%AC%E8%97%8F%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京藏高速公路">
G6京藏
</a>
(
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E5%BC%A0%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京张高速公路">
京张
</a>
|
<a href="/wiki/%E5%85%AB%E8%BE%BE%E5%B2%AD%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="八达岭高速公路">
八达岭
</a>
)
</li>
<li>
<a href="/wiki/%E4%BA%AC%E6%96%B0%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京新高速公路">
G7京新
</a>
(
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E5%8C%85%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京包高速公路">
京包
</a>
)
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%B9%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="大广高速公路">
G45大广
</a>
(部分含
<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京承高速公路">
京承
</a>
、
<a href="/wiki/%E4%BA%AC%E5%BC%80%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="京开高速公路">
京开
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AD%E7%8E%AF%E8%B7%AF" title="北京六环路">
六环路
</a>
)
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AD%E7%8E%AF%E8%B7%AF" title="北京六环路">
G45
<sub>
01
</sub>
六环路
</a>
</li>
<li>
<a href="/wiki/%E9%A6%96%E9%83%BD%E5%9C%B0%E5%8C%BA%E7%8E%AF%E7%BA%BF%E9%AB%98%E9%80%9F%E5%85%AC%E8%B7%AF" title="首都地区环线高速公路">
G95首都环线
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="background:#ccc; line-height:1.1em;">
特殊道路
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%9B%9E%E9%BE%99%E8%A7%82%E8%87%B3%E4%B8%8A%E5%9C%B0%E8%87%AA%E8%A1%8C%E8%BD%A6%E4%B8%93%E7%94%A8%E8%B7%AF" title="回龙观至上地自行车专用路">
回龙观至上地自行车专用路
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3" style="background:#ddd;">
<div>
<center>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%90%84%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E6%99%AE%E9%80%9A%E5%9B%BD%E7%9C%81%E5%B9%B2%E7%BA%BF%E5%85%AC%E8%B7%AF" title="Template:中华人民共和国各省级行政区普通国省干线公路">
中国普通省道
</a>
:
<a class="mw-redirect" href="/wiki/Template:%E5%8C%97%E4%BA%AC%E5%85%AC%E8%B7%AF%E7%BD%91" title="Template:北京公路网">
京
</a>
|
<a class="new" href="/w/index.php?title=Template:%E5%A4%A9%E6%B4%A5%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:天津省道(页面不存在)">
津
</a>
|
<a class="new" href="/w/index.php?title=Template:%E6%B2%B3%E5%8C%97%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:河北省道(页面不存在)">
冀
</a>
|
<a class="new" href="/w/index.php?title=Template:%E5%B1%B1%E8%A5%BF%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:山西省道(页面不存在)">
晋
</a>
|
<a class="new" href="/w/index.php?title=Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:内蒙古自治区省道(页面不存在)">
蒙
</a>
|
<a class="new" href="/w/index.php?title=Template:%E8%BE%BD%E5%AE%81%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:辽宁省道(页面不存在)">
辽
</a>
|
<a class="new" href="/w/index.php?title=Template:%E5%90%89%E6%9E%97%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:吉林省道(页面不存在)">
吉
</a>
|
<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81%E9%81%93" title="Template:黑龙江省道">
黑
</a>
|
<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E7%9C%81%E9%81%93" title="Template:上海省道">
沪
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E7%9C%81%E9%81%93" title="Template:江苏省道">
苏
</a>
|
<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E7%9C%81%E9%81%93" title="Template:浙江省道">
浙
</a>
|
<a class="new" href="/w/index.php?title=Template:%E5%B1%B1%E4%B8%9C%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:山东省道(页面不存在)">
鲁
</a>
|
<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E7%9C%81%E9%81%93" title="Template:安徽省道">
皖
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E7%9C%81%E9%81%93" title="Template:江西省道">
赣
</a>
|
<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E7%9C%81%E9%81%93" title="Template:福建省道">
闽
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E7%9C%81%E9%81%93" title="Template:河南省道">
豫
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E7%9C%81%E9%81%93" title="Template:湖北省道">
鄂
</a>
|
<a class="new" href="/w/index.php?title=Template:%E6%B9%96%E5%8D%97%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:湖南省道(页面不存在)">
湘
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E7%9C%81%E9%81%93" title="Template:广东省道">
粤
</a>
|
<a class="new" href="/w/index.php?title=Template:%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:广西壮族自治区省道(页面不存在)">
桂
</a>
|
<a class="new" href="/w/index.php?title=Template:%E6%B5%B7%E5%8D%97%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:海南省道(页面不存在)">
琼
</a>
|
<a class="new" href="/w/index.php?title=Template:%E9%87%8D%E5%BA%86%E5%B8%82%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:重庆市省道(页面不存在)">
渝
</a>
|
<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E7%9C%81%E9%81%93" title="Template:四川省道">
川
</a>
|
<a class="new" href="/w/index.php?title=Template:%E8%B4%B5%E5%B7%9E%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:贵州省道(页面不存在)">
贵
</a>
|
<a class="new" href="/w/index.php?title=Template:%E4%BA%91%E5%8D%97%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:云南省道(页面不存在)">
滇
</a>
|
<a class="new" href="/w/index.php?title=Template:%E8%A5%BF%E8%97%8F%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:西藏省道(页面不存在)">
藏
</a>
|
<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E7%9C%81%E9%81%93" title="Template:陕西省道">
陕
</a>
|
<a class="new" href="/w/index.php?title=Template:%E7%94%98%E8%82%83%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:甘肃省道(页面不存在)">
甘
</a>
|
<a class="new" href="/w/index.php?title=Template:%E9%9D%92%E6%B5%B7%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:青海省道(页面不存在)">
青
</a>
|
<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA%E7%9C%81%E9%81%93" title="Template:宁夏回族自治区省道">
宁
</a>
|
<a class="new" href="/w/index.php?title=Template:%E6%96%B0%E7%96%86%E7%9C%81%E9%81%93&action=edit&redlink=1" title="Template:新疆省道(页面不存在)">
新
</a>
| 港 | 澳 |
<i>
<a href="/wiki/Template:%E5%8F%B0%E7%81%A3%E7%9C%81%E9%81%93" title="Template:台灣省道">
台
</a>
</i>
</center>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<h4>
<span id=".E9.93.81.E8.B7.AF">
</span>
<span class="mw-headline" id="铁路">
铁路
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=18" title="编辑章节:铁路">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h4>
<div class="hatnote navigation-not-searchable" role="note">
参见:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%93%81%E8%B7%AF%E6%9E%A2%E7%BA%BD" title="北京铁路枢纽">
北京铁路枢纽
</a>
和
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">
北京地铁
</a>
</div>
<p>
北京長期以來就是
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E9%90%B5%E8%B7%AF%E9%81%8B%E8%BC%B8" title="中華人民共和國鐵路運輸">
中國鐵路
</a>
網的中心。北京铁路的历史可追溯至
<a class="mw-redirect" href="/wiki/%E6%99%9A%E6%B8%85" title="晚清">
晚清
</a>
,最早的铁路是由
<a href="/wiki/%E8%A9%B9%E5%A4%A9%E4%BD%91" title="詹天佑">
詹天佑
</a>
主持修建的
<a href="/wiki/%E4%BA%AC%E5%BC%A0%E9%93%81%E8%B7%AF" title="京张铁路">
京张铁路
</a>
,于1909年竣工,是第一条中国人自主修建的铁路。截至2018年底,北京共拥有1103公里的国家铁路
<sup class="reference" id="cite_ref-19年鉴_125-0">
<a href="#cite_note-19年鉴-125">
[118]
</a>
</sup>
,普速铁路方面,
<a href="/wiki/%E4%BA%AC%E5%93%88%E9%93%81%E8%B7%AF" title="京哈铁路">
京哈线
</a>
、
<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%93%81%E8%B7%AF" title="京沪铁路">
京沪线
</a>
、
<a href="/wiki/%E4%BA%AC%E4%B9%9D%E9%93%81%E8%B7%AF" title="京九铁路">
京九线
</a>
、
<a href="/wiki/%E4%BA%AC%E5%B9%BF%E9%93%81%E8%B7%AF" title="京广铁路">
京广线
</a>
、
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E5%8E%9F%E7%BA%BF" title="京原线">
京原线
</a>
、
<a href="/wiki/%E4%BA%AC%E5%8C%85%E9%93%81%E8%B7%AF" title="京包铁路">
京包线
</a>
、
<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%93%81%E8%B7%AF" title="京承铁路">
京承线
</a>
、
<a href="/wiki/%E4%BA%AC%E9%80%9A%E9%93%81%E8%B7%AF" title="京通铁路">
京通线
</a>
、
<a href="/wiki/%E4%B8%B0%E6%B2%99%E9%93%81%E8%B7%AF" title="丰沙铁路">
丰沙线
</a>
等铁路干线均汇集于此,另外
<a href="/wiki/%E5%A4%A7%E7%A7%A6%E9%93%81%E8%B7%AF" title="大秦铁路">
大秦线
</a>
亦途经北京。而經過北京的國際及跨境列車則可以連接
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港
</a>
、
<a href="/wiki/%E8%92%99%E5%8F%A4%E5%9B%BD" title="蒙古国">
蒙古
</a>
、
<a class="mw-redirect" href="/wiki/%E4%BF%84%E7%BE%85%E6%96%AF" title="俄羅斯">
俄羅斯
</a>
、
<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">
越南
</a>
及
<a href="/wiki/%E6%9C%9D%E9%B2%9C%E6%B0%91%E4%B8%BB%E4%B8%BB%E4%B9%89%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="朝鲜民主主义人民共和国">
北韓
</a>
等國家和地區。
<a href="/wiki/%E9%AB%98%E9%80%9F%E9%90%B5%E8%B7%AF" title="高速鐵路">
高速鐵路
</a>
方面,北京已建成
<a href="/wiki/%E4%BA%AC%E6%B4%A5%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京津城际铁路">
京津城际鐵路
</a>
、
<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%AB%98%E9%80%9F%E9%93%81%E8%B7%AF" title="京沪高速铁路">
京沪高速铁路
</a>
、
<a href="/wiki/%E4%BA%AC%E5%B9%BF%E9%AB%98%E9%80%9F%E9%93%81%E8%B7%AF" title="京广高速铁路">
京广高速铁路
</a>
、
<a href="/wiki/%E4%BA%AC%E9%9B%84%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京雄城际铁路">
京雄城际铁路
</a>
、
<a href="/wiki/%E4%BA%AC%E5%BC%A0%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京张城际铁路">
京张城际铁路
</a>
,并有
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E6%B2%88%E9%AB%98%E9%80%9F%E9%93%81%E8%B7%AF" title="京沈高速铁路">
京沈高速铁路
</a>
、
<a href="/wiki/%E4%BA%AC%E5%94%90%E5%9F%8E%E9%99%85%E9%93%81%E8%B7%AF" title="京唐城际铁路">
京唐城际铁路
</a>
等线路在建。
</p>
<p>
北京规划的10个全国客运枢纽
<sup class="reference" id="cite_ref-2035总规_126-0">
<a href="#cite_note-2035总规-126">
[119]
</a>
</sup>
中8个为铁路客运枢纽,已建成的包括
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">
北京站
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">
北京西站
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E7%AB%99" title="北京南站">
北京南站
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8C%97%E7%AB%99" title="北京北站">
北京北站
</a>
和
<a href="/wiki/%E6%B8%85%E6%B2%B3%E7%AB%99" title="清河站">
清河站
</a>
,另有
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%9C%9D%E9%98%B3%E7%AB%99" title="北京朝阳站">
北京朝阳站
</a>
、
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E7%AB%99" title="丰台站">
丰台站
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8%AD%E5%BF%83%E7%AB%99" title="北京城市副中心站">
北京城市副中心站
</a>
在建,这些
<a class="mw-redirect" href="/wiki/%E7%81%AB%E8%BB%8A%E7%AB%99" title="火車站">
火車站
</a>
同時也都是北京市城市交通的重要樞紐。
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">
北京站
</a>
和
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">
北京西站
</a>
之間有
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E4%B8%8B%E7%9B%B4%E5%BE%84%E7%BA%BF" title="北京地下直径线">
地下鐵路
</a>
連接。
</p>
<p>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">
北京站
</a>
是北京建設最早的大型铁路客运站,在
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">
北京西站
</a>
建成以前,北京站是北京最重要的车站,也是全亞洲客流量最大的车站,長期超负荷运转。1996年竣工的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">
北京西站
</a>
大大缓解了北京站的压力,目前北京西站主要負責
<a href="/wiki/%E4%BA%AC%E4%B9%9D%E9%93%81%E8%B7%AF" title="京九铁路">
京九线
</a>
和
<a href="/wiki/%E4%BA%AC%E5%B9%BF%E9%93%81%E8%B7%AF" title="京广铁路">
京广线
</a>
等路线的旅客列车客运业务,而原有的北京站則主要负责
<a href="/wiki/%E4%BA%AC%E5%93%88%E9%93%81%E8%B7%AF" title="京哈铁路">
京哈线
</a>
、
<a href="/wiki/%E4%BA%AC%E6%B2%AA%E9%93%81%E8%B7%AF" title="京沪铁路">
京沪线
</a>
、
<a href="/wiki/%E4%BA%AC%E6%89%BF%E9%93%81%E8%B7%AF" title="京承铁路">
京承线
</a>
和
<a href="/wiki/%E4%B8%B0%E6%B2%99%E9%93%81%E8%B7%AF" title="丰沙铁路">
丰沙线
</a>
等路线的大多数旅客列车客运业务。截至2009年5月1日,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E7%AB%99" title="北京西站">
北京西站
</a>
每日有220車次始發或經停,而
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%AB%99" title="北京站">
北京站
</a>
則有177車次。
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">
北京地铁
</a>
2号线途经北京站,而
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%819%E5%8F%B7%E7%BA%BF" title="北京地铁9号线">
北京地鐵9號线
</a>
和
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%817%E5%8F%B7%E7%BA%BF" title="北京地铁7号线">
北京地鐵7號线
</a>
都通過北京西站。在北京站和北京西站的附近,還設有諸多公交车的總站。2008年改造完成的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E7%AB%99" title="北京南站">
北京南站
</a>
,是
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E6%B4%A5%E5%9F%8E%E9%9A%9B%E9%90%B5%E8%B7%AF" title="京津城際鐵路">
京津城際鐵路
</a>
和
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E6%BB%AC%E9%AB%98%E9%80%9F%E9%90%B5%E8%B7%AF" title="京滬高速鐵路">
京滬高速鐵路
</a>
的起點和終點站。
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%814%E5%8F%B7%E7%BA%BF" title="北京地铁4号线">
北京地鐵4號线
</a>
接駁
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E7%AB%99" title="北京南站">
北京南站
</a>
地下月臺,可以實現無縫換乘,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%8114%E5%8F%B7%E7%BA%BF" title="北京地铁14号线">
北京地铁14号线
</a>
亦途径北京南站。
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8C%97%E7%AB%99" title="北京北站">
北京北站
</a>
主要负责
<a href="/wiki/%E4%BA%AC%E5%8C%85%E5%AE%A2%E8%BF%90%E4%B8%93%E7%BA%BF" title="京包客运专线">
京包客运专线
</a>
和
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E9%83%8A%E9%93%81%E8%B7%AF" title="北京市郊铁路">
北京市郊铁路
</a>
的旅客列车客运业务,也是西直門交通樞紐的重要組成部分。在北京北站可以换乘北京地铁2号线、4号线和13号线。
</p>
<p>
北京市其他主要铁路客运站還有
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%9C%E7%AB%99" title="北京东站">
北京東站
</a>
、
<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%97%E7%AB%99" title="昌平北站">
昌平北站
</a>
、
<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%97%E7%AB%99" title="怀柔北站">
怀柔北站
</a>
、
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%97%E7%AB%99" title="密云北站">
密云北站
</a>
、
<a href="/wiki/%E9%80%9A%E5%B7%9E%E8%A5%BF%E7%AB%99" title="通州西站">
通州西站
</a>
、
<a href="/wiki/%E9%BB%84%E6%9D%91%E7%AB%99_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="黄村站 (北京市)">
黃村站
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E7%AB%99" title="北京大兴站">
北京大兴站
</a>
、
<a href="/wiki/%E5%A4%A7%E5%85%B4%E6%9C%BA%E5%9C%BA%E7%AB%99" title="大兴机场站">
大兴机场站
</a>
等车站。
在北京乘坐列车与购买火车票十分便捷,火车票代售点的数量为全中国第二,僅次於
<a class="mw-redirect" href="/wiki/%E5%BB%A3%E6%9D%B1%E7%9C%81" title="廣東省">
廣東省
</a>
<sup class="reference" id="cite_ref-127">
<a href="#cite_note-127">
[120]
</a>
</sup>
,在各火車站还设有自动售取票机以方便旅客购买火车票和打印网络购买的火车票。持有第二代
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%B1%85%E6%B0%91%E8%BA%AB%E4%BB%BD%E8%AF%81" title="中华人民共和国居民身份证">
中华人民共和国居民身份证
</a>
、
<a href="/wiki/%E6%B8%AF%E6%BE%B3%E5%8F%B0%E5%B1%85%E6%B0%91%E5%B1%85%E4%BD%8F%E8%AF%81" title="港澳台居民居住证">
港澳台居民居住证
</a>
、
<a class="mw-redirect" href="/wiki/%E5%A4%96%E5%9B%BD%E4%BA%BA%E6%B0%B8%E4%B9%85%E5%B1%85%E7%95%99%E8%BA%AB%E4%BB%BD%E8%AF%81" title="外国人永久居留身份证">
外国人永久居留身份证
</a>
的旅客也可直接在北京开行高铁、城际、动车组列车的火车站刷相应的证件乘坐高铁列车(G字头车次)、城际列车(C字头车次)和动车组列车(D字头车次),而无需持纸质火车票乘车。
</p>
<p>
北京是
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B" title="中華人民共和國">
中国
</a>
第一座建设
<a class="mw-redirect" href="/wiki/%E5%9C%B0%E9%93%81" title="地铁">
地铁
</a>
的城市,始建于1965年7月1日。截止2019年底,
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81" title="北京地铁">
北京地铁
</a>
共有22条运营线路(包括2条机场轨道),
线路全长699
<a href="/wiki/%E5%85%AC%E9%87%8C" title="公里">
公里
</a>
<sup class="reference" id="cite_ref-19年公报_120-1">
<a href="#cite_note-19年公报-120">
[113]
</a>
</sup>
,运营车站339座(换乘站不重复计算)。北京地鐵日均客流量突破1000萬人,并且在2017年4月28日创下单日客运量最高值,达到1280.27万人次,为世界最为繁忙的
<a class="mw-redirect" href="/wiki/%E5%9F%8E%E5%B8%82%E8%BD%A8%E9%81%93%E4%BA%A4%E9%80%9A%E7%B3%BB%E7%BB%9F" title="城市轨道交通系统">
城市轨道交通系统
</a>
<sup class="reference" id="cite_ref-128">
<a href="#cite_note-128">
[121]
</a>
</sup>
。北京地鐵正在進行大規模建設,预计到2021年全市
<a class="mw-redirect" href="/wiki/%E8%BB%8C%E9%81%93%E4%BA%A4%E9%80%9A" title="軌道交通">
轨道交通
</a>
总里程将超过1000公里。
</p>
<h4>
<span id=".E8.88.AA.E7.A9.BA">
</span>
<span class="mw-headline" id="航空">
航空
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=19" title="编辑章节:航空">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h4>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E6%A9%9F%E5%A0%B4" title="北京機場">
北京機場
</a>
</div>
<div class="thumb tright">
<div class="thumbinner" style="width:222px;">
<a class="image" href="/wiki/File:Beijing_Capital_International_Airport_Terminal_2_20120915.JPG">
<img alt="" class="thumbimage" data-file-height="1600" data-file-width="2560" decoding="async" height="138" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Beijing_Capital_International_Airport_Terminal_2_20120915.JPG/220px-Beijing_Capital_International_Airport_Terminal_2_20120915.JPG" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Beijing_Capital_International_Airport_Terminal_2_20120915.JPG/330px-Beijing_Capital_International_Airport_Terminal_2_20120915.JPG 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Beijing_Capital_International_Airport_Terminal_2_20120915.JPG/440px-Beijing_Capital_International_Airport_Terminal_2_20120915.JPG 2x" width="220"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Beijing_Capital_International_Airport_Terminal_2_20120915.JPG" title="放大">
</a>
</div>
北京首都国际机场2号航站楼外观
</div>
</div>
</div>
<div class="thumb tright">
<div class="thumbinner" style="width:222px;">
<a class="image" href="/wiki/File:Beijing_New_Airport.jpg">
<img alt="" class="thumbimage" data-file-height="2962" data-file-width="5272" decoding="async" height="124" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Beijing_New_Airport.jpg/220px-Beijing_New_Airport.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Beijing_New_Airport.jpg/330px-Beijing_New_Airport.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/2b/Beijing_New_Airport.jpg/440px-Beijing_New_Airport.jpg 2x" width="220"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Beijing_New_Airport.jpg" title="放大">
</a>
</div>
北京大興國際機場於2019年9月25日正式投入營運,為北京市的第二座国际机场
</div>
</div>
</div>
<p>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E9%A6%96%E9%83%BD%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" title="北京首都國際機場">
北京首都國際機場
</a>
是中國地理位置重要的機場之一,位於顺義區(行政上由順義和朝陽二區共管),距離北京城區20公里。也是該市重要門戶,目前有三個航站、三條跑道、雙塔台、設計客運量為8200萬人次。幾經擴建,首都機場的第三航廈為目前世界第二大的單體
<a class="mw-redirect" href="/wiki/%E8%88%AA%E5%BB%88" title="航廈">
航廈
</a>
<sup class="reference" id="cite_ref-129">
<a href="#cite_note-129">
[122]
</a>
</sup>
,同時也是中國國內擁有三條跑道的三個
<a class="mw-redirect" href="/wiki/%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" title="國際機場">
國際機場
</a>
之一(另兩個為
<a class="mw-redirect" href="/wiki/%E4%B8%8A%E6%B5%B7%E6%B5%A6%E6%9D%B1%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" title="上海浦東國際機場">
上海浦東國際機場
</a>
、
<a class="mw-redirect" href="/wiki/%E5%BB%A3%E5%B7%9E%E7%99%BD%E9%9B%B2%E5%9C%8B%E9%9A%9B%E6%A9%9F%E5%A0%B4" title="廣州白雲國際機場">
廣州白雲國際機場
</a>
)
<sup class="reference" id="cite_ref-130">
<a href="#cite_note-130">
[123]
</a>
</sup>
,作为中国四大门户枢纽机场之首,北京首都國際機場每天有超過70家航空公司的1,400個航班,與世界191個城市串聯。
2018年数据统计,首都机场旅客吞吐量超过1亿人次,为客運量居亚洲第一、世界第二的單一機場,如果以城市來看,略少於上海國內線
<a class="mw-redirect" href="/wiki/%E8%99%B9%E6%A9%8B%E6%A9%9F%E5%A0%B4" title="虹橋機場">
虹橋機場
</a>
和國際線
<a class="mw-redirect" href="/wiki/%E6%B5%A6%E6%9D%B1%E6%A9%9F%E5%A0%B4" title="浦東機場">
浦東機場
</a>
的運量總和(1.2亿人次),以及東京國內線
<a class="mw-redirect" href="/wiki/%E7%BE%BD%E7%94%B0%E6%A9%9F%E5%A0%B4" title="羽田機場">
羽田機場
</a>
和國際線
<a class="mw-redirect" href="/wiki/%E6%88%90%E7%94%B0%E6%A9%9F%E5%A0%B4" title="成田機場">
成田機場
</a>
的運量總和(1億700萬)。
</p>
<p>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA" title="北京大兴国际机场">
北京大兴国际机场
</a>
是北京市的第二个国际机场,为华北地区重要的国际机场,位於
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E8%88%88%E5%8D%80" title="大興區">
大興區
</a>
(行政上由
<a class="mw-selflink selflink">
北京市
</a>
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E8%88%88%E5%8D%80" title="大興區">
大興區
</a>
和
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北省
</a>
<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">
廊坊市
</a>
共管),距離北京城區46公里。大興機場目前擁有世界最大的單體
<a class="mw-redirect" href="/wiki/%E8%88%AA%E5%BB%88" title="航廈">
航廈
</a>
。大興機場將定位為大型國際航空樞紐,目前共有4條營運中的跑道(據遠程規劃將擴建至6條跑道),滿足年旅客吞吐量一億人次需求。机场及各項配套工程于2019年6月30日竣工验收,同年9月25日投入營運。
</p>
<p>
除此之外,北京市另有數個規模相對較小的機場,包括:
</p>
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%8D%97%E8%8B%91%E6%A9%9F%E5%A0%B4" title="北京南苑機場">
北京南苑機場
</a>
:建於1910年,位北京南郊,距市中心12公里,曾是中國聯合航空作为基地运营少量民航班机的军民两用機場,在大兴机场启用后已关闭。
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%A5%BF%E9%83%8A%E6%A9%9F%E5%A0%B4" title="北京西郊機場">
北京西郊機場
</a>
:軍用機場,供中國國家領導人、黨政軍要員使用,不對民眾開放。
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%89%AF%E4%B9%A1%E6%9C%BA%E5%9C%BA" title="北京良乡机场">
北京良鄉機場
</a>
:軍用機場,規劃改為軍民貨運機場。
</li>
</ul>
<h4>
<span id=".E5.9C.B0.E9.9D.A2.E5.85.AC.E4.BA.A4">
</span>
<span class="mw-headline" id="地面公交">
地面公交
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=20" title="编辑章节:地面公交">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h4>
<p>
為緩解城市
<a class="mw-redirect" href="/wiki/%E4%BA%A4%E9%80%9A%E6%8B%A5%E5%A0%B5" title="交通拥堵">
交通擁堵
</a>
問題及改善空氣質量,北京市自2005年起開始制定並實施優先發展
<a href="/wiki/%E5%85%AC%E5%85%B1%E4%BA%A4%E9%80%9A" title="公共交通">
公共交通
</a>
的政策
<sup class="reference" id="cite_ref-131">
<a href="#cite_note-131">
[124]
</a>
</sup>
。
</p>
<p>
1899年北京修建了中國第一條
<a href="/wiki/%E6%9C%89%E8%BB%8C%E9%9B%BB%E8%BB%8A" title="有軌電車">
有軌電車
</a>
,1935年又開闢了第一條
<a href="/wiki/%E5%85%AC%E5%85%B1%E6%B1%BD%E8%BB%8A" title="公共汽車">
公共汽車
</a>
线路,1956年開通第一條
<a href="/wiki/%E7%84%A1%E8%BB%8C%E9%9B%BB%E8%BB%8A" title="無軌電車">
無軌電車
</a>
線路。經過長期,尤其是近年快速的發展,北京公交已擁有各类运营车辆近3万辆,运营线路1158條(2019年),线网总长27632公里(2019年
<sup class="reference" id="cite_ref-19年公报_120-2">
<a href="#cite_note-19年公报-120">
[113]
</a>
</sup>
),年总行驶里程17.53亿公里(2011年),总客运量客运总量48.88亿人次(2011年數據)。
</p>
<h4>
<span id=".E5.87.BA.E7.A7.9F.E8.BD.A6">
</span>
<span class="mw-headline" id="出租车">
出租车
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=21" title="编辑章节:出租车">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h4>
<p>
据统计,截至2006年4月,北京市黑车的数量甚至已经超过了合法的出租车数量
<sup class="reference" id="cite_ref-132">
<a href="#cite_note-132">
[125]
</a>
</sup>
。2020年,北京市出租车总数约为7万辆
<sup class="reference" id="cite_ref-133">
<a href="#cite_note-133">
[126]
</a>
</sup>
。
</p>
<h4>
<span id=".E9.82.AE.E7.94.B5">
</span>
<span class="mw-headline" id="邮电">
邮电
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=22" title="编辑章节:邮电">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h4>
<p>
2015年全年,北京货运量28765.2万吨,客运量69923.1万人。年末全市机动车保有量561.9万辆,民用汽车535万辆。其中,私人汽车440.3万辆,私人汽车中轿车316.5万辆。全年实现邮电业务总量990.9亿元。其中,邮政业务总量67.8亿元,电信业务总量923亿元。全年发送邮政函件6.1亿件,特快专递14.1亿件。年末固定电话用户达到784.6万户,固定电话主线普及率达到36.1线/百人。年末移动电话用户达到4051.9万户,移动电话普及率达到186.7户/百人。年末固定互联网宽带接入用户数达到469.1万户。
<sup class="reference" id="cite_ref-2015公报_114-1">
<a href="#cite_note-2015公报-114">
[108]
</a>
</sup>
</p>
<h3>
<span id=".E6.97.85.E6.B8.B8.E6.A5.AD">
</span>
<span class="mw-headline" id="旅游業">
旅游業
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=23" title="编辑章节:旅游業">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<div class="hatnote navigation-not-searchable" role="note">
参见:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%97%85%E6%B8%B8%E6%99%AF%E7%82%B9%E5%88%97%E8%A1%A8" title="北京旅游景点列表">
北京旅游景点列表
</a>
</div>
<p>
北京市拥有丰富的旅游资源,包括2处
<a class="mw-redirect" href="/wiki/%E5%9B%BD%E5%AE%B6%E9%87%8D%E7%82%B9%E9%A3%8E%E6%99%AF%E5%90%8D%E8%83%9C%E5%8C%BA" title="国家重点风景名胜区">
国家重点风景名胜区
</a>
、1座
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="国家历史文化名城">
国家历史文化名城
</a>
、1座
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E6%9D%91" title="中国历史文化名村">
中国历史文化名村
</a>
、99处
<a href="/wiki/%E5%85%A8%E5%9B%BD%E9%87%8D%E7%82%B9%E6%96%87%E7%89%A9%E4%BF%9D%E6%8A%A4%E5%8D%95%E4%BD%8D" title="全国重点文物保护单位">
全国重点文物保护单位
</a>
(含
<a href="/wiki/%E9%95%BF%E5%9F%8E" title="长城">
长城
</a>
和
<a href="/wiki/%E4%BA%AC%E6%9D%AD%E5%A4%A7%E8%BF%90%E6%B2%B3" title="京杭大运河">
京杭大运河
</a>
的北京段)、326处
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E6%96%87%E7%89%A9%E4%BF%9D%E6%8A%A4%E5%8D%95%E4%BD%8D" title="北京市文物保护单位">
市级文物保护单位
</a>
等。全市共有7处
<a href="/wiki/%E4%B8%96%E7%95%8C%E9%81%97%E4%BA%A7" title="世界遗产">
世界遗产
</a>
,是世界上世界遗产最多的城市。这七处是:
<a href="/wiki/%E9%95%BF%E5%9F%8E" title="长城">
长城
</a>
、明清皇家宫殿的
<a href="/wiki/%E6%95%85%E5%AE%AB" title="故宫">
故宫
</a>
、北京的皇家园林的
<a href="/wiki/%E9%A2%90%E5%92%8C%E5%9B%AD" title="颐和园">
颐和园
</a>
、北京的皇家祭坛的
<a href="/wiki/%E5%A4%A9%E5%9D%9B" title="天坛">
天坛
</a>
、
<a href="/wiki/%E6%98%8E%E6%B8%85%E7%9A%87%E5%AE%B6%E9%99%B5%E5%AF%9D" title="明清皇家陵寝">
明清皇家陵寝
</a>
的
<a class="mw-redirect" href="/wiki/%E5%8D%81%E4%B8%89%E9%99%B5" title="十三陵">
十三陵
</a>
、
<a class="mw-redirect" href="/wiki/%E5%91%A8%E5%8F%A3%E5%BA%97" title="周口店">
周口店
</a>
北京猿人遗址以及
<a href="/wiki/%E4%BA%AC%E6%9D%AD%E5%A4%A7%E8%BF%90%E6%B2%B3" title="京杭大运河">
京杭大运河
</a>
。北京市于2018年全面启动
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E8%BD%B4%E7%BA%BF" title="北京中轴线">
中轴线
</a>
整治规划,计划于2030年将
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E8%BD%B4%E7%BA%BF" title="北京中轴线">
北京城中轴线
</a>
申报
<a class="mw-redirect" href="/wiki/%E4%B8%96%E7%95%8C%E6%96%87%E5%8C%96%E9%81%97%E4%BA%A7" title="世界文化遗产">
世界文化遗产
</a>
。国家重点风景名胜区有
<a href="/wiki/%E5%85%AB%E8%BE%BE%E5%B2%AD" title="八达岭">
八达岭
</a>
的
<a class="mw-redirect" href="/wiki/%E5%8D%81%E4%B8%89%E9%99%B5" title="十三陵">
十三陵
</a>
、
<a class="new" href="/w/index.php?title=%E7%9F%B3%E8%8A%B1%E6%B4%9E&action=edit&redlink=1" title="石花洞(页面不存在)">
石花洞
</a>
。中国历史文化名村有门头沟区斋堂镇的
<a href="/wiki/%E7%88%A8%E5%BA%95%E4%B8%8B%E6%9D%91" title="爨底下村">
爨底下村
</a>
。
</p>
<h2>
<span id=".E6.95.99.E8.82.B2">
</span>
<span class="mw-headline" id="教育">
教育
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=24" title="编辑章节:教育">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
参见:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E9%AB%98%E7%AD%89%E5%AD%A6%E6%A0%A1%E5%88%97%E8%A1%A8" title="北京市高等学校列表">
北京市高等学校列表
</a>
和
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E7%A4%BA%E8%8C%83%E9%AB%98%E4%B8%AD" title="北京市示范高中">
北京市示范高中
</a>
</div>
<p>
北京作為
<a class="mw-redirect" href="/wiki/%E5%85%83%E4%BB%A3" title="元代">
元
</a>
<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">
明
</a>
<a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">
清
</a>
三代的京城,中國官方最高
<a class="mw-redirect" href="/wiki/%E5%AD%A6%E5%BA%9C" title="学府">
學府
</a>
和國家管理
<a href="/wiki/%E6%95%99%E8%82%B2" title="教育">
教育
</a>
的最高行政機構——
<a class="mw-redirect" href="/wiki/%E5%9C%8B%E5%AD%90%E7%9B%A3" title="國子監">
國子監
</a>
自1306年起就設在北京。
</p>
<p>
至近代,
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9C%8B%E6%95%99%E8%82%B2%E5%8F%B2" title="中國教育史">
新式教育
</a>
興起,
<a class="mw-redirect" href="/wiki/%E5%9C%8B%E5%AD%90%E7%9B%A3" title="國子監">
國子監
</a>
和
<a class="mw-redirect" href="/wiki/%E7%A7%91%E8%88%89%E5%88%B6%E5%BA%A6" title="科舉制度">
科舉制度
</a>
被取消,而1898年中国近代第一所国立综合性大学
<a href="/wiki/%E4%BA%AC%E5%B8%88%E5%A4%A7%E5%AD%A6%E5%A0%82" title="京师大学堂">
京師大學堂
</a>
(今
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%B8" title="北京大學">
北京大學
</a>
)在北京成立
<sup class="reference" id="cite_ref-134">
<a href="#cite_note-134">
[127]
</a>
</sup>
,同時行使全国最高教育行政机关的職能,取代了
<a class="mw-redirect" href="/wiki/%E5%9C%8B%E5%AD%90%E7%9B%A3" title="國子監">
國子監
</a>
的地位。民國時期,北京(北平)雖有一段時間不再作為
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中國
</a>
的
<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">
首都
</a>
,但仍是中国的文化教育中心
<sup class="reference" id="cite_ref-135">
<a href="#cite_note-135">
[128]
</a>
</sup>
。
</p>
<p>
時至今日,北京是中國擁有最多
<a class="mw-redirect" href="/wiki/%E9%AB%98%E7%AD%89%E9%99%A2%E6%A0%A1" title="高等院校">
高等院校
</a>
的城市,聚集了眾多著名
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E5%AD%A6" title="大学">
大学
</a>
,更具有包括
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%AD%B8" title="北京大學">
北京大學
</a>
、
<a class="mw-redirect" href="/wiki/%E6%B8%85%E8%8F%AF%E5%A4%A7%E5%AD%B8" title="清華大學">
清華大學
</a>
、
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E7%A7%91%E5%AD%A6%E9%99%A2%E5%A4%A7%E5%AD%A6" title="中国科学院大学">
中国科学院大学
</a>
在内的幾所國際知名的高等學府。據統計,2009-2010年度北京共有
<a class="mw-redirect" href="/wiki/%E6%99%AE%E9%80%9A%E9%AB%98%E7%AD%89%E9%99%A2%E6%A0%A1" title="普通高等院校">
普通高等院校
</a>
88所(其中民办普通高校15所),
<a href="/wiki/%E7%A0%94%E7%A9%B6%E7%94%9F" title="研究生">
研究生
</a>
培养机构169家。
</p>
<h2>
<span id=".E4.BA.BA.E5.8F.A3">
</span>
<span class="mw-headline" id="人口">
人口
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=25" title="编辑章节:人口">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E4%BA%BA%E5%8F%A3&action=edit&redlink=1" title="北京人口(页面不存在)">
北京人口
</a>
</div>
<table class="toccolours" style="width:15em;border-spacing: 0;float:right;clear:right;margin:0.5em 0 1em 0.5em;">
<tbody>
<tr>
<th class="navbox-title" colspan="3" style="padding:0.1em 0.25em;font-size:110%">
歷史人口
</th>
</tr>
<tr style="font-size:95%">
<th style="border-bottom:1px solid black;padding:1px;width:3em">
年份
</th>
<th style="border-bottom:1px solid black;padding:1px 2px;text-align:right">
人口
</th>
<th style="border-bottom:1px solid black;padding:1px;text-align:right">
<abbr title="百分比变化">
±%
</abbr>
</th>
</tr>
<tr>
<th style="text-align:center;padding:1px">
<a class="mw-redirect" href="/wiki/1953%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" title="1953年中国大陆人口普查">
1953
</a>
</th>
<td style="text-align:right;padding:1px">
2,768,149
</td>
<td style="text-align:right;padding:1px">
—
</td>
</tr>
<tr>
<th style="text-align:center;padding:1px">
<a class="mw-redirect" href="/wiki/1964%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" title="1964年中国大陆人口普查">
1964
</a>
</th>
<td style="text-align:right;padding:1px">
7,568,495
</td>
<td style="text-align:right;padding:1px">
+173.4%
</td>
</tr>
<tr>
<th style="text-align:center;padding:1px">
<a class="mw-redirect" href="/wiki/1982%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" title="1982年中国大陆人口普查">
1982
</a>
</th>
<td style="text-align:right;padding:1px">
9,230,663
</td>
<td style="text-align:right;padding:1px">
+22.0%
</td>
</tr>
<tr>
<th style="text-align:center;padding:1px">
<a class="mw-redirect" href="/wiki/1990%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" title="1990年中国大陆人口普查">
1990
</a>
</th>
<td style="text-align:right;padding:1px">
10,819,414
</td>
<td style="text-align:right;padding:1px">
+17.2%
</td>
</tr>
<tr>
<th style="text-align:center;padding:1px;border-bottom:1px solid #bbbbbb">
<a class="mw-redirect" href="/wiki/2000%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" title="2000年中国大陆人口普查">
2000
</a>
</th>
<td style="text-align:right;padding:1px;border-bottom:1px solid #bbbbbb">
13,569,194
</td>
<td style="text-align:right;padding:1px;border-bottom:1px solid #bbbbbb">
+25.4%
</td>
</tr>
<tr>
<th style="text-align:center;padding:1px">
<a class="mw-redirect" href="/wiki/2010%E5%B9%B4%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5" title="2010年中国大陆人口普查">
2010
</a>
</th>
<td style="text-align:right;padding:1px">
19,612,368
</td>
<td style="text-align:right;padding:1px">
+44.5%
</td>
</tr>
<tr>
<th style="text-align:center;padding:1px">
2018
</th>
<td style="text-align:right;padding:1px">
21,542,000
</td>
<td style="text-align:right;padding:1px">
+9.8%
</td>
</tr>
<tr>
<td colspan="3" style="border-top:1px solid black;font-size:85%;text-align:left">
来源:历次人口普查、北京市统计局
</td>
</tr>
</tbody>
</table>
<p>
截至2018年底,北京市人口2154.2万人,比2017年底的2170.7有所下降
<sup class="reference" id="cite_ref-136">
<a href="#cite_note-136">
[129]
</a>
</sup>
。北京居民的平均预期寿命为74岁。中国56个民族的人口都在北京。绝大多数人口属于汉族。回族,满族和蒙古族人口分别超过1万人
<sup class="reference" id="cite_ref-137">
<a href="#cite_note-137">
[130]
</a>
</sup>
。
</p>
<table class="wikitable sortable floatright" style="font-size:smaller;">
<caption>
<b>
北京市各区人口数据(2017年末)
</b>
<sup class="reference" id="cite_ref-138">
<a href="#cite_note-138">
[131]
</a>
</sup>
</caption>
<tbody>
<tr>
<th class="unsortable" rowspan="2">
区划名称
</th>
<th colspan="3">
常住人口
</th>
<th rowspan="2">
户籍人口
<br/>
(万人)
</th>
</tr>
<tr>
<th style="width:60px;">
总计
<br/>
(万人)
</th>
<th style="width:50px;">
比重
<br/>
(%)
</th>
<th style="width:70px;">
每平方公里
<br/>
人口密度
</th>
</tr>
<tr style="text-align:right; font-weight:bold;">
<th>
北京市
</th>
<td>
2170.7
</td>
<td>
100
</td>
<td>
1323
</td>
<td>
1359.2
</td>
</tr>
<tr style="text-align:right;">
<th>
东城区
</th>
<td>
85.1
</td>
<td>
3.92
</td>
<td>
20330
</td>
<td>
96.7
</td>
</tr>
<tr style="text-align:right;">
<th>
西城区
</th>
<td>
122.0
</td>
<td>
5.62
</td>
<td>
24144
</td>
<td>
145.0
</td>
</tr>
<tr style="text-align:right;">
<th>
朝阳区
</th>
<td>
373.9
</td>
<td>
17.22
</td>
<td>
8216
</td>
<td>
209.8
</td>
</tr>
<tr style="text-align:right;">
<th>
丰台区
</th>
<td>
218.6
</td>
<td>
10.07
</td>
<td>
7148
</td>
<td>
113.9
</td>
</tr>
<tr style="text-align:right;">
<th>
石景山区
</th>
<td>
61.2
</td>
<td>
2.82
</td>
<td>
7258
</td>
<td>
38.2
</td>
</tr>
<tr style="text-align:right;">
<th>
海淀区
</th>
<td>
348.0
</td>
<td>
16.03
</td>
<td>
8079
</td>
<td>
235.4
</td>
</tr>
<tr style="text-align:right;">
<th>
门头沟区
</th>
<td>
32.2
</td>
<td>
1.48
</td>
<td>
222
</td>
<td>
24.9
</td>
</tr>
<tr style="text-align:right;">
<th>
房山区
</th>
<td>
115.4
</td>
<td>
5.32
</td>
<td>
580
</td>
<td>
81.9
</td>
</tr>
<tr style="text-align:right;">
<th>
通州区
</th>
<td>
150.8
</td>
<td>
6.95
</td>
<td>
1664
</td>
<td>
76.9
</td>
</tr>
<tr style="text-align:right;">
<th>
顺义区
</th>
<td>
112.8
</td>
<td>
5.20
</td>
<td>
1106
</td>
<td>
63.5
</td>
</tr>
<tr style="text-align:right;">
<th>
昌平区
</th>
<td>
206.3
</td>
<td>
9.50
</td>
<td>
1535
</td>
<td>
61.9
</td>
</tr>
<tr style="text-align:right;">
<th>
大兴区
</th>
<td>
176.1
</td>
<td>
8.11
</td>
<td>
1699
</td>
<td>
69.9
</td>
</tr>
<tr style="text-align:right;">
<th>
怀柔区
</th>
<td>
40.5
</td>
<td>
1.87
</td>
<td>
191
</td>
<td>
28.4
</td>
</tr>
<tr style="text-align:right;">
<th>
平谷区
</th>
<td>
44.8
</td>
<td>
2.06
</td>
<td>
472
</td>
<td>
40.4
</td>
</tr>
<tr style="text-align:right;">
<th>
密云区
</th>
<td>
49.0
</td>
<td>
2.26
</td>
<td>
220
</td>
<td>
43.7
</td>
</tr>
<tr style="text-align:right;">
<th>
延庆区
</th>
<td>
34.0
</td>
<td>
1.57
</td>
<td>
171
</td>
<td>
28.5
</td>
</tr>
</tbody>
</table>
<p>
截至2013年年末,北京市常住人口為2144.9萬人。按
<a class="mw-redirect" href="/wiki/%E6%88%B6%E7%B1%8D" title="戶籍">
戶籍
</a>
劃分,户籍人口1316.3万人,常住外来人口802.7万人(38%)。按城鄉劃分,城镇人口1825.1万人,占常住人口的86.3%。全市常住人口
<a href="/wiki/%E5%87%BA%E7%94%9F%E7%8E%87" title="出生率">
出生率
</a>
8.93‰,
<a href="/wiki/%E6%AD%BB%E4%BA%A1%E7%8E%87" title="死亡率">
死亡率
</a>
4.52‰,
<a href="/wiki/%E4%BA%BA%E5%8F%A3%E8%87%AA%E7%84%B6%E5%A2%9E%E9%95%BF%E7%8E%87" title="人口自然增长率">
自然增长率
</a>
4.41‰。全市常住人口密度为1289人/平方公里
<sup class="reference" id="cite_ref-139">
<a href="#cite_note-139">
[132]
</a>
</sup>
。北京市第六次全国人口普查资料显示:首都功能核心区、城市功能拓展区、城市发展新区、生态涵养发展区的人口密度分别为每平方公里23407人、7488人、958人、213人
<sup class="reference" id="cite_ref-140">
<a href="#cite_note-140">
[133]
</a>
</sup>
。
</p>
<p>
北京人口以
<a class="mw-redirect" href="/wiki/%E6%BC%A2%E6%97%8F" title="漢族">
漢族
</a>
為大多數,但同時包含全
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国">
中国
</a>
56个
<a href="/wiki/%E4%B8%AD%E5%9C%8B%E6%B0%91%E6%97%8F%E5%88%97%E8%A1%A8" title="中國民族列表">
民族
</a>
,北京是
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国">
中国
</a>
第一个聚集起56个民族的城市,其中
<a href="/wiki/%E5%B0%91%E6%95%B0%E6%B0%91%E6%97%8F" title="少数民族">
少数民族
</a>
以
<a href="/wiki/%E6%BB%A1%E6%97%8F" title="满族">
满族
</a>
、
<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">
回族
</a>
及
<a href="/wiki/%E8%92%99%E5%8F%A4%E6%97%8F" title="蒙古族">
蒙古族
</a>
為最多,人口數均过万。據統計,2009年除
<a class="mw-redirect" href="/wiki/%E6%BC%A2%E6%97%8F" title="漢族">
漢族
</a>
外的
<a href="/wiki/%E5%B0%91%E6%95%B0%E6%B0%91%E6%97%8F" title="少数民族">
少数民族
</a>
人口約為48萬人,占北京市总人口数的3.84%。
</p>
<p>
北京也有相當數目的
<a href="/wiki/%E5%A4%96%E5%9C%8B%E4%BA%BA" title="外國人">
外國人
</a>
在此居住,外國人社群聚集的區域包括
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%ACCBD" title="北京CBD">
北京CBD
</a>
(商務中心區)、
<a class="mw-redirect" href="/wiki/%E4%B8%89%E9%87%8C%E5%B1%AF" title="三里屯">
三里屯
</a>
、
<a href="/wiki/%E6%9C%9B%E4%BA%AC" title="望京">
望京
</a>
和
<a href="/wiki/%E4%BA%94%E9%81%93%E5%8F%A3" title="五道口">
五道口
</a>
附近。其中僅在北京居住的
<a class="mw-redirect" href="/wiki/%E9%9F%93%E5%9C%8B" title="韓國">
韓國
</a>
人數目就達20萬(2009年估計數字)
<sup class="reference" id="cite_ref-141">
<a href="#cite_note-141">
[134]
</a>
</sup>
。
</p>
<p>
根据2006年人口数据,北京人口最多的首十个姓氏依次是
<a href="/wiki/%E7%8E%8B%E5%A7%93" title="王姓">
王
</a>
(10.35%)、
<a class="mw-redirect" href="/wiki/%E5%BC%A0%E5%A7%93" title="张姓">
张
</a>
(9.4%)、
<a href="/wiki/%E6%9D%8E%E5%A7%93" title="李姓">
李
</a>
(8.54%)、
<a href="/wiki/%E5%88%98%E5%A7%93" title="刘姓">
刘
</a>
(6.91%)、
<a class="mw-redirect" href="/wiki/%E8%B5%B5%E5%A7%93" title="赵姓">
赵
</a>
(3.45%)、
<a href="/wiki/%E6%9D%A8%E5%A7%93" title="杨姓">
杨
</a>
、
<a href="/wiki/%E9%99%88%E5%A7%93" title="陈姓">
陈
</a>
、
<a href="/wiki/%E5%AD%99%E5%A7%93" title="孙姓">
孙
</a>
、
<a href="/wiki/%E9%AB%98%E5%A7%93" title="高姓">
高
</a>
、
<a href="/wiki/%E9%A9%AC%E5%A7%93" title="马姓">
马
</a>
。这个排名与
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8C%97%E6%96%B9" title="中国北方">
中国北方
</a>
其他大城市相若。
</p>
<p>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E6%BC%82%E6%97%8F" title="北漂族">
北漂族
</a>
是指来自非北京地区的、非北京户口、在北京生活和工作的外地人。北漂族在来京初期都很少有固定的住所,搬来搬去的,给人漂乎不定的感觉,其自身也因诸多原因而不能对于北京有更多的认同感,故此得名。
</p>
<p>
如今北京市正面临着非常严重的人口问题。官方的调查报告指出,北京目前的人口规模已经超过了北京地区环境资源的承载极限,水、电、气、热、煤的供应常年紧张,特别是水资源短缺已经到了十分严重的程度,甚至以至于需要调用应急战略储备水源才能满足城市供水需要。粮油酱醋等生活必需品绝大部分亦需从外省调入,稳定保障供给的难度很大。且按照目前北京市的垃圾产量,全市之垃圾场将会在4-5年内全部被填满。同时引发的交通、住房、医疗、教育等问题也使整个城市不堪重负
<sup class="reference" id="cite_ref-142">
<a href="#cite_note-142">
[135]
</a>
</sup>
。
</p>
<p>
根据人口普查和抽查,北京市1995年以来一直是全国
<a href="/wiki/%E6%80%BB%E5%92%8C%E7%94%9F%E8%82%B2%E7%8E%87" title="总和生育率">
总和生育率
</a>
最低的一級行政區。2000年以来,北京市总和生育率处于0.66和0.71之间,不到世代更替水平的三分之一,不仅低于中国其他省份,但不少數據只計算擁有
<a class="mw-redirect" href="/wiki/%E6%88%B6%E7%B1%8D" title="戶籍">
戶籍
</a>
的北京人口。
</p>
<h2>
<span id=".E6.96.87.E5.8C.96">
</span>
<span class="mw-headline" id="文化">
文化
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=26" title="编辑章节:文化">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<p>
北京是有着千年历史的
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="中国文化名城">
中国文化名城
</a>
,同时也是现代中国的文化中心。北京聚集着全中国最重要的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8D%9A%E7%89%A9%E9%A6%86%E5%88%97%E8%A1%A8" title="北京市博物馆列表">
几座博物馆
</a>
,这些博物館涵蓋了中国悠久的历史知識及其與現在和未來的關聯。有些博物館则涵蓋了某些特定的策展範圍或是某一特定地區,有的則較為籠統。其中,
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%8D%9A%E7%89%A9%E9%A6%86" title="中国国家博物馆">
中国国家博物馆
</a>
<sup class="reference" id="cite_ref-143">
<a href="#cite_note-143">
[136]
</a>
</sup>
<sup class="reference" id="cite_ref-144">
<a href="#cite_note-144">
[137]
</a>
</sup>
、
<a href="/wiki/%E9%A6%96%E9%83%BD%E5%8D%9A%E7%89%A9%E9%A6%86" title="首都博物馆">
首都博物馆
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%87%AA%E7%84%B6%E5%8D%9A%E7%89%A9%E9%A6%86" title="北京自然博物馆">
北京自然博物館
</a>
<sup class="reference" id="cite_ref-145">
<a href="#cite_note-145">
[138]
</a>
</sup>
、
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9C%B0%E8%B4%A8%E5%8D%9A%E7%89%A9%E9%A6%86" title="中国地质博物馆">
中國地質博物館
</a>
、
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%88%AA%E7%A9%BA%E5%8D%9A%E7%89%A9%E9%A6%86" title="中国航空博物馆">
中國航空博物館
</a>
、
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E7%A7%91%E5%AD%A6%E6%8A%80%E6%9C%AF%E9%A6%86" title="中国科学技术馆">
中國科學技術館
</a>
、
<a class="mw-redirect" href="/wiki/%E6%95%85%E5%AE%AE%E5%8D%9A%E7%89%A9%E9%99%A2" title="故宮博物院">
故宮博物院
</a>
<sup class="reference" id="cite_ref-146">
<a href="#cite_note-146">
[139]
</a>
</sup>
以其丰富的馆藏和典藏的权威而知名海内外,并吸引着众多的游客前来观摩欣赏。截至2014年底,北京市共有在北京市文物局註冊登記的博物館171家
<sup class="reference" id="cite_ref-147">
<a href="#cite_note-147">
[140]
</a>
</sup>
。
</p>
<div class="thumb tnone" style="margin-left:auto;margin-right:auto;overflow:hidden;width:auto;max-width:1608px">
<div class="thumbinner">
<div class="noresize" style="overflow:auto;direction:rtl">
<a class="image" href="/wiki/File:The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg" title="现藏于北京故宫博物院的王献之《中秋帖》卷">
<img alt="" data-file-height="531" data-file-width="6219" decoding="async" height="137" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg/1600px-The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg/2400px-The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e6/The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg/3200px-The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg 2x" width="1600"/>
</a>
</div>
<div class="thumbcaption">
<div class="magnify">
<a href="/wiki/File:The_Calligraphy_Model_Mid-Autumn_by_Wang_Xianzhi.jpg" title="File:The Calligraphy Model Mid-Autumn by Wang Xianzhi.jpg">
</a>
</div>
现藏于北京
<a href="/wiki/%E6%95%85%E5%AE%AB%E5%8D%9A%E7%89%A9%E9%99%A2" title="故宫博物院">
故宫博物院
</a>
的
<a href="/wiki/%E7%8E%8B%E7%8C%AE%E4%B9%8B" title="王献之">
王献之
</a>
《
<a href="/wiki/%E4%B8%AD%E7%A7%8B%E5%B8%96" title="中秋帖">
中秋帖
</a>
》卷
</div>
</div>
</div>
<h3>
<span id=".E6.96.87.E5.AD.A6">
</span>
<span class="mw-headline" id="文学">
文学
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=27" title="编辑章节:文学">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a href="/wiki/%E4%BA%AC%E6%B4%BE" title="京派">
京派
</a>
</div>
<p>
北京
<a href="/wiki/%E4%BD%9C%E5%AE%B6" title="作家">
作家
</a>
辈出,由此诞生名为
<a href="/wiki/%E4%BA%AC%E6%B4%BE" title="京派">
京派
</a>
的文学流派,并与以
<a class="mw-redirect" href="/wiki/%E4%B8%8A%E6%B5%B7" title="上海">
上海
</a>
为根据地的
<a href="/wiki/%E6%B5%B7%E6%B4%BE_(%E6%96%87%E8%97%9D)" title="海派 (文藝)">
海派
</a>
相对。京派文学家描寫的內容主要是人生,同時避談
<a href="/wiki/%E6%94%BF%E6%B2%BB" title="政治">
政治
</a>
。京派強調文學是純文學,要「和諧」、「節制」、「恰當」,包含
<a class="mw-redirect" href="/wiki/%E7%8F%BE%E5%AF%A6%E4%B8%BB%E7%BE%A9" title="現實主義">
現實主義
</a>
和
<a class="mw-redirect" href="/wiki/%E6%B5%AA%E6%BC%AB%E4%B8%BB%E7%BE%A9" title="浪漫主義">
浪漫主義
</a>
。京派的風格淳樸自然,回歸田園,寫人情美和人性美,融合鄉土文化,而語言則簡練、樸素、活潑、明淨。
</p>
<p>
著名的京派
<a class="mw-redirect" href="/wiki/%E6%96%87%E5%AD%A6%E5%AE%B6" title="文学家">
文學家
</a>
有
<a class="mw-redirect" href="/wiki/%E7%B4%8D%E8%98%AD%E6%80%A7%E5%BE%B7" title="納蘭性德">
納蘭性德
</a>
、
<a class="mw-redirect" href="/wiki/%E7%BA%AA%E6%99%93%E5%B2%9A" title="纪晓岚">
纪晓岚
</a>
、
<a href="/wiki/%E8%80%81%E8%88%8D" title="老舍">
老舍
</a>
、
<a href="/wiki/%E6%9E%97%E8%AF%AD%E5%A0%82" title="林语堂">
林语堂
</a>
、
<a href="/wiki/%E6%9E%97%E6%B5%B7%E9%9F%B3" title="林海音">
林海音
</a>
、
<a href="/wiki/%E7%AB%AF%E6%9C%A8%E8%95%BB%E8%89%AF" title="端木蕻良">
端木蕻良
</a>
、
<a class="mw-redirect" href="/wiki/%E8%B4%9D%E5%AD%90" title="贝子">
贝子
</a>
、
<a href="/wiki/%E5%94%90%E9%AD%AF%E5%AD%AB" title="唐魯孫">
唐鲁孙
</a>
等。
</p>
<p>
随着
<a class="mw-redirect" href="/wiki/%E5%8D%8E%E8%AF%AD" title="华语">
华语
</a>
文坛的发展和
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E6%96%87" title="中文">
中文
</a>
的国际化,越来越多的华语作家包括
<a href="/wiki/%E7%8E%8B%E8%92%99_(%E4%BD%9C%E5%AE%B6)" title="王蒙 (作家)">
王蒙
</a>
、
<a href="/wiki/%E6%B5%B7%E5%B2%A9" title="海岩">
海岩
</a>
、
<a href="/wiki/%E5%86%AF%E5%94%90_(%E4%BD%9C%E5%AE%B6)" title="冯唐 (作家)">
冯唐
</a>
、
<a href="/wiki/%E6%AD%A5%E9%9D%9E%E7%83%9F_(%E4%BD%9C%E5%AE%B6)" title="步非烟 (作家)">
步非烟
</a>
、
<a href="/wiki/%E6%B1%9F%E5%8D%97_(%E5%B0%8F%E8%AF%B4%E5%AE%B6)" title="江南 (小说家)">
江南
</a>
和
<a href="/wiki/%E5%AE%89%E6%84%8F%E5%A6%82" title="安意如">
安意如
</a>
等,纷纷选择北京作为创作的中心,谱写众多优秀的中文文学。
</p>
<h3>
<span id=".E9.A5.AE.E9.A3.9F.E6.96.87.E5.8C.96">
</span>
<span class="mw-headline" id="饮食文化">
饮食文化
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=28" title="编辑章节:饮食文化">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<div class="thumb tright">
<div class="thumbinner" style="width:222px;">
<a class="image" href="/wiki/File:Beijing_DUck_sliced.jpeg">
<img alt="" class="thumbimage" data-file-height="3024" data-file-width="4032" decoding="async" height="165" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/24/Beijing_DUck_sliced.jpeg/220px-Beijing_DUck_sliced.jpeg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/24/Beijing_DUck_sliced.jpeg/330px-Beijing_DUck_sliced.jpeg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/24/Beijing_DUck_sliced.jpeg/440px-Beijing_DUck_sliced.jpeg 2x" width="220"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Beijing_DUck_sliced.jpeg" title="放大">
</a>
</div>
片好装盘的
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%83%A4%E9%B8%AD" title="北京烤鸭">
北京烤鸭
</a>
</div>
</div>
</div>
<p>
現今的
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E8%8F%9C" title="北京菜">
北京菜
</a>
是由
<a class="mw-redirect" href="/wiki/%E9%AD%AF%E8%8F%9C" title="魯菜">
魯菜
</a>
、市肆菜、
<a class="mw-redirect" href="/wiki/%E8%AD%9A%E5%AE%B6%E8%8F%9C" title="譚家菜">
譚家菜
</a>
、
<a href="/wiki/%E6%B8%85%E7%9C%9F%E8%8F%9C" title="清真菜">
清真菜
</a>
和
<a href="/wiki/%E5%AE%AE%E5%BB%B7%E8%8F%9C" title="宮廷菜">
宮廷菜
</a>
五種風味的菜餚进行
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC" title="北京">
北京
</a>
風味本地化后組合而成。
<sup class="reference" id="cite_ref-148">
<a href="#cite_note-148">
[141]
</a>
</sup>
早期北京与
<a class="mw-redirect" href="/wiki/%E5%B1%B1%E6%9D%B1" title="山東">
山東
</a>
飲食習慣頗為相似,所以较多山东厨师,因而魯菜是京菜的基調。到了
<a class="mw-redirect" href="/wiki/%E8%BE%BD%E4%BB%A3" title="辽代">
遼代
</a>
及
<a class="mw-redirect" href="/wiki/%E5%85%83%E4%BB%A3" title="元代">
元代
</a>
之後,由於北京
<a href="/wiki/%E8%92%99%E5%8F%A4%E6%97%8F" title="蒙古族">
蒙古族
</a>
、
<a href="/wiki/%E5%9B%9E%E6%97%8F" title="回族">
回族
</a>
等北方民族逐渐增多,京菜的風味受到其影響,因而增加了烹製
<a href="/wiki/%E7%BE%8A%E8%82%89" title="羊肉">
羊肉
</a>
菜餚的特點。至
<a class="mw-redirect" href="/wiki/%E6%98%8E%E4%BB%A3" title="明代">
明
</a>
<a class="mw-redirect" href="/wiki/%E6%B8%85" title="清">
清
</a>
兩代时,北京是全國的政經及文化中心,宮廷御廚和大臣的厨房都集中在北京,
<a class="mw-redirect" href="/wiki/%E7%83%B9%E8%B0%83" title="烹调">
烹調
</a>
技術也就不斷地提升,因此,全國各地主要的飲食風味也隨著齊聚於北京。北京菜肴烹調方法非常多元,以爆、
<a href="/wiki/%E7%83%A4" title="烤">
烤
</a>
、
<a href="/wiki/%E6%B6%AE" title="涮">
涮
</a>
、
<a href="/wiki/%E6%BA%9C" title="溜">
溜
</a>
、
<a href="/wiki/%E7%82%B8" title="炸">
炸
</a>
、
<a class="mw-redirect" href="/wiki/%E7%83%A7_(%E7%82%96%E7%85%AE%E6%B3%95)" title="烧 (炖煮法)">
燒
</a>
、
<a href="/wiki/%E7%82%92" title="炒">
炒
</a>
、
<a href="/wiki/%E6%89%92" title="扒">
扒
</a>
、
<a href="/wiki/%E7%85%A8" title="煨">
煨
</a>
、
<a class="mw-redirect" href="/wiki/%E7%84%96" title="焖">
燜
</a>
、
<a href="/wiki/%E9%86%AC" title="醬">
醬
</a>
、
<a href="/wiki/%E6%8B%94%E4%B8%9D" title="拔丝">
拔絲
</a>
、白煮等技法見長。其中的“爆”法,變化多樣,可分為油爆、醬爆、蔥爆、水爆、湯爆等。口味講究酥脆鮮嫩,清鮮爽口,且要做到色、香、味、形、器等五面俱全
<sup class="reference" id="cite_ref-149">
<a href="#cite_note-149">
[142]
</a>
</sup>
。著名京菜有
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%83%A4%E9%B8%AD" title="北京烤鸭">
北京烤鸭
</a>
、蔥爆豬肉、
<a href="/wiki/%E4%BA%AC%E9%85%B1%E8%82%89%E4%B8%9D" title="京酱肉丝">
京酱肉丝
</a>
、
<a href="/wiki/%E6%B6%AE%E7%BE%8A%E8%82%89" title="涮羊肉">
涮羊肉
</a>
、砂鍋魚翅等。老字号饭馆有
<a href="/wiki/%E4%B8%9C%E6%9D%A5%E9%A1%BA" title="东来顺">
东来顺
</a>
、
<a href="/wiki/%E5%85%A8%E8%81%9A%E5%BE%B7" title="全聚德">
全聚德
</a>
、
<a href="/wiki/%E4%BE%BF%E5%AE%9C%E5%9D%8A" title="便宜坊">
便宜坊
</a>
、
<a href="/wiki/%E4%BB%BF%E8%86%B3%E9%A5%AD%E5%BA%84" title="仿膳饭庄">
仿膳饭庄
</a>
等。
</p>
<h3>
<span id=".E8.A1.A8.E6.BC.94.E8.89.BA.E6.9C.AF">
</span>
<span class="mw-headline" id="表演艺术">
表演艺术
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=29" title="编辑章节:表演艺术">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
北京有很多地方特色的民风习俗。
<a href="/wiki/%E4%BA%AC%E5%89%A7" title="京剧">
京剧
</a>
深受部分京城老百姓的喜爱,在北京的街头,偶然可以听到路边传来抑扬顿挫的京戏段子。京剧的源头还要追溯到几种古老的地方戏剧,1790年,
<a class="mw-redirect" href="/wiki/%E5%AE%89%E5%BE%BD" title="安徽">
安徽
</a>
的四大地方戏班——三庆班、四喜班、春公班、和春班——先后进京献艺,获得空前成功。徽班常与来自
<a class="mw-redirect" href="/wiki/%E6%B9%96%E5%8C%97" title="湖北">
湖北
</a>
的汉调艺人合作演出,于是,一种以徽调“二簧”和汉调“
<a href="/wiki/%E8%A5%BF%E7%9A%AE" title="西皮">
西皮
</a>
”为主,兼收
<a href="/wiki/%E6%98%86%E6%9B%B2" title="昆曲">
昆曲
</a>
、
<a href="/wiki/%E7%A7%A6%E8%85%94" title="秦腔">
秦腔
</a>
、
<a href="/wiki/%E6%88%8F%E6%9B%B2" title="戏曲">
梆子
</a>
等地方戏精华的新剧种诞生了,这就是京剧。在200年的发展历程中,京剧在唱词、念白及字韵上越来越北京化,使用的
<a href="/wiki/%E4%BA%8C%E8%83%A1" title="二胡">
二胡
</a>
、
<a href="/wiki/%E4%BA%AC%E8%83%A1" title="京胡">
京胡
</a>
等乐器,也融合了多个民族的特色,终于成为一种成熟的艺术。京剧集歌唱、舞蹈、武打、音乐、美术、文学于一体。
</p>
<p>
京剧舞台艺术在
<a class="mw-redirect" href="/wiki/%E6%96%87%E5%AD%A6" title="文学">
文学
</a>
、
<a href="/wiki/%E8%A1%A8%E6%BC%94" title="表演">
表演
</a>
、
<a href="/wiki/%E9%9F%B3%E4%B9%90" title="音乐">
音乐
</a>
、
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E6%88%8F%E6%9B%B2" title="中国戏曲">
唱腔
</a>
、锣鼓、
<a href="/wiki/%E5%8C%96%E5%A6%86" title="化妆">
化妆
</a>
、
<a class="mw-redirect" href="/wiki/%E8%84%B8%E8%B0%B1" title="脸谱">
脸谱
</a>
等各个方面,通过无数艺人的长期舞台实践,构成了一套互相制约、相得益彰的格律化和规范化的程式。它作为创造舞台形象的艺术手段是十分丰富的,而用法又是十分严格的。不能驾驭这些程式,就无法完成京剧舞台艺术的创造。由于京剧在形成之初,便进入了
<a class="mw-redirect" href="/wiki/%E5%AE%AE%E5%BB%B7" title="宮廷">
宫廷
</a>
,使它的发育成长不同于地方剧种。要求它所要表现的生活领域更宽,所要塑造的人物类型更多,对它的技艺的全面性、完整性也要求得更严,对它创造舞台形象的
<a href="/wiki/%E7%BE%8E%E5%AD%A6" title="美学">
美学
</a>
要求也更高。当然,同时也相应地使它的民间乡土气息减弱,纯朴、粗犷的风格特色相对淡薄。因而,它的表演艺术更趋于虚实结合的表现手法,最大限度地超脱了舞台空间和时间的限制,以达到“以形传神,形神兼备”的艺术境界。表演上要求精致细腻,处处入戏;唱腔上要求悠扬委婉,声情并茂;武戏则不以火爆勇猛取胜,而以“武戏文唱”见佳。2010年11月16日京剧被列入“
<a href="/wiki/%E4%BA%BA%E7%B1%BB%E9%9D%9E%E7%89%A9%E8%B4%A8%E6%96%87%E5%8C%96%E9%81%97%E4%BA%A7%E4%BB%A3%E8%A1%A8%E4%BD%9C%E5%90%8D%E5%BD%95" title="人类非物质文化遗产代表作名录">
人类非物质文化遗产代表作名录
</a>
”。
</p>
<p>
除京剧外,北京还有
<a href="/wiki/%E5%8F%8C%E7%B0%A7" title="双簧">
双簧
</a>
、
<a href="/wiki/%E7%9B%B8%E5%A3%B0" title="相声">
相声
</a>
、
<a href="/wiki/%E8%AF%84%E4%B9%A6" title="评书">
评书
</a>
、
<a class="mw-redirect" href="/wiki/%E6%9D%82%E6%8A%80" title="杂技">
杂技
</a>
、
<a href="/wiki/%E4%BA%AC%E9%9F%B5%E5%A4%A7%E9%BC%93" title="京韵大鼓">
京韵大鼓
</a>
、
<a class="mw-redirect" href="/wiki/%E8%AF%9D%E5%89%A7" title="话剧">
话剧
</a>
、铁板快书、
<a class="mw-redirect" href="/wiki/%E6%99%AF%E6%B3%B0%E8%93%9D" title="景泰蓝">
景泰蓝
</a>
、牙雕、漆雕、蝈蝈笼和吹糖人等传统艺术。
</p>
<p>
进入21世纪,北京已成为中国内地音乐产业的中心。内地音乐人多数选择来北京发展,很大程度上带动了北京音乐文化的繁荣。北京的摇滚界见证了中国摇滚乐的兴衰史,是中国摇滚音乐的心脏。随着时间的推移,摇滚已经风光不再,目前仅处于勉强维持阶段,但是在北京依然拥有数量众多的摇滚乐迷。北京的地下乐队众多、派别多样,主要在各酒吧演出,其中较知名的有
<a href="/wiki/%E6%96%B0%E8%A3%A4%E5%AD%90" title="新裤子">
新裤子
</a>
乐队、
<a class="new" href="/w/index.php?title=%E5%9C%B0%E4%B8%8B%E5%A9%B4%E5%84%BF&action=edit&redlink=1" title="地下婴儿(页面不存在)">
地下婴儿
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8F%8D%E5%85%89%E9%95%9C" title="反光镜">
反光镜
</a>
、
<a class="mw-redirect" href="/wiki/%E7%89%9B%E5%A5%B6%E5%92%96%E5%95%A1_(%E6%A8%82%E9%9A%8A)" title="牛奶咖啡 (樂隊)">
牛奶咖啡
</a>
、
<a class="new" href="/w/index.php?title=%E4%BE%BF%E5%88%A9%E5%95%86%E5%BA%97%E4%B9%90%E9%98%9F&action=edit&redlink=1" title="便利商店乐队(页面不存在)">
便利商店乐队
</a>
等。北京音乐呈现非主流、叛逆、创新的文化特点。
</p>
<div class="thumb tright">
<div class="thumbinner" style="width:252px;">
<a class="image" href="/wiki/File:Beijing_national_stadium.jpg">
<img alt="" class="thumbimage" data-file-height="1019" data-file-width="1762" decoding="async" height="145" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Beijing_national_stadium.jpg/250px-Beijing_national_stadium.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Beijing_national_stadium.jpg/375px-Beijing_national_stadium.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Beijing_national_stadium.jpg/500px-Beijing_national_stadium.jpg 2x" width="250"/>
</a>
<div class="thumbcaption">
<div class="magnify">
<a class="internal" href="/wiki/File:Beijing_national_stadium.jpg" title="放大">
</a>
</div>
北京
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA_(%E5%8C%97%E4%BA%AC)" title="国家体育场 (北京)">
国家体育场
</a>
又被称作“鸟巢”,是2008年夏季奥运会,也是2022年冬季奧運會的主赛场地。现在也作为北京市区大型的表演中心使用。
</div>
</div>
</div>
<p>
北京艺术演出市场非常繁荣,每年都有超过10000场国内外
<a class="mw-redirect" href="/wiki/%E6%BC%94%E5%94%B1%E6%9C%83" title="演唱會">
演唱会
</a>
、
<a class="mw-redirect" href="/wiki/%E9%9F%B3%E4%B9%90%E4%BC%9A" title="音乐会">
音乐会
</a>
、
<a href="/wiki/%E6%AD%8C%E5%89%A7" title="歌剧">
歌剧
</a>
、
<a class="mw-redirect" href="/wiki/%E8%AF%9D%E5%89%A7" title="话剧">
话剧
</a>
在全市近百个场地上演。
<sup class="reference" id="cite_ref-150">
<a href="#cite_note-150">
[143]
</a>
</sup>
世界各大著名交响乐团,以及
<a href="/wiki/%E9%9B%85%E5%B0%BC" title="雅尼">
雅尼
</a>
、
<a href="/wiki/%E7%A5%9E%E7%A7%98%E5%9B%AD" title="神秘园">
神秘园
</a>
、
<a href="/wiki/%E5%B0%8F%E6%B3%BD%E5%BE%81%E5%B0%94" title="小泽征尔">
小泽征尔
</a>
、
<a href="/wiki/%E4%BC%8A%E6%89%8E%E5%85%8B%C2%B7%E5%B8%95%E5%B0%94%E6%9B%BC" title="伊扎克·帕尔曼">
帕尔曼
</a>
等著名音乐家和团体均有来访北京。
</p>
<p>
北京有举办一年一度的著名“三大国际演出季”,即为:北京国际音乐节、北京国际戏剧演出季和北京国际舞蹈季。北京国际音乐节于每年的10月中旬到11月中旬举办,期间有
<a href="/wiki/%E6%9F%8F%E6%9E%97%E7%88%B1%E4%B9%90%E4%B9%90%E5%9B%A2" title="柏林爱乐乐团">
柏林爱乐乐团
</a>
、
<a class="mw-redirect" href="/wiki/%E7%BA%BD%E7%BA%A6%E7%88%B1%E4%B9%90%E4%B9%90%E5%9B%A2" title="纽约爱乐乐团">
纽约爱乐乐团
</a>
、
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E7%88%B1%E4%B9%90%E4%B9%90%E5%9B%A2" title="中国爱乐乐团">
中国爱乐乐团
</a>
等国内外著名乐团,以及
<a href="/wiki/%E4%BD%95%E5%A1%9E%C2%B7%E5%8D%A1%E9%9B%B7%E6%8B%89%E6%96%AF" title="何塞·卡雷拉斯">
何塞·卡雷拉斯
</a>
、
<a class="mw-redirect" href="/wiki/%E5%85%8B%E9%87%8C%E6%96%AF%E6%89%98%E5%A4%AB%C2%B7%E6%BD%98%E5%BE%B7%E5%88%97%E8%8C%A8%E5%9F%BA" title="克里斯托夫·潘德列茨基">
潘德列茨基
</a>
、
<a class="mw-redirect" href="/wiki/%E9%A9%AC%E5%8F%8B%E5%8F%8B" title="马友友">
马友友
</a>
等著名音乐家的30多场艺术演出上演,涵盖了
<a class="mw-redirect" href="/wiki/%E4%BA%A4%E5%93%8D%E4%B9%90" title="交响乐">
交响乐
</a>
、
<a href="/wiki/%E6%AD%8C%E5%89%A7" title="歌剧">
歌剧
</a>
、
<a href="/wiki/%E7%88%B5%E5%A3%AB%E4%B9%90" title="爵士乐">
爵士乐
</a>
等等各种风格及形式的音乐。
<sup class="reference" id="cite_ref-151">
<a href="#cite_note-151">
[144]
</a>
</sup>
北京国际戏剧演出季于每年春末夏初举办,来自世界各大洲国家及国内之戏剧团体在一个月内献上超过50场演出,
<a class="mw-redirect" href="/wiki/%E8%8E%8E%E6%8B%89%C2%B7%E5%B8%83%E8%8E%B1%E6%9B%BC" title="莎拉·布莱曼">
莎拉·布莱曼
</a>
等明星亦有受邀献唱。北京国际舞蹈季为冬季跨年举办,
<span class="ilh-all" data-foreign-title="The Royal Ballet" data-lang-code="en" data-lang-name="英语" data-orig-title="英国皇家芭蕾舞团">
<span class="ilh-page">
<a class="mw-redirect" href="/wiki/%E8%8B%B1%E5%9C%8B%E7%9A%87%E5%AE%B6%E8%8A%AD%E8%95%BE%E8%88%9E%E5%9C%98" title="英國皇家芭蕾舞團">
英国皇家芭蕾舞团
</a>
</span>
<span class="noprint ilh-comment">
(
<span class="ilh-lang">
英语
</span>
<span class="ilh-colon">
:
</span>
<span class="ilh-link">
<a class="extiw" href="https://en.wikipedia.org/wiki/The_Royal_Ballet" title="en:The Royal Ballet">
<span dir="auto" lang="en">
The Royal Ballet
</span>
</a>
</span>
)
</span>
</span>
等国际各大著名芭蕾舞团体均受邀参加。
<sup class="reference" id="cite_ref-152">
<a href="#cite_note-152">
[145]
</a>
</sup>
</p>
<p>
北京市的主要演出场馆有:
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%A4%A7%E5%89%A7%E9%99%A2" title="中国国家大剧院">
中国国家大剧院
</a>
、
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%BD%93%E8%82%B2%E5%9C%BA_(%E5%8C%97%E4%BA%AC)" title="国家体育场 (北京)">
鸟巢
</a>
、
<a href="/wiki/%E4%BF%9D%E5%88%A9%E5%89%A7%E9%99%A2" title="保利剧院">
保利剧院
</a>
、
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%B1%B1%E9%9F%B3%E4%B9%90%E5%A0%82" title="中山音乐堂">
中山音乐堂
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%9F%B3%E4%B9%90%E5%8E%85" title="北京音乐厅">
北京音乐厅
</a>
、
<a href="/wiki/%E4%BA%BA%E6%B0%91%E5%A4%A7%E4%BC%9A%E5%A0%82" title="人民大会堂">
人民大会堂
</a>
、
<a class="mw-redirect" href="/wiki/%E4%B8%9C%E6%96%B9%E5%85%88%E9%94%8B%E5%89%A7%E5%9C%BA" title="东方先锋剧场">
东方先锋剧场
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%BA%E6%B0%91%E8%89%BA%E6%9C%AF%E5%89%A7%E9%99%A2" title="北京人民艺术剧院">
北京人艺小剧场
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B7%A5%E4%BA%BA%E4%BD%93%E8%82%B2%E5%9C%BA" title="北京工人体育场">
北京工人体育场
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B7%A5%E4%BA%BA%E4%BD%93%E8%82%B2%E9%A6%86" title="北京工人体育馆">
北京工人体育馆
</a>
、
<a href="/wiki/%E9%A6%96%E9%83%BD%E4%BD%93%E8%82%B2%E9%A6%86" title="首都体育馆">
首都体育馆
</a>
、
<a class="mw-redirect" href="/wiki/%E4%B8%B0%E5%8F%B0%E4%BD%93%E8%82%B2%E4%B8%AD%E5%BF%83" title="丰台体育中心">
丰台体育中心
</a>
等。
</p>
<h3>
<span id=".E8.89.BA.E6.9C.AF.E5.9B.AD.E5.8C.BA">
</span>
<span class="mw-headline" id="艺术园区">
艺术园区
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=30" title="编辑章节:艺术园区">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h3>
<p>
随着中国文化艺术与时尚产业的复兴,北京作为首都,是中国的
<a href="/wiki/%E8%89%BA%E6%9C%AF" title="艺术">
艺术
</a>
中心、
<a class="mw-redirect" href="/wiki/%E6%99%82%E5%B0%9A%E6%BD%AE%E6%B5%81" title="時尚潮流">
時尚潮流
</a>
中心和
<a href="/wiki/%E6%96%87%E5%8C%96" title="文化">
文化
</a>
中心。北京现当代艺术的地标为位于北京市朝阳区大山子地区的一个艺术园区,即
<a href="/wiki/798%E8%89%BA%E6%9C%AF%E5%8C%BA" title="798艺术区">
798艺术区
</a>
,原为
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%AC%AC%E4%B8%89%E6%97%A0%E7%BA%BF%E7%94%B5%E5%99%A8%E6%9D%90%E5%8E%82&action=edit&redlink=1" title="北京第三无线电器材厂(页面不存在)">
北京第三无线电器材厂
</a>
,建筑多为
<a class="mw-redirect" href="/wiki/%E4%B8%9C%E5%BE%B7" title="东德">
东德
</a>
的
<a href="/wiki/%E5%8C%85%E8%B1%AA%E6%96%AF" title="包豪斯">
包豪斯
</a>
风格。1980年代到1990年代798厂逐渐衰落,从2002年开始,由于租金低廉,来自北京周边和北京以外的艺术家开始聚集于此,逐渐形成了一个艺术群落。2006年后,中国发展文化创意产业,因应北京建设世界城市的步伐,以798艺术区为中心,打造中国乃至世界的当代艺术中心,周边的
<a href="/wiki/%E8%8D%89%E5%9C%BA%E5%9C%B0" title="草场地">
草场地
</a>
、
<a class="mw-redirect" href="/wiki/%E7%8E%AF%E9%93%81" title="环铁">
环铁
</a>
乃至北京远郊的
<a class="new" href="/w/index.php?title=%E5%AE%8B%E5%BA%84&action=edit&redlink=1" title="宋庄(页面不存在)">
宋庄
</a>
均成为这一巨大艺术群落的一部分。
</p>
<h2>
<span id=".E4.BA.BA.E7.89.A9">
</span>
<span class="mw-headline" id="人物">
人物
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=31" title="编辑章节:人物">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主页面:
<a href="/wiki/Category:%E5%8C%97%E4%BA%AC%E4%BA%BA" title="Category:北京人">
Category:北京人
</a>
</div>
<h2>
<span id=".E5.AE.97.E6.95.99">
</span>
<span class="mw-headline" id="宗教">
宗教
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=32" title="编辑章节:宗教">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable" role="note">
主条目:
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%AE%97%E6%95%99%E6%B4%BB%E5%8A%A8%E5%9C%BA%E6%89%80%E5%88%97%E8%A1%A8" title="北京市宗教活动场所列表">
北京市宗教活動場所列表
</a>
</div>
<style data-mw-deduplicate="TemplateStyles:r51421762">
body.skin-minerva .mw-parser-output .transborder{border:solid transparent}
</style>
<div class="thumb tleft" style="">
<div class="thumbinner" style="width:202px">
<div style="background-color:white;margin:auto;position:relative;width:200px;height:200px;overflow:hidden;border-radius:100px;border:1px solid black">
<div class="transborder" style="position:absolute;width:100px;line-height:0;left:0; top:0; border-width:0 200px 200px 0; border-color:#A1887F">
</div>
<div class="transborder" style="position:absolute;width:100px;line-height:0;left:100px; top:100px; border-width:100px 0 0 2038.8140985341px; border-left-color:#000000">
</div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 200px 100px 0;border-color:#000000">
</div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 100px 200px 0;border-color:#000000">
</div>
<div class="transborder" style="position:absolute;width:100px;line-height:0;left:100px; top:100px; border-width:100px 0 0 621.26544569249px; border-left-color:#FDD835">
</div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 200px 100px 0;border-color:#FDD835">
</div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 100px 200px 0;border-color:#FDD835">
</div>
<div class="transborder" style="position:absolute;width:100px;line-height:0;left:100px; top:100px; border-width:100px 0 0 85.516791693412px; border-left-color:#F5F5F5">
</div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 200px 100px 0;border-color:#F5F5F5">
</div>
<div style="position:absolute;line-height:0;border-style:solid;left:0;top:0;border-width:0 100px 200px 0;border-color:#F5F5F5">
</div>
</div>
<div class="thumbcaption">
<p>
北京宗教(2010)
</p>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #F5F5F5;color:black;font-size:small; width:1.5em">
</span>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9C%8B%E6%B0%91%E9%96%93%E4%BF%A1%E4%BB%B0" title="中國民間信仰">
中國民間信仰
</a>
、
<a class="mw-redirect" href="/wiki/%E7%84%A1%E5%AE%97%E6%95%99" title="無宗教">
無宗教
</a>
或
<a class="mw-redirect" href="/wiki/%E7%84%A1%E7%A5%9E%E8%AB%96" title="無神論">
無神論
</a>
(86.26%)
</div>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FDD835;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E4%BD%9B%E6%95%99" title="佛教">
佛教
</a>
(11.2%)
</div>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #000000;color:black;font-size:small; width:1.5em">
</span>
<a class="mw-redirect" href="/wiki/%E4%BC%8A%E6%96%AF%E8%98%AD%E6%95%99" title="伊斯蘭教">
伊斯蘭教
</a>
(1.76%)
</div>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #A1887F;color:black;font-size:small; width:1.5em">
</span>
<a class="mw-redirect" href="/wiki/%E5%9F%BA%E7%9D%A3%E5%AE%97%E6%95%99" title="基督宗教">
基督宗教
</a>
(0.78%)
</div>
</div>
</div>
</div>
<p>
从古至今,各种原始宗教以及土生土长的道教都在北京繁衍和发展,外来的佛教、基督宗教、伊斯兰教等宗教亦相继在北京地区传播,并逐渐融入中华民族传统文化和北京历史文化中,逐渐形成了多元文化体系的北京宗教文化。北京现有宗教活动场所达100多处,拥有宗教信仰者50多万,以2000年北京市人口来计算,宗教信仰者约占4%。各大宗教在北京都建有自己的宗教活动场所和宗教院校,传承各自的宗教文化。
<sup class="reference" id="cite_ref-153">
<a href="#cite_note-153">
[146]
</a>
</sup>
</p>
<p>
道教自东汉产生后,就开始在北京地区流传。北魏时期统治者以道教为国教。始建于唐朝的
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E9%95%B7%E8%A7%80" title="天長觀">
天长观
</a>
是北京地区第一座道观。金元明清时期,道教在北京地区有着很大的影响。1957年4月,道教界第一次全国代表会议在北京召开,中国道教协会正式成立,由岳崇岱任第一届理事会会长
<sup class="reference" id="cite_ref-154">
<a href="#cite_note-154">
[147]
</a>
</sup>
。
</p>
<p>
东晋十六国时起,佛教传入北京地区。历朝帝王出于政治与信仰的需要,大多推崇佛教。1953年6月中国佛教协会在北京成立,圆瑛法师当选会长。2010年2月,中国佛教协会第八次全国代表大会在北京召开,传印长老当选为新一届中国佛教协会会长
<sup class="reference" id="cite_ref-155">
<a href="#cite_note-155">
[148]
</a>
</sup>
。
</p>
<p>
鸦片战争后,基督宗教逐渐在北京传播。北京市天主教爱国会、北京市天主教教务委员会、天主教北京教区三个机构是北京市天主教的三个机构,由北京市天主教爱国会负责北京市天主教的对外所有民事事务
<sup class="reference" id="cite_ref-156">
<a href="#cite_note-156">
[149]
</a>
</sup>
。
</p>
<p>
宋辽时期伊斯兰教传入北京。北京市历史最悠久的
<a href="/wiki/%E7%89%9B%E8%A1%97%E7%A4%BC%E6%8B%9C%E5%AF%BA" title="牛街礼拜寺">
牛街礼拜寺
</a>
始建于公元996年。元代,穆斯林大量进入中国。当时北京(元大都)有信仰伊斯兰教的“回回”逾万人,有清真寺35座。明政府对“保国有功的回回”始终以“敬礼勋臣”相待,敕建、重修了许多清真寺。目前北京大部分较为古老的清真寺,多为明代修建。清朝时期北京的伊斯兰教由内城向外城和近郊扩展,清真寺大量增加,伊斯兰教的影响加大,文化传播范围扩大。中华民国大陆时期,北京地区伊斯兰教发展缓慢。中华人民共和国成立后,特别是十一届三中全会后落实党的民族宗教政策,北京地区伊斯兰教迎来历史上的黄金时期。目前全市共有依法登记的清真寺70座
<sup class="reference" id="cite_ref-157">
<a href="#cite_note-157">
[150]
</a>
</sup>
。
</p>
<h2>
<span id=".E4.BD.93.E8.82.B2">
</span>
<span class="mw-headline" id="体育">
体育
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=33" title="编辑章节:体育">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<p>
北京曾举办许多国际赛事,包括
<a class="mw-redirect" href="/wiki/1990%E5%B9%B4%E4%BA%9A%E8%BF%90%E4%BC%9A" title="1990年亚运会">
1990年亚运会
</a>
、
<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季奥林匹克运动会">
2008年夏季奥林匹克运动会
</a>
及
<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E6%AE%8B%E7%96%BE%E4%BA%BA%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季残疾人奥林匹克运动会">
残疾人奥林匹克运动会
</a>
、
<a href="/wiki/2015%E5%B9%B4%E4%B8%96%E7%95%8C%E7%94%B0%E5%BE%91%E9%8C%A6%E6%A8%99%E8%B3%BD" title="2015年世界田徑錦標賽">
2015年世界田径锦标赛
</a>
。
</p>
<p>
<a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季奥林匹克运动会">
2022年冬季奥林匹克运动会
</a>
及
<a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E6%AE%8B%E7%96%BE%E4%BA%BA%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季残疾人奥林匹克运动会">
残疾人奥林匹克运动会
</a>
将以北京的名义在北京市及
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">
张家口市
</a>
举办,北京因此成为唯一一座已经举办过夏季奥运会,并将举办冬季奥运会的城市
<sup class="reference" id="cite_ref-158">
<a href="#cite_note-158">
[151]
</a>
</sup>
。
</p>
<h2>
<span id=".E5.8F.8B.E5.A5.BD.E5.9F.8E.E5.B8.82">
</span>
<span class="mw-headline" id="友好城市">
友好城市
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=34" title="编辑章节:友好城市">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="hatnote navigation-not-searchable noprint" role="note">
更详尽的列表见
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8F%8B%E5%A5%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="北京市友好城市列表">
北京市友好城市列表
</a>
。
</div>
<table class="wikitable" style="font-size:88%; text-align:left; width:100%;">
<tbody>
<tr>
<td colspan="3" style="text-align:center; background:#e3e3e3;">
<b>
与北京市结为友好城市的城市
</b>
</td>
</tr>
<tr>
<td>
<div class="div-col columns column-count column-count-4" style="-moz-column-count: 4; -webkit-column-count: 4; column-count: 4;">
<dl>
<dt>
欧洲
</dt>
</dl>
<ul>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="630" data-file-width="945" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_Serbia.svg/22px-Flag_of_Serbia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_Serbia.svg/33px-Flag_of_Serbia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_Serbia.svg/44px-Flag_of_Serbia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%A1%9E%E5%B0%94%E7%BB%B4%E4%BA%9A" title="塞尔维亚">
塞爾維亞
</a>
<a href="/wiki/%E8%B4%9D%E5%B0%94%E6%A0%BC%E8%8E%B1%E5%BE%B7" title="贝尔格莱德">
贝尔格莱德
</a>
<br/>
(1980年10月14日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="500" data-file-width="750" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/22px-Flag_of_Spain.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/33px-Flag_of_Spain.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/44px-Flag_of_Spain.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%A5%BF%E7%8F%AD%E7%89%99" title="西班牙">
西班牙
</a>
<a href="/wiki/%E9%A9%AC%E5%BE%B7%E9%87%8C" title="马德里">
马德里
</a>
<br/>
(1985年9月16日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</span>
<a class="mw-redirect" href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
法國
</a>
<a class="mw-redirect" href="/wiki/%E6%B3%95%E5%85%B0%E8%A5%BF%E5%B2%9B" title="法兰西岛">
法兰西岛大区
</a>
<br/>
(1987年7月2日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1000" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/22px-Flag_of_Germany.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/33px-Flag_of_Germany.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/44px-Flag_of_Germany.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">
德國
</a>
<a href="/wiki/%E7%A7%91%E9%9A%86" title="科隆">
科隆
</a>
<br/>
(1987年9月14日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="800" data-file-width="1200" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/49/Flag_of_Ukraine.svg/22px-Flag_of_Ukraine.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/49/Flag_of_Ukraine.svg/33px-Flag_of_Ukraine.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/49/Flag_of_Ukraine.svg/44px-Flag_of_Ukraine.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B9%8C%E5%85%8B%E5%85%B0" title="乌克兰">
烏克蘭
</a>
<a class="mw-redirect" href="/wiki/%E5%9F%BA%E8%BE%85" title="基辅">
基辅
</a>
<br/>
(1993年12月13日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1000" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/22px-Flag_of_Germany.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/33px-Flag_of_Germany.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/44px-Flag_of_Germany.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">
德國
</a>
<a href="/wiki/%E6%9F%8F%E6%9E%97" title="柏林">
柏林
</a>
<br/>
(1994年4月5日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/92/Flag_of_Belgium_%28civil%29.svg/22px-Flag_of_Belgium_%28civil%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/92/Flag_of_Belgium_%28civil%29.svg/33px-Flag_of_Belgium_%28civil%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/92/Flag_of_Belgium_%28civil%29.svg/44px-Flag_of_Belgium_%28civil%29.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%AF%94%E5%88%A9%E6%97%B6" title="比利时">
比利時
</a>
<a href="/wiki/%E5%B8%83%E9%B2%81%E5%A1%9E%E5%B0%94" title="布鲁塞尔">
布鲁塞尔
</a>
<br/>
(1994年9月22日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/22px-Flag_of_the_Netherlands.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/33px-Flag_of_the_Netherlands.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/44px-Flag_of_the_Netherlands.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%8D%B7%E5%85%B0" title="荷兰">
荷蘭
</a>
<a href="/wiki/%E9%98%BF%E5%A7%86%E6%96%AF%E7%89%B9%E4%B8%B9" title="阿姆斯特丹">
阿姆斯特丹
</a>
<br/>
(1994年10月29日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/22px-Flag_of_Russia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/33px-Flag_of_Russia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/44px-Flag_of_Russia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%BF%84%E7%BD%97%E6%96%AF" title="俄罗斯">
俄羅斯
</a>
<a href="/wiki/%E8%8E%AB%E6%96%AF%E7%A7%91" title="莫斯科">
莫斯科
</a>
<br/>
(1995年5月16日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</span>
<a class="mw-redirect" href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
法國
</a>
<a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">
巴黎
</a>
<br/>
(1997年10月23日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" width="22"/>
</span>
<a class="mw-redirect" href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利">
義大利
</a>
<a href="/wiki/%E7%BD%97%E9%A9%AC" title="罗马">
罗马
</a>
<br/>
(1998年5月28日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="500" data-file-width="750" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/22px-Flag_of_Spain.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/33px-Flag_of_Spain.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/44px-Flag_of_Spain.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%A5%BF%E7%8F%AD%E7%89%99" title="西班牙">
西班牙
</a>
<a href="/wiki/%E9%A9%AC%E5%BE%B7%E9%87%8C%E8%87%AA%E6%B2%BB%E5%8C%BA" title="马德里自治区">
马德里自治区
</a>
<br/>
(2005年1月17日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="400" data-file-width="600" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/22px-Flag_of_Greece.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/33px-Flag_of_Greece.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/44px-Flag_of_Greece.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%B8%8C%E8%85%8A" title="希腊">
希臘
</a>
<a href="/wiki/%E9%9B%85%E5%85%B8" title="雅典">
雅典
</a>
<br/>
(2005年5月10日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="400" data-file-width="600" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Portugal.svg/22px-Flag_of_Portugal.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Portugal.svg/33px-Flag_of_Portugal.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Portugal.svg/44px-Flag_of_Portugal.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%91%A1%E8%90%84%E7%89%99" title="葡萄牙">
葡萄牙
</a>
<a href="/wiki/%E9%87%8C%E6%96%AF%E6%9C%AC" title="里斯本">
里斯本
</a>
<br/>
(2007年)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="700" data-file-width="980" decoding="async" height="16" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Flag_of_Albania.svg/22px-Flag_of_Albania.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/36/Flag_of_Albania.svg/33px-Flag_of_Albania.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/36/Flag_of_Albania.svg/44px-Flag_of_Albania.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E9%98%BF%E5%B0%94%E5%B7%B4%E5%B0%BC%E4%BA%9A" title="阿尔巴尼亚">
阿尔巴尼亚
</a>
<a href="/wiki/%E5%9C%B0%E6%8B%89%E9%82%A3" title="地拉那">
地拉那
</a>
<br/>
(2007年)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/45/Flag_of_Ireland.svg/22px-Flag_of_Ireland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/45/Flag_of_Ireland.svg/33px-Flag_of_Ireland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/45/Flag_of_Ireland.svg/44px-Flag_of_Ireland.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E7%88%B1%E5%B0%94%E5%85%B0" title="爱尔兰">
爱尔兰
</a>
<a href="/wiki/%E9%83%BD%E6%9F%8F%E6%9E%97" title="都柏林">
都柏林
</a>
<br/>
(2011年)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c1/Flag_of_Hungary.svg/22px-Flag_of_Hungary.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c1/Flag_of_Hungary.svg/33px-Flag_of_Hungary.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c1/Flag_of_Hungary.svg/44px-Flag_of_Hungary.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%8C%88%E7%89%99%E5%88%A9" title="匈牙利">
匈牙利
</a>
<a href="/wiki/%E5%B8%83%E8%BE%BE%E4%BD%A9%E6%96%AF" title="布达佩斯">
布达佩斯
</a>
<br/>
(2005年6月16日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="400" data-file-width="600" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/73/Flag_of_Romania.svg/22px-Flag_of_Romania.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/73/Flag_of_Romania.svg/33px-Flag_of_Romania.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/73/Flag_of_Romania.svg/44px-Flag_of_Romania.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E7%BE%85%E9%A6%AC%E5%B0%BC%E4%BA%9E" title="羅馬尼亞">
羅馬尼亞
</a>
<a href="/wiki/%E5%B8%83%E5%8A%A0%E5%8B%92%E6%96%AF%E7%89%B9" title="布加勒斯特">
布加勒斯特
</a>
<br/>
(2005年6月21日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国">
英國
</a>
<a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">
伦敦
</a>
<br/>
(2006年4月10日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="1100" data-file-width="1800" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/22px-Flag_of_Finland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/33px-Flag_of_Finland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/44px-Flag_of_Finland.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%8A%AC%E5%85%B0" title="芬兰">
芬兰
</a>
<a href="/wiki/%E8%B5%AB%E5%B0%94%E8%BE%9B%E5%9F%BA" title="赫尔辛基">
赫尔辛基
</a>
<br/>
(2006年)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="387" data-file-width="512" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9c/Flag_of_Denmark.svg/22px-Flag_of_Denmark.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9c/Flag_of_Denmark.svg/33px-Flag_of_Denmark.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9c/Flag_of_Denmark.svg/44px-Flag_of_Denmark.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%B9%E9%BA%A6" title="丹麦">
丹麥
</a>
<a href="/wiki/%E5%93%A5%E6%9C%AC%E5%93%88%E6%A0%B9" title="哥本哈根">
哥本哈根
</a>
<br/>
(2012年6月26日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/84/Flag_of_Latvia.svg/22px-Flag_of_Latvia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/84/Flag_of_Latvia.svg/33px-Flag_of_Latvia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/84/Flag_of_Latvia.svg/44px-Flag_of_Latvia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%8B%89%E8%84%AB%E7%B6%AD%E4%BA%9E" title="拉脫維亞">
拉脫維亞
</a>
<a href="/wiki/%E9%87%8C%E5%8A%A0" title="里加">
里加
</a>
<br/>
(2017年9月15日)
</li>
</ul>
<dl>
<dt>
亚洲
</dt>
</dl>
<ul>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/22px-Flag_of_Japan.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/33px-Flag_of_Japan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/44px-Flag_of_Japan.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
日本
</a>
<a class="mw-redirect" href="/wiki/%E4%B8%9C%E4%BA%AC%E9%83%BD" title="东京都">
东京都
</a>
<br/>
(1979年3月14日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="800" data-file-width="1600" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/51/Flag_of_North_Korea.svg/22px-Flag_of_North_Korea.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/51/Flag_of_North_Korea.svg/33px-Flag_of_North_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/51/Flag_of_North_Korea.svg/44px-Flag_of_North_Korea.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%9C%9D%E9%B2%9C%E6%B0%91%E4%B8%BB%E4%B8%BB%E4%B9%89%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="朝鲜民主主义人民共和国">
北韓
</a>
<a href="/wiki/%E5%B9%B3%E5%A3%A4" title="平壤">
平壤
</a>
<br/>
(1986年10月18日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/21/Flag_of_Vietnam.svg/22px-Flag_of_Vietnam.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/21/Flag_of_Vietnam.svg/33px-Flag_of_Vietnam.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/21/Flag_of_Vietnam.svg/44px-Flag_of_Vietnam.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">
越南
</a>
<a class="mw-redirect" href="/wiki/%E6%B2%B3%E5%86%85" title="河内">
河内
</a>
<br/>
(1994年10月6日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/22px-Flag_of_South_Korea.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/33px-Flag_of_South_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/44px-Flag_of_South_Korea.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国">
南韓
</a>
<a class="mw-redirect" href="/wiki/%E9%A6%96%E5%B0%94" title="首尔">
首尔
</a>
<br/>
(1993年10月23日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Flag_of_Thailand.svg/22px-Flag_of_Thailand.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Flag_of_Thailand.svg/33px-Flag_of_Thailand.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Flag_of_Thailand.svg/44px-Flag_of_Thailand.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%B3%B0%E5%9B%BD" title="泰国">
泰國
</a>
<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">
曼谷
</a>
<br/>
(1993年5月26日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Flag_of_Indonesia.svg/22px-Flag_of_Indonesia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Flag_of_Indonesia.svg/33px-Flag_of_Indonesia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Flag_of_Indonesia.svg/44px-Flag_of_Indonesia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%8D%B0%E5%BA%A6%E5%B0%BC%E8%A5%BF%E4%BA%9A" title="印度尼西亚">
印尼
</a>
<a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">
雅加达
</a>
<br/>
(1993年8月4日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/66/Flag_of_Malaysia.svg/22px-Flag_of_Malaysia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/66/Flag_of_Malaysia.svg/33px-Flag_of_Malaysia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/66/Flag_of_Malaysia.svg/44px-Flag_of_Malaysia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A" title="马来西亚">
马来西亚
</a>
<a href="/wiki/%E5%90%89%E9%9A%86%E5%9D%A1" title="吉隆坡">
吉隆坡
</a>
<br/>
(2009年1月15日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/32/Flag_of_Pakistan.svg/22px-Flag_of_Pakistan.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/32/Flag_of_Pakistan.svg/33px-Flag_of_Pakistan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/32/Flag_of_Pakistan.svg/44px-Flag_of_Pakistan.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%B7%B4%E5%9F%BA%E6%96%AF%E5%9D%A6" title="巴基斯坦">
巴基斯坦
</a>
<a href="/wiki/%E4%BC%8A%E6%96%AF%E5%85%B0%E5%A0%A1" title="伊斯兰堡">
伊斯兰堡
</a>
<br/>
(1992年10月8日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="800" data-file-width="1200" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/22px-Flag_of_Turkey.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/33px-Flag_of_Turkey.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/44px-Flag_of_Turkey.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%9C%9F%E8%80%B3%E5%85%B6" title="土耳其">
土耳其
</a>
<a href="/wiki/%E5%AE%89%E5%8D%A1%E6%8B%89" title="安卡拉">
安卡拉
</a>
<br/>
(1990年6月20日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/99/Flag_of_the_Philippines.svg/22px-Flag_of_the_Philippines.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/99/Flag_of_the_Philippines.svg/33px-Flag_of_the_Philippines.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/99/Flag_of_the_Philippines.svg/44px-Flag_of_the_Philippines.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E8%8F%B2%E5%BE%8B%E5%AE%BE" title="菲律宾">
菲律賓
</a>
<a href="/wiki/%E9%A9%AC%E5%B0%BC%E6%8B%89" title="马尼拉">
马尼拉
</a>
<br/>
(2005年11月14日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="500" data-file-width="1000" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Flag_of_Kazakhstan.svg/22px-Flag_of_Kazakhstan.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Flag_of_Kazakhstan.svg/33px-Flag_of_Kazakhstan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Flag_of_Kazakhstan.svg/44px-Flag_of_Kazakhstan.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%93%88%E8%90%A8%E5%85%8B%E6%96%AF%E5%9D%A6" title="哈萨克斯坦">
哈萨克斯坦
</a>
<a class="mw-redirect" href="/wiki/%E5%8A%AA%E5%B0%94%E8%8B%8F%E4%B8%B9" title="努尔苏丹">
努尔苏丹
</a>
<br/>
(2006年11月16日)
</li>
</ul>
<dl>
<dt>
非洲
</dt>
</dl>
<ul>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Flag_of_Egypt.svg/22px-Flag_of_Egypt.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Flag_of_Egypt.svg/33px-Flag_of_Egypt.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Flag_of_Egypt.svg/44px-Flag_of_Egypt.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%9F%83%E5%8F%8A" title="埃及">
埃及
</a>
<a href="/wiki/%E5%BC%80%E7%BD%97" title="开罗">
开罗
</a>
<br/>
(1990年10月28日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/af/Flag_of_South_Africa.svg/22px-Flag_of_South_Africa.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/af/Flag_of_South_Africa.svg/33px-Flag_of_South_Africa.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/af/Flag_of_South_Africa.svg/44px-Flag_of_South_Africa.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%8D%97%E9%9D%9E" title="南非">
南非
</a>
<a href="/wiki/%E8%B1%AA%E7%99%BB%E7%9C%81" title="豪登省">
豪登省
</a>
<br/>
(1998年5月28日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Flag_of_Malawi.svg/22px-Flag_of_Malawi.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Flag_of_Malawi.svg/33px-Flag_of_Malawi.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d1/Flag_of_Malawi.svg/44px-Flag_of_Malawi.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E9%A9%AC%E6%8B%89%E7%BB%B4" title="马拉维">
马拉维
</a>
<a href="/wiki/%E5%88%A9%E9%9A%86%E5%9C%AD" title="利隆圭">
利隆圭
</a>
<br/>
(2008年1月15日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/71/Flag_of_Ethiopia.svg/22px-Flag_of_Ethiopia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/71/Flag_of_Ethiopia.svg/33px-Flag_of_Ethiopia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/71/Flag_of_Ethiopia.svg/44px-Flag_of_Ethiopia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%9F%83%E5%A1%9E%E4%BF%84%E6%AF%94%E4%BA%9A" title="埃塞俄比亚">
衣索比亞
</a>
<a href="/wiki/%E4%BA%9A%E7%9A%84%E6%96%AF%E4%BA%9A%E8%B4%9D%E5%B7%B4" title="亚的斯亚贝巴">
亚的斯亚贝巴
</a>
<br/>
(2008年1月15日)
</li>
</ul>
<dl>
<dt>
大洋洲
</dt>
</dl>
<ul>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="640" data-file-width="1280" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/22px-Flag_of_Australia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/33px-Flag_of_Australia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/44px-Flag_of_Australia.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%BE%B3%E5%A4%A7%E5%88%A9%E4%BA%9A" title="澳大利亚">
澳大利亚
</a>
<a href="/wiki/%E5%A0%AA%E5%9F%B9%E6%8B%89" title="堪培拉">
堪培拉
</a>
<br/>
(1979年3月14日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/3/3e/Flag_of_New_Zealand.svg/22px-Flag_of_New_Zealand.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/3/3e/Flag_of_New_Zealand.svg/33px-Flag_of_New_Zealand.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/3/3e/Flag_of_New_Zealand.svg/44px-Flag_of_New_Zealand.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%96%B0%E8%A5%BF%E5%85%B0" title="新西兰">
新西蘭
</a>
<a href="/wiki/%E6%83%A0%E7%81%B5%E9%A1%BF" title="惠灵顿">
惠灵顿
</a>
<br/>
(2006年)
</li>
</ul>
<dl>
<dt>
北美洲
</dt>
</dl>
<ul>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</span>
<a class="mw-redirect" href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
美國
</a>
<a href="/wiki/%E7%BA%BD%E7%BA%A6" title="纽约">
纽约
</a>
<br/>
(1980年2月25日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</span>
<a class="mw-redirect" href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
美國
</a>
<a href="/wiki/%E5%8D%8E%E7%9B%9B%E9%A1%BF%E5%93%A5%E4%BC%A6%E6%AF%94%E4%BA%9A%E7%89%B9%E5%8C%BA" title="华盛顿哥伦比亚特区">
华盛顿
</a>
<br/>
(1984年)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="256" data-file-width="512" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大">
加拿大
</a>
<a class="mw-redirect" href="/wiki/%E6%B8%A5%E5%A4%AA%E5%8D%8E" title="渥太华">
渥太华
</a>
<br/>
(1999年10月20日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="560" data-file-width="980" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/22px-Flag_of_Mexico.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/33px-Flag_of_Mexico.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/44px-Flag_of_Mexico.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5" title="墨西哥">
墨西哥
</a>
<a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5%E5%9F%8E" title="墨西哥城">
墨西哥城
</a>
<br/>
(2009年10月21日)
</li>
</ul>
<dl>
<dt>
南美洲
</dt>
</dl>
<ul>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="500" data-file-width="800" decoding="async" height="14" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Flag_of_Argentina.svg/22px-Flag_of_Argentina.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Flag_of_Argentina.svg/33px-Flag_of_Argentina.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1a/Flag_of_Argentina.svg/44px-Flag_of_Argentina.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E9%98%BF%E6%A0%B9%E5%BB%B7" title="阿根廷">
阿根廷
</a>
<a class="mw-redirect" href="/wiki/%E5%B8%83%E5%AE%9C%E8%AF%BA%E6%96%AF%E8%89%BE%E5%88%A9%E6%96%AF" title="布宜诺斯艾利斯">
布宜诺斯艾利斯
</a>
<br/>
(1993年7月13日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="742" data-file-width="1060" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/22px-Flag_of_Brazil.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/33px-Flag_of_Brazil.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/44px-Flag_of_Brazil.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%B7%B4%E8%A5%BF" title="巴西">
巴西
</a>
<a href="/wiki/%E9%87%8C%E7%BA%A6%E7%83%AD%E5%86%85%E5%8D%A2" title="里约热内卢">
里约热内卢
</a>
<br/>
(1986年11月24日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/cf/Flag_of_Peru.svg/22px-Flag_of_Peru.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/cf/Flag_of_Peru.svg/33px-Flag_of_Peru.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/cf/Flag_of_Peru.svg/44px-Flag_of_Peru.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E7%A7%98%E9%B2%81" title="秘鲁">
秘魯
</a>
<a class="mw-redirect" href="/wiki/%E5%88%A9%E9%A9%AC" title="利马">
利马
</a>
<br/>
(1983年11月21日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Flag_of_Cuba.svg/22px-Flag_of_Cuba.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Flag_of_Cuba.svg/33px-Flag_of_Cuba.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bd/Flag_of_Cuba.svg/44px-Flag_of_Cuba.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E5%8F%A4%E5%B7%B4" title="古巴">
古巴
</a>
<a href="/wiki/%E5%93%88%E7%93%A6%E9%82%A3" title="哈瓦那">
哈瓦那
</a>
<br/>
(2005年9月24日)
</li>
<li>
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Chile.svg/22px-Flag_of_Chile.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Chile.svg/33px-Flag_of_Chile.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Chile.svg/44px-Flag_of_Chile.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%99%BA%E5%88%A9" title="智利">
智利
</a>
<a href="/wiki/%E5%9C%A3%E5%9C%B0%E4%BA%9A%E5%93%A5_(%E6%99%BA%E5%88%A9)" title="圣地亚哥 (智利)">
圣地亚哥
</a>
<br/>
(2007年年末)
<sup class="reference" id="cite_ref-159">
<a href="#cite_note-159">
[152]
</a>
</sup>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<h2>
<span id=".E6.B3.A8.E9.87.8A">
</span>
<span class="mw-headline" id="注释">
注释
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=35" title="编辑章节:注释">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div id="references-NoteFoot">
<ol class="references">
<li id="cite_note-3">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-3">
^
</a>
</b>
</span>
<span class="reference-text">
市区指
<a href="/wiki/%E5%9F%8E%E5%85%AD%E5%8C%BA" title="城六区">
城六区
</a>
,即北京市中心城区和拓展区的东城区、西城区、海淀区、朝阳区、丰台区、石景山区六区,面积约为1381平方公里“城六区”就是以前的“城八区”,范围、面积没有改变。“城六区”是现代语境下的北京城。
</span>
</li>
<li id="cite_note-16">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-16">
^
</a>
</b>
</span>
<span class="reference-text">
与此同时,附近的无终县改名
<a href="/wiki/%E6%B8%94%E9%98%B3%E9%83%A1" title="渔阳郡">
渔阳
</a>
成为蓟州的
<a href="/wiki/%E8%A1%8C%E6%94%BF%E4%B8%AD%E5%BF%83" title="行政中心">
首府
</a>
,至1913年更用了
<a class="mw-redirect" href="/wiki/%E8%93%9F%E5%8E%BF" title="蓟县">
蓟县
</a>
的名称,今天属于
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
境内,而非今天的北京市范围。所以
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8E%86%E5%8F%B2" title="中国历史">
中国历史
</a>
上隋唐以前的蓟在今
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC" title="北京">
北京
</a>
,隋唐以后的蓟在今
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E6%B4%A5" title="天津">
天津
</a>
。
</span>
</li>
<li id="cite_note-17">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-17">
^
</a>
</b>
</span>
<span class="reference-text">
金大定二十九年公元1189年始建石桥,三年后的金章宗明昌三年公元1192年建成,当时称广利桥。
</span>
</li>
<li id="cite_note-19">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-19">
^
</a>
</b>
</span>
<span class="reference-text">
<a href="/wiki/%E5%8F%A4%E4%BB%A3%E7%AA%81%E5%8E%A5%E8%AA%9E" title="古代突厥語">
突厥语
</a>
为Khanbalik,意为“汗城”,音译为
<a class="mw-redirect" href="/wiki/%E6%B1%97%E5%85%AB%E9%87%8C" title="汗八里">
汗八里
</a>
、甘巴力克。
</span>
</li>
<li id="cite_note-97">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-97">
^
</a>
</b>
</span>
<span class="reference-text">
土地面积为
<a class="mw-redirect" href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E5%85%A8%E5%9B%BD%E5%9C%9F%E5%9C%B0%E8%B0%83%E6%9F%A5" title="第二次全国土地调查">
第二次全国土地调查
</a>
结果数据。
</span>
</li>
<li id="cite_note-98">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-98">
^
</a>
</b>
</span>
<span class="reference-text">
常住人口为2018年北京市人口变动情况抽样调查数据。
</span>
</li>
<li id="cite_note-119">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-119">
^
</a>
</b>
</span>
<span class="reference-text">
另有一條國道
<a href="/wiki/112%E5%9B%BD%E9%81%93" title="112国道">
G112
</a>
環繞北京但不經過北京市範圍。
</span>
</li>
</ol>
</div>
<h2>
<span id=".E5.8F.82.E8.80.83.E6.96.87.E7.8C.AE">
</span>
<span class="mw-headline" id="参考文献">
参考文献
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=36" title="编辑章节:参考文献">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div class="reflist columns references-column-width" style="-moz-column-width: 32em; -webkit-column-width: 32em; column-width: 32em; list-style-type: decimal;">
<ol class="references">
<li id="cite_note-1">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-1">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://tjj.beijing.gov.cn/tjsj_31433/tjgb_31445/ndgb_31446/202003/t20200302_1673343.html" rel="nofollow">
北京市2019年国民经济和社会发展统计公报
</a>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%822019%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.genre=unknown&rft_id=http%3A%2F%2Ftjj.beijing.gov.cn%2Ftjsj_31433%2Ftjgb_31445%2Fndgb_31446%2F202003%2Ft20200302_1673343.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-2">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-2">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://www.sohu.com/a/405202052_621014" rel="nofollow">
2019年末北京各区县人口排名,你所在区县人口增多了吗?
</a>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=2019%E5%B9%B4%E6%9C%AB%E5%8C%97%E4%BA%AC%E5%90%84%E5%8C%BA%E5%8E%BF%E4%BA%BA%E5%8F%A3%E6%8E%92%E5%90%EF%BC%8C%E4%BD%A0%E6%89%E5%9C%A8%E5%8C%BA%E5%8E%BF%E4%BA%BA%E5%8F%A3%E5%A2%9E%E5%A4%9A%E4%BA%86%E5%90%97%EF%BC%9F&rft.genre=unknown&rft_id=https%3A%2F%2Fwww.sohu.com%2Fa%2F405202052_621014&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-4">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-4">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://tjj.beijing.gov.cn/tjsj_31433/tjgb_31445/ndgb_31446/202003/t20200302_1673343.html" rel="nofollow">
北京市2019年国民经济和社会发展统计公报
</a>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%822019%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.genre=unknown&rft_id=http%3A%2F%2Ftjj.beijing.gov.cn%2Ftjsj_31433%2Ftjgb_31445%2Fndgb_31446%2F202003%2Ft20200302_1673343.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-autogenerated2-5">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-autogenerated2_5-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.bbtnews.com.cn/2018/0225/230505.shtml" rel="nofollow">
存档副本
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2018-04-20
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20180420202857/http://www.bbtnews.com.cn/2018/0225/230505.shtml" rel="nofollow">
存档
</a>
于2018-04-20).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5+%98%E6%A1%A3%E5%89%AF%E6%9C%AC&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bbtnews.com.cn%2F2018%2F0225%2F230505.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-6">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-6">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
travelguide.michelin.com.
<a class="external text" href="https://travelguide.michelin.com/asia/china/pekin" rel="nofollow">
Travelguide Beijing
</a>
. travelguide.michelin.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-04-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200425095712/https://travelguide.michelin.com/asia/china/pekin" rel="nofollow">
存档
</a>
于2020-04-25)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英语网页">
(英语)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=travelguide.michelin.com&rft.btitle=Travelguide+Beijing&rft.genre=unknown&rft.pub=travelguide.michelin.com&rft_id=https%3A%2F%2Ftravelguide.michelin.com%2Fasia%2Fchina%2Fpekin&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-7">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-7">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
马婧.
<a class="external text" href="http://bj.people.com.cn/n2/2018/0605/c82839-31665914.html" rel="nofollow">
北京总部企业5年增127家 500强总部企业北京全球最多
</a>
. 人民网.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-01-21
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%BB%E9%83%A8%E4%BC%81%E4%B8%9A5%E5%B9%B4%E5%A2%9E127%E5%AE%B6+500%E5%BC%BA%E6%BB%E9%83%A8%E4%BC%81%E4%B8%9A%E5%8C%97%E4%BA%AC%E5%85%A8%E7%90%83%E6%9C%E5%A4%9A&rft.au=%E9%A9%AC%E5%A9%A7&rft.genre=unknown&rft.jtitle=%E4%BA%BA%E6%B0%91%E7%BD%91&rft_id=http%3A%2F%2Fbj.people.com.cn%2Fn2%2F2018%2F0605%2Fc82839-31665914.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-2018年旅客破亿-8">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-2018年旅客破亿_8-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
赵晓兵.
<a class="external text" href="http://www.caacnews.com.cn/1/5/201812/t20181228_1263791.html" rel="nofollow">
北京首都国际机场年旅客吞吐量突破1亿人次
</a>
. 中国民航网. 2018-12-28
<span class="reference-accessdate">
[
<span class="nowrap">
2018-12-28
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20181228223136/http://www.caacnews.com.cn/1/5/201812/t20181228_1263791.html" rel="nofollow">
存档
</a>
于2018-12-28).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E8%B5%B5%E6%99%93%E5%85%B5&rft.btitle=%E5%8C%97%E4%BA%AC%E9%A6%96%E9%83%BD%E5%9B%BD%E9%99%85%E6%9C%BA%E5%9C%BA%E5%B9%B4%E6%97%85%E5%AE%A2%E5%90%9E%E5%90%90%E9%87%8F%E7%AA%81%E7%A0%B41%E4%BA%BF%E4%BA%BA%E6%AC%A1&rft.date=2018-12-28&rft.genre=unknown&rft.pub=%E4%B8+%E5%9B%BD%E6%B0%91%E8%88%AA%E7%BD%91&rft_id=http%3A%2F%2Fwww.caacnews.com.cn%2F1%2F5%2F201812%2Ft20181228_1263791.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-9">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-9">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://www.railwaygazette.com/transport-and-mobility-projects/beijing-metro-now-the-worlds-longest/55436.article" rel="nofollow">
Beijing metro now the world’s longest
</a>
. Railway Gazette Group - Metro Report International. 2019-12-30
<span class="reference-accessdate">
[
<span class="nowrap">
2020-01-21
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20191230133940/https://www.railwaygazette.com/transport-and-mobility-projects/beijing-metro-now-the-worlds-longest/55436.article" rel="nofollow">
存档
</a>
于2019-12-30).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=Beijing+metro+now+the+world%99s+longest&rft.date=2019-12-30&rft.genre=unknown&rft.jtitle=Railway+Gazette+Group+-+Metro+Report+International&rft_id=https%3A%2F%2Fwww.railwaygazette.com%2Ftransport-and-mobility-projects%2Fbeijing-metro-now-the-worlds-longest%2F55436.article&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-10">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-10">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://www.railjournal.com/passenger/metros/beijing-metro-tops-699km-making-it-worlds-largest-network/" rel="nofollow">
Beijing Metro tops 699km making it world's largest network
</a>
. International Railway Journal. 2019-12-30
<span class="reference-accessdate">
[
<span class="nowrap">
2020-01-21
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200106092302/https://www.railjournal.com/passenger/metros/beijing-metro-tops-699km-making-it-worlds-largest-network/" rel="nofollow">
存档
</a>
于2020-01-06).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=Beijing+Metro+tops+699km+making+it+world%27s+largest+network&rft.date=2019-12-30&rft.genre=unknown&rft.jtitle=International+Railway+Journal&rft_id=https%3A%2F%2Fwww.railjournal.com%2Fpassenger%2Fmetros%2Fbeijing-metro-tops-699km-making-it-worlds-largest-network%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-11">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-11">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
中国城市轨道交通年度报告课题组.
<a class="external text" href="https://web.archive.org/web/20160304222832/http://huoche.kuxun.cn/news-73978.html" rel="nofollow">
北京地铁成世界最繁忙地铁之首 暑期客流每天破千万人次
</a>
. 北京: 酷讯. 2012
<span class="reference-accessdate">
[
<span class="nowrap">
2020-01-21
</span>
]
</span>
.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-7-5121-1009-0" title="Special:网络书源/978-7-5121-1009-0">
<span title="国际标准书号">
ISBN
</span>
978-7-5121-1009-0
</a>
. (
<a class="external text" href="http://huoche.kuxun.cn/news-73978.html" rel="nofollow">
原始内容
</a>
存档于2016-03-04).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E6%88%90%E4%B8%96%E7%95%8C%E6%9C%E7%B9%81%E5%BF%99%E5%9C%B0%E9%93%81%E4%B9%E9%A6%96+%E6%9A%91%E6%9C%9F%E5%AE%A2%E6%B5%81%E6%AF%8F%E5%A4%A9%E7%A0%B4%E5%83%E4%B8%87%E4%BA%BA%E6%AC%A1&rft.au=%E4%B8+%E5%9B%BD%E5%9F%8E%E5%B8%82%E8%BD%A8%E9%81%93%E4%BA%A4%E9%9A%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%E8%AF%BE%E9%A2%98%E7%BB%84&rft.date=2012&rft.genre=article&rft.isbn=978-7-5121-1009-0&rft_id=http%3A%2F%2Fhuoche.kuxun.cn%2Fnews-73978.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-Beijing-12">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-Beijing_12-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.gaokao.com/e/20150522/555e867ac971b.shtml" rel="nofollow">
<bdi lang="zh">
2015年北京市高校名单(共91所)
</bdi>
</a>
. gaokao.com. 2015-05-22
<span class="reference-accessdate">
[
<span class="nowrap">
2016-11-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20161130185436/http://www.gaokao.com/e/20150522/555e867ac971b.shtml" rel="nofollow">
存档
</a>
于2016-11-30).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=2015%E5%B9%B4%E5%8C%97%E4%BA%AC%E5%B8%82%E9%AB%98%E6%A0%A1%E5%90%E5%95%EF%BC%88%E5%85%B191%E6%89%EF%BC%89&rft.date=2015-05-22&rft.genre=unknown&rft.pub=gaokao.com&rft_id=http%3A%2F%2Fwww.gaokao.com%2Fe%2F20150522%2F555e867ac971b.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-13">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-13">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
徐晉如.
<a class="external text" href="https://books.google.com.tw/books?id=gNdxAAAAIAAJ&q=%E6%B8%85%E8%8F%AF%E7%AC%AC%E4%B8%80%E5%8C%97%E5%A4%A7%E7%AC%AC%E4%BA%8C&dq=%E6%B8%85%E8%8F%AF%E7%AC%AC%E4%B8%80%E5%8C%97%E5%A4%A7%E7%AC%AC%E4%BA%8C&hl=zh-TW&sa=X&ved=0ahUKEwjf0P-TsqnVAhVLmJQKHQj5DEIQ6AEIJDAA" rel="nofollow">
清華第一北大第二
</a>
. 北京: 台海出版社. 2006-12-08
<span class="reference-accessdate">
[
<span class="nowrap">
2017-07-27
</span>
]
</span>
.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/7-80141-295-8" title="Special:网络书源/7-80141-295-8">
<span title="国际标准书号">
ISBN
</span>
7-80141-295-8
</a>
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%BE%90%E6%99%89%E5%A6%82&rft.btitle=%E6%B8%85%E8%8F%AF%E7%AC%AC%E4%B8%E5%8C%97%E5%A4%A7%E7%AC%AC%E4%BA%8C&rft.date=2006-12-08&rft.genre=book&rft.isbn=7-80141-295-8&rft.place=%E5%8C%97%E4%BA%AC&rft.pub=%E5%8F%B0%E6%B5%B7%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=https%3A%2F%2Fbooks.google.com.tw%2Fbooks%3Fid%3DgNdxAAAAIAAJ%26q%3D%25E6%25B8%2585%25E8%258F%25AF%25E7%25AC%25AC%25E4%25B8%2580%25E5%258C%2597%25E5%25A4%25A7%25E7%25AC%25AC%25E4%25BA%258C%26dq%3D%25E6%25B8%2585%25E8%258F%25AF%25E7%25AC%25AC%25E4%25B8%2580%25E5%258C%2597%25E5%25A4%25A7%25E7%25AC%25AC%25E4%25BA%258C%26hl%3Dzh-TW%26sa%3DX%26ved%3D0ahUKEwjf0P-TsqnVAhVLmJQKHQj5DEIQ6AEIJDAA&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-14">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-14">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20200824031341/https://www.lboro.ac.uk/gawc/world2020t.html" rel="nofollow">
GaWC - The World According to GaWC 2020
</a>
. www.lboro.ac.uk.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-09-26
</span>
]
</span>
. (
<a class="external text" href="https://www.lboro.ac.uk/gawc/world2020t.html" rel="nofollow">
原始内容
</a>
存档于2020-08-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=GaWC+-+The+World+According+to+GaWC+2020&rft.genre=unknown&rft.jtitle=www.lboro.ac.uk&rft_id=https%3A%2F%2Fwww.lboro.ac.uk%2Fgawc%2Fworld2020t.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-15">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-15">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
宋大川. 北京考古发现与研究 : 1949-2009 第1版. 北京: 科学出版社. 2009-09.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/9787030255693" title="Special:网络书源/9787030255693">
<span title="国际标准书号">
ISBN
</span>
9787030255693
</a>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%AE%E5%A4%A7%E5%B7%9D&rft.btitle=%E5%8C%97%E4%BA%AC%E8%83%E5%8F%A4%E5%8F%91%E7%8E%B0%E4%B8%8E%E7%A0%94%E7%A9%B6+%3A+1949-2009&rft.date=2009-09&rft.edition=%E7%AC%AC1%E7%89%88&rft.genre=book&rft.isbn=9787030255693&rft.place=%E5%8C%97%E4%BA%AC&rft.pub=%E7%A7%91%E5+%A6%E5%87%BA%E7%89%88%E7%A4%BE&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
<span class="error citation-comment" style="display:none;font-size:100%">
请检查
<code style="color:inherit; border:inherit; padding:inherit;">
|access-date=
</code>
中的日期值 (
<a href="/wiki/Help:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF#bad_date" title="Help:引文格式1错误">
帮助
</a>
);
</span>
<span class="error citation-comment" style="display:none;font-size:100%">
使用
<code style="color:inherit; border:inherit; padding:inherit;">
|accessdate=
</code>
需要含有
<code style="color:inherit; border:inherit; padding:inherit;">
|url=
</code>
(
<a href="/wiki/Help:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF#accessdate_missing_url" title="Help:引文格式1错误">
帮助
</a>
)
</span>
</span>
</li>
<li id="cite_note-18">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-18">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.zgswcn.com/2014/0610/414339.shtml" rel="nofollow">
“实京师”与“徙流民” 北京历史上的人口变迁
</a>
. Zgswcn.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170904085741/http://www.zgswcn.com/2014/0610/414339.shtml" rel="nofollow">
存档
</a>
于2017-09-04).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%9C%E5%AE%9E%E4%BA%AC%E5%B8%88%9D%E4%B8%8E%9C%E5%BE%99%E6%B5%81%E6%B0%91%9D+%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2%E4%B8%8A%E7%9A%84%E4%BA%BA%E5%8F%A3%E5%8F%98%E8%BF%81&rft.genre=unknown&rft.pub=Zgswcn.com&rft_id=http%3A%2F%2Fwww.zgswcn.com%2F2014%2F0610%2F414339.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-20">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-20">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.china.com.cn/culture/txt/2007-07/30/content_8599134.htm" rel="nofollow">
381年前北京王恭厂大爆炸之谜 僵尸都"裸体
<span style="padding-right:0.2em;">
"
</span>
</a>
. 中国网. 2007-07-30
<span class="reference-accessdate">
[
<span class="nowrap">
2014-02-17
</span>
]
</span>
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">
(中文)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=381%E5%B9%B4%E5%89%E5%8C%97%E4%BA%AC%E7%8E%E6%81+%E5%8E%82%E5%A4%A7%E7%88%86%E7%82%B8%E4%B9%E8%B0%9C+%E5%83%B5%E5%B0%B8%E9%83%BD%22%E8%A3%B8%E4%BD%93%22&rft.date=2007-07-30&rft.genre=unknown&rft.pub=%E4%B8+%E5%9B%BD%E7%BD%91&rft_id=http%3A%2F%2Fwww.china.com.cn%2Fculture%2Ftxt%2F2007-07%2F30%2Fcontent_8599134.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:0-21">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-:0_21-0">
<sup>
<b>
17.0
</b>
</sup>
</a>
<a href="#cite_ref-:0_21-1">
<sup>
<b>
17.1
</b>
</sup>
</a>
<a href="#cite_ref-:0_21-2">
<sup>
<b>
17.2
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.chinanews.com/cul/2013/12-03/5572670.shtml" rel="nofollow">
专家谈明朝灭亡:鼠疫或为重要原因
</a>
.
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E6%96%B0%E7%BD%91" title="中新网">
中新网
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-12-29
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E4%B8%93%E5%AE%B6%E8%B0%88%E6%98%8E%E6%9C%9D%E7%81+%E4%BA%A1%EF%BC%9A%E9%BC%A0%E7%96%AB%E6%88%96%E4%B8%BA%E9%87%E8%A6%81%E5%8E%9F%E5%9B%A0&rft.genre=unknown&rft.pub=%E4%B8+%E6%96%B0%E7%BD%91&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fcul%2F2013%2F12-03%2F5572670.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
<span class="error mw-ext-cite-error" dir="ltr" lang="zh">
引用错误:带有name属性“:0”的
<code>
<ref>
</code>
标签用不同内容定义了多次
</span>
</span>
</li>
<li id="cite_note-:1-22">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-:1_22-0">
<sup>
<b>
18.0
</b>
</sup>
</a>
<a href="#cite_ref-:1_22-1">
<sup>
<b>
18.1
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation journal">
<a href="/wiki/%E6%9B%B9%E6%A0%91%E5%9F%BA" title="曹树基">
曹树基
</a>
.
<a class="external text" href="https://history.sjtu.edu.cn/SJTU/JDHistory/kindeditor/Upload/file/20200709/202007091001022470000.pdf" rel="nofollow">
鼠疫流行与华北社会的变迁 (1580—1644 年)
</a>
<span style="font-size:85%;">
(PDF)
</span>
. 《历史研究》. 1997, (1).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%BC%A0%E7%96%AB%E6%B5%81%E8%A1%8C%E4%B8%8E%E5%8E%E5%8C%97%E7%A4%BE%E4%BC%9A%E7%9A%84%E5%8F%98%E8%BF%81+%281580%941644+%E5%B9%B4%29&rft.au=%E6%9B%B9%E6%A0%91%E5%9F%BA&rft.date=1997&rft.genre=article&rft.issue=1&rft.jtitle=%E3%8A%E5%8E%86%E5%8F%B2%E7%A0%94%E7%A9%B6%E3&rft_id=https%3A%2F%2Fhistory.sjtu.edu.cn%2FSJTU%2FJDHistory%2Fkindeditor%2FUpload%2Ffile%2F20200709%2F202007091001022470000.pdf&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
<span class="error mw-ext-cite-error" dir="ltr" lang="zh">
引用错误:带有name属性“:1”的
<code>
<ref>
</code>
标签用不同内容定义了多次
</span>
</span>
</li>
<li id="cite_note-:2-23">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-:2_23-0">
<sup>
<b>
19.0
</b>
</sup>
</a>
<a href="#cite_ref-:2_23-1">
<sup>
<b>
19.1
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation web">
<a href="/wiki/%E9%82%B1%E4%BB%B2%E9%BA%9F" title="邱仲麟">
邱仲麟
</a>
.
<a class="external text" href="http://www.ihp.sinica.edu.tw/~bihp/75/75.2/chiu.htm" rel="nofollow">
明代北京的瘟疫與帝國醫療體系的應變
</a>
.
<a href="/wiki/%E4%B8%AD%E5%A4%AE%E7%A0%94%E7%A9%B6%E9%99%A2" title="中央研究院">
中央研究院
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-12-29
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E9%82%B1%E4%BB%B2%E9%BA%9F&rft.btitle=%E6%98%8E%E4%BB%A3%E5%8C%97%E4%BA%AC%E7%9A%84%E7%98%9F%E7%96%AB%E8%88%87%E5%B8%9D%E5%9C%E9%86%AB%E7%99%82%E9%AB%94%E7%B3%BB%E7%9A%84%E6%87%89%E8%AE%8A&rft.genre=unknown&rft.pub=%E4%B8+%E5%A4%AE%E7%A0%94%E7%A9%B6%E9%99%A2&rft_id=http%3A%2F%2Fwww.ihp.sinica.edu.tw%2F~bihp%2F75%2F75.2%2Fchiu.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
<span class="error mw-ext-cite-error" dir="ltr" lang="zh">
引用错误:带有name属性“:2”的
<code>
<ref>
</code>
标签用不同内容定义了多次
</span>
</span>
</li>
<li id="cite_note-:3-24">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:3_24-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.xinhuanet.com/publish/2020-07/02/c_1210686600.htm" rel="nofollow">
《中国抗疫简史》:面对灾难,我们自古从未低头!
</a>
. 新华出版社. 2020-07-02
<span class="reference-accessdate">
[
<span class="nowrap">
2020-12-29
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E3%8A%E4%B8+%E5%9B%BD%E6%8A%97%E7%96%AB%E7%AE%E5%8F%B2%E3%EF%BC%9A%E9%9D%A2%E5%AF%B9%E7%81%BE%E9%9A%BE%EF%BC%8C%E6%88%91%E4%BB%AC%E8%87%AA%E5%8F%A4%E4%BB%8E%E6%9C%AA%E4%BD%8E%E5%A4%B4%EF%BC%81&rft.date=2020-07-02&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=http%3A%2F%2Fwww.xinhuanet.com%2Fpublish%2F2020-07%2F02%2Fc_1210686600.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-1860年北京条约-25">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-1860年北京条约_25-0">
^
</a>
</b>
</span>
<span class="reference-text">
《1860年北京条约》俄国 布克斯盖夫登男爵 著
</span>
</li>
<li id="cite_note-bj-general-26">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-bj-general_26-0">
<sup>
<b>
22.00
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-1">
<sup>
<b>
22.01
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-2">
<sup>
<b>
22.02
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-3">
<sup>
<b>
22.03
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-4">
<sup>
<b>
22.04
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-5">
<sup>
<b>
22.05
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-6">
<sup>
<b>
22.06
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-7">
<sup>
<b>
22.07
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-8">
<sup>
<b>
22.08
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-9">
<sup>
<b>
22.09
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-10">
<sup>
<b>
22.10
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-11">
<sup>
<b>
22.11
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-12">
<sup>
<b>
22.12
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-13">
<sup>
<b>
22.13
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-14">
<sup>
<b>
22.14
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-15">
<sup>
<b>
22.15
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-16">
<sup>
<b>
22.16
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-17">
<sup>
<b>
22.17
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-18">
<sup>
<b>
22.18
</b>
</sup>
</a>
<a href="#cite_ref-bj-general_26-19">
<sup>
<b>
22.19
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation book">
北京市地方志编纂委员会. 北京志·综合卷·总述·历史概要·大事记.
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%87%BA%E7%89%88%E7%A4%BE" title="北京出版社">
北京出版社
</a>
. 2013.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-7-200-09633-0" title="Special:网络书源/978-7-200-09633-0">
<span title="国际标准书号">
ISBN
</span>
978-7-200-09633-0
</a>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%B0%E6%96%B9%E5%BF%97%E7%BC%96%E7%BA%82%E5%A7%94%E5%91%98%E4%BC%9A&rft.btitle=%E5%8C%97%E4%BA%AC%E5%BF%97+%B7%E7%BB%BC%E5%90%88%E5%B7+%B7%E6%BB%E8%BF%B0+%B7%E5%8E%86%E5%8F%B2%E6%A6%82%E8%A6%81+%B7%E5%A4%A7%E4%BA%E8%AE%B0&rft.date=2013&rft.genre=book&rft.isbn=978-7-200-09633-0&rft.pub=%E5%8C%97%E4%BA%AC%E5%87%BA%E7%89%88%E7%A4%BE&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-27">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-27">
^
</a>
</b>
</span>
<span class="reference-text">
中華民國史事日誌.中華民國八年己未.第437頁
</span>
</li>
<li id="cite_note-28">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-28">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation journal">
許雪姬.
<a class="external text" href="https://web.archive.org/web/20180201011031/http://memo.cgu.edu.tw/cgjhsc/data_files/1-1%2003.pdf" rel="nofollow">
1937至1947年在北京的台灣人
</a>
<span style="font-size:85%;">
(PDF)
</span>
. 長庚人文社會學報. 2008年4月,
<b>
1
</b>
(1): 33–84
<span class="reference-accessdate">
[
<span class="nowrap">
2017-10-12
</span>
]
</span>
.
<a class="external text" href="//www.worldcat.org/issn/2070-9455" rel="nofollow">
<span title="国际标准连续出版物号">
ISSN 2070-9455
</span>
</a>
. (
<a class="external text" href="http://memo.cgu.edu.tw/cgjhsc/data_files/1-1%2003.pdf" rel="nofollow">
原始内容
</a>
<span style="font-size:85%;">
(pdf)
</span>
存档于2018-02-01).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=1937%E8%87%B31947%E5%B9%B4%E5%9C%A8%E5%8C%97%E4%BA%AC%E7%9A%84%E5%8F%B0%E7%81%A3%E4%BA%BA&rft.au=%E8%A8%B1%E9%9B%AA%E5%A7%AC&rft.date=2008-04&rft.genre=article&rft.issn=2070-9455&rft.issue=1&rft.jtitle=%E9%95%B7%E5%BA%9A%E4%BA%BA%E6%96%87%E7%A4%BE%E6%9C%83%E5+%B8%E5%A0%B1&rft.pages=33-84&rft.volume=1&rft_id=http%3A%2F%2Fmemo.cgu.edu.tw%2Fcgjhsc%2Fdata_files%2F1-1%252003.pdf&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-29">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-29">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://vip.book.sina.com.cn/book/chapter_98283_62873.html" rel="nofollow">
傅作义与北平和平解放简介
</a>
. 新浪读书. 2009-06-29
<span class="reference-accessdate">
[
<span class="nowrap">
2012-02-03
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20171116072032/http://vip.book.sina.com.cn/book/chapter_98283_62873.html" rel="nofollow">
存档
</a>
于2017-11-16)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(简体)网页">
(中文(简体))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%82%85%E4%BD%9C%E4%B9%89%E4%B8%8E%E5%8C%97%E5%B9%B3%E5%92%8C%E5%B9%B3%E8%A7%A3%E6%94%BE%E7%AE%E4%BB&rft.date=2009-06-29&rft.genre=unknown&rft.pub=%E6%96%B0%E6%B5%AA%E8%AF%BB%E4%B9%A6&rft_id=http%3A%2F%2Fvip.book.sina.com.cn%2Fbook%2Fchapter_98283_62873.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-30">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-30">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20170312071847/http://dangshi.people.com.cn/GB/120280/9437260.html" rel="nofollow">
共和国大阅兵
</a>
. 中国共产党新闻网.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-16
</span>
]
</span>
. (
<a class="external text" href="http://dangshi.people.com.cn/GB/120280/9437260.html" rel="nofollow">
原始内容
</a>
存档于2017-03-12).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%85%B1%E5%92%8C%E5%9B%BD%E5%A4%A7%E9%98%85%E5%85%B5&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E6%96%B0%E9%97%BB%E7%BD%91&rft_id=http%3A%2F%2Fdangshi.people.com.cn%2FGB%2F120280%2F9437260.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-31">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-31">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.china.com.cn/fangtan/2009-12/09/content_19033074.htm?show=t" rel="nofollow">
彭真与北京新城建设(上)
</a>
. 中国网. 2009-12-11
<span class="reference-accessdate">
[
<span class="nowrap">
2020-10-20
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%BD+%E7%9C%9F%E4%B8%8E%E5%8C%97%E4%BA%AC%E6%96%B0%E5%9F%8E%E5%BB%BA%E8%AE%BE%28%E4%B8%8A%29&rft.date=2009-12-11&rft.genre=unknown&rft.pub=%E4%B8+%E5%9B%BD%E7%BD%91&rft_id=http%3A%2F%2Fwww.china.com.cn%2Ffangtan%2F2009-12%2F09%2Fcontent_19033074.htm%3Fshow%3Dt&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-32">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-32">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="https://news.sina.com.cn/c/2004-08-17/02303409390s.shtml" rel="nofollow">
北京旧城保护调查之回顾
</a>
.
<a href="/wiki/%E6%96%B0%E4%BA%AC%E6%8A%A5" title="新京报">
新京报
</a>
. 2004-08-17
<span class="reference-accessdate">
[
<span class="nowrap">
2020-10-20
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%97%A7%E5%9F%8E%E4%BF%9D%E6%8A%A4%E8%B0%83%E6%9F%A5%E4%B9%E5%9B%9E%E9%A1%BE&rft.date=2004-08-17&rft.genre=article&rft.jtitle=%E6%96%B0%E4%BA%AC%E6%8A%A5&rft_id=https%3A%2F%2Fnews.sina.com.cn%2Fc%2F2004-08-17%2F02303409390s.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:12-33">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:12_33-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
熊景明; 宋永毅; 余國良.
<a class="external text" href="https://books.google.com/books?id=diezDwAAQBAJ&pg=PR43&lpg=PR43&dq=%E7%BA%A2%E8%89%B2%E6%81%90%E6%80%96&source=bl&ots=W_IvRAEcEc&sig=ACfU3U0cfKW2t91VCadqDd1HUSHQDKuf5w&hl=en&ppis=_e&sa=X&ved=2ahUKEwiisLqpsKrmAhVCgK0KHVvUCUIQ6AEwBnoECAgQAQ#v=onepage&q=%E7%BA%A2%E8%89%B2%E6%81%90%E6%80%96%E4%B8%87%E5%B2%81&f=false" rel="nofollow">
中外學者談文革
</a>
. The Chinese University Press. 2018-06-15.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-988-17563-3-6" title="Special:网络书源/978-988-17563-3-6">
<span title="国际标准书号">
ISBN
</span>
978-988-17563-3-6
</a>
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到俄语网页">
(俄语)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E4%BD%99%E5%9C%E8%89%AF&rft.au=%E5%AE%E6%B0%B8%E6%AF%85&rft.au=%E7%86%8A%E6%99%AF%E6%98%8E&rft.btitle=%E4%B8+%E5%A4%96%E5+%B8%E8%85%E8%AB%87%E6%96%87%E9%9D%A9&rft.date=2018-06-15&rft.genre=book&rft.isbn=978-988-17563-3-6&rft.pub=The+Chinese+University+Press&rft_id=https%3A%2F%2Fbooks.google.com%2Fbooks%3Fid%3DdiezDwAAQBAJ%26pg%3DPR43%26lpg%3DPR43%26dq%3D%25E7%25BA%25A2%25E8%2589%25B2%25E6%2581%2590%25E6%2580%2596%26source%3Dbl%26ots%3DW_IvRAEcEc%26sig%3DACfU3U0cfKW2t91VCadqDd1HUSHQDKuf5w%26hl%3Den%26ppis%3D_e%26sa%3DX%26ved%3D2ahUKEwiisLqpsKrmAhVCgK0KHVvUCUIQ6AEwBnoECAgQAQ%23v%3Donepage%26q%3D%25E7%25BA%25A2%25E8%2589%25B2%25E6%2581%2590%25E6%2580%2596%25E4%25B8%2587%25E5%25B2%2581%26f%3Dfalse&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:15-34">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-:15_34-0">
<sup>
<b>
30.0
</b>
</sup>
</a>
<a href="#cite_ref-:15_34-1">
<sup>
<b>
30.1
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation web">
王友琴.
<a class="external text" href="http://www.yhcqw.com/33/8055.html" rel="nofollow">
恐怖的“红八月”
</a>
. 炎黄春秋.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20191210070701/http://www.yhcqw.com/33/8055.html" rel="nofollow">
存档
</a>
于2019-12-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E7%8E%E5%8F%E7%90%B4&rft.btitle=%E6%81%90%E6%96%E7%9A%84%9C%E7%BA%A2%E5%85%AB%E6%9C%88%9D&rft.genre=unknown&rft.pub=%E7%82%8E%E9%BB%84%E6%98%A5%E7%A7&rft_id=http%3A%2F%2Fwww.yhcqw.com%2F33%2F8055.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:14-35">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:14_35-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://www.rfa.org/mandarin/zhuanlan/xinlingzhilyu/wengebeiwanglu/m0816mind-08152013163142.html" rel="nofollow">
47周年回放:再忆文革“八.一八”和 “红八月”
</a>
. Radio Free Asia.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20191210060415/https://www.rfa.org/mandarin/zhuanlan/xinlingzhilyu/wengebeiwanglu/m0816mind-08152013163142.html" rel="nofollow">
存档
</a>
于2019-12-10)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=47%E5%91%A8%E5%B9%B4%E5%9B%9E%E6%94%BE%EF%BC%9A%E5%86%E5%BF%86%E6%96%87%E9%9D%A9%9C%E5%85%AB.%E4%B8%E5%85%AB%9D%E5%92%8C+%9C%E7%BA%A2%E5%85%AB%E6%9C%88%9D&rft.genre=unknown&rft.jtitle=Radio+Free+Asia&rft_id=https%3A%2F%2Fwww.rfa.org%2Fmandarin%2Fzhuanlan%2Fxinlingzhilyu%2Fwengebeiwanglu%2Fm0816mind-08152013163142.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-36">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-36">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
杜钧福.
<a class="external text" href="http://mjlsh.usc.cuhk.edu.hk/Book.aspx?cid=4&tid=1165" rel="nofollow">
西纠
</a>
. 香港中文大学.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160804183418/http://mjlsh.usc.cuhk.edu.hk/Book.aspx?cid=4&tid=1165" rel="nofollow">
存档
</a>
于2016-08-04).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E6%9D%9C%E9%92%A7%E7%A6%8F&rft.btitle=%E8%A5%BF%E7%BA%A0&rft.genre=unknown&rft.pub=%E9%A6%99%E6%B8%AF%E4%B8+%E6%96%87%E5%A4%A7%E5+%A6&rft_id=http%3A%2F%2Fmjlsh.usc.cuhk.edu.hk%2FBook.aspx%3Fcid%3D4%26tid%3D1165&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-37">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-37">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.ifeng.com/history/shixueyuan/detail_2014_01/15/33042066_0.shtml" rel="nofollow">
兰台说史第1期:揭秘宋彬彬道歉背后隐藏的历史
</a>
. 凤凰网.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20191120161145/http://news.ifeng.com/history/shixueyuan/detail_2014_01/15/33042066_0.shtml" rel="nofollow">
存档
</a>
于2019-11-20).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%85%B0%E5%8F%B0%E8%AF%B4%E5%8F%B2%E7%AC%AC1%E6%9C%9F%EF%BC%9A%E6%8F+%E7%A7%98%E5%AE%E5%BD%AC%E5%BD%AC%E9%81%93%E6+%89%E8%83%8C%E5%90%8E%E9%9A%90%E8%97%8F%E7%9A%84%E5%8E%86%E5%8F%B2&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E7%BD%91&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fhistory%2Fshixueyuan%2Fdetail_2014_01%2F15%2F33042066_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-38">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-38">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
孙言诚.
<a class="external text" href="http://www.cnd.org/CR/ZK18/cr986.gb.html" rel="nofollow">
谁制造了“红八月”的恐怖狂潮
</a>
. 华夏文摘.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200629132134/http://www.cnd.org/CR/ZK18/cr986.gb.html" rel="nofollow">
存档
</a>
于2020-06-29).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5+%99%E8%A8%E8%AF%9A&rft.btitle=%E8%B0%81%E5%88%B6%E9%A0%E4%BA%86%9C%E7%BA%A2%E5%85%AB%E6%9C%88%9D%E7%9A%84%E6%81%90%E6%96%E7%82%E6%BD%AE&rft.genre=unknown&rft.pub=%E5%8E%E5%A4%8F%E6%96%87%E6%91%98&rft_id=http%3A%2F%2Fwww.cnd.org%2FCR%2FZK18%2Fcr986.gb.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:31-39">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:31_39-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://cpc.people.com.cn/GB/69112/75843/75871/5164013.html" rel="nofollow">
第九章 颠倒乾坤的“文化大革命”--中国共产党新闻
</a>
. 人民网.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-02-15
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200629132151/http://cpc.people.com.cn/GB/69112/75843/75871/5164013.html" rel="nofollow">
存档
</a>
于2020-06-29).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%AC%AC%E4%B9%9D%E7%AB%A0%E3%E9%A2%A0%E5%92%E4%B9%BE%E5%9D%A4%E7%9A%84%9C%E6%96%87%E5%8C%96%E5%A4%A7%E9%9D%A9%E5%91%BD%9D--%E4%B8+%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E6%96%B0%E9%97%BB&rft.genre=unknown&rft.pub=%E4%BA%BA%E6%B0%91%E7%BD%91&rft_id=http%3A%2F%2Fcpc.people.com.cn%2FGB%2F69112%2F75843%2F75871%2F5164013.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:17-40">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:17_40-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.ifengweekly.com/detil.php?id=604" rel="nofollow">
怎样反思“红卫兵”
</a>
. 凤凰周刊.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20171016074817/http://ifengweekly.com/detil.php?id=604" rel="nofollow">
存档
</a>
于2017-10-16).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%8E%E6%A0%B7%E5%8F%E6%9D%9C%E7%BA%A2%E5%AB%E5%85%B5%9D&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E5%91%A8%E5%88%8A&rft_id=http%3A%2F%2Fwww.ifengweekly.com%2Fdetil.php%3Fid%3D604&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:7-41">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:7_41-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.ifeng.com/history/zhiqing/ziliao/detail_2013_09/02/29238981_0.shtml" rel="nofollow">
北京日报:1966年红卫兵在北京40天打死1772人
</a>
. 凤凰网.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20191210045130/http://news.ifeng.com/history/zhiqing/ziliao/detail_2013_09/02/29238981_0.shtml" rel="nofollow">
存档
</a>
于2019-12-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5%EF%BC%9A1966%E5%B9%B4%E7%BA%A2%E5%AB%E5%85%B5%E5%9C%A8%E5%8C%97%E4%BA%AC40%E5%A4%A9%E6%89%93%E6+%BB1772%E4%BA%BA&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E7%BD%91&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fhistory%2Fzhiqing%2Fziliao%2Fdetail_2013_09%2F02%2F29238981_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:20-42">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:20_42-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
遇罗文.
<a class="external text" href="http://ywang.uchicago.edu/history/daxintusa.htm" rel="nofollow">
大兴屠杀调查
</a>
. 芝加哥大学.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20190507004605/http://ywang.uchicago.edu/history/daxintusa.htm" rel="nofollow">
存档
</a>
于2019-05-07).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E9%81%87%E7%BD%97%E6%96%87&rft.btitle=%E5%A4%A7%E5%85%B4%E5%B1%A0%E6%9D%E8%B0%83%E6%9F%A5&rft.genre=unknown&rft.pub=%E8%8A%9D%E5%8A%A0%E5%93%A5%E5%A4%A7%E5+%A6&rft_id=http%3A%2F%2Fywang.uchicago.edu%2Fhistory%2Fdaxintusa.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:21-43">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:21_43-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
熊景明; 宋永毅; 余國良.
<a class="external text" href="https://books.google.com/books?id=diezDwAAQBAJ&pg=PA62&lpg=PA62&dq=%E5%8C%97%E4%BA%AC+%E5%A6%82%E6%9E%9C%E4%BD%A0%E6%8A%8A%E6%89%93%E4%BA%BA%E7%9A%84%E4%BA%BA%E6%89%A3%E7%95%99%E8%B5%B7%E6%9D%A5%EF%BC%8C%E6%8D%95%E8%B5%B7%E6%9D%A5%EF%BC%8C%E4%BD%A0%E4%BB%AC%E5%B0%B1%E8%A6%81%E7%8A%AF%E9%94%99%E8%AF%AF&source=bl&ots=W_IwIwEeFa&sig=ACfU3U1_kr-aQqJfo7Tfvdq2bMgh9hdNiA&hl=en&ppis=_e&sa=X&ved=2ahUKEwjqwofPkKzmAhXEIDQIHdbODe8Q6AEwAHoECAkQAQ#v=onepage&q=%E5%8C%97%E4%BA%AC%20%E5%A6%82%E6%9E%9C%E4%BD%A0%E6%8A%8A%E6%89%93%E4%BA%BA%E7%9A%84%E4%BA%BA%E6%89%A3%E7%95%99%E8%B5%B7%E6%9D%A5%EF%BC%8C%E6%8D%95%E8%B5%B7%E6%9D%A5%EF%BC%8C%E4%BD%A0%E4%BB%AC%E5%B0%B1%E8%A6%81%E7%8A%AF%E9%94%99%E8%AF%AF&f=false" rel="nofollow">
中外學者談文革
</a>
. The Chinese University Press. 2018-06-15.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-988-17563-3-6" title="Special:网络书源/978-988-17563-3-6">
<span title="国际标准书号">
ISBN
</span>
978-988-17563-3-6
</a>
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到俄语网页">
(俄语)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E4%BD%99%E5%9C%E8%89%AF&rft.au=%E5%AE%E6%B0%B8%E6%AF%85&rft.au=%E7%86%8A%E6%99%AF%E6%98%8E&rft.btitle=%E4%B8+%E5%A4%96%E5+%B8%E8%85%E8%AB%87%E6%96%87%E9%9D%A9&rft.date=2018-06-15&rft.genre=book&rft.isbn=978-988-17563-3-6&rft.pub=The+Chinese+University+Press&rft_id=https%3A%2F%2Fbooks.google.com%2Fbooks%3Fid%3DdiezDwAAQBAJ%26pg%3DPA62%26lpg%3DPA62%26dq%3D%25E5%258C%2597%25E4%25BA%25AC%2B%25E5%25A6%2582%25E6%259E%259C%25E4%25BD%25A0%25E6%258A%258A%25E6%2589%2593%25E4%25BA%25BA%25E7%259A%2584%25E4%25BA%25BA%25E6%2589%25A3%25E7%2595%2599%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E6%258D%2595%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E4%25BD%25A0%25E4%25BB%25AC%25E5%25B0%25B1%25E8%25A6%2581%25E7%258A%25AF%25E9%2594%2599%25E8%25AF%25AF%26source%3Dbl%26ots%3DW_IwIwEeFa%26sig%3DACfU3U1_kr-aQqJfo7Tfvdq2bMgh9hdNiA%26hl%3Den%26ppis%3D_e%26sa%3DX%26ved%3D2ahUKEwjqwofPkKzmAhXEIDQIHdbODe8Q6AEwAHoECAkQAQ%23v%3Donepage%26q%3D%25E5%258C%2597%25E4%25BA%25AC%2520%25E5%25A6%2582%25E6%259E%259C%25E4%25BD%25A0%25E6%258A%258A%25E6%2589%2593%25E4%25BA%25BA%25E7%259A%2584%25E4%25BA%25BA%25E6%2589%25A3%25E7%2595%2599%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E6%258D%2595%25E8%25B5%25B7%25E6%259D%25A5%25EF%25BC%258C%25E4%25BD%25A0%25E4%25BB%25AC%25E5%25B0%25B1%25E8%25A6%2581%25E7%258A%25AF%25E9%2594%2599%25E8%25AF%25AF%26f%3Dfalse&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:8-44">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:8_44-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
宋永毅.
<a class="external text" href="https://boxun.com/news/gb/z_special/2011/09/201109160825.shtml" rel="nofollow">
文革中“非正常死亡”了多少人? ---- 读苏扬的《文革中中国农村的集体屠杀》
</a>
. 博讯.
<span class="reference-accessdate">
[
<span class="nowrap">
2019-12-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20191210045125/https://boxun.com/news/gb/z_special/2011/09/201109160825.shtml" rel="nofollow">
存档
</a>
于2019-12-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%AE%E6%B0%B8%E6%AF%85&rft.btitle=%E6%96%87%E9%9D%A9%E4%B8+%9C%E9%9D%9E%E6+%A3%E5%B8%B8%E6+%BB%E4%BA%A1%9D%E4%BA%86%E5%A4%9A%E5%B0%91%E4%BA%BA%EF%BC%9F+----+%E8%AF%BB%E8%8F%E6%89%AC%E7%9A%84%E3%8A%E6%96%87%E9%9D%A9%E4%B8+%E4%B8+%E5%9B%BD%E5%86%9C%E6%9D%91%E7%9A%84%E9%9B%86%E4%BD%93%E5%B1%A0%E6%9D%E3&rft.genre=unknown&rft.pub=%E5%9A%E8%AE%AF&rft_id=https%3A%2F%2Fboxun.com%2Fnews%2Fgb%2Fz_special%2F2011%2F09%2F201109160825.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-趙紫陽-45">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-趙紫陽_45-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
<a class="mw-redirect" href="/wiki/%E8%B6%99%E7%B4%AB%E9%99%BD" title="趙紫陽">
趙紫陽
</a>
.
<a class="external text" href="https://books.google.com.tw/books?id=9ooub2kRkRQC&printsec=frontcover&hl=zh-TW#v=onepage&q&f=false" rel="nofollow">
《改革歷程》 [Prisoner of the State: The Secret Journal of Premier Zhao Ziyang]
</a>
. 美國紐約:
<a href="/wiki/%E8%A5%BF%E8%92%99%E8%88%87%E8%88%92%E6%96%AF%E7%89%B9" title="西蒙與舒斯特">
西蒙與舒斯特
</a>
. 2009-05-19
<span class="reference-accessdate">
[
<span class="nowrap">
2013-12-28
</span>
]
</span>
.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-1439149386" title="Special:网络书源/978-1439149386">
<span title="国际标准书号">
ISBN
</span>
978-1439149386
</a>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20140106033000/http://books.google.com.tw/books?id=9ooub2kRkRQC&printsec=frontcover&hl=zh-TW#v=onepage&q&f=false" rel="nofollow">
存档
</a>
于2014-01-06)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英语网页">
(英语)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E8%B6%99%E7%B4%AB%E9%99%BD&rft.btitle=%E3%8A%E6%94%B9%E9%9D%A9%E6+%B7%E7%A8%E3&rft.date=2009-05-19&rft.genre=book&rft.isbn=978-1439149386&rft.place=%E7%BE%8E%E5%9C%E7%B4%90%E7%B4%84&rft.pub=%E8%A5%BF%E8%92%99%E8%88%87%E8%88%92%E6%96%AF%E7%89%B9&rft_id=https%3A%2F%2Fbooks.google.com.tw%2Fbooks%3Fid%3D9ooub2kRkRQC%26printsec%3Dfrontcover%26hl%3Dzh-TW%23v%3Donepage%26q%26f%3Dfalse&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-46">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-46">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://sports.sina.com.cn/9811/112541.html" rel="nofollow">
北京市正式宣布申办2008年奥运会
</a>
.
<a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">
新华社
</a>
. 1998-11-25
<span class="reference-accessdate">
[
<span class="nowrap">
2020-02-19
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200219044445/http://sports.sina.com.cn/9811/112541.html" rel="nofollow">
存档
</a>
于2020-02-19).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E6+%A3%E5%BC%8F%E5%AE%A3%E5%B8%83%E7%94%B3%E5%8A%9E2008%E5%B9%B4%E5%A5%A5%E8%BF%90%E4%BC%9A&rft.date=1998-11-25&rft.genre=article&rft.jtitle=%E6%96%B0%E5%8E%E7%A4%BE&rft_id=http%3A%2F%2Fsports.sina.com.cn%2F9811%2F112541.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-47">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-47">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="https://www.thepaper.cn/newsDetail_forward_2148156" rel="nofollow">
口述中国|建筑师③贝聿铭:四合院是中国的代表建筑
</a>
2018-06-06 澎湃新闻 贝聿铭/口述 王军/采访
</span>
</li>
<li id="cite_note-灾情通报2-48">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-灾情通报2_48-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20120727125100/http://news.163.com/12/0724/15/876J4NI700014JB6.html" rel="nofollow">
北京暴雨造成倒塌房屋10660间
</a>
. 网易.
<span class="reference-accessdate">
[
<span class="nowrap">
2012-07-25
</span>
]
</span>
. (
<a class="external text" href="http://news.163.com/12/0724/15/876J4NI700014JB6.html" rel="nofollow">
原始内容
</a>
存档于2012-07-27).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%9A%B4%E9%9B%A8%E9%A0%E6%88%90%E5%92%E5%A1%8C%E6%88%BF%E5%B110660%E9%97%B4&rft.genre=unknown&rft.pub=%E7%BD%91%E6%98%93&rft_id=http%3A%2F%2Fnews.163.com%2F12%2F0724%2F15%2F876J4NI700014JB6.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-人民网20120806-49">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-人民网20120806_49-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20121109121351/http://xj.people.com.cn/n/2012/0806/c186332-17325550.html" rel="nofollow">
北京7-21特大暴雨遇难者人数升至79人
</a>
.
<a href="/wiki/%E4%BA%BA%E6%B0%91%E7%BD%91" title="人民网">
人民网
</a>
. 2012年8月6日
<span class="reference-accessdate">
[2012年8月12日]
</span>
. (
<a class="external text" href="http://xj.people.com.cn/n/2012/0806/c186332-17325550.html" rel="nofollow">
原始内容
</a>
存档于2012年11月9日).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC7-21%E7%89%B9%E5%A4%A7%E6%9A%B4%E9%9B%A8%E9%81%87%E9%9A%BE%E8%85%E4%BA%BA%E6%95%B0%E5%87%E8%87%B379%E4%BA%BA&rft.date=2012-08-06&rft.genre=unknown&rft.pub=%E4%BA%BA%E6%B0%91%E7%BD%91&rft_id=http%3A%2F%2Fxj.people.com.cn%2Fn%2F2012%2F0806%2Fc186332-17325550.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-50">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-50">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/07/120725_beijing_rain_weibo.shtml" rel="nofollow">
网民质疑北京暴雨死亡人数
</a>
. BBC中文网.
<span class="reference-accessdate">
[
<span class="nowrap">
2012-07-25
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20120725125028/http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/07/120725_beijing_rain_weibo.shtml" rel="nofollow">
存档
</a>
于2012-07-25).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%BD%91%E6%B0%91%E8%B4%A8%E7%96%91%E5%8C%97%E4%BA%AC%E6%9A%B4%E9%9B%A8%E6+%BB%E4%BA%A1%E4%BA%BA%E6%95%B0&rft.genre=unknown&rft.pub=BBC%E4%B8+%E6%96%87%E7%BD%91&rft_id=http%3A%2F%2Fwww.bbc.co.uk%2Fzhongwen%2Fsimp%2Fchinese_news%2F2012%2F07%2F120725_beijing_rain_weibo.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-51">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-51">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.chinanews.com/gn/2014/02-26/5887329.shtml" rel="nofollow">
习近平北京考察提要求:遏制“摊大饼”式发展
</a>
.
<a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">
新华社
</a>
. 2014-02-26
<span class="reference-accessdate">
[
<span class="nowrap">
2020-10-20
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B9%A0%E8%BF%91%E5%B9%B3%E5%8C%97%E4%BA%AC%E8%83%E5%AF%9F%E6%8F%90%E8%A6%81%E6%B1%82%3A%E9%81%8F%E5%88%B6%9C%E6%91%8A%E5%A4%A7%E9%A5%BC%9D%E5%BC%8F%E5%8F%91%E5%B1%95&rft.date=2014-02-26&rft.genre=article&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fgn%2F2014%2F02-26%2F5887329.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-52">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-52">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.xinhuanet.com/politics/2014-02/27/c_119538131.htm" rel="nofollow">
打破"一亩三分地" 习近平就京津冀协同发展提七点要求
</a>
.
<a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">
新华社
</a>
. 2014-02-27
<span class="reference-accessdate">
[
<span class="nowrap">
2020-10-20
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E6%89%93%E7%A0%B4%22%E4%B8%E4%BA%A9%E4%B8%89%E5%88%86%E5%9C%B0%22+%E4%B9%A0%E8%BF%91%E5%B9%B3%E5%B0%B1%E4%BA%AC%E6%B4%A5%E5%86%E5%8F%E5%90%8C%E5%8F%91%E5%B1%95%E6%8F%90%E4%B8%83%E7%82%B9%E8%A6%81%E6%B1%82&rft.date=2014-02-27&rft.genre=article&rft_id=http%3A%2F%2Fwww.xinhuanet.com%2Fpolitics%2F2014-02%2F27%2Fc_119538131.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:25-53">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:25_53-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.bbc.com/zhongwen/simp/china/2015/12/151207_beijing_smog_red_alert" rel="nofollow">
雾霾持续 北京首次启动重污染红色预警
</a>
. BBC 中文网.
<span class="reference-accessdate">
[2015年12月21日]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20151210042117/http://www.bbc.com/zhongwen/simp/china/2015/12/151207_beijing_smog_red_alert" rel="nofollow">
存档
</a>
于2015年12月10日).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%9B%BE%E9%9C%BE%E6%8C%81%E7%BB++%E5%8C%97%E4%BA%AC%E9%A6%96%E6%AC%A1%E5%90%AF%E5%8A%A8%E9%87%E6%B1%A1%E6%9F%93%E7%BA%A2%E8%89%B2%E9%A2%84%E8+%A6&rft.genre=article&rft.jtitle=BBC+%E4%B8+%E6%96%87%E7%BD%91&rft_id=http%3A%2F%2Fwww.bbc.com%2Fzhongwen%2Fsimp%2Fchina%2F2015%2F12%2F151207_beijing_smog_red_alert&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:13-54">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:13_54-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://cn.nytimes.com/china/20151208/c08china/" rel="nofollow">
北京首次启动雾霾红色预警
</a>
. 中文纽约时报.
<span class="reference-accessdate">
[
<span class="nowrap">
2015-12-21
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20151220031821/http://cn.nytimes.com/china/20151208/c08china/" rel="nofollow">
存档
</a>
于2015-12-20).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E9%A6%96%E6%AC%A1%E5%90%AF%E5%8A%A8%E9%9B%BE%E9%9C%BE%E7%BA%A2%E8%89%B2%E9%A2%84%E8+%A6&rft.genre=article&rft.jtitle=%E4%B8+%E6%96%87%E7%BA%BD%E7%BA%A6%E6%97%B6%E6%8A%A5&rft_id=http%3A%2F%2Fcn.nytimes.com%2Fchina%2F20151208%2Fc08china%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-:5-55">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-:5_55-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://news.sohu.com/20151219/n431864977.shtml" rel="nofollow">
北京10天两次启动雾霾红色预警 天津河北不跟进
</a>
. 搜狐新闻.
<span class="reference-accessdate">
[2015年12月21日]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20151222083928/http://news.sohu.com/20151219/n431864977.shtml" rel="nofollow">
存档
</a>
于2015年12月22日).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC10%E5%A4%A9%E4%B8%A4%E6%AC%A1%E5%90%AF%E5%8A%A8%E9%9B%BE%E9%9C%BE%E7%BA%A2%E8%89%B2%E9%A2%84%E8+%A6+%E5%A4%A9%E6%B4%A5%E6%B2%B3%E5%8C%97%E4%B8%E8%B7%9F%E8%BF%9B&rft.genre=article&rft.jtitle=%E6%90%9C%E7%90%E6%96%B0%E9%97%BB&rft_id=http%3A%2F%2Fnews.sohu.com%2F20151219%2Fn431864977.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-56">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-56">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="http://www.apdnews.com/news/76298.html" rel="nofollow">
北京正式申办2022年冬奥会
</a>
<a class="external text" href="//web.archive.org/web/20160304212457/http://www.apdnews.com/news/76298.html" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,亚太日报,2014年3月17日
</span>
</li>
<li id="cite_note-57">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-57">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://china.cnr.cn/xwwgf/20170928/t20170928_523969507.shtml" rel="nofollow">
北京城市总体规划获批复:加强“四个中心”功能建设
</a>
.
<a href="/wiki/%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E5%B9%BF%E6%92%AD%E7%94%B5%E5%8F%B0" title="中央人民广播电台">
中央人民广播电台
</a>
. 2017-09-28
<span class="reference-accessdate">
[
<span class="nowrap">
2020-09-16
</span>
]
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E6%BB%E4%BD%93%E8%A7%84%E5%88%92%E8%8E%B7%E6%89%B9%E5%A4%EF%BC%9A%E5%8A%A0%E5%BC%BA%9C%E5%9B%9B%E4%B8%AA%E4%B8+%E5%BF%83%9D%E5%8A%9F%E8%83%BD%E5%BB%BA%E8%AE%BE&rft.date=2017-09-28&rft.genre=article&rft_id=http%3A%2F%2Fchina.cnr.cn%2Fxwwgf%2F20170928%2Ft20170928_523969507.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-58">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-58">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://society.people.com.cn/n1/2017/1123/c1008-29664636.html" rel="nofollow">
北京大兴“11·18”火灾遇难者死因确定
</a>
. 人民网. 新华网. 2017-11-23
<span class="reference-accessdate">
[
<span class="nowrap">
2017-11-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20171201031113/http://society.people.com.cn/n1/2017/1123/c1008-29664636.html" rel="nofollow">
存档
</a>
于2017-12-01).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%A4%A7%E5%85%B4%9C11+%B718%9D%E7%81%AB%E7%81%BE%E9%81%87%E9%9A%BE%E8%85%E6+%BB%E5%9B%A0%E7%A1%AE%E5%AE%9A&rft.date=2017-11-23&rft.genre=article&rft_id=http%3A%2F%2Fsociety.people.com.cn%2Fn1%2F2017%2F1123%2Fc1008-29664636.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-59">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-59">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.zaobao.com/news/china/story20171125-813698" rel="nofollow">
安全隐患清查整治引质疑 北京清理“低端人口”?
</a>
.
<a href="/wiki/%E8%81%94%E5%90%88%E6%97%A9%E6%8A%A5" title="联合早报">
联合早报
</a>
. 2017-11-25
<span class="reference-accessdate">
[
<span class="nowrap">
2017-11-27
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20190912130612/https://www.zaobao.com.sg/news/china/story20171125-813698" rel="nofollow">
存档
</a>
于2019-09-12).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%AE%89%E5%85%A8%E9%9A%90%E6%82%A3%E6%B8%85%E6%9F%A5%E6%95%B4%E6%B2%BB%E5%BC%95%E8%B4%A8%E7%96%91+%E5%8C%97%E4%BA%AC%E6%B8%85%E7%90%86%9C%E4%BD%8E%E7%AB%AF%E4%BA%BA%E5%8F%A3%9D%EF%BC%9F&rft.date=2017-11-25&rft.genre=article&rft_id=http%3A%2F%2Fwww.zaobao.com%2Fnews%2Fchina%2Fstory20171125-813698&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-60">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-60">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="https://www.jfdaily.com/news/detail?id=126682" rel="nofollow">
北京市级行政中心正式迁入北京城市副中心
</a>
.
<a href="/wiki/%E4%B8%8A%E8%A7%82%E6%96%B0%E9%97%BB" title="上观新闻">
上观新闻
</a>
. 2019-01-11
<span class="reference-accessdate">
[
<span class="nowrap">
2020-09-16
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200916190345/https://www.jfdaily.com/news/detail?id=126682" rel="nofollow">
存档
</a>
于2020-09-16).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BA%A7%E8%A1%8C%E6%94%BF%E4%B8+%E5%BF%83%E6+%A3%E5%BC%8F%E8%BF%81%E5%85%A5%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8+%E5%BF%83&rft.date=2019-01-11&rft.genre=article&rft.jtitle=%E4%B8%8A%E8%A7%82%E6%96%B0%E9%97%BB&rft_id=https%3A%2F%2Fwww.jfdaily.com%2Fnews%2Fdetail%3Fid%3D126682&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-61">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-61">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://news.youth.cn/gn/202008/t20200825_12465879.htm" rel="nofollow">
疫情几起几落,北京地坛医院打了三场硬仗
</a>
. 中国青年报客户端. 2020-08-25
<span class="reference-accessdate">
[
<span class="nowrap">
2020-08-27
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200917001221/http://news.youth.cn/gn/202008/t20200825_12465879.htm" rel="nofollow">
存档
</a>
于2020-09-17).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E7%96%AB%E6%83%85%E5%87%A0%E8%B5%B7%E5%87%A0%E8%90%BD%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%9C%B0%E5%9D%9B%E5%8C%BB%E9%99%A2%E6%89%93%E4%BA%86%E4%B8%89%E5%9C%BA%E7%A1%AC%E4%BB%97&rft.date=2020-08-25&rft.genre=article&rft_id=http%3A%2F%2Fnews.youth.cn%2Fgn%2F202008%2Ft20200825_12465879.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-62">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-62">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://news.ynet.com/2020/01/24/2345254t70.html" rel="nofollow">
北京市启动重大突发公共卫生事件一级响应
</a>
.
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%9D%92%E5%B9%B4%E6%8A%A5" title="北京青年报">
北京青年报
</a>
. 2020-01-24
<span class="reference-accessdate">
[
<span class="nowrap">
2020-09-16
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200916195551/http://news.ynet.com/2020/01/24/2345254t70.html" rel="nofollow">
存档
</a>
于2020-09-16).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%90%AF%E5%8A%A8%E9%87%E5%A4%A7%E7%AA%81%E5%8F%91%E5%85%AC%E5%85%B1%E5%AB%E7%94%9F%E4%BA%E4%BB%B6%E4%B8%E7%BA%A7%E5%93%E5%BA%94&rft.date=2020-01-24&rft.genre=article&rft.jtitle=%E5%8C%97%E4%BA%AC%E9%9D%92%E5%B9%B4%E6%8A%A5&rft_id=http%3A%2F%2Fnews.ynet.com%2F2020%2F01%2F24%2F2345254t70.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-63">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-63">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.xinhuanet.com/2020-04/29/c_1125923588.htm" rel="nofollow">
北京将重大突发公共卫生事件应急响应下调为二级响应
</a>
.
<a href="/wiki/%E6%96%B0%E5%8D%8E%E7%A4%BE" title="新华社">
新华社
</a>
. 2020-04-29
<span class="reference-accessdate">
[
<span class="nowrap">
2020-09-16
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200921034548/http://www.xinhuanet.com/2020-04/29/c_1125923588.htm" rel="nofollow">
存档
</a>
于2020-09-21).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B0%86%E9%87%E5%A4%A7%E7%AA%81%E5%8F%91%E5%85%AC%E5%85%B1%E5%AB%E7%94%9F%E4%BA%E4%BB%B6%E5%BA%94%E6%A5%E5%93%E5%BA%94%E4%B8%E8%B0%83%E4%B8%BA%E4%BA%8C%E7%BA%A7%E5%93%E5%BA%94&rft.date=2020-04-29&rft.genre=article&rft_id=http%3A%2F%2Fwww.xinhuanet.com%2F2020-04%2F29%2Fc_1125923588.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-64">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-64">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.bjd.com.cn/a/202006/05/WS5ed9fc3be4b00aba04d2025b.html" rel="nofollow">
重磅!6月6日起,北京应急响应级别下调为三级
</a>
. 北京日报客户端. 2020-06-05
<span class="reference-accessdate">
[
<span class="nowrap">
2020-06-05
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200605112436/http://www.bjd.com.cn/a/202006/05/WS5ed9fc3be4b00aba04d2025b.html" rel="nofollow">
存档
</a>
于2020-06-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%87%E7%A3%85%EF%BC%816%E6%9C%886%E6%97%A5%E8%B5%B7%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%BA%94%E6%A5%E5%93%E5%BA%94%E7%BA%A7%E5%88%AB%E4%B8%E8%B0%83%E4%B8%BA%E4%B8%89%E7%BA%A7&rft.date=2020-06-05&rft.genre=article&rft.jtitle=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5%E5%AE%A2%E6%88%B7%E7%AB%AF&rft_id=http%3A%2F%2Fwww.bjd.com.cn%2Fa%2F202006%2F05%2FWS5ed9fc3be4b00aba04d2025b.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-chinanews20200609-65">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-chinanews20200609_65-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.bj.chinanews.com/news/2020/0609/77614.html" rel="nofollow">
北京本地确诊病例“清零” 仅1例境外输入病例在院治疗
</a>
. 中国新闻网. 2020-06-09
<span class="reference-accessdate">
[
<span class="nowrap">
2020-06-10
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200610024759/http://www.bj.chinanews.com/news/2020/0609/77614.html" rel="nofollow">
存档
</a>
于2020-06-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%9C%AC%E5%9C%B0%E7%A1%AE%E8%AF%8A%E7%97%85%E4%BE%9C%E6%B8%85%E9%9B%B6%9D+%E4%BB%851%E4%BE%E5%A2%83%E5%A4%96%E8%BE%93%E5%85%A5%E7%97%85%E4%BE%E5%9C%A8%E9%99%A2%E6%B2%BB%E7%96%97&rft.date=2020-06-09&rft.genre=article&rft.jtitle=%E4%B8+%E5%9B%BD%E6%96%B0%E9%97%BB%E7%BD%91&rft_id=http%3A%2F%2Fwww.bj.chinanews.com%2Fnews%2F2020%2F0609%2F77614.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-66">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-66">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="https://www.bjd.com.cn/a/202007/19/WS5f140092e4b00aba04d27206.html" rel="nofollow">
调级!北京市突发公共卫生事件应急响应级别调整到三级!
</a>
. 北京日报客户端. 2020-07-19
<span class="reference-accessdate">
[
<span class="nowrap">
2020-07-19
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200719104218/https://www.bjd.com.cn/a/202007/19/WS5f140092e4b00aba04d27206.html" rel="nofollow">
存档
</a>
于2020-07-19).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E8%B0%83%E7%BA%A7%EF%BC%81%E5%8C%97%E4%BA%AC%E5%B8%82%E7%AA%81%E5%8F%91%E5%85%AC%E5%85%B1%E5%AB%E7%94%9F%E4%BA%E4%BB%B6%E5%BA%94%E6%A5%E5%93%E5%BA%94%E7%BA%A7%E5%88%AB%E8%B0%83%E6%95%B4%E5%88%B0%E4%B8%89%E7%BA%A7%EF%BC%81&rft.date=2020-07-19&rft.genre=article&rft_id=https%3A%2F%2Fwww.bjd.com.cn%2Fa%2F202007%2F19%2FWS5f140092e4b00aba04d27206.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-67">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-67">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="https://www.chinanews.com/gn/2020/08-27/9276066.shtml" rel="nofollow">
首都核心区控规获批 推动老城整体保护与有机更新
</a>
.
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%96%B0%E9%97%BB%E7%A4%BE" title="中国新闻社">
中国新闻社
</a>
. 2020-08-27
<span class="reference-accessdate">
[
<span class="nowrap">
2020-09-16
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200921034621/https://www.chinanews.com/gn/2020/08-27/9276066.shtml" rel="nofollow">
存档
</a>
于2020-09-21).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E9%A6%96%E9%83%BD%E6%A0%B8%E5%BF%83%E5%8C%BA%E6%8E%A7%E8%A7%84%E8%8E%B7%E6%89%B9+%E6%8E%A8%E5%8A%A8%E8%81%E5%9F%8E%E6%95%B4%E4%BD%93%E4%BF%9D%E6%8A%A4%E4%B8%8E%E6%9C%89%E6%9C%BA%E6%9B%B4%E6%96%B0&rft.date=2020-08-27&rft.genre=article&rft_id=https%3A%2F%2Fwww.chinanews.com%2Fgn%2F2020%2F08-27%2F9276066.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-68">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-68">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.beijing.gov.cn/rwbj/bjgm/bjfm/t648265.htm" rel="nofollow">
北京風貌,首都之窗-北京市政務門戶網站
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-04-01
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20121209035606/http://www.beijing.gov.cn/rwbj/bjgm/bjfm/t648265.htm" rel="nofollow">
存档
</a>
于2012-12-09).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E9%A2%A8%E8%B2%8C%EF%BC%8C%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97-%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%99%E9%96%E6%88%B6%E7%B6%B2%E7%AB%99&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Frwbj%2Fbjgm%2Fbjfm%2Ft648265.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-69">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-69">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://soil.bjny.gov.cn/jbgk-dlgk-dxdm-1.html" rel="nofollow">
基本概況-地形地貌,北京市土壤资源管理信息网
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-03-31
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20110423180438/http://soil.bjny.gov.cn/jbgk-dlgk-dxdm-1.html" rel="nofollow">
存档
</a>
于2011-04-23).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9F%BA%E6%9C%AC%E6%A6%82%E6%B3%81-%E5%9C%B0%E5%BD%A2%E5%9C%B0%E8%B2%8C%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%9F%E5%A3%A4%E8%B5%84%E6%BA%90%E7%AE%A1%E7%90%86%E4%BF%A1%E6%81%AF%E7%BD%91&rft.genre=unknown&rft_id=http%3A%2F%2Fsoil.bjny.gov.cn%2Fjbgk-dlgk-dxdm-1.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-70">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-70">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.china.com.cn/travel/txt/2008-07/09/content_15980706.htm" rel="nofollow">
灵山 风景最为宜人的北京第一高峰,中国网
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-03-31
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160305035827/http://www.china.com.cn/travel/txt/2008-07/09/content_15980706.htm" rel="nofollow">
存档
</a>
于2016-03-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%81%B5%E5%B1%B1+%E9%A3%8E%E6%99%AF%E6%9C%E4%B8%BA%E5%AE%9C%E4%BA%BA%E7%9A%84%E5%8C%97%E4%BA%AC%E7%AC%AC%E4%B8%E9%AB%98%E5%B3%B0%EF%BC%8C%E4%B8+%E5%9B%BD%E7%BD%91&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.china.com.cn%2Ftravel%2Ftxt%2F2008-07%2F09%2Fcontent_15980706.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-71">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-71">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://soil.bjny.gov.cn/jbgk-dlgk-swtz.html" rel="nofollow">
基本概況-水文特征,北京市土壤资源管理信息网
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-03-31
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20110310195756/http://soil.bjny.gov.cn/jbgk-dlgk-swtz.html" rel="nofollow">
存档
</a>
于2011-03-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9F%BA%E6%9C%AC%E6%A6%82%E6%B3%81-%E6%B0%B4%E6%96%87%E7%89%B9%E5%BE%81%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9C%9F%E5%A3%A4%E8%B5%84%E6%BA%90%E7%AE%A1%E7%90%86%E4%BF%A1%E6%81%AF%E7%BD%91&rft.genre=unknown&rft_id=http%3A%2F%2Fsoil.bjny.gov.cn%2Fjbgk-dlgk-swtz.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-72">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-72">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20110606203032/http://www.bjclimate.com/Article/ViewArticle.aspx?id=74" rel="nofollow">
北京的气候,北京市氣候中心
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-04-01
</span>
]
</span>
. (
<a class="external text" href="http://www.bjclimate.com/Article/ViewArticle.aspx?id=74" rel="nofollow">
原始内容
</a>
存档于2011-06-06).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%94%E5%99%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E6%B0%A3%E5%99%E4%B8+%E5%BF%83&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bjclimate.com%2FArticle%2FViewArticle.aspx%3Fid%3D74&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-73">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-73">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.meworks.net/meworksv2a/meworks/page1.aspx?no=272746&step=1&newsno=71632" rel="nofollow">
第九屆(北京)中國國際園林博覽會台灣園計劃及籌備(上)
</a>
. Meworks.net.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170405191136/http://www.meworks.net/meworksv2a/meworks/page1.aspx?no=272746&step=1&newsno=71632" rel="nofollow">
存档
</a>
于2017-04-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%AC%AC%E4%B9%9D%E5%B1%86%EF%BC%88%E5%8C%97%E4%BA%AC%EF%BC%89%E4%B8+%E5%9C%E5%9C%E9%9A%9B%E5%9C%92%E6%9E%97%E5%9A%E8%A6%BD%E6%9C%83%E5%8F%B0%E7%81%A3%E5%9C%92%E8%A8%88%E5%8A%83%E5%8F%8A%E7%B1%8C%E5%82%99%28%E4%B8%8A%29&rft.genre=unknown&rft.pub=Meworks.net&rft_id=http%3A%2F%2Fwww.meworks.net%2Fmeworksv2a%2Fmeworks%2Fpage1.aspx%3Fno%3D272746%26step%3D1%26newsno%3D71632&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-74">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-74">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.sohu.com/20100308/n270643243.shtml" rel="nofollow">
钢搬迁任务将在今年末完成,解决2.2万人安置,搜狐新聞
</a>
. News.sohu.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160304194311/http://news.sohu.com/20100308/n270643243.shtml" rel="nofollow">
存档
</a>
于2016-03-04).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E9%92%A2%E6%90%AC%E8%BF%81%E4%BB%BB%E5%8A%A1%E5%B0%86%E5%9C%A8%E4%BB%8A%E5%B9%B4%E6%9C%AB%E5%AE%8C%E6%88%90%2C%E8%A7%A3%E5%86%B32.2%E4%B8%87%E4%BA%BA%E5%AE%89%E7%BD%AE%2C%E6%90%9C%E7%90%E6%96%B0%E8%81%9E&rft.genre=unknown&rft.pub=News.sohu.com&rft_id=http%3A%2F%2Fnews.sohu.com%2F20100308%2Fn270643243.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-75">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-75">
^
</a>
</b>
</span>
<span class="reference-text">
[http:/city.cctv.com/html/chengshijingji/78ffb830c262c92c561240150a2831b8.html 北京市政府採購千輛環保公交,央視網]
</span>
</li>
<li id="cite_note-76">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-76">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/life/2008-12/31/content_10584336.htm" rel="nofollow">
北京将禁止黄标车进五环 按规定淘汰者可获补贴
</a>
. 新华网.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20091009222200/http://news.xinhuanet.com/life/2008-12/31/content_10584336.htm" rel="nofollow">
存档
</a>
于2009-10-09).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B0%86%E7%A6%81%E6+%A2%E9%BB%84%E6%A0%87%E8%BD%A6%E8%BF%9B%E4%BA%94%E7%8E%AF+%E6%8C%89%E8%A7%84%E5%AE%9A%E6%B7%98%E6%B1%B0%E8%85%E5%8F%AF%E8%8E%B7%E8%A1%A5%E8%B4%B4&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flife%2F2008-12%2F31%2Fcontent_10584336.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-77">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-77">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.google.com/hostednews/afp/article/ALeqM5h2oAJSt6fzSbhMkQGkeo7mFHJZdg?docId=CNG.d5279d4645145772cb4f2ed6de93e61f.21" rel="nofollow">
Beijing air pollution off the charts, US says
</a>
. AFP.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20110228073848/http://www.google.com/hostednews/afp/article/ALeqM5h2oAJSt6fzSbhMkQGkeo7mFHJZdg?docId=CNG.d5279d4645145772cb4f2ed6de93e61f.21" rel="nofollow">
存档
</a>
于2011-02-28).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=Beijing+air+pollution+off+the+charts%2C+US+says&rft.genre=unknown&rft.pub=AFP&rft_id=http%3A%2F%2Fwww.google.com%2Fhostednews%2Fafp%2Farticle%2FALeqM5h2oAJSt6fzSbhMkQGkeo7mFHJZdg%3FdocId%3DCNG.d5279d4645145772cb4f2ed6de93e61f.21&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-78">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-78">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.qq.com/a/20110224/001032.htm" rel="nofollow">
视频:北京接连三天雾霾缠身 空气质量持续超标
</a>
. 腾讯网.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20161025221534/http://news.qq.com/a/20110224/001032.htm" rel="nofollow">
存档
</a>
于2016-10-25).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E8%A7%86%E9%A2%91%EF%BC%9A%E5%8C%97%E4%BA%AC%E6%8E%A5%E8%BF%9E%E4%B8%89%E5%A4%A9%E9%9B%BE%E9%9C%BE%E7%BC%A0%E8%BA%AB+%E7%A9%BA%E6%B0%94%E8%B4%A8%E9%87%8F%E6%8C%81%E7%BB+%E8%B6%85%E6%A0%87&rft.genre=unknown&rft.pub=%E8%85%BE%E8%AE%AF%E7%BD%91&rft_id=http%3A%2F%2Fnews.qq.com%2Fa%2F20110224%2F001032.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-79">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-79">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20160304133823/http://sports.21cn.com/integrate/other/2013/01/15/14400120.shtml" rel="nofollow">
全球10大空气污染城市太原居首 市民阴霾晨练
</a>
. Sports.21cn.com. 2013-01-15
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (
<a class="external text" href="http://sports.21cn.com/integrate/other/2013/01/15/14400120.shtml" rel="nofollow">
原始内容
</a>
存档于2016-03-04).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%85%A8%E7%90%8310%E5%A4%A7%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E5%9F%8E%E5%B8%82%E5%A4%AA%E5%8E%9F%E5%B1%85%E9%A6%96+%E5%B8%82%E6%B0%91%E9%98%B4%E9%9C%BE%E6%99%A8%E7%BB%83&rft.date=2013-01-15&rft.genre=unknown&rft.pub=Sports.21cn.com&rft_id=http%3A%2F%2Fsports.21cn.com%2Fintegrate%2Fother%2F2013%2F01%2F15%2F14400120.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-80">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-80">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.cnr.cn/gnxw/201004/t20100414_506284381.html" rel="nofollow">
北京加大力度科学治理杨柳飞絮,中國廣播網
</a>
. News.cnr.cn.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160308024128/http://news.cnr.cn/gnxw/201004/t20100414_506284381.html" rel="nofollow">
存档
</a>
于2016-03-08).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%8A%A0%E5%A4%A7%E5%8A%9B%E5%BA%A6%E7%A7%91%E5+%A6%E6%B2%BB%E7%90%86%E6%9D%A8%E6%9F%B3%E9%A3%9E%E7%B5%AE%EF%BC%8C%E4%B8+%E5%9C%E5%BB%A3%E6%92+%E7%B6%B2&rft.genre=unknown&rft.pub=News.cnr.cn&rft_id=http%3A%2F%2Fnews.cnr.cn%2Fgnxw%2F201004%2Ft20100414_506284381.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-asdfsd-81">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-asdfsd_81-0">
<sup>
<b>
77.0
</b>
</sup>
</a>
<a href="#cite_ref-asdfsd_81-1">
<sup>
<b>
77.1
</b>
</sup>
</a>
<a href="#cite_ref-asdfsd_81-2">
<sup>
<b>
77.2
</b>
</sup>
</a>
</span>
<span class="reference-text">
<a class="external text" href="http://env.people.com.cn/GB/16512409.html" rel="nofollow">
PM2.5再惹争议
</a>
<a class="external text" href="//web.archive.org/web/20111207142112/http://env.people.com.cn/GB/16512409.html" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,人民网
</span>
</li>
<li id="cite_note-82">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-82">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="http://www.chinadaily.com.cn/hqgj/jryw/2011-11-01/content_4232542.html" rel="nofollow">
北京市浓雾将加重空气污染
</a>
<a class="external text" href="//web.archive.org/web/20161023171231/http://www.chinadaily.com.cn/hqgj/jryw/2011-11-01/content_4232542.html" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,中国日报
</span>
</li>
<li id="cite_note-83">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-83">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="http://www.chinanews.com/gn/2011/12-16/3538146.shtml" rel="nofollow">
专家称跨省空气污染控制会牵涉多方利益 并非易事
</a>
<a class="external text" href="//web.archive.org/web/20111218034810/http://www.chinanews.com/gn/2011/12-16/3538146.shtml" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,中国新闻网
</span>
</li>
<li id="cite_note-84">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-84">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="http://finance.ifeng.com/opinion/xzsuibi/20111101/4966491.shtml" rel="nofollow">
谁来治理北京的空气污染
</a>
<a class="external text" href="//web.archive.org/web/20120529013516/http://finance.ifeng.com/opinion/xzsuibi/20111101/4966491.shtml" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,凤凰网
</span>
</li>
<li id="cite_note-85">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-85">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="http://news.xinhuanet.com/society/2011-12/18/c_111252730.htm" rel="nofollow">
北京市环保局称北京空气质量优良天数创历史最好水平
</a>
<a class="external text" href="//web.archive.org/web/20161023140227/http://news.xinhuanet.com/society/2011-12/18/c_111252730.htm" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,新华网
</span>
</li>
<li id="cite_note-86">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-86">
^
</a>
</b>
</span>
<span class="reference-text">
<a class="external text" href="http://epaper.jinghua.cn/html/2011-12/22/content_744304.htm" rel="nofollow">
京津冀确定明年起监测PM2.5
</a>
<a class="external text" href="//web.archive.org/web/20120120083625/http://epaper.jinghua.cn/html/2011-12/22/content_744304.htm" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
,京华时报
</span>
</li>
<li id="cite_note-87">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-87">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://money.163.com/12/0214/00/7Q6C7SAO00252G50.html" rel="nofollow">
PM2.5标准向西方看齐不现实_网易财经
</a>
. Money.163.com. 2012-02-14
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20161023133256/http://money.163.com/12/0214/00/7Q6C7SAO00252G50.html" rel="nofollow">
存档
</a>
于2016-10-23).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=PM2.5%E6%A0%87%E5%87%86%E5%90%91%E8%A5%BF%E6%96%B9%E7%9C%E9%BD%90%E4%B8%E7%8E%B0%E5%AE%9E_%E7%BD%91%E6%98%93%E8%B4%A2%E7%BB%8F&rft.date=2012-02-14&rft.genre=unknown&rft.pub=Money.163.com&rft_id=http%3A%2F%2Fmoney.163.com%2F12%2F0214%2F00%2F7Q6C7SAO00252G50.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-88">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-88">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.dw.de/%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E7%A8%8B%E5%BA%A6%E5%88%9B%E5%8E%86%E5%8F%B2%E7%BA%AA%E5%BD%95/a-16517011" rel="nofollow">
北京空气污染程度创历史纪录 | 德国之声中文网中国新闻 | DW | 12.01.2013
</a>
. Dw.de.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20150322202037/http://www.dw.de/%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E7%A8%8B%E5%BA%A6%E5%88%9B%E5%8E%86%E5%8F%B2%E7%BA%AA%E5%BD%95/a-16517011" rel="nofollow">
存档
</a>
于2015-03-22).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E6%B1%A1%E6%9F%93%E7%A8%E5%BA%A6%E5%88%9B%E5%8E%86%E5%8F%B2%E7%BA%AA%E5%BD%95+%26%23124%3B+%E5%BE%B7%E5%9B%BD%E4%B9%E5%A3%B0%E4%B8+%E6%96%87%E7%BD%91%E4%B8+%E5%9B%BD%E6%96%B0%E9%97%BB+%26%23124%3B+DW+%26%23124%3B+12.01.2013&rft.genre=unknown&rft.pub=Dw.de&rft_id=http%3A%2F%2Fwww.dw.de%2F%25E5%258C%2597%25E4%25BA%25AC%25E7%25A9%25BA%25E6%25B0%2594%25E6%25B1%25A1%25E6%259F%2593%25E7%25A8%258B%25E5%25BA%25A6%25E5%2588%259B%25E5%258E%2586%25E5%258F%25B2%25E7%25BA%25AA%25E5%25BD%2595%2Fa-16517011&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-89">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-89">
^
</a>
</b>
</span>
<span class="reference-text">
PM2.5年终大考:超标近两倍
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20140831130529/http://bjwb.bjd.com.cn/html/2014-01/02/content_139456.htm" rel="nofollow">
存档副本
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2014-09-18
</span>
]
</span>
. (
<a class="external text" href="http://bjwb.bjd.com.cn/html/2014-01/02/content_139456.htm" rel="nofollow">
原始内容
</a>
存档于2014-08-31).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5+%98%E6%A1%A3%E5%89%AF%E6%9C%AC&rft.genre=unknown&rft_id=http%3A%2F%2Fbjwb.bjd.com.cn%2Fhtml%2F2014-01%2F02%2Fcontent_139456.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-90">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-90">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京日报.
<a class="external text" href="http://www.gov.cn/xinwen/2020-01/04/content_5466420.htm" rel="nofollow">
2019年北京空气质量7年来最好
</a>
. 中华人民共和国中央人民政府.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-05-30
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200615053953/http://www.gov.cn/xinwen/2020-01/04/content_5466420.htm" rel="nofollow">
存档
</a>
于2020-06-15).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=2019%E5%B9%B4%E5%8C%97%E4%BA%AC%E7%A9%BA%E6%B0%94%E8%B4%A8%E9%87%8F7%E5%B9%B4%E6%9D%A5%E6%9C%E5%A5%BD&rft.au=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8+%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C&rft_id=http%3A%2F%2Fwww.gov.cn%2Fxinwen%2F2020-01%2F04%2Fcontent_5466420.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-91">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-91">
^
</a>
</b>
</span>
<span class="reference-text">
淩霄:民國時期的特別市,鐘山風雨,2009年3期
</span>
</li>
<li id="cite_note-92">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-92">
^
</a>
</b>
</span>
<span class="reference-text">
北京市統計局 國家統計局北京調查總隊編:《北京統計年鑒2009》,1-1行政區劃,中國統計出版社
</span>
</li>
<li id="cite_note-93">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-93">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://big5.china.com.cn/txt/2002-03/28/content_5124681.htm" rel="nofollow">
北京懷柔平谷即將撤縣改區,中國網
</a>
. Big5.china.com.cn. 2002-03-28
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20150910001413/http://big5.china.com.cn/txt/2002-03/28/content_5124681.htm" rel="nofollow">
存档
</a>
于2015-09-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%87%B7%E6%9F%94%E5%B9%B3%E8%B0%B7%E5%B3%E5%B0%87%E6%92%A4%E7%B8%A3%E6%94%B9%E5%EF%BC%8C%E4%B8+%E5%9C%E7%B6%B2&rft.date=2002-03-28&rft.genre=unknown&rft.pub=Big5.china.com.cn&rft_id=http%3A%2F%2Fbig5.china.com.cn%2Ftxt%2F2002-03%2F28%2Fcontent_5124681.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-94">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-94">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.qq.com/a/20100701/001724.htm" rel="nofollow">
北京城4区合并正式获批 宣武崇文退出历史
</a>
. 新华网. 2010-07-01
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-20
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170805150345/http://news.qq.com/a/20100701/001724.htm" rel="nofollow">
存档
</a>
于2017-08-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%9F%8E4%E5%8C%BA%E5%90%88%E5%B9%B6%E6+%A3%E5%BC%8F%E8%8E%B7%E6%89%B9+%E5%AE%A3%E6+%A6%E5%B4%87%E6%96%87%E9%E5%87%BA%E5%8E%86%E5%8F%B2&rft.date=2010-07-01&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.qq.com%2Fa%2F20100701%2F001724.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-95">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-95">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://news.sina.com.cn/o/2015-11-13/doc-ifxkrwks3865811.shtml" rel="nofollow">
北京撤销最后两个县:以后就是密云区、延庆区了
</a>
. 财经网. 2015-11-13
<span class="reference-accessdate">
[
<span class="nowrap">
2015-11-13
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20151117030122/http://news.sina.com.cn/o/2015-11-13/doc-ifxkrwks3865811.shtml" rel="nofollow">
存档
</a>
于2015-11-17).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%92%A4%E9%94%E6%9C%E5%90%8E%E4%B8%A4%E4%B8%AA%E5%8E%BF%EF%BC%9A%E4%BB%A5%E5%90%8E%E5%B0%B1%E6%98%AF%E5%AF%86%E4%BA%91%E5%8C%BA%E3%81%E5%BB%B6%E5%BA%86%E5%8C%BA%E4%BA%86&rft.date=2015-11-13&rft.genre=article&rft_id=http%3A%2F%2Fnews.sina.com.cn%2Fo%2F2015-11-13%2Fdoc-ifxkrwks3865811.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-96">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-96">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://files2.mca.gov.cn/cws/201502/20150225163817214.html" rel="nofollow">
中华人民共和国县以上行政区划代码
</a>
. 中华人民共和国民政部.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-03-12
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20150402113603/http://files2.mca.gov.cn/cws/201502/20150225163817214.html" rel="nofollow">
存档
</a>
于2015-04-02).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81&rft.genre=unknown&rft.pub=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E6%B0%91%E6%94%BF%E9%83%A8&rft_id=http%3A%2F%2Ffiles2.mca.gov.cn%2Fcws%2F201502%2F20150225163817214.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-99">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-99">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20200317033233/http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm" rel="nofollow">
《北京统计年鉴-2019》
</a>
. 北京市统计局.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-03-12
</span>
]
</span>
. (
<a class="external text" href="http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm" rel="nofollow">
原始内容
</a>
存档于2020-03-17).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E3%8A%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B4-2019%E3&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1&rft_id=http%3A%2F%2F202.96.40.155%2Fnj%2Fmain%2F2019-tjnj%2Fzk%2Findexch.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-100">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-100">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
中华人民共和国民政部. 《中国民政统计年鉴2014》. 中国统计出版社. 2014.08.
<a href="/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/978-7-5037-7130-9" title="Special:网络书源/978-7-5037-7130-9">
<span title="国际标准书号">
ISBN
</span>
978-7-5037-7130-9
</a>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E4%B8+%E5%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E6%B0%91%E6%94%BF%E9%83%A8&rft.btitle=%E3%8A%E4%B8+%E5%9B%BD%E6%B0%91%E6%94%BF%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42014%E3&rft.genre=book&rft.isbn=978-7-5037-7130-9&rft.pub=%E4%B8+%E5%9B%BD%E7%BB%9F%E8%AE%A1%E5%87%BA%E7%89%88%E7%A4%BE&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
<span class="error citation-comment" style="display:none;font-size:100%">
请检查
<code style="color:inherit; border:inherit; padding:inherit;">
|date=
</code>
中的日期值 (
<a href="/wiki/Help:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF#bad_date" title="Help:引文格式1错误">
帮助
</a>
)
</span>
</span>
</li>
<li id="cite_note-101">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-101">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://news.sina.com.cn/c/2019-01-10/doc-ihqhqcis5024778.shtml" rel="nofollow">
北京市人民政府摘牌 城市副中心行政办公区将启用
</a>
. 环球网. 2019-01-10
<span class="reference-accessdate">
[
<span class="nowrap">
2019-01-11
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20190111081844/https://news.sina.com.cn/c/2019-01-10/doc-ihqhqcis5024778.shtml" rel="nofollow">
存档
</a>
于2019-01-11).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C%E6%91%98%E7%89%8C+%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8+%E5%BF%83%E8%A1%8C%E6%94%BF%E5%8A%9E%E5%85%AC%E5%8C%BA%E5%B0%86%E5%90%AF%E7%94%A8&rft.date=2019-01-10&rft.genre=article&rft.jtitle=%E7%8E%AF%E7%90%83%E7%BD%91&rft_id=http%3A%2F%2Fnews.sina.com.cn%2Fc%2F2019-01-10%2Fdoc-ihqhqcis5024778.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-102">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-102">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://news.sina.com.cn/c/2019-01-11/doc-ihqhqcis5083453.shtml" rel="nofollow">
北京市政府机关搬迁至通州区 即日起在新址办公
</a>
. 新浪新闻综合. 2019-01-11
<span class="reference-accessdate">
[
<span class="nowrap">
2019-01-12
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20190111121548/https://news.sina.com.cn/c/2019-01-11/doc-ihqhqcis5083453.shtml" rel="nofollow">
存档
</a>
于2019-01-11).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%BA%9C%E6%9C%BA%E5%85%B3%E6%90%AC%E8%BF%81%E8%87%B3%E9%9A%E5%B7%9E%E5%8C%BA+%E5%B3%E6%97%A5%E8%B5%B7%E5%9C%A8%E6%96%B0%E5%9D%E5%8A%9E%E5%85%AC&rft.date=2019-01-11&rft.genre=unknown&rft.pub=%E6%96%B0%E6%B5%AA%E6%96%B0%E9%97%BB%E7%BB%BC%E5%90%88&rft_id=https%3A%2F%2Fnews.sina.com.cn%2Fc%2F2019-01-11%2Fdoc-ihqhqcis5083453.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-103">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-103">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="https://web.archive.org/web/20190111121603/http://shilingdao.beijing.gov.cn/library/191/10/738495/1577140/index.html" rel="nofollow">
北京市级行政中心正式迁入城市副中心 蔡奇陈吉宁李伟吉林出席升旗仪式并揭牌
</a>
. 北京日报. 2019-01-11
<span class="reference-accessdate">
[
<span class="nowrap">
2019-01-11
</span>
]
</span>
. (
<a class="external text" href="http://shilingdao.beijing.gov.cn/library/191/10/738495/1577140/index.html" rel="nofollow">
原始内容
</a>
存档于2019-01-11).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BA%A7%E8%A1%8C%E6%94%BF%E4%B8+%E5%BF%83%E6+%A3%E5%BC%8F%E8%BF%81%E5%85%A5%E5%9F%8E%E5%B8%82%E5%89%AF%E4%B8+%E5%BF%83+%E8%94%A1%E5%A5%87%E9%99%88%E5%90%89%E5%AE%81%E6%9D%8E%E4%BC%9F%E5%90%89%E6%9E%97%E5%87%BA%E5%B8+%E5%87%E6%97%97%E4%BB%AA%E5%BC%8F%E5%B9%B6%E6%8F+%E7%89%8C&rft.date=2019-01-11&rft.genre=article&rft.jtitle=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5&rft_id=http%3A%2F%2Fshilingdao.beijing.gov.cn%2Flibrary%2F191%2F10%2F738495%2F1577140%2Findex.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-104">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-104">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://news.china.com/domestic/945/20170527/30585359.html" rel="nofollow">
蔡奇任北京市委书记 郭金龙不再兼任(图/简历)
</a>
. 新华网. 2017-05-27
<span class="reference-accessdate">
[
<span class="nowrap">
2018-02-24
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20180225064923/http://news.china.com/domestic/945/20170527/30585359.html" rel="nofollow">
存档
</a>
于2018-02-25).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E8%94%A1%E5%A5%87%E4%BB%BB%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E4%B9%A6%E8%AE%B0+%E9%83+%E9%87%91%E9%BE%99%E4%B8%E5%86%E5%85%BC%E4%BB%BB%28%E5%9B%BE%2F%E7%AE%E5%8E%86%29&rft.date=2017-05-27&rft.genre=article&rft_id=http%3A%2F%2Fnews.china.com%2Fdomestic%2F945%2F20170527%2F30585359.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-105">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-105">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="https://web.archive.org/web/20180224232716/http://news.163.com/17/0120/11/CB7JGJUD00018AOQ.html" rel="nofollow">
李伟任北京市人大常委会主任(图/简历)
</a>
. 中国经济网(北京). 2017-01-20
<span class="reference-accessdate">
[
<span class="nowrap">
2018-02-24
</span>
]
</span>
. (
<a class="external text" href="http://news.163.com/17/0120/11/CB7JGJUD00018AOQ.html" rel="nofollow">
原始内容
</a>
存档于2018-02-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E6%9D%8E%E4%BC%9F%E4%BB%BB%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A%E4%B8%BB%E4%BB%BB%28%E5%9B%BE%2F%E7%AE%E5%8E%86%29&rft.date=2017-01-20&rft.genre=article&rft_id=http%3A%2F%2Fnews.163.com%2F17%2F0120%2F11%2FCB7JGJUD00018AOQ.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-106">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-106">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://finance.sina.com.cn/roll/2018-01-30/doc-ifyqyesy4176553.shtml" rel="nofollow">
北京新一届市长、副市长名单 陈吉宁当选市长
</a>
. 中国经济网. 2018-01-30
<span class="reference-accessdate">
[
<span class="nowrap">
2018-02-24
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20180225065047/http://finance.sina.com.cn/roll/2018-01-30/doc-ifyqyesy4176553.shtml" rel="nofollow">
存档
</a>
于2018-02-25).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%96%B0%E4%B8%E5%B1%8A%E5%B8%82%E9%95%BF%E3%81%E5%89%AF%E5%B8%82%E9%95%BF%E5%90%E5%95+%E9%99%88%E5%90%89%E5%AE%81%E5%BD%93%E9%89%E5%B8%82%E9%95%BF&rft.date=2018-01-30&rft.genre=article&rft_id=http%3A%2F%2Ffinance.sina.com.cn%2Froll%2F2018-01-30%2Fdoc-ifyqyesy4176553.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-107">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-107">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.gov.cn/rsrm/2013-01/25/content_2319695.htm" rel="nofollow">
吉林当选北京市政协主席
</a>
. 新华社. 2013-01-25
<span class="reference-accessdate">
[
<span class="nowrap">
2018-02-24
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20180224232726/http://www.gov.cn/rsrm/2013-01/25/content_2319695.htm" rel="nofollow">
存档
</a>
于2018-02-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%90%89%E6%9E%97%E5%BD%93%E9%89%E5%8C%97%E4%BA%AC%E5%B8%82%E6%94%BF%E5%8F%E4%B8%BB%E5%B8+&rft.date=2013-01-25&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%A4%BE&rft_id=http%3A%2F%2Fwww.gov.cn%2Frsrm%2F2013-01%2F25%2Fcontent_2319695.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-108">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-108">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.chinanews.com/cj/2016/01-21/7726436.shtml" rel="nofollow">
去年北京GDP增速6.9% 人均GDP超1.7万美元
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-12
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170113150846/http://www.chinanews.com/cj/2016/01-21/7726436.shtml" rel="nofollow">
存档
</a>
于2017-01-13).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8E%BB%E5%B9%B4%E5%8C%97%E4%BA%ACGDP%E5%A2%9E%E9%9F6.9%25+%E4%BA%BA%E5%9D%87GDP%E8%B6%851.7%E4%B8%87%E7%BE%8E%E5%85%83&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fcj%2F2016%2F01-21%2F7726436.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-21jj-109">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-21jj_109-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
定军、吴靖、史梦怡.
<a class="external text" href="http://www.21jingji.com/2016/1-22/3MMDA2NTFfMTM4Njc3Mg.html" rel="nofollow">
北京晒2015成绩单:传统产业减速
</a>
. 21世纪经济报道. 2016-01-22
<span class="reference-accessdate">
[
<span class="nowrap">
2016-12-26
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20161226220807/http://www.21jingji.com/2016/1-22/3MMDA2NTFfMTM4Njc3Mg.html" rel="nofollow">
存档
</a>
于2016-12-26).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E6%99%922015%E6%88%90%E7%BB%A9%E5%95%EF%BC%9A%E4%BC%A0%E7%BB%9F%E4%BA%A7%E4%B8%9A%E5%87%8F%E9%9F&rft.au=%E5%AE%9A%E5%86%9B%E3%81%E5%90%B4%E9%9D%96%E3%81%E5%8F%B2%E6%A2%A6%E6%A1&rft.date=2016-01-22&rft.genre=unknown&rft.jtitle=21%E4%B8%96%E7%BA%AA%E7%BB%8F%E6%B5%8E%E6%8A%A5%E9%81%93&rft_id=http%3A%2F%2Fwww.21jingji.com%2F2016%2F1-22%2F3MMDA2NTFfMTM4Njc3Mg.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-分省年度數據-110">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-分省年度數據_110-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20150317160159/http://data.stats.gov.cn/workspace/index?m=fsnd" rel="nofollow">
分省年度數據
</a>
. 中華人民共和國國家統計局.
<span class="reference-accessdate">
[
<span class="nowrap">
2015-01-08
</span>
]
</span>
. (
<a class="external text" href="http://data.stats.gov.cn/workspace/index?m=fsnd" rel="nofollow">
原始内容
</a>
存档于2015-03-17)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">
(中文)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%88%86%E7%9C%81%E5%B9%B4%E5%BA%A6%E6%95%B8%E6%93%9A&rft.genre=unknown&rft.pub=%E4%B8+%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%E5%9C%E5%AE%B6%E7%B5%B1%E8%A8%88%E5%B1&rft_id=http%3A%2F%2Fdata.stats.gov.cn%2Fworkspace%2Findex%3Fm%3Dfsnd&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-111">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-111">
^
</a>
</b>
</span>
<span class="reference-text">
李京文, 何喜军《北京制造业发展史》.中国财政经济出版社,2010
</span>
</li>
<li id="cite_note-gk-112">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-gk_112-0">
<sup>
<b>
106.0
</b>
</sup>
</a>
<a href="#cite_ref-gk_112-1">
<sup>
<b>
106.1
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://china-trade-research.hktdc.com/business-news/article/%E6%95%B8%E6%93%9A%E5%8F%8A%E6%8C%87%E6%95%B8/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A0%B4%E6%A6%82%E6%B3%81/ff/tc/1/1X000000/1X06BPU3.htm" rel="nofollow">
北京市場概況
</a>
. China-trade-research.hktdc.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170805144658/http://china-trade-research.hktdc.com/business-news/article/%E6%95%B8%E6%93%9A%E5%8F%8A%E6%8C%87%E6%95%B8/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A0%B4%E6%A6%82%E6%B3%81/ff/tc/1/1X000000/1X06BPU3.htm" rel="nofollow">
存档
</a>
于2017-08-05)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A0%B4%E6%A6%82%E6%B3%81&rft.genre=unknown&rft.pub=China-trade-research.hktdc.com&rft_id=http%3A%2F%2Fchina-trade-research.hktdc.com%2Fbusiness-news%2Farticle%2F%25E6%2595%25B8%25E6%2593%259A%25E5%258F%258A%25E6%258C%2587%25E6%2595%25B8%2F%25E5%258C%2597%25E4%25BA%25AC%25E5%25B8%2582%25E5%25A0%25B4%25E6%25A6%2582%25E6%25B3%2581%2Fff%2Ftc%2F1%2F1X000000%2F1X06BPU3.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-113">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-113">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/auto/2009-12/18/content_12668015.htm" rel="nofollow">
北京机动车保有量突破400万辆,新華網
</a>
. News.xinhuanet.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20141028173609/http://news.xinhuanet.com/auto/2009-12/18/content_12668015.htm" rel="nofollow">
存档
</a>
于2014-10-28).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%9C%BA%E5%8A%A8%E8%BD%A6%E4%BF%9D%E6%9C%89%E9%87%8F%E7%AA%81%E7%A0%B4400%E4%B8%87%E8%BE%86%EF%BC%8C%E6%96%B0%E8%8F%AF%E7%B6%B2&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Fauto%2F2009-12%2F18%2Fcontent_12668015.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-2015公报-114">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-2015公报_114-0">
<sup>
<b>
108.0
</b>
</sup>
</a>
<a href="#cite_ref-2015公报_114-1">
<sup>
<b>
108.1
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20161226221556/http://www.bjstats.gov.cn/tjsj/tjgb/ndgb/201603/t20160329_346055.html" rel="nofollow">
北京市2015年暨“十二五”时期国民经济和社会发展统计公报
</a>
. 北京统计信息网. 北京市统计局. 2016-02-15
<span class="reference-accessdate">
[
<span class="nowrap">
2016-12-26
</span>
]
</span>
. (
<a class="external text" href="http://www.bjstats.gov.cn/tjsj/tjgb/ndgb/201603/t20160329_346055.html" rel="nofollow">
原始内容
</a>
存档于2016-12-26).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%822015%E5%B9%B4%E6%9A%A8%9C%E5%81%E4%BA%8C%E4%BA%94%9D%E6%97%B6%E6%9C%9F%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.date=2016-02-15&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E4%BF%A1%E6%81%AF%E7%BD%91&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Ftjsj%2Ftjgb%2Fndgb%2F201603%2Ft20160329_346055.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-115">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-115">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/fortune/2007-05/19/content_6122037.htm" rel="nofollow">
未来五年北京南城将变什么样
</a>
. 新华网.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20081014183709/http://news.xinhuanet.com/fortune/2007-05/19/content_6122037.htm" rel="nofollow">
存档
</a>
于2008-10-14).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%9C%AA%E6%9D%A5%E4%BA%94%E5%B9%B4%E5%8C%97%E4%BA%AC%E5%97%E5%9F%8E%E5%B0%86%E5%8F%98%E4%BB%E4%B9%88%E6%A0%B7&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Ffortune%2F2007-05%2F19%2Fcontent_6122037.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-116">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-116">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20110217132109/http://news.bjnews.com.cn/2009/0925/45171.shtml" rel="nofollow">
北京南部要三年大变样 “南穷北富”有望缓解
</a>
. 新京报网站.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (
<a class="external text" href="http://news.bjnews.com.cn/2009/0925/45171.shtml" rel="nofollow">
原始内容
</a>
存档于2011-02-17).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%97%E9%83%A8%E8%A6%81%E4%B8%89%E5%B9%B4%E5%A4%A7%E5%8F%98%E6%A0%B7+%9C%E5%97%E7%A9%B7%E5%8C%97%E5%AF%8C%9D%E6%9C%89%E6%9C%9B%E7%BC%93%E8%A7%A3&rft.genre=unknown&rft.pub=%E6%96%B0%E4%BA%AC%E6%8A%A5%E7%BD%91%E7%AB%99&rft_id=http%3A%2F%2Fnews.bjnews.com.cn%2F2009%2F0925%2F45171.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-117">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-117">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.sina.com.cn/c/2004-08-25/18274137286.shtml" rel="nofollow">
北京经济概况
</a>
. News.sina.com.cn.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170113155042/http://news.sina.com.cn/c/2004-08-25/18274137286.shtml" rel="nofollow">
存档
</a>
于2017-01-13).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%BB%8F%E6%B5%8E%E6%A6%82%E5%86%B5&rft.genre=unknown&rft.pub=News.sina.com.cn&rft_id=http%3A%2F%2Fnews.sina.com.cn%2Fc%2F2004-08-25%2F18274137286.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-118">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-118">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20160405103546/http://www.beijing.gov.cn/rwbj/bjgm/sdjj/t648231.htm" rel="nofollow">
首都经济
</a>
. Beijing.gov.cn.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (
<a class="external text" href="http://www.beijing.gov.cn/rwbj/bjgm/sdjj/t648231.htm" rel="nofollow">
原始内容
</a>
存档于2016-04-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E9%A6%96%E9%83%BD%E7%BB%8F%E6%B5%8E&rft.genre=unknown&rft.pub=Beijing.gov.cn&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Frwbj%2Fbjgm%2Fsdjj%2Ft648231.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-19年公报-120">
<span class="mw-cite-backlink">
^
<a href="#cite_ref-19年公报_120-0">
<sup>
<b>
113.0
</b>
</sup>
</a>
<a href="#cite_ref-19年公报_120-1">
<sup>
<b>
113.1
</b>
</sup>
</a>
<a href="#cite_ref-19年公报_120-2">
<sup>
<b>
113.2
</b>
</sup>
</a>
</span>
<span class="reference-text">
<cite class="citation web">
北京市统计局、国家统计局北京调查总队.
<a class="external text" href="http://www.beijing.gov.cn/gongkai/shuju/tjgb/202003/t20200302_1838196.html" rel="nofollow">
北京市2019年国民经济和社会发展统计公报
</a>
. 首都之窗. 2020-03-08
<span class="reference-accessdate">
[
<span class="nowrap">
2020-05-24
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200827102523/http://www.beijing.gov.cn/gongkai/shuju/tjgb/202003/t20200302_1838196.html" rel="nofollow">
存档
</a>
于2020-08-27)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%822019%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.date=2020-03-08&rft.genre=unknown&rft.pub=%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Fgongkai%2Fshuju%2Ftjgb%2F202003%2Ft20200302_1838196.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-121">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-121">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.urbansustrans.cn/info_detail.asp?id=1083" rel="nofollow">
总结交通拥堵五大原因 筹备新北京交通体系,城市交通研究中心
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-04-01
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20110905121501/http://www.urbansustrans.cn/info_detail.asp?id=1083" rel="nofollow">
存档
</a>
于2011-09-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%BB%E7%BB%93%E4%BA%A4%E9%9A%E6%A5%E5%A0%B5%E4%BA%94%E5%A4%A7%E5%8E%9F%E5%9B%A0+%E7+%B9%E5%A4%87%E6%96%B0%E5%8C%97%E4%BA%AC%E4%BA%A4%E9%9A%E4%BD%93%E7%B3%BB%EF%BC%8C%E5%9F%8E%E5%B8%82%E4%BA%A4%E9%9A%E7%A0%94%E7%A9%B6%E4%B8+%E5%BF%83&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.urbansustrans.cn%2Finfo_detail.asp%3Fid%3D1083&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-122">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-122">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.cnr.cn/09zt/2010jjdflh/wyjy/201001/t20100125_505943311.html" rel="nofollow">
2010年北京“兩會”:代表、委員議交通,中廣網
</a>
. Cnr.cn.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160307102936/http://www.cnr.cn/09zt/2010jjdflh/wyjy/201001/t20100125_505943311.html" rel="nofollow">
存档
</a>
于2016-03-07).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=2010%E5%B9%B4%E5%8C%97%E4%BA%AC%9C%E5%85%A9%E6%9C%83%9D%EF%BC%9A%E4%BB%A3%E8%A1%A8%E3%81%E5%A7%94%E5%93%A1%E8+%B0%E4%BA%A4%E9%9A%EF%BC%8C%E4%B8+%E5%BB%A3%E7%B6%B2&rft.genre=unknown&rft.pub=Cnr.cn&rft_id=http%3A%2F%2Fwww.cnr.cn%2F09zt%2F2010jjdflh%2Fwyjy%2F201001%2Ft20100125_505943311.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-123">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-123">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
冯蕾.
<a class="external text" href="http://www.gmw.cn/01gmrb/2006-09/27/content_485833.htm" rel="nofollow">
中国公路“零公里”标志亮相天安门广场,光明日報,2006年9月27日
</a>
. Gmw.cn. 2006-09-27
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170930055840/http://www.gmw.cn/01gmrb/2006-09/27/content_485833.htm" rel="nofollow">
存档
</a>
于2017-09-30).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%86%AF%E8%95%BE&rft.btitle=%E4%B8+%E5%9B%BD%E5%85%AC%E8%B7%AF%9C%E9%9B%B6%E5%85%AC%E9%87%8C%9D%E6%A0%87%E5%BF%97%E4%BA%AE%E7%9B%B8%E5%A4%A9%E5%AE%89%E9%97%A8%E5%B9%BF%E5%9C%BA%EF%BC%8C%E5%85%89%E6%98%8E%E6%97%A5%E5%A0%B1%EF%BC%8C2006%E5%B9%B49%E6%9C%8827%E6%97%A5&rft.date=2006-09-27&rft.genre=unknown&rft.pub=Gmw.cn&rft_id=http%3A%2F%2Fwww.gmw.cn%2F01gmrb%2F2006-09%2F27%2Fcontent_485833.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-124">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-124">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.bjghy.com.cn/xslw/xslw_Detail.asp?UId=2" rel="nofollow">
宋曉龍:北京历史文化名城保护的思考和定位,北京市城市规划设计研究院
</a>
.
<span class="reference-accessdate">
[
<span class="nowrap">
2010-04-14
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20071118000246/http://www.bjghy.com.cn/xslw/xslw_Detail.asp?UId=2" rel="nofollow">
存档
</a>
于2007-11-18).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%AE%E6%9B%89%E9%BE%EF%BC%9A%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%E5%9F%8E%E4%BF%9D%E6%8A%A4%E7%9A%84%E6%9D%E8%83%E5%92%8C%E5%AE%9A%E4%BD%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E5%9F%8E%E5%B8%82%E8%A7%84%E5%88%92%E8%AE%BE%E8%AE%A1%E7%A0%94%E7%A9%B6%E9%99%A2&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bjghy.com.cn%2Fxslw%2Fxslw_Detail.asp%3FUId%3D2&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-19年鉴-125">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-19年鉴_125-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京统计局.
<a class="external text" href="https://web.archive.org/web/20200317033233/http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm" rel="nofollow">
北京统计年鉴2019
</a>
. 北京统计年鉴.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-03-12
</span>
]
</span>
. (
<a class="external text" href="http://202.96.40.155/nj/main/2019-tjnj/zk/indexch.htm" rel="nofollow">
原始内容
</a>
存档于2020-03-17).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42019&rft.au=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B1&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B4&rft_id=http%3A%2F%2F202.96.40.155%2Fnj%2Fmain%2F2019-tjnj%2Fzk%2Findexch.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-2035总规-126">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-2035总规_126-0">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京规划和国土资源委员会.
<a class="external text" href="http://www.beijing.gov.cn/gongkai/guihua/wngh/cqgh/201907/t20190701_100008.html" rel="nofollow">
北京城市总体规划(2016年—2035年)
</a>
. 首都之窗.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-05-24
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200715214829/http://www.beijing.gov.cn/gongkai/guihua/wngh/cqgh/201907/t20190701_100008.html" rel="nofollow">
存档
</a>
于2020-07-15).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%B8%82%E6%BB%E4%BD%93%E8%A7%84%E5%88%92%282016%E5%B9%B4%942035%E5%B9%B4%29&rft.au=%E5%8C%97%E4%BA%AC%E8%A7%84%E5%88%92%E5%92%8C%E5%9B%BD%E5%9C%9F%E8%B5%84%E6%BA%90%E5%A7%94%E5%91%98%E4%BC%9A&rft.genre=unknown&rft.jtitle=%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Fgongkai%2Fguihua%2Fwngh%2Fcqgh%2F201907%2Ft20190701_100008.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-127">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-127">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://daishoudian.114piaowu.com/beijing/" rel="nofollow">
全国火车票订票点大全,火车票订票电话
</a>
. Huoche.com.cn. 2016-12-20
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170606042953/http://daishoudian.114piaowu.com/beijing/" rel="nofollow">
存档
</a>
于2017-06-06)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%85%A8%E5%9B%BD%E7%81%AB%E8%BD%A6%E7%A5%A8%E8%AE%A2%E7%A5%A8%E7%82%B9%E5%A4%A7%E5%85%A8%2C%E7%81%AB%E8%BD%A6%E7%A5%A8%E8%AE%A2%E7%A5%A8%E7%94%B5%E8%AF%9D&rft.date=2016-12-20&rft.genre=unknown&rft.pub=Huoche.com.cn&rft_id=http%3A%2F%2Fdaishoudian.114piaowu.com%2Fbeijing%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-128">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-128">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/local/2013-03/13/c_115001134.htm" rel="nofollow">
北京地铁日客流1000万人次将成常态,新華網-北京日報,2013年03月13日
</a>
. News.xinhuanet.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160822191539/http://news.xinhuanet.com/local/2013-03/13/c_115001134.htm" rel="nofollow">
存档
</a>
于2016-08-22).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%9C%B0%E9%93%81%E6%97%A5%E5%AE%A2%E6%B5%811000%E4%B8%87%E4%BA%BA%E6%AC%A1%E5%B0%86%E6%88%90%E5%B8%B8%E6%81%2C%E6%96%B0%E8%8F%AF%E7%B6%B2-%E5%8C%97%E4%BA%AC%E6%97%A5%E5%A0%B1%EF%BC%8C2013%E5%B9%B403%E6%9C%8813%E6%97%A5&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flocal%2F2013-03%2F13%2Fc_115001134.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-129">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-129">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
CCTV.com央视国际网络有限公司版权所有.
<a class="external text" href="http://news.cctv.com/china/20080229/100141.shtml" rel="nofollow">
首都机场3号航站楼成世界最大单体航站楼,央視網
</a>
. News.cctv.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20160304213336/http://news.cctv.com/china/20080229/100141.shtml" rel="nofollow">
存档
</a>
于2016-03-04).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=CCTV.com%E5%A4%AE%E8%A7%86%E5%9B%BD%E9%99%85%E7%BD%91%E7%BB%9C%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8%E7%89%88%E6%9D%83%E6%89%E6%9C%89&rft.btitle=%E9%A6%96%E9%83%BD%E6%9C%BA%E5%9C%BA3%E5%8F%B7%E8%88%AA%E7%AB%99%E6%A5%BC%E6%88%90%E4%B8%96%E7%95%8C%E6%9C%E5%A4%A7%E5%95%E4%BD%93%E8%88%AA%E7%AB%99%E6%A5%BC%EF%BC%8C%E5%A4%AE%E8%A6%96%E7%B6%B2&rft.genre=unknown&rft.pub=News.cctv.com&rft_id=http%3A%2F%2Fnews.cctv.com%2Fchina%2F20080229%2F100141.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-130">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-130">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20151226044435/http://gz.ifeng.com/zaobanche/detail_2015_02/06/3531219_0.shtml" rel="nofollow">
白云机场第三跑道启用 成为国内第三个拥有三条跑道的机场
</a>
. Gz.ifeng.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (
<a class="external text" href="http://gz.ifeng.com/zaobanche/detail_2015_02/06/3531219_0.shtml" rel="nofollow">
原始内容
</a>
存档于2015-12-26).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%99%BD%E4%BA%91%E6%9C%BA%E5%9C%BA%E7%AC%AC%E4%B8%89%E8%B7%91%E9%81%93%E5%90%AF%E7%94%A8+%E6%88%90%E4%B8%BA%E5%9B%BD%E5%86%85%E7%AC%AC%E4%B8%89%E4%B8%AA%E6%A5%E6%9C%89%E4%B8%89%E6%9D%A1%E8%B7%91%E9%81%93%E7%9A%84%E6%9C%BA%E5%9C%BA&rft.genre=unknown&rft.pub=Gz.ifeng.com&rft_id=http%3A%2F%2Fgz.ifeng.com%2Fzaobanche%2Fdetail_2015_02%2F06%2F3531219_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-131">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-131">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20170827235736/http://202.123.110.3/ztzl/ggjt/content_509491.htm" rel="nofollow">
北京市委市政府高度重视优先发展公共交通工作,中華人民共和國中央人民政府門戶網站
</a>
. 202.123.110.3.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (
<a class="external text" href="http://202.123.110.3/ztzl/ggjt/content_509491.htm" rel="nofollow">
原始内容
</a>
存档于2017-08-27).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%B8%82%E6%94%BF%E5%BA%9C%E9%AB%98%E5%BA%A6%E9%87%E8%A7%86%E4%BC%98%E5%85%88%E5%8F%91%E5%B1%95%E5%85%AC%E5%85%B1%E4%BA%A4%E9%9A%E5%B7%A5%E4%BD%9C%2C%E4%B8+%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%E4%B8+%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C%E9%96%E6%88%B6%E7%B6%B2%E7%AB%99&rft.genre=unknown&rft.pub=202.123.110.3&rft_id=http%3A%2F%2F202.123.110.3%2Fztzl%2Fggjt%2Fcontent_509491.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-132">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-132">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/fortune/2006-04/30/content_4494016.htm" rel="nofollow">
直面北京“黑车”
</a>
. News.xinhuanet.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20161023133959/http://news.xinhuanet.com/fortune/2006-04/30/content_4494016.htm" rel="nofollow">
存档
</a>
于2016-10-23).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%9B%B4%E9%9D%A2%E5%8C%97%E4%BA%AC%9C%E9%BB%91%E8%BD%A6%9D&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Ffortune%2F2006-04%2F30%2Fcontent_4494016.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-133">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-133">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京日报.
<a class="external text" href="http://www.beijing.gov.cn/fuwu/bmfw/jtcx/ggts/201908/t20190817_1843991.html" rel="nofollow">
2000辆换电出租车8月上路 2020年底三成出租车零排放
</a>
. 首都之窗.
<span class="reference-accessdate">
[
<span class="nowrap">
2020-05-24
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20200524112534/http://www.beijing.gov.cn/fuwu/bmfw/jtcx/ggts/201908/t20190817_1843991.html" rel="nofollow">
存档
</a>
于2020-05-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=2000%E8%BE%86%E6%A2%E7%94%B5%E5%87%BA%E7%A7%9F%E8%BD%A68%E6%9C%88%E4%B8%8A%E8%B7%AF+2020%E5%B9%B4%E5%BA%95%E4%B8%89%E6%88%90%E5%87%BA%E7%A7%9F%E8%BD%A6%E9%9B%B6%E6%8E%92%E6%94%BE&rft.au=%E5%8C%97%E4%BA%AC%E6%97%A5%E6%8A%A5&rft.genre=unknown&rft.jtitle=%E9%A6%96%E9%83%BD%E4%B9%E7%AA%97&rft_id=http%3A%2F%2Fwww.beijing.gov.cn%2Ffuwu%2Fbmfw%2Fjtcx%2Fggts%2F201908%2Ft20190817_1843991.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-134">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-134">
^
</a>
</b>
</span>
<span class="reference-text">
趙爾巽等:清史稿,卷一○七,志八二
</span>
</li>
<li id="cite_note-135">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-135">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
李铁虎.
<a class="external text" href="http://www.bjma.gov.cn/bjma/300486/301443/306629/index.html" rel="nofollow">
民国时期北京政治文化地位刍议
</a>
. 北京市档案信息网.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E6%B0%91%E5%9B%BD%E6%97%B6%E6%9C%9F%E5%8C%97%E4%BA%AC%E6%94%BF%E6%B2%BB%E6%96%87%E5%8C%96%E5%9C%B0%E4%BD%E5%88%E8%AE%AE&rft.au=%E6%9D%8E%E9%93%81%E8%99%8E&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E6%A1%A3%E6%A1%88%E4%BF%A1%E6%81%AF%E7%BD%91&rft_id=http%3A%2F%2Fwww.bjma.gov.cn%2Fbjma%2F300486%2F301443%2F306629%2Findex.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-136">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-136">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京市统计局.
<a class="external text" href="https://web.archive.org/web/20190331090019/http://www.bjstats.gov.cn/tjsj/yjdsj/rk/2018/201901/t20190123_415576.html" rel="nofollow">
全市年末常住人口
</a>
. 2019-01-23
<span class="reference-accessdate">
[
<span class="nowrap">
2019-03-31
</span>
]
</span>
. (
<a class="external text" href="http://www.bjstats.gov.cn/tjsj/yjdsj/rk/2018/201901/t20190123_415576.html" rel="nofollow">
原始内容
</a>
存档于2019-03-31).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1&rft.btitle=%E5%85%A8%E5%B8%82%E5%B9%B4%E6%9C%AB%E5%B8%B8%E4%BD%8F%E4%BA%BA%E5%8F%A3&rft.date=2019-01-23&rft.genre=unknown&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Ftjsj%2Fyjdsj%2Frk%2F2018%2F201901%2Ft20190123_415576.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-137">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-137">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://knowledgedatabase.info/the-basic-information-of-beijing/" rel="nofollow">
The Basic Information of BeiJing - Knowledge Database
</a>
. Knowledge Database. 2018-08-14
<span class="reference-accessdate">
[
<span class="nowrap">
2018-08-15
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20180814103401/http://knowledgedatabase.info/the-basic-information-of-beijing/" rel="nofollow">
存档
</a>
于2018-08-14)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到美国英语网页">
(美国英语)
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=The+Basic+Information+of+BeiJing+-+Knowledge+Database&rft.date=2018-08-14&rft.genre=article&rft.jtitle=Knowledge+Database&rft_id=http%3A%2F%2Fknowledgedatabase.info%2Fthe-basic-information-of-beijing%2F&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-138">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-138">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
北京市统计局、国家统计局北京调查总队.
<a class="external text" href="https://web.archive.org/web/20181224170530/http://tjj.beijing.gov.cn/nj/main/2018-tjnj/zk/indexch.htm" rel="nofollow">
北京统计年鉴2018
</a>
. 北京: 中国统计出版社、北京数通电子出版社. : 3–3
<span class="reference-accessdate">
[
<span class="nowrap">
2019-03-31
</span>
]
</span>
. (
<a class="external text" href="http://tjj.beijing.gov.cn/nj/main/2018-tjnj/zk/indexch.htm" rel="nofollow">
原始内容
</a>
存档于2018-12-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft.btitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42018&rft.genre=book&rft.pages=3-3&rft.place=%E5%8C%97%E4%BA%AC&rft.pub=%E4%B8+%E5%9B%BD%E7%BB%9F%E8%AE%A1%E5%87%BA%E7%89%88%E7%A4%BE%E3%81%E5%8C%97%E4%BA%AC%E6%95%B0%E9%9A%E7%94%B5%E5+%90%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=http%3A%2F%2Ftjj.beijing.gov.cn%2Fnj%2Fmain%2F2018-tjnj%2Fzk%2Findexch.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-139">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-139">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京市统计局、国家统计局北京调查总队.
<a class="external text" href="https://web.archive.org/web/20140310101546/http://www.bjstats.gov.cn/xwgb/tjgb/ndgb/201402/t20140213_267744.htm" rel="nofollow">
北京市2013年国民经济和社会发展统计公报
</a>
. 北京市统计局、国家统计局北京调查总队. 2013-02-13
<span class="reference-accessdate">
[
<span class="nowrap">
2013-03-10
</span>
]
</span>
. (
<a class="external text" href="http://www.bjstats.gov.cn/xwgb/tjgb/ndgb/201402/t20140213_267744.htm" rel="nofollow">
原始内容
</a>
存档于2014-03-10)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%822013%E5%B9%B4%E5%9B%BD%E6%B0%91%E7%BB%8F%E6%B5%8E%E5%92%8C%E7%A4%BE%E4%BC%9A%E5%8F%91%E5%B1%95%E7%BB%9F%E8%AE%A1%E5%85%AC%E6%8A%A5&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft.date=2013-02-13&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Fxwgb%2Ftjgb%2Fndgb%2F201402%2Ft20140213_267744.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-140">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-140">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
北京市第六次人口普查办公室.
<a class="external text" href="https://web.archive.org/web/20140310101349/http://www.bjstats.gov.cn/lhzl/rkpc/201201/t20120109_218574.htm" rel="nofollow">
北京市常住人口地区分布特点
</a>
. 北京市统计局、国家统计局北京调查总队. 2011-05-30
<span class="reference-accessdate">
[
<span class="nowrap">
2013-04-03
</span>
]
</span>
. (
<a class="external text" href="http://www.bjstats.gov.cn/lhzl/rkpc/201201/t20120109_218574.htm" rel="nofollow">
原始内容
</a>
存档于2014-03-10)
<span style="font-family: sans-serif; cursor: default; color:#555; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文(中国大陆)网页">
(中文(中国大陆))
</span>
.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%B8%B8%E4%BD%8F%E4%BA%BA%E5%8F%A3%E5%9C%B0%E5%8C%BA%E5%88%86%E5%B8%83%E7%89%B9%E7%82%B9&rft.au=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%AC%AC%E5%85+%E6%AC%A1%E4%BA%BA%E5%8F%A3%E6%99%AE%E6%9F%A5%E5%8A%9E%E5%85%AC%E5%AE%A4&rft.date=2011-05-30&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E7%BB%9F%E8%AE%A1%E5%B1%E3%81%E5%9B%BD%E5%AE%B6%E7%BB%9F%E8%AE%A1%E5%B1%E5%8C%97%E4%BA%AC%E8%B0%83%E6%9F%A5%E6%BB%E9%98%9F&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Flhzl%2Frkpc%2F201201%2Ft20120109_218574.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-141">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-141">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/overseas/2009-10/08/content_12193602.htm" rel="nofollow">
在华居住韩国人达百万 北京人数最多达二十万,新華網
</a>
. News.xinhuanet.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20130724193221/http://news.xinhuanet.com/overseas/2009-10/08/content_12193602.htm" rel="nofollow">
存档
</a>
于2013-07-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9C%A8%E5%8E%E5%B1%85%E4%BD%8F%E9%9F%A9%E5%9B%BD%E4%BA%BA%E8%BE%BE%E7%99%BE%E4%B8%87+%E5%8C%97%E4%BA%AC%E4%BA%BA%E6%95%B0%E6%9C%E5%A4%9A%E8%BE%BE%E4%BA%8C%E5%81%E4%B8%87%2C%E6%96%B0%E8%8F%AF%E7%B6%B2&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Foverseas%2F2009-10%2F08%2Fcontent_12193602.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-142">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-142">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.xinhuanet.com/local/2011-02/21/c_121102340_2.htm" rel="nofollow">
北京人口规模膨胀超资源极限 调控规模箭在弦上
</a>
. 新华网.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20110224072040/http://news.xinhuanet.com/local/2011-02/21/c_121102340_2.htm" rel="nofollow">
存档
</a>
于2011-02-24).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E4%BA%BA%E5%8F%A3%E8%A7%84%E6%A8%A1%E8%86%A8%E8%83%E8%B6%85%E8%B5%84%E6%BA%90%E6%9E%81%E9%99%90+%E8%B0%83%E6%8E%A7%E8%A7%84%E6%A8%A1%E7%AE+%E5%9C%A8%E5%BC%A6%E4%B8%8A&rft.genre=unknown&rft.pub=%E6%96%B0%E5%8E%E7%BD%91&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flocal%2F2011-02%2F21%2Fc_121102340_2.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-143">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-143">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.chinanews.com/cul/2012/03-01/3711416.shtml" rel="nofollow">
中国国家博物馆正式开馆
</a>
. 中新社. 2012-03-01
<span class="reference-accessdate">
[
<span class="nowrap">
2015-11-14
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20120302220956/http://www.chinanews.com/cul/2012/03-01/3711416.shtml" rel="nofollow">
存档
</a>
于2012-03-02).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B8+%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9A%E7%89%A9%E9%A6%86%E6+%A3%E5%BC%8F%E5%BC%E9%A6%86&rft.date=2012-03-01&rft.genre=article&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fcul%2F2012%2F03-01%2F3711416.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-144">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-144">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation news">
<a class="external text" href="http://www.ecns.cn/2014/06-16/119275.shtml" rel="nofollow">
4 China museums listed on world's top 20
</a>
. 中新网. 2014-06-16
<span class="reference-accessdate">
[
<span class="nowrap">
2015-11-14
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20140620094109/http://www.ecns.cn/2014/06-16/119275.shtml" rel="nofollow">
存档
</a>
于2014-06-20).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=4+China+museums+listed+on+world%27s+top+20&rft.date=2014-06-16&rft.genre=article&rft_id=http%3A%2F%2Fwww.ecns.cn%2F2014%2F06-16%2F119275.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-145">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-145">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20160810110451/http://bjfles.com/Item/3567.aspx" rel="nofollow">
神奇的探索之旅——一年级北京自然博物馆社会实践活动,北京市海淀外国语实验学校,2013-03-21
</a>
. Bjfles.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (
<a class="external text" href="http://www.bjfles.com/Item/3567.aspx" rel="nofollow">
原始内容
</a>
存档于2016-08-10).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E7%A5%9E%E5%A5%87%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B9%E6%97%85%94%94%E4%B8%E5%B9%B4%E7%BA%A7%E5%8C%97%E4%BA%AC%E8%87%AA%E7%84%B6%E5%9A%E7%89%A9%E9%A6%86%E7%A4%BE%E4%BC%9A%E5%AE%9E%E8%B7%B5%E6%B4%BB%E5%8A%A8%EF%BC%8C%E5%8C%97%E4%BA%AC%E5%B8%82%E6%B5%B7%E6%B7%E5%A4%96%E5%9B%BD%E8%AF+%E5%AE%9E%E9%AA%8C%E5+%A6%E6%A0%A1%EF%BC%8C2013-03-21&rft.genre=unknown&rft.pub=Bjfles.com&rft_id=http%3A%2F%2Fwww.bjfles.com%2FItem%2F3567.aspx&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-146">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-146">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.ifeng.com/mainland/detail_2012_08/25/17090984_0.shtml" rel="nofollow">
故宫安保设施已14年没有升级
</a>
. 凤凰网. 2012-08-25
<span class="reference-accessdate">
[
<span class="nowrap">
2015-11-14
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20151117040323/http://news.ifeng.com/mainland/detail_2012_08/25/17090984_0.shtml" rel="nofollow">
存档
</a>
于2015-11-17).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E6%95%85%E5%AE%AB%E5%AE%89%E4%BF%9D%E8%AE%BE%E6%96%BD%E5%B7%B214%E5%B9%B4%E6%B2%A1%E6%9C%89%E5%87%E7%BA%A7&rft.date=2012-08-25&rft.genre=unknown&rft.pub=%E5%87%A4%E5%87%B0%E7%BD%91&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fmainland%2Fdetail_2012_08%2F25%2F17090984_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-147">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-147">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
2015年04月25日 15:09:14.
<a class="external text" href="http://news.xinhuanet.com/local/2015-04/25/c_1115088357.htm" rel="nofollow">
中国聚焦:中国阔步走进“博物馆时代”,新华网,2015-04-25
</a>
. News.xinhuanet.com.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-05-23
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20150820213454/http://news.xinhuanet.com/local/2015-04/25/c_1115088357.htm" rel="nofollow">
存档
</a>
于2015-08-20).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=2015%E5%B9%B404%E6%9C%8825%E6%97%A5+15%3A09%3A14&rft.btitle=%E4%B8+%E5%9B%BD%E8%81%9A%E7%84%A6%EF%BC%9A%E4%B8+%E5%9B%BD%E9%98%94%E6+%A5%E8%B5%B0%E8%BF%9B%9C%E5%9A%E7%89%A9%E9%A6%86%E6%97%B6%E4%BB%A3%9D%EF%BC%8C%E6%96%B0%E5%8E%E7%BD%91%EF%BC%8C2015-04-25&rft.genre=unknown&rft.pub=News.xinhuanet.com&rft_id=http%3A%2F%2Fnews.xinhuanet.com%2Flocal%2F2015-04%2F25%2Fc_1115088357.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-148">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-148">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
歐陽甫中. 北京菜. 2007.
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.au=%E6+%90%E9%99%BD%E7%94%AB%E4%B8+&rft.btitle=%E5%8C%97%E4%BA%AC%E8%8F%9C&rft.date=2007&rft.genre=book&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-149">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-149">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://news.ifeng.com/gundong/detail_2014_03/26/35137478_0.shtml" rel="nofollow">
在云南啖尽异域情调
</a>
. 云南信息报. 2014-03-26
<span class="reference-accessdate">
[
<span class="nowrap">
2017-09-16
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170916225255/http://news.ifeng.com/gundong/detail_2014_03/26/35137478_0.shtml" rel="nofollow">
存档
</a>
于2017-09-16).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%9C%A8%E4%BA%91%E5%97%E5%95%96%E5%B0%BD%E5%BC%82%E5%9F%9F%E6%83%85%E8%B0%83&rft.date=2014-03-26&rft.genre=unknown&rft.pub=%E4%BA%91%E5%97%E4%BF%A1%E6%81%AF%E6%8A%A5&rft_id=http%3A%2F%2Fnews.ifeng.com%2Fgundong%2Fdetail_2014_03%2F26%2F35137478_0.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-150">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-150">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20100819100056/http://www.ccmedu.com/bbs55_40092.html" rel="nofollow">
北京文艺演出业现状及未来发展
</a>
. 北京文艺发展论坛.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (
<a class="external text" href="http://www.ccmedu.com/bbs55_40092.html" rel="nofollow">
原始内容
</a>
存档于2010-08-19).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%96%87%E8%89%BA%E6%BC%94%E5%87%BA%E4%B8%9A%E7%8E%B0%E7%8A%B6%E5%8F%8A%E6%9C%AA%E6%9D%A5%E5%8F%91%E5%B1%95&rft.genre=unknown&rft.pub=%E5%8C%97%E4%BA%AC%E6%96%87%E8%89%BA%E5%8F%91%E5%B1%95%E8%AE%BA%E5%9D%9B&rft_id=http%3A%2F%2Fwww.ccmedu.com%2Fbbs55_40092.html&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-151">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-151">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://ent.sina.com.cn/y/2008-04-28/16072006820.shtml" rel="nofollow">
北京国际音乐节简介
</a>
. 新浪网.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20111011002322/http://ent.sina.com.cn/y/2008-04-28/16072006820.shtml" rel="nofollow">
存档
</a>
于2011-10-11).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E5%9B%BD%E9%99%85%E9%9F%B3%E4%B9%90%E8%8A%82%E7%AE%E4%BB&rft.genre=unknown&rft.pub=%E6%96%B0%E6%B5%AA%E7%BD%91&rft_id=http%3A%2F%2Fent.sina.com.cn%2Fy%2F2008-04-28%2F16072006820.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-152">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-152">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://art.china.cn/tslz/2009-11/23/content_3257433.htm" rel="nofollow">
北京演出市场上的三大盛宴
</a>
. 艺术中国.
<span class="reference-accessdate">
[
<span class="nowrap">
2011-08-29
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20140428023819/http://art.china.cn/tslz/2009-11/23/content_3257433.htm" rel="nofollow">
存档
</a>
于2014-04-28).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E6%BC%94%E5%87%BA%E5%B8%82%E5%9C%BA%E4%B8%8A%E7%9A%84%E4%B8%89%E5%A4%A7%E7%9B%9B%E5%AE%B4&rft.genre=unknown&rft.pub=%E8%89%BA%E6%9C%AF%E4%B8+%E5%9B%BD&rft_id=http%3A%2F%2Fart.china.cn%2Ftslz%2F2009-11%2F23%2Fcontent_3257433.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-153">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-153">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.china.com.cn/sports/zhuanti/2008ay/2008-07/11/content_15993221.htm" rel="nofollow">
北京的宗教文化
</a>
. 中国网. 2008-07-11
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-16
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170416200611/http://www.china.com.cn/sports/zhuanti/2008ay/2008-07/11/content_15993221.htm" rel="nofollow">
存档
</a>
于2017-04-16).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E5%AE%97%E6%95%99%E6%96%87%E5%8C%96&rft.date=2008-07-11&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%9B%BD%E7%BD%91&rft_id=http%3A%2F%2Fwww.china.com.cn%2Fsports%2Fzhuanti%2F2008ay%2F2008-07%2F11%2Fcontent_15993221.htm&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-154">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-154">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20170118032854/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/dj/index.shtml" rel="nofollow">
中国道教概述
</a>
. 北京的民族与宗教. 北京市民族事务委员会.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-16
</span>
]
</span>
. (
<a class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/dj/index.shtml" rel="nofollow">
原始内容
</a>
存档于2017-01-18).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B8+%E5%9B%BD%E9%81%93%E6%95%99%E6%A6%82%E8%BF%B0&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Fdj%2Findex.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-155">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-155">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20170118032433/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/fj/index.shtml" rel="nofollow">
中国佛教概述
</a>
. 北京的民族与宗教. 北京市民族事务委员会.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-16
</span>
]
</span>
. (
<a class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/fj/index.shtml#" rel="nofollow">
原始内容
</a>
存档于2017-01-18).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%B8+%E5%9B%BD%E4%BD%9B%E6%95%99%E6%A6%82%E8%BF%B0&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Ffj%2Findex.shtml%23&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-156">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-156">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20170118032533/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/tzj/index.shtml" rel="nofollow">
北京市天主教爱国会
</a>
. 北京的民族与宗教. 北京市民族事务委员会.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-16
</span>
]
</span>
. (
<a class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/tzj/index.shtml#" rel="nofollow">
原始内容
</a>
存档于2017-01-18).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A4%A9%E4%B8%BB%E6%95%99%E7%88%B1%E5%9B%BD%E4%BC%9A&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Ftzj%2Findex.shtml%23&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-157">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-157">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="https://web.archive.org/web/20170130005328/http://www.bjethnic.gov.cn/zongjiao/zjzhjs/yslj/index.shtml" rel="nofollow">
伊斯兰教简介
</a>
. 北京的民族与宗教. 北京市民族事务委员会.
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-16
</span>
]
</span>
. (
<a class="external text" href="http://www.bjethnic.gov.cn/zongjiao/zjzhjs/yslj/index.shtml#" rel="nofollow">
原始内容
</a>
存档于2017-01-30).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E4%BC%8A%E6%96%AF%E5%85%B0%E6%95%99%E7%AE%E4%BB&rft.genre=unknown&rft.jtitle=%E5%8C%97%E4%BA%AC%E7%9A%84%E6%B0%91%E6%97%8F%E4%B8%8E%E5%AE%97%E6%95%99&rft_id=http%3A%2F%2Fwww.bjethnic.gov.cn%2Fzongjiao%2Fzjzhjs%2Fyslj%2Findex.shtml%23&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-158">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-158">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation web">
<a class="external text" href="http://www.chinanews.com/ty/2015/07-31/7440932.shtml" rel="nofollow">
北京赢得2022年冬季奥运会举办权
</a>
. 中国新闻网. 2015-07-31
<span class="reference-accessdate">
[
<span class="nowrap">
2017-08-19
</span>
]
</span>
. (原始内容
<a class="external text" href="https://web.archive.org/web/20170819190042/http://www.chinanews.com/ty/2015/07-31/7440932.shtml" rel="nofollow">
存档
</a>
于2017-08-19).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=%E5%8C%97%E4%BA%AC%E8%B5%A2%E5%BE%972022%E5%B9%B4%E5%86%AC%E5+%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BE%E5%8A%9E%E6%9D%83&rft.date=2015-07-31&rft.genre=unknown&rft.jtitle=%E4%B8+%E5%9B%BD%E6%96%B0%E9%97%BB%E7%BD%91&rft_id=http%3A%2F%2Fwww.chinanews.com%2Fty%2F2015%2F07-31%2F7440932.shtml&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal">
<span style="display:none;">
</span>
</span>
</span>
</li>
<li id="cite_note-159">
<span class="mw-cite-backlink">
<b>
<a href="#cite_ref-159">
^
</a>
</b>
</span>
<span class="reference-text">
<cite class="citation book">
15-11 北京市市级友好城市.
<a class="external text" href="https://web.archive.org/web/20170805145351/http://www.bjstats.gov.cn/nj/main/2016-tjnj/zk/html/CH15-11.xls" rel="nofollow">
北京统计年鉴2016
</a>
. 北京市统计局 (中国统计出版社).
<span class="reference-accessdate">
[
<span class="nowrap">
2017-01-15
</span>
]
</span>
. (
<a class="external text" href="http://www.bjstats.gov.cn/nj/main/2016-tjnj/zk/html/CH15-11.xls" rel="nofollow">
原始内容
</a>
存档于2017-08-05).
</cite>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fzh.wikipedia.org%3A%E5%8C%97%E4%BA%AC%E5%B8%82&rft.atitle=15-11+%E5%8C%97%E4%BA%AC%E5%B8%82%E5%B8%82%E7%BA%A7%E5%8F%E5%A5%BD%E5%9F%8E%E5%B8%82&rft.btitle=%E5%8C%97%E4%BA%AC%E7%BB%9F%E8%AE%A1%E5%B9%B4%E9%89%B42016&rft.genre=bookitem&rft.pub=%E4%B8+%E5%9B%BD%E7%BB%9F%E8%AE%A1%E5%87%BA%E7%89%88%E7%A4%BE&rft_id=http%3A%2F%2Fwww.bjstats.gov.cn%2Fnj%2Fmain%2F2016-tjnj%2Fzk%2Fhtml%2FCH15-11.xls&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook">
<span style="display:none;">
</span>
</span>
</span>
</li>
</ol>
</div>
<h2>
<span id=".E5.A4.96.E9.83.A8.E9.93.BE.E6.8E.A5">
</span>
<span class="mw-headline" id="外部链接">
外部链接
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=37" title="编辑章节:外部链接">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<table class="mbox-small plainlinks sistersitebox" style="border:1px solid #aaa;background-color:#f9f9f9;font-size:small;">
<tbody>
<tr>
<td class="mbox-image">
<img alt="" class="noviewer" data-file-height="1376" data-file-width="1024" decoding="async" height="40" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/30px-Commons-logo.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/45px-Commons-logo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/59px-Commons-logo.svg.png 2x" width="30"/>
</td>
<td class="mbox-text plainlist">
<a href="/wiki/%E7%BB%B4%E5%9F%BA%E5%85%B1%E4%BA%AB%E8%B5%84%E6%BA%90" title="维基共享资源">
维基共享资源
</a>
中相關的多媒體資源:
<b>
<a class="external text" href="https://commons.wikimedia.org/wiki/%E5%8C%97%E4%BA%AC?uselang=zh">
北京市
</a>
</b>
(
<a class="external text" href="https://commons.wikimedia.org/wiki/Category:Beijing?uselang=zh">
分類
</a>
)
</td>
</tr>
</tbody>
</table>
<dl>
<dt>
概况
</dt>
</dl>
<ul>
<li>
《
<a href="/wiki/%E4%B8%96%E7%95%8C%E6%A6%82%E5%86%B5" title="世界概况">
世界概况
</a>
》上有关
<a class="external text" href="https://www.cia.gov/library/publications/the-world-factbook/geos/ch.html" rel="nofollow">
Beijing
</a>
的条目
</li>
</ul>
<dl>
<dt>
官方
</dt>
</dl>
<ul>
<li>
<a class="external text" href="http://www.beijing.gov.cn/" rel="nofollow">
北京市人民政府网站
</a>
<a class="external text" href="//web.archive.org/web/19981212023138/http://www.beijing.gov.cn/" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
<span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">
(简体中文)
</span>
<span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到中文网页">
(繁體中文)
</span>
<span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英語网页">
(英文)
</span>
</li>
</ul>
<dl>
<dt>
旅遊
</dt>
</dl>
<ul>
<li>
<a class="external text" href="https://web.archive.org/web/20031229210524/http://www.bjta.gov.cn/" rel="nofollow">
北京市旅游局
</a>
</li>
<li>
<a class="external text" href="http://whlyj.beijing.gov.cn/" rel="nofollow">
北京市文化和旅游局
</a>
<a class="external text" href="//web.archive.org/web/20200528032942/http://whlyj.beijing.gov.cn/" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
</li>
<li>
<a class="external text" href="https://web.archive.org/web/20140818220225/http://www.mychinatours.com/beijing-travel/" rel="nofollow">
北京市旅游指南
</a>
<span style="font-family: sans-serif; cursor: default; color:#54595d; font-size: 0.8em; bottom: 0.1em; font-weight: bold;" title="连接到英語网页">
(英文)
</span>
</li>
<li>
<a class="external text" href="http://www.visitbeijing.com.cn/" rel="nofollow">
北京旅游信息网
</a>
<a class="external text" href="//web.archive.org/web/20080911065100/http://www.visitbeijing.com.cn/" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
</li>
<li>
<img alt="" class="noviewer" data-file-height="193" data-file-width="193" decoding="async" height="16" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Wikivoyage-Logo-v3-icon.svg/16px-Wikivoyage-Logo-v3-icon.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Wikivoyage-Logo-v3-icon.svg/24px-Wikivoyage-Logo-v3-icon.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Wikivoyage-Logo-v3-icon.svg/32px-Wikivoyage-Logo-v3-icon.svg.png 2x" width="16"/>
<a href="/wiki/%E7%BB%B4%E5%9F%BA%E5%AF%BC%E6%B8%B8" title="维基导游">
维基导游
</a>
中有關
<a class="extiw" href="https://zh.wikivoyage.org/wiki/%E5%8C%97%E4%BA%AC" title="voy:北京">
北京
</a>
的旅遊指南
</li>
</ul>
<dl>
<dt>
地图
</dt>
</dl>
<ul>
<li>
<a class="external text" href="https://www.google.com/maps/place/Beijing" rel="nofollow">
Google地图 - 北京市
</a>
</li>
<li>
<a class="external text" href="https://web.archive.org/web/20200326073940/http://xzqh.info/lt/attachment/Mon_1704/25_171465_eb85a3f10f138fd.jpg" rel="nofollow">
北京市全境行政区划与地形图
</a>
</li>
</ul>
<dl>
<dt>
照片
</dt>
</dl>
<ul>
<li>
Flickr -
<a class="external text" href="http://www.flickr.com/photos/tags/beijing/clusters/" rel="nofollow">
标签为北京的照片
</a>
<a class="external text" href="//web.archive.org/web/20090218161610/http://www.flickr.com/photos/tags/beijing/clusters/" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
</li>
<li>
Flickr -
<a class="external text" href="http://www.flickr.com/groups/beijing/" rel="nofollow">
北京群组
</a>
<a class="external text" href="//web.archive.org/web/20090113164416/http://www.flickr.com/groups/beijing/" rel="nofollow">
页面存档备份
</a>
,存于
<a href="/wiki/%E4%BA%92%E8%81%94%E7%BD%91%E6%A1%A3%E6%A1%88%E9%A6%86" title="互联网档案馆">
互联网档案馆
</a>
</li>
<li>
Pinterest -
<a class="external text" href="https://www.pinterest.com/search/pins/?q=beijing%20travel&term_meta%5B%5D=beijing%7Ctyped&term_meta%5B%5D=travel%7Ctyped" rel="nofollow">
北京旅游照片
</a>
</li>
<li>
<a class="external text" href="https://web.archive.org/web/20180705180525/https://qnachina.com/23923" rel="nofollow">
圖集 / 再也回不去的老北京
</a>
</li>
</ul>
<h2>
<span id=".E5.8F.82.E8.A7.81">
</span>
<span class="mw-headline" id="参见">
参见
</span>
<span class="mw-editsection">
<span class="mw-editsection-bracket">
[
</span>
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit&section=38" title="编辑章节:参见">
编辑
</a>
<span class="mw-editsection-bracket">
]
</span>
</span>
</h2>
<div aria-label="Portals" class="noprint portal plainlist tright" role="navigation" style="margin:0.5em 0 0.5em 1em;border:solid #aaa 1px">
<ul style="display:table;box-sizing:border-box;padding:0.1em;max-width:175px;background:#f9f9f9;font-size:85%;line-height:110%;font-weight:bold">
<li style="display:table-row">
<span style="display:table-cell;padding:0.2em;vertical-align:middle;text-align:center">
<a class="image" href="/wiki/File:China_dragon.svg">
<img alt="icon" class="noviewer" data-file-height="496" data-file-width="744" decoding="async" height="21" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b0/China_dragon.svg/32px-China_dragon.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b0/China_dragon.svg/48px-China_dragon.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b0/China_dragon.svg/64px-China_dragon.svg.png 2x" width="32"/>
</a>
</span>
<span style="display:table-cell;padding:0.2em 0.2em 0.2em 0.3em;vertical-align:middle">
<a href="/wiki/Portal:%E4%B8%AD%E5%9B%BD" title="Portal:中国">
中国主题
</a>
</span>
</li>
<li style="display:table-row">
<span style="display:table-cell;padding:0.2em;vertical-align:middle;text-align:center">
<img alt="flag" class="noviewer thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="21" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/32px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/48px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/64px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="32"/>
</span>
<span style="display:table-cell;padding:0.2em 0.2em 0.2em 0.3em;vertical-align:middle">
<a href="/wiki/Portal:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="Portal:中华人民共和国">
中华人民共和国主题
</a>
</span>
</li>
<li style="display:table-row">
<span style="display:table-cell;padding:0.2em;vertical-align:middle;text-align:center">
<a class="image" href="/wiki/File:Beijing-name.svg">
<img alt="icon" class="noviewer" data-file-height="174" data-file-width="327" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Beijing-name.svg/32px-Beijing-name.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Beijing-name.svg/48px-Beijing-name.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/20/Beijing-name.svg/64px-Beijing-name.svg.png 2x" width="32"/>
</a>
</span>
<span style="display:table-cell;padding:0.2em 0.2em 0.2em 0.3em;vertical-align:middle">
<a href="/wiki/Portal:%E5%8C%97%E4%BA%AC" title="Portal:北京">
北京主题
</a>
</span>
</li>
</ul>
</div>
<ul>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2" title="北京历史">
北京历史
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E8%A9%B1" title="北京話">
北京話
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E5%B9%B3" title="北平">
北平
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E4%BA%AC%E5%89%A7%E5%90%8D%E5%AE%B6%E5%90%8D%E6%AE%B5%E5%88%97%E8%A1%A8" title="京剧名家名段列表">
京剧名家名段列表
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E8%87%AA%E7%84%B6%E4%BF%9D%E6%8A%A4%E5%8C%BA%E5%88%97%E8%A1%A8" title="北京自然保护区列表">
北京自然保护区列表
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E6%96%B0%E9%97%BB%E5%AA%92%E4%BD%93%E5%88%97%E8%A1%A8" title="北京新闻媒体列表">
北京新闻媒体列表
</a>
(包括报社、出版社、媒体等)
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8C%BB%E7%96%97%E6%9C%BA%E6%9E%84%E5%88%97%E8%A1%A8" title="北京市医疗机构列表">
北京市医疗机构列表
</a>
</li>
<li>
<a class="mw-disambig" href="/wiki/%E5%8C%97%E4%BA%AC%E4%BA%BA" title="北京人">
北京人
</a>
(
<a href="/wiki/Category:%E5%8C%97%E4%BA%AC%E4%BA%BA" title="Category:北京人">
分类
</a>
)
</li>
<li>
<a href="/wiki/%E5%B0%8F%E8%A1%8C%E6%98%9F2045" title="小行星2045">
小行星2045
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AC%E4%BA%A4300%E8%B7%AF" title="北京公交300路">
北京市300路公共汽车
</a>
</li>
</ul>
<div style="clear: both; height: 1em">
</div>
<table class="navbox" style="text-align: center; width:80%; font-size:80%; margin:0.5em auto">
<caption>
</caption>
<tbody>
<tr>
<td rowspan="5" style="width:0%; padding-right:5px">
<div class="center">
<div class="floatnone">
<img alt="" data-file-height="512" data-file-width="512" decoding="async" height="50" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/50px-Compass_rose_pale.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/75px-Compass_rose_pale.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/100px-Compass_rose_pale.svg.png 2x" width="50"/>
</div>
</div>
</td>
<td style="width:33%">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北省
</a>
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">
张家口市
</a>
<a href="/wiki/%E8%B5%A4%E5%9F%8E%E5%8E%BF" title="赤城县">
赤城县
</a>
</td>
<td style="width:33%">
河北省
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">
承德市
</a>
<a href="/wiki/%E4%B8%B0%E5%AE%81%E6%BB%A1%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8E%BF" title="丰宁满族自治县">
丰宁满族自治县
</a>
<br/>
</td>
<td style="width:33%">
河北省承德市
<a href="/wiki/%E5%85%B4%E9%9A%86%E5%8E%BF" title="兴隆县">
兴隆县
</a>
、
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%8E%BF" title="承德县">
承德县
</a>
、
<a href="/wiki/%E6%BB%A6%E5%B9%B3%E5%8E%BF" title="滦平县">
滦平县
</a>
</td>
<td rowspan="5" style="width:0%; padding-left:5px">
<img alt="" data-file-height="512" data-file-width="512" decoding="async" height="50" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/50px-Compass_rose_pale.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/75px-Compass_rose_pale.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Compass_rose_pale.svg/100px-Compass_rose_pale.svg.png 2x" width="50"/>
</td>
</tr>
<tr>
<td rowspan="3" style="width:33%">
河北省张家口市
<a href="/wiki/%E6%B6%BF%E9%B9%BF%E5%8E%BF" title="涿鹿县">
涿鹿县
</a>
、
<a href="/wiki/%E6%80%80%E6%9D%A5%E5%8E%BF" title="怀来县">
怀来县
</a>
</td>
<td style="width:33%">
<img alt="" data-file-height="17" data-file-width="17" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/44/North.svg/17px-North.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/44/North.svg/26px-North.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/44/North.svg/34px-North.svg.png 2x" title="北" width="17"/>
</td>
<td rowspan="3" style="width:33%">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
<a href="/wiki/%E8%93%9F%E5%B7%9E%E5%8C%BA" title="蓟州区">
蓟州区
</a>
;
<br/>
河北省
<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">
廊坊市
</a>
<a href="/wiki/%E9%A6%99%E6%B2%B3%E5%8E%BF" title="香河县">
香河县
</a>
、
<a href="/wiki/%E5%A4%A7%E5%8E%82%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8E%BF" title="大厂回族自治县">
大厂回族自治县
</a>
、
<a href="/wiki/%E4%B8%89%E6%B2%B3%E5%B8%82" title="三河市">
三河市
</a>
</td>
</tr>
<tr>
<td style="width:33%">
<table style="width:100%">
<tbody>
<tr>
<td style="width:50%; text-align:right">
<div class="floatright">
<img alt="" data-file-height="17" data-file-width="17" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f0/West.svg/17px-West.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f0/West.svg/26px-West.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f0/West.svg/34px-West.svg.png 2x" title="西" width="17"/>
</div>
</td>
<td nowrap="nowrap" style="width:0%; text-align: center">
<b>
北京市
</b>
</td>
<td style="width:50%; text-align:left">
<div class="floatleft">
<img alt="" data-file-height="17" data-file-width="17" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Boxed_East_arrow.svg/17px-Boxed_East_arrow.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Boxed_East_arrow.svg/26px-Boxed_East_arrow.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5d/Boxed_East_arrow.svg/34px-Boxed_East_arrow.svg.png 2x" title="東" width="17"/>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
<tr>
<td style="width:33%">
<img alt="" data-file-height="17" data-file-width="17" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/South.svg/17px-South.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/cd/South.svg/26px-South.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/cd/South.svg/34px-South.svg.png 2x" title="南" width="17"/>
</td>
</tr>
<tr>
<td style="width:33%">
河北省
<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">
保定市
</a>
<a href="/wiki/%E6%B6%9E%E6%B0%B4%E5%8E%BF" title="涞水县">
涞水县
</a>
、
<a href="/wiki/%E6%B6%BF%E5%B7%9E%E5%B8%82" title="涿州市">
涿州市
</a>
</td>
<td style="width:33%">
河北省廊坊市
<a href="/wiki/%E5%B9%BF%E9%98%B3%E5%8C%BA" title="广阳区">
广阳区
</a>
、
<a href="/wiki/%E5%9B%BA%E5%AE%89%E5%8E%BF" title="固安县">
固安县
</a>
、
<a href="/wiki/%E6%B0%B8%E6%B8%85%E5%8E%BF" title="永清县">
永清县
</a>
<br/>
</td>
<td style="width:33%">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
<a href="/wiki/%E6%AD%A6%E6%B8%85%E5%8C%BA" title="武清区">
武清区
</a>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<span style="float:left;width:8em;font-size:80%;margin-right:0.5em">
</span>
<div style="font-size:110%">
北京相关导航模板
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px;padding:0px;font-size:111%;">
<div style="padding:0px;">
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E8%80%81%E5%8C%97%E4%BA%AC%E5%9F%8E" title="Template:老北京城">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E8%80%81%E5%8C%97%E4%BA%AC%E5%9F%8E" title="Template talk:老北京城">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E8%80%81%E5%8C%97%E4%BA%AC%E5%9F%8E&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a class="mw-selflink selflink">
老北京地名与历史文化主题
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
<a href="/wiki/Portal:%E5%8C%97%E4%BA%AC" title="Portal:北京">
北京主题页
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
規劃
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E8%BD%B4%E7%BA%BF" title="北京中轴线">
北京中軸綫
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%98%8E%E6%B8%85%E5%8C%97%E4%BA%AC%E5%9F%8E" title="明清北京城">
北京城池
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E5%A2%99" title="北京城墙">
北京城牆
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%9F%8E%E9%97%A8" title="北京城门">
北京城門
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%9A%87%E5%9F%8E" title="北京皇城">
北京皇城
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%B8%85%E4%BB%A3%E7%8E%8B%E5%BA%9C" title="北京清代王府">
北京王府
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%83%A1%E5%90%8C%E5%88%97%E8%A1%A8" title="北京胡同列表">
北京胡同
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%89%8C%E6%A5%BC&action=edit&redlink=1" title="北京牌楼(页面不存在)">
北京牌樓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%9B%9B%E5%90%88%E9%99%A2" title="四合院">
四合院
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8E%86%E5%8F%B2" title="北京历史">
<span style="color:#00008B;">
歷史
</span>
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
县级:
<a href="/wiki/%E8%93%9F%E5%8E%BF_(%E7%87%95%E5%9B%BD)" title="蓟县 (燕国)">
薊縣(古代)
</a>
(
<a href="/wiki/%E8%93%9F%E5%9F%8E" title="蓟城">
薊城
</a>
)
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%93%9F%E5%9F%8E" title="蓟城">
薊北縣
</a>
</span>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E6%9E%90%E6%B4%A5" title="析津">
析津县
</a>
</span>
<span class="nowrap">
→
<a class="mw-disambig" href="/wiki/%E5%A4%A7%E5%85%B4%E5%8E%BF" title="大兴县">
大兴县
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E7%87%95%E9%83%BD" title="燕都">
燕都县
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%B9%BD%E9%83%BD%E5%8E%BF" title="幽都县">
幽都县
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%AE%9B%E5%B9%B3%E7%B8%A3" title="宛平縣">
宛平县
</a>
<br/>
郡州路府市级:
<a href="/wiki/%E7%87%95%E5%9B%BD" title="燕国">
燕国
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%87%95%E5%9B%BD_(%E6%A5%9A%E6%B1%89%E6%88%98%E4%BA%89)" title="燕国 (楚汉战争)">
燕国 (楚汉战争)
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E9%98%B3%E9%83%A1" title="广阳郡">
广阳郡
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%B9%BD%E5%B7%9E_(%E5%8D%81%E5%85%AD%E5%9B%BD)" title="幽州 (十六国)">
幽州
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E7%87%95%E4%BA%AC" title="燕京">
燕京
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%BE%BD%E5%8D%97%E4%BA%AC" title="辽南京">
辽南京
</a>
(
<a href="/wiki/%E5%8D%97%E4%BA%AC%E9%81%93" title="南京道">
南京道
</a>
<a href="/wiki/%E6%9E%90%E6%B4%A5%E5%BA%9C" title="析津府">
析津府
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">
金中都
</a>
(
<a href="/wiki/%E4%B8%AD%E9%83%BD%E8%B7%AF" title="中都路">
中都路
</a>
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%BA%9C" title="大兴府">
大兴府
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E5%85%83%E5%A4%A7%E9%83%BD" title="元大都">
元大都
</a>
(
<a href="/wiki/%E5%A4%A7%E9%83%BD%E8%B7%AF" title="大都路">
大都路
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%BA%9C" title="北平府">
北平府
</a>
(
<a class="mw-redirect" href="/wiki/%E5%8C%97%E5%B9%B3" title="北平">
北平
</a>
) ·
</span>
<span class="nowrap">
<a class="mw-redirect mw-disambig" href="/wiki/%E4%BA%AC%E5%B8%88" title="京师">
京师
</a>
<a href="/wiki/%E9%A0%86%E5%A4%A9%E5%BA%9C" title="順天府">
順天府
</a>
(北京) ·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
京兆地方
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">
北平市
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
傳統
<br/>
藝術
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E6%98%86%E6%9B%B2" title="昆曲">
昆曲
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%AC%E5%89%A7" title="京剧">
京剧
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%A9%95%E5%8A%87" title="評劇">
評劇
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E6%A2%86%E5%AD%90" title="河北梆子">
河北梆子
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%AC%E9%9F%B5%E5%A4%A7%E9%BC%93" title="京韵大鼓">
京韻大鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E6%B2%B3%E5%A4%A7%E9%BC%93" title="西河大鼓">
西河大鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%A2%85%E8%8A%B1%E5%A4%A7%E9%BC%93" title="梅花大鼓">
梅花大鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%AC%E4%B8%9C%E5%A4%A7%E9%BC%93" title="京东大鼓">
京东大鼓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%90%AB%E7%81%AF%E5%A4%A7%E9%BC%93&action=edit&redlink=1" title="含灯大鼓(页面不存在)">
含灯大鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%BB%91%E7%A8%BD%E5%A4%A7%E9%BC%93" title="滑稽大鼓">
滑稽大鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%94%E9%9F%B3%E5%A4%A7%E9%BC%93" title="五音大鼓">
五音大鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%90%B4%E4%B9%A6" title="北京琴书">
北京琴書
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E8%A9%95%E6%9B%B8&action=edit&redlink=1" title="北京評書(页面不存在)">
北京評書
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E7%9B%B8%E8%81%B2" title="相聲">
相聲
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8F%8C%E7%B0%A7" title="双簧">
雙簧
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%85%AB%E8%A7%92%E9%BC%93" title="八角鼓">
八角鼓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%95%E5%BC%A6" title="单弦">
單弦
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BF%AB%E6%9D%BF%E4%B9%A6" title="快板书">
快板書
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%95%B0%E6%9D%A5%E5%AE%9D" title="数来宝">
數來寶
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%99%BA%E5%8C%96%E5%AF%BA" title="智化寺">
智化寺京音樂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%99%AF%E6%B3%B0%E8%97%8D" title="景泰藍">
景泰藍
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%B1%A1%E7%89%99%E9%9B%95%E5%88%BB&action=edit&redlink=1" title="象牙雕刻(页面不存在)">
象牙雕刻
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9B%95%E6%BC%86" title="雕漆">
雕漆
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%96%99%E5%99%A8&action=edit&redlink=1" title="料器(页面不存在)">
料器
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%AC%E7%B9%A1" title="京繡">
京綉
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%90%89%E7%92%83" title="琉璃">
琉璃
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%8A%B1%E4%B8%9D%E9%95%B6%E5%B5%8C&action=edit&redlink=1" title="花丝镶嵌(页面不存在)">
花丝镶嵌
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%87%91%E6%BC%86%E9%95%B6%E5%B5%8C&action=edit&redlink=1" title="金漆镶嵌(页面不存在)">
金漆镶嵌
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%A2%A8%E7%AE%8F%E5%93%88&action=edit&redlink=1" title="風箏哈(页面不存在)">
風箏哈
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%AC%83%E4%BA%BA" title="鬃人">
鬃人
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%AF%9B%E7%8C%B4&action=edit&redlink=1" title="毛猴(页面不存在)">
毛猴
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%BC%BB%E7%85%99%E5%A3%BA" title="鼻煙壺">
内畫鼻煙壺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%81%9A%E5%85%83%E5%8F%B7" title="聚元号">
聚元号
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E4%BA%AC%E4%BD%9C%E7%A1%AC%E6%9C%A8%E5%AE%B6%E5%85%B7&action=edit&redlink=1" title="京作硬木家具(页面不存在)">
京作硬木家具
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%87%88%E5%BD%A9&action=edit&redlink=1" title="北京燈彩(页面不存在)">
北京燈彩
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%8E%89%E9%9B%95&action=edit&redlink=1" title="北京玉雕(页面不存在)">
北京玉雕
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%AE%AB%E6%AF%AF&action=edit&redlink=1" title="宫毯(页面不存在)">
宫毯
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A9%E6%A1%A5" title="北京天桥">
天橋
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E6%A1%A5%E5%85%AB%E6%80%AA" title="天桥八怪">
天橋八怪
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%B3%96%E4%BA%BA" title="糖人">
吹糖人
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%9D%A2%E4%BA%BA%E9%83%8E&action=edit&redlink=1" title="面人郎(页面不存在)">
面人郎
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%8B%89%E6%B4%8B%E7%89%87" title="拉洋片">
拉洋片
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%B3%BD%E6%B4%BB%E9%A9%A2&action=edit&redlink=1" title="賽活驢(页面不存在)">
賽活驢
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%8A%80%E6%A7%8D%E5%88%BA%E5%96%89&action=edit&redlink=1" title="銀槍刺喉(页面不存在)">
銀槍刺喉
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%8B%89%E7%A1%AC%E5%BC%93&action=edit&redlink=1" title="拉硬弓(页面不存在)">
拉硬弓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E6%A9%8B%E6%91%94%E8%B7%A4&action=edit&redlink=1" title="天橋摔跤(页面不存在)">
天橋摔跤
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8F%A4%E5%BD%A9%E6%88%B2%E6%B3%95&action=edit&redlink=1" title="古彩戲法(页面不存在)">
古彩戲法
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9B%9C%E6%8A%80" title="雜技">
雜技
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8F%A3%E6%8A%80" title="口技">
口技
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E4%B8%AD%E5%B9%A1&action=edit&redlink=1" title="中幡(页面不存在)">
中幡
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A7%E5%8A%9B%E4%B8%B8&action=edit&redlink=1" title="大力丸(页面不存在)">
大力丸
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E8%80%81%E5%AD%97%E5%8F%B7" title="北京老字号">
<span style="color:#00008B;">
老字號
</span>
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%B6%B4%E5%B9%B4%E5%A0%82&action=edit&redlink=1" title="鶴年堂(页面不存在)">
鶴年堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%90%8C%E4%BB%81%E5%A0%82" title="同仁堂">
同仁堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%95%B7%E6%98%A5%E5%A0%82&action=edit&redlink=1" title="長春堂(页面不存在)">
長春堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%BE%B7%E5%A3%BD%E5%A0%82&action=edit&redlink=1" title="德壽堂(页面不存在)">
德壽堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%A8%BB%E9%A6%99%E6%9D%91" title="北京稻香村">
稻香村
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%A8%BB%E9%A6%99%E6%98%A5" title="稻香春">
稻香春
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%85%A7%E8%81%AF%E9%99%9E" title="內聯陞">
內聯陞
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%A6%AC%E8%81%9A%E6%BA%90&action=edit&redlink=1" title="馬聚源(页面不存在)">
馬聚源
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%9B%9B%E9%8C%AB%E7%A6%8F" title="盛錫福">
盛錫福
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%90%8C%E9%99%9E%E5%92%8C&action=edit&redlink=1" title="同陞和(页面不存在)">
同陞和
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%AD%A5%E7%80%9B%E9%BD%8B&action=edit&redlink=1" title="步瀛齋(页面不存在)">
步瀛齋
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%80%9A%E4%B8%89%E7%9B%8A&action=edit&redlink=1" title="通三益(页面不存在)">
通三益
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%8E%8B%E9%BA%BB%E5%AD%90" title="王麻子">
王麻子
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%85%AB%E5%A4%A7%E7%A5%A5&action=edit&redlink=1" title="八大祥(页面不存在)">
八大祥
</a>
(
<a href="/wiki/%E7%91%9E%E8%9A%A8%E7%A5%A5" title="瑞蚨祥">
瑞蚨祥
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%91%9E%E7%94%9F%E7%A5%A5&action=edit&redlink=1" title="瑞生祥(页面不存在)">
瑞生祥
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%91%9E%E5%A2%9E%E7%A5%A5&action=edit&redlink=1" title="瑞增祥(页面不存在)">
瑞增祥
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%91%9E%E6%9E%97%E7%A5%A5&action=edit&redlink=1" title="瑞林祥(页面不存在)">
瑞林祥
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%9B%8A%E5%92%8C%E7%A5%A5&action=edit&redlink=1" title="益和祥(页面不存在)">
益和祥
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%BB%A3%E7%9B%9B%E7%A5%A5&action=edit&redlink=1" title="廣盛祥(页面不存在)">
廣盛祥
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%A5%A5%E7%BE%A9%E8%99%9F" title="祥義號">
祥義號
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%AC%99%E7%A5%A5%E7%9B%8A" title="謙祥益">
謙祥益
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%80%E5%BE%97%E9%98%81" title="一得阁">
一得閣
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%8D%A3%E5%AE%9D%E6%96%8B" title="荣宝斋">
榮寶齋
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%88%B4%E6%9C%88%E8%BB%92&action=edit&redlink=1" title="戴月軒(页面不存在)">
戴月軒
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%89%BF%E5%8F%A4%E9%BD%8B&action=edit&redlink=1" title="承古齋(页面不存在)">
崇古齋
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BB%BA%E5%8D%8E%E7%9A%AE%E8%B4%A7%E6%9C%8D%E8%A3%85%E5%85%AC%E5%8F%B8" title="建华皮货服装公司">
德源興
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BC%B5%E4%B8%80%E5%85%83" title="張一元">
張一元
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E6%9E%97%E6%98%A5&action=edit&redlink=1" title="慶林春(页面不存在)">
慶林春
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%90%B4%E8%A3%95%E6%B3%B0%E8%8C%B6%E4%B8%9A%E8%82%A1%E4%BB%BD%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8" title="北京吴裕泰茶业股份有限公司">
吳裕泰
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%85%83%E9%95%B7%E5%8E%9A&action=edit&redlink=1" title="元長厚(页面不存在)">
元長厚
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E4%BA%A8%E5%BE%97%E5%88%A9%E9%90%98%E8%A1%A8%E5%BA%97&action=edit&redlink=1" title="亨得利鐘表店(页面不存在)">
亨得利鐘表眼鏡商店
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A7%E6%98%8E%E7%9C%BC%E9%8F%A1%E5%BA%97&action=edit&redlink=1" title="大明眼鏡店(页面不存在)">
大明眼鏡店
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A7%E6%98%8E%E7%9C%BC%E9%8F%A1%E5%BA%97&action=edit&redlink=1" title="大明眼鏡店(页面不存在)">
精益眼鏡店
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%9B%9B%E5%A4%A7%E6%81%86&action=edit&redlink=1" title="四大恆(页面不存在)">
四大恆
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B9%89%E5%88%A9" title="义利">
義利
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%9B%99%E5%90%88%E7%9B%9B&action=edit&redlink=1" title="雙合盛(页面不存在)">
雙合盛
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E6%83%A0%E9%BD%8B&action=edit&redlink=1" title="天惠齋(页面不存在)">
天惠齋
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%9D%B1%E6%98%87%E5%B9%B3&action=edit&redlink=1" title="東昇平(页面不存在)">
東昇平
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B8%85%E5%8D%8E%E5%9B%AD%E6%B5%B4%E6%B1%A0" title="清华园浴池">
清華園浴池
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%B8%85%E8%8F%AF%E6%B1%A0&action=edit&redlink=1" title="清華池(页面不存在)">
清華池
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%91%AB%E5%9B%AD%E5%AE%A2%E6%A0%88" title="鑫园客栈">
鑫园澡堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%88%88%E8%8F%AF%E5%9C%92&action=edit&redlink=1" title="興華園(页面不存在)">
興華園
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E5%B1%B1%E5%85%AC%E5%9B%AD" title="北京中山公园">
來今雨軒
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
名勝
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E5%AE%89%E9%97%A8" title="天安门">
天安門
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%95%85%E5%AE%AE" title="故宮">
故宮
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%AD%A3%E9%98%B3%E9%97%A8" title="正阳门">
正陽門
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%99%AF%E5%B1%B1%E5%85%AC%E5%9B%AD" title="景山公园">
景山
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%8C%97%E6%B5%B7%E5%85%AC%E5%9C%92" title="北海公園">
北海
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BB%80%E5%88%B9%E6%B5%B7" title="什刹海">
什刹海
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B9%9D%E5%A3%87%E5%85%AB%E5%BB%9F" title="九壇八廟">
九壇八廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%87%95%E4%BA%AC%E5%85%AB%E6%99%AF" title="燕京八景">
燕京八景
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A7%E6%A0%85%E6%A0%8F" title="大栅栏">
大柵欄
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%BC%93%E6%A5%BC%E5%92%8C%E9%92%9F%E6%A5%BC" title="北京鼓楼和钟楼">
鐘鼓樓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%A4%A9%E6%A1%A5" title="北京天桥">
天橋
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%90%89%E7%92%83%E5%8E%82" title="琉璃厂">
琉璃廠
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%85%AB%E5%A4%A7%E8%83%A1%E5%90%8C" title="八大胡同">
八大胡同
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
寺廟
<br/>
與廟會
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%85%AB%E5%88%B9%E4%B8%89%E5%B1%B1" title="北京八刹三山">
八刹三山
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%95%85%E5%AE%AB%E5%A4%96%E5%85%AB%E5%BA%99" title="故宫外八庙">
故宫外八庙
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A7%E9%9A%86%E5%96%84%E6%8A%A4%E5%9B%BD%E5%AF%BA" title="大隆善护国寺">
護國寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9A%86%E7%A6%8F%E5%AF%BA_(%E5%8C%97%E4%BA%AC)" title="隆福寺 (北京)">
隆福寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A6%99%E5%BA%94%E5%AF%BA" title="妙应寺">
白塔寺
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%9B%8D%E5%92%8C%E5%AE%AE" title="雍和宮">
雍和宮
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%8A%A5%E5%9B%BD%E5%AF%BA_(%E5%8C%97%E4%BA%AC)" title="报国寺 (北京)">
報國寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%83%BD%E5%9C%9F%E5%9C%B0%E5%BB%9F" title="都土地廟">
都土地廟
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E7%99%BD%E9%9B%B2%E8%A7%80" title="白雲觀">
白雲觀
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%9C%E5%B2%B3%E5%BA%99" title="北京东岳庙">
東岳廟
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E4%BA%94%E9%A0%82&action=edit&redlink=1" title="五頂(页面不存在)">
五頂
</a>
(
<a href="/wiki/%E4%B8%9C%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="东顶娘娘庙">
东顶
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="南顶娘娘庙">
南顶
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E4%BB%81%E5%AE%AB" title="广仁宫">
西顶
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="北顶娘娘庙">
北顶
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%AD%E9%A1%B6%E5%A8%98%E5%A8%98%E5%BA%99" title="中顶娘娘庙">
中顶
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E8%9F%A0%E6%A1%83%E5%AE%AB" title="蟠桃宫">
蟠桃宮
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8E%82%E7%94%B8%E5%BA%99%E4%BC%9A" title="厂甸庙会">
厰甸
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%83%BD%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="北京都城隍廟">
都城隍廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%9B%E5%B9%B3%E7%B8%A3%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="宛平縣城隍廟">
宛平縣城隍廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A7%E8%88%88%E7%B8%A3%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="大興縣城隍廟">
大興縣城隍廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B1%9F%E5%8D%97%E5%9F%8E%E9%9A%8D%E5%BB%9F" title="江南城隍廟">
江南城隍廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%94%E9%A1%AF%E8%B2%A1%E7%A5%9E%E5%BB%9F" title="五顯財神廟">
五顯財神廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B4%87%E5%85%83%E8%A7%82" title="崇元观">
崇元觀
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%AA%E9%98%B3%E5%AE%AB_(%E5%B7%A6%E5%AE%89%E9%97%A8)" title="太阳宫 (左安门)">
太陽宮
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E5%AE%81%E8%A7%82" title="广宁观">
廣寧觀
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%8A%B1%E5%B8%82%E7%81%AB%E7%A5%9E%E5%BA%99" title="花市火神庙">
花市火神廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%9C%B0%E5%AE%89%E9%97%A8%E7%81%AB%E7%A5%9E%E5%BA%99" title="地安门火神庙">
地安門火神廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%83%BD%E7%81%B6%E5%90%9B%E5%BB%9F" title="都灶君廟">
都灶君廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%99%AE%E6%B5%8E%E8%8D%AF%E7%8E%8B%E5%BA%99" title="普济药王庙">
西藥王廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%A6%8F%E4%B8%96%E6%99%AE%E6%B5%8E%E8%8D%AF%E7%8E%8B%E5%BA%99" title="福世普济药王庙">
東藥王廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%95%95%E5%B0%81%E8%97%A5%E7%8E%8B%E5%BB%9F" title="敕封藥王廟">
南藥王廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E8%97%A5%E7%8E%8B%E5%BB%9F" title="北藥王廟">
北藥王廟
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A6%99%E5%B3%B0%E5%B1%B1" title="妙峰山">
妙峰山
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%AB%E9%AB%BB%E5%B1%B1_(%E5%B9%B3%E8%B0%B7)" title="丫髻山 (平谷)">
丫髻山
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%89%9B%E8%A1%97%E7%A4%BC%E6%8B%9C%E5%AF%BA" title="牛街礼拜寺">
牛街礼拜寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%9C%E5%9B%9B%E6%B8%85%E7%9C%9F%E5%AF%BA" title="东四清真寺">
东四清真寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%8A%B1%E5%B8%82%E6%B8%85%E7%9C%9F%E5%AF%BA" title="花市清真寺">
花市清真寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%A9%AC%E7%94%B8%E6%B8%85%E7%9C%9F%E5%AF%BA" title="马甸清真寺">
马甸清真寺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E4%BB%80%E5%BA%93%E5%A4%A9%E4%B8%BB%E5%A0%82" title="西什库天主堂">
北堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%A3%E6%AD%A6%E9%97%A8%E5%A4%A9%E4%B8%BB%E5%A0%82" title="宣武门天主堂">
南堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%8E%8B%E5%BA%9C%E4%BA%95%E5%A4%A9%E4%B8%BB%E5%A0%82" title="王府井天主堂">
东堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E7%9B%B4%E9%97%A8%E5%A4%A9%E4%B8%BB%E5%A0%82" title="西直门天主堂">
西堂
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E8%80%81%E5%8C%97%E4%BA%AC%E5%90%84%E5%9C%B0%E4%BC%9A%E9%A6%86%E5%88%97%E8%A1%A8" title="老北京各地会馆列表">
會館
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%B9%96%E5%B9%BF%E4%BC%9A%E9%A6%86" title="北京湖广会馆">
湖廣會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%AE%89%E5%BE%BD%E4%BC%9A%E9%A6%86" title="北京安徽会馆">
安徽會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E6%B1%9F%E8%A5%BF%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京江西会馆(页面不存在)">
江西會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E6%B9%96%E5%8D%97%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京湖南会馆(页面不存在)">
湖南會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%9B%9B%E5%B7%9D%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京四川会馆(页面不存在)">
四川會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%85%A8%E6%B5%99%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京全浙会馆(页面不存在)">
全浙會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%A6%8F%E5%BB%BA%E4%BC%9A%E9%A6%86" title="北京福建会馆">
福建會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%A6%8F%E5%BB%BA%E6%B1%80%E5%B7%9E%E4%BC%9A%E9%A6%86" title="北京福建汀州会馆">
福建汀州會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%8D%97%E6%B5%B7%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京南海会馆(页面不存在)">
南海會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%AE%89%E5%BA%86%E4%BC%9A%E9%A6%86" title="北京安庆会馆">
安慶會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%B5%8F%E9%98%B3%E4%BC%9A%E9%A6%86" title="北京浏阳会馆">
瀏陽會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%95%AA%E7%A6%BA%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京番禺会馆(页面不存在)">
番禺會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E9%A1%BA%E5%BE%B7%E4%BC%9A%E9%A6%86" title="北京顺德会馆">
順德會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B9%B3%E9%98%B3%E4%BC%9A%E9%A6%86" title="北京平阳会馆">
平陽會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E4%B8%AD%E5%B1%B1%E4%BC%9A%E9%A6%86" title="北京中山会馆">
中山會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%B2%A4%E4%B8%9C%E6%96%B0%E9%A6%86" title="北京粤东新馆">
粵東新舘
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E7%BB%8D%E5%85%B4%E4%BC%9A%E9%A6%86" title="北京绍兴会馆">
紹興會館
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E4%BC%91%E5%AE%81%E4%BC%9A%E9%A6%86&action=edit&redlink=1" title="北京休宁会馆(页面不存在)">
休寧會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E6%BD%AE%E5%B7%9E%E4%BC%9A%E9%A6%86" title="北京潮州会馆">
潮州會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8F%B0%E6%B9%BE%E4%BC%9A%E9%A6%86" title="北京台湾会馆">
台灣會館
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%AD%A3%E4%B9%99%E7%A5%A0" title="正乙祠">
正乙祠
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
商場
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E9%9D%92%E4%BA%91%E9%98%81" title="青云阁">
青雲閣
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%8A%9D%E4%B8%9A%E5%9C%BA" title="北京劝业场">
勸業場
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%9C%E5%AE%89%E5%B8%82%E5%9C%BA" title="东安市场">
東安市場
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%A6%96%E5%96%84%E7%AC%AC%E4%B8%80%E6%A8%93&action=edit&redlink=1" title="首善第一樓(页面不存在)">
首善第一樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E6%A9%8B%E5%B8%82%E5%A0%B4&action=edit&redlink=1" title="天橋市場(页面不存在)">
天橋市場
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%A5%BF%E5%AE%89%E5%B8%82%E5%A0%B4&action=edit&redlink=1" title="西安市場(页面不存在)">
西安市場
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E5%8D%95%E5%95%86%E5%9C%BA" title="西单商场">
西單商場
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
戲院
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E5%92%8C%E6%A5%BC" title="广和楼">
廣和樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%99%AF%E6%B3%B0%E5%9C%92&action=edit&redlink=1" title="景泰園(页面不存在)">
景泰園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%B3%B0%E8%8F%AF%E5%9C%92&action=edit&redlink=1" title="泰華園(页面不存在)">
泰華園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%98%9C%E6%88%90%E5%9C%92&action=edit&redlink=1" title="阜成園(页面不存在)">
阜成園
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E5%BE%B7%E6%A5%BC" title="广德楼">
廣德樓
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%AD%E5%92%8C%E6%88%8F%E9%99%A2" title="中和戏院">
中和戲院
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BA%86%E4%B9%90%E5%A4%A7%E6%88%8F%E9%99%A2" title="庆乐大戏院">
慶樂戲園
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%89%E5%BA%86%E5%9B%AD" title="三庆园">
三慶戲院
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%85%B6%E5%92%8C%E5%9C%92" title="慶和園">
慶和園
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%85%A8%E6%99%AF%E5%8A%A8%E6%84%9F%E7%94%B5%E5%BD%B1%E9%99%A2_(%E5%8C%97%E4%BA%AC)" title="全景动感电影院 (北京)">
同樂軒
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A7%E8%A7%82%E6%A5%BC%E5%BD%B1%E5%9F%8E" title="大观楼影城">
大亨軒
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E4%B9%90%E5%9B%AD%E5%A4%A7%E6%88%8F%E6%A5%BC" title="天乐园大戏楼">
天樂茶園→華樂戲園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%A3%95%E8%88%88%E5%9C%92&action=edit&redlink=1" title="裕興園(页面不存在)">
裕興園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A7%E8%88%9E%E8%87%BA_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" title="大舞臺 (北京)(页面不存在)">
大舞臺
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%87%95%E5%96%9C%E5%A0%82&action=edit&redlink=1" title="燕喜堂(页面不存在)">
燕喜堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%95%B7%E5%AE%89%E5%A4%A7%E6%88%B2%E9%99%A2" title="長安大戲院">
長安大戲院
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%90%89%E7%A5%A5%E6%88%8F%E9%99%A2" title="吉祥戏院">
吉祥戲院
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%96%8B%E6%98%8E%E6%88%B2%E9%99%A2" title="開明戲院">
開明戲院
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E5%8D%95%E5%89%A7%E5%9C%BA" title="西单剧场">
哈爾飛戲院
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%A6%96%E9%83%BD%E7%94%B5%E5%BD%B1%E9%99%A2" title="首都电影院">
新新大戲院
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E6%98%A5%E5%9C%92&action=edit&redlink=1" title="慶春園(页面不存在)">
慶春園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%BB%A3%E8%88%88%E5%9C%92&action=edit&redlink=1" title="廣興園(页面不存在)">
廣興園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%98%A5%E4%BB%99%E5%9C%92&action=edit&redlink=1" title="春仙園(页面不存在)">
春仙園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E9%A0%86%E5%9C%92&action=edit&redlink=1" title="慶順園(页面不存在)">
慶順園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%A5%BF%E5%AE%89%E5%9C%92&action=edit&redlink=1" title="西安園(页面不存在)">
西安園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E6%98%87%E5%9C%92&action=edit&redlink=1" title="慶昇園(页面不存在)">
慶昇園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E5%92%8C%E5%9C%92&action=edit&redlink=1" title="天和園(页面不存在)">
天和園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E5%8C%AF%E5%9C%92&action=edit&redlink=1" title="天匯園(页面不存在)">
天匯園
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%AC%AC%E4%B8%80%E8%88%9E%E5%8F%B0_(%E5%8C%97%E4%BA%AC)" title="第一舞台 (北京)">
第一舞臺
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E6%A1%A5%E6%9D%82%E6%8A%80%E5%89%A7%E5%9C%BA" title="天桥杂技剧场">
萬盛軒
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%BE%B7%E4%BA%91%E7%A4%BE%E5%89%A7%E5%9C%BA" title="北京德云社剧场">
天樂戲院
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a class="mw-redirect" href="/wiki/%E8%8C%B6%E9%A4%A8" title="茶館">
<span style="color:#00008B;">
茶館
</span>
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E6%BB%99%E8%BB%92&action=edit&redlink=1" title="天滙軒(页面不存在)">
天滙軒
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%BB%99%E8%B1%90%E8%BB%92&action=edit&redlink=1" title="滙豐軒(页面不存在)">
滙豐軒
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%BB%A3%E6%85%B6%E8%BB%92&action=edit&redlink=1" title="廣慶軒(页面不存在)">
廣慶軒
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E5%92%8C%E6%A5%BC" title="广和楼">
廣和茶園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%98%9C%E6%88%90%E8%8C%B6%E5%9C%92&action=edit&redlink=1" title="阜成茶園(页面不存在)">
阜成茶園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%9D%B1%E5%92%8C%E9%A0%86&action=edit&redlink=1" title="東和順(页面不存在)">
東和順
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%BE%8D%E6%B5%B7%E8%BB%92&action=edit&redlink=1" title="龍海軒(页面不存在)">
龍海軒
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E7%9B%9B%E8%BB%92&action=edit&redlink=1" title="慶盛軒(页面不存在)">
慶盛軒
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E7%A5%BF%E8%BB%92&action=edit&redlink=1" title="天祿軒(页面不存在)">
天祿軒
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%AC%E8%8F%9C" title="京菜">
<span style="color:#00008B;">
京菜
</span>
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E8%B0%AD%E5%AE%B6%E8%8F%9C" title="谭家菜">
谭家菜
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8E%B2%E5%AE%B6%E8%8F%9C&action=edit&redlink=1" title="厲家菜(页面不存在)">
厲家菜
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E7%83%A4%E9%B4%A8" title="北京烤鴨">
北京烤鴨
</a>
(
<a href="/wiki/%E5%85%A8%E8%81%9A%E5%BE%B7" title="全聚德">
全聚德
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BE%BF%E5%AE%9C%E5%9D%8A" title="便宜坊">
便宜坊
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B6%AE%E7%BE%8A%E8%82%89" title="涮羊肉">
涮羊肉
</a>
(
<a href="/wiki/%E4%B8%9C%E6%9D%A5%E9%A1%BA" title="东来顺">
東來順
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8D%97%E4%BE%86%E9%A0%86&action=edit&redlink=1" title="南來順(页面不存在)">
南來順
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8F%88%E4%B8%80%E9%A0%86&action=edit&redlink=1" title="又一順(页面不存在)">
又一順
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%A5%BF%E4%BE%86%E9%A0%86&action=edit&redlink=1" title="西來順(页面不存在)">
西來順
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E7%82%99%E5%AD%90%E7%83%A4%E8%82%89" title="炙子烤肉">
炙子烤肉
</a>
(
<a class="mw-redirect" href="/wiki/%E7%83%A4%E8%82%89%E5%AD%A3" title="烤肉季">
烤肉季
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%83%A4%E8%82%89%E5%AE%9B&action=edit&redlink=1" title="烤肉宛(页面不存在)">
烤肉宛
</a>
) ·
</span>
<span class="nowrap">
<a href="/wiki/%E7%82%B8%E9%86%AC%E9%BA%B5" title="炸醬麵">
炸醬麵
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%8C%E9%94%85%E5%A4%B4" title="二锅头">
二鍋頭
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BB%BF%E8%86%B3%E9%A5%AD%E5%BA%84" title="仿膳饭庄">
仿膳飯莊
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8E%9A%E5%BE%B7%E7%A6%8F&action=edit&redlink=1" title="厚德福(页面不存在)">
厚德福
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%9F%B3%E6%B3%89%E5%B1%85" title="柳泉居">
柳泉居
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A3%B9%E6%9D%A1%E9%BE%99%E9%A5%AD%E5%BA%84" title="壹条龙饭庄">
壹条龍
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%8E%89%E8%8F%AF%E5%8F%B0%E9%A3%AF%E8%8E%8A&action=edit&redlink=1" title="玉華台飯莊(页面不存在)">
玉華台飯莊
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%85%A8%E7%B4%A0%E9%BD%8B&action=edit&redlink=1" title="全素齋(页面不存在)">
全素齋
</a>
</span>
</p>
<ul>
<li class="mw-empty-elt">
</li>
</ul>
<p>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%85%AB%E5%A4%A7%E6%A8%93&action=edit&redlink=1" title="八大樓(页面不存在)">
八大樓
</a>
:
<a class="new" href="/w/index.php?title=%E6%AD%A3%E9%99%BD%E6%A8%93&action=edit&redlink=1" title="正陽樓(页面不存在)">
正陽樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%9D%B1%E8%88%88%E6%A8%93&action=edit&redlink=1" title="東興樓(页面不存在)">
東興樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%B3%B0%E8%B1%90%E6%A8%93&action=edit&redlink=1" title="泰豐樓(页面不存在)">
泰豐樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%AE%89%E7%A6%8F%E6%A8%93&action=edit&redlink=1" title="安福樓(页面不存在)">
安福樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%87%B4%E7%BE%8E%E6%A8%93&action=edit&redlink=1" title="致美樓(页面不存在)">
致美樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%B4%BB%E8%88%88%E6%A8%93&action=edit&redlink=1" title="鴻興樓(页面不存在)">
鴻興樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%98%A5%E8%8F%AF%E6%A8%93&action=edit&redlink=1" title="春華樓(页面不存在)">
春華樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%96%B0%E8%B1%90%E6%A8%93&action=edit&redlink=1" title="新豐樓(页面不存在)">
新豐樓
</a>
</span>
</p>
<ul>
<li class="mw-empty-elt">
</li>
</ul>
<p>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%8D%81%E5%A4%A7%E5%A0%82&action=edit&redlink=1" title="十大堂(页面不存在)">
十大堂
</a>
:
<a class="new" href="/w/index.php?title=%E6%83%A0%E8%B1%90%E5%A0%82&action=edit&redlink=1" title="惠豐堂(页面不存在)">
惠豐堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%81%9A%E8%B3%A2%E5%A0%82&action=edit&redlink=1" title="聚賢堂(页面不存在)">
聚賢堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%A6%8F%E5%AF%BF%E5%A0%82_(%E5%8C%97%E4%BA%AC)" title="福寿堂 (北京)">
福壽堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A9%E7%A6%8F%E5%A0%82&action=edit&redlink=1" title="天福堂(页面不存在)">
天福堂
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BC%9A%E8%B4%A4%E5%A0%82" title="会贤堂">
會賢堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%A6%8F%E6%85%B6%E5%A0%82&action=edit&redlink=1" title="福慶堂(页面不存在)">
福慶堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E5%92%8C%E5%A0%82&action=edit&redlink=1" title="慶和堂(页面不存在)">
慶和堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%90%8C%E5%92%8C%E5%A0%82&action=edit&redlink=1" title="同和堂(页面不存在)">
同和堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%90%8C%E8%88%88%E5%A0%82&action=edit&redlink=1" title="同興堂(页面不存在)">
同興堂
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E8%B1%90%E5%A0%82&action=edit&redlink=1" title="慶豐堂(页面不存在)">
慶豐堂
</a>
</span>
</p>
<ul>
<li class="mw-empty-elt">
</li>
</ul>
<p>
<span class="nowrap">
<a href="/wiki/%E5%85%AB%E5%A4%A7%E5%B1%85" title="八大居">
八大居
</a>
:
<a class="new" href="/w/index.php?title=%E5%BB%A3%E5%92%8C%E5%B1%85&action=edit&redlink=1" title="廣和居(页面不存在)">
廣和居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%A0%82%E9%8D%8B%E5%B1%85&action=edit&redlink=1" title="砂鍋居(页面不存在)">
砂鍋居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%90%8C%E5%92%8C%E5%B1%85&action=edit&redlink=1" title="同和居(页面不存在)">
同和居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%81%A9%E6%89%BF%E5%B1%85&action=edit&redlink=1" title="恩承居(页面不存在)">
恩承居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%90%AC%E7%A6%8F%E5%B1%85&action=edit&redlink=1" title="萬福居(页面不存在)">
萬福居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%A6%8F%E8%88%88%E5%B1%85&action=edit&redlink=1" title="福興居(页面不存在)">
福興居
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E5%85%B4%E5%B1%85" title="天兴居">
天興居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%90%AC%E8%88%88%E5%B1%85&action=edit&redlink=1" title="萬興居(页面不存在)">
萬興居
</a>
</span>
</p>
<ul>
<li class="mw-empty-elt">
</li>
</ul>
<p>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%85%AB%E5%A4%A7%E6%98%A5&action=edit&redlink=1" title="八大春(页面不存在)">
八大春
</a>
:
<a class="new" href="/w/index.php?title=%E6%96%B9%E5%A3%BA%E6%98%A5&action=edit&redlink=1" title="方壺春(页面不存在)">
方壺春
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%9D%B1%E4%BA%9E%E6%98%A5&action=edit&redlink=1" title="東亞春(页面不存在)">
東亞春
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%85%B6%E6%9E%97%E6%98%A5_(%E9%A3%AF%E8%8E%8A)&action=edit&redlink=1" title="慶林春 (飯莊)(页面不存在)">
慶林春
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%B7%AE%E6%8F%9A%E6%98%A5&action=edit&redlink=1" title="淮揚春(页面不存在)">
淮揚春
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%96%B0%E8%B7%AF%E6%98%A5&action=edit&redlink=1" title="新路春(页面不存在)">
新路春
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A4%A7%E9%99%B8%E6%98%A5&action=edit&redlink=1" title="大陸春(页面不存在)">
大陸春
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%98%A5%E5%9C%92_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" title="春園 (北京)(页面不存在)">
春園
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%90%8C%E6%98%A5%E5%9C%92&action=edit&redlink=1" title="同春園(页面不存在)">
同春園
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E5%B0%8F%E5%90%83" title="北京小吃">
<span style="color:#00008B;">
小吃
</span>
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%8A%A4%E5%9B%BD%E5%AF%BA%E5%B0%8F%E5%90%83&action=edit&redlink=1" title="护国寺小吃(页面不存在)">
护国寺小吃
</a>
(
<a href="/wiki/%E8%B1%86%E6%B1%81" title="豆汁">
豆汁
</a>
、
<a href="/wiki/%E7%84%A6%E5%9C%88" title="焦圈">
焦圈
</a>
、
<a href="/wiki/%E8%B1%8C%E8%B1%86%E9%BB%84" title="豌豆黄">
豌豆黄
</a>
、
<a href="/wiki/%E8%89%BE%E7%AA%9D%E7%AA%9D" title="艾窝窝">
艾窝窝
</a>
、
<a href="/wiki/%E9%A9%B4%E6%89%93%E6%BB%9A" title="驴打滚">
驴打滚
</a>
) ·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%8C%AF%E8%8B%93%E5%A4%B9%E9%A5%BC" title="茯苓夹饼">
茯苓夹饼
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B1%B1%E6%A5%82%E7%B3%95" title="山楂糕">
京糕
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A4%A1%E8%A3%A2%E7%81%AB%E7%83%A7" title="褡裢火烧">
褡裢火烧
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%82%92%E8%82%9D" title="炒肝">
炒肝
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%88%86%E8%82%9A" title="爆肚">
爆肚
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%86%B0%E7%B3%96%E8%91%AB%E8%8A%A6" title="冰糖葫芦">
冰糖葫芦
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%81%8C%E8%82%A0_(%E5%8C%97%E4%BA%AC%E5%B0%8F%E5%90%83)" title="灌肠 (北京小吃)">
煎灌肠
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%82%92%E7%96%99%E7%98%A9&action=edit&redlink=1" title="炒疙瘩(页面不存在)">
炒疙瘩
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%99%BD%E6%B0%B4%E7%BE%8A%E5%A4%B4&action=edit&redlink=1" title="白水羊头(页面不存在)">
白水羊头
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%B3%96%E5%8D%B7%E6%9E%9C&action=edit&redlink=1" title="糖卷果(页面不存在)">
糖卷果
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9D%A2%E8%8C%B6" title="面茶">
面茶
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A7%9C%E4%B8%9D%E6%8E%92%E5%8F%89&action=edit&redlink=1" title="姜丝排叉(页面不存在)">
姜丝排叉
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A5%B6%E6%B2%B9%E7%82%B8%E7%B3%95" title="奶油炸糕">
奶油炸糕
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%9C%9C%E9%BA%BB%E8%8A%B1" title="蜜麻花">
蜜麻花
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%A6%93%E5%AD%90%E9%BA%BB%E8%8A%B1&action=edit&redlink=1" title="馓子麻花(页面不存在)">
馓子麻花
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%96%A9%E5%85%B6%E7%91%AA" title="薩其瑪">
萨其玛
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%B3%96%E7%81%AB%E7%83%A7&action=edit&redlink=1" title="糖火烧(页面不存在)">
糖火烧
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%B1%86%E9%A6%85%E7%83%A7%E9%A5%BC&action=edit&redlink=1" title="豆馅烧饼(页面不存在)">
豆馅烧饼
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%82%96%E5%90%8A%E5%AD%90&action=edit&redlink=1" title="炖吊子(页面不存在)">
炖吊子
</a>
<br/>
<a class="new" href="/w/index.php?title=%E9%A4%9B%E9%A3%A9%E4%BE%AF&action=edit&redlink=1" title="餛飩侯(页面不存在)">
餛飩侯
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B0%8F%E8%82%A0%E9%99%88" title="小肠陈">
小腸陳
</a>
(
<a href="/wiki/%E5%8D%A4%E7%85%AE%E7%81%AB%E7%83%A7" title="卤煮火烧">
卤煮火烧
</a>
) ·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%A5%B6%E9%85%AA%E9%AD%8F&action=edit&redlink=1" title="奶酪魏(页面不存在)">
奶酪魏
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%B9%B4%E7%B3%95%E6%A5%8A&action=edit&redlink=1" title="年糕楊(页面不存在)">
年糕楊
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E5%B9%B4%E7%B3%95%E9%92%B1&action=edit&redlink=1" title="年糕钱(页面不存在)">
年糕钱
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%88%86%E8%82%9A%E9%A6%AE" title="爆肚馮">
爆肚馮
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%88%86%E8%82%9A%E6%BB%A1&action=edit&redlink=1" title="爆肚满(页面不存在)">
爆肚满
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%88%86%E8%82%9A%E7%8E%8B&action=edit&redlink=1" title="爆肚王(页面不存在)">
爆肚王
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%BE%8A%E5%A4%B4%E9%A9%AC&action=edit&redlink=1" title="羊头马(页面不存在)">
羊头马
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%B1%86%E8%85%90%E8%85%A6%E7%99%BD&action=edit&redlink=1" title="豆腐腦白(页面不存在)">
豆腐腦白
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%8C%B6%E6%B9%AF%E6%9D%8E&action=edit&redlink=1" title="茶湯李(页面不存在)">
茶湯李
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%97%A8%E9%92%89%E6%9D%8E&action=edit&redlink=1" title="门钉李(页面不存在)">
门钉李
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%91%9E%E5%AE%BE%E6%A5%BC" title="瑞宾楼">
瑞賓樓
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%9C%88%E7%9B%9B%E9%BD%8B&action=edit&redlink=1" title="月盛齋(页面不存在)">
月盛齋
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E5%85%B4%E5%B1%85" title="天兴居">
天興居
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E9%8C%A6%E9%A6%A8&action=edit&redlink=1" title="錦馨(页面不存在)">
錦馨
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E7%99%BD%E9%AD%81%E8%80%81%E8%99%9F&action=edit&redlink=1" title="白魁老號(页面不存在)">
白魁老號
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E4%B8%8D%E8%80%81%E6%B3%89_(%E5%8C%97%E4%BA%AC)&action=edit&redlink=1" title="不老泉 (北京)(页面不存在)">
不老泉
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%83%BD%E4%B8%80%E8%99%95" title="都一處">
都一處
</a>
(烧麦) ·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E7%A6%8F%E5%8F%B7" title="天福号">
天福號
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%85%AD%E5%BF%85%E5%B1%85" title="六必居">
六必居
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E6%BA%90%E9%85%B1%E5%9B%AD" title="天源酱园">
天源醬園
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%8E%8B%E8%87%B4%E5%92%8C" title="王致和">
王致和
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%A1%82%E9%A6%A8%E9%BD%8B&action=edit&redlink=1" title="桂馨齋(页面不存在)">
桂馨齋
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%BA%BB%E9%86%AC%E9%BA%B5" title="麻醬麵">
麻醬麵
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
玩物
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%BA%9C%E9%B3%A5" title="溜鳥">
溜鳥
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%9B%90%E8%9B%90" title="蛐蛐">
斗蛐蛐
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%9D%88%E8%9D%88" title="蝈蝈">
蟈蟈
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%B8%BD%E5%AD%90" title="鸽子">
鴿子
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%87%91%E9%AD%9A" title="金魚">
金魚
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E8%B2%93" title="貓">
貓
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%A3%97" title="棗">
棗
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%9F%B3%E6%A6%B4" title="石榴">
石榴
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%BE%E7%AB%B9%E6%A1%83" title="夾竹桃">
夾竹桃
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%9F%BF%E5%AD%90" title="柿子">
柿子
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%8F%8A%E8%8A%B1" title="菊花">
菊花
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%9B%BD%E6%A7%90" title="国槐">
國槐
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B5%B7%E6%A3%A0" title="海棠">
海棠
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9C%8B%E8%B1%A1%E6%A3%8B" title="中國象棋">
中國象棋
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%9C%8D%E6%A3%8B" title="圍棋">
圍棋
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%89%8C%E4%B9%9D" title="牌九">
牌九
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%BA%BB%E5%B0%87" title="麻將">
麻將
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B9%9D%E4%B9%9D%E6%B6%88%E5%AF%92%E5%9B%BE" title="九九消寒图">
九九消寒圖
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%A4%AA%E6%A5%B5%E6%8B%B3" title="太極拳">
太極拳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%A9%BA%E7%AB%B9" title="空竹">
抖空竹
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%AF%BD%E5%AD%90" title="毽子">
毽子
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E6%89%8B%E9%83%A8%E5%81%A5%E8%BA%AB%E7%90%83&action=edit&redlink=1" title="手部健身球(页面不存在)">
核桃鐵球
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%87%88%E8%AC%8E" title="燈謎">
燈謎
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AF%B9%E8%81%94" title="对联">
對聯
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
言語
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%8C%97%E4%BA%AC%E8%A9%B1" title="北京話">
北京話
</a>
·
</span>
<span class="nowrap">
<a class="new" href="/w/index.php?title=%E8%80%81%E5%8C%97%E4%BA%AC%E5%8F%AB%E8%B3%A3&action=edit&redlink=1" title="老北京叫賣(页面不存在)">
老北京叫賣
</a>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks hlist collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template talk:中华人民共和国省级行政区">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="中華人民共和國行政區劃">
一级行政区
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3">
<div>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E9%A6%96%E9%83%BD" title="中国首都">
首都
</a>
:
<a class="mw-selflink selflink">
北京市
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
23
<a class="mw-redirect" href="/wiki/%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B)" title="省 (中華人民共和國)">
省
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北省
</a>
</li>
<li>
<a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">
山西省
</a>
</li>
<li>
<a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">
辽宁省
</a>
</li>
<li>
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">
吉林省
</a>
</li>
<li>
<a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">
黑龙江省
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">
江苏省
</a>
</li>
<li>
<a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">
浙江省
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">
安徽省
</a>
</li>
<li>
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
福建省
</a>
<sup>
1
</sup>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">
江西省
</a>
</li>
<li>
<a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">
山东省
</a>
</li>
<li>
<a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">
河南省
</a>
</li>
<li>
<a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">
湖北省
</a>
</li>
<li>
<a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">
湖南省
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">
广东省
</a>
<sup>
1
</sup>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
海南省
</a>
<sup>
1
</sup>
<sup>
2
</sup>
</li>
<li>
<a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">
四川省
</a>
</li>
<li>
<a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">
贵州省
</a>
</li>
<li>
<a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">
云南省
</a>
</li>
<li>
<a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">
陕西省
</a>
</li>
<li>
<a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">
甘肃省
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">
青海省
</a>
</li>
<li>
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
<span style="color:grey;">
台湾省
</span>
</a>
<sup>
1
</sup>
</li>
</ul>
</div>
</td>
<td class="navbox-image" rowspan="7" style="width:0%;padding:0px 0px 0px 2px">
<div>
<a class="image" href="/wiki/File:Flag_of_the_People%27s_Republic_of_China.svg" title="中国国旗">
<img alt="中国国旗" data-file-height="600" data-file-width="900" decoding="async" height="67" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/100px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/150px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/200px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="100"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
5
<a href="/wiki/%E8%87%AA%E6%B2%BB%E5%8C%BA" title="自治区">
自治区
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">
内蒙古自治区
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">
广西壮族自治区
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">
西藏自治区
</a>
<sup>
3
</sup>
</li>
<li>
<a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">
宁夏回族自治区
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">
新疆维吾尔自治区
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
4
<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">
直辖市
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</li>
<li>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
<span class="nowrap">
2
<a href="/wiki/%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" title="特别行政区">
特别行政区
</a>
</span>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="image" href="/wiki/File:Flag_of_Hong_Kong.svg">
<img alt="Flag of Hong Kong.svg" data-file-height="600" data-file-width="900" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5b/Flag_of_Hong_Kong.svg/25px-Flag_of_Hong_Kong.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5b/Flag_of_Hong_Kong.svg/38px-Flag_of_Hong_Kong.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5b/Flag_of_Hong_Kong.svg/50px-Flag_of_Hong_Kong.svg.png 2x" width="25"/>
</a>
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港特别行政区
</a>
</li>
<li>
<a class="image" href="/wiki/File:Flag_of_Macau.svg">
<img alt="Flag of Macau.svg" data-file-height="341" data-file-width="512" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/63/Flag_of_Macau.svg/25px-Flag_of_Macau.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/63/Flag_of_Macau.svg/38px-Flag_of_Macau.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/63/Flag_of_Macau.svg/50px-Flag_of_Macau.svg.png 2x" width="25"/>
</a>
<a href="/wiki/%E6%BE%B3%E9%96%80" title="澳門">
澳门特别行政区
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3" style="text-align: left; font-size: 90%;">
<div>
注1:
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
台湾省
</a>
絕大部分(钓鱼岛及其附属岛屿除外),
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
福建省
</a>
的
<a class="mw-redirect" href="/wiki/%E9%87%91%E9%96%80%E7%BE%A4%E5%B3%B6" title="金門群島">
金門
</a>
、
<a href="/wiki/%E9%A6%AC%E7%A5%96%E5%88%97%E5%B3%B6" title="馬祖列島">
馬祖
</a>
、
<a href="/wiki/%E7%83%8F%E5%9D%B5%E9%84%89" title="烏坵鄉">
烏坵
</a>
,
<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">
广东省
</a>
的
<a href="/wiki/%E6%9D%B1%E6%B2%99%E7%BE%A4%E5%B3%B6" title="東沙群島">
東沙
</a>
和
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
海南省
</a>
<a class="mw-redirect" href="/wiki/%E5%8D%97%E6%B2%99%E7%BE%A4%E5%B3%B6" title="南沙群島">
南沙群島
</a>
的
<a href="/wiki/%E5%A4%AA%E5%B9%B3%E5%B3%B6" title="太平島">
太平島
</a>
與
<a href="/wiki/%E4%B8%AD%E6%B4%B2%E7%A4%81" title="中洲礁">
中洲礁
</a>
现由
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
实际控制。
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
台湾省
</a>
的
<a href="/wiki/%E9%87%A3%E9%AD%9A%E8%87%BA%E5%88%97%E5%B6%BC" title="釣魚臺列嶼">
钓鱼岛及其附属岛屿
</a>
现由
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
日本
</a>
实际控制。參阅
<a class="mw-redirect" href="/wiki/%E5%8F%B0%E6%B5%B7%E7%8F%BE%E7%8B%80" title="台海現狀">
台海現狀
</a>
、
<a class="mw-redirect" href="/wiki/%E5%85%A9%E5%B2%B8%E5%95%8F%E9%A1%8C" title="兩岸問題">
兩岸問題
</a>
和
<a class="mw-redirect" href="/wiki/%E9%92%93%E9%B1%BC%E5%B2%9B%E5%8F%8A%E5%85%B6%E9%99%84%E5%B1%9E%E5%B2%9B%E5%B1%BF%E4%B8%BB%E6%9D%83%E9%97%AE%E9%A2%98" title="钓鱼岛及其附属岛屿主权问题">
钓鱼岛及其附属岛屿主权问题
</a>
。
<p>
注2:
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
海南省
</a>
部分区域现由
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD" title="中华民国">
中华民国
</a>
、
<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">
越南
</a>
、
<a href="/wiki/%E8%8F%B2%E5%BE%8B%E5%AE%BE" title="菲律宾">
菲律宾
</a>
和
<a href="/wiki/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A" title="马来西亚">
马来西亚
</a>
实际控制,參阅
<a href="/wiki/%E5%8D%97%E6%B5%B7%E8%AF%B8%E5%B2%9B" title="南海诸岛">
南海诸岛
</a>
。
</p>
<p>
注3:
<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">
西藏自治区
</a>
部分区域现由
<a href="/wiki/%E5%8D%B0%E5%BA%A6" title="印度">
印度
</a>
、
<a href="/wiki/%E4%B8%8D%E4%B8%B9" title="不丹">
不丹
</a>
实际控制,參阅
<a href="/wiki/%E4%B8%AD%E5%8D%B0%E8%BE%B9%E7%95%8C%E9%97%AE%E9%A2%98" title="中印边界问题">
中印边界问题
</a>
、
<a href="/wiki/%E4%B8%AD%E4%B8%8D%E8%BE%B9%E7%95%8C%E4%BA%89%E8%AE%AE" title="中不边界争议">
中不边界争议
</a>
。
</p>
参阅:
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
中华人民共和国行政区划
</a>
、
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">
省级以上行政区变动
</a>
、
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区">
副省级行政区
</a>
、
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">
县级以上行政区列表
</a>
。
<br/>
<hr/>
<div class="center">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
区划
</a>
索引:
<a href="/wiki/Template:Division_levels_of_China" title="Template:Division levels of China">
单位
</a>
<small>
(
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81" title="中华人民共和国行政区划代码">
代码
</a>
)
</small>
:
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">
省级
</a>
<small>
(
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">
史
</a>
)
</small>
>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区">
<i>
副省级
</i>
</a>
>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">
地级
</a>
>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">
县级
</a>
:
<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">
京
</a>
|
<a href="/wiki/Template:%E5%A4%A9%E6%B4%A5%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:天津行政区划">
津
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河北行政区划">
冀
</a>
|
<a href="/wiki/Template:%E5%B1%B1%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山西行政区划">
晋
</a>
|
<a href="/wiki/Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:内蒙古行政区划">
蒙
</a>
|
<a href="/wiki/Template:%E8%BE%BD%E5%AE%81%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:辽宁行政区划">
辽
</a>
|
<a href="/wiki/Template:%E5%90%89%E6%9E%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:吉林行政区划">
吉
</a>
|
<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:黑龙江行政区划">
黑
</a>
|
<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:上海行政区划">
沪
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江苏行政区划">
苏
</a>
|
<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:浙江行政区划">
浙
</a>
|
<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:安徽行政区划">
皖
</a>
|
<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:福建行政区划">
闽
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江西行政区划">
赣
</a>
|
<a href="/wiki/Template:%E5%B1%B1%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山东行政区划">
鲁
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河南行政区划">
豫
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖北行政区划">
鄂
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖南行政区划">
湘
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广东行政区划">
粤
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广西行政区划">
桂
</a>
|
<a href="/wiki/Template:%E6%B5%B7%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:海南行政区划">
琼
</a>
|
<a href="/wiki/Template:%E9%87%8D%E5%BA%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:重庆行政区划">
渝
</a>
|
<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:四川行政区划">
川
</a>
|
<a href="/wiki/Template:%E8%B4%B5%E5%B7%9E%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:贵州行政区划">
贵
</a>
|
<a href="/wiki/Template:%E4%BA%91%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:云南行政区划">
云
</a>
|
<a href="/wiki/Template:%E8%A5%BF%E8%97%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:西藏行政区划">
藏
</a>
|
<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:陕西行政区划">
陕
</a>
|
<a href="/wiki/Template:%E7%94%98%E8%82%83%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:甘肃行政区划">
甘
</a>
|
<a href="/wiki/Template:%E9%9D%92%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:青海行政区划">
青
</a>
|
<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:宁夏行政区划">
宁
</a>
|
<a href="/wiki/Template:%E6%96%B0%E7%96%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:新疆行政区划">
新
</a>
|
<a href="/wiki/Template:%E9%A6%99%E6%B8%AF%E5%8D%81%E5%85%AB%E5%8D%80" title="Template:香港十八區">
港
</a>
|
<a href="/wiki/Template:%E6%BE%B3%E9%96%80%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="Template:澳門行政區劃">
澳
</a>
|
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
台
</a>
</div>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template talk:北京行政区划">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a class="mw-selflink selflink">
北京市
</a>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="北京市行政區劃">
行政区划
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3">
<div>
国别:
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">
市政府
</a>
所在地:
<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">
通州区
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;;background: #ececec;">
<a href="/wiki/%E5%8E%BF%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="县级行政区">
县级行政区
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;background: #ececec; text-align: center;">
<div style="padding:0em 0.25em">
16
<a href="/wiki/%E5%B8%82%E8%BE%96%E5%8C%BA" title="市辖区">
市辖区
</a>
</div>
</td>
<td class="navbox-image" rowspan="3" style="width:0%;padding:0px 0px 0px 2px">
<div>
<a class="image" href="/wiki/File:China_Beijing.svg">
<img alt="China Beijing.svg" data-file-height="850" data-file-width="1000" decoding="async" height="68" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/80px-China_Beijing.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/120px-China_Beijing.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/160px-China_Beijing.svg.png 2x" width="80"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
<a href="/wiki/%E5%B8%82%E8%BE%96%E5%8C%BA" title="市辖区">
市辖区
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E4%B8%9C%E5%9F%8E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="东城区 (北京市)">
东城区
</a>
·
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E5%9F%8E%E5%8C%BA" title="西城区">
西城区
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%9C%9D%E9%98%B3%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="朝阳区 (北京市)">
朝阳区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%B0%E5%8F%B0%E5%8C%BA" title="丰台区">
丰台区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%9F%B3%E6%99%AF%E5%B1%B1%E5%8C%BA" title="石景山区">
石景山区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B5%B7%E6%B7%80%E5%8C%BA" title="海淀区">
海淀区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%97%A8%E5%A4%B4%E6%B2%9F%E5%8C%BA" title="门头沟区">
门头沟区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%88%BF%E5%B1%B1%E5%8C%BA" title="房山区">
房山区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%8C%BA" title="大兴区">
大兴区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%80%9A%E5%B7%9E%E5%8C%BA_(%E5%8C%97%E4%BA%AC%E5%B8%82)" title="通州区 (北京市)">
通州区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%A1%BA%E4%B9%89%E5%8C%BA" title="顺义区">
顺义区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%98%8C%E5%B9%B3%E5%8C%BA" title="昌平区">
昌平区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%80%80%E6%9F%94%E5%8C%BA" title="怀柔区">
怀柔区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%B3%E8%B0%B7%E5%8C%BA" title="平谷区">
平谷区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AF%86%E4%BA%91%E5%8C%BA" title="密云区">
密云区
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BB%B6%E5%BA%86%E5%8C%BA" title="延庆区">
延庆区
</a>
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3" style="text-align: left; font-size: 80%;">
<div>
参见:
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">
中华人民共和国县级以上行政区列表
</a>
、
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%B9%A1%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="北京市乡级以上行政区列表">
北京市乡级以上行政区列表
</a>
、
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E5%B7%B2%E6%92%A4%E9%94%80%E5%8E%BF%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国北京市已撤销县级行政区">
北京市已撤销县级行政区
</a>
。
<br/>
<hr/>
<div class="center">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
区划
</a>
索引:
<a href="/wiki/Template:Division_levels_of_China" title="Template:Division levels of China">
单位
</a>
<small>
(
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81" title="中华人民共和国行政区划代码">
代码
</a>
)
</small>
:
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">
省级
</a>
<small>
(
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">
史
</a>
)
</small>
>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区">
<i>
副省级
</i>
</a>
>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">
地级
</a>
>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">
县级
</a>
:
<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">
京
</a>
|
<a href="/wiki/Template:%E5%A4%A9%E6%B4%A5%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:天津行政区划">
津
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河北行政区划">
冀
</a>
|
<a href="/wiki/Template:%E5%B1%B1%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山西行政区划">
晋
</a>
|
<a href="/wiki/Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:内蒙古行政区划">
蒙
</a>
|
<a href="/wiki/Template:%E8%BE%BD%E5%AE%81%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:辽宁行政区划">
辽
</a>
|
<a href="/wiki/Template:%E5%90%89%E6%9E%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:吉林行政区划">
吉
</a>
|
<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:黑龙江行政区划">
黑
</a>
|
<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:上海行政区划">
沪
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江苏行政区划">
苏
</a>
|
<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:浙江行政区划">
浙
</a>
|
<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:安徽行政区划">
皖
</a>
|
<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:福建行政区划">
闽
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江西行政区划">
赣
</a>
|
<a href="/wiki/Template:%E5%B1%B1%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山东行政区划">
鲁
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河南行政区划">
豫
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖北行政区划">
鄂
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖南行政区划">
湘
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广东行政区划">
粤
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广西行政区划">
桂
</a>
|
<a href="/wiki/Template:%E6%B5%B7%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:海南行政区划">
琼
</a>
|
<a href="/wiki/Template:%E9%87%8D%E5%BA%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:重庆行政区划">
渝
</a>
|
<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:四川行政区划">
川
</a>
|
<a href="/wiki/Template:%E8%B4%B5%E5%B7%9E%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:贵州行政区划">
贵
</a>
|
<a href="/wiki/Template:%E4%BA%91%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:云南行政区划">
云
</a>
|
<a href="/wiki/Template:%E8%A5%BF%E8%97%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:西藏行政区划">
藏
</a>
|
<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:陕西行政区划">
陕
</a>
|
<a href="/wiki/Template:%E7%94%98%E8%82%83%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:甘肃行政区划">
甘
</a>
|
<a href="/wiki/Template:%E9%9D%92%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:青海行政区划">
青
</a>
|
<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:宁夏行政区划">
宁
</a>
|
<a href="/wiki/Template:%E6%96%B0%E7%96%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:新疆行政区划">
新
</a>
|
<a href="/wiki/Template:%E9%A6%99%E6%B8%AF%E5%8D%81%E5%85%AB%E5%8D%80" title="Template:香港十八區">
港
</a>
|
<a href="/wiki/Template:%E6%BE%B3%E9%96%80%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="Template:澳門行政區劃">
澳
</a>
|
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
台
</a>
</div>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<span style="float:left;width:8em;font-size:80%;margin-right:0.5em">
</span>
<div style="font-size:110%">
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国">
中国
</a>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E6%9C%9D%E4%BB%A3" title="中国朝代">
历代
</a>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E9%A6%96%E9%83%BD" title="中国首都">
都城
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E9%A6%96%E9%83%BD" title="中国首都">
中国首都
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
古都
<br/>
并称
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
两都
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;">
<div style="padding:0em 0.25em">
<a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">
长安
</a>
·
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
四大
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">
长安
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
汴
</a>
·
</span>
<span class="nowrap">
<a class="mw-selflink selflink">
燕
</a>
(明代,陈建)
<br/>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
关中
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
建康
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
开封
</a>
(明末,顾炎武)
<br/>
<a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">
长安
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
金陵
</a>
·
</span>
<span class="nowrap">
<a class="mw-selflink selflink">
燕都
</a>
(民国,朱偰)
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
五大
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E9%95%BF%E5%AE%89" title="长安">
长安
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%B1%B4%E4%BA%AC" title="汴京">
汴京
</a>
·
</span>
<span class="nowrap">
<a class="mw-selflink selflink">
燕都
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
金陵
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
七大
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京
</a>
·
</span>
<span class="nowrap">
<a class="mw-selflink selflink">
北京
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
开封
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">
安阳
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
十大
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px;font-weight: bold;">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京
</a>
·
</span>
<span class="nowrap">
<a class="mw-selflink selflink">
北京
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
开封
</a>
<br/>
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">
安阳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">
大同
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%85%88%E7%A7%A6" title="先秦">
先秦
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%89%E7%9A%87%E4%BA%94%E5%B8%9D#五帝" title="三皇五帝">
五帝
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
黃帝都有熊(疑為
<a href="/wiki/%E8%A5%BF%E5%9D%A1%E9%81%97%E5%9D%80" title="西坡遗址">
西坡遗址
</a>
) ·
<span class="nowrap">
堯都平陽(疑為
<a href="/wiki/%E9%99%B6%E5%AF%BA%E9%81%BA%E5%9D%80" title="陶寺遺址">
陶寺遺址
</a>
)
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%A4%8F%E6%9C%9D" title="夏朝">
夏
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
(僅列出重要的)禹都
<a href="/wiki/%E9%98%B3%E5%9F%8E%E5%8E%BF" title="阳城县">
陽城
</a>
(疑為
<a href="/wiki/%E7%8E%8B%E5%9F%8E%E5%B2%97%E5%8F%8A%E9%98%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="王城岗及阳城遗址">
王城崗遺址
</a>
) ·
<span class="nowrap">
<a href="/wiki/%E6%96%9F%E9%84%A9" title="斟鄩">
斟鄩
</a>
(疑為
<a href="/wiki/%E4%BA%8C%E9%87%8C%E5%A4%B4%E9%81%97%E5%9D%80" title="二里头遗址">
二里头遗址
</a>
)
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%95%86%E6%9C%9D" title="商朝">
商
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E4%BA%B3" title="亳">
亳
</a>
<small>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%95%86%E5%9F%8E%E9%81%97%E5%9D%80" title="郑州商城遗址">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%9A%9E" title="隞">
隞(嚣)
</a>
<small>
<a href="/wiki/%E5%B0%8F%E5%8F%8C%E6%A1%A5%E9%81%97%E5%9D%80" title="小双桥遗址">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E7%9B%B8_(%E5%95%86%E6%9C%9D)" title="相 (商朝)">
相
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%BA%87" title="庇">
庇
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%BA%87" title="庇">
邢
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%95%86%E5%A5%84" title="商奄">
奄
</a>
</span>
<span class="nowrap">
<a href="/wiki/%E7%9B%98%E5%BA%9A%E8%BF%81%E6%AE%B7" title="盘庚迁殷">
→
</a>
<a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">
殷
</a>
<small>
<a href="/wiki/%E6%AE%B7%E5%A2%9F" title="殷墟">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9C%9D%E6%AD%8C" title="朝歌">
朝歌
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%91%A8%E6%9C%9D" title="周朝">
周
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%B2%90%E9%82%91" title="岐邑">
岐邑
</a>
</span>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E4%B8%B0%E4%BA%AC" title="丰京">
丰京
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%8E%AC%E4%BA%AC" title="鎬京">
鎬京
</a>
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%B3%E7%8E%8B%E4%B8%9C%E8%BF%81" title="平王东迁">
→
</a>
<a href="/wiki/%E9%9B%92%E9%82%91" title="雒邑">
雒邑
</a>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E7%A7%A6%E6%9C%9D" title="秦朝">
秦
</a>
<br/>
<a href="/wiki/%E6%B1%89%E6%9C%9D" title="汉朝">
汉
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E7%A7%A6%E6%9C%9D" title="秦朝">
秦朝
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%92%B8%E9%99%BD%E7%B8%A3" title="咸陽縣">
咸阳
</a>
<small>
<a class="mw-redirect" href="/wiki/%E5%92%B8%E9%98%B3%E5%9F%8E" title="咸阳城">
[遗址]
</a>
</small>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B1%89%E6%9C%9D" title="汉朝">
汉朝
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<sup>
<a href="/wiki/%E8%A5%BF%E6%B1%89" title="西汉">
西汉
</a>
→
<a href="/wiki/%E6%96%B0%E6%9C%9D" title="新朝">
新朝
</a>
</sup>
<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">
长安
</a>
</span>
<span class="nowrap">
→
<sup>
<a href="/wiki/%E4%B8%9C%E6%B1%89" title="东汉">
东汉
</a>
</sup>
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
雒陽
</a>
<small>
<a href="/wiki/%E6%B1%89%E9%AD%8F%E6%B4%9B%E9%98%B3%E6%95%85%E5%9F%8E" title="汉魏洛阳故城">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<sup>
<a href="/wiki/%E6%B1%89%E7%8C%AE%E5%B8%9D" title="汉献帝">
东汉献帝
</a>
</sup>
<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">
长安
</a>
</span>
<span class="nowrap">
→
<sup>
<a href="/wiki/%E6%B1%89%E7%8C%AE%E5%B8%9D" title="汉献帝">
东汉献帝
</a>
</sup>
<a href="/wiki/%E8%AE%B8%E6%98%8C%E5%B8%82" title="许昌市">
许都
</a>
<small>
<a href="/wiki/%E6%B1%89%E9%AD%8F%E8%AE%B8%E9%83%BD%E6%95%85%E5%9F%8E" title="汉魏许都故城">
[遗址]
</a>
</small>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%89%E5%9B%BD" title="三国">
三国
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%9B%B9%E9%AD%8F%E4%BA%94%E9%83%BD" title="曹魏五都">
曹魏五都
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<sup>
长安
</sup>
<small>
<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">
遗址
</a>
</small>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E8%B0%AF%E9%83%A1" title="谯郡">
谯都
</a>
</sup>
·
</span>
<span class="nowrap">
<sup>
许都
</sup>
<small>
<a href="/wiki/%E6%B1%89%E9%AD%8F%E8%AE%B8%E9%83%BD%E6%95%85%E5%9F%8E" title="汉魏许都故城">
遗址
</a>
</small>
·
</span>
<span class="nowrap">
<sup>
邺都
</sup>
<small>
<a href="/wiki/%E9%82%BA%E5%9F%8E%E9%81%97%E5%9D%80" title="邺城遗址">
遗址
</a>
</small>
·
</span>
<span class="nowrap">
<sup>
洛阳
</sup>
<small>
<a href="/wiki/%E6%B1%89%E9%AD%8F%E6%B4%9B%E9%98%B3%E6%95%85%E5%9F%8E" title="汉魏洛阳故城">
遗址
</a>
</small>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%97%E5%8C%97%E6%9C%9D" title="南北朝">
南
<br/>
北
<br/>
朝
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%97%E5%8C%97%E6%9C%9D" title="南北朝">
南朝
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<sup>
<a href="/wiki/%E5%88%98%E5%AE%8B" title="刘宋">
宋
</a>
→
<a href="/wiki/%E5%8D%97%E9%BD%90" title="南齐">
齐
</a>
→
<a href="/wiki/%E6%A2%81_(%E5%8D%97%E6%9C%9D)" title="梁 (南朝)">
梁
</a>
→
<a class="mw-redirect" href="/wiki/%E9%99%88_(%E5%8D%97%E6%9C%9D)" title="陈 (南朝)">
陈
</a>
</sup>
<a href="/wiki/%E5%85%AD%E6%9C%9D%E5%BB%BA%E5%BA%B7%E9%83%BD%E5%9F%8E%E9%81%97%E5%9D%80" title="六朝建康都城遗址">
建康
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%97%E5%8C%97%E6%9C%9D" title="南北朝">
北朝
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<span class="nowrap">
<a href="/wiki/%E7%9B%9B%E6%A8%82" title="盛樂">
盛樂
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%B9%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="平城遗址">
平城
</a>
<small>
<a href="/wiki/%E5%B9%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="平城遗址">
[遗址]
</a>
</small>
</span>
<small>
<span class="nowrap">
→
</span>
</small>
<sup>
<a href="/wiki/%E5%8C%97%E9%AD%8F" title="北魏">
北魏
</a>
</sup>
<a href="/wiki/%E6%B1%89%E9%AD%8F%E6%B4%9B%E9%98%B3%E6%95%85%E5%9F%8E" title="汉魏洛阳故城">
洛阳
</a>
·
<span class="nowrap">
<sup>
<a href="/wiki/%E4%B8%9C%E9%AD%8F" title="东魏">
东魏
</a>
</sup>
<a href="/wiki/%E9%82%BA%E5%9F%8E%E9%81%97%E5%9D%80" title="邺城遗址">
邺
</a>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E8%A5%BF%E9%AD%8F" title="西魏">
西魏
</a>
</sup>
<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">
长安
</a>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E5%8C%97%E9%BD%90" title="北齐">
北齐
</a>
</sup>
<a href="/wiki/%E9%82%BA%E5%9F%8E%E9%81%97%E5%9D%80" title="邺城遗址">
邺
</a>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E5%8C%97%E5%91%A8" title="北周">
北周
</a>
</sup>
<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">
长安
</a>
</span>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E9%9A%8B%E6%9C%9D" title="隋朝">
隋
</a>
<br/>
<a href="/wiki/%E5%94%90%E6%9C%9D" title="唐朝">
唐
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E8%A1%8C%E6%94%BF%E4%B8%AD%E5%BF%83" title="行政中心">
统治中心
</a>
:
<a href="/wiki/%E6%B1%89%E9%95%BF%E5%AE%89%E5%9F%8E" title="汉长安城">
长安
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%94%90%E9%95%BF%E5%AE%89%E5%9F%8E" title="唐长安城">
大兴→长安
</a>
(
<a href="/wiki/%E8%83%A1%E5%A7%86%E4%B8%B9" title="胡姆丹">
胡姆丹
</a>
)
</span>
<span class="nowrap">
→
<sup>
<a href="/wiki/%E6%AD%A6%E5%91%A8" title="武周">
武周
</a>
</sup>
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
神都
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%94%90%E9%95%BF%E5%AE%89%E5%9F%8E" title="唐长安城">
长安
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%94%90%E9%95%BF%E5%AE%89%E5%9F%8E" title="唐长安城">
长安
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
<small>
<a href="/wiki/%E9%9A%8B%E5%94%90%E6%B4%9B%E9%98%B3%E5%9F%8E%E9%81%97%E5%9D%80" title="隋唐洛阳城遗址">
[遗址]
</a>
</small>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%94%E4%BA%AC%E5%88%B6" title="五京制">
五
<br/>
京
<br/>
制
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%94%90%E6%9C%9D" title="唐朝">
唐
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
北京
<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%BA%9C" title="太原府">
太原府
</a>
<small>
<a href="/wiki/%E6%99%8B%E9%98%B3%E5%8F%A4%E5%9F%8E%E9%81%97%E5%9D%80" title="晋阳古城遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
东京
<a href="/wiki/%E6%B2%B3%E5%8D%97%E5%BA%9C" title="河南府">
河南府
</a>
·
</span>
<span class="nowrap">
中京
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%BA%9C" title="京兆府">
京兆府
</a>
·
</span>
<span class="nowrap">
南京
<a href="/wiki/%E6%88%90%E9%83%BD%E5%BA%9C" title="成都府">
成都府
</a>
·
</span>
<span class="nowrap">
西京
<a href="/wiki/%E9%B3%B3%E7%BF%94%E5%BA%9C" title="鳳翔府">
鳳翔府
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B8%A4%E6%B5%B7%E5%9B%BD" title="渤海国">
渤
<br/>
海
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
上京
<a href="/wiki/%E9%BE%99%E6%B3%89%E5%BA%9C" title="龙泉府">
龙泉府
</a>
<small>
<a href="/wiki/%E6%B8%A4%E6%B5%B7%E5%9B%BD%E4%B8%8A%E4%BA%AC%E9%BE%99%E6%B3%89%E5%BA%9C%E9%81%97%E5%9D%80" title="渤海国上京龙泉府遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
东京
<a href="/wiki/%E9%BE%99%E5%8E%9F%E5%BA%9C" title="龙原府">
龙原府
</a>
·
</span>
<span class="nowrap">
中京
<a href="/wiki/%E6%98%BE%E5%BE%B7%E5%BA%9C" title="显德府">
显德府
</a>
<small>
<a href="/wiki/%E6%B8%A4%E6%B5%B7%E4%B8%AD%E4%BA%AC%E5%9F%8E%E9%81%97%E5%9D%80" title="渤海中京城遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
南京
<a href="/wiki/%E5%8D%97%E6%B5%B7%E5%BA%9C" title="南海府">
南海府
</a>
·
</span>
<span class="nowrap">
西京
<a href="/wiki/%E9%B8%AD%E6%B8%8C%E5%BA%9C" title="鸭渌府">
鸭绿府
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E8%BE%BD%E6%9C%9D" title="辽朝">
辽
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
上京
<a href="/wiki/%E4%B8%8A%E4%BA%AC%E4%B8%B4%E6%BD%A2%E5%BA%9C" title="上京临潢府">
临潢府
</a>
<small>
<a href="/wiki/%E8%BE%BD%E4%B8%8A%E4%BA%AC%E9%81%97%E5%9D%80" title="辽上京遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
东京
<a href="/wiki/%E8%BE%BD%E9%98%B3%E5%BA%9C" title="辽阳府">
辽阳府
</a>
·
</span>
<span class="nowrap">
中京
<a href="/wiki/%E5%A4%A7%E5%AE%9A%E5%BA%9C_(%E8%BE%BD%E6%9C%9D)" title="大定府 (辽朝)">
大定府
</a>
<small>
<a href="/wiki/%E8%BE%BD%E4%B8%AD%E4%BA%AC%E9%81%97%E5%9D%80" title="辽中京遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%BE%BD%E5%8D%97%E4%BA%AC" title="辽南京">
南京析津府
</a>
·
</span>
<span class="nowrap">
西京
<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%BA%9C" title="大同府">
大同府
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E9%87%91%E6%9C%9D" title="金朝">
金
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
上京
<a href="/wiki/%E6%9C%83%E5%AF%A7%E5%BA%9C" title="會寧府">
会宁府
</a>
<small>
<a href="/wiki/%E9%87%91%E4%B8%8A%E4%BA%AC%E4%BC%9A%E5%AE%81%E5%BA%9C%E9%81%97%E5%9D%80" title="金上京会宁府遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%87%91%E4%B8%AD%E9%83%BD" title="金中都">
中都
</a>
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%BA%9C" title="大兴府">
大兴府
</a>
·
</span>
<span class="nowrap">
南京→东京
<a href="/wiki/%E8%BE%BD%E9%98%B3%E5%BA%9C" title="辽阳府">
辽阳府
</a>
·
</span>
<span class="nowrap">
西京
<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%BA%9C" title="大同府">
大同府
</a>
·
</span>
<span class="nowrap">
北京
<a class="mw-redirect" href="/wiki/%E4%B8%B4%E6%BD%A2%E5%BA%9C" title="临潢府">
临潢府
</a>
→
<a href="/wiki/%E5%A4%A7%E5%AE%9A%E5%BA%9C_(%E8%BE%BD%E6%9C%9D)" title="大定府 (辽朝)">
大定府
</a>
·
</span>
<span class="nowrap">
南京
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%BA%9C" title="开封府">
开封府
</a>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%94%E4%BB%A3%E5%8D%81%E5%9B%BD" title="五代十国">
五代
<br/>
十国
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%94%E4%BB%A3%E5%8D%81%E5%9B%BD" title="五代十国">
五代
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<sup>
<a class="mw-redirect" href="/wiki/%E5%BE%8C%E6%A2%81" title="後梁">
後梁
</a>
</sup>
<a class="mw-redirect" href="/wiki/%E9%96%8B%E5%B0%81%E5%BA%9C" title="開封府">
開封府
</a>
</span>
<span class="nowrap">
→
<sup>
<a class="mw-redirect" href="/wiki/%E5%BE%8C%E5%94%90" title="後唐">
後唐
</a>
</sup>
<a class="mw-redirect" href="/wiki/%E6%B4%9B%E9%99%BD" title="洛陽">
洛陽
</a>
</span>
<span class="nowrap">
→
<sup>
<a href="/wiki/%E5%90%8E%E6%99%8B" title="后晋">
后晋
</a>
→
<a href="/wiki/%E5%BE%8C%E6%BC%A2" title="後漢">
後漢
</a>
→
<a class="mw-redirect" href="/wiki/%E5%BE%8C%E5%91%A8" title="後周">
後周
</a>
</sup>
<a class="mw-redirect" href="/wiki/%E9%96%8B%E5%B0%81%E5%BA%9C" title="開封府">
開封府
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%94%E4%BB%A3%E5%8D%81%E5%9B%BD" title="五代十国">
十国
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<sup>
<a href="/wiki/%E5%8D%97%E5%94%90" title="南唐">
南唐
</a>
</sup>
<a href="/wiki/%E6%B1%9F%E5%AE%81%E5%BA%9C" title="江宁府">
江宁府
</a>
<small>
<a href="/wiki/%E9%87%91%E9%99%B5%E5%9F%8E" title="金陵城">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→ 南都
<a href="/wiki/%E5%8D%97%E6%98%8C%E5%BA%9C" title="南昌府">
南昌府
</a>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E5%8C%97%E6%B1%89" title="北汉">
北汉
</a>
</sup>
<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%BA%9C" title="太原府">
太原府
</a>
<small>
<a href="/wiki/%E6%99%8B%E9%98%B3%E5%8F%A4%E5%9F%8E%E9%81%97%E5%9D%80" title="晋阳古城遗址">
[遗址]
</a>
</small>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E8%A5%BF%E5%A4%8F" title="西夏">
西夏
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
东京
<a href="/wiki/%E5%85%B4%E5%BA%86%E5%BA%9C" title="兴庆府">
兴庆府→中兴府
</a>
·
</span>
<span class="nowrap">
西京
<a href="/wiki/%E8%A5%BF%E5%B9%B3%E5%BA%9C" title="西平府">
西平府
</a>
·
</span>
<span class="nowrap">
辅郡
<a href="/wiki/%E8%A5%BF%E5%87%89%E5%BA%9C" title="西凉府">
西凉府
</a>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%AE%8B%E6%9C%9D" title="宋朝">
宋
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
东京
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%BA%9C" title="开封府">
开封府
</a>
(
<a href="/wiki/%E6%B1%B4%E6%A2%81" title="汴梁">
汴梁
</a>
)
<small>
<a href="/wiki/%E5%8C%97%E5%AE%8B%E4%B8%9C%E4%BA%AC%E5%9F%8E%E9%81%97%E5%9D%80" title="北宋东京城遗址">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">
行在
</a>
<a href="/wiki/%E4%B8%B4%E5%AE%89%E5%BA%9C_(%E6%B5%99%E6%B1%9F)" title="临安府 (浙江)">
临安府
</a>
<small>
<a href="/wiki/%E4%B8%B4%E5%AE%89%E5%9F%8E%E9%81%97%E5%9D%80" title="临安城遗址">
[遗址]
</a>
</small>
、
<a class="mw-redirect" href="/wiki/%E8%A1%8C%E9%83%BD" title="行都">
行都
</a>
<a href="/wiki/%E5%BB%BA%E5%BA%B7%E5%BA%9C" title="建康府">
建康府
</a>
·
</span>
<span class="nowrap">
西京
<a href="/wiki/%E6%B2%B3%E5%8D%97%E5%BA%9C" title="河南府">
河南府
</a>
·
</span>
<span class="nowrap">
南京
<a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E5%AE%8B%E6%9C%9D)" title="应天府 (宋朝)">
应天府
</a>
·
</span>
<span class="nowrap">
北京
<a href="/wiki/%E5%A4%A7%E5%90%8D%E5%BA%9C" title="大名府">
大名府
</a>
<small>
<a href="/wiki/%E5%A4%A7%E5%90%8D%E5%BA%9C%E6%95%85%E5%9F%8E" title="大名府故城">
[遗址]
</a>
</small>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%85%83%E6%9C%9D" title="元朝">
元
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E8%92%99%E5%8F%A4%E5%B8%9D%E5%9B%BD" title="蒙古帝国">
<b>
大蒙古国
</b>
</a>
:
<a href="/wiki/%E6%9B%B2%E9%9B%95%E9%98%BF%E5%85%B0" title="曲雕阿兰">
曲雕阿兰
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%93%88%E6%8B%89%E5%92%8C%E6%9E%97" title="哈拉和林">
哈拉和林
</a>
</span>
<span class="nowrap">
→ 上都
<small>
<a href="/wiki/%E5%85%83%E4%B8%8A%E9%83%BD" title="元上都">
[遗址]
</a>
</small>
<br/>
<a href="/wiki/%E5%A4%A7%E9%83%BD%E8%B7%AF" title="大都路">
大都路
</a>
<small>
<a href="/wiki/%E5%85%83%E5%A4%A7%E9%83%BD" title="元大都">
大都(汗八里)
</a>
</small>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%8A%E9%83%BD%E8%B7%AF" title="上都路">
上都路
</a>
<small>
<a href="/wiki/%E5%85%83%E4%B8%8A%E9%83%BD" title="元上都">
[遗址]
</a>
(陪都)
</small>
<br/>
<b>
<a href="/wiki/%E5%8C%97%E5%85%83" title="北元">
北元
</a>
</b>
:上都
<small>
<a href="/wiki/%E5%85%83%E4%B8%8A%E9%83%BD" title="元上都">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→ 应昌城
<small>
<a href="/wiki/%E6%87%89%E6%98%8C%E5%9F%8E" title="應昌城">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%93%88%E6%8B%89%E5%92%8C%E6%9E%97" title="哈拉和林">
哈拉和林
</a>
<br/>
<a href="/wiki/%E5%AF%9F%E5%93%88%E5%B0%94%E9%83%A8" title="察哈尔部">
察哈尔部
</a>
<a href="/wiki/%E6%9E%97%E4%B8%B9%E6%B1%97" title="林丹汗">
林丹汗
</a>
:查干浩特
<small>
<a href="/wiki/%E6%9F%A5%E5%B9%B2%E6%B5%A9%E7%89%B9%E5%9F%8E%E5%9D%80" title="查干浩特城址">
[遗址]
</a>
</small>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%98%8E%E6%9C%9D" title="明朝">
明
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E4%B8%AD%E7%AB%8B%E5%BA%9C" title="中立府">
<del>
<i>
中都中立府
</i>
</del>
</a>
<small>
<a href="/wiki/%E6%98%8E%E4%B8%AD%E9%83%BD%E9%81%97%E5%9D%80" title="明中都遗址">
[遗址]
</a>
</small>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">
京师應天府
</a>
<small>
(后改为留都南京)
</small>
<small>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%9F%8E" title="南京城">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
<a href="/wiki/%E6%B0%B8%E4%B9%90%E8%BF%81%E9%83%BD" title="永乐迁都">
→
</a>
京师
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
<small>
(原为行在)
<a href="/wiki/%E6%98%8E%E6%B8%85%E5%8C%97%E4%BA%AC%E5%9F%8E" title="明清北京城">
[遗址]
</a>
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">
應天府
</a>
</span>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
<sup>
</sup>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%97%E6%98%8E" title="南明">
南明
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<sup>
<a href="/wiki/%E5%BC%98%E5%85%89" title="弘光">
弘光
</a>
</sup>
<a href="/wiki/%E5%BA%94%E5%A4%A9%E5%BA%9C_(%E6%98%8E%E6%9C%9D)" title="应天府 (明朝)">
應天府
</a>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E9%9A%86%E6%AD%A6" title="隆武">
隆武
</a>
</sup>
<a class="mw-redirect" href="/wiki/%E7%A6%8F%E4%BA%AC" title="福京">
福京
</a>
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E5%85%B4%E5%BA%9C" title="天兴府">
天兴府
</a>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E7%BB%8D%E6%AD%A6" title="绍武">
绍武
</a>
</sup>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E6%B0%B8%E6%9B%86_(%E5%8D%97%E6%98%8E)" title="永曆 (南明)">
永历
</a>
</sup>
·
</span>
<span class="nowrap">
<sup>
<a href="/wiki/%E4%B8%9C%E6%AD%A6_(%E5%B9%B4%E5%8F%B7)" title="东武 (年号)">
东武
</a>
</sup>
</span>
</p>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B8%85%E6%9C%9D" title="清朝">
清
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<b>
<a href="/wiki/%E5%90%8E%E9%87%91" title="后金">
后金
</a>
</b>
:
<a href="/wiki/%E8%B2%BB%E9%98%BF%E6%8B%89%E5%9F%8E" title="費阿拉城">
费阿拉(佛阿拉)
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%B5%AB%E5%9B%BE%E9%98%BF%E6%8B%89%E5%9F%8E" title="赫图阿拉城">
赫图阿拉(兴京)
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%95%8C%E8%97%A9%E5%9F%8E" title="界藩城">
界藩城
</a>
<small>
(
<a class="mw-redirect" href="/wiki/%E8%A1%8C%E9%83%BD" title="行都">
行都
</a>
)
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%96%A9%E7%88%BE%E6%BB%B8%E5%9F%8E" title="薩爾滸城">
薩爾滸城
</a>
<small>
(
<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">
行都
</a>
)
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%BE%BD%E9%98%B3%E5%9F%8E" title="辽阳城">
辽阳
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E4%B8%9C%E4%BA%AC%E5%9F%8E" title="东京城">
东京
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%9B%9B%E4%BA%AC%E5%9F%8E" title="盛京城">
盛京
</a>
<a href="/wiki/%E5%A5%89%E5%A4%A9%E5%BA%9C" title="奉天府">
奉天府
</a>
<small>
<a href="/wiki/%E7%9B%9B%E4%BA%AC%E5%9F%8E" title="盛京城">
[遗址]
</a>
</small>
<small>
(后改为留都)
</small>
<br/>
京师
<a class="mw-redirect" href="/wiki/%E9%A1%BA%E5%A4%A9%E5%BA%9C" title="顺天府">
顺天府
</a>
<small>
<a href="/wiki/%E6%98%8E%E6%B8%85%E5%8C%97%E4%BA%AC%E5%9F%8E" title="明清北京城">
[遗址]
</a>
</small>
<small>
[
<b>
<a href="/wiki/%E5%A4%AA%E5%B9%B3%E5%A4%A9%E5%9B%BD" title="太平天国">
太平天国
</a>
</b>
:
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
天京
</a>
]
</small>
</span>
</p>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E9%A6%96%E9%83%BD" title="中華民國首都">
民国
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<p>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E6%B4%8B%E6%94%BF%E5%BA%9C" title="北洋政府">
<b>
民初政府
</b>
</a>
:
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%BA%9C" title="南京府">
南京府
</a>
<small>
(
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E8%87%A8%E6%99%82%E6%94%BF%E5%BA%9C_(1912%E5%B9%B4%EF%BC%8D1913%E5%B9%B4)" title="中華民國臨時政府 (1912年-1913年)">
临时
</a>
)
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E4%BA%AC%E5%85%86%E5%9C%B0%E6%96%B9" title="京兆地方">
北京
</a>
<br/>
<b>
<a href="/wiki/%E5%9C%8B%E6%B0%91%E6%94%BF%E5%BA%9C" title="國民政府">
國民政府
</a>
</b>
:
<a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣州市 (中華民國)">
广州
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">
南京
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳
</a>
<small>
(
<a href="/wiki/%E8%A1%8C%E5%9C%A8" title="行在">
行都
</a>
)、
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="西安市 (中華民國)">
西京
</a>
<small>
(陪都)
</small>
</small>
</span>
<small>
<span class="nowrap">
→
<a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="重慶市 (中華民國)">
重庆
</a>
<small>
(
<a href="/wiki/%E9%87%8D%E5%BA%86%E9%99%AA%E9%83%BD%E6%97%B6%E6%9C%9F" title="重庆陪都时期">
陪都
</a>
)
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">
南京
</a>
<small>
(还都)
</small>
<br/>
<small>
[
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华共和国">
<b>
中华共和国
</b>
</a>
:
<a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">
福州
</a>
][
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E8%8B%8F%E7%BB%B4%E5%9F%83%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华苏维埃共和国">
<b>
中华苏维埃共和国
</b>
</a>
:
<a href="/wiki/%E7%91%9E%E9%87%91%E5%B8%82" title="瑞金市">
瑞京
</a>
→
<a href="/wiki/%E5%BF%97%E4%B8%B9%E5%8E%BF" title="志丹县">
保安
</a>
→
<a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">
延安
</a>
]
</small>
<br/>
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E6%94%BF%E5%BA%9C" title="中華民國政府">
<b>
行宪政府
</b>
</a>
:
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">
南京
</a>
<small>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E6%B0%91%E5%9B%BD%E5%BB%BA%E7%AD%91" title="南京民国建筑">
[遗迹]
</a>
</small>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣州市 (中華民國)">
广州
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="重慶市 (中華民國)">
重庆
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%87%BA%E5%8C%97%E5%B8%82" title="臺北市">
<b>
臺北
</b>
</a>
<small>
(
<a href="/wiki/%E4%B8%AD%E5%A4%AE%E6%94%BF%E5%BA%9C%E6%89%80%E5%9C%A8%E5%9C%B0" title="中央政府所在地">
中央政府所在地
</a>
)
</small>
</span>
</small>
</p>
<small>
</small>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
共和国
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a class="mw-selflink selflink">
<b>
北京
</b>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
参见:
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%8E%86%E5%8F%B2" title="中国历史">
中国历史
</a>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E6%AD%A3%E8%81%8C%E9%A2%86%E5%AF%BC%E4%BA%BA" title="Template:中华人民共和国北京市正职领导人">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E6%AD%A3%E8%81%8C%E9%A2%86%E5%AF%BC%E4%BA%BA" title="Template talk:中华人民共和国北京市正职领导人">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8C%97%E4%BA%AC%E5%B8%82%E6%AD%A3%E8%81%8C%E9%A2%86%E5%AF%BC%E4%BA%BA&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a class="mw-selflink selflink">
北京市
</a>
<a class="mw-redirect" href="/wiki/%E5%85%9A%E5%92%8C%E5%9B%BD%E5%AE%B6%E6%94%BF%E5%BA%9C%E6%9C%BA%E6%9E%84" title="党和国家政府机构">
五大机构
</a>
<a href="/wiki/%E7%9C%81%E9%83%A8%E7%BA%A7%E6%AD%A3%E8%81%8C" title="省部级正职">
正职
</a>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E9%A2%86%E5%AF%BC%E4%BA%BA" title="中华人民共和国省级行政区领导人">
领导人
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%85%B1%E4%BA%A7%E5%85%9A%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国共产党北京市委员会">
市委
</a>
书记
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%BD%AD%E7%9C%9F" title="彭真">
彭 真
</a>
<span class="nowrap">
→
<a href="/wiki/%E6%9D%8E%E9%9B%AA%E5%B3%B0" title="李雪峰">
李雪峰
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%B0%A2%E5%AF%8C%E6%B2%BB" title="谢富治">
谢富治
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%90%B4%E5%BE%B7" title="吴德">
吴 德
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9E%97%E4%B9%8E%E5%8A%A0" title="林乎加">
林乎加
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%AE%B5%E5%90%9B%E6%AF%85" title="段君毅">
段君毅
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9D%8E%E9%94%A1%E9%93%AD" title="李锡铭">
李锡铭
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%99%88%E5%B8%8C%E5%90%8C" title="陈希同">
陈希同
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%B0%89%E5%81%A5%E8%A1%8C" title="尉健行">
尉健行
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%B4%BE%E5%BA%86%E6%9E%97" title="贾庆林">
贾庆林
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%88%98%E6%B7%87" title="刘淇">
刘 淇
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%83%AD%E9%87%91%E9%BE%99" title="郭金龙">
郭金龙
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">
蔡 奇
</a>
</span>
</div>
</td>
<td class="navbox-image" rowspan="9" style="width:0%;padding:0px 0px 0px 2px">
<div>
<a class="image" href="/wiki/File:China_Beijing.svg">
<img alt="China Beijing.svg" data-file-height="850" data-file-width="1000" decoding="async" height="68" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/80px-China_Beijing.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/120px-China_Beijing.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fd/China_Beijing.svg/160px-China_Beijing.svg.png 2x" width="80"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E4%BB%A3%E8%A1%A8%E5%A4%A7%E4%BC%9A%E5%B8%B8%E5%8A%A1%E5%A7%94%E5%91%98%E4%BC%9A" title="北京市人民代表大会常务委员会">
市人大常委会
</a>
主任
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E8%B4%BE%E5%BA%AD%E4%B8%89" title="贾庭三">
贾庭三
</a>
<span class="nowrap">
→
<a href="/wiki/%E8%B5%B5%E9%B9%8F%E9%A3%9E" title="赵鹏飞">
赵鹏飞
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%BC%A0%E5%81%A5%E6%B0%91_(1931%E5%B9%B4)" title="张健民 (1931年)">
张健民
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E4%BA%8E%E5%9D%87%E6%B3%A2" title="于均波">
于均波
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9D%9C%E5%BE%B7%E5%8D%B0" title="杜德印">
杜德印
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9D%8E%E4%BC%9F_(%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E5%A4%A7%E5%B8%B8%E5%A7%94%E4%BC%9A%E4%B8%BB%E4%BB%BB)" title="李伟 (北京市人大常委会主任)">
李 偉
</a>
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C" title="北京市人民政府">
市人民政府
</a>
市长
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%8F%B6%E5%89%91%E8%8B%B1" title="叶剑英">
叶剑英
</a>
<span class="nowrap">
→
<a href="/wiki/%E8%81%82%E8%8D%A3%E8%87%BB" title="聂荣臻">
聂荣臻
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%BD%AD%E7%9C%9F" title="彭真">
彭 真
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%90%B4%E5%BE%B7" title="吴德">
吴 德
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%B0%A2%E5%AF%8C%E6%B2%BB" title="谢富治">
谢富治
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9E%97%E4%B9%8E%E5%8A%A0" title="林乎加">
林乎加
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%84%A6%E8%8B%A5%E6%84%9A" title="焦若愚">
焦若愚
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%99%88%E5%B8%8C%E5%90%8C" title="陈希同">
陈希同
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E6%9D%8E%E5%85%B6%E7%82%8E" title="李其炎">
李其炎
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%B4%BE%E5%BA%86%E6%9E%97" title="贾庆林">
贾庆林
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%88%98%E6%B7%87" title="刘淇">
刘 淇
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%AD%9F%E5%AD%A6%E5%86%9C" title="孟学农">
孟学农
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%8E%8B%E5%B2%90%E5%B1%B1" title="王岐山">
王岐山
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%83%AD%E9%87%91%E9%BE%99" title="郭金龙">
郭金龙
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%8E%8B%E5%AE%89%E9%A1%BA" title="王安顺">
王安顺
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%94%A1%E5%A5%87" title="蔡奇">
蔡 奇
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%99%88%E5%90%89%E5%AE%81" title="陈吉宁">
陈吉宁
</a>
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E6%94%BF%E6%B2%BB%E5%8D%8F%E5%95%86%E4%BC%9A%E8%AE%AE%E5%8C%97%E4%BA%AC%E5%B8%82%E5%A7%94%E5%91%98%E4%BC%9A" title="中国人民政治协商会议北京市委员会">
市政协
</a>
主席
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%88%98%E4%BB%81" title="刘仁">
刘 仁
</a>
<span class="nowrap">
→
<a href="/wiki/%E4%B8%81%E5%9B%BD%E9%92%B0" title="丁国钰">
丁国钰
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%B5%B5%E9%B9%8F%E9%A3%9E" title="赵鹏飞">
赵鹏飞
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%88%98%E5%AF%BC%E7%94%9F" title="刘导生">
刘导生
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E8%8C%83%E7%91%BE" title="范瑾">
范 瑾
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%99%BD%E4%BB%8B%E5%A4%AB" title="白介夫">
白介夫
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%8E%8B%E5%A4%A7%E6%98%8E" title="王大明">
王大明
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%99%88%E5%B9%BF%E6%96%87" title="陈广文">
陈广文
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%A8%8B%E4%B8%96%E5%B3%A8" title="程世峨">
程世峨
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E9%98%B3%E5%AE%89%E6%B1%9F" title="阳安江">
阳安江
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E7%8E%8B%E5%AE%89%E9%A1%BA" title="王安顺">
王安顺
</a>
</span>
<span class="nowrap">
→
<a href="/wiki/%E5%90%89%E6%9E%97_(%E4%BA%BA%E7%89%A9)" title="吉林 (人物)">
吉 林
</a>
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82%E7%9B%91%E5%AF%9F%E5%A7%94%E5%91%98%E4%BC%9A" title="北京市监察委员会">
市监察委
</a>
主任
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%BC%A0%E7%A1%95%E8%BE%85" title="张硕辅">
张硕辅
</a>
<span class="nowrap">
→
<a href="/wiki/%E9%99%88%E9%9B%8D" title="陈雍">
陈 雍
</a>
</span>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国超大城市">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="new" href="/w/index.php?title=Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82&action=edit&redlink=1" title="Template talk:中华人民共和国超大城市(页面不存在)">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%B6%85%E5%A4%A7%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国超大城市列表">
超大城市
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a class="mw-selflink selflink">
北京
</a>
·
<span class="nowrap">
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉
</a>
</span>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
超大城市为城区常住人口超过1000万的
<a href="/wiki/%E5%9F%8E%E5%B8%82" title="城市">
城市
</a>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table class="navbox nav" width="100%">
<tbody>
<tr>
<th colspan="10" style="padding: 0.2em 1em 0.2em 1em; line-height: 1.3em;">
<div class="plainlinks hlist navbar mini" style="float: left;">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%9C%80%E5%A4%9A%E7%9A%84%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国人口最多的城市">
<abbr title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="new" href="/w/index.php?title=Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%9C%80%E5%A4%9A%E7%9A%84%E5%9F%8E%E5%B8%82&action=edit&redlink=1" title="Template talk:中华人民共和国人口最多的城市(页面不存在)">
<abbr title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BA%BA%E5%8F%A3%E6%9C%80%E5%A4%9A%E7%9A%84%E5%9F%8E%E5%B8%82&action=edit">
<abbr title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<span style="font-size:120%;">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
最大城市排名
</span>
<br/>
<span style="font-weight:normal;">
<small>
数据来源:《中国城市建设统计年鉴2018》“城区人口”与“城区暂住人口”指标
</small>
</span>
</th>
</tr>
<tr>
<th>
</th>
<th>
排名
</th>
<th>
城市名稱
</th>
<th>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
省市
</a>
</th>
<th>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国城市列表">
人口
</a>
</th>
<th>
排名
</th>
<th>
城市名稱
</th>
<th>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
省市
</a>
</th>
<th>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国城市列表">
人口
</a>
</th>
<th>
</th>
</tr>
<tr>
<td align="center" rowspan="10">
<a class="image" href="/wiki/File:Lujiazui_2016.jpg" title="上海">
<img alt="上海" class="thumbborder" data-file-height="1200" data-file-width="1800" decoding="async" height="90" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Lujiazui_2016.jpg/135px-Lujiazui_2016.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Lujiazui_2016.jpg/203px-Lujiazui_2016.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Lujiazui_2016.jpg/270px-Lujiazui_2016.jpg 2x" width="135"/>
</a>
<br/>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
<br/>
<p>
<a class="image" href="/wiki/File:Beijing_skyline_from_northeast_4th_ring_road_(cropped).jpg" title="北京">
<img alt="北京" class="thumbborder" data-file-height="1843" data-file-width="2755" decoding="async" height="90" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/da/Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg/135px-Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/da/Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg/203px-Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/da/Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg/270px-Beijing_skyline_from_northeast_4th_ring_road_%28cropped%29.jpg 2x" width="135"/>
</a>
<br/>
<a class="mw-selflink selflink">
北京
</a>
</p>
</td>
<td align="center" style="background:#f0f0f0;">
1
</td>
<td align="left">
<b>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
</b>
</td>
<td align="left">
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
24,237,800
</td>
<td align="center" style="background:#f0f0f0;">
11
</td>
<td align="left">
<b>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E6%B1%9F%E8%8B%8F" title="江苏">
江苏
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
6,572,000
</td>
<td align="center" rowspan="10">
<a class="image" href="/wiki/File:Tianhe_CBD.jpg" title="广州">
<img alt="广州" class="thumbborder" data-file-height="2592" data-file-width="3888" decoding="async" height="90" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Tianhe_CBD.jpg/135px-Tianhe_CBD.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Tianhe_CBD.jpg/203px-Tianhe_CBD.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a7/Tianhe_CBD.jpg/270px-Tianhe_CBD.jpg 2x" width="135"/>
</a>
<br/>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州
</a>
<br/>
<p>
<a class="image" href="/wiki/File:Futian_District_2017.jpg" title="深圳">
<img alt="深圳" class="thumbborder" data-file-height="2112" data-file-width="3168" decoding="async" height="90" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/46/Futian_District_2017.jpg/135px-Futian_District_2017.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/46/Futian_District_2017.jpg/203px-Futian_District_2017.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/46/Futian_District_2017.jpg/270px-Futian_District_2017.jpg 2x" width="135"/>
</a>
<br/>
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳
</a>
</p>
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
2
</td>
<td align="left">
<b>
<a class="mw-selflink selflink">
北京
</a>
</b>
</td>
<td align="left">
<a class="mw-selflink selflink">
北京
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
18,634,000
</td>
<td align="center" style="background:#f0f0f0;">
12
</td>
<td align="left">
<b>
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E6%B5%99%E6%B1%9F" title="浙江">
浙江
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
6,504,900
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
3
</td>
<td align="left">
<b>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E4%B8%9C" title="广东">
广东
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
13,154,200
</td>
<td align="center" style="background:#f0f0f0;">
13
</td>
<td align="left">
<b>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E6%B2%B3%E5%8D%97" title="河南">
河南
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
6,261,900
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
4
</td>
<td align="left">
<b>
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E4%B8%9C" title="广东">
广东
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
13,026,600
</td>
<td align="center" style="background:#f0f0f0;">
14
</td>
<td align="left">
<b>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E9%99%95%E8%A5%BF" title="陕西">
陕西
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
5,866,100
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
5
</td>
<td align="left">
<b>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
</b>
</td>
<td align="left">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
12,968,100
</td>
<td align="center" style="background:#f0f0f0;">
15
</td>
<td align="left">
<b>
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
沈阳
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E8%BE%BD%E5%AE%81" title="辽宁">
辽宁
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
5,651,200
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
6
</td>
<td align="left">
<b>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆
</a>
</b>
</td>
<td align="left">
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
11,488,000
</td>
<td align="center" style="background:#f0f0f0;">
16
</td>
<td align="left">
<b>
<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">
青岛
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%B1%B1%E4%B8%9C" title="山东">
山东
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
5,127,000
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
7
</td>
<td align="left">
<b>
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E6%B9%96%E5%8C%97" title="湖北">
湖北
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
9,180,000
</td>
<td align="center" style="background:#f0f0f0;">
17
</td>
<td align="left">
<b>
<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">
哈尔滨
</a>
</b>
</td>
<td align="left">
<a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F" title="黑龙江">
黑龙江
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
4,860,000
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
8
</td>
<td align="left">
<b>
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%9B%9B%E5%B7%9D" title="四川">
四川
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
8,379,700
</td>
<td align="center" style="background:#f0f0f0;">
18
</td>
<td align="left">
<b>
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">
长春
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%90%89%E6%9E%97" title="吉林">
吉林
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
4,564,000
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
9
</td>
<td align="left">
<b>
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港
</a>
</b>
</td>
<td align="left">
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
7,448,900
</td>
<td align="center" style="background:#f0f0f0;">
19
</td>
<td align="left">
<b>
<a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">
合肥
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%AE%89%E5%BE%BD" title="安徽">
安徽
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
4,292,400
</td>
</tr>
<tr>
<td align="center" style="background:#f0f0f0;">
10
</td>
<td align="left">
<b>
<a href="/wiki/%E4%B8%9C%E8%8E%9E%E5%B8%82" title="东莞市">
东莞
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E4%B8%9C" title="广东">
广东
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
6,850,300
</td>
<td align="center" style="background:#f0f0f0;">
20
</td>
<td align="left">
<b>
<a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">
济南
</a>
</b>
</td>
<td align="left">
<a class="mw-redirect" href="/wiki/%E5%B1%B1%E4%B8%9C" title="山东">
山东
</a>
</td>
<td style="text-align:right;padding:0 0.3em 0 0;">
4,154,900
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col" style="background: SaddleBrown; color:#ffffff;">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a class="mw-redirect" href="/wiki/Template:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="Template:国家历史文化名城">
<abbr style=";background: SaddleBrown; color:#ffffff;;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="mw-redirect" href="/wiki/Template_talk:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="Template talk:国家历史文化名城">
<abbr style=";background: SaddleBrown; color:#ffffff;;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E&action=edit">
<abbr style=";background: SaddleBrown; color:#ffffff;;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<span class="flagicon">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
<img alt="中华人民共和国" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
<span style="color:white;">
中华人民共和国
</span>
</a>
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="国家历史文化名城">
<span style="color:white;">
国家历史文化名城
</span>
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2" style="background: Sienna; color:#ffffff;">
<div>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%8A%A1%E9%99%A2" title="中华人民共和国国务院">
<span style="color:white;">
中华人民共和国国务院
</span>
</a>
公布,共
<b>
135
</b>
处(截至2018年5月2日):
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区">
<span style="color:white;">
华北
</span>
</a>
<br/>
14
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a class="mw-selflink selflink">
<span style="color:white;">
北 京
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
<span style="color:white;">
天 津
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
<span style="color:white;">
河 北
</span>
</a>
<sub>
6
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">
承德市
</a>
</li>
<li>
<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">
保定市
</a>
</li>
<li>
石家庄市
<ul>
<li>
<a href="/wiki/%E6%AD%A3%E5%AE%9A%E5%8E%BF" title="正定县">
正定县
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E9%82%AF%E9%83%B8%E5%B8%82" title="邯郸市">
邯郸市
</a>
</li>
<li>
秦皇岛市
<ul>
<li>
<a href="/wiki/%E5%B1%B1%E6%B5%B7%E5%85%B3%E5%8C%BA" title="山海关区">
山海关区
</a>
</li>
</ul>
</li>
<li>
张家口市
<ul>
<li>
<a href="/wiki/%E8%94%9A%E5%8E%BF" title="蔚县">
蔚县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">
<span style="color:white;">
山 西
</span>
</a>
<sub>
6
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">
大同市
</a>
</li>
<li>
晋中市
<ul>
<li>
<a href="/wiki/%E5%B9%B3%E9%81%A5%E5%8E%BF" title="平遥县">
平遥县
</a>
</li>
</ul>
</li>
<li>
运城市
<ul>
<li>
<a href="/wiki/%E6%96%B0%E7%BB%9B%E5%8E%BF" title="新绛县">
新绛县
</a>
</li>
</ul>
</li>
<li>
忻州市
<ul>
<li>
<a href="/wiki/%E4%BB%A3%E5%8E%BF" title="代县">
代县
</a>
</li>
</ul>
</li>
<li>
晋中市
<ul>
<li>
<a href="/wiki/%E7%A5%81%E5%8E%BF" title="祁县">
祁县
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">
太原市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">
<span style="color:white;">
内蒙古
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">
呼和浩特市
</a>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%9C%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国东北地区">
<span style="color:white;">
东北
</span>
</a>
<br/>
6
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">
<span style="color:white;">
辽 宁
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
沈阳市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">
<span style="color:white;">
吉 林
</span>
</a>
<sub>
3
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%90%89%E6%9E%97%E5%B8%82" title="吉林市">
吉林市
</a>
</li>
<li>
通化市
<ul>
<li>
<a href="/wiki/%E9%9B%86%E5%AE%89%E5%B8%82" title="集安市">
集安市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">
长春市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">
<span style="color:white;">
黑龙江
</span>
</a>
<sub>
2
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">
哈尔滨市
</a>
</li>
<li>
<a href="/wiki/%E9%BD%90%E9%BD%90%E5%93%88%E5%B0%94%E5%B8%82" title="齐齐哈尔市">
齐齐哈尔市
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%8D%8E%E4%B8%9C%E5%9C%B0%E5%8C%BA" title="华东地区">
<span style="color:white;">
华东
</span>
</a>
<br/>
47
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
<span style="color:white;">
上 海
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">
<span style="color:white;">
江 苏
</span>
</a>
<sub>
13
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京市
</a>
</li>
<li>
<a href="/wiki/%E8%8B%8F%E5%B7%9E%E5%B8%82" title="苏州市">
苏州市
</a>
</li>
<li>
<a href="/wiki/%E6%89%AC%E5%B7%9E%E5%B8%82" title="扬州市">
扬州市
</a>
</li>
<li>
<a href="/wiki/%E9%95%87%E6%B1%9F%E5%B8%82" title="镇江市">
镇江市
</a>
</li>
<li>
苏州市
<ul>
<li>
<a href="/wiki/%E5%B8%B8%E7%86%9F%E5%B8%82" title="常熟市">
常熟市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E5%BE%90%E5%B7%9E%E5%B8%82" title="徐州市">
徐州市
</a>
</li>
<li>
淮安市
<ul>
<li>
<a href="/wiki/%E6%B7%AE%E5%AE%89%E5%8C%BA" title="淮安区">
淮安区
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%97%A0%E9%94%A1%E5%B8%82" title="无锡市">
无锡市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E9%80%9A%E5%B8%82" title="南通市">
南通市
</a>
</li>
<li>
无锡市
<ul>
<li>
<a href="/wiki/%E5%AE%9C%E5%85%B4%E5%B8%82" title="宜兴市">
宜兴市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%B3%B0%E5%B7%9E%E5%B8%82" title="泰州市">
泰州市
</a>
</li>
<li>
<a href="/wiki/%E5%B8%B8%E5%B7%9E%E5%B8%82" title="常州市">
常州市
</a>
</li>
<li>
扬州市
<ul>
<li>
<a href="/wiki/%E9%AB%98%E9%82%AE%E5%B8%82" title="高邮市">
高邮市
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">
<span style="color:white;">
浙 江
</span>
</a>
<sub>
10
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州市
</a>
</li>
<li>
<a href="/wiki/%E7%BB%8D%E5%85%B4%E5%B8%82" title="绍兴市">
绍兴市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">
宁波市
</a>
</li>
<li>
<a href="/wiki/%E8%A1%A2%E5%B7%9E%E5%B8%82" title="衢州市">
衢州市
</a>
</li>
<li>
台州市
<ul>
<li>
<a href="/wiki/%E4%B8%B4%E6%B5%B7%E5%B8%82" title="临海市">
临海市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E9%87%91%E5%8D%8E%E5%B8%82" title="金华市">
金华市
</a>
</li>
<li>
<a href="/wiki/%E5%98%89%E5%85%B4%E5%B8%82" title="嘉兴市">
嘉兴市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%96%E5%B7%9E%E5%B8%82" title="湖州市">
湖州市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%A9%E5%B7%9E%E5%B8%82" title="温州市">
温州市
</a>
</li>
<li>
丽水市
<ul>
<li>
<a href="/wiki/%E9%BE%99%E6%B3%89%E5%B8%82" title="龙泉市">
龙泉市
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">
<span style="color:white;">
安 徽
</span>
</a>
<sub>
5
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
黄山市
<ul>
<li>
<a href="/wiki/%E6%AD%99%E5%8E%BF" title="歙县">
歙县
</a>
</li>
</ul>
</li>
<li>
淮南市
<ul>
<li>
<a href="/wiki/%E5%AF%BF%E5%8E%BF" title="寿县">
寿县
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E4%BA%B3%E5%B7%9E%E5%B8%82" title="亳州市">
亳州市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E5%BA%86%E5%B8%82" title="安庆市">
安庆市
</a>
</li>
<li>
宣城市
<ul>
<li>
<a href="/wiki/%E7%BB%A9%E6%BA%AA%E5%8E%BF" title="绩溪县">
绩溪县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">
<span style="color:white;">
山 东
</span>
</a>
<sub>
10
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
济宁市
<ul>
<li>
<a href="/wiki/%E6%9B%B2%E9%98%9C%E5%B8%82" title="曲阜市">
曲阜市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">
济南市
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">
青岛市
</a>
</li>
<li>
<a href="/wiki/%E8%81%8A%E5%9F%8E%E5%B8%82" title="聊城市">
聊城市
</a>
</li>
<li>
济宁市
<ul>
<li>
<a href="/wiki/%E9%82%B9%E5%9F%8E%E5%B8%82" title="邹城市">
邹城市
</a>
</li>
</ul>
</li>
<li>
淄博市
<ul>
<li>
<a href="/wiki/%E4%B8%B4%E6%B7%84%E5%8C%BA" title="临淄区">
临淄区
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%B3%B0%E5%AE%89%E5%B8%82" title="泰安市">
泰安市
</a>
</li>
<li>
<a href="/wiki/%E7%83%9F%E5%8F%B0%E5%B8%82" title="烟台市">
烟台市
</a>
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E8%93%AC%E8%8E%B1%E5%B8%82" title="蓬莱市">
蓬莱市
</a>
</li>
</ul>
</li>
<li>
潍坊市
<ul>
<li>
<a href="/wiki/%E9%9D%92%E5%B7%9E%E5%B8%82" title="青州市">
青州市
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
<span style="color:white;">
福 建
</span>
</a>
<sub>
4
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B3%89%E5%B7%9E%E5%B8%82" title="泉州市">
泉州市
</a>
</li>
<li>
<a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">
福州市
</a>
</li>
<li>
<a href="/wiki/%E6%BC%B3%E5%B7%9E%E5%B8%82" title="漳州市">
漳州市
</a>
</li>
<li>
龙岩市
<ul>
<li>
<a href="/wiki/%E9%95%BF%E6%B1%80%E5%8E%BF" title="长汀县">
长汀县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">
<span style="color:white;">
江 西
</span>
</a>
<sub>
4
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%99%AF%E5%BE%B7%E9%95%87%E5%B8%82" title="景德镇市">
景德镇市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">
南昌市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%A3%E5%B7%9E%E5%B8%82" title="赣州市">
赣州市
</a>
</li>
<li>
赣州市
<ul>
<li>
<a href="/wiki/%E7%91%9E%E9%87%91%E5%B8%82" title="瑞金市">
瑞金市
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中南地区">
<span style="color:white;">
中南
</span>
</a>
<br/>
30
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">
<span style="color:white;">
河 南
</span>
</a>
<sub>
8
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
开封市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">
安阳市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E9%98%B3%E5%B8%82" title="南阳市">
南阳市
</a>
</li>
<li>
商丘市
<ul>
<li>
<a href="/wiki/%E7%9D%A2%E9%98%B3%E5%8C%BA" title="睢阳区">
睢阳区
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州市
</a>
</li>
<li>
鹤壁市
<ul>
<li>
<a href="/wiki/%E6%B5%9A%E5%8E%BF" title="浚县">
浚县
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%BF%AE%E9%98%B3%E5%B8%82" title="濮阳市">
濮阳市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">
<span style="color:white;">
湖 北
</span>
</a>
<sub>
5
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
荆州市
<ul>
<li>
<a href="/wiki/%E8%8D%86%E5%B7%9E%E5%8C%BA" title="荆州区">
荆州区
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉市
</a>
</li>
<li>
<a href="/wiki/%E8%A5%84%E9%98%B3%E5%B8%82" title="襄阳市">
襄阳市
</a>
</li>
<li>
<a href="/wiki/%E9%9A%8F%E5%B7%9E%E5%B8%82" title="随州市">
随州市
</a>
</li>
<li>
荆门市
<ul>
<li>
<a href="/wiki/%E9%92%9F%E7%A5%A5%E5%B8%82" title="钟祥市">
钟祥市
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">
<span style="color:white;">
湖 南
</span>
</a>
<sub>
4
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">
长沙市
</a>
</li>
<li>
<a href="/wiki/%E5%B2%B3%E9%98%B3%E5%B8%82" title="岳阳市">
岳阳市
</a>
</li>
<li>
湘西土家族苗族自治州
<ul>
<li>
<a href="/wiki/%E5%87%A4%E5%87%B0%E5%8E%BF" title="凤凰县">
凤凰县
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%B0%B8%E5%B7%9E%E5%B8%82" title="永州市">
永州市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">
<span style="color:white;">
广 东
</span>
</a>
<sub>
8
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州市
</a>
</li>
<li>
<a href="/wiki/%E6%BD%AE%E5%B7%9E%E5%B8%82" title="潮州市">
潮州市
</a>
</li>
<li>
<a href="/wiki/%E8%82%87%E5%BA%86%E5%B8%82" title="肇庆市">
肇庆市
</a>
</li>
<li>
<a href="/wiki/%E4%BD%9B%E5%B1%B1%E5%B8%82" title="佛山市">
佛山市
</a>
</li>
<li>
<a href="/wiki/%E6%A2%85%E5%B7%9E%E5%B8%82" title="梅州市">
梅州市
</a>
</li>
<li>
湛江市
<ul>
<li>
<a href="/wiki/%E9%9B%B7%E5%B7%9E%E5%B8%82" title="雷州市">
雷州市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E4%B8%AD%E5%B1%B1%E5%B8%82" title="中山市">
中山市
</a>
</li>
<li>
<a href="/wiki/%E6%83%A0%E5%B7%9E%E5%B8%82" title="惠州市">
惠州市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">
<span style="color:white;">
广 西
</span>
</a>
<sub>
3
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%A1%82%E6%9E%97%E5%B8%82" title="桂林市">
桂林市
</a>
</li>
<li>
<a href="/wiki/%E6%9F%B3%E5%B7%9E%E5%B8%82" title="柳州市">
柳州市
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E6%B5%B7%E5%B8%82" title="北海市">
北海市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
<span style="color:white;">
海 南
</span>
</a>
<sub>
2
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
海口市
<ul>
<li>
<a href="/wiki/%E7%90%BC%E5%B1%B1%E5%8C%BA" title="琼山区">
琼山区
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">
海口市
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中国西南地区">
<span style="color:white;">
西南
</span>
</a>
<br/>
20
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">
<span style="color:white;">
四 川
</span>
</a>
<sub>
8
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都市
</a>
</li>
<li>
<a href="/wiki/%E8%87%AA%E8%B4%A1%E5%B8%82" title="自贡市">
自贡市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E5%AE%BE%E5%B8%82" title="宜宾市">
宜宾市
</a>
</li>
<li>
南充市
<ul>
<li>
<a href="/wiki/%E9%98%86%E4%B8%AD%E5%B8%82" title="阆中市">
阆中市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E4%B9%90%E5%B1%B1%E5%B8%82" title="乐山市">
乐山市
</a>
</li>
<li>
成都市
<ul>
<li>
<a href="/wiki/%E9%83%BD%E6%B1%9F%E5%A0%B0%E5%B8%82" title="都江堰市">
都江堰市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%B3%B8%E5%B7%9E%E5%B8%82" title="泸州市">
泸州市
</a>
</li>
<li>
凉山彝族自治州
<ul>
<li>
<a href="/wiki/%E4%BC%9A%E7%90%86%E5%8E%BF" title="会理县">
会理县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
<span style="color:white;">
重 庆
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">
<span style="color:white;">
贵 州
</span>
</a>
<sub>
2
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%81%B5%E4%B9%89%E5%B8%82" title="遵义市">
遵义市
</a>
</li>
<li>
黔东南苗族侗族自治州
<ul>
<li>
<a href="/wiki/%E9%95%87%E8%BF%9C%E5%8E%BF" title="镇远县">
镇远县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">
<span style="color:white;">
云 南
</span>
</a>
<sub>
6
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">
昆明市
</a>
</li>
<li>
大理白族自治州
<ul>
<li>
<a href="/wiki/%E5%A4%A7%E7%90%86%E5%B8%82" title="大理市">
大理市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E4%B8%BD%E6%B1%9F%E5%B8%82" title="丽江市">
丽江市
</a>
</li>
<li>
红河哈尼族彝族自治州
<ul>
<li>
<a href="/wiki/%E5%BB%BA%E6%B0%B4%E5%8E%BF" title="建水县">
建水县
</a>
</li>
</ul>
</li>
<li>
大理白族自治州
<ul>
<li>
<a href="/wiki/%E5%B7%8D%E5%B1%B1%E5%BD%9D%E6%97%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8E%BF" title="巍山彝族回族自治县">
巍山彝族回族自治县
</a>
</li>
</ul>
</li>
<li>
曲靖市
<ul>
<li>
<a href="/wiki/%E4%BC%9A%E6%B3%BD%E5%8E%BF" title="会泽县">
会泽县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">
<span style="color:white;">
西 藏
</span>
</a>
<sub>
3
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%8B%89%E8%90%A8%E5%B8%82" title="拉萨市">
拉萨市
</a>
</li>
<li>
日喀则市
<a href="/wiki/%E6%A1%91%E7%8F%A0%E5%AD%9C%E5%8C%BA" title="桑珠孜区">
桑珠孜区
</a>
</li>
<li>
日喀则市
<a href="/wiki/%E6%B1%9F%E5%AD%9C%E5%8E%BF" title="江孜县">
江孜县
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国西北地区">
<span style="color:white;">
西北
</span>
</a>
<br/>
17
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">
<span style="color:white;">
陕 西
</span>
</a>
<sub>
6
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安市
</a>
</li>
<li>
<a href="/wiki/%E5%92%B8%E9%98%B3%E5%B8%82" title="咸阳市">
咸阳市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">
延安市
</a>
</li>
<li>
渭南市
<ul>
<li>
<a href="/wiki/%E9%9F%A9%E5%9F%8E%E5%B8%82" title="韩城市">
韩城市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E6%A6%86%E6%9E%97%E5%B8%82" title="榆林市">
榆林市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%89%E4%B8%AD%E5%B8%82" title="汉中市">
汉中市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">
<span style="color:white;">
甘 肃
</span>
</a>
<sub>
4
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%AD%A6%E5%A8%81%E5%B8%82" title="武威市">
武威市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%A0%E6%8E%96%E5%B8%82" title="张掖市">
张掖市
</a>
</li>
<li>
酒泉市
<ul>
<li>
<a href="/wiki/%E6%95%A6%E7%85%8C%E5%B8%82" title="敦煌市">
敦煌市
</a>
</li>
</ul>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B0%B4%E5%B8%82" title="天水市">
天水市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">
<span style="color:white;">
青 海
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
黄南藏族自治州
<ul>
<li>
<a href="/wiki/%E5%90%8C%E4%BB%81%E5%B8%82" title="同仁市">
同仁市
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">
<span style="color:white;">
宁 夏
</span>
</a>
<sub>
1
</sub>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">
银川市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color: SaddleBrown; text-align: center;">
<a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">
<span style="color:white;">
新 疆
</span>
</a>
<sub>
5
</sub>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
喀什地区
<ul>
<li>
<a href="/wiki/%E5%96%80%E4%BB%80%E5%B8%82" title="喀什市">
喀什市
</a>
</li>
</ul>
</li>
<li>
吐鲁番市
<ul>
<li>
<a href="/wiki/%E9%AB%98%E6%98%8C%E5%8C%BA" title="高昌区">
高昌区
</a>
</li>
</ul>
</li>
<li>
伊犁哈萨克自治州
<ul>
<li>
<a href="/wiki/%E4%BC%8A%E5%AE%81%E5%B8%82" title="伊宁市">
伊宁市
</a>
</li>
<li>
<a href="/wiki/%E7%89%B9%E5%85%8B%E6%96%AF%E5%8E%BF" title="特克斯县">
特克斯县
</a>
</li>
</ul>
</li>
<li>
阿克苏地区
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E5%BA%93%E8%BD%A6%E5%8E%BF" title="库车县">
库车县
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD" title="Template:亞洲首都">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD" title="Template talk:亞洲首都">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a class="mw-redirect" href="/wiki/%E4%BA%9E%E6%B4%B2" title="亞洲">
亞洲
</a>
<a href="/wiki/%E9%A6%96%E9%83%BD" title="首都">
首都
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
<i>
<b>
粗斜體
</b>
</i>
为
<a class="mw-redirect" href="/wiki/%E6%9C%AA%E8%A2%AB%E6%99%AE%E9%81%8D%E6%89%BF%E8%AE%A4%E7%9A%84%E5%9B%BD%E5%AE%B6%E5%88%97%E8%A1%A8" title="未被普遍承认的国家列表">
未被国际普遍承认国家
</a>
的首都或未被国际普遍承认的首都。
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="width: 10%;">
<b>
<a href="/wiki/%E4%B8%AD%E4%BA%9A" title="中亚">
中亚
</a>
</b>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<b>
<a class="mw-redirect" href="/wiki/%E5%8A%AA%E5%B0%94-%E8%8B%8F%E4%B8%B9" title="努尔-苏丹">
努尔-苏丹
</a>
</b>
(
<a href="/wiki/%E5%93%88%E8%90%A8%E5%85%8B%E6%96%AF%E5%9D%A6" title="哈萨克斯坦">
哈萨克斯坦
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%AF%94%E4%BB%80%E5%87%AF%E5%85%8B" title="比什凯克">
比什凯克
</a>
</b>
(
<a href="/wiki/%E5%90%89%E5%B0%94%E5%90%89%E6%96%AF%E6%96%AF%E5%9D%A6" title="吉尔吉斯斯坦">
吉尔吉斯斯坦
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%9D%9C%E5%B0%9A%E5%88%AB" title="杜尚别">
杜尚别
</a>
</b>
(
<a href="/wiki/%E5%A1%94%E5%90%89%E5%85%8B%E6%96%AF%E5%9D%A6" title="塔吉克斯坦">
塔吉克斯坦
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%98%BF%E4%BB%80%E5%93%88%E5%B7%B4%E5%BE%B7" title="阿什哈巴德">
阿什哈巴德
</a>
</b>
(
<a href="/wiki/%E5%9C%9F%E5%BA%93%E6%9B%BC%E6%96%AF%E5%9D%A6" title="土库曼斯坦">
土库曼斯坦
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%A1%94%E4%BB%80%E5%B9%B2" title="塔什干">
塔什干
</a>
</b>
(
<a href="/wiki/%E4%B9%8C%E5%85%B9%E5%88%AB%E5%85%8B%E6%96%AF%E5%9D%A6" title="乌兹别克斯坦">
乌兹别克斯坦
</a>
)
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="width: 10%;">
<b>
<a class="mw-redirect" href="/wiki/%E6%9D%B1%E4%BA%9E" title="東亞">
東亞
</a>
</b>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<b>
<a class="mw-selflink selflink">
北京
</a>
</b>
(
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">
東京
</a>
</b>
<sup>
<small>
1
</small>
</sup>
(
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
日本
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%B9%B3%E5%A3%A4" title="平壤">
平壤
</a>
</b>
(
<a href="/wiki/%E6%9C%9D%E9%B2%9C%E6%B0%91%E4%B8%BB%E4%B8%BB%E4%B9%89%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="朝鲜民主主义人民共和国">
朝鲜
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%A6%96%E7%88%BE" title="首爾">
首爾
</a>
</b>
(
<a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国">
韩国
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E4%B9%8C%E5%85%B0%E5%B7%B4%E6%89%98" title="乌兰巴托">
乌兰巴托
</a>
</b>
(
<a href="/wiki/%E8%92%99%E5%8F%A4%E5%9B%BD" title="蒙古国">
蒙古
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E8%87%BA%E5%8C%97%E5%B8%82" title="臺北市">
臺北
</a>
</b>
</i>
<sup>
<small>
2
</small>
</sup>
(
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
)
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="width: 10%;">
<b>
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%9E" title="南亞">
南亞
</a>
</b>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<b>
<a href="/wiki/%E8%BE%BE%E5%8D%A1" title="达卡">
达卡
</a>
</b>
(
<a href="/wiki/%E5%AD%9F%E5%8A%A0%E6%8B%89%E5%9B%BD" title="孟加拉国">
孟加拉
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%BB%B7%E5%B8%83" title="廷布">
廷布
</a>
</b>
(
<a href="/wiki/%E4%B8%8D%E4%B8%B9" title="不丹">
不丹
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%96%B0%E5%BE%B7%E9%87%8C" title="新德里">
新德里
</a>
</b>
(
<a href="/wiki/%E5%8D%B0%E5%BA%A6" title="印度">
印度
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%A6%AC%E7%B4%AF" title="馬累">
马累
</a>
</b>
(
<a href="/wiki/%E9%A9%AC%E5%B0%94%E4%BB%A3%E5%A4%AB" title="马尔代夫">
马尔代夫
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%8A%A0%E5%BE%B7%E6%BB%BF%E9%83%BD" title="加德滿都">
加德滿都
</a>
</b>
(
<a href="/wiki/%E5%B0%BC%E6%B3%8A%E5%B0%94" title="尼泊尔">
尼泊尔
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E4%BC%8A%E6%96%AF%E5%85%B0%E5%A0%A1" title="伊斯兰堡">
伊斯兰堡
</a>
</b>
(
<a href="/wiki/%E5%B7%B4%E5%9F%BA%E6%96%AF%E5%9D%A6" title="巴基斯坦">
巴基斯坦
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%96%AF%E9%87%8C%E8%B3%88%E4%BA%9E%E7%93%A6%E5%BE%B7%E7%B4%8D%E6%99%AE%E6%8B%89%E7%A7%91%E7%89%B9" title="斯里賈亞瓦德納普拉科特">
科特
</a>
</b>
<sup>
<small>
3
</small>
</sup>
<span style="font-size:smaller;">
(正式首都)
</span>
與
<b>
<a href="/wiki/%E5%8F%AF%E5%80%AB%E5%9D%A1" title="可倫坡">
科伦坡
</a>
</b>
<span style="font-size:smaller;">
(行政首都)
</span>
(
<a href="/wiki/%E6%96%AF%E9%87%8C%E8%98%AD%E5%8D%A1" title="斯里蘭卡">
斯里蘭卡
</a>
)
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="width: 10%;">
<b>
<a class="mw-redirect" href="/wiki/%E6%9D%B1%E5%8D%97%E4%BA%9E" title="東南亞">
東南亞
</a>
</b>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<b>
<a class="mw-redirect" href="/wiki/%E6%96%AF%E9%87%8C%E5%B7%B4%E5%8A%A0%E7%81%A3%E5%B8%82" title="斯里巴加灣市">
斯里巴加灣市
</a>
</b>
(
<a href="/wiki/%E6%B1%B6%E8%8E%B1" title="汶莱">
文莱
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%87%91%E8%BE%B9" title="金边">
金边
</a>
</b>
(
<a href="/wiki/%E6%9F%AC%E5%9F%94%E5%AF%A8" title="柬埔寨">
柬埔寨
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%B8%9D%E5%8A%9B" title="帝力">
帝力
</a>
</b>
(
<a href="/wiki/%E4%B8%9C%E5%B8%9D%E6%B1%B6" title="东帝汶">
东帝汶
</a>
)
<sup>
<small>
4
</small>
</sup>
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">
雅加达
</a>
</b>
(
<a href="/wiki/%E5%8D%B0%E5%BA%A6%E5%B0%BC%E8%A5%BF%E4%BA%9A" title="印度尼西亚">
印度尼西亚
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%B0%B8%E7%8F%8D" title="永珍">
万象
</a>
</b>
(
<a href="/wiki/%E8%80%81%E6%8C%9D" title="老挝">
老挝
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%90%89%E9%9A%86%E5%9D%A1" title="吉隆坡">
吉隆坡
</a>
</b>
<span style="font-size:smaller;">
(正式首都)
</span>
與
<b>
<a href="/wiki/%E5%B8%83%E5%9F%8E" title="布城">
布城
</a>
</b>
<span style="font-size:smaller;">
(行政首都)
</span>
(
<a href="/wiki/%E9%A9%AC%E6%9D%A5%E8%A5%BF%E4%BA%9A" title="马来西亚">
马来西亚
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%A5%88%E6%AF%94%E5%A4%9A" title="奈比多">
内比都
</a>
</b>
(
<a href="/wiki/%E7%BC%85%E7%94%B8" title="缅甸">
缅甸
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%A9%AC%E5%B0%BC%E6%8B%89" title="马尼拉">
马尼拉
</a>
</b>
(
<a href="/wiki/%E8%8F%B2%E5%BE%8B%E5%AE%BE" title="菲律宾">
菲律宾
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%96%B0%E5%8A%A0%E5%9D%A1" title="新加坡">
新加坡
</a>
<sup>
<small>
5
</small>
</sup>
</b>
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">
曼谷
</a>
</b>
(
<a href="/wiki/%E6%B3%B0%E5%9B%BD" title="泰国">
泰国
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a class="mw-redirect" href="/wiki/%E6%B2%B3%E5%86%85" title="河内">
河内
</a>
</b>
(
<a href="/wiki/%E8%B6%8A%E5%8D%97" title="越南">
越南
</a>
)
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="width: 10%;">
<b>
<a class="mw-redirect" href="/wiki/%E8%A5%BF%E4%BA%9E" title="西亞">
西亞
</a>
</b>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<b>
<a href="/wiki/%E5%96%80%E5%B8%83%E5%B0%94" title="喀布尔">
喀布尔
</a>
</b>
(
<a href="/wiki/%E9%98%BF%E5%AF%8C%E6%B1%97" title="阿富汗">
阿富汗
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E8%91%89%E9%87%8C%E6%BA%AB" title="葉里溫">
埃里温
</a>
</b>
(
<a href="/wiki/%E4%BA%9E%E7%BE%8E%E5%B0%BC%E4%BA%9E" title="亞美尼亞">
亞美尼亞
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%B7%B4%E5%BA%93" title="巴库">
巴库
</a>
</b>
(
<a href="/wiki/%E9%98%BF%E5%A1%9E%E6%8B%9C%E7%96%86" title="阿塞拜疆">
阿塞拜疆
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%BA%A6%E7%BA%B3%E9%BA%A6" title="麦纳麦">
麦纳麦
</a>
</b>
(
<a href="/wiki/%E5%B7%B4%E6%9E%97" title="巴林">
巴林
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%B0%BC%E7%A7%91%E8%A5%BF%E4%BA%9A" title="尼科西亚">
尼科西亚
</a>
</b>
(
<a href="/wiki/%E8%B3%BD%E6%99%AE%E5%8B%92%E6%96%AF" title="賽普勒斯">
塞浦路斯
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E7%AC%AC%E6%AF%94%E5%88%A9%E6%96%AF" title="第比利斯">
第比利斯
</a>
</b>
(
<a href="/wiki/%E6%A0%BC%E9%B2%81%E5%90%89%E4%BA%9A" title="格鲁吉亚">
格鲁吉亚
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%BE%B7%E9%BB%91%E5%85%B0" title="德黑兰">
德黑兰
</a>
</b>
(
<a href="/wiki/%E4%BC%8A%E6%9C%97" title="伊朗">
伊朗
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%B7%B4%E6%A0%BC%E8%BE%BE" title="巴格达">
巴格达
</a>
</b>
(
<a href="/wiki/%E4%BC%8A%E6%8B%89%E5%85%8B" title="伊拉克">
伊拉克
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E8%80%B6%E8%B7%AF%E6%92%92%E5%86%B7" title="耶路撒冷">
耶路撒冷
</a>
</b>
</i>
<sup>
<small>
6
</small>
</sup>
(
<a href="/wiki/%E4%BB%A5%E8%89%B2%E5%88%97" title="以色列">
以色列
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%AE%89%E6%9B%BC" title="安曼">
安曼
</a>
</b>
(
<a href="/wiki/%E7%BA%A6%E6%97%A6" title="约旦">
约旦
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E7%A7%91%E5%A8%81%E7%89%B9%E5%9F%8E" title="科威特城">
科威特城
</a>
</b>
(
<a href="/wiki/%E7%A7%91%E5%A8%81%E7%89%B9" title="科威特">
科威特
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E8%B4%9D%E9%B2%81%E7%89%B9" title="贝鲁特">
贝鲁特
</a>
</b>
(
<a href="/wiki/%E9%BB%8E%E5%B7%B4%E5%AB%A9" title="黎巴嫩">
黎巴嫩
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%A9%AC%E6%96%AF%E5%96%80%E7%89%B9" title="马斯喀特">
马斯喀特
</a>
</b>
(
<a href="/wiki/%E9%98%BF%E6%9B%BC" title="阿曼">
阿曼
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%A4%9A%E5%93%88" title="多哈">
多哈
</a>
</b>
(
<a href="/wiki/%E5%8D%A1%E5%A1%94%E5%B0%94" title="卡塔尔">
卡塔尔
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%88%A9%E9%9B%85%E5%BE%B7" title="利雅德">
利雅德
</a>
</b>
(
<a href="/wiki/%E6%B2%99%E7%89%B9%E9%98%BF%E6%8B%89%E4%BC%AF" title="沙特阿拉伯">
沙特阿拉伯
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%A4%A7%E9%A9%AC%E5%A3%AB%E9%9D%A9" title="大马士革">
大马士革
</a>
</b>
(
<a href="/wiki/%E5%8F%99%E5%88%A9%E4%BA%9A" title="叙利亚">
叙利亚
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E5%AE%89%E5%8D%A1%E6%8B%89" title="安卡拉">
安卡拉
</a>
</b>
(
<a href="/wiki/%E5%9C%9F%E8%80%B3%E5%85%B6" title="土耳其">
土耳其
</a>
)
<sup>
<small>
7
</small>
</sup>
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E9%98%BF%E5%B8%83%E6%89%8E%E6%AF%94" title="阿布扎比">
阿布扎比
</a>
</b>
(
<a href="/wiki/%E9%98%BF%E6%8B%89%E4%BC%AF%E8%81%94%E5%90%88%E9%85%8B%E9%95%BF%E5%9B%BD" title="阿拉伯联合酋长国">
阿拉伯联合酋长国
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<b>
<a href="/wiki/%E8%90%A8%E9%82%A3" title="萨那">
萨那
</a>
</b>
<sup>
<small>
8
</small>
</sup>
(
<a href="/wiki/%E4%B9%9F%E9%97%A8" title="也门">
也门
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E8%8B%8F%E5%91%BC%E7%B1%B3" title="苏呼米">
苏呼米
</a>
</b>
</i>
(
<a class="mw-redirect" href="/wiki/%E9%98%BF%E5%B8%83%E5%93%88%E5%85%B9" title="阿布哈兹">
阿布哈兹
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E6%96%AF%E6%8D%B7%E6%BD%98%E7%B4%8D%E5%85%8B%E7%89%B9" title="斯捷潘納克特">
斯捷潘納克特
</a>
</b>
</i>
(
<a href="/wiki/%E9%98%BF%E5%B0%94%E5%AF%9F%E8%B5%AB%E5%85%B1%E5%92%8C%E5%9B%BD" title="阿尔察赫共和国">
阿尔察赫
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E8%80%B6%E8%B7%AF%E6%92%92%E5%86%B7" title="耶路撒冷">
耶路撒冷
</a>
</b>
</i>
<sup>
<small>
9
</small>
</sup>
(
<a href="/wiki/%E5%B7%B4%E5%8B%92%E6%96%AF%E5%9D%A6%E5%9C%8B" title="巴勒斯坦國">
巴勒斯坦國
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E8%8C%A8%E6%AC%A3%E7%93%A6%E5%88%A9" title="茨欣瓦利">
茨欣瓦利
</a>
</b>
</i>
(
<a href="/wiki/%E5%8D%97%E5%A5%A5%E5%A1%9E%E6%A2%AF" title="南奥塞梯">
南奥塞梯
</a>
)
<span style="white-space:nowrap; font-weight:bold;">
·
</span>
<i>
<b>
<a href="/wiki/%E5%8C%97%E5%B0%BC%E7%A7%91%E8%A5%BF%E4%BA%9A" title="北尼科西亚">
北尼科西亚
</a>
</b>
</i>
(
<a href="/wiki/%E5%8C%97%E8%B3%BD%E6%99%AE%E5%8B%92%E6%96%AF" title="北賽普勒斯">
北賽普勒斯
</a>
)
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="width: 10%;">
備註
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<div>
<p>
<sup>
1
</sup>
日本现在没有任何法律规定首都之地点,但东京都区部为日本的
<a href="/wiki/%E4%B8%AD%E5%A4%AE%E6%94%BF%E5%BA%9C%E6%89%80%E5%9C%A8%E5%9C%B0" title="中央政府所在地">
中央政府所在地
</a>
,因而使东京都被广泛认知为日本首都。此外日本在1950年制定过《首都建设法》,但已废除。1956年制定的《首都圈整备法》则将东京都、埼玉县、千叶县、神奈川县、茨城县、栃木县、群马县、山梨县规定为
<a href="/wiki/%E9%A6%96%E9%83%BD%E5%9C%88_(%E6%97%A5%E6%9C%AC)" title="首都圈 (日本)">
首都圈
</a>
。
<br/>
<sup>
2
</sup>
自1949年
<a href="/wiki/%E6%B5%B7%E5%B3%BD%E5%85%A9%E5%B2%B8%E9%97%9C%E4%BF%82" title="海峽兩岸關係">
海峽兩岸
</a>
分治後,
<a href="/wiki/%E8%87%BA%E5%8C%97%E5%B8%82" title="臺北市">
臺北市
</a>
普遍被中華民國官方及民間認定為首都。參見
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E9%A6%96%E9%83%BD" title="中華民國首都">
中華民國首都
</a>
條目。
<br/>
<sup>
3
</sup>
全名為
<a href="/wiki/%E6%96%AF%E9%87%8C%E8%B3%88%E4%BA%9E%E7%93%A6%E5%BE%B7%E7%B4%8D%E6%99%AE%E6%8B%89%E7%A7%91%E7%89%B9" title="斯里賈亞瓦德納普拉科特">
斯里賈亞瓦德納普拉科特
</a>
。
<br/>
<sup>
4
</sup>
有時會被歸類為
<a class="mw-redirect" href="/wiki/%E7%BE%8E%E6%8B%89%E5%B0%BC%E8%A5%BF%E4%BA%9E" title="美拉尼西亞">
美拉尼西亞
</a>
群島之一。
<br/>
<sup>
5
</sup>
新加坡是
<a class="mw-redirect" href="/wiki/%E5%9F%8E%E9%82%A6%E5%9B%BD" title="城邦国">
城邦國
</a>
。
<br/>
<sup>
6
</sup>
国际一般公认以色列首都为
<a href="/wiki/%E7%89%B9%E6%8B%89%E7%BB%B4%E5%A4%AB" title="特拉维夫">
特拉维夫
</a>
。
<br/>
<sup>
7
</sup>
土耳其國土橫跨亞洲及
<a class="mw-redirect" href="/wiki/%E6%AD%90%E6%B4%B2" title="歐洲">
歐洲
</a>
,因而有時會被同時歸類為歐洲國家。
<br/>
<sup>
8
</sup>
因
<a href="/wiki/%E8%90%A8%E9%82%A3" title="萨那">
萨那
</a>
被
<a href="/wiki/%E8%83%A1%E5%A1%9E%E8%BF%90%E5%8A%A8" title="胡塞运动">
胡塞运动
</a>
占领,也门首都临时迁往
<a href="/wiki/%E4%BA%9E%E4%B8%81" title="亞丁">
亞丁
</a>
。
<br/>
<sup>
9
</sup>
耶路撒冷為巴勒斯坦國主張之首都,實際之
<a href="/wiki/%E5%B7%B4%E5%8B%92%E6%96%AF%E5%9D%A6%E6%B0%91%E6%97%8F%E6%9D%83%E5%8A%9B%E6%9C%BA%E6%9E%84" title="巴勒斯坦民族权力机构">
政府所在地
</a>
為
<a href="/wiki/%E6%8B%89%E5%A7%86%E5%AE%89%E6%8B%89" title="拉姆安拉">
拉姆安拉
</a>
。
<br/>
</p>
</div>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E5%A4%8F%E5%AD%A3%E5%A5%A7%E9%81%8B%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82" title="Template:夏季奧運會主辦城市">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="new" href="/w/index.php?title=Template_talk:%E5%A4%8F%E5%AD%A3%E5%A5%A7%E9%81%8B%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82&action=edit&redlink=1" title="Template talk:夏季奧運會主辦城市(页面不存在)">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%A4%8F%E5%AD%A3%E5%A5%A7%E9%81%8B%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a href="/wiki/%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="夏季奥林匹克运动会">
夏季奥林匹克运动会
</a>
<a href="/wiki/%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83%E4%B8%BB%E8%BE%A6%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="奧林匹克運動會主辦城市列表">
主办城市
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-odd plainlist" colspan="2" style="width:100%;padding:0px;background:transparent;color:inherit;">
<div style="padding:0px;">
<table cellspacing="0" class="navbox-columns-table" style="text-align:left;width:100%;">
<tbody>
<tr style="vertical-align:top;">
<td style="padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/1896%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1896年夏季奥林匹克运动会">
1896
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%B8%8C%E8%85%8A" title="希腊">
<img alt="希腊" class="thumbborder" data-file-height="800" data-file-width="1200" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Greece_%281822-1978%29.svg/22px-Flag_of_Greece_%281822-1978%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Greece_%281822-1978%29.svg/33px-Flag_of_Greece_%281822-1978%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Greece_%281822-1978%29.svg/44px-Flag_of_Greece_%281822-1978%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%9B%85%E5%85%B8" title="雅典">
雅典
</a>
</li>
<li>
<b>
<a href="/wiki/1900%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1900年夏季奥林匹克运动会">
1900
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
<img alt="法國" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">
巴黎
</a>
</li>
<li>
<b>
<a href="/wiki/1904%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1904年夏季奥林匹克运动会">
1904
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="505" data-file-width="960" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Flag_of_the_United_States_%281896%E2%80%931908%29.svg/22px-Flag_of_the_United_States_%281896%E2%80%931908%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Flag_of_the_United_States_%281896%E2%80%931908%29.svg/33px-Flag_of_the_United_States_%281896%E2%80%931908%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Flag_of_the_United_States_%281896%E2%80%931908%29.svg/44px-Flag_of_the_United_States_%281896%E2%80%931908%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%9C%A3%E8%B7%AF%E6%98%93%E6%96%AF_(%E5%AF%86%E8%8B%8F%E9%87%8C%E5%B7%9E)" title="圣路易斯 (密苏里州)">
圣路易斯
</a>
</li>
<li>
<b>
<a href="/wiki/1908%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1908年夏季奥林匹克运动会">
1908
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国">
<img alt="英国" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">
伦敦
</a>
</li>
<li>
<b>
<a href="/wiki/1912%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1912年夏季奥林匹克运动会">
1912
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%91%9E%E5%85%B8" title="瑞典">
<img alt="瑞典" class="thumbborder" data-file-height="320" data-file-width="512" decoding="async" height="14" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Flag_of_Sweden.svg/22px-Flag_of_Sweden.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Flag_of_Sweden.svg/33px-Flag_of_Sweden.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Flag_of_Sweden.svg/44px-Flag_of_Sweden.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%96%AF%E5%BE%B7%E5%93%A5%E5%B0%94%E6%91%A9" title="斯德哥尔摩">
斯德哥尔摩
</a>
</li>
<li>
<del>
<b>
<a href="/wiki/1916%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1916年夏季奥林匹克运动会">
1916
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%BE%B7%E6%84%8F%E5%BF%97%E5%B8%9D%E5%9B%BD" title="德意志帝国">
<img alt="德意志帝国" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Germany_%281867%E2%80%931919%29.svg/22px-Flag_of_Germany_%281867%E2%80%931919%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Germany_%281867%E2%80%931919%29.svg/33px-Flag_of_Germany_%281867%E2%80%931919%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Germany_%281867%E2%80%931919%29.svg/44px-Flag_of_Germany_%281867%E2%80%931919%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9F%8F%E6%9E%97" title="柏林">
柏林
</a>
</del>
<sup>
(注1)
</sup>
</li>
<li>
<b>
<a href="/wiki/1920%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1920年夏季奥林匹克运动会">
1920
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%AF%94%E5%88%A9%E6%97%B6" title="比利时">
<img alt="比利时" class="thumbborder" data-file-height="780" data-file-width="900" decoding="async" height="19" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Belgium.svg/22px-Flag_of_Belgium.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Belgium.svg/33px-Flag_of_Belgium.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/65/Flag_of_Belgium.svg/44px-Flag_of_Belgium.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%AE%89%E7%89%B9%E5%8D%AB%E6%99%AE" title="安特卫普">
安特卫普
</a>
</li>
<li>
<b>
<a href="/wiki/1924%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1924年夏季奥林匹克运动会">
1924
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
<img alt="法國" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">
巴黎
</a>
</li>
<li>
<b>
<a href="/wiki/1928%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1928年夏季奥林匹克运动会">
1928
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8D%B7%E5%85%B0" title="荷兰">
<img alt="荷兰" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/22px-Flag_of_the_Netherlands.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/33px-Flag_of_the_Netherlands.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/2/20/Flag_of_the_Netherlands.svg/44px-Flag_of_the_Netherlands.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%98%BF%E5%A7%86%E6%96%AF%E7%89%B9%E4%B8%B9" title="阿姆斯特丹">
阿姆斯特丹
</a>
</li>
</ul>
</div>
</td>
<td style="border-left:2px solid #fdfdfd;padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/1932%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1932年夏季奥林匹克运动会">
1932
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f5/Flag_of_the_United_States_%281912-1959%29.svg/22px-Flag_of_the_United_States_%281912-1959%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f5/Flag_of_the_United_States_%281912-1959%29.svg/33px-Flag_of_the_United_States_%281912-1959%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f5/Flag_of_the_United_States_%281912-1959%29.svg/44px-Flag_of_the_United_States_%281912-1959%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%B4%9B%E6%9D%89%E7%9F%B6" title="洛杉矶">
洛杉矶
</a>
</li>
<li>
<b>
<a href="/wiki/1936%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1936年夏季奥林匹克运动会">
1936
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">
<img alt="德国" class="thumbborder" data-file-height="600" data-file-width="1000" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/22px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/33px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/44px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9F%8F%E6%9E%97" title="柏林">
柏林
</a>
</li>
<li>
<del>
<b>
<a href="/wiki/1940%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1940年夏季奥林匹克运动会">
1940
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A4%A7%E6%97%A5%E6%9C%AC%E5%B8%9D%E5%9B%BD" title="大日本帝国">
<img alt="大日本帝国" class="thumbborder" data-file-height="700" data-file-width="1000" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E5%B8%82" title="東京市">
東京
</a>
/
<span class="flagicon">
<a href="/wiki/%E8%8A%AC%E5%85%B0" title="芬兰">
<img alt="芬兰" class="thumbborder" data-file-height="1100" data-file-width="1800" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/22px-Flag_of_Finland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/33px-Flag_of_Finland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/44px-Flag_of_Finland.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E8%B5%AB%E5%B0%94%E8%BE%9B%E5%9F%BA" title="赫尔辛基">
赫尔辛基
</a>
</del>
<sup>
(注2)
</sup>
</li>
<li>
<del>
<b>
<a href="/wiki/1944%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1944年夏季奥林匹克运动会">
1944
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国">
<img alt="英国" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">
伦敦
</a>
</del>
<sup>
(注2)
</sup>
</li>
<li>
<b>
<a href="/wiki/1948%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1948年夏季奥林匹克运动会">
1948
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国">
<img alt="英国" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">
伦敦
</a>
</li>
<li>
<b>
<a href="/wiki/1952%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1952年夏季奥林匹克运动会">
1952
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8A%AC%E5%85%B0" title="芬兰">
<img alt="芬兰" class="thumbborder" data-file-height="1100" data-file-width="1800" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/22px-Flag_of_Finland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/33px-Flag_of_Finland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bc/Flag_of_Finland.svg/44px-Flag_of_Finland.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E8%B5%AB%E5%B0%94%E8%BE%9B%E5%9F%BA" title="赫尔辛基">
赫尔辛基
</a>
</li>
<li>
<b>
<a href="/wiki/1956%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1956年夏季奥林匹克运动会">
1956
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%BE%B3%E5%A4%A7%E5%88%A9%E4%BA%9A" title="澳大利亚">
<img alt="澳大利亚" class="thumbborder" data-file-height="640" data-file-width="1280" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/22px-Flag_of_Australia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/33px-Flag_of_Australia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/44px-Flag_of_Australia.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%A2%A8%E5%B0%94%E6%9C%AC" title="墨尔本">
墨尔本
</a>
</li>
<li>
<b>
<a href="/wiki/1960%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1960年夏季奥林匹克运动会">
1960
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利">
<img alt="義大利" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E7%BD%97%E9%A9%AC" title="罗马">
罗马
</a>
</li>
<li>
<b>
<a href="/wiki/1964%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1964年夏季奥林匹克运动会">
1964
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
<img alt="日本" class="thumbborder" data-file-height="700" data-file-width="1000" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">
东京
</a>
</li>
</ul>
</div>
</td>
<td style="border-left:2px solid #fdfdfd;padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/1968%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1968年夏季奥林匹克运动会">
1968
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5" title="墨西哥">
<img alt="墨西哥" class="thumbborder" data-file-height="560" data-file-width="980" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/22px-Flag_of_Mexico.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/33px-Flag_of_Mexico.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fc/Flag_of_Mexico.svg/44px-Flag_of_Mexico.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%A2%A8%E8%A5%BF%E5%93%A5%E5%9F%8E" title="墨西哥城">
墨西哥城
</a>
</li>
<li>
<b>
<a href="/wiki/1972%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1972年夏季奥林匹克运动会">
1972
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%A5%BF%E5%BE%B7" title="西德">
<img alt="西德" class="thumbborder" data-file-height="600" data-file-width="1000" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/22px-Flag_of_Germany.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/33px-Flag_of_Germany.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/ba/Flag_of_Germany.svg/44px-Flag_of_Germany.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%85%95%E5%B0%BC%E9%BB%91" title="慕尼黑">
慕尼黑
</a>
</li>
<li>
<b>
<a href="/wiki/1976%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1976年夏季奥林匹克运动会">
1976
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大">
<img alt="加拿大" class="thumbborder" data-file-height="256" data-file-width="512" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E8%92%99%E7%89%B9%E5%88%A9%E5%B0%94" title="蒙特利尔">
蒙特利尔
</a>
</li>
<li>
<b>
<a href="/wiki/1980%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1980年夏季奥林匹克运动会">
1980
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8B%8F%E8%81%94" title="苏联">
<img alt="苏联" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/ce/Flag_of_the_Soviet_Union_%28dark_version%29.svg/22px-Flag_of_the_Soviet_Union_%28dark_version%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/ce/Flag_of_the_Soviet_Union_%28dark_version%29.svg/33px-Flag_of_the_Soviet_Union_%28dark_version%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/ce/Flag_of_the_Soviet_Union_%28dark_version%29.svg/44px-Flag_of_the_Soviet_Union_%28dark_version%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E8%8E%AB%E6%96%AF%E7%A7%91" title="莫斯科">
莫斯科
</a>
</li>
<li>
<b>
<a href="/wiki/1984%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1984年夏季奥林匹克运动会">
1984
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%B4%9B%E6%9D%89%E7%9F%B6" title="洛杉矶">
洛杉矶
</a>
</li>
<li>
<b>
<a href="/wiki/1988%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1988年夏季奥林匹克运动会">
1988
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国">
<img alt="大韩民国" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/22px-Flag_of_South_Korea.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/33px-Flag_of_South_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/44px-Flag_of_South_Korea.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%A6%96%E7%88%BE" title="首爾">
漢城
</a>
</li>
<li>
<b>
<a href="/wiki/1992%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1992年夏季奥林匹克运动会">
1992
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%A5%BF%E7%8F%AD%E7%89%99" title="西班牙">
<img alt="西班牙" class="thumbborder" data-file-height="500" data-file-width="750" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/22px-Flag_of_Spain.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/33px-Flag_of_Spain.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9a/Flag_of_Spain.svg/44px-Flag_of_Spain.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%B7%B4%E5%A1%9E%E7%BD%97%E9%82%A3" title="巴塞罗那">
巴塞罗那
</a>
</li>
<li>
<b>
<a href="/wiki/1996%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1996年夏季奥林匹克运动会">
1996
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E4%BA%9A%E7%89%B9%E5%85%B0%E5%A4%A7" title="亚特兰大">
亚特兰大
</a>
</li>
<li>
<b>
<a href="/wiki/2000%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2000年夏季奥林匹克运动会">
2000
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%BE%B3%E5%A4%A7%E5%88%A9%E4%BA%9A" title="澳大利亚">
<img alt="澳大利亚" class="thumbborder" data-file-height="640" data-file-width="1280" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/22px-Flag_of_Australia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/33px-Flag_of_Australia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/b9/Flag_of_Australia.svg/44px-Flag_of_Australia.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%82%89%E5%B0%BC" title="悉尼">
悉尼
</a>
</li>
</ul>
</div>
</td>
<td style="border-left:2px solid #fdfdfd;padding:0px;text-align:l eft; padding-left: 0.2em; white-space: nowrap;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/2004%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2004年夏季奥林匹克运动会">
2004
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%B8%8C%E8%85%8A" title="希腊">
<img alt="希腊" class="thumbborder" data-file-height="400" data-file-width="600" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/22px-Flag_of_Greece.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/33px-Flag_of_Greece.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/5/5c/Flag_of_Greece.svg/44px-Flag_of_Greece.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%9B%85%E5%85%B8" title="雅典">
雅典
</a>
</li>
<li>
<b>
<a href="/wiki/2008%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2008年夏季奥林匹克运动会">
2008
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国">
<img alt="中国" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</a>
</span>
<a class="mw-selflink selflink">
北京
</a>
</li>
<li>
<b>
<a href="/wiki/2012%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2012年夏季奥林匹克运动会">
2012
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E8%8B%B1%E5%9B%BD" title="英国">
<img alt="英国" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/22px-Flag_of_the_United_Kingdom.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/33px-Flag_of_the_United_Kingdom.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ae/Flag_of_the_United_Kingdom.svg/44px-Flag_of_the_United_Kingdom.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E4%BC%A6%E6%95%A6" title="伦敦">
伦敦
</a>
</li>
<li>
<b>
<a class="mw-redirect" href="/wiki/2016%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2016年夏季奥林匹克运动会">
2016
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%B7%B4%E8%A5%BF" title="巴西">
<img alt="巴西" class="thumbborder" data-file-height="742" data-file-width="1060" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/22px-Flag_of_Brazil.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/33px-Flag_of_Brazil.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/05/Flag_of_Brazil.svg/44px-Flag_of_Brazil.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%87%8C%E7%BA%A6%E7%83%AD%E5%86%85%E5%8D%A2" title="里约热内卢">
里约热内卢
</a>
</li>
<li>
<i>
<b>
<a href="/wiki/2020%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2020年夏季奥林匹克运动会">
2020
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
<img alt="日本" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/22px-Flag_of_Japan.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/33px-Flag_of_Japan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/44px-Flag_of_Japan.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">
东京
</a>
<sup>
(注3)
</sup>
</i>
</li>
<li>
<i>
<b>
<a href="/wiki/2024%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2024年夏季奥林匹克运动会">
2024
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
<img alt="法國" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%B7%B4%E9%BB%8E" title="巴黎">
巴黎
</a>
</i>
</li>
<li>
<i>
<b>
<a href="/wiki/2028%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2028年夏季奥林匹克运动会">
2028
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%B4%9B%E6%9D%89%E7%9F%B6" title="洛杉矶">
洛杉矶
</a>
</i>
</li>
<li>
<i>
<b>
<a class="new" href="/w/index.php?title=2032%E5%B9%B4%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A&action=edit&redlink=1" title="2032年夏季奥林匹克运动会(页面不存在)">
2032
</a>
:
</b>
尚未選出
</i>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
<sup>
(注1)
</sup>
因
<a href="/wiki/%E7%AC%AC%E4%B8%80%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%98" title="第一次世界大战">
第一次世界大战
</a>
取消;
<sup>
(注2)
</sup>
因
<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%98" title="第二次世界大战">
第二次世界大战
</a>
取消;
<sup>
(注3)
</sup>
受
<a href="/wiki/2019%E5%86%A0%E7%8A%B6%E7%97%85%E6%AF%92%E7%97%85%E7%96%AB%E6%83%85" title="2019冠状病毒病疫情">
2019冠状病毒病疫情
</a>
影响推迟,但仍保留原定名称
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E5%86%AC%E5%AD%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Template:冬季奥运会主办城市">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="new" href="/w/index.php?title=Template_talk:%E5%86%AC%E5%AD%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit&redlink=1" title="Template talk:冬季奥运会主办城市(页面不存在)">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E5%86%AC%E5%AD%A3%E5%A5%A5%E8%BF%90%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a href="/wiki/%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="冬季奥林匹克运动会">
冬季奥林匹克运动会
</a>
主办城市
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-odd plainlist" colspan="2" style="width:100%;padding:0px;background:transparent;color:inherit;">
<div style="padding:0px;">
<table cellspacing="0" class="navbox-columns-table" style="text-align:left;width:100%;">
<tbody>
<tr style="vertical-align:top;">
<td style="padding:0px;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/1924%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1924年冬季奥林匹克运动会">
1924
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
<img alt="法國" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</a>
</span>
<a class="mw-redirect" href="/wiki/%E9%9C%9E%E6%85%95%E5%B0%BC" title="霞慕尼">
霞慕尼
</a>
</li>
<li>
<b>
<a href="/wiki/1928%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1928年冬季奥林匹克运动会">
1928
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%91%9E%E5%A3%AB" title="瑞士">
<img alt="瑞士" class="thumbborder" data-file-height="512" data-file-width="512" decoding="async" height="20" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/20px-Flag_of_Switzerland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/30px-Flag_of_Switzerland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/40px-Flag_of_Switzerland.svg.png 2x" width="20"/>
</a>
</span>
<a href="/wiki/%E5%9C%A3%E8%8E%AB%E9%87%8C%E8%8C%A8" title="圣莫里茨">
圣莫里茨
</a>
</li>
<li>
<b>
<a href="/wiki/1932%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1932年冬季奥林匹克运动会">
1932
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%99%AE%E8%90%8A%E8%A5%BF%E5%BE%B7%E6%B9%96" title="普萊西德湖">
普萊西德湖
</a>
</li>
<li>
<b>
<a href="/wiki/1936%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1936年冬季奥林匹克运动会">
1936
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">
<img alt="德国" class="thumbborder" data-file-height="600" data-file-width="1000" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/22px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/33px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/44px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%8A%A0%E7%B1%B3%E6%96%BD-%E5%B8%95%E6%BB%95%E5%9F%BA%E5%85%B4" title="加米施-帕滕基兴">
加米施-帕滕基兴
</a>
</li>
<li>
<del>
<b>
<a href="/wiki/1940%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1940年冬季奥林匹克运动会">
1940
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A4%A7%E6%97%A5%E6%9C%AC%E5%B8%9D%E5%9B%BD" title="大日本帝国">
<img alt="大日本帝国" class="thumbborder" data-file-height="700" data-file-width="1000" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">
札幌
</a>
/
<span class="flagicon">
<a href="/wiki/%E7%91%9E%E5%A3%AB" title="瑞士">
<img alt="瑞士" class="thumbborder" data-file-height="512" data-file-width="512" decoding="async" height="20" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/20px-Flag_of_Switzerland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/30px-Flag_of_Switzerland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/40px-Flag_of_Switzerland.svg.png 2x" width="20"/>
</a>
</span>
<a href="/wiki/%E5%9C%A3%E8%8E%AB%E9%87%8C%E8%8C%A8" title="圣莫里茨">
圣莫里茨
</a>
/
<span class="flagicon">
<a href="/wiki/%E5%BE%B7%E5%9B%BD" title="德国">
<img alt="德国" class="thumbborder" data-file-height="600" data-file-width="1000" decoding="async" height="13" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/22px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/33px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/77/Flag_of_Germany_%281935%E2%80%931945%29.svg/44px-Flag_of_Germany_%281935%E2%80%931945%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%8A%A0%E7%B1%B3%E6%96%BD-%E5%B8%95%E6%BB%95%E5%9F%BA%E5%85%B4" title="加米施-帕滕基兴">
加米施-帕滕基兴
</a>
</del>
<sup>
(注)
</sup>
</li>
<li>
<del>
<b>
<a class="mw-redirect" href="/wiki/1944%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" title="1944年冬季奧林匹克運動會">
1944
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利">
<img alt="義大利" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Italy_%281861%E2%80%931946%29.svg/22px-Flag_of_Italy_%281861%E2%80%931946%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Italy_%281861%E2%80%931946%29.svg/33px-Flag_of_Italy_%281861%E2%80%931946%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/78/Flag_of_Italy_%281861%E2%80%931946%29.svg/44px-Flag_of_Italy_%281861%E2%80%931946%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E7%A7%91%E7%88%BE%E8%92%82%E7%B4%8D%E4%B8%B9%E4%BD%A9%E4%BD%90" title="科爾蒂納丹佩佐">
科爾蒂納丹佩佐
</a>
</del>
<sup>
(注)
</sup>
</li>
<li>
<b>
<a href="/wiki/1948%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1948年冬季奥林匹克运动会">
1948
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%91%9E%E5%A3%AB" title="瑞士">
<img alt="瑞士" class="thumbborder" data-file-height="512" data-file-width="512" decoding="async" height="20" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/20px-Flag_of_Switzerland.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/30px-Flag_of_Switzerland.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Switzerland.svg/40px-Flag_of_Switzerland.svg.png 2x" width="20"/>
</a>
</span>
<a href="/wiki/%E5%9C%A3%E8%8E%AB%E9%87%8C%E8%8C%A8" title="圣莫里茨">
圣莫里茨
</a>
</li>
</ul>
</div>
</td>
<td style="border-left:2px solid #fdfdfd;padding:0px;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/1952%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1952年冬季奥林匹克运动会">
1952
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%8C%AA%E5%A8%81" title="挪威">
<img alt="挪威" class="thumbborder" data-file-height="800" data-file-width="1100" decoding="async" height="16" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/22px-Flag_of_Norway.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/33px-Flag_of_Norway.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/44px-Flag_of_Norway.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%A5%A5%E6%96%AF%E9%99%86" title="奥斯陆">
奥斯陆
</a>
</li>
<li>
<b>
<a href="/wiki/1956%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1956年冬季奥林匹克运动会">
1956
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利">
<img alt="義大利" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E7%A7%91%E7%88%BE%E8%92%82%E7%B4%8D%E4%B8%B9%E4%BD%A9%E4%BD%90" title="科爾蒂納丹佩佐">
科爾蒂納丹佩佐
</a>
</li>
<li>
<b>
<a href="/wiki/1960%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1960年冬季奥林匹克运动会">
1960
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%96%AF%E9%98%94%E8%B0%B7%E6%BB%91%E9%9B%AA%E6%B8%A1%E5%81%87%E8%83%9C%E5%9C%B0" title="斯阔谷滑雪渡假胜地">
斯阔谷
</a>
</li>
<li>
<b>
<a href="/wiki/1964%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1964年冬季奥林匹克运动会">
1964
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A5%A5%E5%9C%B0%E5%88%A9" title="奥地利">
<img alt="奥地利" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/22px-Flag_of_Austria.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/33px-Flag_of_Austria.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/44px-Flag_of_Austria.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%9B%A0%E6%96%AF%E5%B8%83%E9%B2%81%E5%85%8B" title="因斯布鲁克">
因斯布鲁克
</a>
</li>
<li>
<b>
<a class="mw-redirect" href="/wiki/1968%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" title="1968年冬季奧林匹克運動會">
1968
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
<img alt="法國" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%A0%BC%E5%8B%92%E8%AF%BA%E5%B8%83%E5%B0%94" title="格勒诺布尔">
格勒诺布尔
</a>
</li>
<li>
<b>
<a class="mw-redirect" href="/wiki/1972%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" title="1972年冬季奧林匹克運動會">
1972
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
<img alt="日本" class="thumbborder" data-file-height="700" data-file-width="1000" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/22px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/33px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/1b/Flag_of_Japan_%281870%E2%80%931999%29.svg/44px-Flag_of_Japan_%281870%E2%80%931999%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">
札幌
</a>
</li>
<li>
<b>
<a href="/wiki/1976%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1976年冬季奥林匹克运动会">
1976
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A5%A5%E5%9C%B0%E5%88%A9" title="奥地利">
<img alt="奥地利" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/22px-Flag_of_Austria.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/33px-Flag_of_Austria.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/41/Flag_of_Austria.svg/44px-Flag_of_Austria.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%9B%A0%E6%96%AF%E5%B8%83%E9%B2%81%E5%85%8B" title="因斯布鲁克">
因斯布鲁克
</a>
</li>
</ul>
</div>
</td>
<td style="border-left:2px solid #fdfdfd;padding:0px;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/1980%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1980年冬季奥林匹克运动会">
1980
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%99%AE%E8%90%8A%E8%A5%BF%E5%BE%B7%E6%B9%96" title="普萊西德湖">
普萊西德湖
</a>
</li>
<li>
<b>
<a href="/wiki/1984%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1984年冬季奥林匹克运动会">
1984
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%8D%97%E6%96%AF%E6%8B%89%E5%A4%AB" title="南斯拉夫">
<img alt="南斯拉夫" class="thumbborder" data-file-height="600" data-file-width="1200" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/61/Flag_of_Yugoslavia_%281946-1992%29.svg/22px-Flag_of_Yugoslavia_%281946-1992%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/61/Flag_of_Yugoslavia_%281946-1992%29.svg/33px-Flag_of_Yugoslavia_%281946-1992%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/61/Flag_of_Yugoslavia_%281946-1992%29.svg/44px-Flag_of_Yugoslavia_%281946-1992%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%A1%9E%E6%8B%89%E8%80%B6%E4%BD%9B" title="塞拉耶佛">
萨拉热窝
</a>
</li>
<li>
<b>
<a href="/wiki/1988%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1988年冬季奥林匹克运动会">
1988
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大">
<img alt="加拿大" class="thumbborder" data-file-height="256" data-file-width="512" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%8D%A1%E5%B0%94%E5%8A%A0%E9%87%8C" title="卡尔加里">
卡尔加里
</a>
</li>
<li>
<b>
<a href="/wiki/1992%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1992年冬季奥林匹克运动会">
1992
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%B3%95%E5%9C%8B" title="法國">
<img alt="法國" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/22px-Flag_of_France.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/33px-Flag_of_France.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Flag_of_France.svg/44px-Flag_of_France.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%98%BF%E5%B0%94%E8%B4%9D%E7%BB%B4%E5%B0%94" title="阿尔贝维尔">
阿尔贝维尔
</a>
</li>
<li>
<b>
<a href="/wiki/1994%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1994年冬季奥林匹克运动会">
1994
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%8C%AA%E5%A8%81" title="挪威">
<img alt="挪威" class="thumbborder" data-file-height="800" data-file-width="1100" decoding="async" height="16" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/22px-Flag_of_Norway.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/33px-Flag_of_Norway.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Norway.svg/44px-Flag_of_Norway.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%88%A9%E5%8B%92%E5%93%88%E9%BB%98%E5%B0%94" title="利勒哈默尔">
利勒哈默尔
</a>
</li>
<li>
<b>
<a href="/wiki/1998%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1998年冬季奥林匹克运动会">
1998
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
<img alt="日本" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/22px-Flag_of_Japan.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/33px-Flag_of_Japan.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/9e/Flag_of_Japan.svg/44px-Flag_of_Japan.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%95%B7%E9%87%8E%E5%B8%82" title="長野市">
長野
</a>
</li>
<li>
<b>
<a href="/wiki/2002%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2002年冬季奥林匹克运动会">
2002
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%8E%E5%9C%8B" title="美國">
<img alt="美國" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E7%9B%90%E6%B9%96%E5%9F%8E" title="盐湖城">
盐湖城
</a>
</li>
</ul>
</div>
</td>
<td style="border-left:2px solid #fdfdfd;padding:0px;;;;width:10em;">
<div>
<ul>
<li>
<b>
<a href="/wiki/2006%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2006年冬季奥林匹克运动会">
2006
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利">
<img alt="義大利" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E9%83%BD%E7%81%B5" title="都灵">
都灵
</a>
</li>
<li>
<b>
<a href="/wiki/2010%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2010年冬季奥林匹克运动会">
2010
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%8A%A0%E6%8B%BF%E5%A4%A7" title="加拿大">
<img alt="加拿大" class="thumbborder" data-file-height="256" data-file-width="512" decoding="async" height="11" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/22px-Flag_of_Canada_%28Pantone%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/33px-Flag_of_Canada_%28Pantone%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Canada_%28Pantone%29.svg/44px-Flag_of_Canada_%28Pantone%29.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E6%BA%AB%E5%93%A5%E8%8F%AF" title="溫哥華">
溫哥華
</a>
</li>
<li>
<b>
<a href="/wiki/2014%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2014年冬季奥林匹克运动会">
2014
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E4%BF%84%E7%BD%97%E6%96%AF" title="俄罗斯">
<img alt="俄罗斯" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/22px-Flag_of_Russia.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/33px-Flag_of_Russia.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f3/Flag_of_Russia.svg/44px-Flag_of_Russia.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E7%B4%A2%E5%A5%91" title="索契">
索契
</a>
</li>
<li>
<b>
<a href="/wiki/2018%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2018年冬季奥林匹克运动会">
2018
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E5%A4%A7%E9%9F%A9%E6%B0%91%E5%9B%BD" title="大韩民国">
<img alt="大韩民国" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/22px-Flag_of_South_Korea.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/33px-Flag_of_South_Korea.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/09/Flag_of_South_Korea.svg/44px-Flag_of_South_Korea.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E5%B9%B3%E6%98%8C%E9%83%A1" title="平昌郡">
平昌
</a>
</li>
<li>
<i>
<b>
<a href="/wiki/2022%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2022年冬季奥林匹克运动会">
2022
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国">
<img alt="中国" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</a>
</span>
<a class="mw-selflink selflink">
北京
</a>
</i>
</li>
<li>
<i>
<b>
<a href="/wiki/2026%E5%B9%B4%E5%86%AC%E5%AD%A3%E5%A5%A7%E6%9E%97%E5%8C%B9%E5%85%8B%E9%81%8B%E5%8B%95%E6%9C%83" title="2026年冬季奧林匹克運動會">
2026
</a>
:
</b>
<span class="flagicon">
<a href="/wiki/%E7%BE%A9%E5%A4%A7%E5%88%A9" title="義大利">
<img alt="義大利" class="thumbborder" data-file-height="1000" data-file-width="1500" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/22px-Flag_of_Italy.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/33px-Flag_of_Italy.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/03/Flag_of_Italy.svg/44px-Flag_of_Italy.svg.png 2x" width="22"/>
</a>
</span>
<a href="/wiki/%E7%B1%B3%E8%98%AD" title="米蘭">
米蘭
</a>
-
<a href="/wiki/%E7%A7%91%E7%88%BE%E8%92%82%E7%B4%8D%E4%B8%B9%E4%BD%A9%E4%BD%90" title="科爾蒂納丹佩佐">
科爾蒂納丹佩佐
</a>
</i>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
<sup>
(注)
</sup>
因
<a href="/wiki/%E7%AC%AC%E4%BA%8C%E6%AC%A1%E4%B8%96%E7%95%8C%E5%A4%A7%E6%88%98" title="第二次世界大战">
第二次世界大战
</a>
取消
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks hlist collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Template:亚洲运动会主办城市">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="new" href="/w/index.php?title=Template_talk:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit&redlink=1" title="Template talk:亚洲运动会主办城市(页面不存在)">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a href="/wiki/%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲运动会">
亚洲运动会
</a>
主办城市
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px;background:transparent;color:inherit;">
<div style="padding:0px;">
<table cellspacing="0" class="navbox-columns-table" style="text-align:left;width:auto;margin-left:auto;margin-right:auto;">
</table>
</div>
</td>
<td class="navbox-image" rowspan="5" style="width:0%;padding:0px 0px 0px 2px;padding: 0 0.5em;">
<div>
<a class="image" href="/wiki/File:Asian_Games_logo.svg" title="Asian Games logo">
<img alt="Asian Games logo" data-file-height="406" data-file-width="400" decoding="async" height="71" src="//upload.wikimedia.org/wikipedia/commons/thumb/1/19/Asian_Games_logo.svg/70px-Asian_Games_logo.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/1/19/Asian_Games_logo.svg/105px-Asian_Games_logo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/1/19/Asian_Games_logo.svg/140px-Asian_Games_logo.svg.png 2x" width="70"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲运动会">
夏季
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<b>
<a href="/wiki/1951%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1951年亚洲运动会">
1951
</a>
</b>
:
<a href="/wiki/%E5%BE%B7%E9%87%8C" title="德里">
德里
</a>
</li>
<li>
<b>
<a href="/wiki/1954%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1954年亚洲运动会">
1954
</a>
</b>
:
<a href="/wiki/%E9%A9%AC%E5%B0%BC%E6%8B%89" title="马尼拉">
马尼拉
</a>
</li>
<li>
<b>
<a href="/wiki/1958%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1958年亚洲运动会">
1958
</a>
</b>
:
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E9%83%BD" title="東京都">
东京
</a>
</li>
<li>
<b>
<a href="/wiki/1962%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1962年亚洲运动会">
1962
</a>
</b>
:
<a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">
雅加达
</a>
</li>
<li>
<b>
<a href="/wiki/1966%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1966年亚洲运动会">
1966
</a>
</b>
:
<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">
曼谷
</a>
</li>
<li>
<b>
<a href="/wiki/1970%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1970年亚洲运动会">
1970
</a>
</b>
:
<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">
曼谷
</a>
</li>
<li>
<b>
<a href="/wiki/1974%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1974年亚洲运动会">
1974
</a>
</b>
:
<a href="/wiki/%E5%BE%B7%E9%BB%91%E5%85%B0" title="德黑兰">
德黑兰
</a>
</li>
<li>
<b>
<a href="/wiki/1978%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1978年亚洲运动会">
1978
</a>
</b>
:
<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">
曼谷
</a>
</li>
<li>
<b>
<a href="/wiki/1982%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1982年亚洲运动会">
1982
</a>
</b>
:
<a href="/wiki/%E5%BE%B7%E9%87%8C" title="德里">
德里
</a>
</li>
<li>
<b>
<a href="/wiki/1986%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1986年亚洲运动会">
1986
</a>
</b>
:
<a href="/wiki/%E9%A6%96%E7%88%BE" title="首爾">
首爾
</a>
</li>
<li>
<b>
<a href="/wiki/1990%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1990年亚洲运动会">
1990
</a>
</b>
:
<a class="mw-selflink selflink">
北京
</a>
</li>
<li>
<b>
<a href="/wiki/1994%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1994年亚洲运动会">
1994
</a>
</b>
:
<a href="/wiki/%E5%BB%A3%E5%B3%B6%E5%B8%82" title="廣島市">
广岛
</a>
</li>
<li>
<b>
<a href="/wiki/1998%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="1998年亚洲运动会">
1998
</a>
</b>
:
<a href="/wiki/%E6%9B%BC%E8%B0%B7" title="曼谷">
曼谷
</a>
</li>
<li>
<b>
<a href="/wiki/2002%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2002年亚洲运动会">
2002
</a>
</b>
:
<a href="/wiki/%E9%87%9C%E5%B1%B1%E5%BB%A3%E5%9F%9F%E5%B8%82" title="釜山廣域市">
釜山
</a>
</li>
<li>
<b>
<a href="/wiki/2006%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2006年亚洲运动会">
2006
</a>
</b>
:
<a href="/wiki/%E5%A4%9A%E5%93%88" title="多哈">
多哈
</a>
</li>
<li>
<b>
<a href="/wiki/2010%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2010年亚洲运动会">
2010
</a>
</b>
:
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州
</a>
</li>
<li>
<b>
<a href="/wiki/2014%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2014年亚洲运动会">
2014
</a>
</b>
:
<a href="/wiki/%E4%BB%81%E5%B7%9D%E5%BB%A3%E5%9F%9F%E5%B8%82" title="仁川廣域市">
仁川
</a>
</li>
<li>
<b>
<a href="/wiki/2018%E5%B9%B4%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A" title="2018年亚洲运动会">
2018
</a>
</b>
:
<a href="/wiki/%E9%9B%85%E5%8A%A0%E8%BE%BE" title="雅加达">
雅加达
</a>
-
<a href="/wiki/%E5%B7%A8%E6%B8%AF" title="巨港">
巨港
</a>
</li>
<li>
<b>
<a href="/wiki/2022%E5%B9%B4%E4%BA%9E%E6%B4%B2%E9%81%8B%E5%8B%95%E6%9C%83" title="2022年亞洲運動會">
2022
</a>
</b>
:
<i>
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州
</a>
</i>
</li>
<li>
<b>
<a href="/wiki/2026%E5%B9%B4%E4%BA%9E%E6%B4%B2%E9%81%8B%E5%8B%95%E6%9C%83" title="2026年亞洲運動會">
2026
</a>
</b>
:
<i>
<a href="/wiki/%E5%90%8D%E5%8F%A4%E5%B1%8B%E5%B8%82" title="名古屋市">
名古屋
</a>
</i>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a class="mw-redirect" href="/wiki/%E4%BA%9A%E6%B4%B2%E5%86%AC%E5%AD%A3%E8%BF%90%E5%8A%A8%E4%BC%9A" title="亚洲冬季运动会">
冬季
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<b>
<a href="/wiki/1986%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1986年亞洲冬季運動會">
1986
</a>
</b>
:
<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">
札幌
</a>
</li>
<li>
<b>
<a href="/wiki/1990%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1990年亞洲冬季運動會">
1990
</a>
</b>
:
<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">
札幌
</a>
</li>
<li>
<b>
<a href="/wiki/1996%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1996年亞洲冬季運動會">
1996
</a>
</b>
:
<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">
哈尔滨
</a>
</li>
<li>
<b>
<a href="/wiki/1999%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="1999年亞洲冬季運動會">
1999
</a>
</b>
:
<a href="/wiki/%E6%B1%9F%E5%8E%9F%E9%81%93_(%E9%9F%93%E5%9C%8B)" title="江原道 (韓國)">
江原
</a>
</li>
<li>
<b>
<a href="/wiki/2003%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2003年亞洲冬季運動會">
2003
</a>
</b>
:
<a class="mw-redirect" href="/wiki/%E9%9D%92%E6%A3%AE%E5%8E%BF" title="青森县">
青森
</a>
</li>
<li>
<b>
<a href="/wiki/2007%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2007年亞洲冬季運動會">
2007
</a>
</b>
:
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">
长春
</a>
</li>
<li>
<b>
<a href="/wiki/2011%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2011年亞洲冬季運動會">
2011
</a>
</b>
:
<a href="/wiki/%E5%8A%AA%E7%88%BE-%E8%98%87%E4%B8%B9" title="努爾-蘇丹">
阿斯塔纳
</a>
-
<a href="/wiki/%E9%98%BF%E6%8B%89%E6%9C%A8%E5%9C%96" title="阿拉木圖">
阿拉木圖
</a>
</li>
<li>
<b>
<a href="/wiki/2017%E5%B9%B4%E4%BA%9E%E6%B4%B2%E5%86%AC%E5%AD%A3%E9%81%8B%E5%8B%95%E6%9C%83" title="2017年亞洲冬季運動會">
2017
</a>
</b>
:
<a href="/wiki/%E6%9C%AD%E5%B9%8C%E5%B8%82" title="札幌市">
札幌
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col" style="background: khaki;">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80" title="Template:中國地理大區">
<abbr style=";background: khaki;;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80" title="Template talk:中國地理大區">
<abbr style=";background: khaki;;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80&action=edit">
<abbr style=";background: khaki;;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a href="/wiki/%E4%B8%AD%E5%9C%8B%E5%9C%B0%E7%90%86%E5%A4%A7%E5%8D%80" title="中國地理大區">
中國地理大區
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks collapsible uncollapsed navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col" style=";background:#D8000F; color:#FFFFFF;">
<span style="float:left;width:8em;font-size:80%;margin-right:0.5em">
</span>
<div style="font-size:110%">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
<span style="color:white;">
中华人民共和国
</span>
</a>
的分区
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-image" rowspan="1" style="width:0%;padding:0px 2px 0px 0px">
<div>
<a class="image" href="/wiki/File:Regions_of_China_Names_Chinese_Simp.svg">
<img alt="Regions of China Names Chinese Simp.svg" data-file-height="699" data-file-width="857" decoding="async" height="245" src="//upload.wikimedia.org/wikipedia/commons/thumb/b/bb/Regions_of_China_Names_Chinese_Simp.svg/300px-Regions_of_China_Names_Chinese_Simp.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/b/bb/Regions_of_China_Names_Chinese_Simp.svg/450px-Regions_of_China_Names_Chinese_Simp.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/b/bb/Regions_of_China_Names_Chinese_Simp.svg/600px-Regions_of_China_Names_Chinese_Simp.svg.png 2x" width="300"/>
</a>
</div>
</td>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px">
<div style="padding:0em 0.25em">
<table>
<tbody>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #DAEA7B;color:black;font-size:small; width:1.5em">
</span>
<b>
<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区">
华北
</a>
</b>
</div>
</td>
<td align="left">
<a class="mw-selflink selflink">
北京
</a>
·
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">
山西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">
內蒙古
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #8092D4;color:black;font-size:small; width:1.5em">
</span>
<b>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%9C%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国东北地区">
东北
</a>
</b>
</div>
</td>
<td align="left">
<a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">
辽宁
</a>
·
<span class="nowrap">
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">
吉林
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">
黑龙江
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #99C1FB;color:black;font-size:small; width:1.5em">
</span>
<b>
<a href="/wiki/%E5%8D%8E%E4%B8%9C%E5%9C%B0%E5%8C%BA" title="华东地区">
华东
</a>
</b>
</div>
</td>
<td align="left">
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
·
<span class="nowrap">
<a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">
江苏
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">
浙江
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">
安徽
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
福建
</a>
<sup>
<small>
1
</small>
</sup>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">
江西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">
山东
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
<span style="color:grey;">
台湾
</span>
</a>
<sup>
<small>
1
</small>
</sup>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FADB4C;color:black;font-size:small; width:1.5em">
</span>
<b>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中南地区">
中南
</a>
</b>
</div>
</td>
<td align="left">
<a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">
河南
</a>
·
<span class="nowrap">
<a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">
湖北
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">
湖南
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">
广东
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">
广西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
海南
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%A6%99%E6%B8%AF%E7%89%B9%E5%88%A5%E8%A1%8C%E6%94%BF%E5%8D%80" title="香港特別行政區">
香港
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%BE%B3%E9%96%80%E7%89%B9%E5%88%A5%E8%A1%8C%E6%94%BF%E5%8D%80" title="澳門特別行政區">
澳門
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #DCA9E9;color:black;font-size:small; width:1.5em">
</span>
<b>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中国西南地区">
西南
</a>
</b>
</div>
</td>
<td align="left">
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆
</a>
·
<span class="nowrap">
<a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">
四川
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">
贵州
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">
云南
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">
西藏
</a>
<sup>
<small>
2
</small>
</sup>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFCB78;color:black;font-size:small; width:1.5em">
</span>
<b>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国西北地区">
西北
</a>
</b>
</div>
</td>
<td align="left">
<a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">
陕西
</a>
·
<span class="nowrap">
<a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">
甘肃
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">
青海
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">
宁夏
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">
新疆
</a>
</span>
</td>
</tr>
<tr>
<td align="left" colspan="2">
<b>
註:
</b>
<p>
<span style="position: relative; top: 0.2em;">
<sup>
1
</sup>
</span>
<a class="mw-redirect" href="/wiki/%E5%8F%B0%E6%B9%BE" title="台湾">
台湾
</a>
、
<a class="mw-redirect" href="/wiki/%E6%BE%8E%E6%B9%96" title="澎湖">
澎湖
</a>
、
<a class="mw-redirect" href="/wiki/%E9%87%91%E9%97%A8" title="金门">
金门
</a>
、
<a href="/wiki/%E9%A6%AC%E7%A5%96%E5%88%97%E5%B3%B6" title="馬祖列島">
马祖
</a>
等地实际仍由
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD%E6%94%BF%E5%BA%9C" title="中华民国政府">
中华民国政府
</a>
管辖。关于台澎归属问题,详见
<a class="mw-redirect" href="/wiki/%E5%8F%B0%E6%B9%BE%E9%97%AE%E9%A2%98" title="台湾问题">
台灣问题
</a>
;关于金马归属问题,详见
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)#國共內戰再起" title="福建省 (中華民國)">
金马地区沿革
</a>
。
</p>
<span style="position: relative; top: 0.2em;">
<sup>
2
</sup>
</span>
<a href="/wiki/%E8%97%8F%E5%8D%97%E5%9C%B0%E5%8D%80" title="藏南地區">
藏南地區
</a>
現由
<a href="/wiki/%E5%8D%B0%E5%BA%A6" title="印度">
印度
</a>
實際管轄,詳見
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%B0%E9%82%8A%E7%95%8C%E5%95%8F%E9%A1%8C" title="中印邊界問題">
中印邊界問題
</a>
。
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-list navbox-even" colspan="2" style="width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col" style=";background:#002864;color:white">
<span style="float:left;width:8em;font-size:80%;margin-right:0.5em">
</span>
<div style="font-size:110%">
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
<span style="color:white;">
中華民國
</span>
</a>
的分区
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-image" rowspan="1" style="width:0%;padding:0px 2px 0px 0px">
<div>
<a class="image" href="/wiki/File:ROC_Geo_Regions_Text.png">
<img alt="ROC Geo Regions Text.png" data-file-height="650" data-file-width="781" decoding="async" height="250" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fb/ROC_Geo_Regions_Text.png/300px-ROC_Geo_Regions_Text.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fb/ROC_Geo_Regions_Text.png/450px-ROC_Geo_Regions_Text.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fb/ROC_Geo_Regions_Text.png/600px-ROC_Geo_Regions_Text.png 2x" width="300"/>
</a>
</div>
</td>
<td class="navbox-list navbox-odd" colspan="2" style="width:100%;padding:0px">
<div style="padding:0em 0.25em">
<table>
<tbody>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #AAFFAA;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E5%8D%8E%E4%B8%AD%E5%9C%B0%E5%8C%BA" title="华中地区">
<b>
華中
</b>
</a>
</div>
</td>
<td align="left">
<a href="/wiki/%E6%B1%9F%E8%98%87%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="江蘇省 (中華民國)">
江蘇
</a>
·
<span class="nowrap">
<a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="浙江省 (中華民國)">
浙江
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="安徽省 (中華民國)">
安徽
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="江西省 (中華民國)">
江西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="湖北省 (中華民國)">
湖北
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="湖南省 (中華民國)">
湖南
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="四川省 (中華民國)">
四川
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">
南京市
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="上海市 (中華民國)">
上海市
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82" title="重慶市">
重慶市
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%BC%A2%E5%8F%A3%E5%B8%82" title="漢口市">
漢口市
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #AAFFFF;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E5%8D%8E%E5%8D%97%E5%9C%B0%E5%8C%BA" title="华南地区">
<b>
華南
</b>
</a>
</div>
</td>
<td align="left">
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="福建省 (中華民國)">
福建
</a>
·
<span class="nowrap">
<a href="/wiki/%E8%87%BA%E7%81%A3%E7%9C%81" title="臺灣省">
臺灣
</a>
<sup>
<small>
1
</small>
</sup>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BB%A3%E6%9D%B1%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣東省 (中華民國)">
廣東
</a>
<sup>
<small>
3
</small>
</sup>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%BB%A3%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣西省 (中華民國)">
廣西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9B%B2%E5%8D%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="雲南省 (中華民國)">
雲南
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%B2%B4%E5%B7%9E%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="貴州省 (中華民國)">
貴州
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%89%B9%E5%88%A5%E8%A1%8C%E6%94%BF%E5%8D%80" title="海南特別行政區">
海南特別行政區
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82" title="廣州市">
廣州市
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFFFAA;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区">
<b>
華北
</b>
</a>
</div>
</td>
<td align="left">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="河北省 (中華民國)">
河北
</a>
·
<span class="nowrap">
<a href="/wiki/%E5%B1%B1%E6%9D%B1%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="山東省 (中華民國)">
山東
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="河南省 (中華民國)">
河南
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="山西省 (中華民國)">
山西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%99%9D%E8%A5%BF%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="陝西省 (中華民國)">
陝西
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%94%98%E8%82%85%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="甘肅省 (中華民國)">
甘肅
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">
北平市
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%9D%92%E5%B3%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="青島市 (中華民國)">
青島市
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安市
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFD4AA;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E5%A1%9E%E5%8C%97" title="塞北">
<b>
塞北
</b>
</a>
</div>
</td>
<td align="left">
<a href="/wiki/%E5%AF%A7%E5%A4%8F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="寧夏省 (中華民國)">
寧夏
</a>
·
<span class="nowrap">
<a href="/wiki/%E7%B6%8F%E9%81%A0%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="綏遠省 (中華民國)">
綏遠
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%AF%9F%E5%93%88%E7%88%BE%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="察哈爾省 (中華民國)">
察哈爾
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E7%86%B1%E6%B2%B3%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="熱河省 (中華民國)">
熱河
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%92%99%E5%8F%A4%E5%9C%B0%E6%96%B9" title="蒙古地方">
蒙古地方
</a>
<sup>
<small>
2
</small>
</sup>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #FFAAAA;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E6%9D%B1%E5%8C%97%E6%96%B0%E7%9C%81%E5%8D%80%E6%96%B9%E6%A1%88" title="東北新省區方案">
<b>
東北
</b>
</a>
</div>
</td>
<td align="left">
<a href="/wiki/%E9%81%BC%E5%AF%A7%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="遼寧省 (中華民國)">
遼寧
</a>
·
<span class="nowrap">
<a href="/wiki/%E5%AE%89%E6%9D%B1%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="安東省 (中華民國)">
安東
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E9%81%BC%E5%8C%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="遼北省 (中華民國)">
遼北
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="吉林省 (中華民國)">
吉林
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%9D%BE%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="松江省 (中華民國)">
松江
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%90%88%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="合江省 (中華民國)">
合江
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E9%BB%91%E9%BE%8D%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="黑龍江省 (中華民國)">
黑龍江
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%AB%A9%E6%B1%9F%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="嫩江省 (中華民國)">
嫩江
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%88%88%E5%AE%89%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="興安省 (中華民國)">
興安
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%A4%A7%E9%80%A3%E5%B8%82" title="大連市">
大連市
</a>
·
</span>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E5%93%88%E7%88%BE%E6%BF%B1%E5%B8%82" title="哈爾濱市">
哈爾濱市
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
瀋陽市
</a>
</span>
</td>
</tr>
<tr>
<td>
<div class="legend">
<span class="legend-color" style="border:1px solid black;display:inline-block; height:1.5em; margin:1px; text-align:center; background: #D4AAFF;color:black;font-size:small; width:1.5em">
</span>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E9%83%A8" title="中国西部">
<b>
西部
</b>
</a>
</div>
</td>
<td align="left">
<a href="/wiki/%E8%A5%BF%E5%BA%B7%E7%9C%81" title="西康省">
西康
</a>
·
<span class="nowrap">
<a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="青海省 (中華民國)">
青海
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E6%96%B0%E7%96%86%E7%9C%81_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="新疆省 (中華民國)">
新疆
</a>
·
</span>
<span class="nowrap">
<a href="/wiki/%E8%A5%BF%E8%97%8F%E5%9C%B0%E6%96%B9" title="西藏地方">
西藏地方
</a>
</span>
</td>
</tr>
<tr>
<td align="left" colspan="2">
<b>
註:
</b>
此為1949年以前
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
統治
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86" title="中国大陆">
中国大陆
</a>
時所使用的分區,現已不再适用。
<p>
<span style="position: relative; top: 0.2em;">
<sup>
1
</sup>
</span>
1912年中華民國成立之时台湾仍为
<a href="/wiki/%E6%97%A5%E6%9C%AC" title="日本">
日本
</a>
属土,1945年日本戰敗投降后
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E6%94%BF%E5%BA%9C" title="中華民國政府">
中華民國政府
</a>
接收並統治至今,詳見
<a class="mw-redirect" href="/wiki/%E5%8F%B0%E6%B9%BE%E5%85%89%E5%A4%8D" title="台湾光复">
台湾光复
</a>
、
<a class="mw-redirect" href="/wiki/%E5%8F%B0%E7%81%A3%E5%95%8F%E9%A1%8C" title="台灣問題">
台灣問題
</a>
。
</p>
<p>
<span style="position: relative; top: 0.2em;">
<sup>
2
</sup>
</span>
即
<a href="/wiki/%E5%A4%96%E8%92%99%E5%8F%A4" title="外蒙古">
外蒙古
</a>
与
<a href="/wiki/%E5%94%90%E5%8A%AA%E4%B9%8C%E6%A2%81%E6%B5%B7" title="唐努乌梁海">
唐努乌梁海
</a>
地区,
<a href="/wiki/%E5%A4%96%E8%92%99%E5%8F%A4" title="外蒙古">
外蒙古
</a>
已成為主權獨立且受國際普遍承認之
<a class="mw-redirect" href="/wiki/%E8%92%99%E5%8F%A4%E5%9C%8B" title="蒙古國">
蒙古國
</a>
,中華民國政府亦然,並於2012年5月發新聞稿表示其非中華民國之「固有疆域」;
<a href="/wiki/%E5%94%90%E5%8A%AA%E4%B9%8C%E6%A2%81%E6%B5%B7" title="唐努乌梁海">
唐努乌梁海
</a>
地区于1921年成立
<a class="mw-redirect" href="/wiki/%E5%94%90%E5%8A%AA%EF%BC%8D%E5%9B%BE%E7%93%A6%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="唐努-图瓦人民共和国">
唐努-图瓦
</a>
,随后被
<a href="/wiki/%E8%8B%8F%E8%81%94" title="苏联">
苏联
</a>
吞并,
<a href="/wiki/%E8%8B%8F%E8%81%94%E8%A7%A3%E4%BD%93" title="苏联解体">
苏联解体
</a>
后被
<a href="/wiki/%E4%BF%84%E7%BD%97%E6%96%AF" title="俄罗斯">
俄罗斯
</a>
继承。
</p>
<span style="position: relative; top: 0.2em;">
<sup>
3
</sup>
</span>
广东省的
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港
</a>
和
<a class="mw-redirect" href="/wiki/%E6%BE%B3%E9%97%A8" title="澳门">
澳门
</a>
彼時分别為
<a href="/wiki/%E5%A4%A7%E8%8B%B1%E5%B8%9D%E5%9B%BD" title="大英帝国">
英國
</a>
与
<a href="/wiki/%E8%91%A1%E8%90%84%E7%89%99" title="葡萄牙">
葡萄牙
</a>
殖民地,詳見
<a href="/wiki/%E8%8B%B1%E5%B1%AC%E9%A6%99%E6%B8%AF" title="英屬香港">
英屬香港
</a>
及
<a class="mw-redirect" href="/wiki/%E8%91%A1%E5%B1%9E%E6%BE%B3%E9%97%A8" title="葡属澳门">
葡属澳门
</a>
。
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2" style="background: khaki;">
<div>
另见:
<b>
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E5%9C%B0%E7%90%86" title="中国地理">
中国地理
</a>
</b>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="Template:中国直辖市">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="Template talk:中国直辖市">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%9B%BD" title="中国">
中国
</a>
<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82" title="直辖市">
直辖市
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
附:
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="960" decoding="async" height="14" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/22px-Flag_of_China_%281912%E2%80%931928%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/33px-Flag_of_China_%281912%E2%80%931928%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/44px-Flag_of_China_%281912%E2%80%931928%29.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E5%A4%A7%E9%99%B8%E6%99%82%E6%9C%9F" title="中華民國大陸時期">
中华民国
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<sub>
(注)
</sub>
<br/>
<sub>
(1921年7月-1928年7月)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E4%BA%AC%E9%83%BD%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD)&action=edit&redlink=1" title="京都市 (中华民国)(页面不存在)">
京都市
</a>
<sub>
(受内务总长监督)
</sub>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%B4%A5%E6%B2%BD%E5%B8%82&action=edit&redlink=1" title="津沽市(页面不存在)">
津沽市
</a>
<sub>
(受直隶省省长监督)
</sub>
</li>
<li>
<a class="new" href="/w/index.php?title=%E6%B7%9E%E6%BB%AC%E5%B8%82&action=edit&redlink=1" title="淞滬市(页面不存在)">
淞滬市
</a>
<sub>
(受江苏省省长监督)
</sub>
</li>
<li>
<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">
青岛市
</a>
<sub>
(受山东省省长监督)
</sub>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E7%89%B9%E5%88%AB%E5%B8%82" title="哈尔滨特别市">
哈尔滨特别市
</a>
<sub>
(受
<a href="/wiki/%E4%B8%9C%E7%9C%81%E7%89%B9%E5%88%AB%E5%8C%BA%E8%A1%8C%E6%94%BF%E9%95%BF%E5%AE%98" title="东省特别区行政长官">
东省特别区行政长官
</a>
监督)
</sub>
</li>
<li>
<a href="/wiki/%E6%BC%A2%E5%8F%A3%E5%B8%82" title="漢口市">
汉口市
</a>
<sub>
(受湖北省省长监督)
</sub>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/22px-Flag_of_the_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/33px-Flag_of_the_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/44px-Flag_of_the_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1928年7月-1930年5月)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC%E7%89%B9%E5%88%A5%E5%B8%82" title="南京特別市">
南京特别市
</a>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E9%A6%96%E9%83%BD%E7%89%B9%E5%88%A5%E5%B8%82" title="首都特別市">
首都特别市
</a>
</span>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%8C%97%E5%B9%B3%E7%89%B9%E5%88%A5%E5%B8%82" title="北平特別市">
北平特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E6%B4%A5%E7%89%B9%E5%88%AB%E5%B8%82" title="天津特别市">
天津特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E9%9D%92%E5%B3%B6%E7%89%B9%E5%88%A5%E5%B8%82" title="青島特別市">
青岛特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E4%B8%8A%E6%B5%B7%E7%89%B9%E5%88%AB%E5%B8%82" title="上海特别市">
上海特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E6%AD%A6%E6%B1%89%E7%89%B9%E5%88%AB%E5%B8%82" title="武汉特别市">
武汉特别市
</a>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E6%BC%A2%E5%8F%A3%E7%89%B9%E5%88%A5%E5%B8%82" title="漢口特別市">
汉口特别市
</a>
</span>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%B9%BF%E5%B7%9E%E7%89%B9%E5%88%AB%E5%B8%82" title="广州特别市">
广州特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E7%89%B9%E5%88%AB%E5%B8%82" title="哈尔滨特别市">
哈尔滨特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/22px-Flag_of_the_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/33px-Flag_of_the_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/72/Flag_of_the_Republic_of_China.svg/44px-Flag_of_the_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
中華民國
</a>
<a class="mw-redirect" href="/wiki/%E9%99%A2%E8%BE%96%E5%B8%82" title="院辖市">
院辖市
</a>
<br/>
<sub>
(1930年5月-1949年)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="南京市 (中華民國)">
南京市
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E5%B9%B3%E5%B8%82" title="北平市">
北平市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="天津市 (中華民國)">
天津市
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E5%B3%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="青島市 (中華民國)">
青岛市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E8%A5%BF%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD)" title="西京市 (中华民国)">
西京市
</a>
<span class="nowrap">
→
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="西安市 (中華民國)">
西安市
</a>
(1948年改制)
</span>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="上海市 (中華民國)">
上海市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E6%BC%A2%E5%8F%A3%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="漢口市 (中華民國)">
汉口市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%A3%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="廣州市 (中華民國)">
广州市
</a>
</li>
<li>
<a href="/wiki/%E9%87%8D%E6%85%B6%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="重慶市 (中華民國)">
重庆市
</a>
(1939年改制)
</li>
<li>
<a href="/wiki/%E5%A4%A7%E9%80%A3%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="大連市 (中華民國)">
大连市
</a>
(1945年改制)
</li>
<li>
<a href="/wiki/%E5%93%88%E7%88%BE%E6%BF%B1%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="哈爾濱市 (中華民國)">
哈尔滨市
</a>
(1947年改制)
</li>
<li>
<a href="/wiki/%E7%80%8B%E9%99%BD%E5%B8%82_(%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B)" title="瀋陽市 (中華民國)">
沈阳市
</a>
(1947年改制)
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8c/Flag_of_Manchukuo.svg/22px-Flag_of_Manchukuo.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8c/Flag_of_Manchukuo.svg/33px-Flag_of_Manchukuo.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8c/Flag_of_Manchukuo.svg/44px-Flag_of_Manchukuo.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E6%BB%A1%E6%B4%B2%E5%9B%BD" title="满洲国">
滿洲國
</a>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E6%BB%BF%E6%B4%B2%E5%B8%9D%E5%9C%8B" title="滿洲帝國">
满洲帝国
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1932年-1945年)
</sub>
</span>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E9%95%BF%E6%98%A5%E7%89%B9%E5%88%AB%E5%B8%82" title="长春特别市">
长春特别市
</a>
<span class="nowrap">
→
<a href="/wiki/%E6%96%B0%E4%BA%AC" title="新京">
新京特别市
</a>
</span>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E7%89%B9%E5%88%AB%E5%B8%82" title="哈尔滨特别市">
哈尔滨特别市
</a>
<sub>
(1933年-1937年)
</sub>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<a class="image" href="/wiki/File:Flag_of_Fujian_People%27s_Government.svg">
<img alt="Flag of Fujian People's Government.svg" data-file-height="600" data-file-width="900" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Fujian_People%27s_Government.svg/25px-Flag_of_Fujian_People%27s_Government.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Fujian_People%27s_Government.svg/38px-Flag_of_Fujian_People%27s_Government.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d9/Flag_of_Fujian_People%27s_Government.svg/50px-Flag_of_Fujian_People%27s_Government.svg.png 2x" width="25"/>
</a>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华共和国">
中华共和国
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1933年-1934年)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E7%A6%8F%E5%B7%9E%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="福州特别市(页面不存在)">
福州特别市
</a>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8E%A6%E9%97%A8%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="厦门特别市(页面不存在)">
厦门特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<a class="image" href="/wiki/File:Flag_of_Mongol_United_Autonomous_Government_(1937-1939).svg">
<img alt="Flag of Mongol United Autonomous Government (1937-1939).svg" data-file-height="434" data-file-width="737" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg/25px-Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg/38px-Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg/50px-Flag_of_Mongol_United_Autonomous_Government_%281937-1939%29.svg.png 2x" width="25"/>
</a>
<a href="/wiki/%E8%92%99%E5%8F%A4%E8%81%94%E7%9B%9F%E8%87%AA%E6%B2%BB%E6%94%BF%E5%BA%9C" title="蒙古联盟自治政府">
蒙古联盟自治政府
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1937年-1939年)
</sub>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E5%8E%9A%E5%92%8C%E8%B1%AA%E7%89%B9%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="厚和豪特特别市(页面不存在)">
厚和豪特特别市
</a>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E5%8E%9A%E5%92%8C%E7%89%B9%E5%88%AB%E5%B8%82" title="厚和特别市">
厚和特别市
</a>
</span>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8C%85%E5%A4%B4%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="包头特别市(页面不存在)">
包头特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<a class="image" href="/wiki/File:Flag_of_the_Mengjiang.svg">
<img alt="Flag of the Mengjiang.svg" data-file-height="300" data-file-width="450" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6d/Flag_of_the_Mengjiang.svg/25px-Flag_of_the_Mengjiang.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6d/Flag_of_the_Mengjiang.svg/38px-Flag_of_the_Mengjiang.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6d/Flag_of_the_Mengjiang.svg/50px-Flag_of_the_Mengjiang.svg.png 2x" width="25"/>
</a>
<a class="mw-redirect" href="/wiki/%E8%92%99%E7%96%86%E8%81%94%E5%90%88%E8%87%AA%E6%B2%BB%E6%94%BF%E5%BA%9C" title="蒙疆联合自治政府">
蒙疆联合自治政府
</a>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E9%82%A6" title="蒙古自治邦">
蒙古自治邦
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1939年-1945年)
</sub>
</span>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E7%89%B9%E5%88%AB%E5%B8%82" title="张家口特别市">
张家口特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B" title="中華民國">
<img alt="中華民國" class="thumbborder" data-file-height="600" data-file-width="960" decoding="async" height="14" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/22px-Flag_of_China_%281912%E2%80%931928%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/33px-Flag_of_China_%281912%E2%80%931928%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/ff/Flag_of_China_%281912%E2%80%931928%29.svg/44px-Flag_of_China_%281912%E2%80%931928%29.svg.png 2x" width="22"/>
</a>
</span>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E8%8F%AF%E6%B0%91%E5%9C%8B%E8%87%A8%E6%99%82%E6%94%BF%E5%BA%9C_(1937%E2%80%931940)" title="中華民國臨時政府 (1937–1940)">
中华民国临时政府
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1937年-1940年)
</sub>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="北京特别市(页面不存在)">
北京特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E6%B4%A5%E7%89%B9%E5%88%AB%E5%B8%82" title="天津特别市">
天津特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<a class="image" href="/wiki/File:Flag_of_Reformed_Government_of_the_Republic_of_China.svg">
<img alt="Flag of Reformed Government of the Republic of China.svg" data-file-height="300" data-file-width="480" decoding="async" height="16" src="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Flag_of_Reformed_Government_of_the_Republic_of_China.svg/25px-Flag_of_Reformed_Government_of_the_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Flag_of_Reformed_Government_of_the_Republic_of_China.svg/38px-Flag_of_Reformed_Government_of_the_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/e/e6/Flag_of_Reformed_Government_of_the_Republic_of_China.svg/50px-Flag_of_Reformed_Government_of_the_Republic_of_China.svg.png 2x" width="25"/>
</a>
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD%E7%BB%B4%E6%96%B0%E6%94%BF%E5%BA%9C" title="中华民国维新政府">
中华民国维新政府
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1938年-1940年)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC%E7%89%B9%E5%88%A5%E5%B8%82" title="南京特別市">
南京特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E4%B8%8A%E6%B5%B7%E7%89%B9%E5%88%AB%E5%B8%82" title="上海特别市">
上海特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<a class="image" href="/wiki/File:Flag_of_the_Republic_of_China-Nanjing_(Peace,_Anti-Communism,_National_Construction).svg">
<img alt="Flag of the Republic of China-Nanjing (Peace, Anti-Communism, National Construction).svg" data-file-height="825" data-file-width="900" decoding="async" height="23" src="//upload.wikimedia.org/wikipedia/commons/thumb/0/08/Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg/25px-Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/0/08/Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg/38px-Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/0/08/Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg/50px-Flag_of_the_Republic_of_China-Nanjing_%28Peace%2C_Anti-Communism%2C_National_Construction%29.svg.png 2x" width="25"/>
</a>
<a href="/wiki/%E6%B1%AA%E7%B2%BE%E5%8D%AB%E6%94%BF%E6%9D%83" title="汪精卫政权">
汪精卫政权
</a>
<a class="mw-redirect" href="/wiki/%E7%89%B9%E5%88%AB%E5%B8%82" title="特别市">
特别市
</a>
<br/>
<sub>
(1940年-1945年)
</sub>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E5%8D%97%E4%BA%AC%E7%89%B9%E5%88%A5%E5%B8%82" title="南京特別市">
南京特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E4%B8%8A%E6%B5%B7%E7%89%B9%E5%88%AB%E5%B8%82" title="上海特别市">
上海特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E6%AD%A6%E6%B1%89%E7%89%B9%E5%88%AB%E5%B8%82" title="武汉特别市">
武汉特别市
</a>
<span class="nowrap">
→
<a class="mw-redirect" href="/wiki/%E6%BC%A2%E5%8F%A3%E7%89%B9%E5%88%A5%E5%B8%82" title="漢口特別市">
汉口特别市
</a>
</span>
</li>
<li>
<a class="new" href="/w/index.php?title=%E5%8E%A6%E9%97%A8%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="厦门特别市(页面不存在)">
厦门特别市
</a>
</li>
</ul>
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%8E%E5%8C%97%E6%94%BF%E5%8A%A1%E5%A7%94%E5%91%98%E4%BC%9A" title="华北政务委员会">
华北政务委员会
</a>
直属
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="new" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E7%89%B9%E5%88%AB%E5%B8%82&action=edit&redlink=1" title="北京特别市(页面不存在)">
北京特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E5%A4%A9%E6%B4%A5%E7%89%B9%E5%88%AB%E5%B8%82" title="天津特别市">
天津特别市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E9%9D%92%E5%B3%B6%E7%89%B9%E5%88%A5%E5%B8%82" title="青島特別市">
青岛特别市
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="中华人民共和国直辖市">
直辖市
</a>
<br/>
<sub>
(1949年-1953年)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E4%B8%AD%E5%A4%AE%E4%BA%BA%E6%B0%91%E6%94%BF%E5%BA%9C_(1949%E5%B9%B4%EF%BC%8D1954%E5%B9%B4)" title="中華人民共和國中央人民政府 (1949年-1954年)">
中央
</a>
直属
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a class="new" href="/w/index.php?title=%E5%A4%A7%E8%A1%8C%E6%94%BF%E5%8C%BA%E7%9B%B4%E8%BE%96%E5%B8%82&action=edit&redlink=1" title="大行政区直辖市(页面不存在)">
大区直属
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
华东:
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="南京市 (中华人民共和国直辖市)">
南京市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
<br/>
中南:
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="武汉市 (中华人民共和国直辖市)">
武汉市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="广州市 (中华人民共和国直辖市)">
广州市
</a>
<br/>
西南:
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆市
</a>
<br/>
西北:
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="西安市 (中华人民共和国直辖市)">
西安市
</a>
<br/>
<a href="/wiki/%E4%B8%9C%E5%8C%97%E5%A4%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="东北大行政区">
东北
</a>
:
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="沈阳市 (中华人民共和国直辖市)">
沈阳市
</a>
</li>
<li>
<a href="/wiki/%E6%97%85%E5%A4%A7%E5%B8%82" title="旅大市">
旅大市
</a>
</li>
<li>
<a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="鞍山市 (中华人民共和国直辖市)">
鞍山市
</a>
</li>
<li>
<a href="/wiki/%E6%8A%9A%E9%A1%BA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="抚顺市 (中华人民共和国直辖市)">
抚顺市
</a>
</li>
<li>
<a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="本溪市 (中华人民共和国直辖市)">
本溪市
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="中华人民共和国直辖市">
直辖市
</a>
<br/>
<sub>
(1953年-1954年)
</sub>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="南京市 (中华人民共和国直辖市)">
南京市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="沈阳市 (中华人民共和国直辖市)">
沈阳市
</a>
</li>
<li>
<a href="/wiki/%E6%97%85%E5%A4%A7%E5%B8%82" title="旅大市">
旅大市
</a>
</li>
<li>
<a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="鞍山市 (中华人民共和国直辖市)">
鞍山市
</a>
</li>
<li>
<a href="/wiki/%E6%8A%9A%E9%A1%BA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="抚顺市 (中华人民共和国直辖市)">
抚顺市
</a>
</li>
<li>
<a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="本溪市 (中华人民共和国直辖市)">
本溪市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="广州市 (中华人民共和国直辖市)">
广州市
</a>
</li>
<li>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆市
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="西安市 (中华人民共和国直辖市)">
西安市
</a>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="武汉市 (中华人民共和国直辖市)">
武汉市
</a>
</li>
<li>
<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="哈尔滨市 (中华人民共和国直辖市)">
哈尔滨市
</a>
</li>
<li>
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82)" title="长春市 (中华人民共和国直辖市)">
长春市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: left;">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82" title="中华人民共和国直辖市">
直辖市
</a>
<br/>
<sub>
(1954年至今)
</sub>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
<sub>
(1958年–1967年划归河北省)
</sub>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</li>
<li>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆市
</a>
<sub>
(1954年–1997年划归四川省)
</sub>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2">
<div>
参见:
<a class="new" href="/w/index.php?title=%E4%B8%AD%E5%9B%BD%E7%9B%B4%E8%BE%96%E5%B8%82%E5%88%97%E8%A1%A8&action=edit&redlink=1" title="中国直辖市列表(页面不存在)">
中国直辖市列表
</a>
<br/>
<small>
注:该“特别市”是1921年7月3日北洋政府頒布的《市自治制》中规定的和“普通市”相对的市,并不等同于直辖市。后来成立或拟成立的各特别市中,除
<a class="new" href="/w/index.php?title=%E4%BA%AC%E9%83%BD%E5%B8%82_(%E4%B8%AD%E5%8D%8E%E6%B0%91%E5%9B%BD)&action=edit&redlink=1" title="京都市 (中华民国)(页面不存在)">
京都市
</a>
受内务总长监督,尚可算作直辖市外,其余各特别市均受省级行政长官监督,并非直辖市。姑列于此,供参考。
</small>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国中心城市">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Template talk:中华人民共和国中心城市">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
中心
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%BB%BA%E5%88%B6" title="中华人民共和国城市建制">
城市
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="国家中心城市">
国家中心城市
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
2005年正式版
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州
</a>
</li>
<li>
<a href="/wiki/%E9%A6%99%E6%B8%AF" title="香港">
香港
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
2010年草案版
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海
</a>
</li>
<li>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
2016年后续版
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉
</a>
</li>
<li>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
<td class="navbox-image" rowspan="3" style="width:0%;padding:0px 0px 0px 2px">
<div>
<a class="image" href="/wiki/File:Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png">
<img alt="Map of National central cities in the People's Republic of China.png" data-file-height="2183" data-file-width="2677" decoding="async" height="163" src="//upload.wikimedia.org/wikipedia/commons/thumb/d/d0/Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png/200px-Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/d0/Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png/300px-Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/d0/Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png/400px-Map_of_National_central_cities_in_the_People%27s_Republic_of_China.png 2x" width="200"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8C%BA%E5%9F%9F%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="区域中心城市">
区域中心城市
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
2005年正式版
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
华北:
<a href="/wiki/%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%B8%82" title="石家庄市">
石家庄
</a>
<ul>
<li>
<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">
太原
</a>
</li>
<li>
<a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">
呼和浩特
</a>
<br/>
东北:
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
沈阳
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E8%BF%9E%E5%B8%82" title="大连市">
大连
</a>
</li>
<li>
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">
长春
</a>
</li>
<li>
<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">
哈尔滨
</a>
<br/>
华东:
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京
</a>
</li>
<li>
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州
</a>
</li>
<li>
<a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">
宁波
</a>
</li>
<li>
<a href="/wiki/%E5%8E%A6%E9%97%A8%E5%B8%82" title="厦门市">
厦门
</a>
</li>
<li>
<a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">
济南
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">
青岛
</a>
</li>
<li>
<a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">
福州
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">
南昌
</a>
</li>
<li>
<a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">
合肥
</a>
<br/>
中南:
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉
</a>
</li>
<li>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州
</a>
</li>
<li>
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳
</a>
</li>
<li>
<a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">
长沙
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E5%AE%81%E5%B8%82" title="南宁市">
南宁
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">
海口
</a>
<br/>
西南:
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆
</a>
</li>
<li>
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
</li>
<li>
<a href="/wiki/%E8%B4%B5%E9%98%B3%E5%B8%82" title="贵阳市">
贵阳
</a>
</li>
<li>
<a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">
昆明
</a>
<br/>
西北:
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安
</a>
</li>
<li>
<a href="/wiki/%E5%85%B0%E5%B7%9E%E5%B8%82" title="兰州市">
兰州
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%81%E5%B8%82" title="西宁市">
西宁
</a>
</li>
<li>
<a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">
银川
</a>
</li>
<li>
<a href="/wiki/%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%B8%82" title="乌鲁木齐市">
乌鲁木齐
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="text-align: center;">
2010年草案版
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
沈阳
</a>
<small>
(东北)
</small>
<li>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京
</a>
<small>
(华东)
</small>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉
</a>
<small>
(华中)
</small>
</li>
<li>
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳
</a>
<small>
(华南)
</small>
</li>
<li>
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都
</a>
<small>
(西南)
</small>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安
</a>
<small>
(西北)
</small>
</li>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3">
<div>
注:
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="国家中心城市">
国家中心城市
</a>
在《
<a class="new" href="/w/index.php?title=%E5%85%A8%E5%9B%BD%E5%9F%8E%E9%95%87%E4%BD%93%E7%B3%BB%E8%A7%84%E5%88%92%E7%BA%B2%E8%A6%81&action=edit&redlink=1" title="全国城镇体系规划纲要(页面不存在)">
全国城镇体系规划纲要
</a>
(2005-2020年)》中称“
<a href="/wiki/%E5%85%A8%E7%90%83%E5%9F%8E%E5%B8%82" title="全球城市">
全球职能城市
</a>
”,概念略有不同。
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks hlist collapsible collapsed navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="3" scope="col">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">
<abbr style=";;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a href="/wiki/Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template talk:中华人民共和国地级以上行政区">
<abbr style=";;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA&action=edit">
<abbr style=";;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<span class="flagicon">
<img alt="" class="thumbborder" data-file-height="600" data-file-width="900" decoding="async" height="15" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/22px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/33px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/44px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="22"/>
</span>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
中华人民共和国
</a>
<a href="/wiki/%E5%9C%B0%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="地级行政区">
地级
</a>
以上
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
行政区
</a>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3">
<div>
<ul>
<li>
☆1个
<a href="/wiki/%E5%89%AF%E7%9C%81%E7%BA%A7%E8%87%AA%E6%B2%BB%E5%B7%9E" title="副省级自治州">
副省级自治州
</a>
、★15个
<a href="/wiki/%E5%89%AF%E7%9C%81%E7%BA%A7%E5%B8%82" title="副省级市">
副省级市
</a>
、✦5个
<a href="/wiki/%E8%AE%A1%E5%88%92%E5%8D%95%E5%88%97%E5%B8%82" title="计划单列市">
计划单列市
</a>
、✧18个
<a href="/wiki/%E8%BE%83%E5%A4%A7%E7%9A%84%E5%B8%82" title="较大的市">
经国务院批准的较大的市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%80%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="一级行政区">
中央直属
</a>
<br/>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%BB%BA%E5%88%B6" title="中华人民共和国城市建制">
市域
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E7%9B%B4%E8%BE%96%E5%B8%82#中华人民共和国" title="直辖市">
直辖市
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B4%A5%E5%B8%82" title="天津市">
天津市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</li>
<li>
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
重庆市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" title="特别行政区">
特别行政区
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-redirect" href="/wiki/%E9%A6%99%E6%B8%AF%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" title="香港特别行政区">
香港特别行政区
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E6%BE%B3%E9%97%A8%E7%89%B9%E5%88%AB%E8%A1%8C%E6%94%BF%E5%8C%BA" title="澳门特别行政区">
澳门特别行政区
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
<td class="navbox-image" rowspan="13" style="width:0%;padding:0px 0px 0px 2px">
<div>
<a class="image" href="/wiki/File:China_Prefectural-level_divisions_(PRC_claim).png">
<img alt="China Prefectural-level divisions (PRC claim).png" data-file-height="2179" data-file-width="2677" decoding="async" height="163" src="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/China_Prefectural-level_divisions_%28PRC_claim%29.png/200px-China_Prefectural-level_divisions_%28PRC_claim%29.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/China_Prefectural-level_divisions_%28PRC_claim%29.png/300px-China_Prefectural-level_divisions_%28PRC_claim%29.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/China_Prefectural-level_divisions_%28PRC_claim%29.png/400px-China_Prefectural-level_divisions_%28PRC_claim%29.png 2x" width="200"/>
</a>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%8E%E5%8C%97%E5%9C%B0%E5%8C%BA" title="华北地区">
华北地区
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
河北
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%B8%82" title="石家庄市">
石家庄市
</a>
</li>
<li>
✧
<a href="/wiki/%E5%94%90%E5%B1%B1%E5%B8%82" title="唐山市">
唐山市
</a>
</li>
<li>
<a href="/wiki/%E7%A7%A6%E7%9A%87%E5%B2%9B%E5%B8%82" title="秦皇岛市">
秦皇岛市
</a>
</li>
<li>
✧
<a href="/wiki/%E9%82%AF%E9%83%B8%E5%B8%82" title="邯郸市">
邯郸市
</a>
</li>
<li>
<a href="/wiki/%E9%82%A2%E5%8F%B0%E5%B8%82" title="邢台市">
邢台市
</a>
</li>
<li>
<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">
保定市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">
张家口市
</a>
</li>
<li>
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">
承德市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%A7%E5%B7%9E%E5%B8%82" title="沧州市">
沧州市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">
廊坊市
</a>
</li>
<li>
<a href="/wiki/%E8%A1%A1%E6%B0%B4%E5%B8%82" title="衡水市">
衡水市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">
山西
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">
太原市
</a>
</li>
<li>
✧
<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">
大同市
</a>
</li>
<li>
<a href="/wiki/%E9%98%B3%E6%B3%89%E5%B8%82" title="阳泉市">
阳泉市
</a>
</li>
<li>
<a href="/wiki/%E9%95%BF%E6%B2%BB%E5%B8%82" title="长治市">
长治市
</a>
</li>
<li>
<a href="/wiki/%E6%99%8B%E5%9F%8E%E5%B8%82" title="晋城市">
晋城市
</a>
</li>
<li>
<a href="/wiki/%E6%9C%94%E5%B7%9E%E5%B8%82" title="朔州市">
朔州市
</a>
</li>
<li>
<a href="/wiki/%E6%99%8B%E4%B8%AD%E5%B8%82" title="晋中市">
晋中市
</a>
</li>
<li>
<a href="/wiki/%E8%BF%90%E5%9F%8E%E5%B8%82" title="运城市">
运城市
</a>
</li>
<li>
<a href="/wiki/%E5%BF%BB%E5%B7%9E%E5%B8%82" title="忻州市">
忻州市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B4%E6%B1%BE%E5%B8%82" title="临汾市">
临汾市
</a>
</li>
<li>
<a href="/wiki/%E5%90%95%E6%A2%81%E5%B8%82" title="吕梁市">
吕梁市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">
内蒙古
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">
呼和浩特市
</a>
</li>
<li>
✧
<a href="/wiki/%E5%8C%85%E5%A4%B4%E5%B8%82" title="包头市">
包头市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%8C%E6%B5%B7%E5%B8%82" title="乌海市">
乌海市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%A4%E5%B3%B0%E5%B8%82" title="赤峰市">
赤峰市
</a>
</li>
<li>
<a href="/wiki/%E9%80%9A%E8%BE%BD%E5%B8%82" title="通辽市">
通辽市
</a>
</li>
<li>
<a href="/wiki/%E9%84%82%E5%B0%94%E5%A4%9A%E6%96%AF%E5%B8%82" title="鄂尔多斯市">
鄂尔多斯市
</a>
</li>
<li>
<a href="/wiki/%E5%91%BC%E4%BC%A6%E8%B4%9D%E5%B0%94%E5%B8%82" title="呼伦贝尔市">
呼伦贝尔市
</a>
</li>
<li>
<a href="/wiki/%E5%B7%B4%E5%BD%A6%E6%B7%96%E5%B0%94%E5%B8%82" title="巴彦淖尔市">
巴彦淖尔市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%8C%E5%85%B0%E5%AF%9F%E5%B8%83%E5%B8%82" title="乌兰察布市">
乌兰察布市
</a>
</li>
<li>
<a href="/wiki/%E5%85%B4%E5%AE%89%E7%9B%9F" title="兴安盟">
兴安盟
</a>
</li>
<li>
<a href="/wiki/%E9%94%A1%E6%9E%97%E9%83%AD%E5%8B%92%E7%9B%9F" title="锡林郭勒盟">
锡林郭勒盟
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E6%8B%89%E5%96%84%E7%9B%9F" title="阿拉善盟">
阿拉善盟
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E4%B8%9C%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国东北地区">
东北地区
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">
辽宁
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
沈阳市
</a>
</li>
<li>
★✦✧
<a href="/wiki/%E5%A4%A7%E8%BF%9E%E5%B8%82" title="大连市">
大连市
</a>
</li>
<li>
✧
<a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82" title="鞍山市">
鞍山市
</a>
</li>
<li>
✧
<a href="/wiki/%E6%8A%9A%E9%A1%BA%E5%B8%82" title="抚顺市">
抚顺市
</a>
</li>
<li>
✧
<a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82" title="本溪市">
本溪市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B9%E4%B8%9C%E5%B8%82" title="丹东市">
丹东市
</a>
</li>
<li>
<a href="/wiki/%E9%94%A6%E5%B7%9E%E5%B8%82" title="锦州市">
锦州市
</a>
</li>
<li>
<a href="/wiki/%E8%90%A5%E5%8F%A3%E5%B8%82" title="营口市">
营口市
</a>
</li>
<li>
<a href="/wiki/%E9%98%9C%E6%96%B0%E5%B8%82" title="阜新市">
阜新市
</a>
</li>
<li>
<a href="/wiki/%E8%BE%BD%E9%98%B3%E5%B8%82" title="辽阳市">
辽阳市
</a>
</li>
<li>
<a href="/wiki/%E7%9B%98%E9%94%A6%E5%B8%82" title="盘锦市">
盘锦市
</a>
</li>
<li>
<a href="/wiki/%E9%93%81%E5%B2%AD%E5%B8%82" title="铁岭市">
铁岭市
</a>
</li>
<li>
<a href="/wiki/%E6%9C%9D%E9%98%B3%E5%B8%82" title="朝阳市">
朝阳市
</a>
</li>
<li>
<a href="/wiki/%E8%91%AB%E8%8A%A6%E5%B2%9B%E5%B8%82" title="葫芦岛市">
葫芦岛市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">
吉林
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">
长春市
</a>
</li>
<li>
✧
<a href="/wiki/%E5%90%89%E6%9E%97%E5%B8%82" title="吉林市">
吉林市
</a>
</li>
<li>
<a href="/wiki/%E5%9B%9B%E5%B9%B3%E5%B8%82" title="四平市">
四平市
</a>
</li>
<li>
<a href="/wiki/%E8%BE%BD%E6%BA%90%E5%B8%82" title="辽源市">
辽源市
</a>
</li>
<li>
<a href="/wiki/%E9%80%9A%E5%8C%96%E5%B8%82" title="通化市">
通化市
</a>
</li>
<li>
<a href="/wiki/%E7%99%BD%E5%B1%B1%E5%B8%82" title="白山市">
白山市
</a>
</li>
<li>
<a href="/wiki/%E6%9D%BE%E5%8E%9F%E5%B8%82_(%E5%90%89%E6%9E%97%E7%9C%81)" title="松原市 (吉林省)">
松原市
</a>
</li>
<li>
<a href="/wiki/%E7%99%BD%E5%9F%8E%E5%B8%82" title="白城市">
白城市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%B6%E8%BE%B9%E6%9C%9D%E9%B2%9C%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="延边朝鲜族自治州">
延边朝鲜族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">
黑龙江
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82" title="哈尔滨市">
哈尔滨市
</a>
</li>
<li>
✧
<a href="/wiki/%E9%BD%90%E9%BD%90%E5%93%88%E5%B0%94%E5%B8%82" title="齐齐哈尔市">
齐齐哈尔市
</a>
</li>
<li>
<a href="/wiki/%E9%B8%A1%E8%A5%BF%E5%B8%82" title="鸡西市">
鸡西市
</a>
</li>
<li>
<a href="/wiki/%E9%B9%A4%E5%B2%97%E5%B8%82" title="鹤岗市">
鹤岗市
</a>
</li>
<li>
<a href="/wiki/%E5%8F%8C%E9%B8%AD%E5%B1%B1%E5%B8%82" title="双鸭山市">
双鸭山市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%BA%86%E5%B8%82" title="大庆市">
大庆市
</a>
</li>
<li>
<a href="/wiki/%E4%BC%8A%E6%98%A5%E5%B8%82" title="伊春市">
伊春市
</a>
</li>
<li>
<a href="/wiki/%E4%BD%B3%E6%9C%A8%E6%96%AF%E5%B8%82" title="佳木斯市">
佳木斯市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%83%E5%8F%B0%E6%B2%B3%E5%B8%82" title="七台河市">
七台河市
</a>
</li>
<li>
<a href="/wiki/%E7%89%A1%E4%B8%B9%E6%B1%9F%E5%B8%82" title="牡丹江市">
牡丹江市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%91%E6%B2%B3%E5%B8%82" title="黑河市">
黑河市
</a>
</li>
<li>
<a href="/wiki/%E7%BB%A5%E5%8C%96%E5%B8%82" title="绥化市">
绥化市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%85%B4%E5%AE%89%E5%B2%AD%E5%9C%B0%E5%8C%BA" title="大兴安岭地区">
大兴安岭地区
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%8D%8E%E4%B8%9C%E5%9C%B0%E5%8C%BA" title="华东地区">
华东地区
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">
江苏
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京市
</a>
</li>
<li>
✧
<a href="/wiki/%E6%97%A0%E9%94%A1%E5%B8%82" title="无锡市">
无锡市
</a>
</li>
<li>
✧
<a href="/wiki/%E5%BE%90%E5%B7%9E%E5%B8%82" title="徐州市">
徐州市
</a>
</li>
<li>
<a href="/wiki/%E5%B8%B8%E5%B7%9E%E5%B8%82" title="常州市">
常州市
</a>
</li>
<li>
✧
<a href="/wiki/%E8%8B%8F%E5%B7%9E%E5%B8%82" title="苏州市">
苏州市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E9%80%9A%E5%B8%82" title="南通市">
南通市
</a>
</li>
<li>
<a href="/wiki/%E8%BF%9E%E4%BA%91%E6%B8%AF%E5%B8%82" title="连云港市">
连云港市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%AE%E5%AE%89%E5%B8%82" title="淮安市">
淮安市
</a>
</li>
<li>
<a href="/wiki/%E7%9B%90%E5%9F%8E%E5%B8%82" title="盐城市">
盐城市
</a>
</li>
<li>
<a href="/wiki/%E6%89%AC%E5%B7%9E%E5%B8%82" title="扬州市">
扬州市
</a>
</li>
<li>
<a href="/wiki/%E9%95%87%E6%B1%9F%E5%B8%82" title="镇江市">
镇江市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%B0%E5%B7%9E%E5%B8%82" title="泰州市">
泰州市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%BF%E8%BF%81%E5%B8%82" title="宿迁市">
宿迁市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">
浙江
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州市
</a>
</li>
<li>
★✦✧
<a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">
宁波市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%A9%E5%B7%9E%E5%B8%82" title="温州市">
温州市
</a>
</li>
<li>
<a href="/wiki/%E5%98%89%E5%85%B4%E5%B8%82" title="嘉兴市">
嘉兴市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%96%E5%B7%9E%E5%B8%82" title="湖州市">
湖州市
</a>
</li>
<li>
<a href="/wiki/%E7%BB%8D%E5%85%B4%E5%B8%82" title="绍兴市">
绍兴市
</a>
</li>
<li>
<a href="/wiki/%E9%87%91%E5%8D%8E%E5%B8%82" title="金华市">
金华市
</a>
</li>
<li>
<a href="/wiki/%E8%A1%A2%E5%B7%9E%E5%B8%82" title="衢州市">
衢州市
</a>
</li>
<li>
<a href="/wiki/%E8%88%9F%E5%B1%B1%E5%B8%82" title="舟山市">
舟山市
</a>
</li>
<li>
<a href="/wiki/%E5%8F%B0%E5%B7%9E%E5%B8%82" title="台州市">
台州市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%BD%E6%B0%B4%E5%B8%82" title="丽水市">
丽水市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">
安徽
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">
合肥市
</a>
</li>
<li>
<a href="/wiki/%E8%8A%9C%E6%B9%96%E5%B8%82" title="芜湖市">
芜湖市
</a>
</li>
<li>
<a href="/wiki/%E8%9A%8C%E5%9F%A0%E5%B8%82" title="蚌埠市">
蚌埠市
</a>
</li>
<li>
✧
<a href="/wiki/%E6%B7%AE%E5%8D%97%E5%B8%82" title="淮南市">
淮南市
</a>
</li>
<li>
<a href="/wiki/%E9%A9%AC%E9%9E%8D%E5%B1%B1%E5%B8%82" title="马鞍山市">
马鞍山市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%AE%E5%8C%97%E5%B8%82" title="淮北市">
淮北市
</a>
</li>
<li>
<a href="/wiki/%E9%93%9C%E9%99%B5%E5%B8%82" title="铜陵市">
铜陵市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E5%BA%86%E5%B8%82" title="安庆市">
安庆市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E5%B1%B1%E5%B8%82" title="黄山市">
黄山市
</a>
</li>
<li>
<a href="/wiki/%E6%BB%81%E5%B7%9E%E5%B8%82" title="滁州市">
滁州市
</a>
</li>
<li>
<a href="/wiki/%E9%98%9C%E9%98%B3%E5%B8%82" title="阜阳市">
阜阳市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%BF%E5%B7%9E%E5%B8%82" title="宿州市">
宿州市
</a>
</li>
<li>
<a href="/wiki/%E5%85%AD%E5%AE%89%E5%B8%82" title="六安市">
六安市
</a>
</li>
<li>
<a href="/wiki/%E4%BA%B3%E5%B7%9E%E5%B8%82" title="亳州市">
亳州市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%A0%E5%B7%9E%E5%B8%82" title="池州市">
池州市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%A3%E5%9F%8E%E5%B8%82" title="宣城市">
宣城市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
福建
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">
福州市
</a>
</li>
<li>
★✦
<a href="/wiki/%E5%8E%A6%E9%97%A8%E5%B8%82" title="厦门市">
厦门市
</a>
</li>
<li>
<a href="/wiki/%E8%8E%86%E7%94%B0%E5%B8%82" title="莆田市">
莆田市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E6%98%8E%E5%B8%82" title="三明市">
三明市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%89%E5%B7%9E%E5%B8%82" title="泉州市">
泉州市
</a>
</li>
<li>
<a href="/wiki/%E6%BC%B3%E5%B7%9E%E5%B8%82" title="漳州市">
漳州市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E5%B9%B3%E5%B8%82" title="南平市">
南平市
</a>
</li>
<li>
<a href="/wiki/%E9%BE%99%E5%B2%A9%E5%B8%82" title="龙岩市">
龙岩市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%81%E5%BE%B7%E5%B8%82" title="宁德市">
宁德市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">
江西
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">
南昌市
</a>
</li>
<li>
<a href="/wiki/%E6%99%AF%E5%BE%B7%E9%95%87%E5%B8%82" title="景德镇市">
景德镇市
</a>
</li>
<li>
<a href="/wiki/%E8%90%8D%E4%B9%A1%E5%B8%82" title="萍乡市">
萍乡市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%9D%E6%B1%9F%E5%B8%82" title="九江市">
九江市
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E4%BD%99%E5%B8%82" title="新余市">
新余市
</a>
</li>
<li>
<a href="/wiki/%E9%B9%B0%E6%BD%AD%E5%B8%82" title="鹰潭市">
鹰潭市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%A3%E5%B7%9E%E5%B8%82" title="赣州市">
赣州市
</a>
</li>
<li>
<a href="/wiki/%E5%90%89%E5%AE%89%E5%B8%82" title="吉安市">
吉安市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E6%98%A5%E5%B8%82" title="宜春市">
宜春市
</a>
</li>
<li>
<a href="/wiki/%E6%8A%9A%E5%B7%9E%E5%B8%82" title="抚州市">
抚州市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E9%A5%B6%E5%B8%82" title="上饶市">
上饶市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">
山东
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">
济南市
</a>
</li>
<li>
★✦✧
<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">
青岛市
</a>
</li>
<li>
✧
<a href="/wiki/%E6%B7%84%E5%8D%9A%E5%B8%82" title="淄博市">
淄博市
</a>
</li>
<li>
<a href="/wiki/%E6%9E%A3%E5%BA%84%E5%B8%82" title="枣庄市">
枣庄市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%9C%E8%90%A5%E5%B8%82" title="东营市">
东营市
</a>
</li>
<li>
<a href="/wiki/%E7%83%9F%E5%8F%B0%E5%B8%82" title="烟台市">
烟台市
</a>
</li>
<li>
<a href="/wiki/%E6%BD%8D%E5%9D%8A%E5%B8%82" title="潍坊市">
潍坊市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%8E%E5%AE%81%E5%B8%82" title="济宁市">
济宁市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%B0%E5%AE%89%E5%B8%82" title="泰安市">
泰安市
</a>
</li>
<li>
<a href="/wiki/%E5%A8%81%E6%B5%B7%E5%B8%82" title="威海市">
威海市
</a>
</li>
<li>
<a href="/wiki/%E6%97%A5%E7%85%A7%E5%B8%82" title="日照市">
日照市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B4%E6%B2%82%E5%B8%82" title="临沂市">
临沂市
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E5%B7%9E%E5%B8%82" title="德州市">
德州市
</a>
</li>
<li>
<a href="/wiki/%E8%81%8A%E5%9F%8E%E5%B8%82" title="聊城市">
聊城市
</a>
</li>
<li>
<a href="/wiki/%E6%BB%A8%E5%B7%9E%E5%B8%82" title="滨州市">
滨州市
</a>
</li>
<li>
<a href="/wiki/%E8%8F%8F%E6%B3%BD%E5%B8%82" title="菏泽市">
菏泽市
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a class="mw-redirect" href="/wiki/%E4%B8%AD%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中南地区">
中南地区
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">
河南
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
开封市
</a>
</li>
<li>
✧
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%B3%E9%A1%B6%E5%B1%B1%E5%B8%82" title="平顶山市">
平顶山市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">
安阳市
</a>
</li>
<li>
<a href="/wiki/%E9%B9%A4%E5%A3%81%E5%B8%82" title="鹤壁市">
鹤壁市
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E4%B9%A1%E5%B8%82" title="新乡市">
新乡市
</a>
</li>
<li>
<a href="/wiki/%E7%84%A6%E4%BD%9C%E5%B8%82" title="焦作市">
焦作市
</a>
</li>
<li>
<a href="/wiki/%E6%BF%AE%E9%98%B3%E5%B8%82" title="濮阳市">
濮阳市
</a>
</li>
<li>
<a href="/wiki/%E8%AE%B8%E6%98%8C%E5%B8%82" title="许昌市">
许昌市
</a>
</li>
<li>
<a href="/wiki/%E6%BC%AF%E6%B2%B3%E5%B8%82" title="漯河市">
漯河市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E9%97%A8%E5%B3%A1%E5%B8%82" title="三门峡市">
三门峡市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E9%98%B3%E5%B8%82" title="南阳市">
南阳市
</a>
</li>
<li>
<a href="/wiki/%E5%95%86%E4%B8%98%E5%B8%82" title="商丘市">
商丘市
</a>
</li>
<li>
<a href="/wiki/%E4%BF%A1%E9%98%B3%E5%B8%82" title="信阳市">
信阳市
</a>
</li>
<li>
<a href="/wiki/%E5%91%A8%E5%8F%A3%E5%B8%82" title="周口市">
周口市
</a>
</li>
<li>
<a href="/wiki/%E9%A9%BB%E9%A9%AC%E5%BA%97%E5%B8%82" title="驻马店市">
驻马店市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">
湖北
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E7%9F%B3%E5%B8%82" title="黄石市">
黄石市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%81%E5%A0%B0%E5%B8%82" title="十堰市">
十堰市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E6%98%8C%E5%B8%82" title="宜昌市">
宜昌市
</a>
</li>
<li>
<a href="/wiki/%E8%A5%84%E9%98%B3%E5%B8%82" title="襄阳市">
襄阳市
</a>
</li>
<li>
<a href="/wiki/%E9%84%82%E5%B7%9E%E5%B8%82" title="鄂州市">
鄂州市
</a>
</li>
<li>
<a href="/wiki/%E8%8D%86%E9%97%A8%E5%B8%82" title="荆门市">
荆门市
</a>
</li>
<li>
<a href="/wiki/%E5%AD%9D%E6%84%9F%E5%B8%82" title="孝感市">
孝感市
</a>
</li>
<li>
<a href="/wiki/%E8%8D%86%E5%B7%9E%E5%B8%82" title="荆州市">
荆州市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E5%86%88%E5%B8%82" title="黄冈市">
黄冈市
</a>
</li>
<li>
<a href="/wiki/%E5%92%B8%E5%AE%81%E5%B8%82" title="咸宁市">
咸宁市
</a>
</li>
<li>
<a href="/wiki/%E9%9A%8F%E5%B7%9E%E5%B8%82" title="随州市">
随州市
</a>
</li>
<li>
<a href="/wiki/%E6%81%A9%E6%96%BD%E5%9C%9F%E5%AE%B6%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="恩施土家族苗族自治州">
恩施土家族苗族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">
湖南
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">
长沙市
</a>
</li>
<li>
<a href="/wiki/%E6%A0%AA%E6%B4%B2%E5%B8%82" title="株洲市">
株洲市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%98%E6%BD%AD%E5%B8%82" title="湘潭市">
湘潭市
</a>
</li>
<li>
<a href="/wiki/%E8%A1%A1%E9%98%B3%E5%B8%82" title="衡阳市">
衡阳市
</a>
</li>
<li>
<a href="/wiki/%E9%82%B5%E9%98%B3%E5%B8%82" title="邵阳市">
邵阳市
</a>
</li>
<li>
<a href="/wiki/%E5%B2%B3%E9%98%B3%E5%B8%82" title="岳阳市">
岳阳市
</a>
</li>
<li>
<a href="/wiki/%E5%B8%B8%E5%BE%B7%E5%B8%82" title="常德市">
常德市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E7%95%8C%E5%B8%82" title="张家界市">
张家界市
</a>
</li>
<li>
<a href="/wiki/%E7%9B%8A%E9%98%B3%E5%B8%82" title="益阳市">
益阳市
</a>
</li>
<li>
<a href="/wiki/%E9%83%B4%E5%B7%9E%E5%B8%82" title="郴州市">
郴州市
</a>
</li>
<li>
<a href="/wiki/%E6%B0%B8%E5%B7%9E%E5%B8%82" title="永州市">
永州市
</a>
</li>
<li>
<a href="/wiki/%E6%80%80%E5%8C%96%E5%B8%82" title="怀化市">
怀化市
</a>
</li>
<li>
<a href="/wiki/%E5%A8%84%E5%BA%95%E5%B8%82" title="娄底市">
娄底市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%98%E8%A5%BF%E5%9C%9F%E5%AE%B6%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="湘西土家族苗族自治州">
湘西土家族苗族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">
广东
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州市
</a>
</li>
<li>
<a href="/wiki/%E9%9F%B6%E5%85%B3%E5%B8%82" title="韶关市">
韶关市
</a>
</li>
<li>
★✦
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳市
</a>
</li>
<li>
<a href="/wiki/%E7%8F%A0%E6%B5%B7%E5%B8%82" title="珠海市">
珠海市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%95%E5%A4%B4%E5%B8%82" title="汕头市">
汕头市
</a>
</li>
<li>
<a href="/wiki/%E4%BD%9B%E5%B1%B1%E5%B8%82" title="佛山市">
佛山市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E9%97%A8%E5%B8%82" title="江门市">
江门市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%9B%E6%B1%9F%E5%B8%82" title="湛江市">
湛江市
</a>
</li>
<li>
<a href="/wiki/%E8%8C%82%E5%90%8D%E5%B8%82" title="茂名市">
茂名市
</a>
</li>
<li>
<a href="/wiki/%E8%82%87%E5%BA%86%E5%B8%82" title="肇庆市">
肇庆市
</a>
</li>
<li>
<a href="/wiki/%E6%83%A0%E5%B7%9E%E5%B8%82" title="惠州市">
惠州市
</a>
</li>
<li>
<a href="/wiki/%E6%A2%85%E5%B7%9E%E5%B8%82" title="梅州市">
梅州市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%95%E5%B0%BE%E5%B8%82" title="汕尾市">
汕尾市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%B3%E6%BA%90%E5%B8%82" title="河源市">
河源市
</a>
</li>
<li>
<a href="/wiki/%E9%98%B3%E6%B1%9F%E5%B8%82" title="阳江市">
阳江市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%85%E8%BF%9C%E5%B8%82" title="清远市">
清远市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%9C%E8%8E%9E%E5%B8%82" title="东莞市">
东莞市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%AD%E5%B1%B1%E5%B8%82" title="中山市">
中山市
</a>
</li>
<li>
<a href="/wiki/%E6%BD%AE%E5%B7%9E%E5%B8%82" title="潮州市">
潮州市
</a>
</li>
<li>
<a href="/wiki/%E6%8F%AD%E9%98%B3%E5%B8%82" title="揭阳市">
揭阳市
</a>
</li>
<li>
<a href="/wiki/%E4%BA%91%E6%B5%AE%E5%B8%82" title="云浮市">
云浮市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">
广西
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%97%E5%AE%81%E5%B8%82" title="南宁市">
南宁市
</a>
</li>
<li>
<a href="/wiki/%E6%9F%B3%E5%B7%9E%E5%B8%82" title="柳州市">
柳州市
</a>
</li>
<li>
<a href="/wiki/%E6%A1%82%E6%9E%97%E5%B8%82" title="桂林市">
桂林市
</a>
</li>
<li>
<a href="/wiki/%E6%A2%A7%E5%B7%9E%E5%B8%82" title="梧州市">
梧州市
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E6%B5%B7%E5%B8%82" title="北海市">
北海市
</a>
</li>
<li>
<a href="/wiki/%E9%98%B2%E5%9F%8E%E6%B8%AF%E5%B8%82" title="防城港市">
防城港市
</a>
</li>
<li>
<a href="/wiki/%E9%92%A6%E5%B7%9E%E5%B8%82" title="钦州市">
钦州市
</a>
</li>
<li>
<a href="/wiki/%E8%B4%B5%E6%B8%AF%E5%B8%82" title="贵港市">
贵港市
</a>
</li>
<li>
<a href="/wiki/%E7%8E%89%E6%9E%97%E5%B8%82" title="玉林市">
玉林市
</a>
</li>
<li>
<a href="/wiki/%E7%99%BE%E8%89%B2%E5%B8%82" title="百色市">
百色市
</a>
</li>
<li>
<a href="/wiki/%E8%B4%BA%E5%B7%9E%E5%B8%82" title="贺州市">
贺州市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%B3%E6%B1%A0%E5%B8%82" title="河池市">
河池市
</a>
</li>
<li>
<a href="/wiki/%E6%9D%A5%E5%AE%BE%E5%B8%82" title="来宾市">
来宾市
</a>
</li>
<li>
<a href="/wiki/%E5%B4%87%E5%B7%A6%E5%B8%82" title="崇左市">
崇左市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
海南
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">
海口市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E4%BA%9A%E5%B8%82" title="三亚市">
三亚市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E6%B2%99%E5%B8%82" title="三沙市">
三沙市
</a>
</li>
<li>
<a href="/wiki/%E5%84%8B%E5%B7%9E%E5%B8%82" title="儋州市">
儋州市
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8D%97%E5%9C%B0%E5%8C%BA" title="中国西南地区">
西南地区
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">
四川
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都市
</a>
</li>
<li>
<a href="/wiki/%E8%87%AA%E8%B4%A1%E5%B8%82" title="自贡市">
自贡市
</a>
</li>
<li>
<a href="/wiki/%E6%94%80%E6%9E%9D%E8%8A%B1%E5%B8%82" title="攀枝花市">
攀枝花市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%B8%E5%B7%9E%E5%B8%82" title="泸州市">
泸州市
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E9%98%B3%E5%B8%82" title="德阳市">
德阳市
</a>
</li>
<li>
<a href="/wiki/%E7%BB%B5%E9%98%B3%E5%B8%82" title="绵阳市">
绵阳市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%85%83%E5%B8%82" title="广元市">
广元市
</a>
</li>
<li>
<a href="/wiki/%E9%81%82%E5%AE%81%E5%B8%82" title="遂宁市">
遂宁市
</a>
</li>
<li>
<a href="/wiki/%E5%86%85%E6%B1%9F%E5%B8%82" title="内江市">
内江市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%90%E5%B1%B1%E5%B8%82" title="乐山市">
乐山市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E5%85%85%E5%B8%82" title="南充市">
南充市
</a>
</li>
<li>
<a href="/wiki/%E7%9C%89%E5%B1%B1%E5%B8%82" title="眉山市">
眉山市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E5%AE%BE%E5%B8%82" title="宜宾市">
宜宾市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%AE%89%E5%B8%82" title="广安市">
广安市
</a>
</li>
<li>
<a href="/wiki/%E8%BE%BE%E5%B7%9E%E5%B8%82" title="达州市">
达州市
</a>
</li>
<li>
<a href="/wiki/%E9%9B%85%E5%AE%89%E5%B8%82" title="雅安市">
雅安市
</a>
</li>
<li>
<a href="/wiki/%E5%B7%B4%E4%B8%AD%E5%B8%82" title="巴中市">
巴中市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%84%E9%98%B3%E5%B8%82" title="资阳市">
资阳市
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E5%9D%9D%E8%97%8F%E6%97%8F%E7%BE%8C%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="阿坝藏族羌族自治州">
阿坝藏族羌族自治州
</a>
</li>
<li>
<a href="/wiki/%E7%94%98%E5%AD%9C%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="甘孜藏族自治州">
甘孜藏族自治州
</a>
</li>
<li>
<a href="/wiki/%E5%87%89%E5%B1%B1%E5%BD%9D%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="凉山彝族自治州">
凉山彝族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">
贵州
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E8%B4%B5%E9%98%B3%E5%B8%82" title="贵阳市">
贵阳市
</a>
</li>
<li>
<a href="/wiki/%E5%85%AD%E7%9B%98%E6%B0%B4%E5%B8%82" title="六盘水市">
六盘水市
</a>
</li>
<li>
<a href="/wiki/%E9%81%B5%E4%B9%89%E5%B8%82" title="遵义市">
遵义市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E9%A1%BA%E5%B8%82" title="安顺市">
安顺市
</a>
</li>
<li>
<a href="/wiki/%E6%AF%95%E8%8A%82%E5%B8%82" title="毕节市">
毕节市
</a>
</li>
<li>
<a href="/wiki/%E9%93%9C%E4%BB%81%E5%B8%82" title="铜仁市">
铜仁市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%94%E8%A5%BF%E5%8D%97%E5%B8%83%E4%BE%9D%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黔西南布依族苗族自治州">
黔西南布依族苗族自治州
</a>
</li>
<li>
<a href="/wiki/%E9%BB%94%E4%B8%9C%E5%8D%97%E8%8B%97%E6%97%8F%E4%BE%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黔东南苗族侗族自治州">
黔东南苗族侗族自治州
</a>
</li>
<li>
<a href="/wiki/%E9%BB%94%E5%8D%97%E5%B8%83%E4%BE%9D%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黔南布依族苗族自治州">
黔南布依族苗族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">
云南
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">
昆明市
</a>
</li>
<li>
<a href="/wiki/%E6%9B%B2%E9%9D%96%E5%B8%82" title="曲靖市">
曲靖市
</a>
</li>
<li>
<a href="/wiki/%E7%8E%89%E6%BA%AA%E5%B8%82" title="玉溪市">
玉溪市
</a>
</li>
<li>
<a href="/wiki/%E4%BF%9D%E5%B1%B1%E5%B8%82" title="保山市">
保山市
</a>
</li>
<li>
<a href="/wiki/%E6%98%AD%E9%80%9A%E5%B8%82" title="昭通市">
昭通市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%BD%E6%B1%9F%E5%B8%82" title="丽江市">
丽江市
</a>
</li>
<li>
<a href="/wiki/%E6%99%AE%E6%B4%B1%E5%B8%82" title="普洱市">
普洱市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B4%E6%B2%A7%E5%B8%82" title="临沧市">
临沧市
</a>
</li>
<li>
<a href="/wiki/%E6%A5%9A%E9%9B%84%E5%BD%9D%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="楚雄彝族自治州">
楚雄彝族自治州
</a>
</li>
<li>
<a href="/wiki/%E7%BA%A2%E6%B2%B3%E5%93%88%E5%B0%BC%E6%97%8F%E5%BD%9D%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="红河哈尼族彝族自治州">
红河哈尼族彝族自治州
</a>
</li>
<li>
<a href="/wiki/%E6%96%87%E5%B1%B1%E5%A3%AE%E6%97%8F%E8%8B%97%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="文山壮族苗族自治州">
文山壮族苗族自治州
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E5%8F%8C%E7%89%88%E7%BA%B3%E5%82%A3%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="西双版纳傣族自治州">
西双版纳傣族自治州
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E7%90%86%E7%99%BD%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="大理白族自治州">
大理白族自治州
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E5%AE%8F%E5%82%A3%E6%97%8F%E6%99%AF%E9%A2%87%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="德宏傣族景颇族自治州">
德宏傣族景颇族自治州
</a>
</li>
<li>
<a href="/wiki/%E6%80%92%E6%B1%9F%E5%82%88%E5%83%B3%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="怒江傈僳族自治州">
怒江傈僳族自治州
</a>
</li>
<li>
<a href="/wiki/%E8%BF%AA%E5%BA%86%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="迪庆藏族自治州">
迪庆藏族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">
西藏
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%8B%89%E8%90%A8%E5%B8%82" title="拉萨市">
拉萨市
</a>
</li>
<li>
<a href="/wiki/%E6%97%A5%E5%96%80%E5%88%99%E5%B8%82" title="日喀则市">
日喀则市
</a>
</li>
<li>
<a href="/wiki/%E6%98%8C%E9%83%BD%E5%B8%82" title="昌都市">
昌都市
</a>
</li>
<li>
<a href="/wiki/%E6%9E%97%E8%8A%9D%E5%B8%82" title="林芝市">
林芝市
</a>
</li>
<li>
<a href="/wiki/%E5%B1%B1%E5%8D%97%E5%B8%82" title="山南市">
山南市
</a>
</li>
<li>
<a href="/wiki/%E9%82%A3%E6%9B%B2%E5%B8%82" title="那曲市">
那曲市
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E9%87%8C%E5%9C%B0%E5%8C%BA" title="阿里地区">
阿里地区
</a>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E4%B8%AD%E5%9B%BD%E8%A5%BF%E5%8C%97%E5%9C%B0%E5%8C%BA" title="中国西北地区">
西北地区
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
</div>
<table cellspacing="0" class="nowraplinks navbox-subgroup" style="border-spacing:0">
<tbody>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">
陕西
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
★
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安市
</a>
</li>
<li>
<a href="/wiki/%E9%93%9C%E5%B7%9D%E5%B8%82" title="铜川市">
铜川市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9D%E9%B8%A1%E5%B8%82" title="宝鸡市">
宝鸡市
</a>
</li>
<li>
<a href="/wiki/%E5%92%B8%E9%98%B3%E5%B8%82" title="咸阳市">
咸阳市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%AD%E5%8D%97%E5%B8%82" title="渭南市">
渭南市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">
延安市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%89%E4%B8%AD%E5%B8%82" title="汉中市">
汉中市
</a>
</li>
<li>
<a href="/wiki/%E6%A6%86%E6%9E%97%E5%B8%82" title="榆林市">
榆林市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E5%BA%B7%E5%B8%82" title="安康市">
安康市
</a>
</li>
<li>
<a href="/wiki/%E5%95%86%E6%B4%9B%E5%B8%82" title="商洛市">
商洛市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">
甘肃
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%85%B0%E5%B7%9E%E5%B8%82" title="兰州市">
兰州市
</a>
</li>
<li>
<a href="/wiki/%E5%98%89%E5%B3%AA%E5%85%B3%E5%B8%82" title="嘉峪关市">
嘉峪关市
</a>
</li>
<li>
<a href="/wiki/%E9%87%91%E6%98%8C%E5%B8%82" title="金昌市">
金昌市
</a>
</li>
<li>
<a href="/wiki/%E7%99%BD%E9%93%B6%E5%B8%82" title="白银市">
白银市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E6%B0%B4%E5%B8%82" title="天水市">
天水市
</a>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E5%A8%81%E5%B8%82" title="武威市">
武威市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%A0%E6%8E%96%E5%B8%82" title="张掖市">
张掖市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%B3%E5%87%89%E5%B8%82" title="平凉市">
平凉市
</a>
</li>
<li>
<a href="/wiki/%E9%85%92%E6%B3%89%E5%B8%82" title="酒泉市">
酒泉市
</a>
</li>
<li>
<a href="/wiki/%E5%BA%86%E9%98%B3%E5%B8%82" title="庆阳市">
庆阳市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9A%E8%A5%BF%E5%B8%82" title="定西市">
定西市
</a>
</li>
<li>
<a href="/wiki/%E9%99%87%E5%8D%97%E5%B8%82" title="陇南市">
陇南市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B4%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="临夏回族自治州">
临夏回族自治州
</a>
</li>
<li>
<a href="/wiki/%E7%94%98%E5%8D%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="甘南藏族自治州">
甘南藏族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">
青海
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%81%E5%B8%82" title="西宁市">
西宁市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E4%B8%9C%E5%B8%82" title="海东市">
海东市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E5%8C%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="海北藏族自治州">
海北藏族自治州
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E5%8D%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="黄南藏族自治州">
黄南藏族自治州
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E5%8D%97%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="海南藏族自治州">
海南藏族自治州
</a>
</li>
<li>
<a href="/wiki/%E6%9E%9C%E6%B4%9B%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="果洛藏族自治州">
果洛藏族自治州
</a>
</li>
<li>
<a href="/wiki/%E7%8E%89%E6%A0%91%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="玉树藏族自治州">
玉树藏族自治州
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E8%A5%BF%E8%92%99%E5%8F%A4%E6%97%8F%E8%97%8F%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="海西蒙古族藏族自治州">
海西蒙古族藏族自治州
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">
宁夏
</a>
</th>
<td class="navbox-list navbox-even" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">
银川市
</a>
</li>
<li>
<a href="/wiki/%E7%9F%B3%E5%98%B4%E5%B1%B1%E5%B8%82" title="石嘴山市">
石嘴山市
</a>
</li>
<li>
<a href="/wiki/%E5%90%B4%E5%BF%A0%E5%B8%82" title="吴忠市">
吴忠市
</a>
</li>
<li>
<a href="/wiki/%E5%9B%BA%E5%8E%9F%E5%B8%82" title="固原市">
固原市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%AD%E5%8D%AB%E5%B8%82" title="中卫市">
中卫市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row">
<a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">
新疆
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%B8%82" title="乌鲁木齐市">
乌鲁木齐市
</a>
</li>
<li>
<a href="/wiki/%E5%85%8B%E6%8B%89%E7%8E%9B%E4%BE%9D%E5%B8%82" title="克拉玛依市">
克拉玛依市
</a>
</li>
<li>
<a href="/wiki/%E5%90%90%E9%B2%81%E7%95%AA%E5%B8%82" title="吐鲁番市">
吐鲁番市
</a>
</li>
<li>
<a href="/wiki/%E5%93%88%E5%AF%86%E5%B8%82" title="哈密市">
哈密市
</a>
</li>
<li>
<a href="/wiki/%E6%98%8C%E5%90%89%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%B7%9E" title="昌吉回族自治州">
昌吉回族自治州
</a>
</li>
<li>
<a href="/wiki/%E5%8D%9A%E5%B0%94%E5%A1%94%E6%8B%89%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%B7%9E" title="博尔塔拉蒙古自治州">
博尔塔拉蒙古自治州
</a>
</li>
<li>
<a href="/wiki/%E5%B7%B4%E9%9F%B3%E9%83%AD%E6%A5%9E%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%B7%9E" title="巴音郭楞蒙古自治州">
巴音郭楞蒙古自治州
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E5%85%8B%E8%8B%8F%E5%9C%B0%E5%8C%BA" title="阿克苏地区">
阿克苏地区
</a>
</li>
<li>
<a href="/wiki/%E5%85%8B%E5%AD%9C%E5%8B%92%E8%8B%8F%E6%9F%AF%E5%B0%94%E5%85%8B%E5%AD%9C%E8%87%AA%E6%B2%BB%E5%B7%9E" title="克孜勒苏柯尔克孜自治州">
克孜勒苏柯尔克孜自治州
</a>
</li>
<li>
<a href="/wiki/%E5%96%80%E4%BB%80%E5%9C%B0%E5%8C%BA" title="喀什地区">
喀什地区
</a>
</li>
<li>
<a href="/wiki/%E5%92%8C%E7%94%B0%E5%9C%B0%E5%8C%BA" title="和田地区">
和田地区
</a>
</li>
<li>
☆
<a href="/wiki/%E4%BC%8A%E7%8A%81%E5%93%88%E8%90%A8%E5%85%8B%E8%87%AA%E6%B2%BB%E5%B7%9E" title="伊犁哈萨克自治州">
伊犁哈萨克自治州
</a>
<ul>
<li>
<a href="/wiki/%E5%A1%94%E5%9F%8E%E5%9C%B0%E5%8C%BA" title="塔城地区">
塔城地区
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E5%8B%92%E6%B3%B0%E5%9C%B0%E5%8C%BA" title="阿勒泰地区">
阿勒泰地区
</a>
</li>
</ul>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
<div>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="3" style="text-align: left; font-size: 90%;">
<div>
<ul>
<li>
参见:
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">
县级以上行政区列表
</a>
</li>
<li>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%BB%BA%E5%88%B6" title="中华人民共和国城市建制">
城市建制
</a>
、
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9F%8E%E5%B8%82%E5%88%97%E8%A1%A8" title="中华人民共和国城市列表">
城市列表
</a>
</li>
</ul>
<hr/>
<div class="center">
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="中华人民共和国行政区划">
区划
</a>
索引:
<a href="/wiki/Template:Division_levels_of_China" title="Template:Division levels of China">
单位
</a>
<small>
(
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92%E4%BB%A3%E7%A0%81" title="中华人民共和国行政区划代码">
代码
</a>
)
</small>
:
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国省级行政区">
省级
</a>
<small>
(
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E7%9C%81%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%8F%98%E5%8A%A8" title="Template:中华人民共和国省级以上行政区变动">
史
</a>
)
</small>
>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%89%AF%E7%9C%81%E7%BA%A7%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国副省级行政区">
<i>
副省级
</i>
</a>
>
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9C%B0%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA" title="Template:中华人民共和国地级以上行政区">
地级
</a>
>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%8E%BF%E7%BA%A7%E4%BB%A5%E4%B8%8A%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%97%E8%A1%A8" title="中华人民共和国县级以上行政区列表">
县级
</a>
:
<a href="/wiki/Template:%E5%8C%97%E4%BA%AC%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:北京行政区划">
京
</a>
|
<a href="/wiki/Template:%E5%A4%A9%E6%B4%A5%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:天津行政区划">
津
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河北行政区划">
冀
</a>
|
<a href="/wiki/Template:%E5%B1%B1%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山西行政区划">
晋
</a>
|
<a href="/wiki/Template:%E5%86%85%E8%92%99%E5%8F%A4%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:内蒙古行政区划">
蒙
</a>
|
<a href="/wiki/Template:%E8%BE%BD%E5%AE%81%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:辽宁行政区划">
辽
</a>
|
<a href="/wiki/Template:%E5%90%89%E6%9E%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:吉林行政区划">
吉
</a>
|
<a href="/wiki/Template:%E9%BB%91%E9%BE%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:黑龙江行政区划">
黑
</a>
|
<a href="/wiki/Template:%E4%B8%8A%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:上海行政区划">
沪
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%8B%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江苏行政区划">
苏
</a>
|
<a href="/wiki/Template:%E6%B5%99%E6%B1%9F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:浙江行政区划">
浙
</a>
|
<a href="/wiki/Template:%E5%AE%89%E5%BE%BD%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:安徽行政区划">
皖
</a>
|
<a href="/wiki/Template:%E7%A6%8F%E5%BB%BA%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:福建行政区划">
闽
</a>
|
<a href="/wiki/Template:%E6%B1%9F%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:江西行政区划">
赣
</a>
|
<a href="/wiki/Template:%E5%B1%B1%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:山东行政区划">
鲁
</a>
|
<a href="/wiki/Template:%E6%B2%B3%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:河南行政区划">
豫
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8C%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖北行政区划">
鄂
</a>
|
<a href="/wiki/Template:%E6%B9%96%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:湖南行政区划">
湘
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E4%B8%9C%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广东行政区划">
粤
</a>
|
<a href="/wiki/Template:%E5%B9%BF%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:广西行政区划">
桂
</a>
|
<a href="/wiki/Template:%E6%B5%B7%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:海南行政区划">
琼
</a>
|
<a href="/wiki/Template:%E9%87%8D%E5%BA%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:重庆行政区划">
渝
</a>
|
<a href="/wiki/Template:%E5%9B%9B%E5%B7%9D%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:四川行政区划">
川
</a>
|
<a href="/wiki/Template:%E8%B4%B5%E5%B7%9E%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:贵州行政区划">
贵
</a>
|
<a href="/wiki/Template:%E4%BA%91%E5%8D%97%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:云南行政区划">
云
</a>
|
<a href="/wiki/Template:%E8%A5%BF%E8%97%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:西藏行政区划">
藏
</a>
|
<a href="/wiki/Template:%E9%99%95%E8%A5%BF%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:陕西行政区划">
陕
</a>
|
<a href="/wiki/Template:%E7%94%98%E8%82%83%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:甘肃行政区划">
甘
</a>
|
<a href="/wiki/Template:%E9%9D%92%E6%B5%B7%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:青海行政区划">
青
</a>
|
<a href="/wiki/Template:%E5%AE%81%E5%A4%8F%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:宁夏行政区划">
宁
</a>
|
<a href="/wiki/Template:%E6%96%B0%E7%96%86%E8%A1%8C%E6%94%BF%E5%8C%BA%E5%88%92" title="Template:新疆行政区划">
新
</a>
|
<a href="/wiki/Template:%E9%A6%99%E6%B8%AF%E5%8D%81%E5%85%AB%E5%8D%80" title="Template:香港十八區">
港
</a>
|
<a href="/wiki/Template:%E6%BE%B3%E9%96%80%E8%A1%8C%E6%94%BF%E5%8D%80%E5%8A%83" title="Template:澳門行政區劃">
澳
</a>
|
<a href="/wiki/%E5%8F%B0%E6%B9%BE%E7%9C%81_(%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD)" title="台湾省 (中华人民共和国)">
台
</a>
</div>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-title" colspan="2" scope="col" style="background:#3CB371; color:#ffffff;">
<div class="plainlinks hlist navbar mini">
<ul>
<li class="nv-view">
<a href="/wiki/Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82" title="Template:中华人民共和国国家园林城市">
<abbr style=";background:#3CB371; color:#ffffff;;background:none transparent;border:none;" title="查看该模板">
查
</abbr>
</a>
</li>
<li class="nv-talk">
<a class="new" href="/w/index.php?title=Template_talk:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82&action=edit&redlink=1" title="Template talk:中华人民共和国国家园林城市(页面不存在)">
<abbr style=";background:#3CB371; color:#ffffff;;background:none transparent;border:none;" title="讨论该模板">
论
</abbr>
</a>
</li>
<li class="nv-edit">
<a class="external text" href="https://zh.wikipedia.org/w/index.php?title=Template:%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82&action=edit">
<abbr style=";background:#3CB371; color:#ffffff;;background:none transparent;border:none;" title="编辑该模板">
编
</abbr>
</a>
</li>
</ul>
</div>
<div style="font-size:110%">
<a class="image" href="/wiki/File:Flag_of_the_People%27s_Republic_of_China.svg" title="中华人民共和国国旗">
<img alt="中华人民共和国国旗" data-file-height="600" data-file-width="900" decoding="async" height="17" src="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/25px-Flag_of_the_People%27s_Republic_of_China.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/38px-Flag_of_the_People%27s_Republic_of_China.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/fa/Flag_of_the_People%27s_Republic_of_China.svg/50px-Flag_of_the_People%27s_Republic_of_China.svg.png 2x" width="25"/>
</a>
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD" title="中华人民共和国">
<span style="color:white;">
中华人民共和国
</span>
</a>
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82" title="国家园林城市">
<span style="color:white;">
国家园林城市
</span>
</a>
<span style="color:white;">
</span>
</div>
</th>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2" style="background:#3CB371; color:#ffffff;">
<div>
国家园林城市是
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BD%8F%E6%88%BF%E5%92%8C%E5%9F%8E%E4%B9%A1%E5%BB%BA%E8%AE%BE%E9%83%A8" title="中华人民共和国住房和城乡建设部">
<span style="color:white;">
中华人民共和国住房和城乡建设部
</span>
</a>
设立的城市荣誉称号。
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a class="mw-selflink selflink">
<span style="color:white;">
北京市
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a class="mw-selflink selflink">
北京市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B2%B3%E5%8C%97%E7%9C%81" title="河北省">
<span style="color:white;">
河北省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%94%90%E5%B1%B1%E5%B8%82" title="唐山市">
唐山市
</a>
</li>
<li>
<a href="/wiki/%E7%A7%A6%E7%9A%87%E5%B2%9B%E5%B8%82" title="秦皇岛市">
秦皇岛市
</a>
</li>
<li>
<a href="/wiki/%E9%82%AF%E9%83%B8%E5%B8%82" title="邯郸市">
邯郸市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%8A%E5%9D%8A%E5%B8%82" title="廊坊市">
廊坊市
</a>
</li>
<li>
<a href="/wiki/%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%B8%82" title="石家庄市">
石家庄市
</a>
</li>
<li>
<a href="/wiki/%E8%BF%81%E5%AE%89%E5%B8%82" title="迁安市">
迁安市
</a>
</li>
<li>
<a href="/wiki/%E6%89%BF%E5%BE%B7%E5%B8%82" title="承德市">
承德市
</a>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E5%AE%89%E5%B8%82" title="武安市">
武安市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E5%8F%A3%E5%B8%82" title="张家口市">
张家口市
</a>
</li>
<li>
<a href="/wiki/%E4%BF%9D%E5%AE%9A%E5%B8%82" title="保定市">
保定市
</a>
</li>
<li>
<a href="/wiki/%E9%82%A2%E5%8F%B0%E5%B8%82" title="邢台市">
邢台市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%A7%E5%B7%9E%E5%B8%82" title="沧州市">
沧州市
</a>
</li>
<li>
<a href="/wiki/%E8%BE%9B%E9%9B%86%E5%B8%82" title="辛集市">
辛集市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E9%AA%85%E5%B8%82" title="黄骅市">
黄骅市
</a>
</li>
<li>
<a href="/wiki/%E6%99%8B%E5%B7%9E%E5%B8%82_(%E4%B8%AD%E5%9B%BD)" title="晋州市 (中国)">
晋州市
</a>
</li>
<li>
<a href="/wiki/%E4%BB%BB%E4%B8%98%E5%B8%82" title="任丘市">
任丘市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%B1%B1%E8%A5%BF%E7%9C%81" title="山西省">
<span style="color:white;">
山西省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%95%BF%E6%B2%BB%E5%B8%82" title="长治市">
长治市
</a>
</li>
<li>
<a href="/wiki/%E6%99%8B%E5%9F%8E%E5%B8%82" title="晋城市">
晋城市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%AA%E5%8E%9F%E5%B8%82" title="太原市">
太原市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E6%BD%9E%E5%9F%8E%E5%B8%82" title="潞城市">
潞城市
</a>
</li>
<li>
<a href="/wiki/%E4%BE%AF%E9%A9%AC%E5%B8%82" title="侯马市">
侯马市
</a>
</li>
<li>
<a href="/wiki/%E9%98%B3%E6%B3%89%E5%B8%82" title="阳泉市">
阳泉市
</a>
</li>
<li>
<a href="/wiki/%E5%AD%9D%E4%B9%89%E5%B8%82" title="孝义市">
孝义市
</a>
</li>
<li>
<a href="/wiki/%E4%BB%8B%E4%BC%91%E5%B8%82" title="介休市">
介休市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%90%8C%E5%B8%82" title="大同市">
大同市
</a>
</li>
<li>
<a href="/wiki/%E6%9C%94%E5%B7%9E%E5%B8%82" title="朔州市">
朔州市
</a>
</li>
<li>
<a href="/wiki/%E6%B0%B8%E6%B5%8E%E5%B8%82" title="永济市">
永济市
</a>
</li>
<li>
<a href="/wiki/%E6%99%8B%E4%B8%AD%E5%B8%82" title="晋中市">
晋中市
</a>
</li>
<li>
<a href="/wiki/%E5%BF%BB%E5%B7%9E%E5%B8%82" title="忻州市">
忻州市
</a>
</li>
<li>
<a href="/wiki/%E8%BF%90%E5%9F%8E%E5%B8%82" title="运城市">
运城市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%86%85%E8%92%99%E5%8F%A4%E8%87%AA%E6%B2%BB%E5%8C%BA" title="内蒙古自治区">
<span style="color:white;">
内蒙古自治区
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8C%85%E5%A4%B4%E5%B8%82" title="包头市">
包头市
</a>
</li>
<li>
<a href="/wiki/%E9%80%9A%E8%BE%BD%E5%B8%82" title="通辽市">
通辽市
</a>
</li>
<li>
<a href="/wiki/%E9%84%82%E5%B0%94%E5%A4%9A%E6%96%AF%E5%B8%82" title="鄂尔多斯市">
鄂尔多斯市
</a>
</li>
<li>
<a href="/wiki/%E5%91%BC%E5%92%8C%E6%B5%A9%E7%89%B9%E5%B8%82" title="呼和浩特市">
呼和浩特市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%8C%E6%B5%B7%E5%B8%82" title="乌海市">
乌海市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%8C%E5%85%B0%E5%AF%9F%E5%B8%83%E5%B8%82" title="乌兰察布市">
乌兰察布市
</a>
</li>
<li>
<a href="/wiki/%E6%89%8E%E5%85%B0%E5%B1%AF%E5%B8%82" title="扎兰屯市">
扎兰屯市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%A4%E5%B3%B0%E5%B8%82" title="赤峰市">
赤峰市
</a>
</li>
<li>
<a href="/wiki/%E5%B7%B4%E5%BD%A6%E6%B7%96%E5%B0%94%E5%B8%82" title="巴彦淖尔市">
巴彦淖尔市
</a>
</li>
<li>
<a href="/wiki/%E9%94%A1%E6%9E%97%E6%B5%A9%E7%89%B9%E5%B8%82" title="锡林浩特市">
锡林浩特市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E8%BE%BD%E5%AE%81%E7%9C%81" title="辽宁省">
<span style="color:white;">
辽宁省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%A4%A7%E8%BF%9E%E5%B8%82" title="大连市">
大连市
</a>
</li>
<li>
<a href="/wiki/%E8%91%AB%E8%8A%A6%E5%B2%9B%E5%B8%82" title="葫芦岛市">
葫芦岛市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%88%E9%98%B3%E5%B8%82" title="沈阳市">
沈阳市
</a>
</li>
<li>
<a href="/wiki/%E8%B0%83%E5%85%B5%E5%B1%B1%E5%B8%82" title="调兵山市">
调兵山市
</a>
</li>
<li>
<a href="/wiki/%E9%93%81%E5%B2%AD%E5%B8%82" title="铁岭市">
铁岭市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%80%E5%8E%9F%E5%B8%82" title="开原市">
开原市
</a>
</li>
<li>
<a href="/wiki/%E6%9C%AC%E6%BA%AA%E5%B8%82" title="本溪市">
本溪市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B9%E4%B8%9C%E5%B8%82" title="丹东市">
丹东市
</a>
</li>
<li>
<a href="/wiki/%E9%9E%8D%E5%B1%B1%E5%B8%82" title="鞍山市">
鞍山市
</a>
</li>
<li>
<a href="/wiki/%E7%9B%98%E9%94%A6%E5%B8%82" title="盘锦市">
盘锦市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%90%89%E6%9E%97%E7%9C%81" title="吉林省">
<span style="color:white;">
吉林省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%95%BF%E6%98%A5%E5%B8%82" title="长春市">
长春市
</a>
</li>
<li>
<a href="/wiki/%E5%90%89%E6%9E%97%E5%B8%82" title="吉林市">
吉林市
</a>
</li>
<li>
<a href="/wiki/%E5%9B%9B%E5%B9%B3%E5%B8%82" title="四平市">
四平市
</a>
</li>
<li>
<a href="/wiki/%E6%9D%BE%E5%8E%9F%E5%B8%82_(%E5%90%89%E6%9E%97%E7%9C%81)" title="松原市 (吉林省)">
松原市
</a>
</li>
<li>
<a href="/wiki/%E6%95%A6%E5%8C%96%E5%B8%82" title="敦化市">
敦化市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%B6%E5%90%89%E5%B8%82" title="延吉市">
延吉市
</a>
</li>
<li>
<a href="/wiki/%E9%9B%86%E5%AE%89%E5%B8%82" title="集安市">
集安市
</a>
</li>
<li>
<a href="/wiki/%E7%8F%B2%E6%98%A5%E5%B8%82" title="珲春市">
珲春市
</a>
</li>
<li>
<a href="/wiki/%E6%A2%85%E6%B2%B3%E5%8F%A3%E5%B8%82" title="梅河口市">
梅河口市
</a>
</li>
<li>
<a href="/wiki/%E9%80%9A%E5%8C%96%E5%B8%82" title="通化市">
通化市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%AE%89%E5%B8%82" title="大安市">
大安市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E9%BB%91%E9%BE%99%E6%B1%9F%E7%9C%81" title="黑龙江省">
<span style="color:white;">
黑龙江省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E4%BC%8A%E6%98%A5%E5%B8%82" title="伊春市">
伊春市
</a>
</li>
<li>
<a href="/wiki/%E4%BD%B3%E6%9C%A8%E6%96%AF%E5%B8%82" title="佳木斯市">
佳木斯市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%83%E5%8F%B0%E6%B2%B3%E5%B8%82" title="七台河市">
七台河市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E6%9E%97%E5%B8%82" title="海林市">
海林市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%BA%86%E5%B8%82" title="大庆市">
大庆市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%91%E6%B2%B3%E5%B8%82" title="黑河市">
黑河市
</a>
</li>
<li>
<a href="/wiki/%E5%90%8C%E6%B1%9F%E5%B8%82" title="同江市">
同江市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
<span style="color:white;">
上海市
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B5%A6%E4%B8%9C%E6%96%B0%E5%8C%BA" title="浦东新区">
浦东新区
</a>
</li>
<li>
<a href="/wiki/%E9%97%B5%E8%A1%8C%E5%8C%BA" title="闵行区">
闵行区
</a>
</li>
<li>
<a href="/wiki/%E9%87%91%E5%B1%B1%E5%8C%BA_(%E4%B8%8A%E6%B5%B7%E5%B8%82)" title="金山区 (上海市)">
金山区
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E6%B5%B7%E5%B8%82" title="上海市">
上海市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B1%9F%E8%8B%8F%E7%9C%81" title="江苏省">
<span style="color:white;">
江苏省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%97%E4%BA%AC%E5%B8%82" title="南京市">
南京市
</a>
</li>
<li>
<a href="/wiki/%E5%B8%B8%E7%86%9F%E5%B8%82" title="常熟市">
常熟市
</a>
</li>
<li>
<a href="/wiki/%E6%97%A0%E9%94%A1%E5%B8%82" title="无锡市">
无锡市
</a>
</li>
<li>
<a href="/wiki/%E6%89%AC%E5%B7%9E%E5%B8%82" title="扬州市">
扬州市
</a>
</li>
<li>
<a href="/wiki/%E8%8B%8F%E5%B7%9E%E5%B8%82" title="苏州市">
苏州市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%A0%E5%AE%B6%E6%B8%AF%E5%B8%82" title="张家港市">
张家港市
</a>
</li>
<li>
<a href="/wiki/%E6%98%86%E5%B1%B1%E5%B8%82" title="昆山市">
昆山市
</a>
</li>
<li>
<a href="/wiki/%E5%BE%90%E5%B7%9E%E5%B8%82" title="徐州市">
徐州市
</a>
</li>
<li>
<a href="/wiki/%E9%95%87%E6%B1%9F%E5%B8%82" title="镇江市">
镇江市
</a>
</li>
<li>
<a href="/wiki/%E5%90%B4%E6%B1%9F%E5%8C%BA" title="吴江区">
吴江区
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E5%85%B4%E5%B8%82" title="宜兴市">
宜兴市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%AA%E4%BB%93%E5%B8%82" title="太仓市">
太仓市
</a>
</li>
<li>
<a href="/wiki/%E5%B8%B8%E5%B7%9E%E5%B8%82" title="常州市">
常州市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E9%80%9A%E5%B8%82" title="南通市">
南通市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E9%98%B4%E5%B8%82" title="江阴市">
江阴市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%AE%E5%AE%89%E5%B8%82" title="淮安市">
淮安市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%BF%E8%BF%81%E5%B8%82" title="宿迁市">
宿迁市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%B0%E5%B7%9E%E5%B8%82" title="泰州市">
泰州市
</a>
</li>
<li>
<a href="/wiki/%E9%87%91%E5%9D%9B%E5%8C%BA" title="金坛区">
金坛区
</a>
</li>
<li>
<a href="/wiki/%E8%BF%9E%E4%BA%91%E6%B8%AF%E5%B8%82" title="连云港市">
连云港市
</a>
</li>
<li>
<a href="/wiki/%E5%A6%82%E7%9A%8B%E5%B8%82" title="如皋市">
如皋市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E9%83%BD%E5%8C%BA" title="江都区">
江都区
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E6%B2%82%E5%B8%82" title="新沂市">
新沂市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%9C%E5%8F%B0%E5%B8%82" title="东台市">
东台市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E4%B8%B0%E5%8C%BA" title="大丰区">
大丰区
</a>
</li>
<li>
<a href="/wiki/%E6%89%AC%E4%B8%AD%E5%B8%82" title="扬中市">
扬中市
</a>
</li>
<li>
<a href="/wiki/%E9%9D%96%E6%B1%9F%E5%B8%82" title="靖江市">
靖江市
</a>
</li>
<li>
<a href="/wiki/%E9%82%B3%E5%B7%9E%E5%B8%82" title="邳州市">
邳州市
</a>
</li>
<li>
<a href="/wiki/%E6%BA%A7%E9%98%B3%E5%B8%82" title="溧阳市">
溧阳市
</a>
</li>
<li>
<a href="/wiki/%E5%90%AF%E4%B8%9C%E5%B8%82" title="启东市">
启东市
</a>
</li>
<li>
<a href="/wiki/%E9%AB%98%E9%82%AE%E5%B8%82" title="高邮市">
高邮市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B5%99%E6%B1%9F%E7%9C%81" title="浙江省">
<span style="color:white;">
浙江省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%9D%AD%E5%B7%9E%E5%B8%82" title="杭州市">
杭州市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%81%E6%B3%A2%E5%B8%82" title="宁波市">
宁波市
</a>
</li>
<li>
<a href="/wiki/%E7%BB%8D%E5%85%B4%E5%B8%82" title="绍兴市">
绍兴市
</a>
</li>
<li>
<a href="/wiki/%E5%AF%8C%E9%98%B3%E5%8C%BA" title="富阳区">
富阳区
</a>
</li>
<li>
<a href="/wiki/%E5%98%89%E5%85%B4%E5%B8%82" title="嘉兴市">
嘉兴市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%96%E5%B7%9E%E5%B8%82" title="湖州市">
湖州市
</a>
</li>
<li>
<a href="/wiki/%E8%AF%B8%E6%9A%A8%E5%B8%82" title="诸暨市">
诸暨市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B4%E6%B5%B7%E5%B8%82" title="临海市">
临海市
</a>
</li>
<li>
<a href="/wiki/%E6%A1%90%E4%B9%A1%E5%B8%82" title="桐乡市">
桐乡市
</a>
</li>
<li>
<a href="/wiki/%E8%A1%A2%E5%B7%9E%E5%B8%82" title="衢州市">
衢州市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%89%E4%B9%8C%E5%B8%82" title="义乌市">
义乌市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E8%99%9E%E5%8C%BA" title="上虞区">
上虞区
</a>
</li>
<li>
<a href="/wiki/%E5%8F%B0%E5%B7%9E%E5%B8%82" title="台州市">
台州市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%B3%E6%B9%96%E5%B8%82" title="平湖市">
平湖市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E5%AE%81%E5%B8%82" title="海宁市">
海宁市
</a>
</li>
<li>
<a href="/wiki/%E4%BD%99%E5%A7%9A%E5%B8%82" title="余姚市">
余姚市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E5%B1%B1%E5%B8%82" title="江山市">
江山市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%A9%E5%B2%AD%E5%B8%82" title="温岭市">
温岭市
</a>
</li>
<li>
<a href="/wiki/%E9%87%91%E5%8D%8E%E5%B8%82" title="金华市">
金华市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%BD%E6%B0%B4%E5%B8%82" title="丽水市">
丽水市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%BA%E5%BE%B7%E5%B8%82" title="建德市">
建德市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%A9%E5%B7%9E%E5%B8%82" title="温州市">
温州市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E4%B8%B4%E5%AE%89%E5%B8%82" title="临安市">
临安市
</a>
</li>
<li>
<a href="/wiki/%E9%BE%99%E6%B3%89%E5%B8%82" title="龙泉市">
龙泉市
</a>
</li>
<li>
<a href="/wiki/%E6%85%88%E6%BA%AA%E5%B8%82" title="慈溪市">
慈溪市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%9C%E9%98%B3%E5%B8%82" title="东阳市">
东阳市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%90%E6%B8%85%E5%B8%82" title="乐清市">
乐清市
</a>
</li>
<li>
<a href="/wiki/%E7%91%9E%E5%AE%89%E5%B8%82" title="瑞安市">
瑞安市
</a>
</li>
<li>
<a href="/wiki/%E5%85%B0%E6%BA%AA%E5%B8%82" title="兰溪市">
兰溪市
</a>
</li>
<li>
<a href="/wiki/%E8%88%9F%E5%B1%B1%E5%B8%82" title="舟山市">
舟山市
</a>
</li>
<li>
<a href="/wiki/%E5%B5%8A%E5%B7%9E%E5%B8%82" title="嵊州市">
嵊州市
</a>
</li>
<li>
<a href="/wiki/%E6%B0%B8%E5%BA%B7%E5%B8%82" title="永康市">
永康市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%AE%89%E5%BE%BD%E7%9C%81" title="安徽省">
<span style="color:white;">
安徽省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%90%88%E8%82%A5%E5%B8%82" title="合肥市">
合肥市
</a>
</li>
<li>
<a href="/wiki/%E9%A9%AC%E9%9E%8D%E5%B1%B1%E5%B8%82" title="马鞍山市">
马鞍山市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E5%BA%86%E5%B8%82" title="安庆市">
安庆市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E5%B1%B1%E5%B8%82" title="黄山市">
黄山市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%AE%E5%8C%97%E5%B8%82" title="淮北市">
淮北市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%AE%E5%8D%97%E5%B8%82" title="淮南市">
淮南市
</a>
</li>
<li>
<a href="/wiki/%E9%93%9C%E9%99%B5%E5%B8%82" title="铜陵市">
铜陵市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%A0%E5%B7%9E%E5%B8%82" title="池州市">
池州市
</a>
</li>
<li>
<a href="/wiki/%E8%8A%9C%E6%B9%96%E5%B8%82" title="芜湖市">
芜湖市
</a>
</li>
<li>
<a href="/wiki/%E5%85%AD%E5%AE%89%E5%B8%82" title="六安市">
六安市
</a>
</li>
<li>
<a href="/wiki/%E6%BB%81%E5%B7%9E%E5%B8%82" title="滁州市">
滁州市
</a>
</li>
<li>
<a href="/wiki/%E8%9A%8C%E5%9F%A0%E5%B8%82" title="蚌埠市">
蚌埠市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%BF%E5%B7%9E%E5%B8%82" title="宿州市">
宿州市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%A3%E5%9F%8E%E5%B8%82" title="宣城市">
宣城市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%81%E5%9B%BD%E5%B8%82" title="宁国市">
宁国市
</a>
</li>
<li>
<a href="/wiki/%E5%B7%A2%E6%B9%96%E5%B8%82" title="巢湖市">
巢湖市
</a>
</li>
<li>
<a href="/wiki/%E6%98%8E%E5%85%89%E5%B8%82" title="明光市">
明光市
</a>
</li>
<li>
<a href="/wiki/%E6%A1%90%E5%9F%8E%E5%B8%82" title="桐城市">
桐城市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E7%A6%8F%E5%BB%BA%E7%9C%81" title="福建省">
<span style="color:white;">
福建省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8E%A6%E9%97%A8%E5%B8%82" title="厦门市">
厦门市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E6%98%8E%E5%B8%82" title="三明市">
三明市
</a>
</li>
<li>
<a href="/wiki/%E7%A6%8F%E5%B7%9E%E5%B8%82" title="福州市">
福州市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%89%E5%B7%9E%E5%B8%82" title="泉州市">
泉州市
</a>
</li>
<li>
<a href="/wiki/%E6%BC%B3%E5%B7%9E%E5%B8%82" title="漳州市">
漳州市
</a>
</li>
<li>
<a href="/wiki/%E6%B0%B8%E5%AE%89%E5%B8%82" title="永安市">
永安市
</a>
</li>
<li>
<a href="/wiki/%E8%8E%86%E7%94%B0%E5%B8%82" title="莆田市">
莆田市
</a>
</li>
<li>
<a href="/wiki/%E9%BE%99%E5%B2%A9%E5%B8%82" title="龙岩市">
龙岩市
</a>
</li>
<li>
<a href="/wiki/%E6%99%8B%E6%B1%9F%E5%B8%82" title="晋江市">
晋江市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%81%E5%BE%B7%E5%B8%82" title="宁德市">
宁德市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B1%9F%E8%A5%BF%E7%9C%81" title="江西省">
<span style="color:white;">
江西省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%AE%9C%E6%98%A5%E5%B8%82" title="宜春市">
宜春市
</a>
</li>
<li>
<a href="/wiki/%E6%99%AF%E5%BE%B7%E9%95%87%E5%B8%82" title="景德镇市">
景德镇市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E6%98%8C%E5%B8%82" title="南昌市">
南昌市
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E4%BD%99%E5%B8%82" title="新余市">
新余市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%A3%E5%B7%9E%E5%B8%82" title="赣州市">
赣州市
</a>
</li>
<li>
<a href="/wiki/%E8%90%8D%E4%B9%A1%E5%B8%82" title="萍乡市">
萍乡市
</a>
</li>
<li>
<a href="/wiki/%E5%90%89%E5%AE%89%E5%B8%82" title="吉安市">
吉安市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%9D%E6%B1%9F%E5%B8%82" title="九江市">
九江市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%8A%E9%A5%B6%E5%B8%82" title="上饶市">
上饶市
</a>
</li>
<li>
<a href="/wiki/%E9%B9%B0%E6%BD%AD%E5%B8%82" title="鹰潭市">
鹰潭市
</a>
</li>
<li>
<a href="/wiki/%E6%8A%9A%E5%B7%9E%E5%B8%82" title="抚州市">
抚州市
</a>
</li>
<li>
<a href="/wiki/%E8%B4%B5%E6%BA%AA%E5%B8%82" title="贵溪市">
贵溪市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%B1%B1%E4%B8%9C%E7%9C%81" title="山东省">
<span style="color:white;">
山东省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%A8%81%E6%B5%B7%E5%B8%82" title="威海市">
威海市
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E5%B2%9B%E5%B8%82" title="青岛市">
青岛市
</a>
</li>
<li>
<a href="/wiki/%E7%83%9F%E5%8F%B0%E5%B8%82" title="烟台市">
烟台市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%8E%E5%8D%97%E5%B8%82" title="济南市">
济南市
</a>
</li>
<li>
<a href="/wiki/%E8%8D%A3%E6%88%90%E5%B8%82" title="荣成市">
荣成市
</a>
</li>
<li>
<a href="/wiki/%E6%97%A5%E7%85%A7%E5%B8%82" title="日照市">
日照市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%84%E5%8D%9A%E5%B8%82" title="淄博市">
淄博市
</a>
</li>
<li>
<a href="/wiki/%E5%AF%BF%E5%85%89%E5%B8%82" title="寿光市">
寿光市
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E6%B3%B0%E5%B8%82" title="新泰市">
新泰市
</a>
</li>
<li>
<a href="/wiki/%E8%83%B6%E5%8D%97%E5%B8%82" title="胶南市">
胶南市
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E5%B7%9E%E5%B8%82" title="青州市">
青州市
</a>
</li>
<li>
<s>
<a href="/wiki/%E8%8E%B1%E8%8A%9C%E5%B8%82" title="莱芜市">
莱芜市
</a>
</s>
</li>
<li>
<a href="/wiki/%E8%83%B6%E5%B7%9E%E5%B8%82" title="胶州市">
胶州市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%B3%E5%B1%B1%E5%B8%82" title="乳山市">
乳山市
</a>
</li>
<li>
<a href="/wiki/%E6%96%87%E7%99%BB%E5%8C%BA" title="文登区">
文登区
</a>
</li>
<li>
<a href="/wiki/%E6%BD%8D%E5%9D%8A%E5%B8%82" title="潍坊市">
潍坊市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B4%E6%B2%82%E5%B8%82" title="临沂市">
临沂市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%B0%E5%AE%89%E5%B8%82" title="泰安市">
泰安市
</a>
</li>
<li>
<a class="mw-redirect" href="/wiki/%E7%AB%A0%E4%B8%98%E5%B8%82" title="章丘市">
章丘市
</a>
</li>
<li>
<a href="/wiki/%E8%82%A5%E5%9F%8E%E5%B8%82" title="肥城市">
肥城市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%9C%E8%90%A5%E5%B8%82" title="东营市">
东营市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%8E%E5%AE%81%E5%B8%82" title="济宁市">
济宁市
</a>
</li>
<li>
<a href="/wiki/%E8%81%8A%E5%9F%8E%E5%B8%82" title="聊城市">
聊城市
</a>
</li>
<li>
<a href="/wiki/%E9%BE%99%E5%8F%A3%E5%B8%82" title="龙口市">
龙口市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%B7%E9%98%B3%E5%B8%82" title="海阳市">
海阳市
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E5%B7%9E%E5%B8%82" title="德州市">
德州市
</a>
</li>
<li>
<a href="/wiki/%E6%BB%A8%E5%B7%9E%E5%B8%82" title="滨州市">
滨州市
</a>
</li>
<li>
<a href="/wiki/%E8%8F%8F%E6%B3%BD%E5%B8%82" title="菏泽市">
菏泽市
</a>
</li>
<li>
<a href="/wiki/%E8%8E%B1%E5%B7%9E%E5%B8%82" title="莱州市">
莱州市
</a>
</li>
<li>
<a href="/wiki/%E8%AF%B8%E5%9F%8E%E5%B8%82" title="诸城市">
诸城市
</a>
</li>
<li>
<a href="/wiki/%E9%AB%98%E5%AF%86%E5%B8%82" title="高密市">
高密市
</a>
</li>
<li>
<a href="/wiki/%E6%9E%A3%E5%BA%84%E5%B8%82" title="枣庄市">
枣庄市
</a>
</li>
<li>
<a href="/wiki/%E6%BB%95%E5%B7%9E%E5%B8%82" title="滕州市">
滕州市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E4%B8%98%E5%B8%82" title="安丘市">
安丘市
</a>
</li>
<li>
<a href="/wiki/%E6%9B%B2%E9%98%9C%E5%B8%82" title="曲阜市">
曲阜市
</a>
</li>
<li>
<a href="/wiki/%E9%82%B9%E5%9F%8E%E5%B8%82" title="邹城市">
邹城市
</a>
</li>
<li>
<a href="/wiki/%E6%98%8C%E9%82%91%E5%B8%82" title="昌邑市">
昌邑市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B2%B3%E5%8D%97%E7%9C%81" title="河南省">
<span style="color:white;">
河南省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%BF%AE%E9%98%B3%E5%B8%82" title="濮阳市">
濮阳市
</a>
</li>
<li>
<a href="/wiki/%E6%B4%9B%E9%98%B3%E5%B8%82" title="洛阳市">
洛阳市
</a>
</li>
<li>
<a href="/wiki/%E6%BC%AF%E6%B2%B3%E5%B8%82" title="漯河市">
漯河市
</a>
</li>
<li>
<a href="/wiki/%E9%83%91%E5%B7%9E%E5%B8%82" title="郑州市">
郑州市
</a>
</li>
<li>
<a href="/wiki/%E8%AE%B8%E6%98%8C%E5%B8%82" title="许昌市">
许昌市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E9%98%B3%E5%B8%82" title="南阳市">
南阳市
</a>
</li>
<li>
<a href="/wiki/%E7%84%A6%E4%BD%9C%E5%B8%82" title="焦作市">
焦作市
</a>
</li>
<li>
<a href="/wiki/%E5%81%83%E5%B8%88%E5%B8%82" title="偃师市">
偃师市
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E4%B9%A1%E5%B8%82" title="新乡市">
新乡市
</a>
</li>
<li>
<a href="/wiki/%E6%B5%8E%E6%BA%90%E5%B8%82" title="济源市">
济源市
</a>
</li>
<li>
<a href="/wiki/%E8%88%9E%E9%92%A2%E5%B8%82" title="舞钢市">
舞钢市
</a>
</li>
<li>
<a href="/wiki/%E7%99%BB%E5%B0%81%E5%B8%82" title="登封市">
登封市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E9%97%A8%E5%B3%A1%E5%B8%82" title="三门峡市">
三门峡市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E9%98%B3%E5%B8%82" title="安阳市">
安阳市
</a>
</li>
<li>
<a href="/wiki/%E5%95%86%E4%B8%98%E5%B8%82" title="商丘市">
商丘市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%B3%E9%A1%B6%E5%B1%B1%E5%B8%82" title="平顶山市">
平顶山市
</a>
</li>
<li>
<a href="/wiki/%E5%B7%A9%E4%B9%89%E5%B8%82" title="巩义市">
巩义市
</a>
</li>
<li>
<a href="/wiki/%E4%BF%A1%E9%98%B3%E5%B8%82" title="信阳市">
信阳市
</a>
</li>
<li>
<a href="/wiki/%E9%A9%BB%E9%A9%AC%E5%BA%97%E5%B8%82" title="驻马店市">
驻马店市
</a>
</li>
<li>
<a href="/wiki/%E6%B0%B8%E5%9F%8E%E5%B8%82" title="永城市">
永城市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%80%E5%B0%81%E5%B8%82" title="开封市">
开封市
</a>
</li>
<li>
<a href="/wiki/%E6%9E%97%E5%B7%9E%E5%B8%82" title="林州市">
林州市
</a>
</li>
<li>
<a href="/wiki/%E9%82%93%E5%B7%9E%E5%B8%82" title="邓州市">
邓州市
</a>
</li>
<li>
<a href="/wiki/%E9%B9%A4%E5%A3%81%E5%B8%82" title="鹤壁市">
鹤壁市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9D%E5%B7%9E%E5%B8%82" title="汝州市">
汝州市
</a>
</li>
<li>
<a href="/wiki/%E7%A6%B9%E5%B7%9E%E5%B8%82" title="禹州市">
禹州市
</a>
</li>
<li>
<a href="/wiki/%E8%8D%A5%E9%98%B3%E5%B8%82" title="荥阳市">
荥阳市
</a>
</li>
<li>
<a href="/wiki/%E5%91%A8%E5%8F%A3%E5%B8%82" title="周口市">
周口市
</a>
</li>
<li>
<a href="/wiki/%E6%96%B0%E9%83%91%E5%B8%82" title="新郑市">
新郑市
</a>
</li>
<li>
<a href="/wiki/%E9%95%BF%E8%91%9B%E5%B8%82" title="长葛市">
长葛市
</a>
</li>
<li>
<a href="/wiki/%E5%AD%9F%E5%B7%9E%E5%B8%82" title="孟州市">
孟州市
</a>
</li>
<li>
<a href="/wiki/%E9%A1%B9%E5%9F%8E%E5%B8%82" title="项城市">
项城市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%89%E9%A9%AC%E5%B8%82" title="义马市">
义马市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B9%96%E5%8C%97%E7%9C%81" title="湖北省">
<span style="color:white;">
湖北省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%81%E5%A0%B0%E5%B8%82" title="十堰市">
十堰市
</a>
</li>
<li>
<a href="/wiki/%E8%A5%84%E9%98%B3%E5%B8%82" title="襄阳市">
襄阳市
</a>
</li>
<li>
<a href="/wiki/%E6%AD%A6%E6%B1%89%E5%B8%82" title="武汉市">
武汉市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E6%98%8C%E5%B8%82" title="宜昌市">
宜昌市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E7%9F%B3%E5%B8%82" title="黄石市">
黄石市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E9%83%BD%E5%B8%82" title="宜都市">
宜都市
</a>
</li>
<li>
<a href="/wiki/%E9%84%82%E5%B7%9E%E5%B8%82" title="鄂州市">
鄂州市
</a>
</li>
<li>
<a href="/wiki/%E8%8D%86%E9%97%A8%E5%B8%82" title="荆门市">
荆门市
</a>
</li>
<li>
<a href="/wiki/%E8%8D%86%E5%B7%9E%E5%B8%82" title="荆州市">
荆州市
</a>
</li>
<li>
<a href="/wiki/%E5%92%B8%E5%AE%81%E5%B8%82" title="咸宁市">
咸宁市
</a>
</li>
<li>
<a href="/wiki/%E9%9A%8F%E5%B7%9E%E5%B8%82" title="随州市">
随州市
</a>
</li>
<li>
<a href="/wiki/%E5%BD%93%E9%98%B3%E5%B8%82" title="当阳市">
当阳市
</a>
</li>
<li>
<a href="/wiki/%E6%81%A9%E6%96%BD%E5%B8%82" title="恩施市">
恩施市
</a>
</li>
<li>
<a href="/wiki/%E4%BB%99%E6%A1%83%E5%B8%82" title="仙桃市">
仙桃市
</a>
</li>
<li>
<a href="/wiki/%E5%AD%9D%E6%84%9F%E5%B8%82" title="孝感市">
孝感市
</a>
</li>
<li>
<a href="/wiki/%E9%BB%84%E5%86%88%E5%B8%82" title="黄冈市">
黄冈市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E5%86%B6%E5%B8%82" title="大冶市">
大冶市
</a>
</li>
<li>
<a href="/wiki/%E5%BA%94%E5%9F%8E%E5%B8%82" title="应城市">
应城市
</a>
</li>
<li>
<a href="/wiki/%E6%9D%BE%E6%BB%8B%E5%B8%82" title="松滋市">
松滋市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%A4%E5%A3%81%E5%B8%82" title="赤壁市">
赤壁市
</a>
</li>
<li>
<a href="/wiki/%E6%BD%9C%E6%B1%9F%E5%B8%82" title="潜江市">
潜江市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A9%E9%97%A8%E5%B8%82" title="天门市">
天门市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%B9%E6%B1%9F%E5%8F%A3%E5%B8%82" title="丹江口市">
丹江口市
</a>
</li>
<li>
<a href="/wiki/%E6%9E%9D%E6%B1%9F%E5%B8%82" title="枝江市">
枝江市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E5%9F%8E%E5%B8%82" title="宜城市">
宜城市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E9%99%86%E5%B8%82" title="安陆市">
安陆市
</a>
</li>
<li>
<a href="/wiki/%E7%9F%B3%E9%A6%96%E5%B8%82" title="石首市">
石首市
</a>
</li>
<li>
<a href="/wiki/%E5%88%A9%E5%B7%9D%E5%B8%82" title="利川市">
利川市
</a>
</li>
<li>
<a href="/wiki/%E9%92%9F%E7%A5%A5%E5%B8%82" title="钟祥市">
钟祥市
</a>
</li>
<li>
<a href="/wiki/%E6%B4%AA%E6%B9%96%E5%B8%82" title="洪湖市">
洪湖市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E6%B0%B4%E5%B8%82" title="广水市">
广水市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B9%96%E5%8D%97%E7%9C%81" title="湖南省">
<span style="color:white;">
湖南省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%B8%B8%E5%BE%B7%E5%B8%82" title="常德市">
常德市
</a>
</li>
<li>
<a href="/wiki/%E5%B2%B3%E9%98%B3%E5%B8%82" title="岳阳市">
岳阳市
</a>
</li>
<li>
<a href="/wiki/%E6%A0%AA%E6%B4%B2%E5%B8%82" title="株洲市">
株洲市
</a>
</li>
<li>
<a href="/wiki/%E9%95%BF%E6%B2%99%E5%B8%82" title="长沙市">
长沙市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%98%E6%BD%AD%E5%B8%82" title="湘潭市">
湘潭市
</a>
</li>
<li>
<a href="/wiki/%E5%A8%84%E5%BA%95%E5%B8%82" title="娄底市">
娄底市
</a>
</li>
<li>
<a href="/wiki/%E9%83%B4%E5%B7%9E%E5%B8%82" title="郴州市">
郴州市
</a>
</li>
<li>
<a href="/wiki/%E8%A1%A1%E9%98%B3%E5%B8%82" title="衡阳市">
衡阳市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%84%E5%85%B4%E5%B8%82" title="资兴市">
资兴市
</a>
</li>
<li>
<a href="/wiki/%E9%86%B4%E9%99%B5%E5%B8%82" title="醴陵市">
醴陵市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%B9%BF%E4%B8%9C%E7%9C%81" title="广东省">
<span style="color:white;">
广东省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E7%8F%A0%E6%B5%B7%E5%B8%82" title="珠海市">
珠海市
</a>
</li>
<li>
<a href="/wiki/%E6%B7%B1%E5%9C%B3%E5%B8%82" title="深圳市">
深圳市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%AD%E5%B1%B1%E5%B8%82" title="中山市">
中山市
</a>
</li>
<li>
<a href="/wiki/%E4%BD%9B%E5%B1%B1%E5%B8%82" title="佛山市">
佛山市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%9F%E9%97%A8%E5%B8%82" title="江门市">
江门市
</a>
</li>
<li>
<a href="/wiki/%E6%83%A0%E5%B7%9E%E5%B8%82" title="惠州市">
惠州市
</a>
</li>
<li>
<a href="/wiki/%E8%8C%82%E5%90%8D%E5%B8%82" title="茂名市">
茂名市
</a>
</li>
<li>
<a href="/wiki/%E8%82%87%E5%BA%86%E5%B8%82" title="肇庆市">
肇庆市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%80%E5%B9%B3%E5%B8%82" title="开平市">
开平市
</a>
</li>
<li>
<a href="/wiki/%E6%B9%9B%E6%B1%9F%E5%B8%82" title="湛江市">
湛江市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%B7%9E%E5%B8%82" title="广州市">
广州市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%9C%E8%8E%9E%E5%B8%82" title="东莞市">
东莞市
</a>
</li>
<li>
<a href="/wiki/%E6%BD%AE%E5%B7%9E%E5%B8%82" title="潮州市">
潮州市
</a>
</li>
<li>
<a href="/wiki/%E9%9F%B6%E5%85%B3%E5%B8%82" title="韶关市">
韶关市
</a>
</li>
<li>
<a href="/wiki/%E6%A2%85%E5%B7%9E%E5%B8%82" title="梅州市">
梅州市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%95%E5%A4%B4%E5%B8%82" title="汕头市">
汕头市
</a>
</li>
<li>
<a href="/wiki/%E9%98%B3%E6%B1%9F%E5%B8%82" title="阳江市">
阳江市
</a>
</li>
<li>
<a href="/wiki/%E6%B8%85%E8%BF%9C%E5%B8%82" title="清远市">
清远市
</a>
</li>
<li>
<a href="/wiki/%E6%B2%B3%E6%BA%90%E5%B8%82" title="河源市">
河源市
</a>
</li>
<li>
<a href="/wiki/%E4%BA%91%E6%B5%AE%E5%B8%82" title="云浮市">
云浮市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%B9%BF%E8%A5%BF%E5%A3%AE%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="广西壮族自治区">
<span style="color:white;">
广西壮族自治区
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8D%97%E5%AE%81%E5%B8%82" title="南宁市">
南宁市
</a>
</li>
<li>
<a href="/wiki/%E6%A1%82%E6%9E%97%E5%B8%82" title="桂林市">
桂林市
</a>
</li>
<li>
<a href="/wiki/%E6%9F%B3%E5%B7%9E%E5%B8%82" title="柳州市">
柳州市
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E6%B5%B7%E5%B8%82" title="北海市">
北海市
</a>
</li>
<li>
<a href="/wiki/%E7%99%BE%E8%89%B2%E5%B8%82" title="百色市">
百色市
</a>
</li>
<li>
<a href="/wiki/%E6%A2%A7%E5%B7%9E%E5%B8%82" title="梧州市">
梧州市
</a>
</li>
<li>
<a href="/wiki/%E5%8C%97%E6%B5%81%E5%B8%82" title="北流市">
北流市
</a>
</li>
<li>
<a href="/wiki/%E9%92%A6%E5%B7%9E%E5%B8%82" title="钦州市">
钦州市
</a>
</li>
<li>
<a href="/wiki/%E7%8E%89%E6%9E%97%E5%B8%82" title="玉林市">
玉林市
</a>
</li>
<li>
<a href="/wiki/%E9%98%B2%E5%9F%8E%E6%B8%AF%E5%B8%82" title="防城港市">
防城港市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%B5%B7%E5%8D%97%E7%9C%81" title="海南省">
<span style="color:white;">
海南省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%B5%B7%E5%8F%A3%E5%B8%82" title="海口市">
海口市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%89%E4%BA%9A%E5%B8%82" title="三亚市">
三亚市
</a>
</li>
<li>
<a href="/wiki/%E5%84%8B%E5%B7%9E%E5%B8%82" title="儋州市">
儋州市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E9%87%8D%E5%BA%86%E5%B8%82" title="重庆市">
<span style="color:white;">
重庆市
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%8C%97%E7%A2%9A%E5%8C%BA" title="北碚区">
北碚区
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%9B%9B%E5%B7%9D%E7%9C%81" title="四川省">
<span style="color:white;">
四川省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%B3%A8%E7%9C%89%E5%B1%B1%E5%B8%82" title="峨眉山市">
峨眉山市
</a>
</li>
<li>
<a href="/wiki/%E7%BB%B5%E9%98%B3%E5%B8%82" title="绵阳市">
绵阳市
</a>
</li>
<li>
<a href="/wiki/%E9%83%BD%E6%B1%9F%E5%A0%B0%E5%B8%82" title="都江堰市">
都江堰市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%90%E5%B1%B1%E5%B8%82" title="乐山市">
乐山市
</a>
</li>
<li>
<a href="/wiki/%E6%88%90%E9%83%BD%E5%B8%82" title="成都市">
成都市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%AE%89%E5%B8%82" title="广安市">
广安市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%97%E5%85%85%E5%B8%82" title="南充市">
南充市
</a>
</li>
<li>
<a href="/wiki/%E9%81%82%E5%AE%81%E5%B8%82" title="遂宁市">
遂宁市
</a>
</li>
<li>
<a href="/wiki/%E8%87%AA%E8%B4%A1%E5%B8%82" title="自贡市">
自贡市
</a>
</li>
<li>
<a href="/wiki/%E5%BE%B7%E9%98%B3%E5%B8%82" title="德阳市">
德阳市
</a>
</li>
<li>
<a href="/wiki/%E7%9C%89%E5%B1%B1%E5%B8%82" title="眉山市">
眉山市
</a>
</li>
<li>
<a href="/wiki/%E6%B3%B8%E5%B7%9E%E5%B8%82" title="泸州市">
泸州市
</a>
</li>
<li>
<a href="/wiki/%E9%98%86%E4%B8%AD%E5%B8%82" title="阆中市">
阆中市
</a>
</li>
<li>
<a href="/wiki/%E6%94%80%E6%9E%9D%E8%8A%B1%E5%B8%82" title="攀枝花市">
攀枝花市
</a>
</li>
<li>
<a href="/wiki/%E8%B5%84%E9%98%B3%E5%B8%82" title="资阳市">
资阳市
</a>
</li>
<li>
<a href="/wiki/%E5%B9%BF%E5%85%83%E5%B8%82" title="广元市">
广元市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%9C%E5%AE%BE%E5%B8%82" title="宜宾市">
宜宾市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E8%B4%B5%E5%B7%9E%E7%9C%81" title="贵州省">
<span style="color:white;">
贵州省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%81%B5%E4%B9%89%E5%B8%82" title="遵义市">
遵义市
</a>
</li>
<li>
<a href="/wiki/%E8%B4%B5%E9%98%B3%E5%B8%82" title="贵阳市">
贵阳市
</a>
</li>
<li>
<a href="/wiki/%E5%AE%89%E9%A1%BA%E5%B8%82" title="安顺市">
安顺市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E4%BA%91%E5%8D%97%E7%9C%81" title="云南省">
<span style="color:white;">
云南省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%AE%89%E5%AE%81%E5%B8%82" title="安宁市">
安宁市
</a>
</li>
<li>
<a href="/wiki/%E6%98%86%E6%98%8E%E5%B8%82" title="昆明市">
昆明市
</a>
</li>
<li>
<a href="/wiki/%E7%8E%89%E6%BA%AA%E5%B8%82" title="玉溪市">
玉溪市
</a>
</li>
<li>
<a href="/wiki/%E6%99%AF%E6%B4%AA%E5%B8%82" title="景洪市">
景洪市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%BD%E6%B1%9F%E5%B8%82" title="丽江市">
丽江市
</a>
</li>
<li>
<a href="/wiki/%E6%99%AE%E6%B4%B1%E5%B8%82" title="普洱市">
普洱市
</a>
</li>
<li>
<a href="/wiki/%E5%BC%80%E8%BF%9C%E5%B8%82" title="开远市">
开远市
</a>
</li>
<li>
<a href="/wiki/%E8%8A%92%E5%B8%82" title="芒市">
芒市
</a>
</li>
<li>
<a href="/wiki/%E6%9B%B2%E9%9D%96%E5%B8%82" title="曲靖市">
曲靖市
</a>
</li>
<li>
<a href="/wiki/%E5%A4%A7%E7%90%86%E5%B8%82" title="大理市">
大理市
</a>
</li>
<li>
<a href="/wiki/%E8%85%BE%E5%86%B2%E5%B8%82" title="腾冲市">
腾冲市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E8%A5%BF%E8%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="西藏自治区">
<span style="color:white;">
西藏自治区
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E6%8B%89%E8%90%A8%E5%B8%82" title="拉萨市">
拉萨市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E9%99%95%E8%A5%BF%E7%9C%81" title="陕西省">
<span style="color:white;">
陕西省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E5%AE%9D%E9%B8%A1%E5%B8%82" title="宝鸡市">
宝鸡市
</a>
</li>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%89%E5%B8%82" title="西安市">
西安市
</a>
</li>
<li>
<a href="/wiki/%E5%92%B8%E9%98%B3%E5%B8%82" title="咸阳市">
咸阳市
</a>
</li>
<li>
<a href="/wiki/%E5%BB%B6%E5%AE%89%E5%B8%82" title="延安市">
延安市
</a>
</li>
<li>
<a href="/wiki/%E6%B1%89%E4%B8%AD%E5%B8%82" title="汉中市">
汉中市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E9%9D%92%E6%B5%B7%E7%9C%81" title="青海省">
<span style="color:white;">
青海省
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E8%A5%BF%E5%AE%81%E5%B8%82" title="西宁市">
西宁市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E7%94%98%E8%82%83%E7%9C%81" title="甘肃省">
<span style="color:white;">
甘肃省
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%87%91%E6%98%8C%E5%B8%82" title="金昌市">
金昌市
</a>
</li>
<li>
<a href="/wiki/%E6%95%A6%E7%85%8C%E5%B8%82" title="敦煌市">
敦煌市
</a>
</li>
<li>
<a href="/wiki/%E5%98%89%E5%B3%AA%E5%85%B3%E5%B8%82" title="嘉峪关市">
嘉峪关市
</a>
</li>
<li>
<a href="/wiki/%E7%8E%89%E9%97%A8%E5%B8%82" title="玉门市">
玉门市
</a>
</li>
<li>
<a href="/wiki/%E5%85%B0%E5%B7%9E%E5%B8%82" title="兰州市">
兰州市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E5%AE%81%E5%A4%8F%E5%9B%9E%E6%97%8F%E8%87%AA%E6%B2%BB%E5%8C%BA" title="宁夏回族自治区">
<span style="color:white;">
宁夏回族自治区
</span>
</a>
</th>
<td class="navbox-list navbox-even hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E9%93%B6%E5%B7%9D%E5%B8%82" title="银川市">
银川市
</a>
</li>
<li>
<a href="/wiki/%E9%9D%92%E9%93%9C%E5%B3%A1%E5%B8%82" title="青铜峡市">
青铜峡市
</a>
</li>
<li>
<a href="/wiki/%E5%90%B4%E5%BF%A0%E5%B8%82" title="吴忠市">
吴忠市
</a>
</li>
<li>
<a href="/wiki/%E4%B8%AD%E5%8D%AB%E5%B8%82" title="中卫市">
中卫市
</a>
</li>
<li>
<a href="/wiki/%E7%81%B5%E6%AD%A6%E5%B8%82" title="灵武市">
灵武市
</a>
</li>
<li>
<a href="/wiki/%E7%9F%B3%E5%98%B4%E5%B1%B1%E5%B8%82" title="石嘴山市">
石嘴山市
</a>
</li>
<li>
<a href="/wiki/%E5%9B%BA%E5%8E%9F%E5%B8%82" title="固原市">
固原市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<th class="navbox-group" scope="row" style="color: #ffffff; background-color:#3CB371; text-align: center;">
<a href="/wiki/%E6%96%B0%E7%96%86%E7%BB%B4%E5%90%BE%E5%B0%94%E8%87%AA%E6%B2%BB%E5%8C%BA" title="新疆维吾尔自治区">
<span style="color:white;">
新疆维吾尔自治区
</span>
</a>
</th>
<td class="navbox-list navbox-odd hlist" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<a href="/wiki/%E7%9F%B3%E6%B2%B3%E5%AD%90%E5%B8%82" title="石河子市">
石河子市
</a>
</li>
<li>
<a href="/wiki/%E5%BA%93%E5%B0%94%E5%8B%92%E5%B8%82" title="库尔勒市">
库尔勒市
</a>
</li>
<li>
<a href="/wiki/%E5%85%8B%E6%8B%89%E7%8E%9B%E4%BE%9D%E5%B8%82" title="克拉玛依市">
克拉玛依市
</a>
</li>
<li>
<a href="/wiki/%E6%98%8C%E5%90%89%E5%B8%82" title="昌吉市">
昌吉市
</a>
</li>
<li>
<a href="/wiki/%E5%A5%8E%E5%B1%AF%E5%B8%82" title="奎屯市">
奎屯市
</a>
</li>
<li>
<a href="/wiki/%E5%93%88%E5%AF%86%E5%B8%82" title="哈密市">
哈密市
</a>
</li>
<li>
<a href="/wiki/%E4%BC%8A%E5%AE%81%E5%B8%82" title="伊宁市">
伊宁市
</a>
</li>
<li>
<a href="/wiki/%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%B8%82" title="乌鲁木齐市">
乌鲁木齐市
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E5%8B%92%E6%B3%B0%E5%B8%82" title="阿勒泰市">
阿勒泰市
</a>
</li>
<li>
<a href="/wiki/%E4%BA%94%E5%AE%B6%E6%B8%A0%E5%B8%82" title="五家渠市">
五家渠市
</a>
</li>
<li>
<a href="/wiki/%E9%98%9C%E5%BA%B7%E5%B8%82" title="阜康市">
阜康市
</a>
</li>
<li>
<a href="/wiki/%E5%8D%9A%E4%B9%90%E5%B8%82" title="博乐市">
博乐市
</a>
</li>
<li>
<a href="/wiki/%E5%90%90%E9%B2%81%E7%95%AA%E5%B8%82" title="吐鲁番市">
吐鲁番市
</a>
</li>
<li>
<a href="/wiki/%E9%98%BF%E6%8B%89%E5%B0%94%E5%B8%82" title="阿拉尔市">
阿拉尔市
</a>
</li>
<li>
<a href="/wiki/%E5%9B%BE%E6%9C%A8%E8%88%92%E5%85%8B%E5%B8%82" title="图木舒克市">
图木舒克市
</a>
</li>
</ul>
</div>
</td>
</tr>
<tr style="height:2px">
<td colspan="3">
</td>
</tr>
<tr>
<td class="navbox-abovebelow" colspan="2" style="background:#3CB371; color: #ffffff;">
<div>
注1:截至2019年公布第二十一批国家园林城市,
<a href="/wiki/%E4%B8%AD%E5%8D%8E%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9B%BD%E4%BD%8F%E6%88%BF%E5%92%8C%E5%9F%8E%E4%B9%A1%E5%BB%BA%E8%AE%BE%E9%83%A8" title="中华人民共和国住房和城乡建设部">
|
<span style="color:white;">
住建部
</span>
</a>
已经累计授予了376个国家园林城市,11个国家园林区。
<br/>
注2:
<s>
划线者
</s>
为因行政区划调整撤销的城市。
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<table cellspacing="0" class="navbox" style="border-spacing:0">
<tbody>
<tr>
<td style="padding:2px">
<table cellspacing="0" class="nowraplinks hlist navbox-inner" style="border-spacing:0;background:transparent;color:inherit">
<tbody>
<tr>
<th class="navbox-group nowrap" scope="row">
<a href="/wiki/Help:%E8%A7%84%E8%8C%83%E6%8E%A7%E5%88%B6" title="Help:规范控制">
规范控制
</a>
<a href="https://www.wikidata.org/wiki/Q956" title="編輯維基數據鏈接">
<img alt="編輯維基數據鏈接" data-file-height="20" data-file-width="20" decoding="async" height="10" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/OOjs_UI_icon_edit-ltr-progressive.svg/10px-OOjs_UI_icon_edit-ltr-progressive.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/8a/OOjs_UI_icon_edit-ltr-progressive.svg/15px-OOjs_UI_icon_edit-ltr-progressive.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/8a/OOjs_UI_icon_edit-ltr-progressive.svg/20px-OOjs_UI_icon_edit-ltr-progressive.svg.png 2x" style="vertical-align: text-top" width="10"/>
</a>
</th>
<td class="navbox-list navbox-odd" style="text-align:left;border-left-width:2px;border-left-style:solid;width:100%;padding:0px">
<div style="padding:0em 0.25em">
<ul>
<li>
<span class="nowrap">
<a class="external text" href="https://www.worldcat.org/identities/containsVIAFID/312565158" rel="nofollow">
WorldCat Identities
</a>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E8%97%9D%E8%A1%93%E8%88%87%E5%BB%BA%E7%AF%89%E7%B4%A2%E5%BC%95%E5%85%B8" title="藝術與建築索引典">
AAT
</a>
:
<span class="uid">
<a class="external text" href="http://vocab.getty.edu/page/aat/300245351" rel="nofollow">
300245351
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%B3%95%E5%9B%BD%E5%9B%BD%E5%AE%B6%E5%9B%BE%E4%B9%A6%E9%A6%86" title="法国国家图书馆">
BNF
</a>
:
<span class="uid">
<a class="external text" href="http://catalogue.bnf.fr/ark:/12148/cb11957264c" rel="nofollow">
cb11957264c
</a>
<a class="external text" href="http://data.bnf.fr/ark:/12148/cb11957264c" rel="nofollow">
(data)
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E6%95%B4%E5%90%88%E8%A7%84%E8%8C%83%E6%96%87%E6%A1%A3" title="整合规范文档">
GND
</a>
:
<span class="uid">
<a class="external text" href="https://d-nb.info/gnd/4075971-4" rel="nofollow">
4075971-4
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E5%9C%8B%E9%9A%9B%E6%A8%99%E6%BA%96%E5%90%8D%E7%A8%B1%E8%AD%98%E5%88%A5%E7%A2%BC" title="國際標準名稱識別碼">
ISNI
</a>
:
<span class="uid">
<a class="external text" href="http://isni.org/isni/0000000121597692" rel="nofollow">
0000 0001 2159 7692
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E7%BE%8E%E5%9B%BD%E5%9B%BD%E4%BC%9A%E5%9B%BE%E4%B9%A6%E9%A6%86%E6%8E%A7%E5%88%B6%E5%8F%B7" title="美国国会图书馆控制号">
LCCN
</a>
:
<span class="uid">
<a class="external text" href="http://id.loc.gov/authorities/names/n79076155" rel="nofollow">
n79076155
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E5%9B%BD%E5%AE%B6%E6%A1%A3%E6%A1%88%E5%92%8C%E8%AE%B0%E5%BD%95%E7%AE%A1%E7%90%86%E5%B1%80" title="国家档案和记录管理局">
NARA
</a>
:
<span class="uid">
<a class="external text" href="https://catalog.archives.gov/id/10036657" rel="nofollow">
10036657
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E5%9C%8B%E7%AB%8B%E5%9C%8B%E6%9C%83%E5%9C%96%E6%9B%B8%E9%A4%A8" title="國立國會圖書館">
NDL
</a>
:
<span class="uid">
<a class="external text" href="https://id.ndl.go.jp/auth/ndlna/00646810" rel="nofollow">
00646810
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a class="mw-redirect" href="/wiki/%E6%8D%B7%E5%85%8B%E5%9B%BD%E5%AE%B6%E5%9B%BE%E4%B9%A6%E9%A6%86" title="捷克国家图书馆">
NKC
</a>
:
<span class="uid">
<a class="external text" href="https://aleph.nkp.cz/F/?func=find-c&local_base=aut&ccl_term=ica=ge130384&CON_LNG=ENG" rel="nofollow">
ge130384
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E4%BB%A5%E8%89%B2%E5%88%97%E5%9B%BD%E5%AE%B6%E5%9B%BE%E4%B9%A6%E9%A6%86" title="以色列国家图书馆">
NNL
</a>
:
<span class="uid">
<a class="external text" href="http://aleph.nli.org.il/F/?func=find-b&local_base=NNL10&find_code=SYS&con_lng=eng&request=000976022" rel="nofollow">
000976022
</a>
</span>
</span>
</li>
<li>
<span class="nowrap">
<a href="/wiki/%E8%99%9A%E6%8B%9F%E5%9B%BD%E9%99%85%E8%A7%84%E8%8C%83%E6%96%87%E6%A1%A3" title="虚拟国际规范文档">
VIAF
</a>
:
<span class="uid">
<a class="external text" href="https://viaf.org/viaf/312565158" rel="nofollow">
312565158
</a>
</span>
</span>
</li>
</ul>
</div>
</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
<!--
NewPP limit report
Parsed by mw1401
Cached time: 20210109032017
Cache expiry: 86400
Dynamic content: true
Complications: []
CPU time usage: 3.848 seconds
Real time usage: 4.782 seconds
Preprocessor visited node count: 29346/1000000
Post‐expand include size: 2036601/2097152 bytes
Template argument size: 274762/2097152 bytes
Highest expansion depth: 22/40
Expensive parser function count: 25/500
Unstrip recursion depth: 0/20
Unstrip post‐expand size: 202785/5000000 bytes
Lua time usage: 1.006/10.000 seconds
Lua memory usage: 10095269/52428800 bytes
Lua Profile:
Scribunto_LuaSandboxCallback::getExpandedArgument 460 ms 32.9%
Scribunto_LuaSandboxCallback::find 220 ms 15.7%
? 100 ms 7.1%
<mw.lua:683> 80 ms 5.7%
Scribunto_LuaSandboxCallback::getEntity 80 ms 5.7%
recursiveClone <mwInit.lua:41> 60 ms 4.3%
tonumber 40 ms 2.9%
Scribunto_LuaSandboxCallback::newTitle 40 ms 2.9%
Scribunto_LuaSandboxCallback::getAllExpandedArguments 40 ms 2.9%
Scribunto_LuaSandboxCallback::plain 40 ms 2.9%
[others] 240 ms 17.1%
Number of Wikibase entities loaded: 1/400
-->
<!--
Transclusion expansion time report (%,ms,calls,template)
100.00% 3147.668 1 -total
41.47% 1305.187 44 Template:Navbox
26.25% 826.113 1 Template:Reflist
22.79% 717.504 1 Template:Template_group
15.20% 478.549 97 Template:Cite_web
10.64% 334.758 53 Template:Flag
7.93% 249.616 3 Template:Navbox_with_columns
7.24% 227.781 66 Template:Flagicon
5.92% 186.452 5 Template:Infobox
5.89% 185.443 1 Template:夏季奧運會主辦城市
-->
<!-- Saved in parser cache with key zhwiki:pcache:idhash:463-0!canonical!zh and timestamp 20210109032013 and revision id 63604485. Serialized with JSON.
-->
</div>
<noscript>
<img alt="" height="1" src="//zh.wikipedia.org/wiki/Special:CentralAutoLogin/start?type=1x1" style="border: none; position: absolute;" title="" width="1"/>
</noscript>
<div class="printfooter">
取自“
<a dir="ltr" href="https://zh.wikipedia.org/w/index.php?title=北京市&oldid=63604485">
https://zh.wikipedia.org/w/index.php?title=北京市&oldid=63604485
</a>
”
</div>
</div>
<div class="catlinks" data-mw="interface" id="catlinks">
<div class="mw-normal-catlinks" id="mw-normal-catlinks">
<a href="/wiki/Special:%E9%A1%B5%E9%9D%A2%E5%88%86%E7%B1%BB" title="Special:页面分类">
分类
</a>
:
<ul>
<li>
<a href="/wiki/Category:%E4%BD%BF%E7%94%A8%E4%BA%BA%E5%8F%A3%E6%A8%A1%E6%9D%BF%E7%9A%84%E9%A0%81%E9%9D%A2" title="Category:使用人口模板的頁面">
使用人口模板的頁面
</a>
</li>
<li>
<a href="/wiki/Category:%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E7%9C%81%E7%B4%9A%E8%A1%8C%E6%94%BF%E5%8D%80" title="Category:中華人民共和國省級行政區">
中華人民共和國省級行政區
</a>
</li>
<li>
<a href="/wiki/Category:%E4%BA%9E%E6%B4%B2%E9%A6%96%E9%83%BD" title="Category:亞洲首都">
亞洲首都
</a>
</li>
<li>
<a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E5%9B%AD%E6%9E%97%E5%9F%8E%E5%B8%82" title="Category:国家园林城市">
国家园林城市
</a>
</li>
<li>
<a href="/wiki/Category:%E4%B8%AD%E8%8F%AF%E4%BA%BA%E6%B0%91%E5%85%B1%E5%92%8C%E5%9C%8B%E7%9B%B4%E8%BD%84%E5%B8%82" title="Category:中華人民共和國直轄市">
中華人民共和國直轄市
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%97%E4%BA%AC%E5%B8%82" title="Category:北京市">
北京市
</a>
</li>
<li>
<a href="/wiki/Category:%E4%B8%AD%E5%9B%BD%E7%89%B9%E5%A4%A7%E5%9F%8E%E5%B8%82" title="Category:中国特大城市">
中国特大城市
</a>
</li>
<li>
<a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E5%8E%86%E5%8F%B2%E6%96%87%E5%8C%96%E5%90%8D%E5%9F%8E" title="Category:国家历史文化名城">
国家历史文化名城
</a>
</li>
<li>
<a href="/wiki/Category:%E4%BA%AC%E6%B4%A5%E5%86%80%E5%9F%8E%E5%B8%82%E7%BE%A4" title="Category:京津冀城市群">
京津冀城市群
</a>
</li>
<li>
<a href="/wiki/Category:%E5%A4%8F%E5%AD%A3%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Category:夏季奥林匹克运动会主办城市">
夏季奥林匹克运动会主办城市
</a>
</li>
<li>
<a href="/wiki/Category:%E4%BA%9A%E6%B4%B2%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B8%BB%E5%8A%9E%E5%9F%8E%E5%B8%82" title="Category:亚洲运动会主办城市">
亚洲运动会主办城市
</a>
</li>
<li>
<a href="/wiki/Category:%E4%B8%AD%E5%9B%BD%E5%8E%86%E4%BB%A3%E5%9B%BD%E9%83%BD" title="Category:中国历代国都">
中国历代国都
</a>
</li>
<li>
<a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Category:国家中心城市">
国家中心城市
</a>
</li>
<li>
<a href="/wiki/Category:%E5%9B%BD%E5%AE%B6%E7%BB%8F%E6%B5%8E%E4%B8%AD%E5%BF%83%E5%9F%8E%E5%B8%82" title="Category:国家经济中心城市">
国家经济中心城市
</a>
</li>
</ul>
</div>
<div class="mw-hidden-catlinks mw-hidden-cats-hidden" id="mw-hidden-catlinks">
隐藏分类:
<ul>
<li>
<a href="/wiki/Category:%E6%9C%89%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE%E9%94%99%E8%AF%AF%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:有参考文献错误的页面">
有参考文献错误的页面
</a>
</li>
<li>
<a href="/wiki/Category:CS1%E8%8B%B1%E8%AF%AD%E6%9D%A5%E6%BA%90_(en)" title="Category:CS1英语来源 (en)">
CS1英语来源 (en)
</a>
</li>
<li>
<a href="/wiki/Category:CS1%E5%90%AB%E6%9C%89%E4%B8%AD%E6%96%87%E6%96%87%E6%9C%AC_(zh)" title="Category:CS1含有中文文本 (zh)">
CS1含有中文文本 (zh)
</a>
</li>
<li>
<a href="/wiki/Category:%E5%BC%95%E6%96%87%E6%A0%BC%E5%BC%8F1%E9%94%99%E8%AF%AF%EF%BC%9A%E6%97%A5%E6%9C%9F" title="Category:引文格式1错误:日期">
引文格式1错误:日期
</a>
</li>
<li>
<a href="/wiki/Category:%E5%90%AB%E6%9C%89%E8%AE%BF%E9%97%AE%E6%97%A5%E6%9C%9F%E4%BD%86%E6%97%A0%E7%BD%91%E5%9D%80%E7%9A%84%E5%BC%95%E7%94%A8%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:含有访问日期但无网址的引用的页面">
含有访问日期但无网址的引用的页面
</a>
</li>
<li>
<a href="/wiki/Category:CS1%E4%BF%84%E8%AF%AD%E6%9D%A5%E6%BA%90_(ru)" title="Category:CS1俄语来源 (ru)">
CS1俄语来源 (ru)
</a>
</li>
<li>
<a href="/wiki/Category:CS1%E7%BE%8E%E5%9B%BD%E8%8B%B1%E8%AF%AD%E6%9D%A5%E6%BA%90_(en-us)" title="Category:CS1美国英语来源 (en-us)">
CS1美国英语来源 (en-us)
</a>
</li>
<li>
<a href="/wiki/Category:%E9%A1%B6%E6%B3%A8%E9%87%8D%E5%AE%9A%E5%90%91%E9%9C%80%E8%A6%81%E5%AE%A1%E9%98%85%E7%9A%84%E6%9D%A1%E7%9B%AE" title="Category:顶注重定向需要审阅的条目">
顶注重定向需要审阅的条目
</a>
</li>
<li>
<a href="/wiki/Category:%E7%BB%B4%E5%9F%BA%E6%95%B0%E6%8D%AE%E5%AD%98%E5%9C%A8%E5%9D%90%E6%A0%87%E6%95%B0%E6%8D%AE%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:维基数据存在坐标数据的页面">
维基数据存在坐标数据的页面
</a>
</li>
<li>
<a href="/wiki/Category:%E4%BD%BF%E7%94%A8%E5%A4%9A%E4%B8%AA%E5%9B%BE%E5%83%8F%E4%B8%94%E8%87%AA%E5%8A%A8%E7%BC%A9%E6%94%BE%E7%9A%84%E9%A1%B5%E9%9D%A2" title="Category:使用多个图像且自动缩放的页面">
使用多个图像且自动缩放的页面
</a>
</li>
<li>
<a href="/wiki/Category:%E5%90%AB%E6%9C%89%E9%9D%9E%E4%B8%AD%E6%96%87%E5%85%A7%E5%AE%B9%E7%9A%84%E6%A2%9D%E7%9B%AE" title="Category:含有非中文內容的條目">
含有非中文內容的條目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%B5%8C%E5%85%A5hAudio%E5%BE%AE%E6%A0%BC%E5%BC%8F%E7%9A%84%E6%A2%9D%E7%9B%AE" title="Category:嵌入hAudio微格式的條目">
嵌入hAudio微格式的條目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABAAT%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含AAT标识符的维基百科条目">
包含AAT标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABBNF%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含BNF标识符的维基百科条目">
包含BNF标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABGND%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含GND标识符的维基百科条目">
包含GND标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABISNI%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含ISNI标识符的维基百科条目">
包含ISNI标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABLCCN%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含LCCN标识符的维基百科条目">
包含LCCN标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABNARA%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NARA标识符的维基百科条目">
包含NARA标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABNDL%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NDL标识符的维基百科条目">
包含NDL标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABNKC%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NKC标识符的维基百科条目">
包含NKC标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABNNL%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含NNL标识符的维基百科条目">
包含NNL标识符的维基百科条目
</a>
</li>
<li>
<a href="/wiki/Category:%E5%8C%85%E5%90%ABVIAF%E6%A0%87%E8%AF%86%E7%AC%A6%E7%9A%84%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E6%9D%A1%E7%9B%AE" title="Category:包含VIAF标识符的维基百科条目">
包含VIAF标识符的维基百科条目
</a>
</li>
</ul>
</div>
</div>
</div>
</div>
<div id="mw-data-after-content">
<div class="read-more-container">
</div>
</div>
<div id="mw-navigation">
<h2>
导航菜单
</h2>
<div id="mw-head">
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-personal-label" class="mw-portlet mw-portlet-personal vector-menu" id="p-personal" role="navigation">
<h3 id="p-personal-label">
<span>
个人工具
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li id="pt-anonuserpage">
没有登录
</li>
<li id="pt-anontalk">
<a accesskey="n" href="/wiki/Special:%E6%88%91%E7%9A%84%E8%AE%A8%E8%AE%BA%E9%A1%B5" title="对于来自此IP地址编辑的讨论[n]">
讨论
</a>
</li>
<li id="pt-anoncontribs">
<a accesskey="y" href="/wiki/Special:%E6%88%91%E7%9A%84%E8%B4%A1%E7%8C%AE" title="来自此IP地址的编辑列表[y]">
贡献
</a>
</li>
<li id="pt-createaccount">
<a href="/w/index.php?title=Special:%E5%88%9B%E5%BB%BA%E8%B4%A6%E6%88%B7&returnto=%E5%8C%97%E4%BA%AC%E5%B8%82" title="建议您创建一个账户并登录,但这不是强制的">
创建账户
</a>
</li>
<li id="pt-login">
<a accesskey="o" href="/w/index.php?title=Special:%E7%94%A8%E6%88%B7%E7%99%BB%E5%BD%95&returnto=%E5%8C%97%E4%BA%AC%E5%B8%82" title="建议你登录,尽管并非必须。[o]">
登录
</a>
</li>
</ul>
</div>
</nav>
<div id="left-navigation">
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-namespaces-label" class="mw-portlet mw-portlet-namespaces vector-menu vector-menu-tabs" id="p-namespaces" role="navigation">
<h3 id="p-namespaces-label">
<span>
名字空间
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li class="selected" id="ca-nstab-main">
<a accesskey="c" href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" title="浏览条目正文[c]">
条目
</a>
</li>
<li id="ca-talk">
<a accesskey="t" href="/wiki/Talk:%E5%8C%97%E4%BA%AC%E5%B8%82" rel="discussion" title="关于此页面的讨论[t]">
讨论
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-variants-label" class="mw-portlet mw-portlet-variants vector-menu vector-menu-dropdown" id="p-variants" role="navigation">
<input aria-labelledby="p-variants-label" class="vector-menu-checkbox" type="checkbox"/>
<h3 id="p-variants-label">
<span>
不转换
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li class="selected" id="ca-varlang-0">
<a href="/zh/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh" lang="zh">
不转换
</a>
</li>
<li id="ca-varlang-1">
<a href="/zh-hans/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans" lang="zh-Hans">
简体
</a>
</li>
<li id="ca-varlang-2">
<a href="/zh-hant/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant" lang="zh-Hant">
繁體
</a>
</li>
<li id="ca-varlang-3">
<a href="/zh-cn/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans-CN" lang="zh-Hans-CN">
大陆简体
</a>
</li>
<li id="ca-varlang-4">
<a href="/zh-hk/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant-HK" lang="zh-Hant-HK">
香港繁體
</a>
</li>
<li id="ca-varlang-5">
<a href="/zh-mo/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant-MO" lang="zh-Hant-MO">
澳門繁體
</a>
</li>
<li id="ca-varlang-6">
<a href="/zh-my/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans-MY" lang="zh-Hans-MY">
大马简体
</a>
</li>
<li id="ca-varlang-7">
<a href="/zh-sg/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hans-SG" lang="zh-Hans-SG">
新加坡简体
</a>
</li>
<li id="ca-varlang-8">
<a href="/zh-tw/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="zh-Hant-TW" lang="zh-Hant-TW">
臺灣正體
</a>
</li>
</ul>
</div>
</nav>
</div>
<div id="right-navigation">
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-views-label" class="mw-portlet mw-portlet-views vector-menu vector-menu-tabs" id="p-views" role="navigation">
<h3 id="p-views-label">
<span>
视图
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li class="selected" id="ca-view">
<a href="/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82">
阅读
</a>
</li>
<li id="ca-edit">
<a accesskey="e" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=edit" title="编辑本页[e]">
编辑
</a>
</li>
<li id="ca-history">
<a accesskey="h" href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=history" title="本页面的早前版本。[h]">
查看历史
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-cactions-label" class="mw-portlet mw-portlet-cactions emptyPortlet vector-menu vector-menu-dropdown" id="p-cactions" role="navigation">
<input aria-labelledby="p-cactions-label" class="vector-menu-checkbox" type="checkbox"/>
<h3 id="p-cactions-label">
<span>
更多
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
</ul>
</div>
</nav>
<div id="p-search" role="search">
<h3>
<label for="searchInput">
搜索
</label>
</h3>
<form action="/w/index.php" id="searchform">
<div data-search-loc="header-navigation" id="simpleSearch">
<input accesskey="f" autocapitalize="sentences" id="searchInput" name="search" placeholder="搜索维基百科" title="搜索维基百科[f]" type="search"/>
<input name="title" type="hidden" value="Special:搜索"/>
<input class="searchButton mw-fallbackSearchButton" id="mw-searchButton" name="fulltext" title="搜索含这些文字的页面" type="submit" value="搜索">
<input class="searchButton" id="searchButton" name="go" title="若相同标题存在,则直接前往该页面" type="submit" value="前往"/>
</input>
</div>
</form>
</div>
</div>
</div>
<div id="mw-panel">
<div id="p-logo" role="banner">
<a class="mw-wiki-logo" href="/wiki/Wikipedia:%E9%A6%96%E9%A1%B5" title="首页">
</a>
</div>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-navigation-label" class="mw-portlet mw-portlet-navigation vector-menu vector-menu-portal portal portal-first" id="p-navigation" role="navigation">
<h3 id="p-navigation-label">
<span>
导航
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li id="n-mainpage-description">
<a accesskey="z" href="/wiki/Wikipedia:%E9%A6%96%E9%A1%B5" title="访问首页[z]">
首页
</a>
</li>
<li id="n-indexpage">
<a href="/wiki/Wikipedia:%E5%88%86%E7%B1%BB%E7%B4%A2%E5%BC%95" title="以分类索引搜寻中文维基百科">
分类索引
</a>
</li>
<li id="n-Featured_content">
<a href="/wiki/Portal:%E7%89%B9%E8%89%B2%E5%85%A7%E5%AE%B9" title="查看中文维基百科的特色内容">
特色内容
</a>
</li>
<li id="n-currentevents">
<a href="/wiki/Portal:%E6%96%B0%E8%81%9E%E5%8B%95%E6%85%8B" title="提供当前新闻事件的背景资料">
新闻动态
</a>
</li>
<li id="n-recentchanges">
<a accesskey="r" href="/wiki/Special:%E6%9C%80%E8%BF%91%E6%9B%B4%E6%94%B9" title="列出维基百科中的最近修改[r]">
最近更改
</a>
</li>
<li id="n-randompage">
<a accesskey="x" href="/wiki/Special:%E9%9A%8F%E6%9C%BA%E9%A1%B5%E9%9D%A2" title="随机载入一个页面[x]">
随机条目
</a>
</li>
<li id="n-sitesupport">
<a href="https://donate.wikimedia.org/?utm_source=donate&utm_medium=sidebar&utm_campaign=spontaneous&uselang=zh-hans" title="如果您在維基百科受益良多,您可以考慮資助我們">
资助维基百科
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-help-label" class="mw-portlet mw-portlet-help vector-menu vector-menu-portal portal" id="p-help" role="navigation">
<h3 id="p-help-label">
<span>
帮助
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li id="n-help">
<a href="/wiki/Help:%E7%9B%AE%E5%BD%95" title="寻求帮助">
帮助
</a>
</li>
<li id="n-portal">
<a href="/wiki/Wikipedia:%E7%A4%BE%E7%BE%A4%E9%A6%96%E9%A1%B5" title="关于本计划、你可以做什么、应该如何做">
维基社群
</a>
</li>
<li id="n-policy">
<a href="/wiki/Wikipedia:%E6%96%B9%E9%87%9D%E8%88%87%E6%8C%87%E5%BC%95" title="查看维基百科的方针和指引">
方针与指引
</a>
</li>
<li id="n-villagepump">
<a href="/wiki/Wikipedia:%E4%BA%92%E5%8A%A9%E5%AE%A2%E6%A0%88" title="参与维基百科社群的讨论">
互助客栈
</a>
</li>
<li id="n-Information_desk">
<a href="/wiki/Wikipedia:%E7%9F%A5%E8%AF%86%E9%97%AE%E7%AD%94" title="解答任何与维基百科无关的问题的地方">
知识问答
</a>
</li>
<li id="n-conversion">
<a href="/wiki/Wikipedia:%E5%AD%97%E8%AF%8D%E8%BD%AC%E6%8D%A2" title="提出字词转换请求">
字词转换
</a>
</li>
<li id="n-IRC">
<a href="/wiki/Wikipedia:IRC%E8%81%8A%E5%A4%A9%E9%A2%91%E9%81%93">
IRC即时聊天
</a>
</li>
<li id="n-contact">
<a href="/wiki/Wikipedia:%E8%81%94%E7%BB%9C%E6%88%91%E4%BB%AC" title="如何联络维基百科">
联络我们
</a>
</li>
<li id="n-about">
<a href="/wiki/Wikipedia:%E5%85%B3%E4%BA%8E" title="查看维基百科的简介">
关于维基百科
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-tb-label" class="mw-portlet mw-portlet-tb vector-menu vector-menu-portal portal" id="p-tb" role="navigation">
<h3 id="p-tb-label">
<span>
工具
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li id="t-whatlinkshere">
<a accesskey="j" href="/wiki/Special:%E9%93%BE%E5%85%A5%E9%A1%B5%E9%9D%A2/%E5%8C%97%E4%BA%AC%E5%B8%82" title="列出所有与本页相链的页面[j]">
链入页面
</a>
</li>
<li id="t-recentchangeslinked">
<a accesskey="k" href="/wiki/Special:%E9%93%BE%E5%87%BA%E6%9B%B4%E6%94%B9/%E5%8C%97%E4%BA%AC%E5%B8%82" rel="nofollow" title="页面链出所有页面的更改[k]">
相关更改
</a>
</li>
<li id="t-upload">
<a accesskey="u" href="/wiki/Project:%E4%B8%8A%E4%BC%A0" title="上传图像或多媒体文件[u]">
上传文件
</a>
</li>
<li id="t-specialpages">
<a accesskey="q" href="/wiki/Special:%E7%89%B9%E6%AE%8A%E9%A1%B5%E9%9D%A2" title="全部特殊页面的列表[q]">
特殊页面
</a>
</li>
<li id="t-permalink">
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&oldid=63604485" title="本页面该版本的固定链接">
固定链接
</a>
</li>
<li id="t-info">
<a href="/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&action=info" title="关于此页面的更多信息">
页面信息
</a>
</li>
<li id="t-cite">
<a href="/w/index.php?title=Special:%E5%BC%95%E7%94%A8%E6%AD%A4%E9%A1%B5%E9%9D%A2&page=%E5%8C%97%E4%BA%AC%E5%B8%82&id=63604485&wpFormIdentifier=titleform" title="关于如何引用本页的信息">
引用本页
</a>
</li>
<li id="t-wikibase">
<a accesskey="g" href="https://www.wikidata.org/wiki/Special:EntityPage/Q956" title="查看连接的数据存储库项[g]">
维基数据项
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-electronpdfservice-sidebar-portlet-heading-label" class="mw-portlet mw-portlet-electronpdfservice-sidebar-portlet-heading vector-menu vector-menu-portal portal" id="p-electronpdfservice-sidebar-portlet-heading" role="navigation">
<h3 id="p-electronpdfservice-sidebar-portlet-heading-label">
<span>
打印/导出
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li id="electron-print_pdf">
<a href="/w/index.php?title=Special:DownloadAsPdf&page=%E5%8C%97%E4%BA%AC%E5%B8%82&action=show-download-screen">
下载为PDF
</a>
</li>
<li id="t-print">
<a accesskey="p" href="javascript:print();" rel="alternate" title="本页面的可打印版本[p]">
打印页面
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-wikibase-otherprojects-label" class="mw-portlet mw-portlet-wikibase-otherprojects vector-menu vector-menu-portal portal" id="p-wikibase-otherprojects" role="navigation">
<h3 id="p-wikibase-otherprojects-label">
<span>
在其他项目中
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li class="wb-otherproject-link wb-otherproject-commons">
<a href="https://commons.wikimedia.org/wiki/Category:Beijing" hreflang="en">
维基共享资源
</a>
</li>
<li class="wb-otherproject-link wb-otherproject-wikinews">
<a href="https://zh.wikinews.org/wiki/Category:%E5%8C%97%E4%BA%AC" hreflang="zh">
维基新闻
</a>
</li>
<li class="wb-otherproject-link wb-otherproject-wikiquote">
<a href="https://zh.wikiquote.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="zh">
维基语录
</a>
</li>
<li class="wb-otherproject-link wb-otherproject-wikivoyage">
<a href="https://zh.wikivoyage.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="zh">
维基导游
</a>
</li>
</ul>
</div>
</nav>
<!-- Please do not use role attribute as CSS selector, it is deprecated. -->
<nav aria-labelledby="p-lang-label" class="mw-portlet mw-portlet-lang vector-menu vector-menu-portal portal" id="p-lang" role="navigation">
<h3 id="p-lang-label">
<span>
其他语言
</span>
</h3>
<div class="vector-menu-content">
<ul class="vector-menu-content-list">
<li class="interlanguage-link interwiki-ace">
<a class="interlanguage-link-target" href="https://ace.wikipedia.org/wiki/Beijing" hreflang="ace" lang="ace" title="Beijing – 亚齐语">
Acèh
</a>
</li>
<li class="interlanguage-link interwiki-ady">
<a class="interlanguage-link-target" href="https://ady.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="ady" lang="ady" title="Пекин – 阿迪格语">
Адыгабзэ
</a>
</li>
<li class="interlanguage-link interwiki-af">
<a class="interlanguage-link-target" href="https://af.wikipedia.org/wiki/Beijing" hreflang="af" lang="af" title="Beijing – 南非荷兰语">
Afrikaans
</a>
</li>
<li class="interlanguage-link interwiki-als">
<a class="interlanguage-link-target" href="https://als.wikipedia.org/wiki/Peking" hreflang="gsw" lang="gsw" title="Peking – Alemannisch">
Alemannisch
</a>
</li>
<li class="interlanguage-link interwiki-am">
<a class="interlanguage-link-target" href="https://am.wikipedia.org/wiki/%E1%89%A4%E1%8B%AA%E1%8C%82%E1%8A%95%E1%8C%8D" hreflang="am" lang="am" title="ቤዪጂንግ – 阿姆哈拉语">
አማርኛ
</a>
</li>
<li class="interlanguage-link interwiki-an">
<a class="interlanguage-link-target" href="https://an.wikipedia.org/wiki/Pequ%C3%ADn" hreflang="an" lang="an" title="Pequín – 阿拉贡语">
Aragonés
</a>
</li>
<li class="interlanguage-link interwiki-ang">
<a class="interlanguage-link-target" href="https://ang.wikipedia.org/wiki/Pecing" hreflang="ang" lang="ang" title="Pecing – 古英语">
Ænglisc
</a>
</li>
<li class="interlanguage-link interwiki-ar">
<a class="interlanguage-link-target" href="https://ar.wikipedia.org/wiki/%D8%A8%D9%83%D9%8A%D9%86" hreflang="ar" lang="ar" title="بكين – 阿拉伯语">
العربية
</a>
</li>
<li class="interlanguage-link interwiki-ary">
<a class="interlanguage-link-target" href="https://ary.wikipedia.org/wiki/%D9%BE%D9%8A%D9%83%D9%8A%D9%86" hreflang="ary" lang="ary" title="پيكين – Moroccan Arabic">
الدارجة
</a>
</li>
<li class="interlanguage-link interwiki-arz">
<a class="interlanguage-link-target" href="https://arz.wikipedia.org/wiki/%D8%A8%D9%8A%D9%83%D9%8A%D9%86" hreflang="arz" lang="arz" title="بيكين – Egyptian Arabic">
مصرى
</a>
</li>
<li class="interlanguage-link interwiki-as">
<a class="interlanguage-link-target" href="https://as.wikipedia.org/wiki/%E0%A6%AC%E0%A7%87%E0%A6%87%E0%A6%9C%E0%A6%BF%E0%A6%82" hreflang="as" lang="as" title="বেইজিং – 阿萨姆语">
অসমীয়া
</a>
</li>
<li class="interlanguage-link interwiki-ast">
<a class="interlanguage-link-target" href="https://ast.wikipedia.org/wiki/Beix%C3%ADn" hreflang="ast" lang="ast" title="Beixín – 阿斯图里亚斯语">
Asturianu
</a>
</li>
<li class="interlanguage-link interwiki-awa">
<a class="interlanguage-link-target" href="https://awa.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99%E0%A5%8D" hreflang="awa" lang="awa" title="बेइजिङ् – 阿瓦德语">
अवधी
</a>
</li>
<li class="interlanguage-link interwiki-ay">
<a class="interlanguage-link-target" href="https://ay.wikipedia.org/wiki/Pekin" hreflang="ay" lang="ay" title="Pekin – 艾马拉语">
Aymar aru
</a>
</li>
<li class="interlanguage-link interwiki-az">
<a class="interlanguage-link-target" href="https://az.wikipedia.org/wiki/Pekin" hreflang="az" lang="az" title="Pekin – 阿塞拜疆语">
Azərbaycanca
</a>
</li>
<li class="interlanguage-link interwiki-azb">
<a class="interlanguage-link-target" href="https://azb.wikipedia.org/wiki/%D9%BE%DA%A9%D9%86" hreflang="azb" lang="azb" title="پکن – South Azerbaijani">
تۆرکجه
</a>
</li>
<li class="interlanguage-link interwiki-ba">
<a class="interlanguage-link-target" href="https://ba.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="ba" lang="ba" title="Пекин – 巴什基尔语">
Башҡортса
</a>
</li>
<li class="interlanguage-link interwiki-bar">
<a class="interlanguage-link-target" href="https://bar.wikipedia.org/wiki/Peking" hreflang="bar" lang="bar" title="Peking – Bavarian">
Boarisch
</a>
</li>
<li class="interlanguage-link interwiki-bat-smg">
<a class="interlanguage-link-target" href="https://bat-smg.wikipedia.org/wiki/Pek%C4%97ns" hreflang="sgs" lang="sgs" title="Pekėns – Samogitian">
Žemaitėška
</a>
</li>
<li class="interlanguage-link interwiki-bcl">
<a class="interlanguage-link-target" href="https://bcl.wikipedia.org/wiki/Pekin" hreflang="bcl" lang="bcl" title="Pekin – Central Bikol">
Bikol Central
</a>
</li>
<li class="interlanguage-link interwiki-be">
<a class="interlanguage-link-target" href="https://be.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D1%96%D0%BD" hreflang="be" lang="be" title="Пекін – 白俄罗斯语">
Беларуская
</a>
</li>
<li class="interlanguage-link interwiki-be-x-old">
<a class="interlanguage-link-target" href="https://be-tarask.wikipedia.org/wiki/%D0%9F%D1%8D%D0%BA%D1%96%D0%BD" hreflang="be-tarask" lang="be-tarask" title="Пэкін – Belarusian (Taraškievica orthography)">
Беларуская (тарашкевіца)
</a>
</li>
<li class="interlanguage-link interwiki-bg">
<a class="interlanguage-link-target" href="https://bg.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="bg" lang="bg" title="Пекин – 保加利亚语">
Български
</a>
</li>
<li class="interlanguage-link interwiki-bh">
<a class="interlanguage-link-target" href="https://bh.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%82%E0%A4%97" hreflang="bh" lang="bh" title="बीजिंग – Bhojpuri">
भोजपुरी
</a>
</li>
<li class="interlanguage-link interwiki-bi">
<a class="interlanguage-link-target" href="https://bi.wikipedia.org/wiki/Beijing" hreflang="bi" lang="bi" title="Beijing – 比斯拉马语">
Bislama
</a>
</li>
<li class="interlanguage-link interwiki-bjn">
<a class="interlanguage-link-target" href="https://bjn.wikipedia.org/wiki/P%C3%A9ycing" hreflang="bjn" lang="bjn" title="Péycing – Banjar">
Banjar
</a>
</li>
<li class="interlanguage-link interwiki-bm">
<a class="interlanguage-link-target" href="https://bm.wikipedia.org/wiki/Beijing" hreflang="bm" lang="bm" title="Beijing – 班巴拉语">
Bamanankan
</a>
</li>
<li class="interlanguage-link interwiki-bn">
<a class="interlanguage-link-target" href="https://bn.wikipedia.org/wiki/%E0%A6%AC%E0%A7%87%E0%A6%87%E0%A6%9C%E0%A6%BF%E0%A6%82" hreflang="bn" lang="bn" title="বেইজিং – 孟加拉语">
বাংলা
</a>
</li>
<li class="interlanguage-link interwiki-bo">
<a class="interlanguage-link-target" href="https://bo.wikipedia.org/wiki/%E0%BD%94%E0%BD%BA%E0%BC%8B%E0%BD%85%E0%BD%B2%E0%BD%84%E0%BC%8B%E0%BD%82%E0%BE%B2%E0%BD%BC%E0%BD%84%E0%BC%8B%E0%BD%81%E0%BE%B1%E0%BD%BA%E0%BD%A2%E0%BC%8D" hreflang="bo" lang="bo" title="པེ་ཅིང་གྲོང་ཁྱེར། – 藏语">
བོད་ཡིག
</a>
</li>
<li class="interlanguage-link interwiki-bpy">
<a class="interlanguage-link-target" href="https://bpy.wikipedia.org/wiki/%E0%A6%AC%E0%A7%87%E0%A6%87%E0%A6%9C%E0%A6%BF%E0%A6%82" hreflang="bpy" lang="bpy" title="বেইজিং – Bishnupriya">
বিষ্ণুপ্রিয়া মণিপুরী
</a>
</li>
<li class="interlanguage-link interwiki-br">
<a class="interlanguage-link-target" href="https://br.wikipedia.org/wiki/Beijing" hreflang="br" lang="br" title="Beijing – 布列塔尼语">
Brezhoneg
</a>
</li>
<li class="interlanguage-link interwiki-bs">
<a class="interlanguage-link-target" href="https://bs.wikipedia.org/wiki/Peking" hreflang="bs" lang="bs" title="Peking – 波斯尼亚语">
Bosanski
</a>
</li>
<li class="interlanguage-link interwiki-bxr">
<a class="interlanguage-link-target" href="https://bxr.wikipedia.org/wiki/%D0%91%D1%8D%D1%8D%D0%B6%D1%8D%D0%BD" hreflang="bxr" lang="bxr" title="Бээжэн – Russia Buriat">
Буряад
</a>
</li>
<li class="interlanguage-link interwiki-ca">
<a class="interlanguage-link-target" href="https://ca.wikipedia.org/wiki/Pequ%C3%ADn" hreflang="ca" lang="ca" title="Pequín – 加泰罗尼亚语">
Català
</a>
</li>
<li class="interlanguage-link interwiki-cbk-zam">
<a class="interlanguage-link-target" href="https://cbk-zam.wikipedia.org/wiki/Pek%C3%ADn" hreflang="cbk" lang="cbk" title="Pekín – Chavacano">
Chavacano de Zamboanga
</a>
</li>
<li class="interlanguage-link interwiki-cdo">
<a class="interlanguage-link-target" href="https://cdo.wikipedia.org/wiki/B%C3%A1e%CC%A4k-g%C4%ADng" hreflang="cdo" lang="cdo" title="Báe̤k-gĭng – Min Dong Chinese">
Mìng-dĕ̤ng-ngṳ̄
</a>
</li>
<li class="interlanguage-link interwiki-ce">
<a class="interlanguage-link-target" href="https://ce.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="ce" lang="ce" title="Пекин – 车臣语">
Нохчийн
</a>
</li>
<li class="interlanguage-link interwiki-ceb">
<a class="interlanguage-link-target" href="https://ceb.wikipedia.org/wiki/Pekin" hreflang="ceb" lang="ceb" title="Pekin – 宿务语">
Cebuano
</a>
</li>
<li class="interlanguage-link interwiki-ch">
<a class="interlanguage-link-target" href="https://ch.wikipedia.org/wiki/Beijing" hreflang="ch" lang="ch" title="Beijing – 查莫罗语">
Chamoru
</a>
</li>
<li class="interlanguage-link interwiki-chy">
<a class="interlanguage-link-target" href="https://chy.wikipedia.org/wiki/Beijing" hreflang="chy" lang="chy" title="Beijing – 夏延语">
Tsetsêhestâhese
</a>
</li>
<li class="interlanguage-link interwiki-ckb">
<a class="interlanguage-link-target" href="https://ckb.wikipedia.org/wiki/%D9%BE%DB%8E%DA%A9%DB%95%D9%86" hreflang="ckb" lang="ckb" title="پێکەن – 中库尔德语">
کوردی
</a>
</li>
<li class="interlanguage-link interwiki-crh">
<a class="interlanguage-link-target" href="https://crh.wikipedia.org/wiki/Pekin" hreflang="crh" lang="crh" title="Pekin – 克里米亚土耳其语">
Qırımtatarca
</a>
</li>
<li class="interlanguage-link interwiki-cs">
<a class="interlanguage-link-target" href="https://cs.wikipedia.org/wiki/Peking" hreflang="cs" lang="cs" title="Peking – 捷克语">
Čeština
</a>
</li>
<li class="interlanguage-link interwiki-cv">
<a class="interlanguage-link-target" href="https://cv.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="cv" lang="cv" title="Пекин – 楚瓦什语">
Чӑвашла
</a>
</li>
<li class="interlanguage-link interwiki-cy">
<a class="interlanguage-link-target" href="https://cy.wikipedia.org/wiki/Beijing" hreflang="cy" lang="cy" title="Beijing – 威尔士语">
Cymraeg
</a>
</li>
<li class="interlanguage-link interwiki-da">
<a class="interlanguage-link-target" href="https://da.wikipedia.org/wiki/Beijing" hreflang="da" lang="da" title="Beijing – 丹麦语">
Dansk
</a>
</li>
<li class="interlanguage-link interwiki-de badge-Q17437796 badge-featuredarticle" title="典范条目">
<a class="interlanguage-link-target" href="https://de.wikipedia.org/wiki/Peking" hreflang="de" lang="de" title="Peking – 德语">
Deutsch
</a>
</li>
<li class="interlanguage-link interwiki-diq">
<a class="interlanguage-link-target" href="https://diq.wikipedia.org/wiki/Pekin" hreflang="diq" lang="diq" title="Pekin – Zazaki">
Zazaki
</a>
</li>
<li class="interlanguage-link interwiki-dsb">
<a class="interlanguage-link-target" href="https://dsb.wikipedia.org/wiki/Peking" hreflang="dsb" lang="dsb" title="Peking – 下索布语">
Dolnoserbski
</a>
</li>
<li class="interlanguage-link interwiki-dty">
<a class="interlanguage-link-target" href="https://dty.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" hreflang="dty" lang="dty" title="बेइजिङ – Doteli">
डोटेली
</a>
</li>
<li class="interlanguage-link interwiki-dv">
<a class="interlanguage-link-target" href="https://dv.wikipedia.org/wiki/%DE%84%DE%A9%DE%96%DE%A8%DE%82%DE%B0%DE%8E" hreflang="dv" lang="dv" title="ބީޖިންގ – 迪维希语">
ދިވެހިބަސް
</a>
</li>
<li class="interlanguage-link interwiki-ee">
<a class="interlanguage-link-target" href="https://ee.wikipedia.org/wiki/Beijing" hreflang="ee" lang="ee" title="Beijing – 埃维语">
Eʋegbe
</a>
</li>
<li class="interlanguage-link interwiki-el">
<a class="interlanguage-link-target" href="https://el.wikipedia.org/wiki/%CE%A0%CE%B5%CE%BA%CE%AF%CE%BD%CE%BF" hreflang="el" lang="el" title="Πεκίνο – 希腊语">
Ελληνικά
</a>
</li>
<li class="interlanguage-link interwiki-en">
<a class="interlanguage-link-target" href="https://en.wikipedia.org/wiki/Beijing" hreflang="en" lang="en" title="Beijing – 英语">
English
</a>
</li>
<li class="interlanguage-link interwiki-eo">
<a class="interlanguage-link-target" href="https://eo.wikipedia.org/wiki/Pekino" hreflang="eo" lang="eo" title="Pekino – 世界语">
Esperanto
</a>
</li>
<li class="interlanguage-link interwiki-es">
<a class="interlanguage-link-target" href="https://es.wikipedia.org/wiki/Pek%C3%ADn" hreflang="es" lang="es" title="Pekín – 西班牙语">
Español
</a>
</li>
<li class="interlanguage-link interwiki-et">
<a class="interlanguage-link-target" href="https://et.wikipedia.org/wiki/Peking" hreflang="et" lang="et" title="Peking – 爱沙尼亚语">
Eesti
</a>
</li>
<li class="interlanguage-link interwiki-eu">
<a class="interlanguage-link-target" href="https://eu.wikipedia.org/wiki/Pekin" hreflang="eu" lang="eu" title="Pekin – 巴斯克语">
Euskara
</a>
</li>
<li class="interlanguage-link interwiki-ext">
<a class="interlanguage-link-target" href="https://ext.wikipedia.org/wiki/Pequ%C3%ADn" hreflang="ext" lang="ext" title="Pequín – Extremaduran">
Estremeñu
</a>
</li>
<li class="interlanguage-link interwiki-fa">
<a class="interlanguage-link-target" href="https://fa.wikipedia.org/wiki/%D9%BE%DA%A9%D9%86" hreflang="fa" lang="fa" title="پکن – 波斯语">
فارسی
</a>
</li>
<li class="interlanguage-link interwiki-fi badge-Q17559452 badge-recommendedarticle" title="推荐条目">
<a class="interlanguage-link-target" href="https://fi.wikipedia.org/wiki/Peking" hreflang="fi" lang="fi" title="Peking – 芬兰语">
Suomi
</a>
</li>
<li class="interlanguage-link interwiki-fiu-vro">
<a class="interlanguage-link-target" href="https://fiu-vro.wikipedia.org/wiki/Peking" hreflang="vro" lang="vro" title="Peking – võro">
Võro
</a>
</li>
<li class="interlanguage-link interwiki-fj">
<a class="interlanguage-link-target" href="https://fj.wikipedia.org/wiki/Beijig" hreflang="fj" lang="fj" title="Beijig – 斐济语">
Na Vosa Vakaviti
</a>
</li>
<li class="interlanguage-link interwiki-fo">
<a class="interlanguage-link-target" href="https://fo.wikipedia.org/wiki/Beijing" hreflang="fo" lang="fo" title="Beijing – 法罗语">
Føroyskt
</a>
</li>
<li class="interlanguage-link interwiki-fr badge-Q17437798 badge-goodarticle" title="优良条目">
<a class="interlanguage-link-target" href="https://fr.wikipedia.org/wiki/P%C3%A9kin" hreflang="fr" lang="fr" title="Pékin – 法语">
Français
</a>
</li>
<li class="interlanguage-link interwiki-frp">
<a class="interlanguage-link-target" href="https://frp.wikipedia.org/wiki/P%C3%A8quin" hreflang="frp" lang="frp" title="Pèquin – Arpitan">
Arpetan
</a>
</li>
<li class="interlanguage-link interwiki-frr">
<a class="interlanguage-link-target" href="https://frr.wikipedia.org/wiki/Peking" hreflang="frr" lang="frr" title="Peking – 北弗里西亚语">
Nordfriisk
</a>
</li>
<li class="interlanguage-link interwiki-fy">
<a class="interlanguage-link-target" href="https://fy.wikipedia.org/wiki/Peking" hreflang="fy" lang="fy" title="Peking – 西弗里西亚语">
Frysk
</a>
</li>
<li class="interlanguage-link interwiki-ga">
<a class="interlanguage-link-target" href="https://ga.wikipedia.org/wiki/B%C3%A9ising" hreflang="ga" lang="ga" title="Béising – 爱尔兰语">
Gaeilge
</a>
</li>
<li class="interlanguage-link interwiki-gan">
<a class="interlanguage-link-target" href="https://gan.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="gan" lang="gan" title="北京 – 赣语">
贛語
</a>
</li>
<li class="interlanguage-link interwiki-gcr">
<a class="interlanguage-link-target" href="https://gcr.wikipedia.org/wiki/P%C3%A9ken" hreflang="gcr" lang="gcr" title="Péken – Guianan Creole">
Kriyòl gwiyannen
</a>
</li>
<li class="interlanguage-link interwiki-gd">
<a class="interlanguage-link-target" href="https://gd.wikipedia.org/wiki/Beijing" hreflang="gd" lang="gd" title="Beijing – 苏格兰盖尔语">
Gàidhlig
</a>
</li>
<li class="interlanguage-link interwiki-gl">
<a class="interlanguage-link-target" href="https://gl.wikipedia.org/wiki/Pequ%C3%ADn" hreflang="gl" lang="gl" title="Pequín – 加利西亚语">
Galego
</a>
</li>
<li class="interlanguage-link interwiki-gn">
<a class="interlanguage-link-target" href="https://gn.wikipedia.org/wiki/Pek%C4%A9" hreflang="gn" lang="gn" title="Pekĩ – 瓜拉尼语">
Avañe'ẽ
</a>
</li>
<li class="interlanguage-link interwiki-gu">
<a class="interlanguage-link-target" href="https://gu.wikipedia.org/wiki/%E0%AA%AA%E0%AB%87%E0%AA%87%E0%AA%9A%E0%AA%BF%E0%AA%82%E0%AA%97" hreflang="gu" lang="gu" title="પેઇચિંગ – 古吉拉特语">
ગુજરાતી
</a>
</li>
<li class="interlanguage-link interwiki-gv">
<a class="interlanguage-link-target" href="https://gv.wikipedia.org/wiki/Beijing" hreflang="gv" lang="gv" title="Beijing – 马恩语">
Gaelg
</a>
</li>
<li class="interlanguage-link interwiki-ha">
<a class="interlanguage-link-target" href="https://ha.wikipedia.org/wiki/Beijing" hreflang="ha" lang="ha" title="Beijing – 豪萨语">
Hausa
</a>
</li>
<li class="interlanguage-link interwiki-hak">
<a class="interlanguage-link-target" href="https://hak.wikipedia.org/wiki/Pet-k%C3%AEn" hreflang="hak" lang="hak" title="Pet-kîn – 客家语">
客家語/Hak-kâ-ngî
</a>
</li>
<li class="interlanguage-link interwiki-haw">
<a class="interlanguage-link-target" href="https://haw.wikipedia.org/wiki/Beijing" hreflang="haw" lang="haw" title="Beijing – 夏威夷语">
Hawaiʻi
</a>
</li>
<li class="interlanguage-link interwiki-he">
<a class="interlanguage-link-target" href="https://he.wikipedia.org/wiki/%D7%91%D7%99%D7%99%D7%92%27%D7%99%D7%A0%D7%92" hreflang="he" lang="he" title="בייג'ינג – 希伯来语">
עברית
</a>
</li>
<li class="interlanguage-link interwiki-hi">
<a class="interlanguage-link-target" href="https://hi.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%82%E0%A4%97" hreflang="hi" lang="hi" title="बीजिंग – 印地语">
हिन्दी
</a>
</li>
<li class="interlanguage-link interwiki-hif">
<a class="interlanguage-link-target" href="https://hif.wikipedia.org/wiki/Beijing" hreflang="hif" lang="hif" title="Beijing – Fiji Hindi">
Fiji Hindi
</a>
</li>
<li class="interlanguage-link interwiki-hr">
<a class="interlanguage-link-target" href="https://hr.wikipedia.org/wiki/Peking" hreflang="hr" lang="hr" title="Peking – 克罗地亚语">
Hrvatski
</a>
</li>
<li class="interlanguage-link interwiki-hsb">
<a class="interlanguage-link-target" href="https://hsb.wikipedia.org/wiki/Peking" hreflang="hsb" lang="hsb" title="Peking – 上索布语">
Hornjoserbsce
</a>
</li>
<li class="interlanguage-link interwiki-ht">
<a class="interlanguage-link-target" href="https://ht.wikipedia.org/wiki/Peken" hreflang="ht" lang="ht" title="Peken – 海地克里奥尔语">
Kreyòl ayisyen
</a>
</li>
<li class="interlanguage-link interwiki-hu badge-Q17437796 badge-featuredarticle" title="典范条目">
<a class="interlanguage-link-target" href="https://hu.wikipedia.org/wiki/Peking" hreflang="hu" lang="hu" title="Peking – 匈牙利语">
Magyar
</a>
</li>
<li class="interlanguage-link interwiki-hy">
<a class="interlanguage-link-target" href="https://hy.wikipedia.org/wiki/%D5%8A%D5%A5%D5%AF%D5%AB%D5%B6" hreflang="hy" lang="hy" title="Պեկին – 亚美尼亚语">
Հայերեն
</a>
</li>
<li class="interlanguage-link interwiki-ia">
<a class="interlanguage-link-target" href="https://ia.wikipedia.org/wiki/Beijing" hreflang="ia" lang="ia" title="Beijing – 国际语">
Interlingua
</a>
</li>
<li class="interlanguage-link interwiki-id">
<a class="interlanguage-link-target" href="https://id.wikipedia.org/wiki/Beijing" hreflang="id" lang="id" title="Beijing – 印度尼西亚语">
Bahasa Indonesia
</a>
</li>
<li class="interlanguage-link interwiki-ie">
<a class="interlanguage-link-target" href="https://ie.wikipedia.org/wiki/Beijing" hreflang="ie" lang="ie" title="Beijing – 国际文字(E)">
Interlingue
</a>
</li>
<li class="interlanguage-link interwiki-ilo">
<a class="interlanguage-link-target" href="https://ilo.wikipedia.org/wiki/Beijing" hreflang="ilo" lang="ilo" title="Beijing – 伊洛卡诺语">
Ilokano
</a>
</li>
<li class="interlanguage-link interwiki-inh">
<a class="interlanguage-link-target" href="https://inh.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="inh" lang="inh" title="Пекин – 印古什语">
ГӀалгӀай
</a>
</li>
<li class="interlanguage-link interwiki-io">
<a class="interlanguage-link-target" href="https://io.wikipedia.org/wiki/Beijing" hreflang="io" lang="io" title="Beijing – 伊多语">
Ido
</a>
</li>
<li class="interlanguage-link interwiki-is">
<a class="interlanguage-link-target" href="https://is.wikipedia.org/wiki/Beijing" hreflang="is" lang="is" title="Beijing – 冰岛语">
Íslenska
</a>
</li>
<li class="interlanguage-link interwiki-it">
<a class="interlanguage-link-target" href="https://it.wikipedia.org/wiki/Pechino" hreflang="it" lang="it" title="Pechino – 意大利语">
Italiano
</a>
</li>
<li class="interlanguage-link interwiki-ja">
<a class="interlanguage-link-target" href="https://ja.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="ja" lang="ja" title="北京市 – 日语">
日本語
</a>
</li>
<li class="interlanguage-link interwiki-jam">
<a class="interlanguage-link-target" href="https://jam.wikipedia.org/wiki/Biejing" hreflang="jam" lang="jam" title="Biejing – Jamaican Creole English">
Patois
</a>
</li>
<li class="interlanguage-link interwiki-jbo">
<a class="interlanguage-link-target" href="https://jbo.wikipedia.org/wiki/beidjin" hreflang="jbo" lang="jbo" title="beidjin – 逻辑语">
La .lojban.
</a>
</li>
<li class="interlanguage-link interwiki-jv">
<a class="interlanguage-link-target" href="https://jv.wikipedia.org/wiki/Beijing" hreflang="jv" lang="jv" title="Beijing – 爪哇语">
Jawa
</a>
</li>
<li class="interlanguage-link interwiki-ka">
<a class="interlanguage-link-target" href="https://ka.wikipedia.org/wiki/%E1%83%9E%E1%83%94%E1%83%99%E1%83%98%E1%83%9C%E1%83%98" hreflang="ka" lang="ka" title="პეკინი – 格鲁吉亚语">
ქართული
</a>
</li>
<li class="interlanguage-link interwiki-kaa">
<a class="interlanguage-link-target" href="https://kaa.wikipedia.org/wiki/Pekin" hreflang="kaa" lang="kaa" title="Pekin – 卡拉卡尔帕克语">
Qaraqalpaqsha
</a>
</li>
<li class="interlanguage-link interwiki-kab">
<a class="interlanguage-link-target" href="https://kab.wikipedia.org/wiki/Pekin" hreflang="kab" lang="kab" title="Pekin – 卡拜尔语">
Taqbaylit
</a>
</li>
<li class="interlanguage-link interwiki-kbp">
<a class="interlanguage-link-target" href="https://kbp.wikipedia.org/wiki/Peek%C9%9B%C9%9B" hreflang="kbp" lang="kbp" title="Peekɛɛ – Kabiye">
Kabɩyɛ
</a>
</li>
<li class="interlanguage-link interwiki-kg">
<a class="interlanguage-link-target" href="https://kg.wikipedia.org/wiki/Beijing_(kizunga)" hreflang="kg" lang="kg" title="Beijing (kizunga) – 刚果语">
Kongo
</a>
</li>
<li class="interlanguage-link interwiki-ki">
<a class="interlanguage-link-target" href="https://ki.wikipedia.org/wiki/Beijing" hreflang="ki" lang="ki" title="Beijing – 吉库尤语">
Gĩkũyũ
</a>
</li>
<li class="interlanguage-link interwiki-kk">
<a class="interlanguage-link-target" href="https://kk.wikipedia.org/wiki/%D0%91%D0%B5%D0%B9%D0%B6%D1%96%D2%A3" hreflang="kk" lang="kk" title="Бейжің – 哈萨克语">
Қазақша
</a>
</li>
<li class="interlanguage-link interwiki-km">
<a class="interlanguage-link-target" href="https://km.wikipedia.org/wiki/%E1%9E%94%E1%9F%89%E1%9F%81%E1%9E%80%E1%9E%B6%E1%9F%86%E1%9E%84" hreflang="km" lang="km" title="ប៉េកាំង – 高棉语">
ភាសាខ្មែរ
</a>
</li>
<li class="interlanguage-link interwiki-kn">
<a class="interlanguage-link-target" href="https://kn.wikipedia.org/wiki/%E0%B2%AC%E0%B3%80%E0%B2%9C%E0%B2%BF%E0%B2%82%E0%B2%97%E0%B3%8D" hreflang="kn" lang="kn" title="ಬೀಜಿಂಗ್ – 卡纳达语">
ಕನ್ನಡ
</a>
</li>
<li class="interlanguage-link interwiki-ko">
<a class="interlanguage-link-target" href="https://ko.wikipedia.org/wiki/%EB%B2%A0%EC%9D%B4%EC%A7%95%EC%8B%9C" hreflang="ko" lang="ko" title="베이징시 – 韩语">
한국어
</a>
</li>
<li class="interlanguage-link interwiki-ku">
<a class="interlanguage-link-target" href="https://ku.wikipedia.org/wiki/Beijing" hreflang="ku" lang="ku" title="Beijing – 库尔德语">
Kurdî
</a>
</li>
<li class="interlanguage-link interwiki-kv">
<a class="interlanguage-link-target" href="https://kv.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="kv" lang="kv" title="Пекин – 科米语">
Коми
</a>
</li>
<li class="interlanguage-link interwiki-kw">
<a class="interlanguage-link-target" href="https://kw.wikipedia.org/wiki/Beijing" hreflang="kw" lang="kw" title="Beijing – 康沃尔语">
Kernowek
</a>
</li>
<li class="interlanguage-link interwiki-ky">
<a class="interlanguage-link-target" href="https://ky.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="ky" lang="ky" title="Пекин – 柯尔克孜语">
Кыргызча
</a>
</li>
<li class="interlanguage-link interwiki-la">
<a class="interlanguage-link-target" href="https://la.wikipedia.org/wiki/Pechinum" hreflang="la" lang="la" title="Pechinum – 拉丁语">
Latina
</a>
</li>
<li class="interlanguage-link interwiki-lad">
<a class="interlanguage-link-target" href="https://lad.wikipedia.org/wiki/Peking" hreflang="lad" lang="lad" title="Peking – 拉迪诺语">
Ladino
</a>
</li>
<li class="interlanguage-link interwiki-lb">
<a class="interlanguage-link-target" href="https://lb.wikipedia.org/wiki/Peking" hreflang="lb" lang="lb" title="Peking – 卢森堡语">
Lëtzebuergesch
</a>
</li>
<li class="interlanguage-link interwiki-lez">
<a class="interlanguage-link-target" href="https://lez.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="lez" lang="lez" title="Пекин – 列兹金语">
Лезги
</a>
</li>
<li class="interlanguage-link interwiki-li">
<a class="interlanguage-link-target" href="https://li.wikipedia.org/wiki/Peking" hreflang="li" lang="li" title="Peking – 林堡语">
Limburgs
</a>
</li>
<li class="interlanguage-link interwiki-lij">
<a class="interlanguage-link-target" href="https://lij.wikipedia.org/wiki/Pechin" hreflang="lij" lang="lij" title="Pechin – Ligurian">
Ligure
</a>
</li>
<li class="interlanguage-link interwiki-lld">
<a class="interlanguage-link-target" href="https://lld.wikipedia.org/wiki/Beijing" hreflang="lld" lang="lld" title="Beijing – Ladin">
Ladin
</a>
</li>
<li class="interlanguage-link interwiki-lmo">
<a class="interlanguage-link-target" href="https://lmo.wikipedia.org/wiki/Pechin" hreflang="lmo" lang="lmo" title="Pechin – Lombard">
Lumbaart
</a>
</li>
<li class="interlanguage-link interwiki-ln">
<a class="interlanguage-link-target" href="https://ln.wikipedia.org/wiki/Beij%C3%ADng" hreflang="ln" lang="ln" title="Beijíng – 林加拉语">
Lingála
</a>
</li>
<li class="interlanguage-link interwiki-lo">
<a class="interlanguage-link-target" href="https://lo.wikipedia.org/wiki/%E0%BA%9B%E0%BA%B1%E0%BA%81%E0%BA%81%E0%BA%B4%E0%BB%88%E0%BA%87" hreflang="lo" lang="lo" title="ປັກກິ່ງ – 老挝语">
ລາວ
</a>
</li>
<li class="interlanguage-link interwiki-lrc">
<a class="interlanguage-link-target" href="https://lrc.wikipedia.org/wiki/%D9%BE%DA%A9%D9%B1%D9%86" hreflang="lrc" lang="lrc" title="پکٱن – 北卢尔语">
لۊری شومالی
</a>
</li>
<li class="interlanguage-link interwiki-lt">
<a class="interlanguage-link-target" href="https://lt.wikipedia.org/wiki/Pekinas" hreflang="lt" lang="lt" title="Pekinas – 立陶宛语">
Lietuvių
</a>
</li>
<li class="interlanguage-link interwiki-lv">
<a class="interlanguage-link-target" href="https://lv.wikipedia.org/wiki/Pekina" hreflang="lv" lang="lv" title="Pekina – 拉脱维亚语">
Latviešu
</a>
</li>
<li class="interlanguage-link interwiki-mai">
<a class="interlanguage-link-target" href="https://mai.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" hreflang="mai" lang="mai" title="बेइजिङ – 迈蒂利语">
मैथिली
</a>
</li>
<li class="interlanguage-link interwiki-mg">
<a class="interlanguage-link-target" href="https://mg.wikipedia.org/wiki/Beijing" hreflang="mg" lang="mg" title="Beijing – 马拉加斯语">
Malagasy
</a>
</li>
<li class="interlanguage-link interwiki-mhr">
<a class="interlanguage-link-target" href="https://mhr.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="mhr" lang="mhr" title="Пекин – Eastern Mari">
Олык марий
</a>
</li>
<li class="interlanguage-link interwiki-mi">
<a class="interlanguage-link-target" href="https://mi.wikipedia.org/wiki/Beijing" hreflang="mi" lang="mi" title="Beijing – 毛利语">
Māori
</a>
</li>
<li class="interlanguage-link interwiki-min">
<a class="interlanguage-link-target" href="https://min.wikipedia.org/wiki/Beijing" hreflang="min" lang="min" title="Beijing – 米南佳保语">
Minangkabau
</a>
</li>
<li class="interlanguage-link interwiki-mk">
<a class="interlanguage-link-target" href="https://mk.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD%D0%B3" hreflang="mk" lang="mk" title="Пекинг – 马其顿语">
Македонски
</a>
</li>
<li class="interlanguage-link interwiki-ml">
<a class="interlanguage-link-target" href="https://ml.wikipedia.org/wiki/%E0%B4%AC%E0%B5%86%E0%B4%AF%E0%B5%8D%E2%80%8C%E0%B4%9C%E0%B4%BF%E0%B4%99%E0%B5%8D%E0%B4%99%E0%B5%8D%E2%80%8C" hreflang="ml" lang="ml" title="ബെയ്ജിങ്ങ് – 马拉雅拉姆语">
മലയാളം
</a>
</li>
<li class="interlanguage-link interwiki-mn">
<a class="interlanguage-link-target" href="https://mn.wikipedia.org/wiki/%D0%91%D1%8D%D1%8D%D0%B6%D0%B8%D0%BD" hreflang="mn" lang="mn" title="Бээжин – 蒙古语">
Монгол
</a>
</li>
<li class="interlanguage-link interwiki-mr">
<a class="interlanguage-link-target" href="https://mr.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%82%E0%A4%97" hreflang="mr" lang="mr" title="बीजिंग – 马拉地语">
मराठी
</a>
</li>
<li class="interlanguage-link interwiki-ms">
<a class="interlanguage-link-target" href="https://ms.wikipedia.org/wiki/Beijing" hreflang="ms" lang="ms" title="Beijing – 马来语">
Bahasa Melayu
</a>
</li>
<li class="interlanguage-link interwiki-mwl">
<a class="interlanguage-link-target" href="https://mwl.wikipedia.org/wiki/Pequin" hreflang="mwl" lang="mwl" title="Pequin – 米兰德斯语">
Mirandés
</a>
</li>
<li class="interlanguage-link interwiki-my">
<a class="interlanguage-link-target" href="https://my.wikipedia.org/wiki/%E1%80%95%E1%80%B1%E1%80%80%E1%80%BB%E1%80%84%E1%80%BA%E1%80%B8%E1%80%99%E1%80%BC%E1%80%AD%E1%80%AF%E1%80%B7" hreflang="my" lang="my" title="ပေကျင်းမြို့ – 缅甸语">
မြန်မာဘာသာ
</a>
</li>
<li class="interlanguage-link interwiki-myv">
<a class="interlanguage-link-target" href="https://myv.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD_%D0%BE%D1%88" hreflang="myv" lang="myv" title="Пекин ош – 厄尔兹亚语">
Эрзянь
</a>
</li>
<li class="interlanguage-link interwiki-mzn">
<a class="interlanguage-link-target" href="https://mzn.wikipedia.org/wiki/%D9%BE%DA%A9%D9%86" hreflang="mzn" lang="mzn" title="پکن – 马赞德兰语">
مازِرونی
</a>
</li>
<li class="interlanguage-link interwiki-na">
<a class="interlanguage-link-target" href="https://na.wikipedia.org/wiki/Beijing" hreflang="na" lang="na" title="Beijing – 瑙鲁语">
Dorerin Naoero
</a>
</li>
<li class="interlanguage-link interwiki-ne">
<a class="interlanguage-link-target" href="https://ne.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" hreflang="ne" lang="ne" title="बेइजिङ – 尼泊尔语">
नेपाली
</a>
</li>
<li class="interlanguage-link interwiki-new">
<a class="interlanguage-link-target" href="https://new.wikipedia.org/wiki/%E0%A4%AC%E0%A5%87%E0%A4%87%E0%A4%9C%E0%A4%BF%E0%A4%99" hreflang="new" lang="new" title="बेइजिङ – 尼瓦尔语">
नेपाल भाषा
</a>
</li>
<li class="interlanguage-link interwiki-nl">
<a class="interlanguage-link-target" href="https://nl.wikipedia.org/wiki/Peking" hreflang="nl" lang="nl" title="Peking – 荷兰语">
Nederlands
</a>
</li>
<li class="interlanguage-link interwiki-nn">
<a class="interlanguage-link-target" href="https://nn.wikipedia.org/wiki/Beijing" hreflang="nn" lang="nn" title="Beijing – 挪威尼诺斯克语">
Norsk nynorsk
</a>
</li>
<li class="interlanguage-link interwiki-no badge-Q17437796 badge-featuredarticle" title="典范条目">
<a class="interlanguage-link-target" href="https://no.wikipedia.org/wiki/Beijing" hreflang="nb" lang="nb" title="Beijing – 书面挪威语">
Norsk bokmål
</a>
</li>
<li class="interlanguage-link interwiki-nov">
<a class="interlanguage-link-target" href="https://nov.wikipedia.org/wiki/Beyjing" hreflang="nov" lang="nov" title="Beyjing – Novial">
Novial
</a>
</li>
<li class="interlanguage-link interwiki-nrm">
<a class="interlanguage-link-target" href="https://nrm.wikipedia.org/wiki/P%C3%A9q%C3%B9in" hreflang="nrf" lang="nrf" title="Péqùin – Norman">
Nouormand
</a>
</li>
<li class="interlanguage-link interwiki-nso">
<a class="interlanguage-link-target" href="https://nso.wikipedia.org/wiki/Beijing" hreflang="nso" lang="nso" title="Beijing – 北索托语">
Sesotho sa Leboa
</a>
</li>
<li class="interlanguage-link interwiki-ny">
<a class="interlanguage-link-target" href="https://ny.wikipedia.org/wiki/Beijing" hreflang="ny" lang="ny" title="Beijing – 齐切瓦语">
Chi-Chewa
</a>
</li>
<li class="interlanguage-link interwiki-oc">
<a class="interlanguage-link-target" href="https://oc.wikipedia.org/wiki/Pequin" hreflang="oc" lang="oc" title="Pequin – 奥克语">
Occitan
</a>
</li>
<li class="interlanguage-link interwiki-olo">
<a class="interlanguage-link-target" href="https://olo.wikipedia.org/wiki/Pekin" hreflang="olo" lang="olo" title="Pekin – Livvi-Karelian">
Livvinkarjala
</a>
</li>
<li class="interlanguage-link interwiki-om">
<a class="interlanguage-link-target" href="https://om.wikipedia.org/wiki/Beejiingi" hreflang="om" lang="om" title="Beejiingi – 奥罗莫语">
Oromoo
</a>
</li>
<li class="interlanguage-link interwiki-or">
<a class="interlanguage-link-target" href="https://or.wikipedia.org/wiki/%E0%AC%AC%E0%AD%87%E0%AC%9C%E0%AC%BF%E0%AC%82" hreflang="or" lang="or" title="ବେଜିଂ – 奥里亚语">
ଓଡ଼ିଆ
</a>
</li>
<li class="interlanguage-link interwiki-os">
<a class="interlanguage-link-target" href="https://os.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="os" lang="os" title="Пекин – 奥塞梯语">
Ирон
</a>
</li>
<li class="interlanguage-link interwiki-pa">
<a class="interlanguage-link-target" href="https://pa.wikipedia.org/wiki/%E0%A8%AC%E0%A9%80%E0%A8%9C%E0%A8%BF%E0%A9%B0%E0%A8%97" hreflang="pa" lang="pa" title="ਬੀਜਿੰਗ – 旁遮普语">
ਪੰਜਾਬੀ
</a>
</li>
<li class="interlanguage-link interwiki-pam">
<a class="interlanguage-link-target" href="https://pam.wikipedia.org/wiki/Beijing" hreflang="pam" lang="pam" title="Beijing – 邦板牙语">
Kapampangan
</a>
</li>
<li class="interlanguage-link interwiki-pap">
<a class="interlanguage-link-target" href="https://pap.wikipedia.org/wiki/Bejing" hreflang="pap" lang="pap" title="Bejing – 帕皮阿门托语">
Papiamentu
</a>
</li>
<li class="interlanguage-link interwiki-pcd">
<a class="interlanguage-link-target" href="https://pcd.wikipedia.org/wiki/P%C3%A9kin" hreflang="pcd" lang="pcd" title="Pékin – Picard">
Picard
</a>
</li>
<li class="interlanguage-link interwiki-pdc">
<a class="interlanguage-link-target" href="https://pdc.wikipedia.org/wiki/Beijing" hreflang="pdc" lang="pdc" title="Beijing – Pennsylvania German">
Deitsch
</a>
</li>
<li class="interlanguage-link interwiki-pih">
<a class="interlanguage-link-target" href="https://pih.wikipedia.org/wiki/Beijing" hreflang="pih" lang="pih" title="Beijing – Norfuk / Pitkern">
Norfuk / Pitkern
</a>
</li>
<li class="interlanguage-link interwiki-pl">
<a class="interlanguage-link-target" href="https://pl.wikipedia.org/wiki/Pekin" hreflang="pl" lang="pl" title="Pekin – 波兰语">
Polski
</a>
</li>
<li class="interlanguage-link interwiki-pms">
<a class="interlanguage-link-target" href="https://pms.wikipedia.org/wiki/Pechin" hreflang="pms" lang="pms" title="Pechin – Piedmontese">
Piemontèis
</a>
</li>
<li class="interlanguage-link interwiki-pnb">
<a class="interlanguage-link-target" href="https://pnb.wikipedia.org/wiki/%D8%A8%DB%8C%D8%AC%D9%86%DA%AF" hreflang="pnb" lang="pnb" title="بیجنگ – Western Punjabi">
پنجابی
</a>
</li>
<li class="interlanguage-link interwiki-ps">
<a class="interlanguage-link-target" href="https://ps.wikipedia.org/wiki/%D8%A8%DB%8C%D8%AC%D9%86%DA%AB" hreflang="ps" lang="ps" title="بیجنګ – 普什图语">
پښتو
</a>
</li>
<li class="interlanguage-link interwiki-pt">
<a class="interlanguage-link-target" href="https://pt.wikipedia.org/wiki/Pequim" hreflang="pt" lang="pt" title="Pequim – 葡萄牙语">
Português
</a>
</li>
<li class="interlanguage-link interwiki-qu">
<a class="interlanguage-link-target" href="https://qu.wikipedia.org/wiki/Pikkin" hreflang="qu" lang="qu" title="Pikkin – 克丘亚语">
Runa Simi
</a>
</li>
<li class="interlanguage-link interwiki-rmy">
<a class="interlanguage-link-target" href="https://rmy.wikipedia.org/wiki/Pekenk" hreflang="rmy" lang="rmy" title="Pekenk – Vlax Romani">
Romani čhib
</a>
</li>
<li class="interlanguage-link interwiki-ro">
<a class="interlanguage-link-target" href="https://ro.wikipedia.org/wiki/Beijing" hreflang="ro" lang="ro" title="Beijing – 罗马尼亚语">
Română
</a>
</li>
<li class="interlanguage-link interwiki-roa-tara">
<a class="interlanguage-link-target" href="https://roa-tara.wikipedia.org/wiki/Pechine" hreflang="nap-x-tara" lang="nap-x-tara" title="Pechine – Tarantino">
Tarandíne
</a>
</li>
<li class="interlanguage-link interwiki-ru">
<a class="interlanguage-link-target" href="https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="ru" lang="ru" title="Пекин – 俄语">
Русский
</a>
</li>
<li class="interlanguage-link interwiki-rue">
<a class="interlanguage-link-target" href="https://rue.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D1%96%D0%BD%D2%91" hreflang="rue" lang="rue" title="Пекінґ – Rusyn">
Русиньскый
</a>
</li>
<li class="interlanguage-link interwiki-sa">
<a class="interlanguage-link-target" href="https://sa.wikipedia.org/wiki/%E0%A4%AC%E0%A5%80%E0%A4%9C%E0%A4%BF%E0%A4%99%E0%A5%8D%E0%A4%97%E0%A5%8D" hreflang="sa" lang="sa" title="बीजिङ्ग् – 梵语">
संस्कृतम्
</a>
</li>
<li class="interlanguage-link interwiki-sah">
<a class="interlanguage-link-target" href="https://sah.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="sah" lang="sah" title="Пекин – 萨哈语">
Саха тыла
</a>
</li>
<li class="interlanguage-link interwiki-sat">
<a class="interlanguage-link-target" href="https://sat.wikipedia.org/wiki/%E1%B1%B5%E1%B1%AE%E1%B1%A1%E1%B1%A4%E1%B1%9D" hreflang="sat" lang="sat" title="ᱵᱮᱡᱤᱝ – 桑塔利语">
ᱥᱟᱱᱛᱟᱲᱤ
</a>
</li>
<li class="interlanguage-link interwiki-sc">
<a class="interlanguage-link-target" href="https://sc.wikipedia.org/wiki/Beijing" hreflang="sc" lang="sc" title="Beijing – 萨丁语">
Sardu
</a>
</li>
<li class="interlanguage-link interwiki-scn">
<a class="interlanguage-link-target" href="https://scn.wikipedia.org/wiki/Pechinu" hreflang="scn" lang="scn" title="Pechinu – 西西里语">
Sicilianu
</a>
</li>
<li class="interlanguage-link interwiki-sco">
<a class="interlanguage-link-target" href="https://sco.wikipedia.org/wiki/Beijing" hreflang="sco" lang="sco" title="Beijing – 苏格兰语">
Scots
</a>
</li>
<li class="interlanguage-link interwiki-se">
<a class="interlanguage-link-target" href="https://se.wikipedia.org/wiki/Peking" hreflang="se" lang="se" title="Peking – 北方萨米语">
Davvisámegiella
</a>
</li>
<li class="interlanguage-link interwiki-sh badge-Q17437796 badge-featuredarticle" title="典范条目">
<a class="interlanguage-link-target" href="https://sh.wikipedia.org/wiki/Peking" hreflang="sh" lang="sh" title="Peking – 塞尔维亚-克罗地亚语">
Srpskohrvatski / српскохрватски
</a>
</li>
<li class="interlanguage-link interwiki-si">
<a class="interlanguage-link-target" href="https://si.wikipedia.org/wiki/%E0%B6%B6%E0%B7%99%E0%B6%BA%E0%B7%92%E0%B6%A2%E0%B7%92%E0%B6%82" hreflang="si" lang="si" title="බෙයිජිං – 僧伽罗语">
සිංහල
</a>
</li>
<li class="interlanguage-link interwiki-simple">
<a class="interlanguage-link-target" href="https://simple.wikipedia.org/wiki/Beijing" hreflang="en-simple" lang="en-simple" title="Beijing – Simple English">
Simple English
</a>
</li>
<li class="interlanguage-link interwiki-sk">
<a class="interlanguage-link-target" href="https://sk.wikipedia.org/wiki/Peking" hreflang="sk" lang="sk" title="Peking – 斯洛伐克语">
Slovenčina
</a>
</li>
<li class="interlanguage-link interwiki-sl">
<a class="interlanguage-link-target" href="https://sl.wikipedia.org/wiki/Peking" hreflang="sl" lang="sl" title="Peking – 斯洛文尼亚语">
Slovenščina
</a>
</li>
<li class="interlanguage-link interwiki-sn">
<a class="interlanguage-link-target" href="https://sn.wikipedia.org/wiki/Beijing" hreflang="sn" lang="sn" title="Beijing – 绍纳语">
ChiShona
</a>
</li>
<li class="interlanguage-link interwiki-so">
<a class="interlanguage-link-target" href="https://so.wikipedia.org/wiki/Beijing" hreflang="so" lang="so" title="Beijing – 索马里语">
Soomaaliga
</a>
</li>
<li class="interlanguage-link interwiki-sq">
<a class="interlanguage-link-target" href="https://sq.wikipedia.org/wiki/Pekini" hreflang="sq" lang="sq" title="Pekini – 阿尔巴尼亚语">
Shqip
</a>
</li>
<li class="interlanguage-link interwiki-sr badge-Q17437796 badge-featuredarticle" title="典范条目">
<a class="interlanguage-link-target" href="https://sr.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD%D0%B3" hreflang="sr" lang="sr" title="Пекинг – 塞尔维亚语">
Српски / srpski
</a>
</li>
<li class="interlanguage-link interwiki-srn">
<a class="interlanguage-link-target" href="https://srn.wikipedia.org/wiki/Beijing" hreflang="srn" lang="srn" title="Beijing – 苏里南汤加语">
Sranantongo
</a>
</li>
<li class="interlanguage-link interwiki-stq">
<a class="interlanguage-link-target" href="https://stq.wikipedia.org/wiki/Peking" hreflang="stq" lang="stq" title="Peking – Saterland Frisian">
Seeltersk
</a>
</li>
<li class="interlanguage-link interwiki-su">
<a class="interlanguage-link-target" href="https://su.wikipedia.org/wiki/B%C3%A9ijing" hreflang="su" lang="su" title="Béijing – 巽他语">
Sunda
</a>
</li>
<li class="interlanguage-link interwiki-sv">
<a class="interlanguage-link-target" href="https://sv.wikipedia.org/wiki/Peking" hreflang="sv" lang="sv" title="Peking – 瑞典语">
Svenska
</a>
</li>
<li class="interlanguage-link interwiki-sw">
<a class="interlanguage-link-target" href="https://sw.wikipedia.org/wiki/Beijing" hreflang="sw" lang="sw" title="Beijing – 斯瓦希里语">
Kiswahili
</a>
</li>
<li class="interlanguage-link interwiki-szl">
<a class="interlanguage-link-target" href="https://szl.wikipedia.org/wiki/Bejd%C5%BCing" hreflang="szl" lang="szl" title="Bejdżing – Silesian">
Ślůnski
</a>
</li>
<li class="interlanguage-link interwiki-ta">
<a class="interlanguage-link-target" href="https://ta.wikipedia.org/wiki/%E0%AE%AA%E0%AF%86%E0%AE%AF%E0%AF%8D%E0%AE%9C%E0%AE%BF%E0%AE%99%E0%AF%8D" hreflang="ta" lang="ta" title="பெய்ஜிங் – 泰米尔语">
தமிழ்
</a>
</li>
<li class="interlanguage-link interwiki-te">
<a class="interlanguage-link-target" href="https://te.wikipedia.org/wiki/%E0%B0%AC%E0%B1%80%E0%B0%9C%E0%B0%BF%E0%B0%82%E0%B0%97%E0%B1%8D" hreflang="te" lang="te" title="బీజింగ్ – 泰卢固语">
తెలుగు
</a>
</li>
<li class="interlanguage-link interwiki-tg">
<a class="interlanguage-link-target" href="https://tg.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="tg" lang="tg" title="Пекин – 塔吉克语">
Тоҷикӣ
</a>
</li>
<li class="interlanguage-link interwiki-th">
<a class="interlanguage-link-target" href="https://th.wikipedia.org/wiki/%E0%B8%9B%E0%B8%B1%E0%B8%81%E0%B8%81%E0%B8%B4%E0%B9%88%E0%B8%87" hreflang="th" lang="th" title="ปักกิ่ง – 泰语">
ไทย
</a>
</li>
<li class="interlanguage-link interwiki-tk">
<a class="interlanguage-link-target" href="https://tk.wikipedia.org/wiki/Pekin" hreflang="tk" lang="tk" title="Pekin – 土库曼语">
Türkmençe
</a>
</li>
<li class="interlanguage-link interwiki-tl">
<a class="interlanguage-link-target" href="https://tl.wikipedia.org/wiki/Beijing" hreflang="tl" lang="tl" title="Beijing – 他加禄语">
Tagalog
</a>
</li>
<li class="interlanguage-link interwiki-tn">
<a class="interlanguage-link-target" href="https://tn.wikipedia.org/wiki/Beijing" hreflang="tn" lang="tn" title="Beijing – 茨瓦纳语">
Setswana
</a>
</li>
<li class="interlanguage-link interwiki-to">
<a class="interlanguage-link-target" href="https://to.wikipedia.org/wiki/Beijing" hreflang="to" lang="to" title="Beijing – 汤加语">
Lea faka-Tonga
</a>
</li>
<li class="interlanguage-link interwiki-tpi">
<a class="interlanguage-link-target" href="https://tpi.wikipedia.org/wiki/Beijing" hreflang="tpi" lang="tpi" title="Beijing – 托克皮辛语">
Tok Pisin
</a>
</li>
<li class="interlanguage-link interwiki-tr">
<a class="interlanguage-link-target" href="https://tr.wikipedia.org/wiki/Pekin" hreflang="tr" lang="tr" title="Pekin – 土耳其语">
Türkçe
</a>
</li>
<li class="interlanguage-link interwiki-ts">
<a class="interlanguage-link-target" href="https://ts.wikipedia.org/wiki/Beyijingi" hreflang="ts" lang="ts" title="Beyijingi – 聪加语">
Xitsonga
</a>
</li>
<li class="interlanguage-link interwiki-tt">
<a class="interlanguage-link-target" href="https://tt.wikipedia.org/wiki/%D0%A5%D0%B0%D0%BD%D0%B1%D0%B0%D0%BB%D1%8B%D0%BA" hreflang="tt" lang="tt" title="Ханбалык – 鞑靼语">
Татарча/tatarça
</a>
</li>
<li class="interlanguage-link interwiki-tum">
<a class="interlanguage-link-target" href="https://tum.wikipedia.org/wiki/Beijing" hreflang="tum" lang="tum" title="Beijing – 通布卡语">
ChiTumbuka
</a>
</li>
<li class="interlanguage-link interwiki-tw">
<a class="interlanguage-link-target" href="https://tw.wikipedia.org/wiki/Beijing" hreflang="tw" lang="tw" title="Beijing – 契维语">
Twi
</a>
</li>
<li class="interlanguage-link interwiki-udm">
<a class="interlanguage-link-target" href="https://udm.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D0%B8%D0%BD" hreflang="udm" lang="udm" title="Пекин – 乌德穆尔特语">
Удмурт
</a>
</li>
<li class="interlanguage-link interwiki-ug">
<a class="interlanguage-link-target" href="https://ug.wikipedia.org/wiki/%D8%A8%DB%90%D9%8A%D8%AC%D9%89%DA%AD_%D8%B4%DB%95%DA%BE%D9%89%D8%B1%D9%89" hreflang="ug" lang="ug" title="بېيجىڭ شەھىرى – 维吾尔语">
ئۇيغۇرچە / Uyghurche
</a>
</li>
<li class="interlanguage-link interwiki-uk">
<a class="interlanguage-link-target" href="https://uk.wikipedia.org/wiki/%D0%9F%D0%B5%D0%BA%D1%96%D0%BD" hreflang="uk" lang="uk" title="Пекін – 乌克兰语">
Українська
</a>
</li>
<li class="interlanguage-link interwiki-ur">
<a class="interlanguage-link-target" href="https://ur.wikipedia.org/wiki/%D8%A8%DB%8C%D8%AC%D9%86%DA%AF" hreflang="ur" lang="ur" title="بیجنگ – 乌尔都语">
اردو
</a>
</li>
<li class="interlanguage-link interwiki-uz">
<a class="interlanguage-link-target" href="https://uz.wikipedia.org/wiki/Pekin" hreflang="uz" lang="uz" title="Pekin – 乌兹别克语">
Oʻzbekcha/ўзбекча
</a>
</li>
<li class="interlanguage-link interwiki-vec">
<a class="interlanguage-link-target" href="https://vec.wikipedia.org/wiki/Pechin" hreflang="vec" lang="vec" title="Pechin – Venetian">
Vèneto
</a>
</li>
<li class="interlanguage-link interwiki-vep">
<a class="interlanguage-link-target" href="https://vep.wikipedia.org/wiki/Pekin" hreflang="vep" lang="vep" title="Pekin – 维普森语">
Vepsän kel’
</a>
</li>
<li class="interlanguage-link interwiki-vi">
<a class="interlanguage-link-target" href="https://vi.wikipedia.org/wiki/B%E1%BA%AFc_Kinh" hreflang="vi" lang="vi" title="Bắc Kinh – 越南语">
Tiếng Việt
</a>
</li>
<li class="interlanguage-link interwiki-vo">
<a class="interlanguage-link-target" href="https://vo.wikipedia.org/wiki/Beycing" hreflang="vo" lang="vo" title="Beycing – 沃拉普克语">
Volapük
</a>
</li>
<li class="interlanguage-link interwiki-wa">
<a class="interlanguage-link-target" href="https://wa.wikipedia.org/wiki/Pekin" hreflang="wa" lang="wa" title="Pekin – 瓦隆语">
Walon
</a>
</li>
<li class="interlanguage-link interwiki-war">
<a class="interlanguage-link-target" href="https://war.wikipedia.org/wiki/Beijing" hreflang="war" lang="war" title="Beijing – 瓦瑞语">
Winaray
</a>
</li>
<li class="interlanguage-link interwiki-wo">
<a class="interlanguage-link-target" href="https://wo.wikipedia.org/wiki/Beijing" hreflang="wo" lang="wo" title="Beijing – 沃洛夫语">
Wolof
</a>
</li>
<li class="interlanguage-link interwiki-wuu">
<a class="interlanguage-link-target" href="https://wuu.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="wuu" lang="wuu" title="北京 – 吴语">
吴语
</a>
</li>
<li class="interlanguage-link interwiki-xal">
<a class="interlanguage-link-target" href="https://xal.wikipedia.org/wiki/%D0%91%D3%99%D3%99%D2%97%D2%A3_%D0%B1%D0%B0%D0%BB%D2%BB%D1%81%D0%BD" hreflang="xal" lang="xal" title="Бәәҗң балһсн – 卡尔梅克语">
Хальмг
</a>
</li>
<li class="interlanguage-link interwiki-xmf">
<a class="interlanguage-link-target" href="https://xmf.wikipedia.org/wiki/%E1%83%9E%E1%83%94%E1%83%99%E1%83%98%E1%83%9C%E1%83%98" hreflang="xmf" lang="xmf" title="პეკინი – Mingrelian">
მარგალური
</a>
</li>
<li class="interlanguage-link interwiki-yi">
<a class="interlanguage-link-target" href="https://yi.wikipedia.org/wiki/%D7%91%D7%99%D7%99%D7%96%D7%A9%D7%99%D7%A0%D7%92" hreflang="yi" lang="yi" title="בייזשינג – 意第绪语">
ייִדיש
</a>
</li>
<li class="interlanguage-link interwiki-yo">
<a class="interlanguage-link-target" href="https://yo.wikipedia.org/wiki/Beijing" hreflang="yo" lang="yo" title="Beijing – 约鲁巴语">
Yorùbá
</a>
</li>
<li class="interlanguage-link interwiki-za">
<a class="interlanguage-link-target" href="https://za.wikipedia.org/wiki/Baekging" hreflang="za" lang="za" title="Baekging – 壮语">
Vahcuengh
</a>
</li>
<li class="interlanguage-link interwiki-zea">
<a class="interlanguage-link-target" href="https://zea.wikipedia.org/wiki/Peking" hreflang="zea" lang="zea" title="Peking – Zeelandic">
Zeêuws
</a>
</li>
<li class="interlanguage-link interwiki-zh-classical">
<a class="interlanguage-link-target" href="https://zh-classical.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC%E5%B8%82" hreflang="lzh" lang="lzh" title="北京市 – Classical Chinese">
文言
</a>
</li>
<li class="interlanguage-link interwiki-zh-min-nan">
<a class="interlanguage-link-target" href="https://zh-min-nan.wikipedia.org/wiki/Pak-kia%E2%81%BF-chh%C4%AB" hreflang="nan" lang="nan" title="Pak-kiaⁿ-chhī – Chinese (Min Nan)">
Bân-lâm-gú
</a>
</li>
<li class="interlanguage-link interwiki-zh-yue">
<a class="interlanguage-link-target" href="https://zh-yue.wikipedia.org/wiki/%E5%8C%97%E4%BA%AC" hreflang="yue" lang="yue" title="北京 – Cantonese">
粵語
</a>
</li>
<li class="interlanguage-link interwiki-zu">
<a class="interlanguage-link-target" href="https://zu.wikipedia.org/wiki/Beijing" hreflang="zu" lang="zu" title="Beijing – 祖鲁语">
IsiZulu
</a>
</li>
</ul>
<div class="after-portlet after-portlet-lang">
<span class="wb-langlinks-edit wb-langlinks-link">
<a class="wbc-editpage" href="https://www.wikidata.org/wiki/Special:EntityPage/Q956#sitelinks-wikipedia" title="编辑跨语言链接">
编辑链接
</a>
</span>
</div>
</div>
</nav>
</div>
</div>
<footer class="mw-footer" id="footer" role="contentinfo">
<ul id="footer-info">
<li id="footer-info-lastmod">
本页面最后修订于2021年1月6日 (星期三) 07:09。
</li>
<li id="footer-info-copyright">
本站的全部文字在
<a href="//zh.wikipedia.org/wiki/Wikipedia:CC-BY-SA-3.0%E5%8D%8F%E8%AE%AE%E6%96%87%E6%9C%AC" rel="license" title="Wikipedia:CC-BY-SA-3.0协议文本">
知识共享 署名-相同方式共享 3.0协议
</a>
<a href="//creativecommons.org/licenses/by-sa/3.0/deed.zh" rel="license" style="display:none;">
</a>
之条款下提供,附加条款亦可能应用。(请参阅
<a href="//foundation.wikimedia.org/wiki/Terms_of_Use">
使用条款
</a>
)
<br/>
Wikipedia®和维基百科标志是
<a href="//wikimediafoundation.org">
维基媒体基金会
</a>
的注册商标;维基™是维基媒体基金会的商标。
<br/>
维基媒体基金会是按美国国內稅收法501(c)(3)登记的
<a href="//donate.wikimedia.org/wiki/Tax_deductibility">
非营利慈善机构
</a>
。
<br/>
</li>
</ul>
<ul id="footer-places">
<li id="footer-places-privacy">
<a class="extiw" href="https://foundation.wikimedia.org/wiki/Privacy_policy" title="wmf:Privacy policy">
隐私政策
</a>
</li>
<li id="footer-places-about">
<a href="/wiki/Wikipedia:%E5%85%B3%E4%BA%8E" title="Wikipedia:关于">
关于维基百科
</a>
</li>
<li id="footer-places-disclaimer">
<a href="/wiki/Wikipedia:%E5%85%8D%E8%B4%A3%E5%A3%B0%E6%98%8E" title="Wikipedia:免责声明">
免责声明
</a>
</li>
<li id="footer-places-mobileview">
<a class="noprint stopMobileRedirectToggle" href="//zh.m.wikipedia.org/w/index.php?title=%E5%8C%97%E4%BA%AC%E5%B8%82&mobileaction=toggle_view_mobile">
手机版视图
</a>
</li>
<li id="footer-places-developers">
<a href="https://www.mediawiki.org/wiki/Special:MyLanguage/How_to_contribute">
开发者
</a>
</li>
<li id="footer-places-statslink">
<a href="https://stats.wikimedia.org/#/zh.wikipedia.org">
统计
</a>
</li>
<li id="footer-places-cookiestatement">
<a href="https://foundation.wikimedia.org/wiki/Cookie_statement">
Cookie声明
</a>
</li>
</ul>
<ul class="noprint" id="footer-icons">
<li id="footer-copyrightico">
<a href="https://wikimediafoundation.org/">
<img alt="Wikimedia Foundation" height="31" loading="lazy" src="/static/images/footer/wikimedia-button.png" srcset="/static/images/footer/wikimedia-button-1.5x.png 1.5x, /static/images/footer/wikimedia-button-2x.png 2x" width="88"/>
</a>
</li>
<li id="footer-poweredbyico">
<a href="https://www.mediawiki.org/">
<img alt="Powered by MediaWiki" height="31" loading="lazy" src="/static/images/footer/poweredby_mediawiki_88x31.png" srcset="/static/images/footer/poweredby_mediawiki_132x47.png 1.5x, /static/images/footer/poweredby_mediawiki_176x62.png 2x" width="88"/>
</a>
</li>
</ul>
<div style="clear: both;">
</div>
</footer>
<script>
(RLQ=window.RLQ||[]).push(function(){mw.config.set({"wgPageParseReport":{"limitreport":{"cputime":"3.848","walltime":"4.782","ppvisitednodes":{"value":29346,"limit":1000000},"postexpandincludesize":{"value":2036601,"limit":2097152},"templateargumentsize":{"value":274762,"limit":2097152},"expansiondepth":{"value":22,"limit":40},"expensivefunctioncount":{"value":25,"limit":500},"unstrip-depth":{"value":0,"limit":20},"unstrip-size":{"value":202785,"limit":5000000},"entityaccesscount":{"value":1,"limit":400},"timingprofile":["100.00% 3147.668 1 -total"," 41.47% 1305.187 44 Template:Navbox"," 26.25% 826.113 1 Template:Reflist"," 22.79% 717.504 1 Template:Template_group"," 15.20% 478.549 97 Template:Cite_web"," 10.64% 334.758 53 Template:Flag"," 7.93% 249.616 3 Template:Navbox_with_columns"," 7.24% 227.781 66 Template:Flagicon"," 5.92% 186.452 5 Template:Infobox"," 5.89% 185.443 1 Template:夏季奧運會主辦城市"]},"scribunto":{"limitreport-timeusage":{"value":"1.006","limit":"10.000"},"limitreport-memusage":{"value":10095269,"limit":52428800},"limitreport-profile":[["Scribunto_LuaSandboxCallback::getExpandedArgument","460","32.9"],["Scribunto_LuaSandboxCallback::find","220","15.7"],["?","100","7.1"],["\u003Cmw.lua:683\u003E","80","5.7"],["Scribunto_LuaSandboxCallback::getEntity","80","5.7"],["recursiveClone \u003CmwInit.lua:41\u003E","60","4.3"],["tonumber","40","2.9"],["Scribunto_LuaSandboxCallback::newTitle","40","2.9"],["Scribunto_LuaSandboxCallback::getAllExpandedArguments","40","2.9"],["Scribunto_LuaSandboxCallback::plain","40","2.9"],["[others]","240","17.1"]]},"cachereport":{"origin":"mw1401","timestamp":"20210109032017","ttl":86400,"transientcontent":true}}});});
</script>
<script type="application/ld+json">
{"@context":"https:\/\/schema.org","@type":"Article","name":"\u5317\u4eac\u5e02","url":"https:\/\/zh.wikipedia.org\/wiki\/%E5%8C%97%E4%BA%AC%E5%B8%82","sameAs":"http:\/\/www.wikidata.org\/entity\/Q956","mainEntity":"http:\/\/www.wikidata.org\/entity\/Q956","author":{"@type":"Organization","name":"\u7ef4\u57fa\u5a92\u4f53\u9879\u76ee\u8d21\u732e\u8005"},"publisher":{"@type":"Organization","name":"Wikimedia Foundation, Inc.","logo":{"@type":"ImageObject","url":"https:\/\/www.wikimedia.org\/static\/images\/wmf-hor-googpub.png"}},"datePublished":"2003-03-22T14:53:23Z","dateModified":"2021-01-06T07:09:44Z","image":"https:\/\/upload.wikimedia.org\/wikipedia\/commons\/f\/f2\/Flickr_-_archer10_%28Dennis%29_-_China-6123.jpg","headline":"\u4e2d\u534e\u4eba\u6c11\u5171\u548c\u56fd\u7684\u9996\u90fd\u548c\u4e00\u4e2a\u76f4\u8f96\u5e02"}
</script>
<script>
(RLQ=window.RLQ||[]).push(function(){mw.config.set({"wgBackendResponseTime":309,"wgHostname":"mw1387"});});
</script>
</body>
</html>
输出格式发生了明显变化。现在,可以通过 soup 对象的 title 属性来查看网页标题了
web_text.title
<title>北京市 - 维基百科,自由的百科全书</title>
网页上有很多北京的名胜古迹与地标照片,不妨把它们存到本地文件夹里。
这要用到 python 的 urlib 库来检索要保存图片的 URL,它有一个 urllib.request() 方法用来打开和读取 URL,调用该对象的 urlretrieve() 方法可以将 URL 表示的对象下到本地文件中:
import urllib
def download_img(url, i):
# 提前建好文件夹
folder = r'./data/demo data/Beijing/'
# 图像存储路径
filepath = folder + str(i) + '.jpg'
# 检索图像并存入文件夹
urllib.request.urlretrieve(url, filepath)
图像都存在 HTML 的“img”标签下,可以调用 soup 对象的 find_all() 将他们找出来。然后就可以遍历图像,用 image 对象的 get() 获取原图。
images = web_text.find_all("img")
i = 1
for image in images[2:10]:
try:
download_img('https:' + image.get('src'), i)
i = i+1
except:
continue
在用 CNN 之类的技术分析图像前,总得先知道怎么把图像读进来。以上面存好的图像为例,为此你需要用到 Python 的 PIL(Python Image Library) 库。
调用 PIL 里 Image 模块的 open() 方法并把图像路径传进去:
from PIL import Image
filename = r'./data/demo data/Beijing/1.jpg'
Image.open(filename)

如果你想一口气读取多个文件怎么办?这可算是很常见的需求了
Python 的 Glob 模块可以遍历同一位置的多个文件。用 glob.glob() 可以将本地文件夹中符合特殊模式的文件一并导入。
文件名模式可以用不同的通配符表示,比如 * 可以匹配多个字符,? 匹配单个字符,或者 [0-9] 匹配任意数字。
举例来讲,从相同目录导入多个 .py 文件,可以用通配符 *:
import glob
for i in glob.glob('./data/demo data/*.py'):
print(i)
./data/demo data\test1.py ./data/demo data\test_demo_1.py ./data/demo data\test_demo_2.py
导入只有五个字符的 Python 文件,可以用 ?:
for i in glob.glob('./data/demo data/?????.py'):
print(i)
./data/demo data\test1.py
导入文件名中带数字的图像文件时,可以用[0-9]:
for i in glob.glob('./data/demo data/test_img[0-9].png'):
print(i)
./data/demo data\test_img1.png
上面我们从维基百科下了些北京的图片,并存到了本地。现在我们来用 glob 模块检索,然后用 PIL 库展示:
from PIL import Image
import matplotlib.pyplot as plt
filepath = r'./data/demo data/Beijing'
images = glob.glob(filepath + '\*.jpg')
for i in images[:3]:
img = Image.open(i)
plt.imshow(img)
plt.show()